一种鲁棒的双耳声源方位角定位方法
2022-12-01陈国良赵祥瑞
陈国良,赵祥瑞
(武汉理工大学 机电工程学院,武汉 430070)
0 引言
机器人的听觉系统是机器人与外部环境互动的一种重要方式。与视觉相比,机器人听觉系统受障碍物影响较小,且具有360度的识别范围。机器人听觉系统包括许多方面,例如声源定位、语音识别、讲话者识别、情感识别和语音降噪等[1]。其中,机器人声源定位(SSL, sound source localization)作为听觉系统的前端处理模块之一,在机器人导航、人机交互、视频会议等领域发挥着重要作用[2-5]。
目前的声源定位研究主要分为两类:基于双耳SSL算法研究和基于传声器阵列的SSL算法研究。与基于传声器阵列的SSL相比,双耳SSL具有阵列结构简单,计算复杂度小,定位线索较少的特点。双耳SSL的线索主要有:双耳时间差(ITD,interaural time difference)、双耳强度差(IID,interaural intensity difference)和双耳相位差(IPD,binaural phase difference)[6-7]。ITD是指声波从声源到左右耳之间的时间间隔,IID是指两耳接收到的声波之间的强度差,IPD 是ITD在频域内的表现。在中低频(小于1.5 kHz)的情况下,ITD其主要作用,利用该时延差可以很好地进行方位的评估,但在噪声和混响的干扰下,ITD的性能会严重下降。因此本文主要讨论在噪声和混响环境下基于ITD的双耳声源定位。
在正常情况下,假设声音从声源到麦克风是一个简单的直线传输。然而,在混响的室内环境中,麦克风接收到的信号是声源信号与墙壁、地面、家具等物体反射产生的反射信号的叠加。这使得每个麦克风之间的信号不服从理想的时间延迟关系,最终使得麦克风之间的ITD难以判断。此外,环境噪声是SSL无法避免的一个重要问题。当环境噪声较强时,目标信号与双耳麦克风之间的时间差常常被抑制[8]。
针对混响和噪声的定位环境,基于ITD的双耳声源定位性能会严重下降问题,文献[9]对基于互相关函数的ITD算法进行改进,提出一种基于PHAH加权的广义互相关算法和可控波束算法融合的声源定位算法,实验证明该方法可提高在噪声环境中的定位准确性。文献[10]提出一种基于过零率(ZC,zero crossing)的ITD估计方法,该算法首先根据过零点获取各帧的ITD,然后通过信噪比估计进行各帧ITD的加权,从而获取最后的ITD。文献[11]提出一种基于混响加权的声源定位算法,该算法通过信道的混响权重分别降低早期混响和晚期混响的影响,从而获取更加准确的双耳定位线索,提高了在混响环境中的声源定位性能。因此,降低噪声和混响的干扰是双耳声源方位角定位技术的关键。
近年来,模式识别和机器学习技术在双耳声源定位中运用,文献[12]提出一种模板匹配的方法,对环境中的不同方位角建立不同的模板,基于特征和频率加权进行模板匹配。针对低信噪比的双耳SSL问题,文献[13]基于深度学习建立双耳定位线索和方位角的映射关系,进行定位。文献[14]将基于模型的声源频谱特征信息与深度神经网络相结合,解决各种噪声和混响条件下双耳SSL问题。这些方法在噪声和混响的环境中可取得较好的定位效果,但需要训练不同声学环境下的ITD和IID模型,通用性差,且计算量较大。
基于以上算法的不足之处,本文提出一种信号子频带选择结合具有噪声的基于密度的聚类方法(DBSCAN,density-based spatial clustering of applications with noise)的声源定位方法。首先对采集到的双耳语音信号进行Gammatone滤波,分频为不同的子频带;其次进行数据压缩,减少无关子带数量,降低计算复杂度;然后基于谱减算法进行各个子频带信噪比(SNR,signal-to-noise ratio)估计,选出最优的子频带;最后对子带信号进行分帧,基于互相关(CC,cross correlation)时延估计算法,获取每一帧互相关函数峰值对应的数据点,再根据DBSCAN聚类算法消除异常帧的影响,获取最优点,从而根据时延和ITD定位模型得到方位角。本文提出的算法不仅适用不同的SSL环境,而且提高SSL的鲁棒性。所提算法的框图如图1所示。
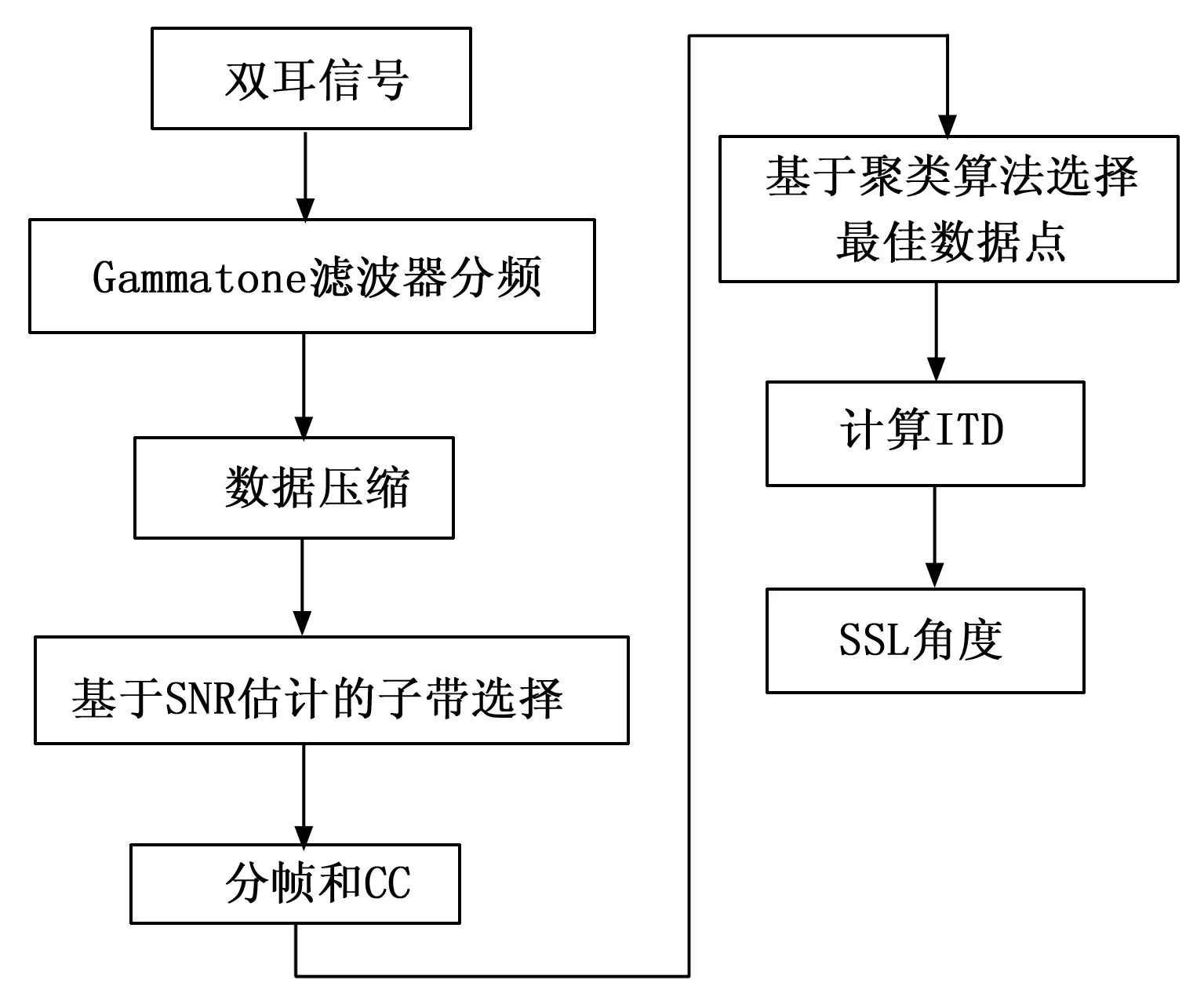
图1 双耳声源定位算法框图
1 基于Gammatone滤波器的数据压缩和子带选择
1.1 基于Gammatone滤波器组的分频
Gammatone滤波器组可以模拟耳蜗基底膜对于语音信号的处理机制,耳蜗基底膜可以将信号分解为不同频率的频带信号进行处理,Gammatone滤波器组将其组中的各个滤波器的带宽参数从低频到高频由窄到宽设置,可以将含噪语音按频率高低范围进行分频处理。
假设s(n)为声源语音信号,左右耳接收到的语音信号为xL(n)和xR(n),则信号模型为:
(1)
式中,hL(n)和hR(n)分别为声源信号到达左右耳的传递响应函数,nL(n)和nR(n)分别为左右耳的噪声信号,包含加性噪声和混响。
Gammatone滤波器组的响应函数gi(n,fi)为:
gi(n,fi)=
cos(2πfinTs+φ)·exp(-2πBnTs)·BJ·nJ-1·U(n)
(2)
式中,fi为第i个子频带的中心频率,Ts为采样周期,φ为滤波器的初始相位,J为滤波器的阶数,设置J=4以模拟人类听力,U(n)为单位阶跃函数,B为带宽,B的计算公式为:
B=b·ERB(fi)
(3)
式中,b=1.019为衰减系数,ERB(fi)为滤波器等效矩形带宽,根据大量实验[15],可得ERB(fi)的计算公式为:
ERB(fi)=24.7+0.108fi
(4)
将左右耳信号xL(n)和xR(n)进行分频,第i个左右耳子频带信号为Gi,L(n,fi)和Gi,R(n,fi),:即:
(5)
1.2 数据压缩
语音信号经过分频之后,不同的频带具有的能量不同,所包含的信息量也不同,将分频后的数据进行数据压缩,压缩后的左右语音信号数据yL(n)和yR(n)为:
(6)
式中,yL(n)=[y1,L(n),y2,L(n),…,yi,L(n)]T,yR(n)=[y1,R(n),y2,R(n),…,yi,R(n)]T,其中yi,L(n)和yi,R(n)分别是加权之后第i个左右子带信号。W是基于子带能量的加权矩阵,W=diag(w1,w2,…,wi)。GL和GR是分别是分频后的左右子带信号矩阵,即加权之后第i个左右子带信号:
(7)
式中,Gi,L(n,fi)和Gi,R(n,fi)是经过Gammatone滤波器组处理的左右耳第i个子带的信号。
由于语音信号的能量和信息主要集中在前2/3部分的子频带中[16],所以将w1,w2,…,w|2i/3|的权重设置为1,其余的权重设置为0。通过该数据压缩,可以提取信号中的重要子带信息,消除次要信息的干扰,降低计算复杂度。
1.3 基于SNR估计的子带选择
语音信号是一种非平稳的随机信号,考虑到人类发声器官在发声过程中的变化速度具有一定限度而且远小于语音信号的变化速度,因此可以假定语音信号是短时平稳的。噪声分为加性噪声和非加性噪声,加性噪声通常分为冲击噪声,周期噪声,宽带噪声,语音干扰噪声等;非加性噪声主要是残响及传送网络的电路噪声等[17]。
采用谱减法对子带信号进行SNR估计,谱减法是语音增强的有效方法之一,其基本思想是假定加性噪声与短时平稳的语音信号相互独立的条件下,从带噪语音的功率谱中减去噪声功率谱,将语音信号和噪声信号分离,从而进行SNR估计[18]。假定第i个左右子带信号yi,L(n)和yi,R(n)中,si,L(n)和si,R(n)分别为左右子带信号中的纯净语音信号,ni,L(n)和ni,R(n)分别为左右子带信号中的噪声信号,则有:
(8)
用Yi,L(w),Si,L(w),Ni,L(w)分别表示左通道的yi,L(n),si,L(n),ni,L(n)的傅里叶变换,Yi,R(w),Si,R(w),Ni,R(w)分别表示右通道的yi,R(n),si,R(n),ni,R(n)的傅里叶变换,则可得下式:
(9)
用Yi,L,angle(w),Yi,R,angle(w)分别表示相位谱,保留相角,则:
(10)
由于假定语音信号与加性噪声是相互独立的,因此有:
(11)
用Pi,L,y(w),Pi,L,s(w),Pi,L,n(w)分别表示yi,L(n),si,L(n),ni,L(n)的功率谱,用Pi,R,y(w),Pi,R,s(w),Pi,R,n(w)分别表示yi,R(n),si,R(n),ni,R(n)的功率谱,则有:
(12)
由于平稳噪声的功率谱在发声前和发声期间可以认为基本没有变化,因此可以通过发声前的所谓“寂静段”来估计噪声的功率谱,从而有:
(13)
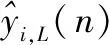
(14)
因此根据第i个左右子带信号yi,L(n)和yi,R(n)以及式(14),可得第i个左右子带的信噪比SNRi,L,SNRi,R,即:
(15)
根据子带SNR估计,当左右子频带信号SNR的均值最大值时,为最优左右子频带Y=[yL(n),yR(n)]T,其选择计算公式为:
(16)
1.4 基于子带选择方法的定位对比实验
为了评估本文所提出的子带选择方法的性能,将本文所提出的基于最优子带选择的SSL算法(SS-SSL)与文献[19]的基于通道求和的子带选择定位算法(GT-PHAT-SSL)进行比较,实验设置和性能评估标准如3.1节所示。将采集到的双耳信号添加信噪比为-5 dB,0 dB,5 dB,10 dB,15 dB,20 dB的全局白噪声,如图2~3展示了不同SNR下的两种算法定位的准确率和RMSE。为了评估算法的运算复杂度,本文使用Matlab 计算两种子带选择算法的运算时间,如表1展示了两种算法的运算时间对比。
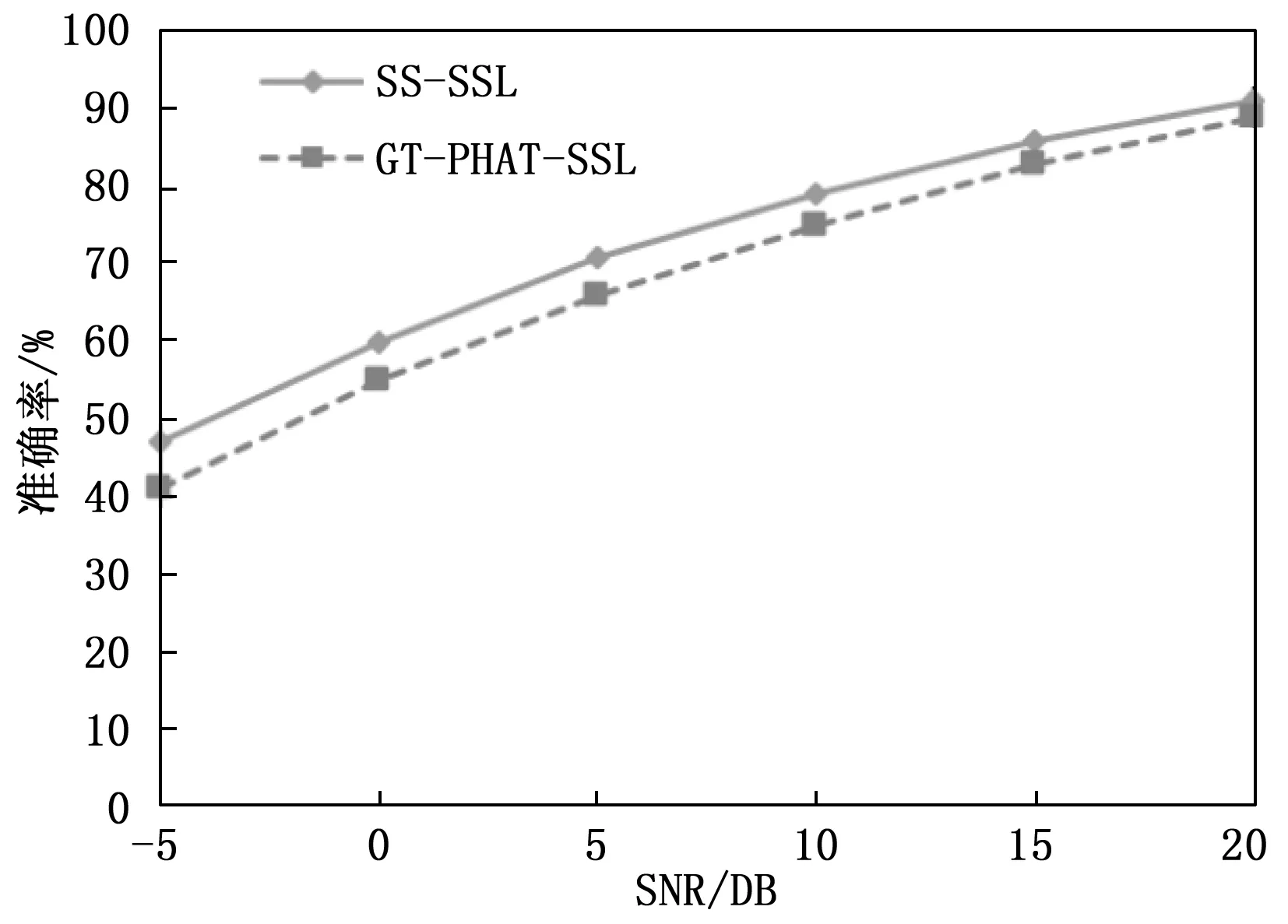
图2 不同信噪比下的准确率
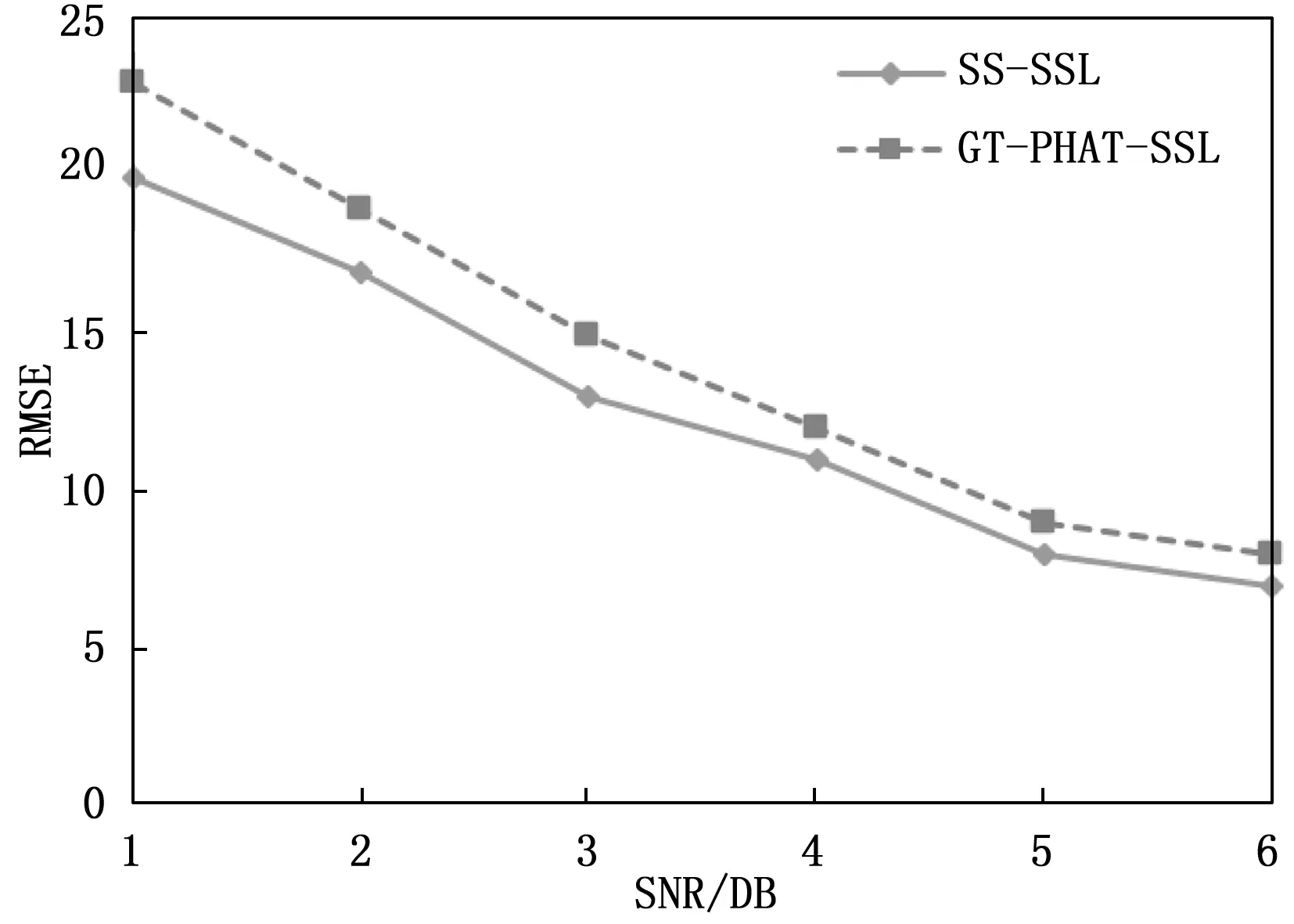
图3 不同信噪比下的RMSE

表1 运算时间对比
图2显示了不同SNR情况下基于最优子带选择的SS-SSL算法的准确率高于基于通道求和的子带选择的GT-PHAT-SSL算法,图3显示了不同SNR情况下基于最优子带选择的SS-SSL算法的RMSE低于基于通道求和的子带选择的GT-PHAT-SSL算法,这说明SS-SSL的定位性能优于GT-PHAT-SSL。表1显示了SS-SSL的运算时间低于GT-PHAT-SSL,这说明与GT-PHAT-SSL算法相比,采用最优子带选择的SS-SSL可以降低运算复杂度,提高机器人声源方位角定位的实时性。
2 基于互相关的ITD估计和基于DBSCAN的SSL
2.1 基于互相关的ITD估计
ITD估计算法的方法有很多,基于互相关的ITD算法(CC-ITD)具有原理简单,运算量小的特点。CC-ITD通过求左右耳两信号yL(n)与yR(n)之间的互功率谱,并在频域内给予一定的加权ΦyLyR,再反变换到时域得到两信号之间的互相关函数,互相关函数的峰值处就是两信号之间的相对时延[20]。CC-ITD基本流程如图4所示。
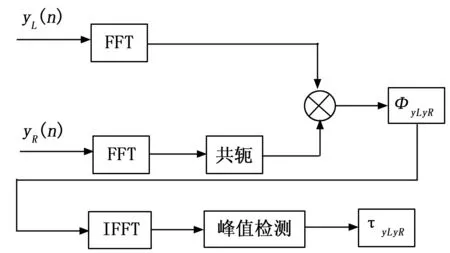
图4 CC-ITD基本流程
yL(n)与yR(n)是左右两耳的最优子频带信号,其傅里叶变换分别为YL(w)和YR(w),两路滤波器的系统函数分别为FL(w)和FR(w),则两信号之间的互相关函数RyLyR(τ)可表示为:
(17)
式中,φyLyR(w)为互相关函数的加权函数,针对不同的噪声和混响环境可以选择不同的加权函数,其计算公式为:
(18)
当φyLyR(w)=1时表示基本广义互相关法的加权函数。RyLyR(τ)的峰值处是两信号yL(n)与yR(n)的相对时延τyLyR,即:
(19)
根据τyLyR可以通过ITD定位模型求得所需的方位角θ,ITD定位模型如图5所示,图中A,B是左右双耳麦克风用于接收声源信号,以O为圆心的圆半径为r,θ为声源的水平方位角。
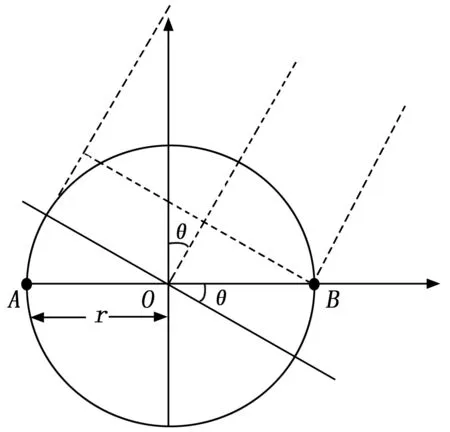
图5 ITD定位模型
假定声速传播速度为c,τyLyR与θ的关系式可以表示为:
(20)
对于不同的信号频率,ITD模型有一定的变化规律,其参数化形式表示为:
(21)
式中,αf是与fi相关的尺度因子。反转模型就可以得到水平方位角θ为:
(22)
式中,g-1为g(θ)=sinθ+θ的反转函数,g-1近似表示为:
(23)
2.2 基于DBSCAN的SSL
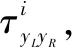
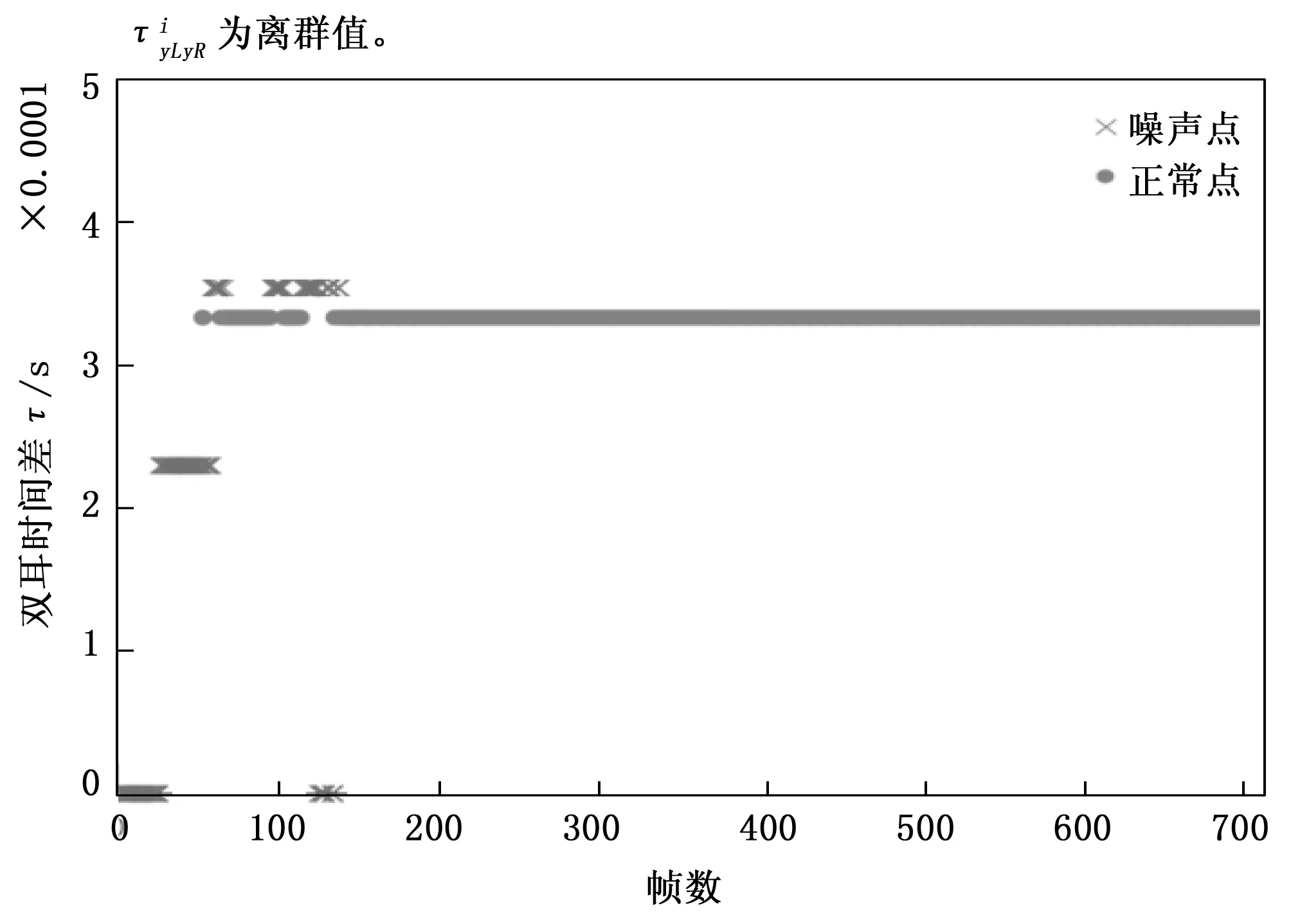
图6 不同帧的双耳时间差
引入DBSCAN算法解决CC-ITD的噪声问题,DBSCAN算法使用基于密度的方法来计算数据中任意形状的簇和离群值(噪声),并且不需要事先知道簇的数量[21-22],所以引入DBSCAN用来解决异常问题,消除噪声的干扰。
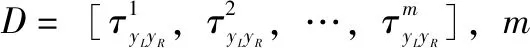
1)核对象 一个样本p以Eps为半径的圆内的有超过一定数目(≥MinPts)的样本,则样本p称为核对象。
2)Eps邻域 领域内的点定义为NEps(p)={q∈D,dist(p,q)≤Eps},其中dist(p,q)为p,q之间的距离。
3)密度直达对象p为核对象,并且q为p的Eps邻域,则称对象q从对象p密度直达。
4)密度相连 若存在一个对象o,使得对象p和q都从o密度可达,则称对象p和对象q密度相连。
DBSCAN算法的处理流程如表2所示。
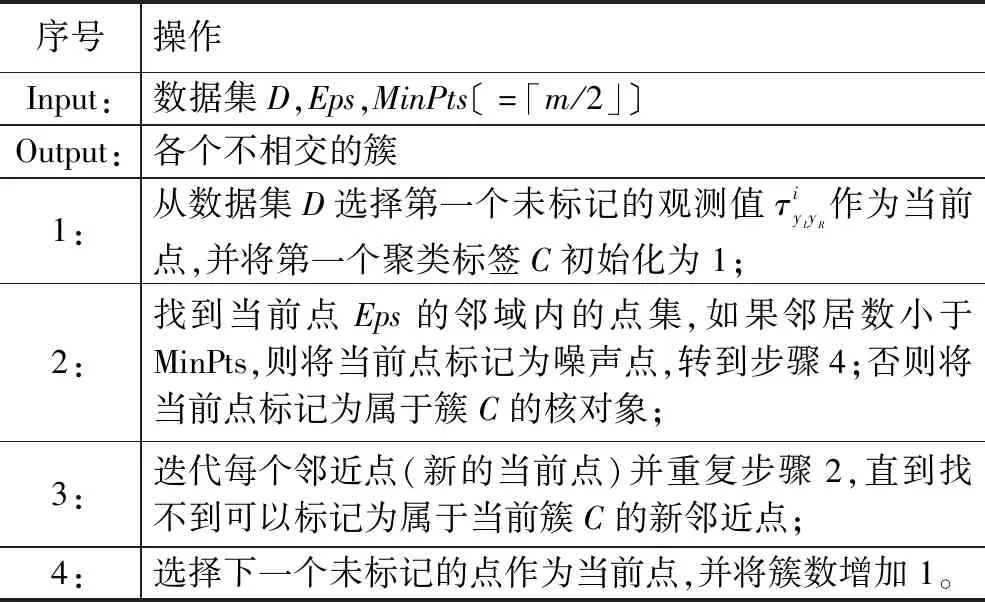
表2 DBSCAN算法处理流程
2.3 基于DBSCAN的SSL定位性能分析
为了评估本文提出的基于DBSCAN的声源定位算法(DBS-SSL)的定位性能,将DBS-SSL与基于均值互相关的声源定位算法(MEAN-SSL)进行对比实验,实验条件和定位性能标准如3.1节所示。将采集到的双耳信号添加信噪比为-5 dB,0 dB,5 dB,10 dB,15 dB,20 dB的全局白噪声,如图7~8展示了不同SNR下的两种算法定位的准确率和RMSE。
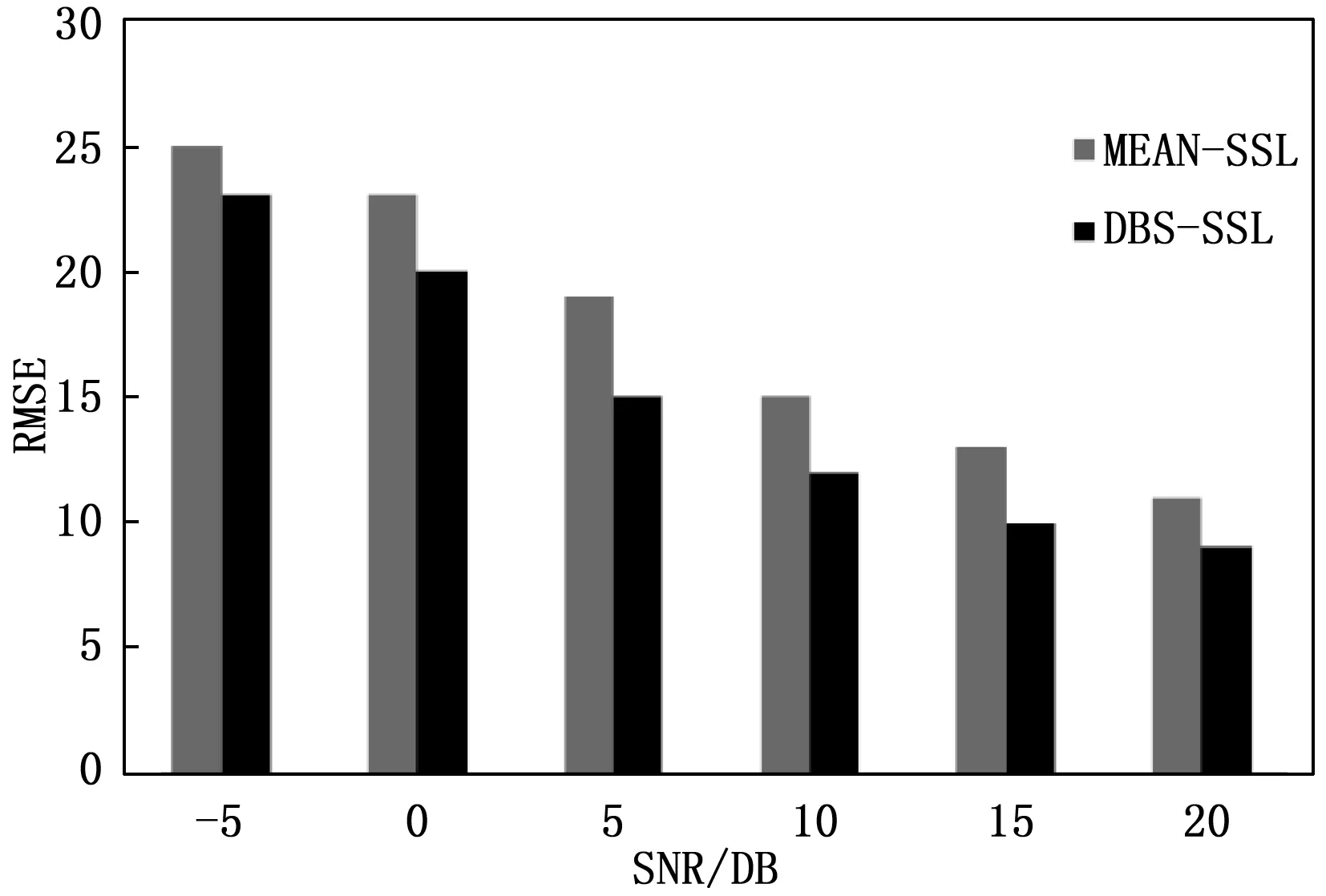
图8 不同信噪比下的RMSE
由图7可知,不同信噪比的情况下DBS-SSL定位准确率都高于MEAN-SSL算法,由图8可知,不同信噪比的情况下DBS-SSL的RMSE都要低于MEAN-SSL算法,这说明引入DNSCAN算法可以降低基于GCC-ITD法获取τyLyR时的噪声影响,提高定位鲁棒性。
3 实验与结果分析
3.1 声源定位实验
声源定位系统主要包括麦克风模块,数据采集模块,计算机处理模块等。两个麦克风阵列搭载在3D打印的平台上,两个麦克风之间的距离为15 cm,麦克风传感器连接到信号数据采集卡上,通过数据线将计算机和信号数据采集卡进行连接,使用LabView对声源信号进行采集,使用MatLab对采集到的左右耳声源信号进行数据分析和处理,声源定位实验平台如图9所示。

图9 实验平台
本文选用的声音传感器型号为HJ-386,该型号麦克风具有全指向性、灵敏度高、抗干扰能力强以及阻抗值低等特点。数据采集卡型号为NI USB-6009,其技术参数如表3所示。
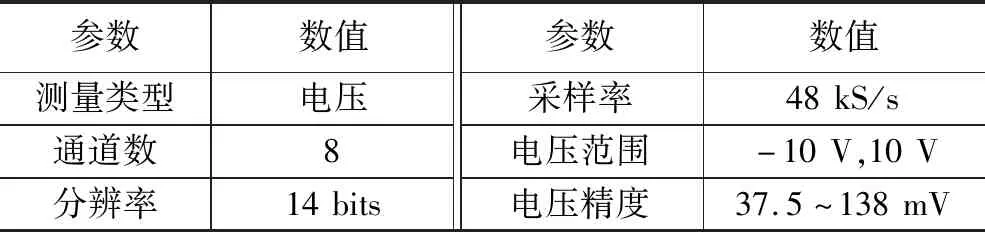
表3 数据采集卡技术参数
实验在5 m×4 m×3.5 m和6 m×8 m×3.5 m的室内环境中进行,混响时间T60分别为0.3 s和0.6 s,室内噪声主要来自计算机散热和室外车辆行驶噪声。声源采用CHAINS Speech Corpus语音库SOLO中的单声道女声、男声信号。噪声采用Noisex-92和Nonspeech噪声库的噪声语音。采样率为44.1 kHz,滤波器的频率范围为[0,8 000]Hz,最大的中心频率为 8 000 Hz,根据听觉阈值范围内的临界带[23],选择滤波器个数为 22个,所以子带数量为 22 条,由于语音信号的能量和信息主要集中在前 15个子频带中,所以将w1,w2, …,w15的权重设置为 1,其余的权重设置为 0。帧长为20 ms,帧移为10 ms,规定声源在双耳麦克风右侧时方位角为0°,与双耳麦克风垂直时且垂直点为双耳麦克风中点时方位角为90,在双耳麦克风左侧时方位角为180°。
为了评估基于SNR估计的子带选择和DBSCAN算法对声源定位性能的影响,本文采用4种不同算法做对比声源定位实验,分别是本文所提出的基于子带选择和DBSCAN的SSL算法(SS-DBS-SLL),基于互相关函数的SSL算法(CC-SSL),基于最优子带选择的SSL算法(SS-SSL)和基于DBSCAN的SSL算法(DBS-SSL)。算法性能由定位准确率和均方根误差(RMSE)评估,其中定位准确率定义为估计方位角和实际方位角之间的误差在±5°之内。
3.2 不同信噪比下的声源定位性能研究
为了评估算法在不同噪声环境中的声源定位性能,本实验将采集之后的左右耳语音信号添加信噪比为-5 dB,0 dB,5 dB,10 dB,15 dB,20 dB的全局白噪声,测试算法性能。如图10~11展示了不同SNR下的算法定位性能。
图10表明,不同信噪比的情况下,本文所提的SS-DBS-SSL算法的定位准确率都要优于CC-SSL算法,并且SS-SSL和DBS-SSL算法的准确率也都要优于CC-SSL,这说明子带选择和DBSCAN都可以有效提高定位准确率,其中子带选择对于提高SSL的准确率有更积极作用。在不同信噪比的情况下,4种算法的定位性能都随SNR的提高而提高。图11显示了SS-DBS-SSL的RMSE在各个信噪比条件下也是最好的,并且随着信噪比的增大RMSE越来越小,定位性能越来越好。
图10和图11说明子带选择和DBSCAN都可以提高定位性能,其中子带选择的作用更大。分析其原因,基于子带选择可以消除噪声频带的影响,保留主要信号能量,引入DBSCAN可以消除在信号处理引入的异常帧,以及最优子带中残留的部分噪声的影响,从而从两个方面提高了定位性能。

图10 不同信噪比下的定位准确率
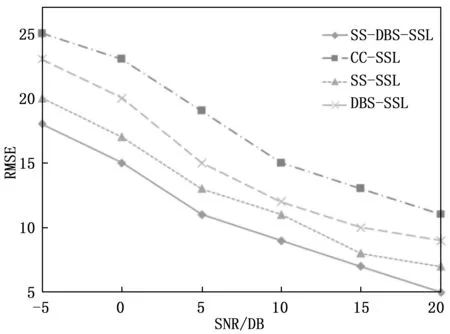
图11 不同信噪比下的RMSE
3.3 不同噪声环境下的声源定位性能研究
为了评估算法在不同噪声环境下的定位性能,将采集到的双耳信号添加SNR为的15 dB不同背景噪声,选择了12种不同的背景噪声类型,其如表4所示。
表5和表6显示了不同噪声环境下的定位准确率和RMSE。从表5可以看出,N2和N11的定位准确率较低,表6也可以看出,N2和N11的RMSE较高,定位性能较低,这说明算法在babble和Crowd noise的背景噪声下影响较大,分析其原因主要是该噪声的主要频率与信号中的主要频率相似,通过子带选择无法有效消除噪声干扰,从而影响定位性能。在不同的噪声环境下,SS-DBS-SSL的定位性能最好,这也说明了SS-DBS-SSL具有较高的鲁棒性。
3.4 不同混响条件下声源定位性能研究
为了评估算法在不同混响环境下的定位性能,分别在混响参数T60为0.3 s和0.6 s的房间中进行方位角定位实验。如图12展示了算法在不同混响条件下的定位性能。

表4 背景噪声类型

表5 不同噪声环境下的定位准确率

表6 不同噪声环境下的RMSE
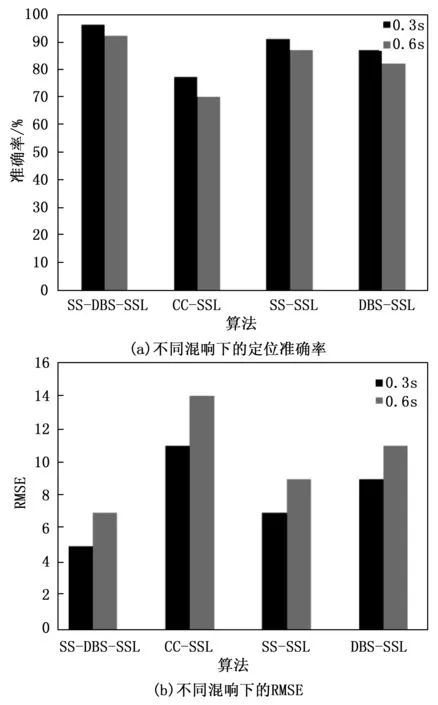
图12 不同混响条件下的定位性能
图12显示了4种算法在不同混响条件下的定位准确率和RMSE。由图12可知,4种算法在低T60的混响条件下的定位准确率表现更好,并且RMSE也更低。这T60说明越大,定位性能越低。在不同的混响条件下,SS-DBS-SSL的表现优于其它算法。这也说明了本文所提算法在混响环境中具有一定的鲁棒性。
3.5 不同距离和角度下的声源定位性能研究
为了评估算法在不同角度下的定位性能,将声源放置在实验平台的前半面,声源与双耳麦克风的中点距离为1 m,角度依次为0°,30°,60°,90°,120°,150°,180°。图13展示了不同角度的情况下定位的准确率和RMSE。从图13可以看到,不同角度的情况下,各个算法的定位性能没有明显的变化趋势,基本保持稳定,其中SS-DBS-SSL的定位性能最好。
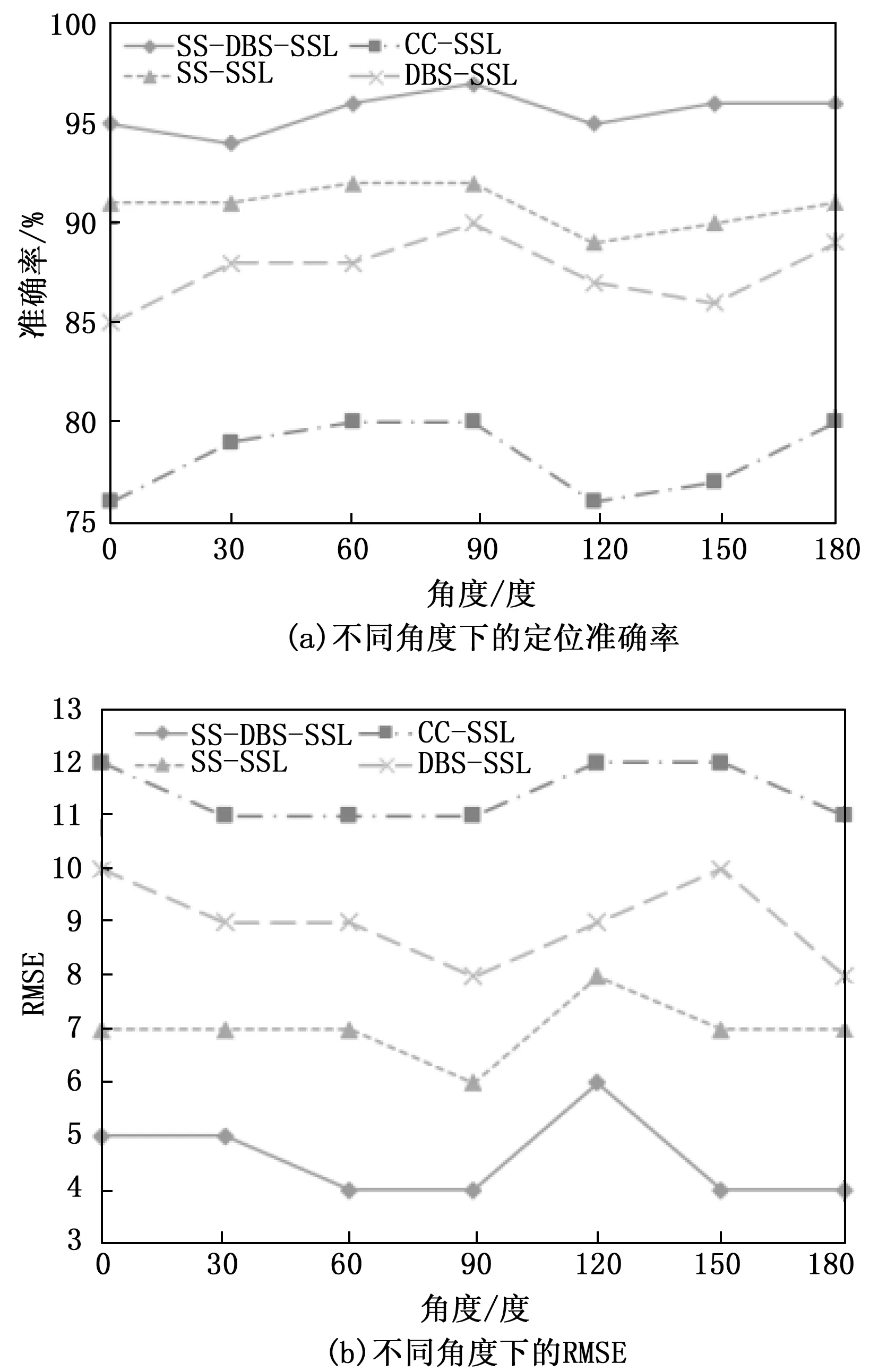
图13 不同角度下的定位性能
为了评估算法在不同距离下的定位性能,将声源放置在距离实验平台1 m,1.5 m,2 m,2.5 m,3 m,3.5 m处,角度为90°。图14展示了不同距离的情况下定位的准确率和RMSE。从图14可以看到,算法的定位性能随着距离的增大而降低。分析其原因,随着距离的增大,采集到的信号中的噪声能量越来越高,声源信号能量越来越低,从而导致SNR越来越低,所以定位性能下降。
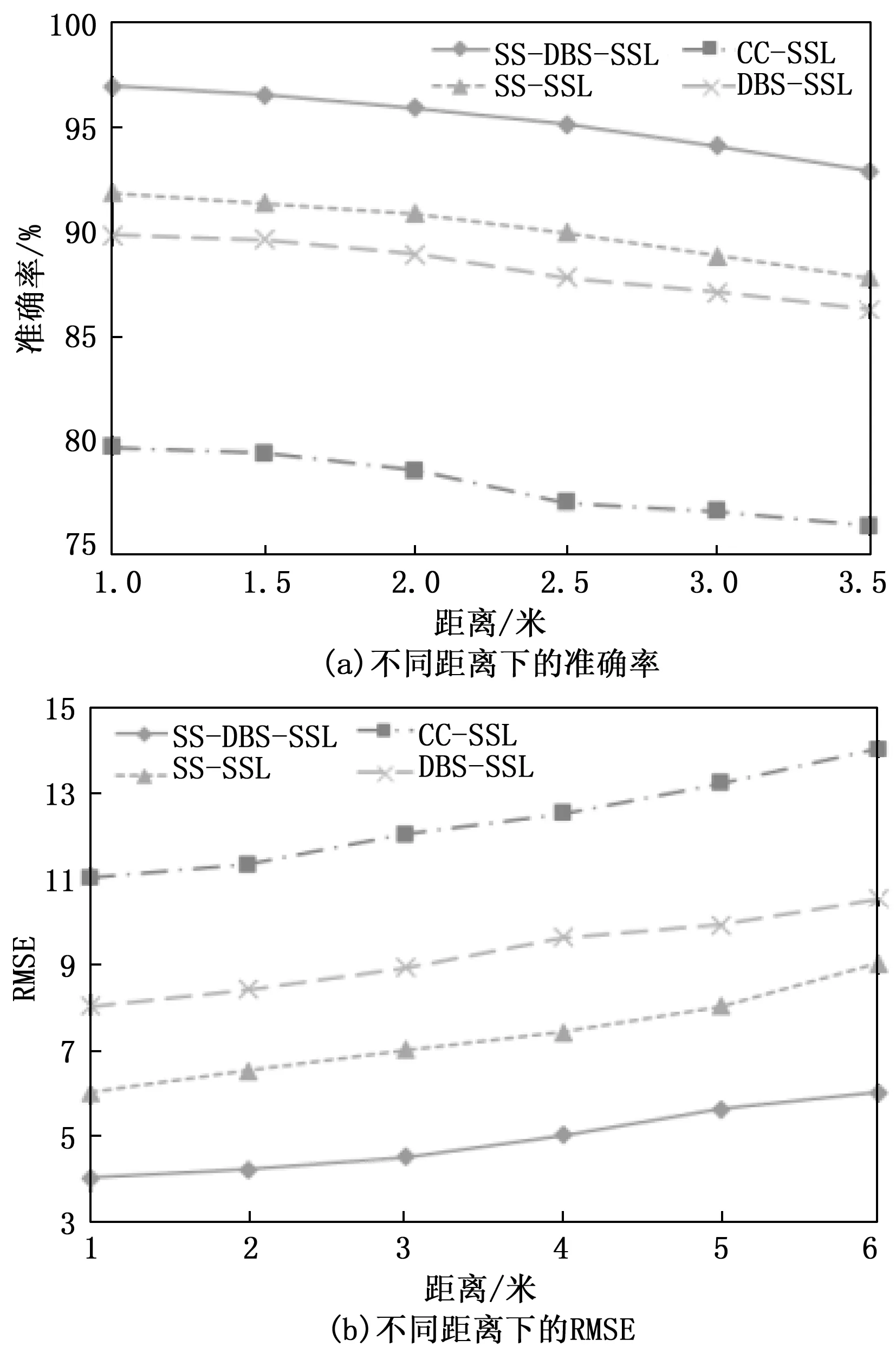
图14 不同距离下的定位性能
在不同角度和距离的情况下,SS-DBS-SSL的定位性能都要优于其它算法,这也体现了本文算法具有较高的鲁棒性和稳定性。
3.6 不同声源下的声源定位性能研究
为了评估不同声源对定位性能的影响,采用男声、女声作为不同的声源,分析男声和女声情况下的定位性能。图15显示了男声和女声的情况下的定位准确率和RMSE。从图15可以看到,在声源为女声的情况下的定位准确率要优于声源为男声的情况,在声源为女声的情况下,RMSE也较小,并且本文所提算法的表现优于其它算法。这说明声源为女声的定位性能要优于男声,在不同的声源条件下,SS-DBS-SSL的定位性能也更好。分析其原因可知,女声信号的能量大,在相同的实验环境中,其定位性能也越好。
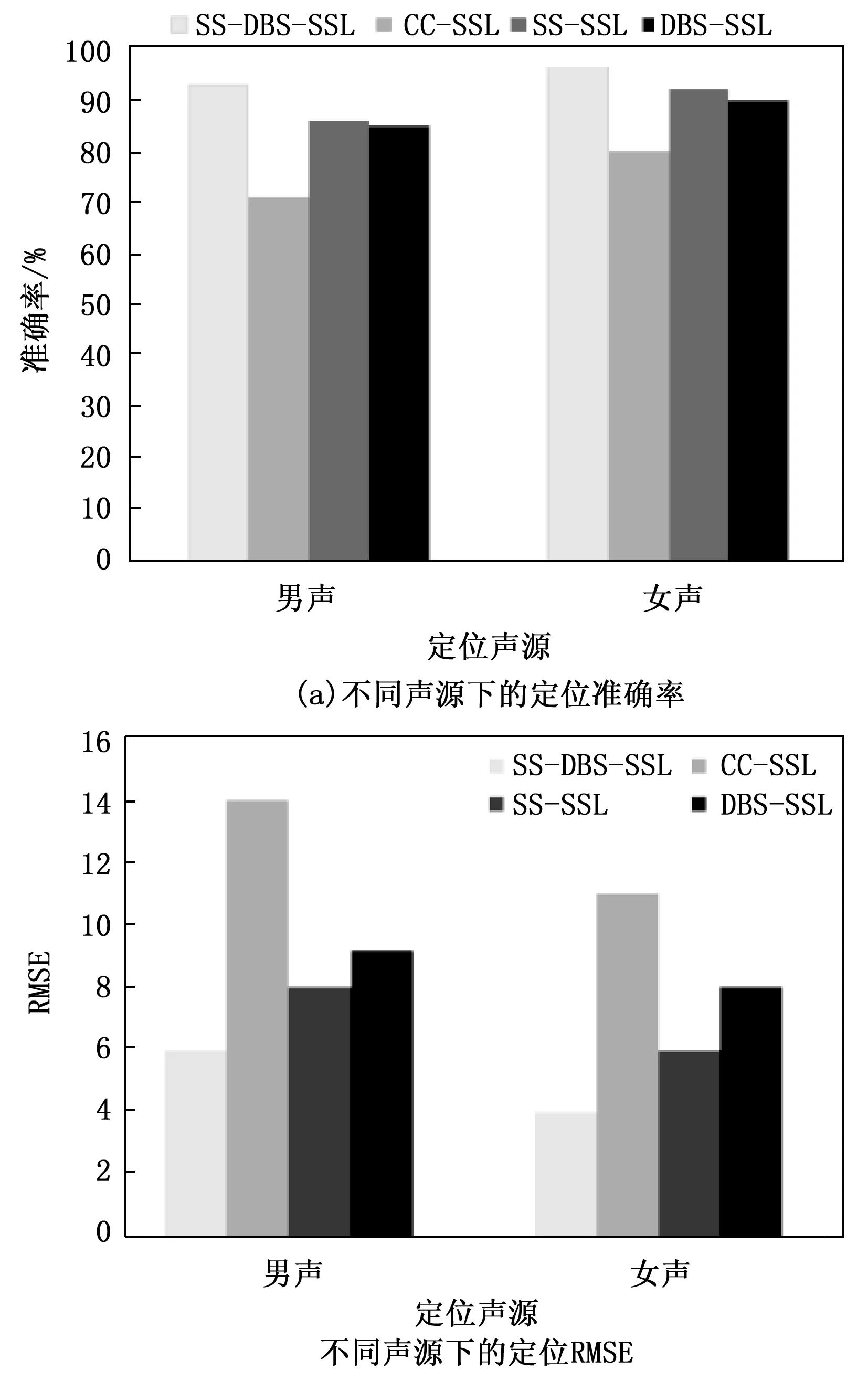
图15 不同声源下的定位性能
4 结束语
本文基于Gammatone 滤波原理对双耳语音信号进行分频,并通过数据压缩降低计算复杂度,然后基于谱减法的SNR估计选择最优子带,减少无关子频带影响,并引入DBSCAN算法减少噪声点,降低异常帧对定位结果的干扰。从实验结果和分析可以看出,本文提出的算法通用性强,与基于互相关的传统算法相比,可以有效改善在混响和噪声的复杂环境中双耳声源的定位精度,提高声源定位的鲁棒性。进一步,该实验平台可与移动机器人结合,研究机器人与声源相对运动时的双耳声源定位问题。
