基于颜色通道的车牌定位算法研究
2022-11-17陈大龙魏东迎
陈大龙 魏东迎 孟 维
南京华苏科技有限公司
0 引言
随着近几年计算机视觉技术的飞速发展,深度学习技术在各个领域获得了不错的成绩和试验成果,特别是在语音识别和图像识别领域,所以深度学习开始越来越多的应用到实际的行业中。传统图像检测算法相对深度学习而言,在目前很多的图像识别领域没有优势可言,然而在一些传统行业,传统图像算法却是深度学习无法替代和比拟的,例如工业检测、视觉尺寸测量等。传统算法相对与深度学习不需要大量的样本,针对不同的检测需求可以快速做出调整等优点,目前仍然应用在很多领域中。由于汽车车牌其具有一定的规范性,使用传统算法可以很好地提取其特征量从而进行快速的检测。
针对车牌的检测传统图像算法的处理流程基本上是:首先进行图像处理获得单通道图像,然后对单通道图像进行二值化处理,最后对二值图进行区域提取分析确定车牌区域。在处理的过程中,二值化处理往往是研究的重点和难点,因为其结果决定车牌区域是否可以有效地被表示出来。但二值化的弊端也是显而易见的,高于车牌灰度值的区域也会被保留甚至和车牌连为一体。本文针对车牌二值化存在的问题,采用Kmeans结合灰度直方图的方法对区域进行分割从而替代一般的二值化处理的方式,以提高对车牌区域的有效分割。对于获取的预处理单通道图,本文充分利用车牌颜色的特性,经过彩色通道的处理获得有效的单通道图,从而提高图像的区域分割正确率。对于分割后的区域,采用SVM的方法对本文新设计的特征向量进行区分,从而最终获得车牌区域完成定位。
1 研究现状
车牌识别系统是一种比较成熟的图像识别智能设备,目前已经大量应用于停车场、交通管理、电子收费、车辆追踪等领域。通常车牌检测系统一般采用传统的图像处理算法进行车牌的提取和识别,现有较为常用的车牌定位方法主要有三种:一是基于车牌颜色特征的方法;二是基于边缘检测的方法;三是基于adaboost结合haar特征检测的方法。方法一较为简单、易于实现,但鲁棒性不够好,受光照、车牌磨损等因素影响很大,并且在车身颜色和车牌颜色较为相近时定位区域容易出错;方法二定位较为准确,但在复杂场景中虚警率较高;方法三在单独使用时很难把车牌区域完成地检测出来且虚警率较高。
随着深度学习网络的兴起,目前的车牌系统研究绝大多数开始集中于深度学习领域。通过对各种不用模型网络结构的修改和优化,或者训练数据集的多样性和增强等处理,以达到提高检测效率的目的,常见的有YoLo、SSD等网络的各种变形。但是深度学习往往需要大量的数据进行训练,且存在不可预测性。由于其端到端的属性,所以当模型出现一定的检测能力退化的时候,重新训练需要大量的时间和数据集,因此存在了一定的不便性且深度学习往往需要GPU作为算力支撑,造成了高昂的成本。为了实现快速检测定位和实际部署以及实用性,本文提出了基于传统图像处理的一种新的检测方法,从而实现车牌在复杂环境下的快速定位和提取。
2 测试数据
为了充分验证算法的实用性和适用性,本文中所用的数据集全部来自于真实环境拍摄。为了最大程度的体现车牌检测的使用环境,对于车牌数据分别在不同路段,不同天气环境下进行了采集,以此来保证数据的多样性和实用性。
数据集均为人工采集,在充分考虑数据多样性的情况下,一共采集到有效图像1800张,黄色、绿色、蓝色车牌各600张,其中每个车牌在光照环境、拍摄角度、视距远近三种条件下各200张图像。图像数据在满足多样性的情况下,也考虑了数据的均衡性问题,因此三种车牌采集的图像具有一定的普适性和合理性。
3 算法流程
3.1 图像彩色通道处理
为了有效地凸显车牌信息,针对车牌具有固定颜色的特点,本文分析了不同车牌在不同颜色通道下的表现形式,本文仅以黄色车牌作为样例展示,分别对比分析了RGB图像转为Lab、Luv、YCrCb形式下的各通道图像效果。
针对黄色车牌而言,在Lab,Luv色彩模式b通道下黄色表现为灰度值较低,在YCrCb色彩模式的Cb通道下,黄色表现为灰度值较大,针对这种情况本文将Cb通道和b通道做差取得需要检测的单通道图S,具体处理公式如下所示:
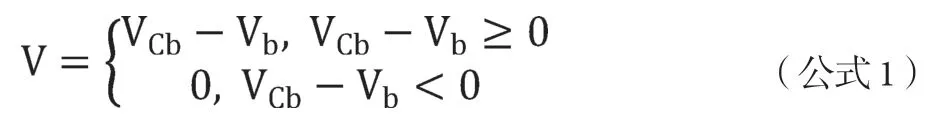
对于公式1,其中VCb,Vb分别代表Cb通道和v通道图像对应点的灰度值,V代表做差后产生的新的单通道差值图S对应像素点的灰度值。其具体效果和原图的灰度图如图1所示。

图1 单通道差值图和原图灰度图
通过彩色通道的预处理得到的灰度差值图相较于原图的灰度图而言,光照和其他颜色的影响都得到了相对的弱化,黄色车牌在差值图中更好地凸显了出来,而且和其相近区域颜色具有明显的灰度值区分,这对于区域的分割具有良好的效果。所以采用彩色通道处理后的单通道图,具有良好的区分度和一定抗干扰性。
3.2 自适应Kmeans区域分割
K-means的定义:k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是,预将数据分为K组,则随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
对于预处理获得的单通道差分图,常用的方法是使用不同的阈值处理获得二值图像,常用的有固定阈值化处理、区域自适应阈值化处理、类间方差最大化阈值处理等方法。对于目标明显且目标明显灰度高或者低的时候,阈值处理不失为一种有效快速的方法。但是本文针对的检测环境较为复杂,在检测目标即车牌附近可能出现灰度值相近的情况,以及灰度值比车牌灰度值大或者小的区域,这种情况会造成区域的连接,如图2所示。

图2 不同二值化方法效果图
根据不同二值化方法的效果可知,固定阈值虽然有时会取得较理想的效果,但是其固定阈值的缺点导致根本无法应用于本文检测环境的问题,而区域自适应和类间方差最大算法的结果明显不太理想。所以为了提高对车牌的区域的有效提取,本文将Kmeans和图像的灰度直方图特征相结合,提出了一种新的有效检测方法。
对于检测的图像首先计算灰度直方图,继续以上一节的单通道差值图为例,其灰度直方图的折线图如图3所示。
第四,分销渠道延伸性较弱,忽视促销策略。直接渠道模式,是南通鹏越纺织有限公司的主要分销模式,但这在一定程度上制约了企业的发展,且对竞争对手的了解相对落后。且在促销实践中,推销人员不足,推销力度广度都不够,新客户群体的获得都会受到不同程度的影响。
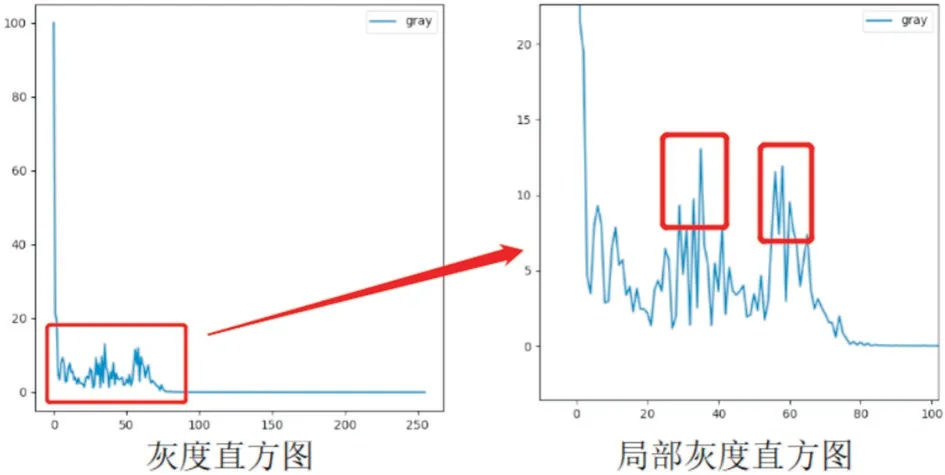
图3 灰度直方图
从总体灰度直方图和局部灰度直方图折线图可以看到,图像在最左侧有一个大波峰,在局部直方图内有两个明显的大波峰。对于灰度直方图来说,每一个波峰意味着图像上像素值的出现次数频数,而通道差值图中的灰度值不同区域也就对应着不同的波峰区域。因此准确提取波峰的个数,并以此作为区域分类的类别数对图像的灰度值进行分类,可以有效地分类灰度值从而达到区域分割的目的。对于波峰的提取,将灰度直方图表示为数列如下式所示:
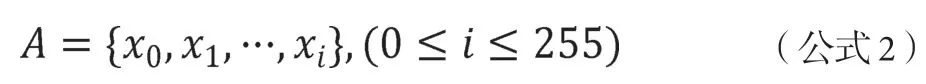
其中A为波峰像素值集合,为对应i灰度值时的数值,i为像素的灰度值,范围为[0,255]的整数。对公式2,按下式计算得到波峰数列 B,如下式3所示:
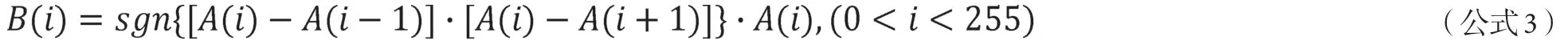
其中B(i)为得到的波峰序列,i为像素灰度值,范围为(0,255)的整数。
对于得到的波峰序列便是灰度直方图的所有波峰,但是根据实际情况考虑并不是所有波峰都可以作为一个类别数,对于相接较近的波峰应该取附近区域最大的波峰作为主波峰,也就是图3中的局部灰度直方图的2个红框所示的情况。为了选取合适的波峰数,需要设定相应的波峰宽度w,然后对数列B(i)进行计算,按如下公式4获得过滤后的波峰序列C(i)。

其中i{max|B(i)~B(i+w)}为B(i)~B(i+w)序列最大对应的i值,对得到的数列C(i)进行同数的除去,只保留不相同的数,最后C数列的元素个数就是图像最终需要分类的数目S,C数列如下式5所示:

将得到的数列C的元素个数设置为Kmeans的类别数,将C数列的元素数值作为Kmean的种子值,然后对通道差值图进行聚类。经过聚类后的图像分割效果如图4所示。

图4 Kmeans分割图
3.3 区域判断
对于使用Kmeans聚类分割出来的候选区域,需要进一步的进行判断筛选从而选出真正的车牌区域。首先对需要判别的候选区域计算其外界矩形获取局部的小图像,如图5所示。

图5 候选区域图
然后根据像素的分类值,将图5中红色的类别的像素点选取出来置为255,其他像素点灰度值置为0,即将计算外接矩形的目标候选区域像素点提取出来。从而可以获得候选区域的二值图,如图6所示。

图6 候选区域二值图
对于候选区域的筛选常见的筛选方法是通过长宽比、面积等进行筛选,但是这些都存在一些显而易见的弊端,比如长宽比和面积都符合的,可能是中心区域镂空的一个矩形。又由于本文研究的检测条件还存在拍摄角度和视距的远近等问题,所以常用的长宽比、面积等方法将无法达到准确筛选的效果。
为了更准确地进行判断,本文根据车牌的特征采用垂直方向上累计灰度直方图变化进行车牌的判断。为了减少车牌边缘存在模糊的影响,在计算垂直方向累计直方图时,先在垂直方向的上下进行一定的内缩,内缩大小为候选区域最小外接矩形的短边长度的二分之一,经过处理后的图像如图7所示。

图7 上下内缩后候选区域二值图
对处理后的图像计算垂直累计积分,如图8所示。
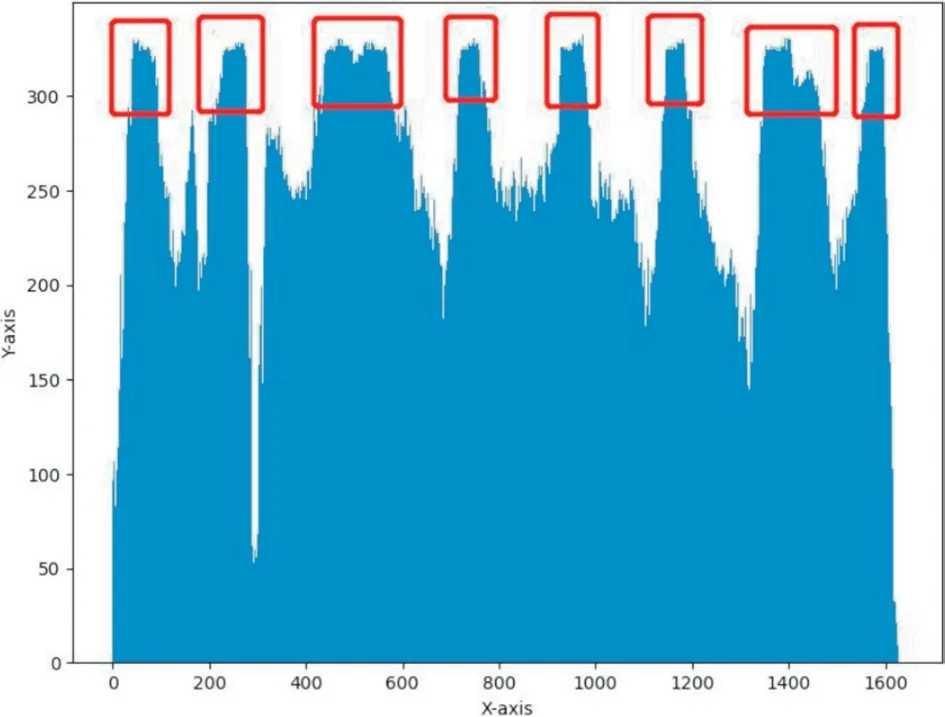
图8 垂直累计直方图
从垂直累计直方图可以看出来,存在明显的8个波峰,且每个波峰之间间距差距不大,这是因为车牌号码之间存在间隙造成,所以根据这种特性使用上一节计算波峰的方法计算出直方图的波峰数,根据波峰数的数目个间距可以判断出是否为车牌区域。对于波峰数的筛选条件,由于可能存在提取不准等情况,通过测试经验,将波峰数阈值设为5比较合适。至此,就完成了整个车牌提取的过程。
4 数据验证和分析
本文对采集到的一共1800张车牌的数据集进行了不同条件下的测试,分别在光照、拍摄角度、视距大小等不同条件下进行了测试统计,分析在不同的场景下,对于不同颜色的车牌的识别率。识别率的定义为,在同一条件下识别出的车牌数与车牌总数的占比。其中每种车牌的总张数为600张,每个测试条件下的张数为200张,根据不同的测试条件获得的测试数据如表1所示。
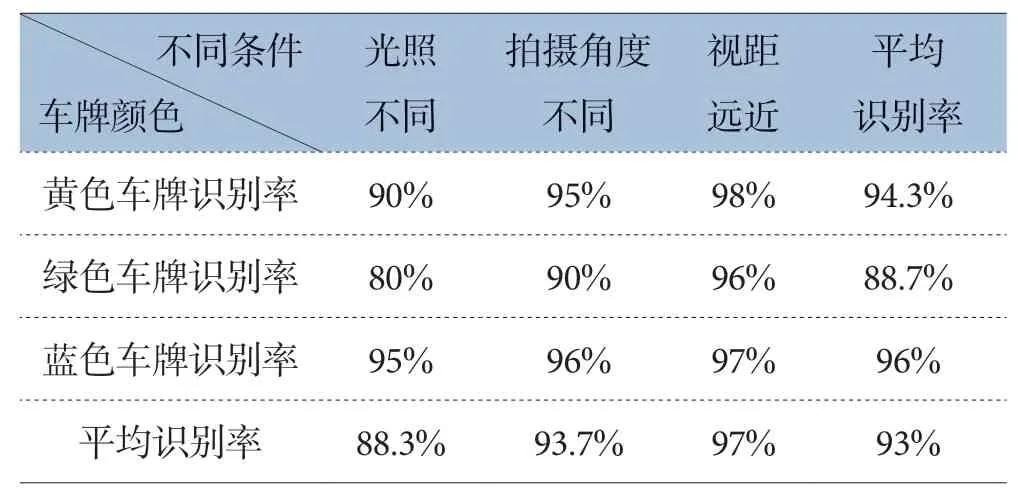
表1 测试结果
通过对不同情况下采集的数据进行测试,在光照变化的数据集中三种颜色车牌检测都是不同条件下最差的,主要是车牌的颜色在不同光照下表现的差距比较大,本文主要是根据颜色通道进行预处理的,因此光照的变化对本文产生的影响较大,但是相对传统的灰度图检测效果还是获得了一定的提升。光照不同条件下,因为绿色车牌是渐变色的缘故,因此检测效果是三种颜色车牌中最差,黄色属于比较显著的亮色因此是三种效果最好的。对于不同视角的拍摄情况,由于拍摄视角的不同对于颜色通道处理不会产生很大的影响,其影响主要体现在对于候选区域的筛选阶段,由于过度倾斜的角度会造成候选区域的区域二值图中字符间隔缩短甚至消失,因此造成垂直积分图的波峰数减少从而造成漏检,因此造成检测率降低的主要是倾斜角过大的图像,经过测试当倾斜视角大于60度时将产生明显的影响。对于视距远近条件下的测试,同样是由于视距的过远造成字符的模糊和车牌字符间隔的消失,从而造成筛选出错。
通过对实际数据的分析可知,本文虽然解决了一定的光照、拍摄角度等问题的影响,但是在环境较暗致使车牌颜色无法很好显现、倾斜度过大、视距过远的时候,还是无法很好地检测,针对这种情况,一方面可以提高图像采集像的分辨率和光照敏感度等,另一面可以尝试在颜色通道预处理时,做一定的对比度增强等方法,从而提高检测的精度和准确度。
此外本文还分别测试其他传统算法和深度学习算法在本数据集上得效果,具体数据如表2所示。
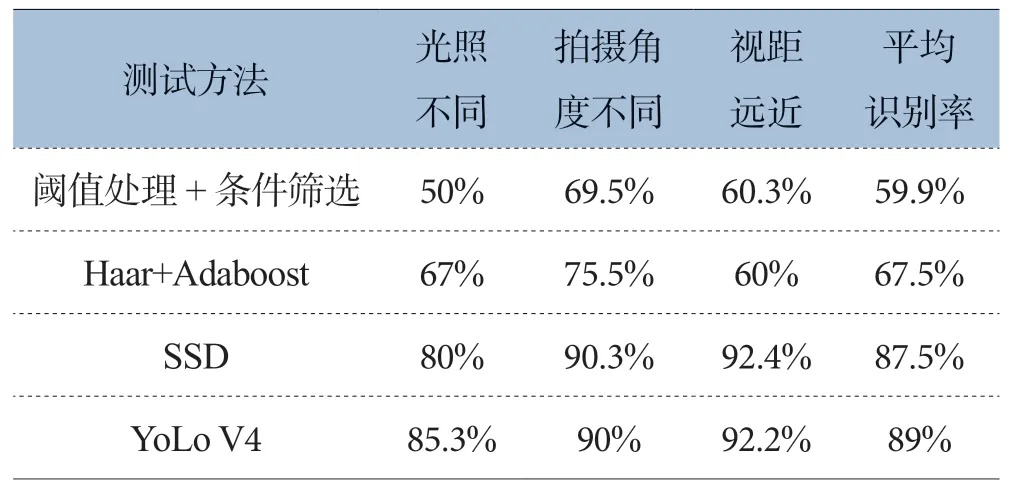
表2 不同算法测试效果
通过对比得出,使用传统的算法阈值处理+条件筛选,平均识别率远低于其他算法,主要原因在于光照环境、视角、距离远近等产生的影响。而目标检测算法如YoLo有很高的准确率,但是受限与样本的数量,和样本的类别。如果样本总量较少,或复杂场景下的样本的总数少的前提下,目标检测算法的准确率也会受到较大的限制。且目标检测算法在进行识别时,需要进行复杂的运算,因此检测的速率较低。因此本文使用的图像灰度直方图和Kmeans相结合的方法,无需进行复杂的推理运算,不受复杂环境的影响,依然保持高效地检测速率。
5 结束语
本文主要通过图像灰度直方图和Kmeans相结合的定位算法,实现了小样本数据在复杂场景下的车牌定位,相较于传统的算法,本文采用的算法可以适用各种复杂的环境。与深度学习目标检测相比,本文采用的算法可以采用少量的样本,便可获得很高的识别的准确率。因此本文的算法具有深度学习的检测准确率,又有传统算法的检测速率。兼顾了两类算法的优点。非常适合复杂环境下的车牌的提取。
