基于多源数据及三层模型的小班林型识别
2022-11-29吴达胜方陆明
黄 健,吴达胜,方陆明
(浙江农林大学数学与计算机科学学院,林业感知技术与智能装备国家林业和草原局重点实验室,浙江 杭州 311300)
传统的森林资源调查以实地调查为主,不仅需要大量的人力、物力、财力,而且调查周期长,难以满足森林资源动态监测的需求[1-2]。当然,传统的地面调查可为森林资源调查提供客观可靠的数据,再结合遥感影像和机器学习方法,可以提高森林资源监测的时效性、降低监测成本。近年来,光学遥感影像数据在林业资源监测中备受关注。
李煜等[3]、张悦楠等[4]、蔡林菲等[5]使用遥感影像结合机器学习的方式对树种进行识别,均得到了较高的总体识别精度,3个研究结果均表明光谱信息是决定树种识别精度的主要特征变量。随着遥感技术的迅速发展,将光学遥感影像与雷达遥感影像相结合的方法在森林资源监测中的使用也越来越广泛,且在树种识别方面取得了较好的效果[6-7]。王瑞瑞等[8]使用机载多光谱数据与雷达点云数据,结合RF、SVM与ANN进行树种识别,总体精度达到了86.19%;徐逸等[9]采用XGBoost算法,以机载高光谱数据与雷达数据对红树林树种进行了分类,总体精度达到了96.74%;皋厦等[10]结合LiDAR与高光谱数据,使用RF算法构建树种识别模型,总体精度达到了91.30%。Persson等[11]使用Sentinel-2影像数据,结合RF对瑞典常见树种进行分类,总体精度达到了86.30%,研究表明近红外波段对树种的识别有重要的作用;Dalponte等[12]使用高光谱与多光谱数据融合激光雷达数据对南阿尔卑斯山区域特兰托的部分区域进行树种识别,经对比实验发现,高光谱数据结合激光雷达数据与多光谱数据结合雷达数据在对“森林” “非森林”和“阔叶林” “针叶林” “非森林”这两种宏观分类上没有明显差距,但在对树种进行精细分类时,高光谱数据结合激光雷达数据的效果更优。
淳安县的主要林型为阔叶林与针叶林,其中阔叶林中包含阔叶混交林、其他硬阔林、山核桃林(Caryacathayensis),针叶林中包括杉木(Cunninghamialancelata)林与马尾松(Pinusmassoniana)林,这些林种起到了保持水土、调控天气以及维持生物多样性等作用,同时也为人类生产生活提供了丰富的原材料,为可持续发展提供了坚实的物质基础。毛竹(Phyllosstachysedulis)与茶树(Camelliasinensis)林是研究区中经济林的重要组成部分,并带来了较可观的经济效益。由于淳安县面积较大,森林资源丰富,通过卫星遥感技术不易于树种的精细分类;而通过对淳安县小班中的林型进行识别,便于整个区域森林资源的经营与管理。故本研究将淳安县各小班的林型作为最终识别对象。
综上所述,关于优势林种识别的研究区域主要集中在林场或森林且都获取了较高的识别精度,但对于大范围内的林型识别研究较少[6],模型的泛化能力不够,为了进一步提高区域森林小班林型识别结果的可靠性与模型的泛化能力,并获取较高的识别精度,本研究集成Sentinel-2和Sentinel-1遥感影像、数字高程模型(DEM)和森林资源二类调查数据,将模型分为3层:首先使用RF建立林地识别模型,再使用RF、XGBoost、LightGBM建立树种结构识别模型,最后一层根据树种结构识别模型的识别结果,使用LightGBM进行林型识别,这是一个逐步求精的过程。本研究采用3层模型结构对大范围内的林型进行识别,以期获取相较于传统的单层模型更高的精度。
1 材料与方法
1.1 研究区概况
研究区域为浙江省淳安县(118°20′~119°20′E,29°11′~30°02′N),位于浙江省西部、杭州市西南部丘陵山区,白际山脉和千里岗山脉之间,新安江和千岛湖交汇之处,四面多山,中为丘陵,略呈盆地状,属北亚热带季风气候区。陆域面积4 417.48 km2,是浙江省陆域面积最大的县。淳安县中部是千岛湖区,生态环境较好,拥有33.332万hm2的森林面积,覆盖率高达75.27%。其中,包括了阔叶混交林、其他硬阔林、山核桃林、马尾松林、杉木林、毛竹林、茶树林这7种林型(表1)。

表1 树种结构分类及样本数量
1.2 遥感影像数据
1.2.1 光学遥感影像
本研究使用的光学遥感影像数据来源于欧洲航天局哥白尼计划中的Sentinel-2卫星,成像时间为2017年10月29日—10月30日,共5景,影像可覆盖13个光谱波段[13]。
1.2.2 雷达遥感影像
本研究所用的雷达遥感影像来源于搭载合成孔径雷达的Sentinel-1卫星,成像时间为2017年10月18日,使用的是IW GRD级的2景影像数据。
1.3 地形因子
地形因子提取于先进星载热发射和反射辐射仪全球数字高程模型(ASTER GDEM)第2版,共4景,分辨率为30 m,公布时间为2017年。
1.4 实地调查数据
本研究的实地调查数据来自2017年的淳安县森林资源二类调查数据,其中包含了研究区域各森林小班的详细信息。
1.5 自变量提取
1.5.1光学遥感因子
光学遥感因子包括光谱特征因子和纹理特征因子。光谱特征因子:在Sen2Cor插件与SNAP软件中经过预处理将影像转为ENVI格式,去除Sentinel-2遥感影像中分辨率较低且与实验关系不大的3个波段(Band1为海岸/气溶胶波段,Band9为水蒸气波段,这两个波段对于本研究的意义不大,而Band10为卷云波段,获取的是大气顶部的反射率,并不是地表的反射率,在Sen2Cor插件中的大气校正步骤中自动删除),剩余10个波段;外加计算得到的4个植被指数,即比值植被指数(RVI)、增强型植被指数(EVI)、差值环境植被指数(DVI)、归一化植被指数(NDVI)[5,14]以及6个光学波段组合因子,共计20个光谱特征因子作为自变量(表2)。

表2 光谱特征因子
纹理特征因子:对基于Sentinel-2光学遥感影像中空间分辨率最高(10 m)的Band2、Band3、Band4和Band8进行主成分分析,并选取第1主成分进行计算纹理特征值。在遥感影像的研究中,使用的滑动窗口大小一般不大于51×51像素[15],所以本研究共使用了13个大小为3×3像素至51×51像素,方向为135°,且移动步长为1像素的滑动窗口进行对比。各个窗口提取均值(mean)、同质性(homogeneity)、熵(entropy)、非相似性(dissimilarity)、对比度(contrast)、相关性(correlation)、方差(variance)和二阶矩(second moment)8个纹理特征值[16-18]参与后续实验。
1.5.2 雷达遥感数据提取特征
使用SNAP软件对Sentinel-1雷达遥感影像数据进行轨道校正、消除边界噪声、去除热噪声、抑制相干斑噪声、辐射定标、分贝化等操作,得到VV(垂直发射,垂直接收,同向极化)和VH(垂直发射,水平接收,交叉极化)两种极化方式的后向散射系数,并将VV和VH进行相减和相除,共得到4个雷达遥感因子。
1.5.3 地形特征提取
将获取的4景DEM在ArcGIS中进行坐标系转换、拼接和裁剪后,提取研究区域的海拔、坡度、坡向这3个地形因子。
1.5.4 森林资源二类调查数据
从森林资源二类调查数据中提取各个小班的土层厚度、腐殖质厚度作为特征因子[19-20],并将其所对应的树种结构与林型作为模型标签,用于模型精度的验证指标。
二类调查数据中的腐殖质厚度表示为:薄、中、厚。由于这两个特征因子并没有详细的数值且相互之间存在递进的数学关系,本研究采用了标签编码的方式(编码薄为0,中为1,厚为2)。土层厚度在二类数据中有具体的数值表示,故不需要进行编码。
综上所述,本研究共使用37个特征因子,其中光谱特征因子20个,纹理特征因子8个,雷达遥感因子4个,地形因子3个,森林资源二类调查因子2个。
1.6 总体路线
以小班为研究单元,集成Sentinel-2、Sentinel-1、DEM及森林资源二类调查数据,提取自变量因子数据,并将各个因子使用不同的组合方式进行建模。第1层模型使用RF模型识别林地与非林地;第2层使用RF、XGBoost、LightGBM模型识别林地上的树种结构类型;第3层使用上层中的最优方法结合雷达遥感数据识别林型。
具体流程如图1所示。
2 研究方法
2.1 建模算法
1)随机森林(RF)。使用Boostrap重采样算法对原始数据集进行有放回的横向欠采样与纵向欠采样,得到若干份数据集。使用每一份训练集训练1棵决策树,所有的决策树集成后构成随机森林,最终的分类结果由各子树投票进行决定,得票数最多的识别结果作为随机森林的最终结果。本研究设置了最大特征数为总特征数量的平方根,子树的数量设置为250棵。
2)极端梯度提升(XGBoost)。该算法的基础学习器之间存在线性的相关性,通过特征预排序机制,减少了迭代过程中的计算量,每次迭代对残差进行拟合。基础学习器采用了与RF相似的特征降采样,降低过拟合的风险。XGBoost模型采用决策树作为基学习器,子树数量设为250棵,最大深度为6,每棵决策树使用80%的训练集样本与80%的特征进行构建,学习率默认为0.3。
3)LightGBM。该算法与XGBoost都是提升算法,其最明显的特点是在训练的过程中可以将连续型特征离散化,类似于数据分箱操作,将连续数据进行分段划分,并装入对应的箱子中,大大减少计算量,并且支持类别特征直接输入。在子树的生长过程中采用了leaf-wise生长策略,减少了无效节点分裂,提升树设为250棵,学习率设为0.2,最大深度设为6。
2.2 数据处理
1)本研究中3层模型都以7∶3的比例进行训练集与测试集的划分,并构建模型。其中,二类数据中提取的树种结构信息与林型信息作为模型的标签,用于精度验证,模型评价指标采用了用户精度(user accuracy, UA)、生产者精度(producer accuracy, PA)、总体精度(overall accuracy, OA)以及Kappa系数。
2)本研究获取的森林资源二类调查数据中共包含了133 429条小班数据,剔除残缺的数据以及小样本树种与灌木林地数据,保留共65 542条林地数据与4 094条非林地数据。
3)由于第1层中的正负样本不均衡,为了提高识别结果中林地数据的纯度,林地识别模型中采用了4种过采样算法:合成少数类别过采样技术(synthetic minority oversampling technique, SMOTE)、边界过采样(borderline-SMOTE)、支持向量机过采样(SVM-SMOTE)、自适应过采样(adaptive synthetic sampling, ADASYN)。为了避免正负样本的边界模糊,从过采样后的数据集中提取了90 000条数据用于模型构建,其中63 000条数据用于模型训练,27 000条数据用于精度测试。训练集中林地数据45 890条、非林地数据17 110条,测试集中林地数据19 652条、非林地数据7 348条。
4)林种结构识别模型使用来自第1层模型中识别结果为林地的数据,将获取的林地数据使用拉依达准则[21]进行筛选,剔除了270条识别错误的数据以及14 345条异常数据,剩余50 565条林地数据。从中提取11 480条阔叶林数据、10 957条针叶林数据、12 957条经济林数据作为训练数据,剩余数据用于模型精度测试。
5)在第3层林型识别时,共使用阔叶混交林3 271条、其他硬阔林3 624条、山核桃林4 585条、杉木林6 742条、马尾松林4 215条、毛竹林6 850条、茶树林6 107条数据进行模型的训练,其余数据用于模型精度验证。
2.3 模型构建
林型的识别通过分层模型的方法实现:
1)第1层林地与非林地识别模型基于RF与过采样算法构建,将识别结果为林地的数据用于林种结构识别。
2)第2层树种结构识别模型将第1层模型识别结果中的林地数据作为数据集,使用RF、XGBoost、LightGBM进行构建。
3)第3层林型识别模型使用第2层对比实验中的最优建模算法进行构建,并将第2层模型的识别结果作为类别特征。为了探究雷达遥感因子及特征选择对模型精度的影响,设计了3种遥感因子及特征选择方案。
3 结果与分析
3.1 林地与非林地识别
林地与非林地识别模型的分类结果如表3所示。从表3可知,SMOTE过采样可以使第1层模型的总体精度达到最高,其中测试集识别结果混淆矩阵如图2所示。

表3 不同过采样算法下的RF模型精度
3.2 树种结构识别
将第1层模型中识别结果为林地的数据进行筛选后,利用RF、XGBoost、LightGBM这3种算法模型,使用如下4个自变量组合方案进行建模。方案1为光谱特征因子;方案2为光谱特征因子、森林资源二类调查因子;方案3为光谱特征因子、森林资源二类调查因子、地形因子;方案4为光谱特征因子、森林资源二类调查因子、地形因子、纹理特征因子,其中前3种方案得到9种建模结果。测试数据在9个模型上的精度表现,如表4所示。
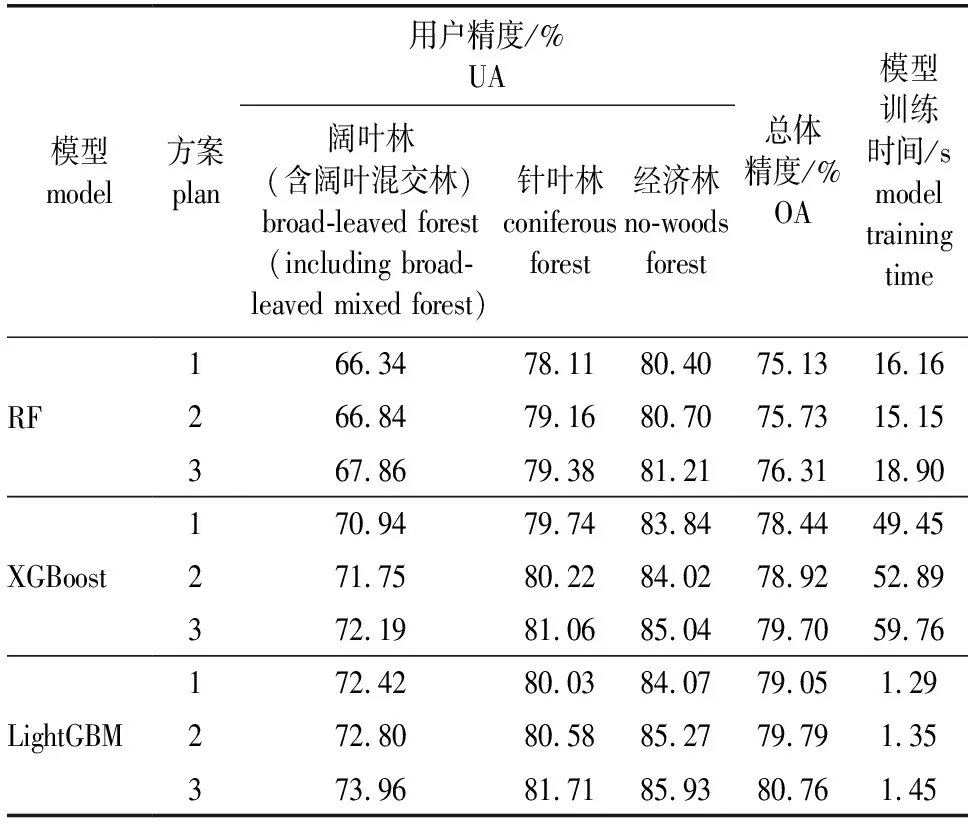
表4 基于3种自变量组合方案及3种算法模型的精度比较
对比表4中的9个实验方案的总体精度,可以发现,LightGBM模型方案3的结果最优,其总体精度达到了80.76%,且计算所需的时间也远少于RF和XGBoost模型,表现最佳。
基于LightGBM模型方案3,再加入13个不同大小窗口获取的纹理特征(方案4),进一步评价LightGBM模型的精度(如表5所示)。由表5可知:在窗口大小为7×7时,LightGBM-4树种结构的总体识别精度最高,达到了81.43%。

表5 LightGBM方案4的模型识别精度
上述的LightGBM模型方案4的原始自变量集涉及33个因子,为降低模型的复杂度与建模成本,使用RFE将自变量个数由33个降为14个(其中包含了10个光谱特征因子、2个纹理特征因子、2个地形因子、0个二类数据因子),模型总体精度略有下降,由原来的81.43%下降到80.27%,识别结果混淆矩阵如图3所示。
基于RFE和LightGBM-4树种结构识别模型中的特征重要性如图4所示,光谱特征中Band3、Band4、Band6、Band11、Band12波段和B8A_B7、B6_B5、B7_B6光学波段组合因子在模型中贡献度较高。纹理特征中的均值(mean)、二阶段矩(second moment)和地形因子中的坡度(slope)、海拔(elevation)的贡献度也较高。
3.3 林型识别
本研究涉及的林型主要有7类:阔叶混交林、其他硬阔林、山核桃林、杉木林、马尾松林、毛竹林、茶树林。
构建林型识别模型时,特征组合方式使用构建树种结构识别的方案4结合雷达遥感因子。对于纹理特征处理,采用与树种结构识别模型一样的窗口数量及大小(表5)评价纹理特征对模型精度的影响,结果见图5。由图5可知,精度较高的窗口大小为23×23、31×31、35×35、39×39、51×51,其中51×51窗口获取的纹理特征使模型精度最高,识别结果混淆矩阵如图6所示。
由图6可知:毛竹、茶树和山核桃林的识别精度较高,阔叶混交林和其他硬阔林的识别精度都比较低。从混淆矩阵来看,这两类林型有比较大的概率被识别成同一类,难以准确地将它们区分开,从而导致总体识别精度下降。针叶林中的识别结果来看,杉木林的识别效果优于马尾松林。
为了进一步研究雷达遥感数据对林型识别的影响及分析各自变量因子的重要性,基于表4的第4种自变量因子组合方案,分别使用了3种雷达遥感因子及特征选择方案:方案A为未加入雷达遥感因子进行特征选择;方案B为加入雷达遥感因子进行特征选择;方案C为特征选择后加入雷达遥感因子,利用LightGBM模型识别林型,结果见表6。
由表6可知:雷达遥感因子对林型识别精度影响不明显。方案B和方案C的特征重要性如图7所示。由图7可知来自光学遥感和DEM的自变量因子比雷达遥感数据获取的自变量因子对模型的精度影响更大。

表6 基于LightGBM-4及3种雷达遥感因子及特征选择方案的建模精度对比
本研究所使用的林地数据为经过拉依达准则筛选后的50 565条数据,在区分了林地与非林地的基础上,对所有林地数据进行了树种结构识别,识别结果如图8(a)所示。所有林地的树种结构识别完成后,将树种结构细分为更精细的林型,识别结果如图8(b)所示。
由图8可知,本研究采用的方法对于淳安县林型有较好的识别效果,整体精度较高。
本研究同时基于LightGBM模型方案4(表4)及雷达遥感因子,构建一层模型直接对林型进行识别,识别结果如下所示:一层模型使用所有特征进行建模的总体精度为70.99%,RFE后特征建模精度为68.13%,模型训练时间为3.72 s;三层模型使用所有特征进行建模的总体精度为84.51%,RFE后特征建模精度为68.13%,模型训练时间为36.68 s。由模型对比结果可知:一层模型的林型识别结果相较于三层模型(RF-LightGBM-LightGBM)而言精度下降非常明显。这表明,三层模型逐步求精的识别方式比一层模型直接识别有更高的精度。
此外,从实验结果中发现,在林型识别模型中,阔叶混交林与其他硬阔林两种林型区分难度较大,识别精度较低,根据3个光谱特征距离对其进行分析,如图9所示。
林海军等[22]计算了数据间的协方差(马氏距离),获取树种光谱特征之间的相似度,用于确定树种之间差异显著的波段,并剔除差异不显著的波段。在本研究中,通过图9中的3个光谱特征距离的对比可发现,山核桃、毛竹、茶树林的特征距离比其他林型的大,说明了这3种林型与其他林型的光谱特征差异较明显,容易与其他林型区分开,从而获得了较高的识别精度。由于阔叶混交林与其他硬阔林为多种树种混交生长,且研究区域属于丘陵地区,地表起伏变化较为明显,可能导致了“异物同谱”现象的发生,使模型对其识别难度增大。这两种林型的切比雪夫距离仅为15.5,说明两者之间的光谱特征差异非常小,无法找到2个林型间差异显著的波段,这可能是导致两种优势林种识别精度较低的主要原因。
4 讨 论
本研究使用Sentinel-2光学遥感影像提取了光谱特征因子、纹理特征因子,结合Sentinel-1雷达遥感影像提取的后向散射系数与DEM提取的地形因子,进行林型识别模型的构建。经特征选择后,地形因子均保留了下来,可见在本研究中,地形与林型的识别精度有密切的联系。陶江玥等[23]研究中发现,地形因素与树种多样性容易导致光学遥感影像中“异物同谱”现象的发生,影响树种识别的精度。本研究中使用的3个地形因子补充了光学遥感因子的不足,且在模型中的贡献度较高,利于各林型的识别。此外,RFE后得到的特征集合中,绿光、红光、红边波段组合因子以及短波红外对林型识别也起到了重要的作用,这与陈继龙等[24]、张沁雨等[25]和Bolyn等[26]的研究结果相似。
近年来的研究发现,光学遥感影像数据结合雷达遥感影像数据结合可以提高树种识别的精度[27-28]。本研究同样使用了多源遥感数据对林种进行了识别,但雷达遥感自变量因子加入后,并未使模型的精度得到较明显的提升。胥为等[29]使用Sentinel-1雷达遥感影像对沼泽植被进行了提取,通过不同时相的影像提取后向散射系数对比发现,当植被在落叶期时,雷达发射的电磁波更容易穿透冠层,发生二次回波散射。本研究获取雷达遥感影像成像时间为2017年10月18日,部分阔叶树种准备进入冬眠期,叶片开始掉落,C波段SAR可能获取了接近于地表的后向散射系数,各树种之间的后向散射系数值差距变小,从而使4个雷达遥感因子在模型中的贡献度相较于其他特征因子来说不够显著。
本研究针对森林资源小班的林型识别进行研究,取得了较高的识别精度,后续工作可从如下几个方面继续探索和深化:
1)光学遥感影像与雷达遥感影像的成像时间为10月底,叶片变色与掉落使各林型之间的光谱特征与后续散射系数差距变小,后续研究若能获取成像时间为生长季的遥感影像,很有可能进一步提高识别精度。
2)本研究使用的Sentinel系列光学遥感影像的分辨率是10 m级的,下一步研究若能获取更高精度的遥感影像(如1 m级的高分系列遥感影像),也可能更有利于捕捉各种林型尤其是混合优势树种林型间更细微的差别。
3)本研究中纹理特征只使用了13种不同大小的窗口,对不同角度以及不同步长的滑动窗口可以再探究更多种组合,以期获取更丰富的纹理信息,提高模型的精度。实验中所用Sentinel-1雷达遥感影像也包含了丰富的纹理信息,后续实验可以尝试从雷达遥感影像中提取纹理特征因子进行模型构建。
4)本研究使用了4个植被指数和6个光学波段组合因子,在后续的研究中可以尝试使用如绿度植被指数(GVI)、垂直植被指数(PVI)等植被指数。
5)Sentinel-1星载雷达的灵活性较低,后续研究可以通过机载雷达等其他途径获取雷达遥感数据进行实验。
5 结 论
本研究使用3层模型对研究区域内7类林型:山核桃林、阔叶混交林、其他硬阔林、马尾松林、杉木林、毛竹林和茶树林进行了识别,识别精度比单层模型有了明显的提高,本研究结论如下:
1)采用3层模型识别林型,第1层模型使用光谱特征因子对林地与非林地进行识别;第2层模型为树种结构识别模型,以第1层识别结果为林地的数据作为输入,识别3种树种结构,即阔叶林(含阔叶混交林)、针叶林、经济林;第3层模型为林型识别模型,以第2层模型识别的树种结构作为输入,进一步分类林型,特征降维后最终精度为83.21%。本研究还建立了只有一层的林型识别模型,特征降维后的精度仅为68.13%,这表明3层模型能够起到逐步求精的作用,对模型的优化起到了很好的效果。
2)当光谱特征、纹理特征、地形因子、二类数据共同作为自变量时,树种结构的识别精度最高,近红外波段、红边波段、短波红外以及红光和绿光在树种结构和林型识别的过程中起着比较重要的作用。DEM获取的地形因子对模型的贡献度较为明显,说明了研究区域内的林型分布与地形也有密切的关系。
3)对比RF、XGBoost、LightGBM 3个模型的结果发现,LightGBM模型在本研究的大样本数据上表现最佳。
4)使用不同窗口大小下的纹理特征因子参与模型构建,7×7大小窗口获取的纹理特征因子在树种结构识别模型中贡献度最高,而在林型识别模型中,51×51大小窗口获取的纹理特征表现最优。
5)从识别结果的总体精度及特征重要性排序结果均表明,雷达遥感因子对小班林型的识别影响并不明显。
