另类数据征信对信贷公平的影响及展望
2022-12-13庞德良李思卓
庞德良,李思卓
(1.吉林大学东北亚研究中心,吉林 长春 130012;2.吉林大学东北亚学院,吉林 长春 130012)
一、引 言
一个运转良好的金融体系应尽可能为更多的消费者提供储蓄、支付和风险管理产品,并为所有有价值的增长寻找融资和机会。[1]美国的金融业深度和宽度居于全球领先地位。在20世纪20年代,美国进入消费社会初始阶段,丰富的金融产品和服务、健全的法律体系和覆盖全美85%人口的征信体系,为消费社会的发展提供了极大的推动力和保障。然而,在美国金融科技公司ZestFinance于2019年发起的关于“美国人对目前信用评分及体系满意程度”的哈里斯民意调查(Harris Poll)中,很多人认为传统征信体系无法反映真实信誉,年轻人和少数族裔的不满情绪尤其突出。
一方面,在传统征信过程中“无档案”(no-file)和“薄档案”(thin-file)借款人的规模仍然较大,本文将此类容易被传统金融服务排斥的弱势金融群体称为“长尾人群”。2018年美国金融消费者保护局(CFPB)官员表示,美国有2600万人(约占成年人口的11%)是在三大征信机构都不存在信用记录的“无档案”消费者,有1940万人(约占成年人口的8%)是拥有不大于三个交易记录、难以生成信用评分的“薄档案”消费者。“薄档案”消费者可能有信用评分,但如果没有足够的近期交易记录,贷方通常会忽略这些评分。根据Creditcards.com2015年的统计,在15~28岁的美国人中从未拥有过信用卡的人数占36%,信用记录缺失是主要原因之一,他们经常被怀疑具有“高风险”特征。此外,还有数百万人的信用档案存在重大错误。CFPB在2019年接到的投诉中,仅关于“信用报告信息出错”的投诉就占29%。很多实际信用优质的借款人因为信用记录不足或出错,又缺少其他申诉渠道证明信誉,常遭到主流银行的排斥,传统金融服务和产品的可及性不足。另一方面,信贷歧视在传统金融服务业中仍然广泛存在。自20世纪60年代美国的《消费者信贷保护法》颁布至今,涉及个人征信的法律多达几十部。特别是1970年颁布的《公平信用报告法》和1974年颁布的《平等信用机会法》,都强调信用机构档案中所包含的消费者个人信息应具有公平性、准确性和隐私性。但是,据美国联邦金融机构审查委员会(FFIEC)公布的2017年HMDA数据显示,黑人和拉美裔白人申请人的传统购房贷款拒绝率高于非拉美裔白人申请人。此外,还有一些机构诱导少数族裔办理高风险的次级抵押贷款,甚至有很多金融机构在划定贷款评级时,直接将少数族裔聚集地标记为低收入、治安差、贷款风险极高的区域。
P2P网络借贷平台的主要作用之一是弥补传统金融机构的不足,解决被传统金融机构排斥的“长尾”用户借贷需求,促进信贷公平。由于需要面对许多薄档案甚至无档案用户,以及经常被美国传统征信“歧视”的少数族裔,P2P平台引入非传统来源的另类数据(Alternative Data,国内早期译为“替代数据”),通过建立高维度的信用评分模型,以期更有效地预测借款人的信贷风险。
另类数据是指在投资研究中使用的区别于主流来源的新型数据。[2]在征信实践中,美国联邦机构和业内人士通常将另类数据定义为:国家消费者报告机构在计算信用评分时使用的非传统信息。其中,“非传统信息”包括任何美国三大全国性消费者信用报告机构(即Experian、Equifax和TransUnion)传统上在计算信用评分时不使用的信息。目前,无论是美国的传统三大征信机构,还是具备先天技术优势的金融科技公司,都在积极研发另类数据相关征信产品,突破传统数据的选取和使用方式,通过海量的另类数据对平台用户进行画像,最终评估用户的信用情况。至此,信贷领域的个人风险评估方法已经开始分化,传统征信和大数据征信之间出现一定的互补,理论上有利于促进金融普惠,这也是金融科技发展的初衷之一。
另类数据的选取和应用,直接决定最后的信用评分能在多大程度上还原借款人的真实信誉,扩大负责任的信贷规模。虽然由于行业乱象风险频发,P2P网贷平台已经在我国国内全部退出经营,但随着国内征信民间化的发展趋势,P2P网贷平台作为构建新型体系的重要样本,其经验十分值得借鉴。因此,本文将以近年在CB insights发布的全球FinTech 250强上榜的10个美国P2P网贷平台——Upgrade、Upstart、Prosper、Earnest、Sofi、LendUp、LendingClub、Affirm、FuturelFuel、CommonBond 为例,对另类数据在征信应用中的优势进行定性分析。而后根据完全信息静态博弈的结论,提出应对另类数据征信缺陷的办法。
二、另类数据征信对促进信贷公平的优势
目前,国内外关于另类数据的研究非常丰富,主要视角有二:
一是研究非传统信息对个人征信评价的影响,并通过实证进行信息含量分析。研究多将借款人信息分为“软信息”和“硬信息”,主要分析“软信息”对反映借款人的贷款成功率、违约率的参考价值。Iyer等以Prosper数据为例,发现P2P网贷中的贷款人使用软信息预测借款人的违约率时,准确率比传统信用分高45%,在筛选信用评级较低的借款人时软信息作用显著。廖理、吉霖等研究发现,高学历借款者如约还款的概率更高。[3]刘新海和丁伟发现,信贷记录并非总与信用状况相互映射,申请者的其他个人信息和行为信息也会与信用状况产生联系,虽然这种联系可能比较弱。[4]Cong等认为另类数据为金融行业提供了一个新视角,人们通过另类数据可以更好地监控、理解和优化市场中的人类决策。[5]在信息含量研究方面,Berg等的研究表明数字足迹变量能够体现收入、性格和声誉,其信息含量甚至比征信机构给出的分数表现得更好。[6]王正位、周从意等对消费行为在个人信用风险识别中的信息含量进行研究,结果表明消费行为信息能够显著提升对借款人信用风险的识别能力,如果将其纳入征信评估,能够在一定程度上减少信贷市场的信息不对称。[7]另一种研究视角,是探讨另类数据对提高金融普惠的作用。学者和业界是肯定另类数据对扩大负责任的信贷规模的作用,但是也提出其仍然无法从根本上消除信贷歧视。20世纪90年代就有学者提出当缺乏征信分数时,数字足迹有助于信贷的获取,从而提高金融包容度,降低信贷中的不平等。[8]近年来随着具有“普惠”特征的金融科技发展,相关研究再次得到重视。Berg等[6]特别提到数字足迹对新兴市场信贷中不被欢迎客户的帮助作用,这一点在田利辉、李政对“一带一路”发展中国家的研究[9]对小额信贷平台在欠发达地区的研究中得到证实,显示出另类数据应用在缓解金融市场不平等方面的巨大潜力。
在征信实践中,另类数据相对传统的单一金融数据具有以下优势:
(1)另类数据有助于提高数据整体质量。美国P2P网贷平台的另类数据来源,既包括具有金融属性的服务商,也包括非金融属性的机构和平台(如图1)。这有助于从多角度评估借款人的违约风险,并且数据集之间能够互为佐证。例如,在GAO于2019年调查的10家金融科技贷款机构中,部分机构通过从借款人互联网浏览器收集的信息来验证借款人身份,还有机构应用借款人所提供的电子邮件地址与被第三方认定为欺诈的电子邮件地址进行比对。可见,另类数据的应用有助于提高征信评估的准确性,这是仅依靠单一财务数据集不具备的优势。
(2)另类数据有助于丰富人物画像。另类数据集的数据构成丰富,能从多角度对借款人进行画像,增加被传统金融机构排斥的“长尾”人群获取信贷的机会。由于数据获取和处理能力的限制,传统个人信用评分模型由具有强“因果关系”的结构化数据构成(如图2),被称为“强(财务)特征数据”。在数据分析方法上,以统计学方法中的判别分析(Discriminant Analysis)为主(以FICO Score为代表)。随着数据储存成本的下降和数据处理能力的提高,使用数据的逻辑和习惯也发生改变,为金融科技机构进行预测性分析(Predictive Analytics)提供了基础。预测性分析强调的是变量间的相关关系而非明确的因果关系,因此可以通过大量的“弱(财务)特征”的另类数据弥补“信用隐形者”财务信息不足的劣势(如图3)。
(3)另类数据有助于提高分析结果的代表性和稳定性。由于另类数据量相对金融数据更庞大,有助于提升数据分析结果的代表性和稳定性。数据的“代表性”指数据代表全部的消费者,还是仅代表其中一个子集。数据量是否足够庞大且丰富决定着数据集的代表性程度,最终影响数据整体质量和作用。在数据数量上,P2P网络平台数据项个数能达到几千个,变量个数多达上万个,数据量十分丰富;在数据格式上,兼具结构化数据和非结构化数据;在数据性质上,既包括财务性数据又涵盖各类行为数据。因此,另类数据集比传统财务数据集更丰富,更能全面展现借款人的特征。数据的“稳定性”(data stability),在统计学上是用于测量数据波动性与离散性的指标。从时间角度纵向观察,另类数据具有动态特征,P2P平台的征信分析模型可以根据最新数据进行动态调整。与传统征信评分使用的数据相比,另类数据能更有效地反映借款人近期的生活状态以预测未来风险。综上,另类数据在征信中的使用更有助于预测金融消费者近期的真实个人信用。
三、另类数据征信引发的新型歧视使信贷歧视更加隐秘
大数据的核心是对数据价值的充分挖掘和利用,而机器学习是利用数据价值的关键技术。金融科技的出现及其对另类数据的应用,使弱势金融消费者的借贷需求得到一定程度的满足。但与此同时,基于机器学习的另类数据征信也引发多种新的歧视现象,如数字歧视和算法歧视。这类新型歧视使信贷歧视更加隐秘,导致信贷公平难以实现。
(1)数字歧视。数字歧视是数字经济时代的特有现象,指用户由于一些原因不使用或不接触数字化产品,导致其被排除在更广泛的数字生活模式之外,逐渐在很多方面与主流人群脱离,这些用户被称为“数字弱势群体”。目前,美国年轻人出于对个人隐私的保护,已经表现出对社交网络的抵触情绪。Pew Research Center2018年的调查显示(如图4),美国50岁以上的用户对Facebook需求较高,并且可能会留下更多公开的个人信息,而在18~29岁的Facebook用户中,47%的用户在几周或更长的时间里没有登录账号,44%的用户表示已删除Facebook应用程序,64%的用户在过去一年中对隐私设置进行调整。这种选择使许多人客观上成为数字弱势群体,特别是在基于机器学习的另类数据征信方面。例如,LendUp通过申请者的Facebook和Twitter透露出的社会关系紧密程度判断其信誉的好坏,这样的数据选择可能将排斥社交网络中不活跃、很少留下或习惯删除数字足迹的借款人。机器学习预测的准确性取决于训练的数据是否全面、准确。征信实践中,P2P平台无法保证其用于机器学习的另类数据样本足够多样。由于缺乏数字信息、被歧视等原因,从最开始就被拒绝的潜在优质借款人样本永远都不会被观察到。机器学习样本不足将导致模型泛化能力比较低,会产生两种结果:一是机器无法预测其风险,借款人的贷款申请被拒绝;二是借款人被错误地分类到其他特征人群,最终预测结果产生偏差,例如一些照片识别软件会因为没有包含足够多样的数据,错误地分辨非洲裔美国人和亚裔美国人的照片。无论哪种预测结果,被歧视人群都可能无法得到与自己相匹配的产品和服务,失去获得公平信贷的机会。
(2)算法歧视。算法歧视指在大数据技术下,当机器学习对数据做出分析决策时,由于数据和算法本身隐含错误、不具备中立性或被人为操控等原因,造成对数据主体的差别对待并形成歧视后果。
数据混乱造成的数据失真会导致机器学习产生偏差。在声誉经济里,声誉评分或许会因为一次点击而受到多方面的影响。申请人的账号被盗、将电脑借予他人操作或者有意制造与“好信誉”有关的虚假数据,这些行为都将造成数据无法反映借款人真实情况。虽然在机器学习中,少量存在问题的弱特征另类数据并不会对结果产生极大误差,人们对数据错误的宽容度因为样本量的扩大和对算法的信任得到很大提高。但随着虚假数据的增多,数据分析师不再有能力判断数据质量。机器使用错误的数据进行学习和分析,终将导致“无用输入、无用输出”的结果。此外,从数据更新速度来看,模型中对诸如社交网络数据等高频变化数据的大量应用,是否会随着申请者在线行为变化对数据的稳定性造成影响,以及这种影响程度有多大,类似问题也需在未来的实践中进一步论证。
不具备中立性和人为操控下的另类数据征信,使信贷歧视更加隐秘。在数据获取方式上,数字足迹等非结构数据主要通过爬虫自动获取,不仅可以避免人力输入错误,提高数据实效性,还能避免传统金融机构中由于信贷员自由裁量权过大,根据主观判断轻易变更条款,使具有少数族裔等特征的弱势金融消费者受到不公平的待遇。同时,另类数据集的厚度和维度都大幅度增加,理论上也有助于还原借款者的真实信誉。但“另类数据”使“歧视数据”和“行为数据”的边界更加模糊,歧视因素变得更加隐秘。加之人们对“相关关系”的宽容度增加,对数据之间潜在联系的理解又十分有限,导致难以察觉到看似不关联的数据集成分析时显示出的歧视特征。因此,机器学习技术背景下的另类数据征信,使信贷歧视更加隐秘。
另类数据征信只是从仅专注财务数据扩展为关注个人的整体素质,而技术上的突破仍未改变另类数据征信与传统征信类似的“参照系”评分逻辑。既往研究发现,不同阶级间的数字足迹存在差异并且会对个人发展造成不同影响,因此另类数据的过度应用可能进一步拉开阶级差距。传统征信中存在的地域歧视、身份歧视通过技术处理被更隐秘地带入算法,固有的“地理歧视”和社交网络中“朋友圈”信息引发的种族、宗教歧视等甚至助长了信贷歧视。虽然,实践中的确存在“战略性违约”的情况,但因为借款人处于贫困人口较多的地区或社交关系中存在较多的少数族裔等特殊群体,就判定其同样具有高违约风险,最终仍未改变信贷歧视的现状。与法理学中的法官中立基本要求类似,各国的法律中都明确指出不能存在歧视性质的数据,也是为了避免由于不客观的参照导致不公平的“预判”。但实际上歧视仍然存在,例如Pope和Sydnor(2011)在Prosper的案例中找到明显基于种族差异的证据,还发现借贷市场对老年人和超重人士也存在一定程度的歧视。2020年2月,学生借款人保护中心(Student Borrower Protection Center)的一份报告称,在5年期贷款中著名黑人大学Howard University的学生要比Yale大学的学生多支付3499美元,多名参议员致函Upstart Network和其他贷款机构,认为学生信贷过程中使用的教育数据可能涉及教育歧视。
新技术的使用初衷是让贷款机构的决策更趋于理性,而在进行信用评估前就将歧视因素纳入其中,机器学习则会因为人类的认知偏差而变得更具主观色彩,这种主观歧视是增加数据厚度和维度都无法消除的。一些P2P平台还在机器学习中公开或隐秘地设置以传统信用分数为标准的申请门槛。在表1中,虽然P2P平台要求申请者达到的传统信用分数并不高,但是这一限制却再次将缺少传统信用评分的申请者排除在外。同时,根据LendingClub官网提供的借款人特征,截止到2016年3月,借款人的平均FICO分数达到近700分,且拥有16.4年的信用记录历史。也就是说,很多能在LendingClub成功申请借款的用户也能在传统金融机构获得借贷服务。可见,P2P平台使用另类数据的主要目的是发现更有信誉、更优质的消费者,降低不良贷款率,而非耗费大量人力物力重点挖掘弱势金融消费者中的优质借款人。
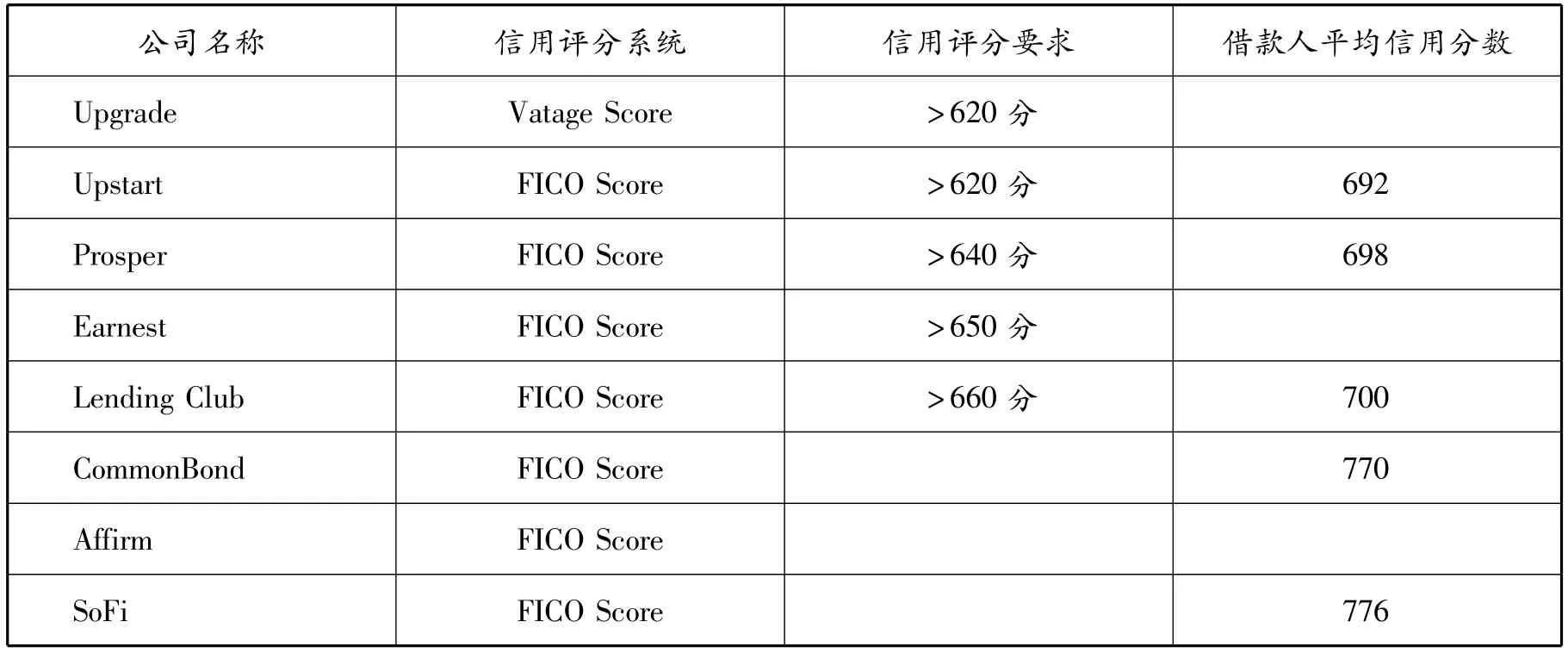
表1 美国P2P借贷平台的传统信用评分要求
借款人透露更多个人信息的初衷是证明好信誉以获得贷款,而P2P平台使用另类数据的目的源于两个方面:一是为更好地风险控制,识别欺诈;二是为精准营销,牟取更大利益。P2P网贷平台具有“公共使命”下的盈利动机,增强金融普惠,负责任地扩大信贷规模是一种溢出效应。这也是目前国内外出现算法歧视的“杀熟”行为的主要原因。大数据杀熟是经济学完全价格歧视行为的表象,体现的是新制度经济学中买卖双方对信息产权的诉求。[10]与传统商业银行的“交叉销售”(Cross Selling)推广手段相似,P2P平台也使用另类数据施行“差别对待”策略。这种歧视性的针对行为将加剧信贷不公平,而潜在借款人甚至不知道自己已经被差别对待。综上,在传统信用分门槛限制和差别营销的作用下,另类数据的使用实际上提高了特定人群(特别是传统征信体系中的优质客户)获取信贷产品和服务的能力,进而挤压处于劣势的金融消费群体获得合适且更高质量信贷服务的空间,增加潜在的不公平。在这一点上,另类数据对扩大信贷规模的作用十分有限。
四、另类数据征信的效果分析
根据上文分析,另类数据在征信领域的应用仍然存在诸多弊端,甚至可能使长期被传统金融机构排斥的金融消费者处于更加弱势的地位。鉴于此,本文将构建金融消费者和网贷平台的完全信息静态博弈模型,通过梳理使用另类数据进行征信过程中弱势金融消费者和网贷平台可能产生的不同策略选择,分析另类数据在征信领域的应用是否有助于促进信贷公平。
(1)参与主体。参与主体为金融消费者和网贷平台。金融消费者特指由于信用记录缺失或出错、种族歧视等原因,被传统金融机构不公平排斥的弱势金融消费者。网贷平台指具备另类数据进行征信的相关技术,提供网络贷款业务的平台。由于实践中,金融监管机构对另类数据征信仍处于观察期,监管缺失仅仅引发网贷平台在信用评估中是否进行信贷歧视的动机,但不会对金融消费者和网贷平台造成直接影响,因此不予考虑。
(2)策略集合。博弈双方具有追求自身利益最大化的倾向。金融消费者的目标是以尽可能低的成本得到金融服务;网贷平台的目标是降低违约风险,扩大盈利率,保持平台的健康稳定发展。双方在博弈中都有两种策略选择——金融消费者既可以选择主动配合提供关于自己的另类数据(即“提供信息”),也可以尝试保护自己的数据,尽量不提供给网贷平台(即“不提供信息”),此时将导致网贷平台掌握数据不足;网贷平台在金融监管缺失、法律定位不明的情况下,既可以为了追求短期利益利用技术优势在对金融消费者的信贷评估中设置信贷歧视(即“歧视”),也可以选择出于为自身健康发展等长远考虑不设置信贷歧视(即“不歧视”)。表2即博弈双方的策略组合:

表2 博弈双方的策略组合矩阵
(3)参数设置及模型。以美国网贷平台对另类数据的应用现状为基础,将对博弈双方产生重要影响的相关要素纳入模型。
在金融消费者方面:如果金融消费者不提供信息,网贷平台将依据传统征信评分情况进行授信决策,此时无论网贷平台是否设置歧视,另类数据都不会使金融消费者的信贷结果产生变化,即金融消费者被拒绝信贷,额外收益为0。如果金融消费者提供信息且网贷平台不存在信贷歧视,则可能产生两种结果——另类数据有助于获得信贷,则额外收益为C1(C1>0),或者是另类数据反而对信贷评分产生负面影响,导致借贷失败,则额外收益为C1(C1=0)。如果金融消费者提供数据,而网贷平台存在信贷歧视,则金融消费者不仅难以获得信贷,还需额外付出数据泄露或受到交叉销售等差别对待的风险S(S>0)。
在网贷平台方面:如果金融消费者不提供信息,网贷平台选择“歧视”,则由于信息不足拒绝信贷,网贷平台的额外收益为0;如果金融消费者不提供信息,网贷平台选择“不歧视”,平台额外收益也为0。如果金融消费者提供信息真实,网贷平台选择“歧视”,不予授信,则网贷平台获得另类数据带来的额外收益R和交叉销售等其他歧视策略带来的额外收益I;如果金融消费者提供的信息虚假,导致网贷平台误判最终授信,则网贷平台需承担额外风险W(W可能大于R+I),此时网络平台总收益为R+I-W。如果消费者提供信息真实,网贷平台“不歧视”,则网贷平台获得另类数据带来的额外收益R;如果消费者提供信息虚假,网贷平台“不歧视”,则承担额外风险W(W>0)。
(4)分析结果。由博弈双方的收益矩阵表3可见,金融消费者在没有遭到信贷歧视时,选择提供信息是最优策略。虽然金融消费者提供信息可能存在歧视带来的风险损失,但是现实生活中另类数据造成的信贷歧视多为隐形,消费者无法评估提供信息的损失,因此为了获得服务一定会选择牺牲个人信息,获得收益C1。从网贷平台角度看,歧视具有额外收益I,是绝对上策。由此可见,金融消费者深知失去一些隐私是参与和享受信息密集型经济带来好处的代价,因此希望利用更多另类数据评估个人信誉,但在监管缺失的情况下,这样做不仅不会换来公平的金融服务,反而会助长信贷歧视现象。

表3 博弈双方的收益矩阵
五、另类数据征信的发展及建议
本文通过对美国P2P网络借贷平台的另类数据应用进行梳理,发现另类数据征信可以增加数据的维度和厚度,使个人信誉得到更全面的体现,能够在一定程度上帮助缺少信用记录和长期受到歧视的少数族裔等人群争取更多享受金融服务的机会。然而,金融科技平台在利用另类数据征信、促进金融普惠的同时,也隐含着“大数据杀熟”的情况,而且机器学习下的另类数据征信使基于数字歧视和算法歧视的信贷歧视类型更加隐秘。
根据弱势金融消费者与网贷平台的完全信息静态博弈分析可以发现,监管的不确定性会限制福利的溢出。政府的正确引导和监管部门的积极举措是另类数据征信能否真正扩大金融普惠的重要因素之一。美国P2P网络借贷发展是成熟市场下的业界典范。虽然,美国监管机构很早就开始关注使用另类数据是否侵犯消费者的公平信贷权等问题,但目前无论是美国联邦银行监管机构,还是消费者金融保护局(CFPB)仍然未针对另类数据的适当使用以及如何监管第三方使用另类数据和相关风险等问题发布具体的指导。监管机构认为,另类数据或将为看不到信用记录或缺乏足够记录的消费者更容易获得信贷服务提供契机,应该为其提供足够的发展空间。因此,在监管不确定的情况下,CFPB仅采取向使用另类数据的公司发出“不行动信函”(no-action letter)的办法,推动有利消费者的金融创新。CFPB也将在金融科技机构定期提供的报告中进一步观察另类数据的使用如何帮助金融消费者,以及这些新做法是否合规。然而,从金融科技借贷机构的角度,监管的不确定性反而成为另类数据助力金融服务可及性的阻碍。在美国问责局(GAO)2019年的调查中,部分金融科技贷款机构指出缺乏明确指引将成为金融创新和潜在信贷扩张的障碍。虽然很多金融科技机构已经积极通过各类测试考察其对另类数据的使用是否带来潜在歧视,以及是否违反《平等信贷机会法》等相关法律,但缺少官方指导,机构内部测试结果的参考价值有限,另类数据不规范使用可能产生的问题仍然会存续,对促进信贷公平的溢出效应有限。综上可见,由于另类数据在征信中的应用并不成熟,加之缺乏监管细则使金融科技公司对另类数据应用始终持谨慎的态度,传统信用评分和大数据征信综合应用,甚至传统财务数据为主另类数据为辅的局面将长期存在。这些都将缩减金融科技贷款机构对金融普惠的溢出效应。
在数字经济时代,通过机器学习等先进技术的深入使用仍然是金融业的发展方向之一。一方面,金融科技机构要审慎使用新兴技术,注意可能存在的风险。另一方面,通过政府的正确引导和监管的积极举措,另类数据征信仍然有机会更好地惠及“长尾”人群,促进信贷公平。机器学习是另类数据征信的工具,核心仍然是数据。在数字经济时代,会产生大量涉及个人敏感、核心的个人信息,且未进行完整的脱敏化(Data Masking)处理,导致个人信息权和隐私权受到侵害。[11]缺乏对个人信息权及隐私权的保护,是个人信息被“杀熟”,遭遇信贷歧视的源头。因此,监管部门应尽快出台数据保护相关指引和细则,颁布必要的法律法规,规范金融科技企业及第三方数据提供机构的业务。加强数据共享链条中对个人信息的全链条保护,保证用户对个人数据的控制能力。同时,作为维护金融行业有序发展的金融监管部门,亟须加强对金融科技企业的业务规范,尽早提供相关指引。金融科技机构不仅要严格遵守相关法律,更要提防数据集成后可能存在的隐性歧视。只有这样,才能有效保护金融消费者权益,扩大信贷公平,使金融科技机构合规经营,促进整个金融科技行业的有序发展。
