基于关系网络的孪生单目标视觉跟踪
2022-12-01李震鑫张选德
李震鑫, 张选德
(陕西科技大学 电子信息与人工智能学院, 陕西 西安 710021)
0 引言
视觉目标跟踪作为计算机视觉领域的基本问题之一,在视频监控[1,2]、智能交通[3]、医疗诊断[4]、战场监控[5]等诸多实际场景中都有着广泛应用.该问题可阐述为:在视频帧或图像序列第一帧中,给定任意感兴趣目标的中心位置以及目标边界框的大小,在后续视频帧或图像序列中对目标的位置和大小进行估计,为其它视觉任务提供可用信息.
单目标视觉跟踪的算法可以根据外观模型的统计策略进行分类,包括生成式模型和判别式模型.简单而言,生成式模型是通过学习先验分布来推导后验分布而进行分类;判别式模型是直接学习后验分布来进行分类.具体而言,生成式模型首先学习一个表示目标的模型,然后在图像的搜索区域优化样本误差,即找到与模型最匹配的区域.判别式模型则是对目标与周围背景分别建模,将跟踪问题转换为回归或二元分类问题,目标作为正样本,背景作为负样本,寻找一个判别函数将目标从背景中提取出来,以达到跟踪的目的.
传统的目标跟踪算法由于不能充分地利用数据来建模渐渐被基于深度学习的目标跟踪算法所取代.虽然基于深度学习的单目标跟踪算法取得了一些效果,但它们无法兼顾速度的实时性和精度的鲁棒性.孪生网络[6]的出现打破了这一瓶颈,现如今的基于孪生网络的单目标视觉跟踪算法在保证实时的条件下,跟踪性能已经超过了之前的跟踪器.
视觉目标跟踪是用来解决视频中特定目标的定位问题,每个跟踪视频都可以看作相互独立的不同任务,视频数据的第一帧为各个视频跟踪任务的唯一训练样本,故视觉目标跟踪可看作小样本的学习任务,因此可用元学习的相关方法来解决.近些年来,基于元学习的目标跟踪算法备受关注.
在基于孪生网络的单目标跟踪算法中,相关性计算是解决其分类问题的关键步骤,但现有算法均采用固定的距离来度量相关性,比如欧式距离或者余弦距离等[7].这些度量指标严重依赖于学习到的特征空间,对于目标跟踪算法中目标和背景的分类有一定的局限性.在元学习领域,关系网络[8]不仅可以学习深度特征的特征映射,而且可以学习特征间的非线性度量,称其为相似性函数.相比之下,关系网络学习得到的非线性相似性度量可以更好地进行分类.
基于以上考虑,本文提出一种基于关系网络的孪生单目标视觉跟踪网络.关系网络的引入可以改善跟踪器对于目标和背景的分类性能,从而提高单目标跟踪的准确率.在OTB2015[9](Object tracking benchmark)、VOT2018[10](Visual Object Tracking)两个基准数据集上的实验表明,提出的算法与目前几个代表性算法相比,具有一定的竞争力.
1 基于孪生网络的目标跟踪算法
基于深度学习的目标跟踪算法在精度上取得了较好的成绩,但由于深度网络参数过多会导致计算效率下降,实时性会受到不同程度的影响.为了便于实时跟踪,Bertinetto等[11]采用全卷积的孪生网络进行目标和搜索区域的模板匹配.此后,基于孪生网络的跟踪算法因其高效和鲁棒性能,国内外研究者们不断地在此基础上创新与拓展,取得了较大地进步,Valmadre等[12]提出一种非对称的Siamese网络的跟踪算法,引入相关滤波方法在网络层的末端创建一个可微的卷积神经网络层.He等[13]提出了一种双 Siamese网络的实时目标跟踪方法.Wang等[14]在孪生网络跟踪框架中引入不同的注意机制来适应网络模型,实现了鲁棒的视觉跟踪.Li等[15]提出了基于Siamese和区域候选网络(Siamese region proposal network,Siamese-RPN)的目标跟踪方法.Fan等[16]在孪生网络框架中引入级联的区域候选网络.
与此同时,Bhat等[17]为了提高目标状态估计精度,提出了一种新的跟踪算法ATOM(Accurate Tracking of Overlap Maximization),该体系结构由两部分构成,一部分是目标估计子网络,另一部分是分类子网络,其中目标估计网络通过预测目标对象和估计的边界框之间的重叠比来训练,该方法提高了单目标跟踪算法中估计目标边界框的精度.继而,Danelljan等[18]为了实现目标跟踪网络的端到端训练并且可以在线更新,受到判别学习损失的启发,提出了一个可以同时利用目标的外观信息和背景信息来预测目标的模型DiMP(Learning Discriminative Model Prediction for Tracking),大幅地提升了目标跟踪的精度.
2 基于元学习的目标跟踪算法
从一个或者几个实例中学习知识的能力是人类智能的基本特点,例如,一个第一次见过狗的人,在之后也能从不同动物中快速辨认出狗,而机器却需要大量数据进行训练才能区分出不同类别的动物.相比较而言,元学习的出现正是让机器仅仅给定少量样本的情况下,具备这种有效学习的能力.
目前,元学习领域和视觉目标跟踪虽然没有产生十分广泛的交集和联系,但是已经存在相关研究者尝试将元学习的相关方法引入到视觉目标跟踪领域来,并且取得了一定的效果.
Park E等[19]首次将元学习引入视觉跟踪领域,通过MAML[20](Model-agnostic Meta-Learning)元学习的方式,将复杂的多域简化为单域,训练一个更为鲁棒的特征初始化提取器,改进了MDNet[21](Learning Multi-Doamin Network for Visual Tracking)的跟踪结果.Wang等[22]将跟踪看作一个特殊的检测问题,并利用元学习在跟踪序列上训练检测器FCOS(Fully Convolutional One-Stage Object Detection)和RetinaNet,使得检测器从单帧中仅需几步梯度下降便可对目标进行较好的定位,从而极大地提升了跟踪的实时性.
3 基于关系网络的孪生单目标跟踪
对于单目标跟踪,相似度匹配是提高目标和背景分类精度的关键.元学习中,基于度量学习的方法旨在最大程度地提取任务样本内含的特征,以便使用特征比对的方式来进行样本分类,这种方法为相似度匹配提供了很好的解决方案,如何提取最能代表样本特点的特征是该方法的研究重点.
孪生网络作为早期工作的代表之一,是通过相同的网络结构分别对两张图片提取特征,使得提取的特征具有很好的判别性.匹配网络[23]对于支撑集和查询集的图片经过特征提取后,在特征空间利用余弦距离来度量特征相似性,对测试样本通过相似度匹配程度进行分类.原型网络[24]主要利用聚类思想,将标注样本的特征投影到一个度量空间,在欧式距离基础上获取向量均值,基于测试样本到每个原型的距离进行分类.
由于图像包含十分丰富的信息,在特征空间内利用经典的欧式距离或余弦距离难以准确度量样本间的相关性.为了缓解这一问题,关系网络提出了单独的非线性比较模块,该模块学习得到一种非线性相似性度量,替换了匹配网络和原型网络中的余弦距离和欧式距离度量.学习得到的度量是依赖于样本的,相比“固定”的经典距离能更好地描述样本间的相似性.为了充分利用关系网络的这种优势,本文以孪生网络为出发点,基于关系网络构建单目标跟踪模型.该模型利用关系网络学习深度嵌入函数和深度非线性距离度量函数,且对二者联合训练.
模型主要包括以下四个方面:(1)基于关系网络的特征提取模块,主要负责样本的特征提取和非线性度量函数的学习;(2)分类分支和回归分支,分类分支负责从包含目标的背景中区分出目标,回归分支负责目标边界框的准确回归;(3)离线训练过程,通过离线训练确定网络结构的参数和优化;(4)在线跟踪过程,利用在线跟踪对网络结构进行微调,提高泛化能力.具体在下列各节展开.
3.1 基于关系网络的特征提取模块
这里关系网络将作为整个目标跟踪网络的特征提取模块,该部分主要由两种模块组成:嵌入模块fθ和关系模块gφ,所提出的整个基于关系网络的孪生单目标跟踪网络框架如图1所示.
在图1中,关系网络使用4个嵌入模块,每个模块与一个关系模块匹配,具体而言,每个模块都是由多个SENet(Squeeze and Excitation Network)块构成,SENet具体细节如图2所示.
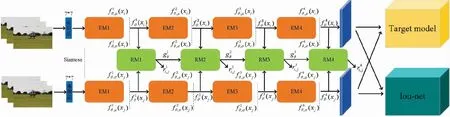
图1 基于关系网络的孪生单目标跟踪网络框架图
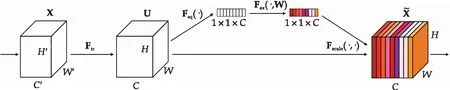
图2 SENet模块

如图1所示,将来自支撑集和查询集中的一对图像xi和xj作为输入,首先使用一个7*7卷积,经过一个3*3的最大池化层,再传入4个嵌入模块,然后,多级嵌入模块将随机特征输出到相应的多级关系模块,并学习多级关系模块的关系分数和权重;最后,整个关系网络学习目标跟踪中分类问题的加权非线性度量.

(1)
式(1)中:ε是从高斯分布中随机采样得到的,这样使得每个模块每次重构时得到的特征图都带有随机性,这就能够起到数据增强的效果;⊙表示元素的乘积.
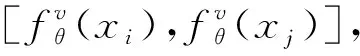
(2)

(3)
3.2 回归分支和分类分支
对于所提出的基于关系网络的孪生目标跟踪算法,经过上述的特征提取模块之后,分别进入目标跟踪算法的分类分支和回归分支,对于分类分支,本文遵循DiMP算法中所提出的目标模型预测模块来预测最终用来分类的模型,为了解决原来只利用目标所在区域的模板分支进行训练带来的问题,使用支持向量机中的hinge-like损失函数,利用背景信息使得目标和背景分类结果更好.
对于回归分支,本文利用ATOM中介绍的重叠最大化策略来实现精确的目标边界框回归.首先给定一个目标外观特征的参考值,训练边界框估计分支用来预测目标和在测试图像上产生的一组候选框之间的交并重叠比.通过从目标的外观特征计算调制向量,将目标信息集成到IoU(Inter-section over Union)预测中.计算出的矢量用于调制来自测试图像的特征,然后用于IoU预测.IoU预测网络输入的是是可微的边界框坐标,允许在跟踪过程中通过最大化预测IoU来细化候选对象.
3.3 离线训练过程
训练集的图片来自LaSOT(A High-quality Benchmark for Large-scale Single Object Tracking)数据集[26],对于特征提取网络的训练有两个步骤,首先训练嵌入网络,然后确定嵌入网络的参数之后再训练关系网络,即运行由嵌入模块和关系模块构成的整个特征提取网络,但只更新关系模块的参数.使用交叉熵损失CE训练嵌入网络θ作为目标跟踪网络中目标和背景的分类器,为了利用层级式的嵌入模块,添加了一个特征方差正则化项,该参数可由公式(4)计算:
(4)
式(4)中:σi是每个嵌入模块输出特征图方差的均值,m是输入视频帧的总数,λ是微调正则化项影响的超参数(本文设为0.01).
这确保了网络可以学习良好的特征分布,同时也可以视为一种为关系模块的特征层次结构可学习的数据增广策略,该策略可以提高网络的泛化性能,经过嵌入网络的训练之后,嵌入模块的参数是固定的.
在训练该嵌入网络的同时,我们还要对目标跟踪网络的分类分支和回归分支进行训练,对于分类分支的训练,经过嵌入网络提取到对应的特征,得到的特征输入到预测网络中得到滤波器f,然后将f在查询集上测试,然后计算一个损失,其损失可由公式(5)计算:

(5)
式(5)中:阈值T表示目标和背景所在区域,s表示预测的置信度分数,z表示标签的置信度值,该损失只惩罚背景样本,该式即为hinge-like损失函数.
分类分支的损失函数可由公式(6)计算:
(6)
回归分支的损失函数Lbb是通过计算在查询集上得到的预测交并重叠比值和真实值之间的均方误差.
接下来,在相同的数据集上训练关系网络,同样使用交叉熵损失函数CE进行训练,为了对四个关系模块V进行加权,还设计一种可学习的注意力权重用于计算每个模块的关系相似性分数整个关系网络的训练损失可由公式(7)计算:
(7)
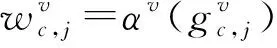
3.4 在线跟踪过程
在线跟踪时,将各个视频序列中带有目标中心位置和边界框的第一帧作为支撑集,取相同视频序列中的任意后续视频帧产生多个候选区域的集合作为查询集.首先经过关系网络,利用嵌入模块提取不同层级的特征,经过相应的关系模块计算关系分数,关系分数可由公式(8)计算,求得最佳候选区域.
(8)
在跟踪过程中,本文通过每20帧执行一次优化器递归,或者每当检测到干扰峰值时执行一次递归来优化目标模型f.边界框估计子网络的使用与文献[18]中设置相同.
4 实验结果
本文提出的算法实现平台为Ubuntu18.04系统下Pycharm2019中实现,配置为Intel Xeon Gold 6226R和NVIDIA GeForce GTX 2080Ti,所提出的整个网络架构是在Pytorch1.4.0框架上进行训练的,选择了近年来数个先进算法来进行对比实验,从而验证本文提出算法的有效性.由于大多数算法在性能综合评估时采用OTB和VOT数据集,故而选择OTB2015和VOT2018两个基准数据集进行评估.
4.1 在OTB2015上的评估
OTB2015 评测数据库一共包含100个视频序列,主要通过两个评价指标来对算法性能进行评估:基于中心位置误差的精确率(Precision rate)和基于重叠率的成功率(Success rate).OTB还提供了3个度量指标OPE、TRE、SRE.本实验中采用的评估方法为一次通过评价OPE(One Pass Evaluation),即在所有测试视频上目标跟踪算法都只运行一次,计算目标跟踪算法在跟踪目标过程中的精确率与成功率,生成 OPE 指标.
将本文提出的算法与各自不同的目标跟踪算法进行对比实验,实验结果如图3所示.
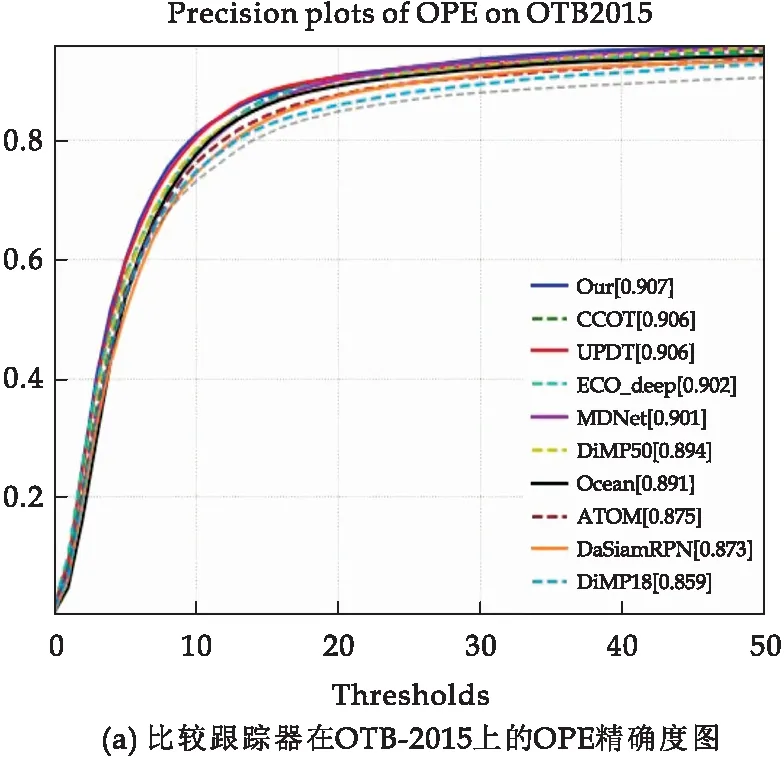
图3 OTB-2015中算法整体对比结果图
图3为OTB-2015数据集下的测试结果,进行对比的算法有:ATOM算法,DiMP算法的两个版本DiMP18和DiMP50,及改进版本PrDiMP18和PrDiMP50,高效卷积算法使用深度特征的版本ECO_deep和使用手工特征的版本ECO-hc,连续域卷积相关滤波算法CCOT,VOT2015的冠军算法MDNet,VOT2018的冠军算法DaSiamRPN,相关滤波算法UPDT.
图3(a)为各种算法在OTB2015的精确率结果图.由图3(a)可知,图中蓝色实线即为本文所提出的算法结果,其OPE指标中的精确度达到了0.907,虽然比CCOT和UPDT算法仅仅高出0.1个百分点,但是相比于基线算法DiMP和ATOM分别超出了1.3个百分点和3.2个百分点,由此说明,关系网络的引入对目标跟踪的精度提高起到了一定的改善.
图3(b)为各种算法在OTB2015的成功率结果图.由图3(b)可知,本文提出的算法相比于DiMP和ATOM两个跟踪器,分别获得了0.692和2.358的增益.
4.2 在VOT2018上的评估
VOT 是一个自 2013 年开始每年举办一次的目标跟踪比赛,一般作为 ICCV和 ECCV 会议的研讨会.从 VOT2016 开始,主要采用三个衡量目标跟踪算法性能的指标:
(1)准确性(Accuracy).在测试视频中目标跟踪算法预测的跟踪框,计算预测的目标边界框与手工标记的目标边界框之间的重叠程度,通过边界框的重叠程度来衡量算法的性能,重叠率越高则目标跟踪算法的精确性越好.
(2)鲁棒性(Robustness).目标跟踪算法完整地跑完测试视频,可能不会一次性就能成功,其中可能需要好几次重新初始化才能成功,目标跟踪算法在运行过程中丢失了跟踪目标导致跟踪失败那么需要重新进行初始化操作来保证对目标的持续跟踪,一般设置初始化的位置在跟踪失败的图像帧节点后面几帧,统计跟踪算法在完成一个完整的视频序列的跟踪任务需要重新初始化跟踪算法的次数,越少则表明算法的鲁棒性越好.
(3)平均重叠期望(Expected Average Overlap,EAO).在短时图像序列上,目标的外观会因为出现遮挡等情况发生变化导致跟踪过程中目标丢失,算法的鲁棒性是通过重置算法进行初始化的次数进行衡量,EAO 则是在目标跟踪失败后不再重新初始化算法,然后计算目标跟踪算法预测生成的目标边界框与实际的边界框的期望重叠程度来表征算法的跟踪度,值越大则目标跟踪算法的精度越高.对比实验结果如表1所示.

表1 本文算法在VOT2018上的对比结果
表1列出了一些追踪器的具体性能数据.对比算法还加入了文献[22]所提出的两种基于元学习的目标跟踪器,由表1可知,本文所提出的算法在EAO和鲁棒性方面排名第一,精确度方面略低于FCOS-MAML算法,相比于其他算法,本文所提算法有较好的性能表现,值得注意的是,本文所提出的算法相比于DiMP50和ATOM具有更加优秀的表现,其期望平均重叠率达到了0.462,相比于DiMP50有明显提升.
5 结论
将单目标跟踪算法作为小样本学习的问题,提出一种基于关系网络的孪生单目标跟踪算法,该算法利用关系网络中的两种模块提取不同层级的特征并且计算相应的关系分数,能够有效地提高目标和背景的分类效果,继而提升单目标跟踪的精度.通过在OTB2015和VOT2018两个基准数据集上的对比实验结果可以看出,本文提出的算法可以有效提升跟踪的性能.另外,本文也为元学习和目标跟踪结合提供了一种新的思路,未来将考虑引入更有效的结合方式,不仅实现更好的跟踪性能,而且要满足跟踪器的实时性.
