生物医学数据匿名化工具ARX 研究及启示
2022-11-18唐明坤张丽鑫周佳茵吴思竹
唐明坤,钱 庆,张丽鑫,周佳茵,吴思竹
随着大数据和医疗信息化建设的发展,数据共享成为大数据利用和学术研究过程中的重要环节,数据安全问题也受到越来越多的关注。2017 年国务院发布的《“十三五”卫生与健康规划》提到,我国要全面深化医疗大数据的应用,加强医疗数据保护和患者隐私保护,推动医疗信息化的建设[1]。随后我国陆续出台了《中华人民共和国网络安全法》《中华人民共和国数据安全法》《中华人民共和国个人信息保护法》《网络数据安全管理条例(征求意见稿)》等数据安全相关的法律或规定,反复强调了数据生命周期流程中数据安全和隐私保护的重要性。数据的共享和发布是数据生命周期中最容易出现隐私泄露的环节,然而单纯地删去数据集中的标识符并不能保证数据隐私安全。如美国马萨诸塞州曾发布过删除患者姓名和地址的医疗信息数据库,仅保留性别、出生日期、诊断结果等信息,但攻击者通过结合另一个具有性别、出生日期等信息的州选民登记表,锁定了大部分选民的医疗健康信息,从而造成了严重的医疗信息泄露事故[2]。因此数据共享和发布不能只是简单地删除数据集中的标识符,还需要结合其他隐私保护技术对数据集进行处理。
目前常用的隐私保护技术主要包括数据匿名化发布技术、数据加密技术、隐私保护数据挖掘技术和数据访问控制技术4 类[3]。其中,数据匿名化发布技术即统计披露控制相关技术,是最基本和核心的隐私保护技术,其核心思想是在数据共享或发布前对数据集进行处理,防止敏感信息泄露的同时确保数据能够用于分析挖掘[4]。随着数据匿名化发布技术的发展,陆续出现了k-Anonymity[2]、l-Diversity[5]、t-Closeness[6]等隐私模型。这些隐私模型的算法逐渐复杂,随着数据量的增加,匿名化转换的计算量也逐渐增大,因此需要集合到可靠、可拓展的工具中才能实现基于隐私模型的匿名化转换的操作。近年来,国外多家机构和单位的研究人员在这些隐私模型的基础上开发了多款开源数据匿名化工具,如ARX 匿名化工具、UTD匿名化工具箱、康奈尔匿名化工具包(CAT)、R统计软件开源包sdcMicro 等[7]。对国外成熟的匿名化工具进行研究可以为开发适用于我国实际需求的数据匿名化工具提供很好的借鉴。因此,本文针对生物医学领域的数据匿名化处理需求,重点研究了目前发展最成熟的生物医学数据匿名化工具ARX 的组成结构和功能特点,为我国匿名化工具的研发和数据共享技术的发展提供参考。
1 ARX 工具概述
ARX 工具是由慕尼黑工业大学的Fabian Prasser团队在2011 年开发的一款拥有易操作的用户图形界面的开源可拓展的数据匿名化工具。Fabian Prasser 团队长期专注于数据匿名化研究,研究内容包括统计披露控制、隐私模型、匿名化数据效用评价等[8-12]。ARX 工具的设计特别关注了生物医学领域数据匿名化的需求,但同时也适合其他领域数据的应用。2015 年发布的ARX 工具2.2.0 版本已经具备了丰富的隐私模型支持、匿名化数据效用评估及重识别风险评估等主要功能。2016 年,ARX 工具还成为了欧洲药品管理局临床数据发布政策的数据匿名化和风险评估推荐工具[13]。随后,ARX 工具经过不断的更新,又增加了基于统计模型的匿名化方法[14]、基于博弈论的隐私模型[15]、差分隐私模型[16]等功能。由于出色的效用评估功能、重识别风险评估功能及能处理数百万条记录并支持丰富的隐私模型的特点,ARX 工具被广泛应用于各领域的数据匿名化研究,包括开放政府数据的匿名化技术应用[17]、实现医疗信息数据库匿名化策略方案[18]等。有学者在进行医疗领域数据匿名化现状研究时发现,与其他工具相比,ARX 工具的功能更丰富全面,支持的隐私模型数量也遥遥领先[19]。目前,ARX 工具还在持续更新中,隐私模型和相关功能也在进一步丰富。
2 ARX 工具的整体架构和工作流程
2.1 ARX 工具的整体架构
本文使用2021 年1 月10 日发布的ARX 3.9.0 Windows 64-Bit 版本(https://arx.deidentifier.org/downloads/)。ARX 工具具有友好的图形用户界面,操作界面与各功能模块紧密连接。本文通过对各个功能模块的分析,总结了ARX 工具整体架构图(图1)。从功能上进行归纳,ARX 工具的整体架构可以分为数据导入导出模块、数据处理模块、隐私模型及其他参数模块、匿名化方案探索模块、效用分析及风险分析模块。其中,隐私模型及其他参数模块、效用分析及风险分析模块具有很高的可拓展性,在历次版本更新中,这些模块功能得到不断强化。
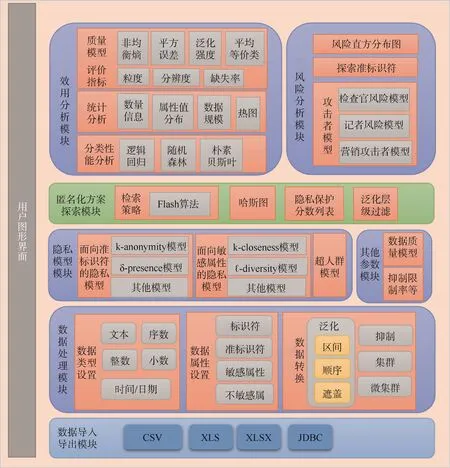
图1 ARX 工具的整体架构
2.1.1 数据导入导出模块
ARX 工具主要支持结构化数据的匿名化处理,其数据导入导出模块目前支持CSV、XLS、XLSX、JDBC 等多种格式的数据的导入,但经过匿名化处理后的数据仅可以保存输出为CSV 格式。
2.1.2 数据处理模块
导入ARX 工具的数据需要在数据处理模块进行数据类型设置、数据属性设置及数据转换,这是获得匿名化方案的前提。数据类型设置根据每列数据的格式特点决定。数据属性设置则需要研究者根据每个属性与个体身份的关系进行设置。数据属性共分为标识符、准标识符、敏感属性和不敏感属性4 类。标识符是指能直接确定个体身份的属性,如姓名、身份证号等;准标识符是指在一定的背景知识下,能够通过该属性或属性组合确定个体身份的属性,如年龄、性别、身高等;敏感属性是指想保护的、涉及个体隐私信息的属性,如疾病、家族史等;不敏感属性是与隐私无关的属性。标识符和准标识符是匿名化处理过程中的重点关注对象,也是数据转换的处理对象。标识符直接暴露了个体身份,需要进行完全的信息删除即抑制处理。准标识符间接暴露了个体身份,需要进行泛化、集群等转换,将暴露的风险降低到符合隐私保护要求的水平。泛化是数据转换最常用的方式,是指创建多个范围更广的层级的数据值来替代原数据值,如用区间值[18,28]替代年龄值18。匿名化处理的过程需要通过算法实现,泛化可以根据不同的算法处理进一步分为全域泛化和局域泛化,前者是指在一个准标识符中所有值采取同一泛化层级,后者则是允许一个准标识符中存在不同泛化层级的值。
2.1.3 隐私模型及其他参数模块
泛化层级的创建是隐私模型实现的基础。在ARX 工具中,匿名化处理的过程是通过筛选出准标识符泛化层级组合方案中所有满足隐私模型和相关参数要求的方案,并形成一个隐私保护效果最佳的推荐方案的过程。根据隐私模型对生成数据的要求,可以将其分为面向准标识符的隐私模型、面向敏感属性的隐私模型及超人群模型等。多种隐私模型和相关参数可以组合使用,但是隐私模型越严格,准标识符的值会被泛化到更高的层级,虽然隐私信息能够得到更好保护,却会降低数据质量,影响数据分析质量。因此,需要结合数据处理和使用需求选择合适的隐私模型和相关参数,以获得最佳的结果。
2.1.4 匿名化方案探索模块
ARX 工具形成隐私保护效果最佳的推荐方案的过程是通过Flash 检索算法实现的。当该方案不能满足需要时,可在匿名化方案探索模块提供的泛化层级组合方案集合中探索新的匿名化方案。在该模块中,ARX 工具提供的哈斯图和隐私保护分数列表分别展示了所有满足隐私模型和相关参数的匿名化方案。研究者可以通过泛化层级过滤,保留自己所需要的重要信息。假如年龄是研究所需要的重要属性,在探索模块中指定年龄的泛化层级为0,那么最终筛选出的泛化方案均为保留原始年龄数据的方案,保证了重要属性信息的留存。
2.1.5 效用分析及风险分析模块
效用分析及风险分析模块提供了多个维度的指标衡量输出数据的数据质量和重识别风险。ARX工具关注的重点是输入数据和输出数据之间的质量变化,提供输入和输出数据的差异分析对比和展示。效用分析包含质量模型评价指标、统计分析和分类性能分析3 个部分,分析内容围绕着匿名化处理前后数据的分布、属性相关关系、数据规模、数据包含信息的缺失等变化评价数据的质量;风险分析模块则主要包含风险直方分布图、准标识符探索和攻击者模型3 个部分,分析内容围绕匿名化处理后的数据的重识别风险,即攻击者基于背景知识从共享发布的数据中确定个体身份的危险。
2.2 ARX 工具的工作流程
ARX 工具进行数据匿名化流程设计时考虑较为全面,包括数据输入、数据处理(属性设置、泛化层级创建、模型和参数的选择)、匿名化方案探索及效用和重识别风险评价等步骤,考虑了数据处理的评估和反馈。图2 展示的是ARX 工具从导入数据到生成并输出匿名化数据的工作流程,具体分为5 个步骤。同时,本文以UCI Machine Learning Repository 中的Adult 数据集进行k=5 的k-anonymity匿名化处理为例,对各个步骤进行介绍。
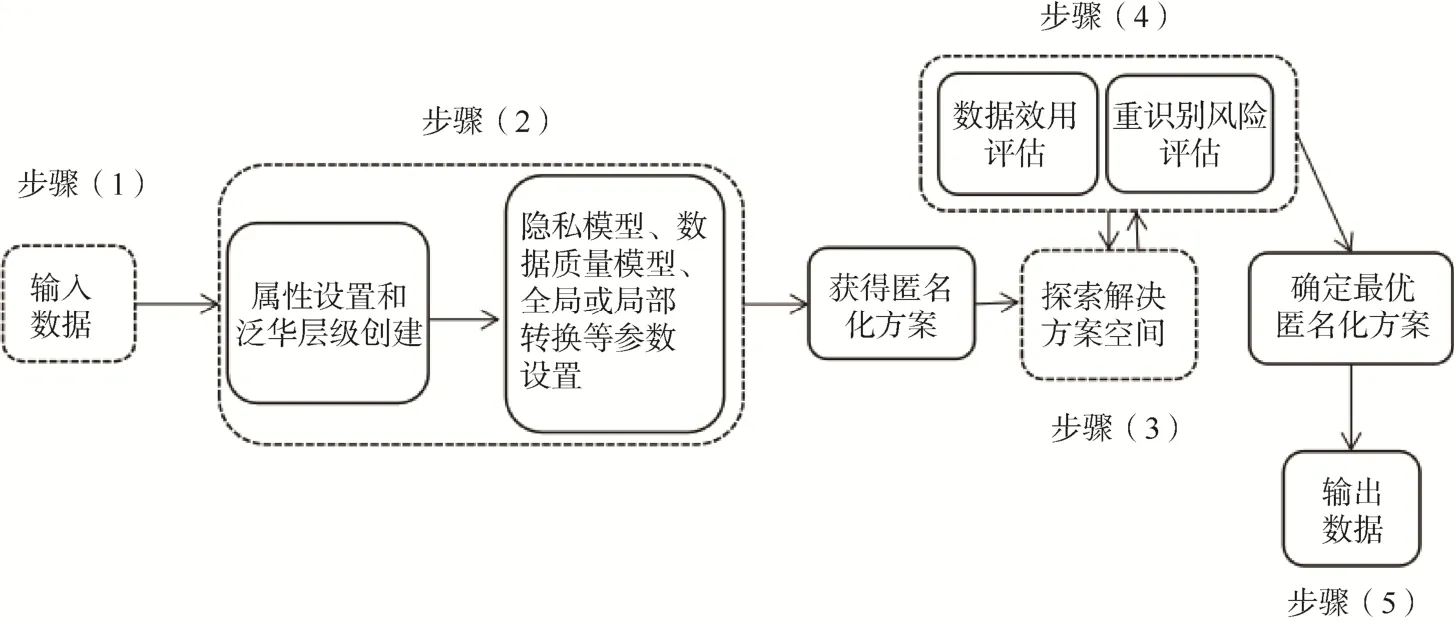
图2 ARX 工具进行数据匿名化处理的工作流程
2.2.1 数据输入
数据输入是匿名化处理的第一个步骤。在ARX 工具中,需要先创建一个项目,然后再把结构化的Adult 数据集导入,如图3 左半部分所示,数据集以表格的形式在工具中展现。
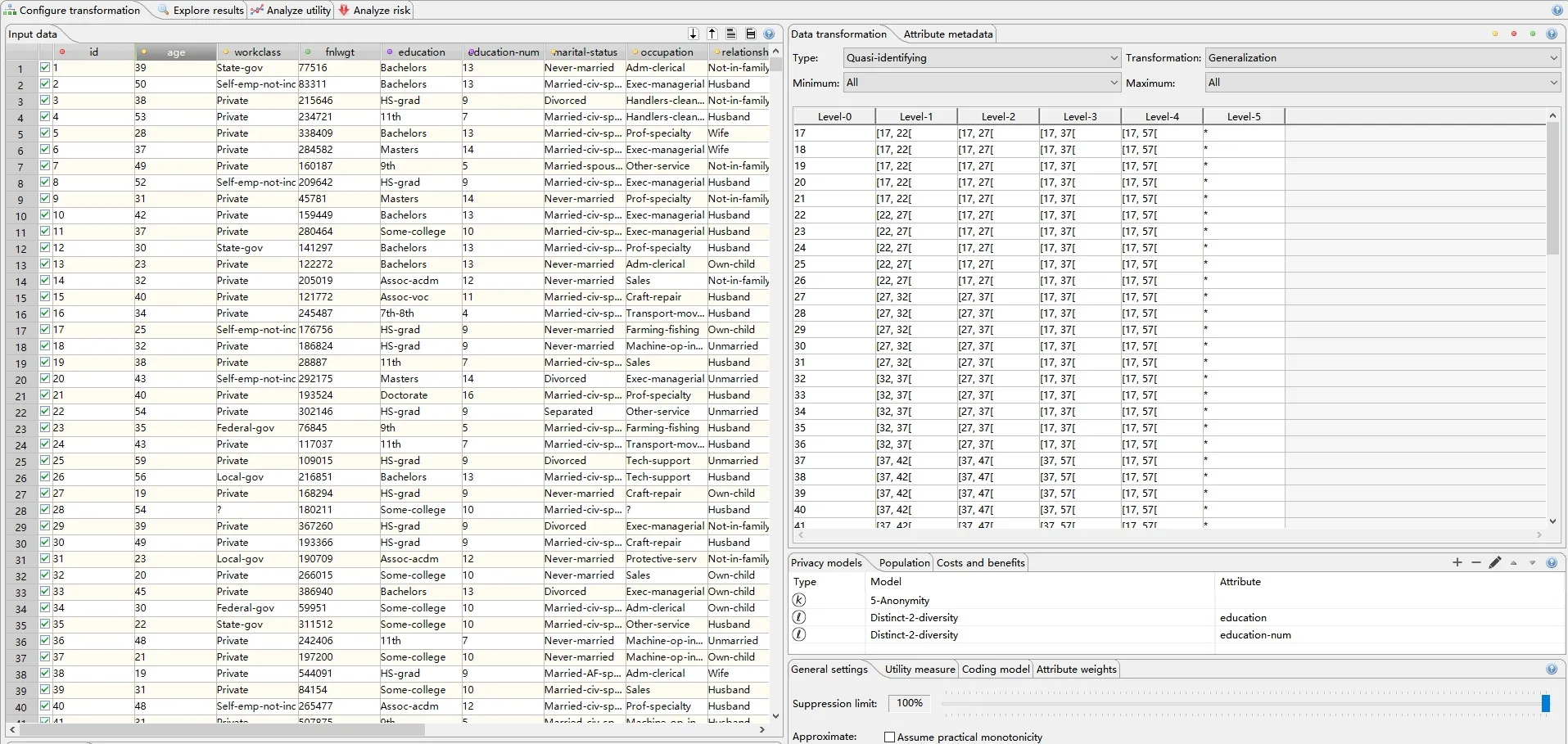
图3 ARX 的工作界面
2.2.2 数据处理
输入的Adult 数据集需要进行属性的设置、泛化层次的创建及模型和参数的选择。属性设置需要研究者根据领域知识将所有属性中的标识符、准标识符、敏感属性标记出来,如本文将id 设为标识符,将年龄、性别、种族等属性设为准标识符,将教育年限、收入作为敏感属性。然后,准标识符需要创建相应的泛化层级来保证隐私模型的实现。ARX 工具提供了4 种系统定义的泛化方法用于快速创建泛化层级方案,包括时间泛化、区间泛化、顺序泛化及遮盖泛化。对诸如年龄等数值类型的准标识符采用区间泛化的方法,以5 为间隔区间范围创建泛化层级方案;对诸如种族等标量类型的准标识符首先考虑语义关系创建泛化层级方案并导入使用,当准标识符没有语义层级概念时,考察数据的特点使用顺序泛化或遮盖泛化创建泛化层级方案。在隐私模型选择方面,本文选择k-anonymity 模型,k 值设置为5;两个敏感属性均选择参数为2 的ℓ-diversity 模型。在相关参数设置方面,最大抑制率设置为推荐的100%,其他相关参数使用默认值。经过上述处理后,选择实现隐私模型的默认最优算法检索策略,ARX 工具就会自动计算出所有符合隐私模型要求的泛化层级的组合方案,并生成一个最优推荐方案。图4 为ARX 工具匿名化解决方案空间,每一个节点代表一种准标识符泛化层级组合,黄色方形的节点为最优推荐方案,节点中的数字代表准标识符的泛化层级。
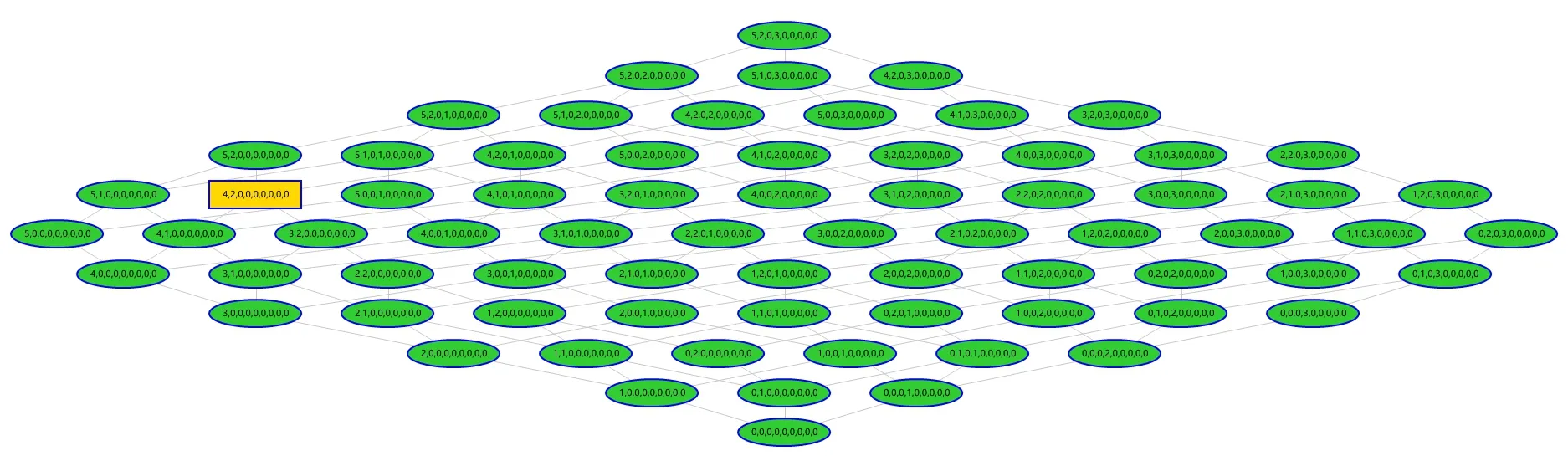
图4 ARX 工具匿名化解决方案空间
2.2.3 匿名化方案探索
ARX 工具生成的最优推荐方案是满足隐私模型和相关参数标准下的最佳方案,但该方案不一定能满足实际情况中对某准标识符泛化层级及数据效用指标的要求。如果选择保留年龄准标识符的最大信息,在匿名化解决方案空间中把年龄的泛化层级限制为0,可以在维持年龄不泛化的基础上调整最佳匿名化方案。
2.2.4 效用和重识别风险评价
生物医学领域对数据质量具有较高的要求,因此需要对匿名化方案进行效用和重识别风险评价以确保输出数据的质量。在该步骤中,ARX 工具会自动给出匿名化方案的数据值缺失率、粒度及非均衡熵等衡量数据质量的指标和风险直方分布图、检察官模型风险等重识别风险评价内容。当该方案满足数据效用和重识别风险的要求时,则可确定为匿名化最优方案并输出,否则需要进行新方案的探索。
2.2.5 数据输出
当匿名化方案满足效用和重识别风险后,通过数据效用评价模块对输出数据进行预览,确认无误后以结构化的CSV 格式输出数据。
3 ARX 工具的功能特点及局限性
3.1 ARX 工具的功能特点
ARX 工具功能丰富全面,支持匿名化处理的全流程。与UTD 匿名化工具箱、sdcMicro、CAT等其他数据匿名化工具相比,ARX 具有采用高效的全域匿名化算法、支持丰富的隐私模型、较为全面的数据效用评价指标、较为丰富的风险分析功能等4 个功能特点。ARX 工具的历次更新也多是在围绕增加更多的隐私模型和效用评价指标方面进行的。ARX 工具与其他匿名化工具具体的功能特点比较如表1 所示。

表1 ARX 工具与其他匿名化工具的功能特点比较
3.1.1 高效的全域匿名化算法
ARX 工具支持全域匿名化处理和局域匿名化处理。在全域匿名化处理中,支持多种高效稳定的Flash 算法及变体是ARX 工具的一个重要特点。UTD 匿名化工具箱支持Datafly、Incognito 等算法实现k-anonymity 等匿名化处理,CAT 支持Incognito算法[20]实现匿名化处理,而sdcMicro 则提供多种自底向上和自顶向下的全域匿名化算法和10 余种局域匿名化算法[21]。与这些算法相比,Flash 算法使用预测标记的方法,采用垂直遍历匿名化解决方案空间的策略,剪枝能力和执行时间要优于Incognito 等其他算法,算法稳定性较强,能够实现数据集的快速全域匿名化处理。目前,ARX 工具还加入了对遗传算法的支持,显著提高了对高维数据的处理能力。
3.1.2 丰富的隐私模型
相比于UTD 匿名化工具箱、sdcMicro、CAT等其他匿名化工具仅支持2~3 种隐私模型,ARX工具支持的隐私模型高达10 余种,是目前支持隐私模型数量最多的数据匿名化工具。表2 是对各隐私模型相关研究的总结。根据隐私模型计算原理的不同,面向对象主要包括准标识符和敏感属性。k-anonymity、k-map 等隐私模型面向对象为准标识符,是较为常用的隐私模型,这些模型主要通过泛化和抑制等手段增加准标识符中等价类(即准标识符值相同的记录)的数目,减少唯一记录,从而降低重识别风险;ℓ-diversity、t-closeness 等隐私模型主要面向敏感属性,因为尽管等价类数目增多保证了唯一记录的减少,但如果同一等价类记录对应的敏感属性值都相同时会导致一致性攻击,容易使个体的敏感属性信息被发现。因此,还需要保证敏感属性的分布具有多样性,从不同算法的层面上要求相同等价类记录的敏感属性下至少要存在一定阈值数量不同的值。此外,k-map、δ-presence 等隐私模型考虑到了种群唯一性的再识别风险,使用时还需要获得人群信息作为参数,而ARX 工具也内置了美国等国家的人口数量供参考;Profitability 模型基于博弈论进行成本效益分析,可以更明确地解释数据发布者和接收者的动机,但需要获取攻击者成本和收益等参数;Average-reidentification-risk 模型则通过设置重识别风险阈值,获得满足重识别风险要求的匿名化方案。

表2 ARX 工具支持的主要隐私模型及其原理
3.1.3 数据效用评估
从生物医学研究需求的不同角度衡量匿名化数据的质量,会获得不同的结果。为此,ARX 工具提供了一系列的质量评估指标和数据质量模型对匿名化数据进行效用评估,供使用者从多个角度评估匿名化处理导致的信息丢失情况。在ARX 工具中,质量评估指标分为属性级别的质量评估指标和数据集级别的质量评估指标。前者包含缺失率、泛化强度、粒度、非均衡熵和平方误差等指标,后者包含泛化强度、粒度、非均衡熵、平方误差和平均等价类大小等指标。ARX 工具提供的部分质量评估指标的具体含义如表3 所示。

表3 ARX 工具提供的部分质量评估指标
数据质量模型用于优化匿名化处理的目标函数,不同的数据质量模型侧重考虑不同的评价指标,如粒度、泛化强度等,从而影响最终生成的匿名化数据。如在参数配置阶段选择了侧重匿名化数据平均等价类大小的模型(AECS 模型)时,最终生成的匿名化数据是具有平均等价类大小更优的匿名化方案。质量评估指标众多,ARX 工具中也内置了丰富的数据质量模型可供选择,包括Loss模型、AECS 模型、Precision 模型、Discernibility模型和Non-Uniform Entropy 模型等。
ARX 工具还提供了逻辑回归、随机森林和朴素贝叶斯等算法对输入数据和输出数据的分类性能进行比较。研究结果显示,选择了Discernibility模型、Precision 模型和Non-Uniform Entropy 模型的输出数据具有较好的分类模型训练能力,测量结果的相对准确度为94%~99%,因此具有无监督学习研究需求的数据应优先选择这几类数据质量模型进行匿名化处理[22]。
3.1.4 风险分析功能
风险分析主要是指对输出数据的重识别风险的评估、ARX 工具中提供了攻击风险模型分析、风险分布直方图和发现准标记符等功能。
3.1.4.1 攻击风险模型分析
攻击风险模型分析包括对检察官风险模型、记者风险模型和营销攻击者风险模型3 种模型风险的分析。检察官风险和记者风险是数据集隐私风险两个基础的重识别风险度量方法,都是衡量攻击者从数据集中锁定目标个体的数据的风险。二者的区别在于对手能否知道某个特定的个体是否在数据集中。如果攻击者能知道目标是否在数据集内,则是所谓的“检察官风险”;如果攻击者不知道或不能知道目标是否在数据集中,则被称为“记者风险”。由于不能事先确定攻击者掌握的背景知识,因此无法得出一个固定的检察官风险值或记者风险值。使用者可以在ARX 工具中设置风险阈值,工具将自动计算超过阈值风险的记录比例、平均能被重识别的记录比例和单个记录最高重识别风险。营销攻击者风险模型则是以重新识别数据集中的大部分个体为目标,而不是特定个体为目标来计算重识别风险。
3.1.4.2 风险分布直方图
风险分布直方图是数据集记录中重识别风险分布的直方图,它是以检察官重识别风险作为横坐标,受影响记录百分比为纵坐标,可以直观地看到有多少数量的记录的检察官风险小于某一个值。通过对比输入输出数据的风险分布直方图可以发现检察官重识别风险与受影响记录的变化。ARX 工具可以直观地对比输入输出数据风险直方分布图的变化。一般而言,经过了匿名化处理的数据集的最大重识别风险和平均重识别风险都将明显下降。
3.1.4.3 发现准标记符功能
发现准标记符功能是指通过分析单个属性或多个属性组合的重识别风险,发现其中的准标识符。ARX 工具提供了所有的属性组合(包括不敏感属性)的重新识别相关风险的值。当这些值较高甚至达到100%时,则需要考虑相应属性组合中是否存在未发现的准标识符。
3.2 应用局限
ARX 工具是面向结构化数据集设计的开源匿名化工具,研究者可以脱机使用,能保障处理过程中的数据安全。该工具应用功能丰富全面,适用于高维大规模的结构化数据集。但该工具在真实世界生物医学数据匿名化的应用中,还存在以下3 个问题。一是真实世界生物医学数据集中存在许多非结构化数据,但ARX 工具仅适用于结构化数据集的匿名化;二是当数据集存在的缺失值较多时,需要对数据集进行预处理,因为ARX 工具的匿名化处理过程缺乏对缺失值的考虑,当缺失值较多时会导致过度泛化而造成较多的信息损失;三是不太适合小规模数据集匿名化处理的应用,因为小规模的数据集处理成本较低,往往采用局域匿名化的方法保留更细颗粒度的信息,而该工具提供的局域匿名化算法较少,它使用的Flash 算法的匿名化处理能力虽然高效稳定,但在保留数据信息的能力方面不如局域匿名化算法。
4 对我国数据匿名化工具研发的启示
目前,我国生物医学领域有大量的数据匿名化需求,但却缺乏可靠的开源数据匿名化工具。ARX工具作为一款在国际上被广泛应用的开源数据匿名化工具,具有高效的全域匿名化算法、丰富的隐私模型、数据效用分析和风险分析功能,为我国数据匿名化工具的研发提供了很好的启示。
4.1 完善匿名化处理流程,加强数据效用和风险评价
生物医学数据匿名化工具的研发比较重视数据匿名化处理算法模型研究,而容易忽视数据处理结果的可用性和风险评估。首先,过度的匿名化处理会导致过多的信息丢失,在开展临床科学研究时,容易引起假阴性研究结果的出现。其次,数据匿名化处理后,由于处理粒度不足,或通过与其他数据关联,也存在个人信息被重识别的风险。ARX工具较好地考虑了数据匿名化处理的全链条,不仅提供了众多可选择的隐私模型,而且在效用评估和风险评价方面提供了较为丰富的评价指标和参数。因此,我国生物医学数据匿名化工具研发时可以借鉴它,完善数据匿名化处理全流程,完善效用评估和风险评价功能。结合不同生物医学数据的实际应用场景(如科学研究、临床应用、跨域共享等),建立完善多维度数据效用评价和风险评价指标及技术方法,形成对匿名化处理方法和工具处理有效性的评估和及时反馈闭环,探索实现隐私保护和数据利用的相对平衡,提高工具匿名化处理的效果和能力。
4.2 结合敏感数据特征,支持多类型可扩展隐私模型
中文生物医学数据来源广泛,包括基础调查、临床、实验室等多种来源,具有数据量大、关联性强、类型多样(如数值、时间/日期、字符等)等特点。不同来源和不同数据类型的匿名化处理需要使用合适的隐私模型和相关参数才能取得理想的匿名化处理结果。ARX 工具支持k-anonymity、ℓ-diversity、t-closeness 等10 余种隐私模型和多种隐私参数设置,虽然有一部分的改进模型并未得到支持,但目前已经能够满足大多数研究的数据匿名化处理需求。在我国数据匿名化工具的研发过程中,应不断研究和丰富工具所能支持的隐私模型,包括面向准标识符的隐私模型、面向敏感属性的隐私模型和考虑人群唯一性的隐私模型等。同时还要保证工具的可拓展性,使工具可以随着隐私模型的研究改进不断进行更新迭代,从而满足更广泛的研究需求,并得到更优的匿名化处理结果,从而提高研究效率。此外,ARX 工具实现隐私模型的算法主要集中在全域匿名化算法方面,提供的局域匿名化算法较少,减少泛化造成的信息损失的能力较弱。因此,在研发我国数据匿名化工具时,还需要拓展对局域匿名化算法的支持,使匿名化工具的应用场景更加丰富和全面。
4.3 利用自然语言技术,加强非结构化数据处理能力
ARX 工具主要是针对结构化数据的匿名化处理,虽然对结构化数据提供了丰富的匿名化处理功能,但是缺乏对文本等非结构化数据的处理功能。而生物医学领域中存在大量的非结构化数据,需要对散落在非结构化文本中的敏感信息进行识别和处理,如电子病历数据中的现病史、既往史、主诉等部分的非结构化文本描述。特别是中文数据中的专业术语、分词和表达与英文数据存在较大差异,需要予以关注。敏感数据类型和特征识别也要结合国内外发布的相关法律、法规和政策中对敏感数据或信息的范围和类型的要求进行及时更新和补充。因此,在研发我国生物医学数据匿名化工具时,还需要结合自然语言处理、深度学习、图像识别等技术,自动和半自动提取和识别电子病历数据现病史中的准标识符和敏感属性,并提供数据审查,支持泛化等匿名化处理功能进行数据处理,从而实现敏感信息的保护。
4.4 实现人性化功能设计,提高工具易用性和可理解性
ARX 工具丰富的隐私模型和可自定义的参数设置,能够满足面向多种需求的数据处理需要,但同时,这种灵活性需要研究者了解隐私模型和掌握一定的数据匿名处理相关专业知识,对研究者使用该工具有一定门槛。而要达到较好的数据处理效果,也的确需要结合数据集特点和匿名化转换目的调整和优化数据匿名化处理方案,才能获得较好的数据匿名化处理结果。因此,在研发我国生物医学数据匿名化工具时,需要着重考虑用户的应用场景,提供快捷、易用的应用入口,加强工具使用的指导性和引导性。另外,还需要增强工具的人性化设计,结合用户使用习惯设计工具功能和流程,采用用户可理解的方式描述并进行提示和说明,提供一键式自动化和分步检查等不同运行方式满足用户需求。
此外,ARX 工具数据处理规模较大,适用范围较广,这也是许多研究者选择使用ARX 工具进行数据匿名化处理的原因。随着生物医学研究数据规模的不断增长,对数据匿名化工具的数据处理能力要求也在不断增加,因此在工具研发时还需要在此基础上继续拓展,达到更大规模的数据处理能力,保障工具的实用性。
5 结语
我国的数据匿名化工具的研发还处于探索阶段。本文剖析了具有代表性的匿名化工具ARX 的功能架构,以Adult 数据集的匿名化处理为例介绍了ARX 工具的应用流程。通过与其他匿名化工具的比较,本文归纳了ARX 工具的功能特点和不足之处,总结了隐私模型的原理、匿名化数据评价指标和重识别风险评估的内涵,并在此基础上提出了我国数据匿名化工具研发时需要重点关注的内容。但因为篇幅的限制,本文也存在一定的不足,如未深入分析ARX 工具各隐私模型和功能指标的具体适用场景,对我国数据匿名化工具的研发仅提供了方向上的指导等。后续的研究中,可以增加场景化的研究,为数据匿名化工具的研发提供更全面、更具体的指导。
