临床实践指南制定的自动化、智能化工具研究进展
2023-01-03余丽娜任相颖任相阁王永博李绪辉黄桥张蓉王婷靳英辉
余丽娜,任相颖,任相阁,王永博,李绪辉,黄桥,张蓉,王婷,靳英辉
2011年,美国医学研究所(IOM)将临床实践指南(CPG,下文简称指南)定义为是基于系统评价证据,平衡不同干预措施的利弊后形成的旨在为患者提供最佳保健服务的推荐意见[1]。指南是促进高质量证据向临床决策转化的重要路径,指南的推广和实施有助于持续提高医疗服务质量,保证医务人员提供给患者最佳和最合理的医疗服务,同时也可减少不同机构或人员之间医疗实践的差异性,规范医疗行为[2]。指南的制订是一项复杂、耗时且昂贵的系统工程,通常需1~2年时间完成。2003年一项对指南制订者的调查发现指南制订的平均成本为每部指南200 000美元[3]。一项针对国际指南制订机构的调查显示,22.9%(8/35)的国际指南制订机构修订周期为4~5年,40%(14/35)的修订周期为2~3年,8.6%(3/35)的修订周期≤1年,28.6%(10/35)未明确修订周期[4]。指南制订的时间长、成本高和更新慢,严重影响了指南的有效使用及最新临床研究证据向实践的有效转化。如何利用自动化、智能化的工具或平台加速指南的制订流程,提高其更新效率,创新其传播方式现已成为循证医学研究中核心议题之一,为此研究者应用计算机、数据挖掘等技术,开发了多种工具或平台,辅助指南的制订、更新与传播。本文旨在介绍指南制订工具或平台并对其能实现的功能进行总结分析,以传播这些方法和技术,促进指南制订者的选择使用。
1 指南制订中系统评价的自动化、智能化工具
在指南制订过程中,涉及一系列严格的科学步骤,其中最耗时的过程是对现有证据进行系统评价[5]。有研究表明从注册到发布,系统评价平均需要67周[6]。使用自动化、智能化工具可提高文献检索、文献筛选、数据提取与分析和偏倚风险评估的效率,减少人工重复劳动,进而优化和加速指南的制订过程。国际指南网(GIN)已在其网站上发布了一系列推荐的工具,如CAN-IMPLEMENT©(用于对现有的指南进行修订和改编);Abstrackr(半自动的文献筛选工具);Epistemonikos(面向医疗专业人员、研究人员和医疗决策者的证据库);RevMan、Distiller SR、Rayyan、JBI-SUMARI、EPPI-Reviewer和Covidence(系统评价工具)等[7]。为了方便研究人员选择合适的自动化工具,Dr.Mershall于2015年创建了系统评价工具箱(http://systematicreviewtools.com),该在线平台全面的汇总了现存的系统评价工具,截止目前已收录了213个自动化、智能化工具。
1.1 文献检索指南的制订需要收集所有可能获得的相关高质量证据。文献检索的过程常常依据证据金字塔“从高到低”逐级检索的顺序进行,证据的类型一般包括临床实践指南、系统评价、Meta分析、实验性研究、观察性研究、质性研究、专业共识、专家意见、案例分析、经济学研究等[8]。常用数据库有Cochrane图书馆、JBI循证卫生保健数据库、Campbell图书馆、Pubmed、CNKI等。相较于常用数据库而言,Epistemoniko(https://www.epistemonikos.org)作为系统评价数据库能够同时搜索多个数据库(包括Cochrane、JBI、DARE、Pubmed等10个数据库),同时可使用包括中文在内的9种语言直接搜索。其次,Epistemoniko“证据矩阵”工具有助于快速搜索和更新。该工具可以自动检测与“证据矩阵”共享原始研究的新的系统评价,并提醒研究者有新证据更新[9]。
1.1.1 构建检索策略在文献检索中,首要任务是构建检索策略。确定检索式、查找主题词和自由词是形成敏感和完整检索策略的关键。John在对研究人员和医生的调查中发现“难以选择最佳策略来搜索文献”是文献检索的障碍之一[10]。医学文本索引器(MTI)是美国国家医学图书馆(NLM)开发的文本分析工具,能够根据医学主题词(MeSH)生成半自动和全自动索引建议[11]。2014年,MTI与NLM的MeSH部门合作开发了MeSH on Demand(https://meshb.nlm.nih.gov/MeSHonDemand),为MTI提供了简化的用户界面。研究者可将含有主题词或自由词的文本(手稿或是文献摘要)复制到MeSH on Demand中,系统可自动标识出文本中MeSH术语,研究者可利用标识出的MeSH术语在PubMed中开始检索。同时系统还会列出与提交文本相关的PubMed/MEDLINE中的相识文献。
1.1.2 基于Web的搜索工具Import.io(https://www.import.io/)是一个免费的网络爬取软件,主要功能是搜索现有的基于Web的搜索引擎,并下载搜索结果(包括搜索词,搜索日期和网页地址等)。在系统评价中,可被用来从网站上下载文献,以提高灰色文献检索的透明度和可重复性[12]。Import.io通过透明地记录搜索结果,可以提高系统评价检索的可重复性。同时,使用Import.io可以将在各网站上的搜索结果整理到一个数据库中,并以详细的引文形式呈现,研究者可以很容易对其进行更新,组合和修改。
PaperBot(https://github.com/NeuroMorphoOrg)是一个免费的、可配置、模块化的开源爬网程序,可自动、定期的进行全文检索并能有效注释经过同行评审的文献。PaperBot可独立运行,也可与其他软件平台集成。PaperBot根据预设的检索策略来检索包括Elsevier、Wiley、Springer、PubMed、Nature和Google Scholar在内的各种数据库。PaperBot还提供手动添加文章的一键式选项,保存文献信息后能通过网络访问。PaperBot的定期每月搜索,重复检测和文献信息提取大大节省了在文献检索和更新上耗费的人力[13]。
1.2 文献筛选对文献进行系统的筛选是一项繁琐且耗时但至关重要的步骤。文献筛选通常分为两个阶段,第一阶段通过阅读文献的标题和摘要来排除不相关的文献,第二阶段通过阅读全文来排除不相关的文献。基于研究设计类型和标题和摘要的文献的筛选工具已经成熟。利用机器学习、文字挖掘、数据挖掘、文本分类等技术开发的文献筛选工具,能够对标题和摘要进行自动、半自动筛选,排除不相关的文献,获取符合纳入标准的文献,极大节省了人工筛选的时间[14],但基于全文的文献筛选仍是严峻的挑战[15]。
1.2.1 基于研究设计类型的文献筛选工具Cochrane协作网通过众包(Cochrane Crowd平台)和机器学习混合的方法来识别所有已发表的随机对照试验(RCT)以建立一个全面的RCT数据库。研究表明使用这种混合方法将所需手动筛选的文献数量减少78%,召回率保持在98%[16]。Cohen开发的RCT Tagge(http://arrowsmith.psych.uic.edu/cgibin/arrowsmith_uic/RCT_Tagger.cgi)使用机器学习的方法来检测文献中的RCT。研究显示该工具准确区分RCT和非RCT的接受者操作特征曲线下面积(AUROC)为0.973[17]。该工具可免费使用并允许研究者自主选择搜索的置信度阈值。另外,Marshall开发的RobotSearch使用卷积神经网络、支持向量机和集成法来识别RCT。该工具已被验证能够达到很高的区分性能(AUROC=0.987),与基于关键词的Cochrane高敏感度搜索策略相比,检索到的不相关文章的数量减少了大约一半,而不会丢失任何其他RCT[18]。研究者可通过将RIS文件上传到RobotSearch网站(https://robotsearch.vortext.systems/)就可以免费使用该工具,工具会返回仅包含RCT的过滤文件。
1.2.2 基于标题和摘要的文献筛选工具Abstrackr(http://abstrackr.cebm.brown.edu/)是一个免费的在线机器学习工具,通过半自动化标题和摘要筛选来提高证据综合的效率。截至2012年,Abstrackr已被用于促进至少50个系统评价的筛选[19]。Abstrackr通过学习研究者的纳入和排除标准,从已筛选文献的摘要和标题中提取关键字,构建可模仿用户决策的模型。当Abstrackr学习了足够多的纳入和排除文献时,就可自动筛选剩余的文献,从而使人工筛选的工作量减半。类似的文献筛选的工具还有ASReview(https://asreview.nl/#!/up),该工具使用主动学习来训练机器学习模型,以提高筛选标题和摘要的效率[20]。另外,国内的研究者如北医三院也开发的基于PICO问题的文献题录筛选工具EBM AI-Reviewer(http://www.Ebmeasyreviewer.com/login)[21]。
1.3 数据提取传统系统评价方法中利用数据提取表格手动采集录入相关研究数据无疑是耗时耗力的,如何自动提取数据的方法和技术仍具有挑战,目前并未成熟[22]。Jonnalagadda在系统评价中指出尚未找到统一的数据提取框架,生物医学自然语言处理技术未得到充分利用,无法完全或部分完成自动化的数据提取[23]。2016年,国际系统评价自动化协作组织(ICASR)将开发数据提取工具作为优先领域,目前在提取哪些元素,如何测量准确性以及如何在协作中共享数据等方面尚未达成共识[24]。目前存在的数据提取工具主要有机器学习数据提取工具(ExaCT)和用于PDF的自动化结构化数据提取工具(Graph2Data)。
ExaCT(http://exactdemo.iit.nrc.ca)可帮助研究者从文献中提取关键的实验特征[25]。该工具由两个主要部分组成:IE引擎和交互式用户界面。IE引擎自动识别文献中描述实验的干预措施、人群、结局指标、资金来源和其他特征的文本。对全文数据的提取有两个阶段,第一个阶段是目标句子的识别,第二阶段是弱提取规则的应用。通过用户界面向研究者展示每项提取的实验特征相应目标片段中得分最高的句子。研究者可评估并更正信息,再将其存储在数据库中。在ExaCT团队的评估中发现,当检索到5个最有可能的句子时,该工具具有很高的召回率(对于收集的不同变量而言,召回率为72%~100%)。
Graph2Data(https://github.com/EPPI-Centre/Graph2Data)是基于Web的图形数据提取工具,可以帮助研究者从PDF文件的图形中提取定量数据。该工具在研究者指定轴值和数据类型后通过鼠标在屏幕上单击适当的点来从图形中提取数据[26]。
1.4 数据分析数据分析工具,特别是用于执行meta分析的工具,已被大家熟知,如RevMan、MetaDisc、WinBUGS、Stata和R等。但从原始文献自动提取效应量,尤其是从图形中提取统计信息仍然是困难的,相关的自动化工具还有待开发。
MetaInsight(https://crsu.shinyapps.io/Metainsightc)不需要用户安装任何专用软件,可直接通过Web进行网状Meta分析[27]。该工具是交互式的,用户输入数据后只需点击各选项就能进行数据分析并以可视化方式呈现研究结果、网络图和森林图。该工具还可进行异致性检验和敏感性分析。
PythonMeta(https://www.pymeta.com/)是适用于Python语言的Meta分析软件包,可实现固定和随机效应模型常见效应量(OR、RR、RD、MD、SMD),异质性检验(Q/卡方检验)、亚组分析、累积Meta分析、敏感性分析、森林图、漏斗图等。相较于其他Meta分析软件,具有跨平台使用、功能定制、网络支持和易于扩展的优点[28]。
1.5 偏倚风险评估在系统评价中评估原始研究的方法学质量非常重要。质量包括内部真实性和外部真实性,而方法学质量通常是指内部真实性。内部真实性也被Cochrane协作网称为“偏倚风险(RoB)[29]。研究表明,80%的RCT的偏倚风险评估需要花费平均10~60 min的时间才能完成[30]。利用人工智能技术,实现偏倚风险评估的自动化,将从一定程度上减轻研究者的工作量。
RobotReviewer(https://vortext.systems/robotreviewer)是一个机器学习系统,可自动进行临床实验偏倚风险评估。RobotReviewer会以PDF格式获取RCT报告,自动检索并标记文献中描述PICO(人群、干预、对照和结果)和实验设计(随机序列生成、分配隐藏等)的句子,进行偏倚风险评估并输出结果(低、高或不明确)。开发团队进行的验证研究发现,自动化的RoB评估偏倚风险测试结果比人工评估的准确度低7%。开发者认为尽管现在该工具准确性落后于人类,但随着方法的改进和性能的提升可能会缩小这一差距,且最终可完全取代人工偏倚风险评估[31]。
1.6 用于系统评价综合性工具除单一功能的自动化、智能化工具外,许多研究组织还开发了具有更多功能的综合性系统评价工具,包括Covidence[32]、DistillerSR[33]、EPPI-Reviewer[34]、Rayyan[35]、JBI-SUMARI[36]、SyRF[37]和Systematic Review Accelerator(SRA)[38],表1。其中,Covidence和EPPI-Reviewer都是Cochrane社区推荐的工具,可使用Cochrane帐户登录并免费使用[39]。同时,已有研究者在案例报告中描述了如何使用SRA在2周内完成一个完整的系统评价的详细过程[38]。

表1 多功能自动化、智能化的综合性系统评价工具
2 针对指南制订全过程的自动化、智能化工具
2.1 MAGIC证据生态系统的核心平台--MAGICappMAGIC(Making GRADE the Irresistible Choice,网址:www.magicproject.org)是一项非盈利的国际性科研和创新组织,致力于结合网络技术并通过国际合作以促进可信赖指南的制定,传播和动态更新。MAGIC提出了“数据化和可信的证据生态系统(Digital and trustworthy evidence ecosystem)”的概念,该系统认为一个良好的证据生态系统要求最佳的证据必须在原始研究的研究者、证据合成的研究者、证据传播和证据应用的专业实践者之间进行无缝转化,以实现可持续循环[40]。这样一个动态化的过程被称之为证据生态系统。证据生态系统的循环基于五大核心要素,包括:①电子化、结构化数据;②可信证据;③方法上共识;④分享文化和氛围;⑤工具和平台。这五大要素推动了证据从研究向实践不断的流动更新。2013年MAGIC发布了一个在线应用程序MAGICapp(网址:www.magicapp.org)。MAGICapp是证据生态系统的核心平台,可以创建,传播和动态更新数字化和结构化的证据概要和推荐意见[41],它是一个基于web的协作工具,不需要安装任何软件,适用于所有移动设备。MAGICapp使用GRADE方法,以高度结构化的方式编写指南和证据概要。同时,也可对指南进行维护以使它们始终保持最新状态,并根据研究者选择的渠道发布它们,图1。MAGICapp能够实现简化指南制订的过程(参考资料管理,结构化PICO问题,进行GRADE证据评价等)、在线发布指南、各指南制订小组成员在线协同工作、项目管理(监控进度、发布分配任务和质量控制)、根据相应PICO的证据摘要自动生成决策辅助工具和实现与电子医疗记录(Electronic Medical Records,EMR)集成的功能。
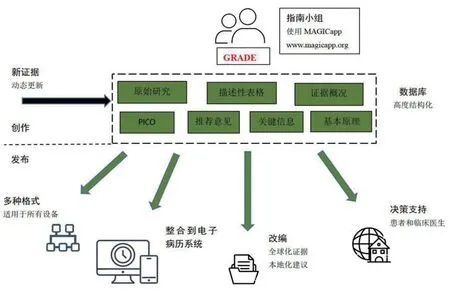
图1 MAGICapp-指南的创作和发布平台
2.2 GRADE工作组开发的指南制订工具--GRADEpro GRADE工作组于2013年正式推出了一款在线的指南制订工具GRADEpro GDT[42],可通过http://guidelinedevelopment.org或http://gradepro.org获得,GRADEpro用于系统评价和指南制定。GRADEpro遵循GRADE方法,从证据总结到推荐意见的产生和传播,能够指导整个指南制定的过程。GRADEpro的主要功能包括团队管理、范围管理(向项目成员发送表格以进行头脑风暴,通过优先级的划分筛选临床问题,确定指南领域)、利益冲突管理、参考文献管理、创建证据概要表、简化从证据到推荐意见的流程、与各种外部系统(例如RevMan、电子医疗记录系统等)交换数据和发布指南。目前,已有全球许多知名的医疗卫生机构和协会(如世界卫生组织、欧洲呼吸学会、美国胸腔学会、欧洲重症监护医学会、世界过敏组织和沙特阿拉伯卫生部等)在指南制订的过程中使用GRADEpro[43]。一项对GIN个人及组织成员的调查结果发现 GRADEpro是最受欢迎的指南制订工具(在受访者中占26%),指南制订工具主要用于指南制定的证据收集阶段[44]。
2.3 MAGICapp和GRADEPro关键功能的比较
2.3.1 团队管理与任务管理MAGICapp区分了组织和个人账户。只有组织账户才能发布指南,组织账户的管理员才能以该组织的名义创建指南。创建指南后,管理员可以添加指南管理员、作者、审阅者和查看者。个人账户无法发布指南,个人帐户下创建的指南只能用于研究或教学目的。MAGICapp中,可将指南的状态设置为“正在开发”、“内部审查”、“外部审查”、“完成出版”、“更新”和“空白(未设置)”,能够使成员掌握指南完成进度。GRADEPro页面菜单中的团队(TEAM)选项允许管理指南团队成员。可通过姓名和电子邮件将成员添加到指南团队中。任务(TASKS)选项具有基本的日历功能,可以将与指南或团队相关的任务或事件添加到日历,设置任务的截止日期。
2.3.2 利益冲突管理GRADEPro支持利益冲突表单的跟踪和收集。指南管理员能够选择适当的利益冲突表单(如国际医学期刊编辑委员会和世界卫生组织的利益冲突表单),并一键将其发送给团队成员。MAGICapp的此项功能正在开发中。
2.3.3 构建临床问题MAGICapp使用PICO来描述临床问题,在页面中可以使用“添加PICO”按钮添加和编辑PICO的任一部分。有3种方式用来添加PICO:①手动:创建一个PICO,手动填写数据;②使用RevMan文件:从RevMan文件中提取更多信息;③使用下载的PICO文件:可以从组织内部的其他指南下载,也可从共享数据的组织外部指南下载。在MAGICapp中对于每个PICO都可以添加不同术语(ICD-10和MeSH等)的代码,可以使用PICO进行更精确的搜索,并为电子医疗记录提供有关PICO内容的信息。GRADEPro页面菜单中的范围(SCOPE)选项支持临床问题生成。问题生成过程的流程为:①初稿:流程的第一步,再次添加最初的临床问题;②集思广益:团队成员通过电子邮件接收表格,添加和提交他们提出的问题;③完整问题列表:收集了团队成员的问题后,管理员对其审核并能够添加或修改问题;④优先排序:电子邮件表格要求用户优先考虑头脑风暴期间收集的问题;⑤确定最终问题:在此流程中确定最终问题清单;⑥审核问题清单:团队成员审批问题清单;⑦完成:标记为重要的临床问题将自动传输到比较(COMPARISONES)选项中。
2.3.4 证据分级和推荐强度MAGICapp和GRADEPro都使用GRADE方法进行证据分级与推荐强度的制定。在MAGICapp的证据(Evidence)选项中对证据分级,并通过三个颜色选项来区分推荐强度:灰色(未设置)、黄色(弱推荐)和绿色(强推荐)。GRADEpro支持在“证据概要表”中评估证据的等级,推荐意见分为:强推荐使用、强反对使用、考虑使用、考虑反对使用、不明确五种情况。
2.3.5 证据向推荐意见转化MAGICapp在每条建议下都有一个“关键信息”(key information)选项,提供了EtD框架可填写4个关键信息:收益/危害(benefit/harms )、证据质量(quality of evidence)、偏好和价值(preferences and values)以及资源使用(resource use)。GRADEpro开发了8种不同类型的EtD框架以利于证据向推荐意见转化。不同类型EtD框架的大多数标准是相似的,主要从8个方面(问题的优先性、期望的结果、不良反应,对证据体的信心、患者价值偏好、利弊平衡、终端用户的可接受性及推荐的可行性)来总结相关综合信息,以供形成推荐意见时做参考。
3 临床实践指南制定的自动化、智能化工具面临的挑战和未来方向
随着自动化、智能化工具和平台在指南领域的开发和应用,这些工具和平台已成为优化加速指南制订流程,实现其持续更新,拓展其传播方式的重要方法和发展趋势。但在实际应用中仍然存在许多障碍。首先,指南制订要求其方法学具有绝对的准确性,可能是实现完全自动化的一大障碍。这些工具和平台中运用的人工智能技术,例如机器学习算法尤其是那些基于神经网络的算法,可能会做出难以预料的预测。对于这些算法,通常很难检测到错误或偏差,被认为是最终用户的黑匣子[45]。其次,部分自动化、智能化工具和平台的学习曲线曲折,研究者可能需要花费较多时间才能熟练应用。最后,在具有一定“创造性”的流程中(如证据质量评价和证据向推荐意见转化),读者可能对专家深思熟虑的意见更有信心,而不是机器[15]。目前,大多数工具和平台都被设计为人机交互界面,人工审核者拥有最终决定权。也有研究[46]建议使用文献筛选工具节省双重筛选中的一个人力,作为传统双人筛选的替代方案。由于上述原因,目前完全实现指南的自动化、智能化仍是遥不可及。
国际系统评价自动化协作组织(ICASR)致力于最大程度地利用技术来进行快速,准确和高效的系统评价。在2015年,该组织提出了“维也纳原则”,该原则共8条内容,包括:①系统评价的制作涉及许多工作,每项工作存在不同问题,需持续改进;②自动化可协助完成系统评价的所有步骤,从确定选题到发现研究空白,从计划书的撰写到全文的撰写及传播;③每个步骤都可以且应不断改进,以提高应用自动化方法和工具时的效率和准确性;④自动化可以且应高标准地促进系统评价的报告、制作和更新;⑤开发商还应提供友好的界面和组件,如将任务进行细分或合并,允许不同用户使用不同的界面;⑥具有不同专长的工作组在系统评价制作的不同部分发挥作用,需加强小组间的合作;⑦每一项自动化技术都应该共享,最好免费提供代码、评估数据和语料;⑧所有自动化技术和工具都应使用可靠、可复制的方法进行评估,并报告评估结果和数据[47]。指南制订的限速环节主要是系统评价的制作,推动自动化、智能化工具和平台应用于系统评价是当前指南制订最重要和需优先的领域[21]。当前已有案例报告表明使用自动化、智能化工具2周完成系统评价[38],但仍需开展更多的实证研究。
4 小结
目前,指南制订的自动化、智能化工具和平台已有较多的研究和成果应用。但在实际应用中仍然存在许多障碍。在信息化技术高速发展的今天,人工智能与循证医学的结合应用是必然的趋势。随着指南制订、发布和更新过程中越来越多地使用自动化、智能化工具和平台,研究者未来可更高效、便捷地制订指南,对推动循证证据和推荐意见的实时更新及促进科学临床决策有重要意义。
