基于声音采集与分类技术的报警系统设计
2022-12-03沈丹丹朱习松
徐 婕,沈丹丹,潘 硕,朱习松
(中科芯集成电路有限公司,江苏无锡 214072)
1 引言
在现代环境质量评价体系中,环境噪声指标日益受到重视,成为评价一个场所舒适度的重要标准,准确检测、记录环境声音具有重要的现实意义[1]。在完成声音能量检测的同时,确定主要声音类别,一方面可以指导工作人员确定主要工作方向,尽量杜绝此类声源以提升环境质量;另一方面通过捕捉例如尖叫声、哭喊声等异常声音[2],给出报警信息,配合视频监控,有利于安保人员第一时间判断危险源并进行应急处理,可以弥补视频监控的不足[3]。
本文论述了一种声音报警系统,以模数转换、控制、传输电路搭建硬件平台,以声音的端点检测、特征参数提取和分类技术为算法核心,实现对环境声音大小的实时检测及声音分类、异常报警等功能。
2 系统架构
报警系统的硬件部分主要选用国内外成熟的元器件和设备,包括麦克风(MIC)装置、运算放大器(AMP)、模数转换电路(ADC)、电平转换、FPGA、以太网PHY RJ45 芯片、电源、时钟系统、配有识别算法及报警显示的主控计算机,系统结构硬件如图1 所示。

图1 系统硬件结构
远端采集部分器件的功能及选用原则如下:
1)MIC 装置实现声音电信号的转换,需要具有拾音准、干扰小、采集范围大的特点,此处选用高性能拾音器;2)AMP 有调整模拟信号的作用,可根据后级器件调整信号幅度,其高输出电阻特性可有效避免信号失配,考虑后级转换器件的差分特性,选择全差分AMP XX6362,其具有全差分、低失调、噪声小、轨到轨传输的特点,能够满足系统要求;3)ADC 是声音采集的核心器件,它将模拟信号转换为数字语音,因声音变化量丰富,选用16 位高精度专用语音电路XX73311;4)电平转换器件可适配不同电压的总线互联,选用XX0108,其具有电压范围宽、工作速率快、自适应方向的特点,可应用于推挽或开漏的不同总线信号传输;5)远端控制器主要完成模数转换器的配置、数据读取,按照以太网UDP 协议打包发送数据,FPGA可以胜任此项工作,且设计简单,考虑成本及体积因素,选用XX25-363[4];6)计算机数据传输选用以太网,其速率快且上位机设计方便,经实际计算,选用百兆以太网PHY 电路XX83848,其性能稳定、使用简单,协议部分由FPGA 完成;7)系统中的电源采用多路DC-DC,模拟电源单独加低噪声的LDO,时钟以晶振直接提供,FPGA 的配置电路使用专用的PROM,型号为XX32P。
3 采集终端实现
3.1 硬件构成
考虑到系统链路较为复杂,本研究主要论述系统的声音采集部分,XX73311 是一款功能强大的语音芯片,其内部包括1 路16 位Σ-Δ 型ADC、1 路16 位DAC、输入输出增益模块、基准等结构,支持3.3 V 或5 V 2 种电源电压。采用SPI 接口传输配置及数据信息,输入可选交直流耦合模式,最终输入端口信号需满足电压要求。考虑5 V 供电的共模电压对AMP 的适配性更好,XX73311 及XX6362 均采用5 V 供电。XX6362 承接前端拾音器单端信号,差分输出给XX73311,XX73311 的数字接口电压跟随电源电压,因FPGA 端口电压为3.3 V,使用XX0108 适配两端器件的接口电压,时钟选用16.384 MHz 典型频率,采集终端硬件电路如图2 所示。

图2 采集终端硬件电路
3.2 XX73311 的配置
XX73311 时钟采用多级分频,其中外部主时钟MCLK 分频后,DMCLK 作为内部系统主时钟,DMCLK 再次分频后作为SPI 的时钟SCLK,DMCLK/256 作为编码时钟。XX73311 的SPI 总线主要是主控型,SCLK 由其发出,每个信息须有FS 脉冲信号引领才能识别,并允许最多8 个器件级连,使用时需严格按照时序图的设计。在总线中,XX73311 的读写使能位、地址位为1 个字节,每个数据位或寄存器为1 个字节,其内部共有5 个功能寄存器。系统配置信息如表1 所示,寄存器用CR 表示,CR-E 默认为初始值。

表1 XX73311 配置表
一般应优先配置寄存器B/C/D/E,然后配置寄存器A,使器件从编程模式转为数据收发模式。XX73311可提供灵活的调试帮助,在编程模式中使能模拟回环(ALB)、数字回环(DLB)2 个回环模式,可轻松检查模拟端或数字段的信号链路功能。
4 声音分类的实现
4.1 工作流程
本系统算法部分以计算机为平台,基于MATLAB完成,使用基于MATLAB GUI 的可视化设计,既可以连续、实时地显示声音信号,还可以对异常信息报警[5]。系统工作流程如图3 所示。
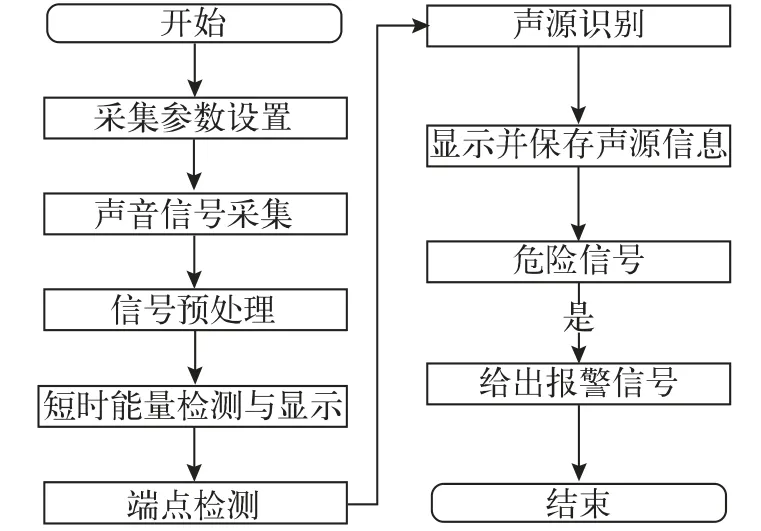
图3 系统工作流程
在研究阶段选用部分公共场所常见声音作为验证样本,有汽车鸣笛声、人的说话声、尖叫声、哭声、雷声、狗叫声、物体撞击声和爆炸声等。根据声音代表的信息,将其分为危险声源和一般声源。尖叫声和哭声有可能表示有人受到侵害,爆炸声则表示有人违反公共场所管理规定燃放烟花、爆竹等,将其列为危险声源,其余声音为一般声源[6]。
4.2 声音处理
获得声音信号以后,为使信号的频谱变得平坦,提高信号的高频部分,保持在低频到高频的整个频段中,能用同样的信噪比求频谱,系统需对声音信号进行预加重处理。预加重有多重形式,本设计选用数字滤波器实现,对n 时刻的采样值x(n)预加重,得值y(n)为:
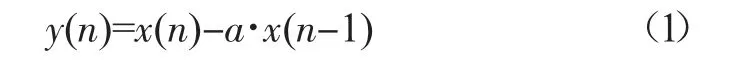
式中a 是预加重系数。
根据声音信号的短时平稳性特点,系统对声音信号进行分帧处理。为使特征参数平滑变化,在分帧过程中,系统采用部分重叠的办法实现过渡,使声音特征平滑过渡,保持其连续性。声音分帧的效果如图4所示。

图4 音频分帧
对声音信号x(n)的处理中进行分帧。

式(2)采用卷积形式,相当于通过一个单位冲激响应为ω(m)的FIR 滤波器。
4.3 声音能量检测
短时能量高是异常声音最突出的表现,实时计算声音能量既可监测声音强度,又可划定异常声音范围。采用双门限法可提取异常声音段[7]。以一段0.3 s 的声音信号为例,其声音波形和对应的短时能量波形如图5 所示。
图5 中TH 为设定的高门限,TL 为设定的低门限,首先对声音信号进行逐帧判断,当某帧能量幅值高于TH 时,往两边寻找声音边界TL,当某帧能量幅值小于TL 时,即认为声音结束。

图5 门限值与能量波形对比
4.4 MFCC 特征参数提取
在得到声音段的起始帧以后,系统需要提取异常声音段的特征参数,常用的特征参数有线性预测倒谱系数(LPCC)和Mel 频率倒谱系数(MFCC),鉴于MFCC 在信噪比降低时的良好识别性能,同时较好地利用听觉模型的研究成果,本研究选用MFCC[8]。MFCC 是在Mel 标度频率域提取出来的倒谱系数,其特征参数提取原理如图6 所示。

图6 MFCC 特征参数提取原理
对声音样本取帧长256、帧移128 进行预处理、端点检测、提取MFCC,对样本的参数按声音类别合成匹配文件模板库,由8 类模板库组成总模板库。部分声音的MFCC 特征参数三维图像如图7 所示,从图7 中可以很直观地观察到信号的MFCC 随Mel 阶数的变化情况,不同声音类别之间区别明显。
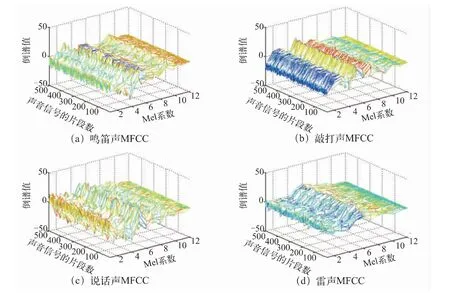
图7 MFCC 特征参数三维对比图
4.5 BP 神经网络分类
声音识别属于模式识别的应用范畴[9],在声音识别的发展过程中,有动态弯折算法[10]、隐马尔可夫模型[11]、高斯混合模型[12]、神经网络[13]、支持向量机[14]等多种算法,本研究只需要识别出声音的几种类别,应用相对简单,因此选用算法成熟、工具箱函数丰富的BP 神经网络算法。
以MFCC 模板库作为BP 神经网络的训练样本,对数据进行归一化处理。BP 算法建模包括BP 神经网络的构建、BP 神经网络的训练和BP 神经网络分类3步。首先是BP 神经网络的初始化,模型拓扑结构包括输入层、隐含层和输出层,本研究采用12 阶的MFCC,所以BP 神经网络输入层的神经元个数是12,网络输出神经元取4 个,目标输出一个4 位二进制数,足以表示8 类样本,隐含层设置为15 个神经元。取学习率0.1,训练误差0.01,训练次数2000 次,2 次显示之间的训练步长为10,隐含层神经元的传递函数采用S 型正切函数,由于输出模式为0-1,输出层神经元的传递函数采用S 型对数正切函数f(x),

式中β 为常数,用于控制曲线扭曲部分的斜率。
在网络训练阶段根据预测误差调整网络的权值和阈值。定向对比录制的样本同类声源,输入上述训练好的神经网络,得到帧特征平均分类成功率,BP 神经网络识别结果如表2 所示。

表2 BP 神经网络识别结果
表2 是逐一输入单一声音源的识别结果,若要排除其他声音尤其是混合声音需要大量的声音样本做训练,有可能还需要提取更多特征参数以提高识别精度[15],并且随着复杂度的增加,识别效果会降低。本试验主要验证系统的可行性,因此只是在音源位置等固定的情况下识别声音信号。
通过实测,系统能够检测出异常声音段并判断是否为危险信号,如是危险信号则给出报警信息。接到报警信息,值班人员可查看历史记录,重听保存的报警信息,通过录像或赴现场勘查异常并予以解决。
5 结论
本研究通过对声音信号进行预处理、计算帧短时能量,给出环境实时声音幅度参数,作为环境声音的第一级监测;然后通过端点检测技术区分出有别于常规环境噪声的有声段,提取有声段MFCC 参数,用BP神经网络对参数分类,对代表危险信息的声音给出报警信息,作为环境声音的第二级监测。
今后的研究重点一是考虑远端直接识别,直接给出判断信息,减小远距离数据传输量,为此考虑使用高性能DSP;二是提高复杂环境下的识别率,考虑从声音的基音、共振峰、谱熵等多方面进行分析,构建包含多种特征信息的混合参数作为分类计算的依据,将近年来模式识别学科的发展成果运用到声音识别中,以期获得更好的效果。
