基于特征编码和动态路由优化的视觉定位方法
2022-11-11郑飂默谭振华
仉 新,郑飂默,谭振华,李 锁
(1.沈阳理工大学 机械工程学院,沈阳 110159;2.中国科学院沈阳计算技术研究所有限公司,沈阳 110168;3.东北大学 软件学院,沈阳 110169)
同时定位与地图构建(Simultaneous Localization and Mapping,SLAM)是搭载传感器的移动机器人通过对未知环境进行观测构建环境地图,同时实现自主定位与导航的技术[1]。SLAM是移动机器人实现自主导航的关键,广泛应用于自动驾驶、无人机,虚拟现实和智能家居等领域[2]。由于视觉传感器成本低且获取场景信息丰富,视觉SLAM受到广泛关注。闭环检测是SLAM的重要模块,对于减小视觉里程计产生的累计误差,提升机器人位姿估计的准确性,构建全局一致性地图具有重要作用[3]。随着SLAM的广泛应用,复杂场景下闭环检测准确性低和鲁棒性差的问题亟待解决[4]。
学者们对闭环检测进行广泛研究,视觉词袋模型(Bag of Visual Words,BoVW)是实现闭环检测的传统方法,通过提取人工特征,聚类不同的视觉单词,以单词向量的形式来描述图像,度量图像相似性实现闭环检测。全局特征(Global Characteristics Information of a Scene,GIST)采用二维滤波方法处理区域纹理信息,提取图像的整体特征,提升闭环检测效率[5]。但是传统特征对光照、季节、视角、遮挡,动态物体以及大尺度等环境变化敏感,影响闭环检测的准确性和鲁棒性。
深度学习不需要人工设计特征,具备强大的特征自主提取能力,对环境变化具有较好的鲁棒性,广泛应用于人脸识别、场景分类和医疗诊断等领域。Hou等利用深度学习实现闭环检测,相比BoVW和GIST方法,在光照变化场景下提升了闭环检测的准确性[6]。Sünderhauf等利用AlexNet网络提取图像特征,表明中高层特征更好地应对场景外观和视角变化[7]。牛津大学视觉几何组Simonyan等提出了VGG网络,采用连续的卷积核代替AlexNet的卷积核,通过增加网络深度提升网络的性能,在ImageNet挑战赛取得了优异成绩[8]。
传统深度学习方法可以自主提取图像特征,但浅层特征难以准确地描述图像的丰富信息,忽略了图像的空间细节特征。随着层数的加深,具有一定的局限性。随着网络层数的加深,增加了存储和计算资源;最大池化层未考虑特征间空间位置关系,丢失图像细节信息;神经元的输入和输出为标量,模型表达能力受限。
为解决上述问题,提升SLAM系统闭环检测的准确性和鲁棒性,提高图像特征提取和表达能力,实现复杂场景下移动机器人自主定位和导航,本文提出了一种融合特征编码和动态路由优化的视觉定位方法。
1 深度卷积神经网络框架
深度卷积神经网络具有局部区域感知、时空域上采样和权重共享等特点,在语音、文字、图像,视频识别和分类等领域取得了巨大的突破。随着网络层数的加深,提升了网络的学习能力,但是会降低网络的收敛速度。同时,梯度反向传播使得梯度变为无限小,无法有效调整网络权重,难以实现反向梯度传导,出现梯度爆炸、梯度消失及计算量大等问题。
为解决深度卷积神经网络的梯度消失和网络退化等问题,He等提出了残差网络(Residual Network,ResNet),残差网络跳跃式结构简单,且特征提取能力强,广泛应用于人脸识别、自动驾驶和图像分类等方向[9]。ResNet通过引入残差机制,采用恒等映射构建残差单元,降低了网络参数量和计算复杂度,提高运算效率,解决了网络退化问题,提升了网络性能[10]。根据网络层数划分,ResNet包含ResNet-18、ResNet-34、ResNet-50,ResNet-101和ResNet-152等典型网络结构。其中,ResNet-18和ResNet-34由基本残差模块构成,ResNet-50、ResNet-101和ResNet-152由bottleneck模块构成。
1.1 残差单元
残差单元是残差网络的基本组成部分,如图1所示,残差单元由卷积层Conv、批处理归一化层BN以及非线性激活函数Relu构成。

1.2 残差网络结构
残差网络的基本结构是残差单元,如图2所示。首先,将输入数据传入卷积层Conv、非线性激活函数层Relu和批处理归一化层BN;然后将结果传入多个残差单元;经批处理归一化层BN及全连接层,获得输出结果。ResNet采用旁路连接,将输入直接发送到输出,避免信息丢失,能够有效解决梯度爆炸和梯度消失问题。
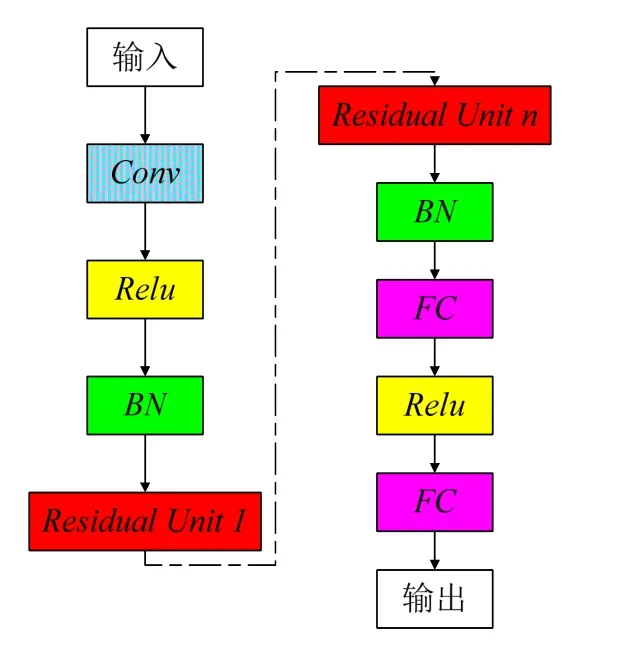
图2 残差网络结构Fig.2 The structure of ResNet
2 融合特征编码和动态路由优化的视觉定位方法
为提升图像特征的提取和表达能力,避免空间位置特征丢失,提高闭环检测的准确率和鲁棒性,实现移动机器人的自主定位和建图,本文提出融合特征编码和动态路由优化的视觉定位方法。首先,采用预训练的ResNet模型作为特征提取器,提取图像的浅层几何特征和深层语义特征,融合残差机制和GhostVLAD特征编码方式,获取图像的全局特征描述符,减少图像数据中的噪声信息,加快训练中模型的收敛速度;其次,通过熵密度峰值优化动态路由,利用CapsNet提取图像特征间的相对位置和方向,参数简单且鲁棒性强,实现优化网络整体性能;最后,将全局特征描述符和特征向量相结合,包含特征间的相对位置分布关系,保留特征间的差异性和关联性,提高SLAM系统定位和建图的准确性。
2.1 引入特征编码策略的残差网络模型
为提升场景位置识别的准确性,解决深度神经网络的梯度消失、网络退化以及计算量大等问题,加快训练中模型收敛速度,满足SLAM系统实时性要求,提出基于特征编码策略的残差网络模型。综合考虑模型的参数量及训练效果,采用如图3所示的ResNet-50模型作为特征提取基础网络,提取图像浅层几何特征和深层语义特征,为闭环检测带来了新的研究思路。特征编码通过对提取的图像特征聚类,提升残差网络对图像的识别能力。局部聚合描述符向量(Vector of Locally Aggregated Descriptors,VLAD)计算图像特征描述子及其聚类中心的差矢量,将局部特征聚类为全局特征,可以解决图像检索和图像分类问题[11]。Arandjelović等对局部特征进行聚类,提取特征之间的分布关系,获得全局特征描述,提出了结合神经网络的VLAD编码算法NetVLAD,该算法相对于VLAD算法更加灵活,适用于相似场景识别问题[12]。为提取高质量的图像特征描述子,Arandjelovi等人结合NetVLAD和“ghost”中心点,提出了GhostVLAD算法[13],如图4所示。
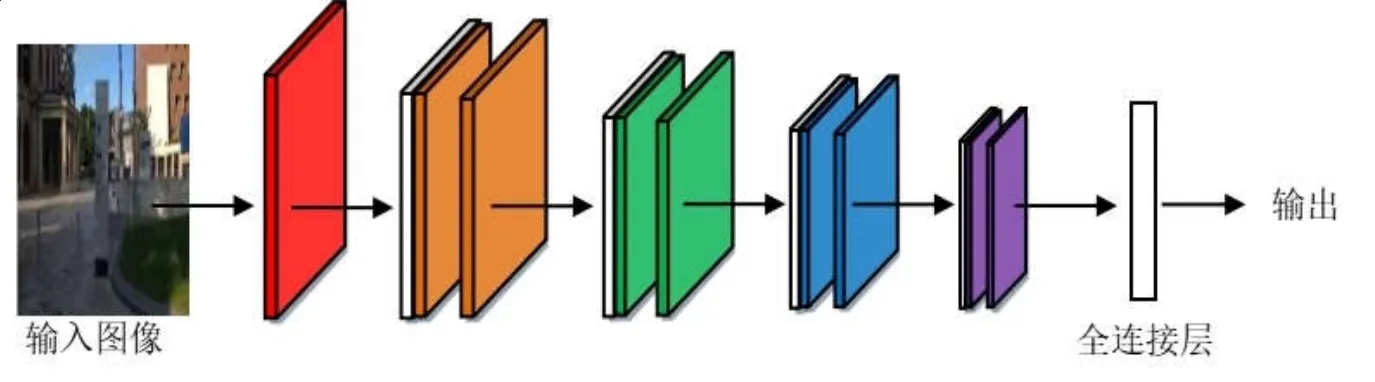
图3 ResNet-50结构图Fig.3 The structure of ResNet-50
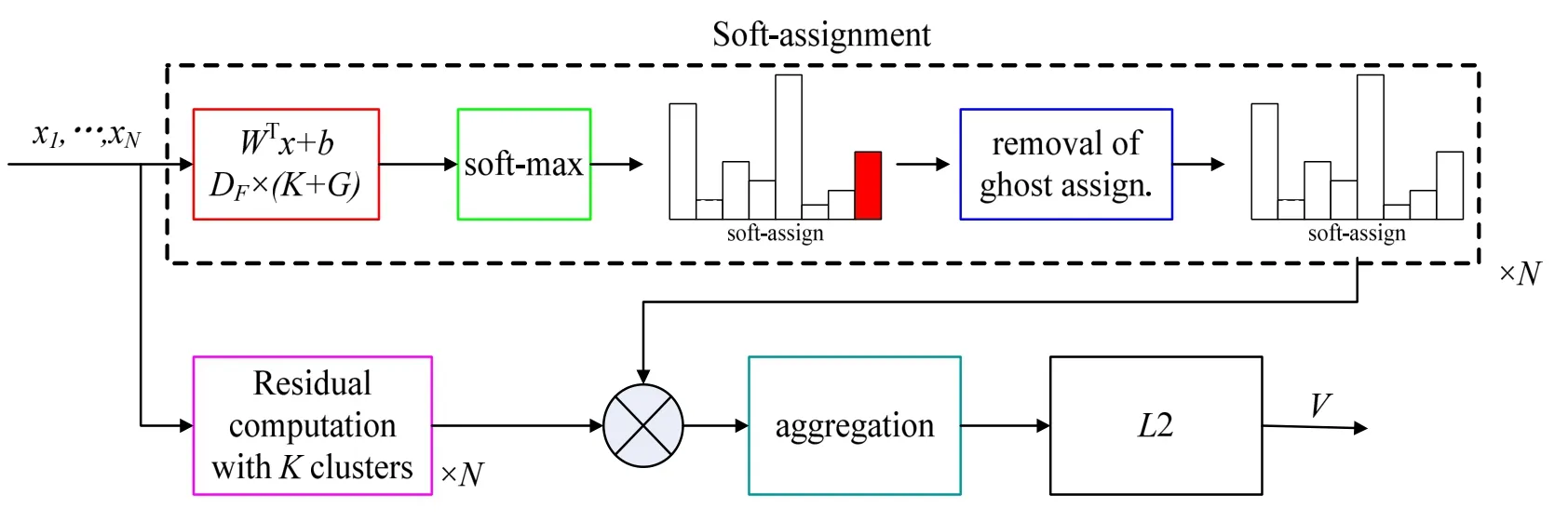
图4 GhostVLAD算法流程Fig.4 The algorithm flowchart of GhostVLAD

GhostVLAD是全局描述子,通过加入G个ghost聚类中心,对输入图像进行外观描述,采用自动加权降低低质量图像的权重。NetVLAD是GhostVLAD的一种特殊形式,即当0G=时,ghost类数目设定为0时,GhostVLAD计算结果和NetVLAD结果一致。
ResNet的输入是真实场景的彩色图像,输入图像大小为224*224*3。如图5所示,去除ResNet-50最后的均值池化层和全连接层,引入GhostVLAD层,将含噪声的信息分配到ghost类,降低噪声数据的干扰。通过对融合后的ResNet网络和GhostVLAD模块进行训练,对GhostVLAD层进行降维,得到512维的输出向量,有效降低了计算量,提升了场景识别的鲁棒性。
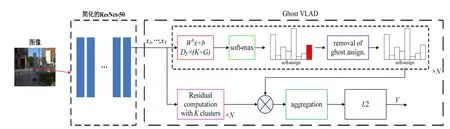
图5 基于GhostVLAD的ResNet网络结构图Fig.5 Network structure of ResNet based on GhostVLAD
2.2 熵密度峰值优化的胶囊网络
为提升卷积神经网络(Convolutional Neural Networks,CNN)识别图像的准确性,保留图像特征间的空间位置关系,2017年Hinton等首次提出了胶囊网络(Capsule Network,CapsNet)[14],CapsNet的动态路由机制采用k-means聚类,只适用于处理球形数据,对初始聚类中心敏感。本文采用密度峰值优化的动态路由,通过优化熵的最小值求解最优截断距离,提升胶囊网络的整体性能。
Sabour提出胶囊网络(Capsule Network,CapsNet)来改善CNN特征提取的局限性,通过更新主胶囊和数字胶囊之间的动态路由机制,得到高层级的实体表示,不仅减少了网络参数,而且避免发生过拟合[15]。通过MNIST数据集实验验证,CapsNet相比CNN在数字识别、交通标志识别以及医学图像分析等方面分类准确率高[16,17]。
CapsNet结构的基本单元是胶囊,采用胶囊代替CNN中的神经元表示图像的特征[18]。每个胶囊是一组神经元的集合,多个胶囊构成整个胶囊网络。每个胶囊表示全部或部分实体,向量的长度代表实体存在的概率,向量的方向代表图像中实体的各种属性,如姿态(位置、大小和方向)、纹理,形变和颜色等。采用动态路由替代最大或平均池化层,实现由向量输出替代标量输出,利用向量化的胶囊来编码特征信息[19]。胶囊间的信息传播过程如图6所示。
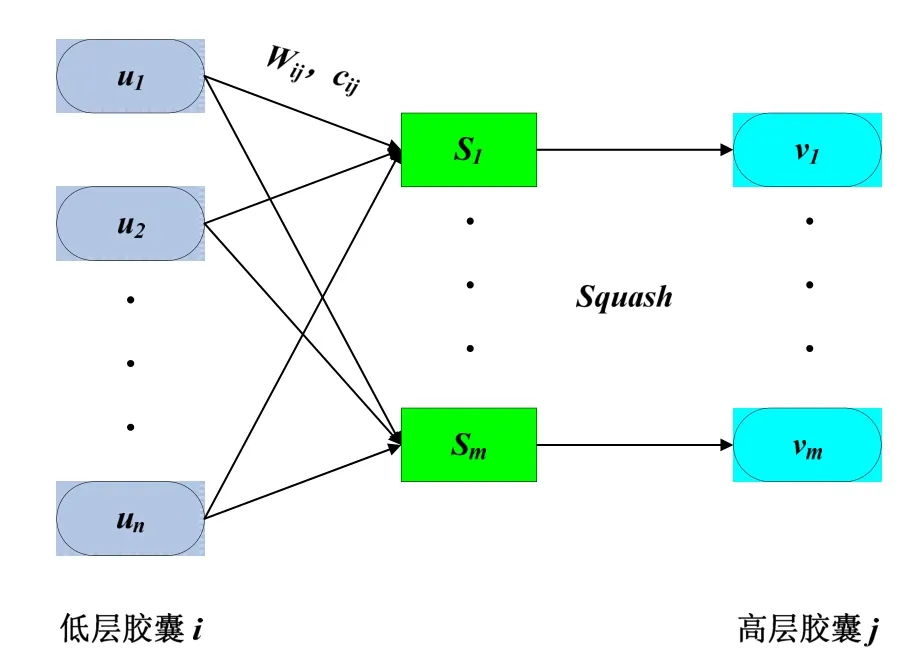
图6 胶囊间的信息传播过程Fig.6 Information transmission between capsules


经典CapsNet包含输入层、卷积层(Conv1)、初始胶囊层(PrimaryCaps)、数字胶囊层(DigitalCaps),全连接层和输出层,如图7所示。相比CNN的池化策略,CapsNet的信息传递机制充分地保留了特征间的空间位置关系,实现了图片信息的准确传递。加权系数由预测向量和高层胶囊之间的内积决定。内积越大,胶囊神经元间的加权系数越大,低层胶囊向高层胶囊传递的特征信息越多;内积越小,胶囊神经元间的加权系数越小,低层胶囊向高层胶囊传递的特征信息越少。实验可得通过3次迭代就可得到较好的耦合系数,不会增大计算量。
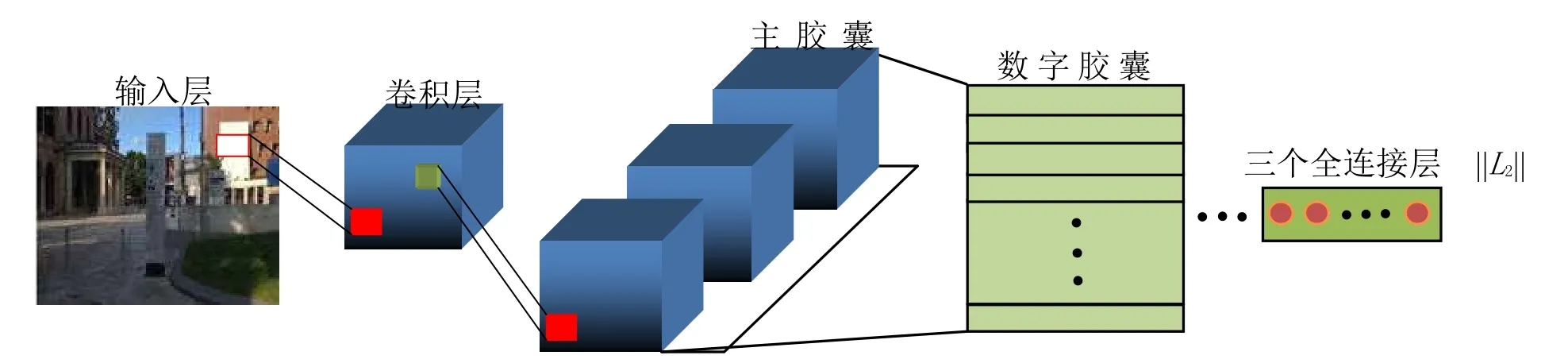
图7 胶囊网络结构Fig.7 The structure of CapsNet
胶囊网络的动态路由机制采用k-means聚类算法,将低层特征转换为高层特征,且只适用于处理球形数据,对初始聚类中心敏感。密度峰聚类(Density Peaks Clustering,DPC)算法适用于任意形状的数据,参数简单且鲁棒性强[20]。采用密度峰值优化的动态路由,通过优化熵的最小值求解最优截断距离,解决胶囊网络对初始聚类中心敏感问题,实现低层特征到高层特征的聚合,利用向量表示特征间的相对位置和方向,提高网络整体性能。
DPC算法主要包含局部密度iρ和邻近距离iδ。采用高斯核定义局部密度为:

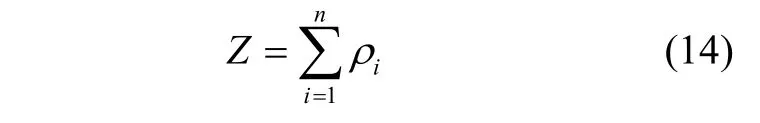
其中,Z为标准化系数。将式(11)代入式(13)(14),构造关于截断距离的函数,通过优化熵的最小值求解最优截断距离。实验可知,当熵为最小值时,可得到截断距离的最优值。具体优化过程为:
步骤1 低层胶囊的权重映射;
2.3 融合优化后的残差网络和胶囊网络
将残差网络特征输入GhostVLAD层获取特征点和聚类中心的残差之和,整合特征得到全局特征描述符,通过胶囊网络获取表示特征分布的特征向量,提取差异化特征,将全局特征描述符和特征向量相结合,ResNet-50特征对应图8中抽象的红、黄及绿色块等,CapsNet的全连接层对应图8中蓝色块及特征向量,表示特征之间的相对位置分布关系。融合后保留了特征之间的差异性和关联性,提升特征识别能力,提高SLAM系统定位和建图的准确性。
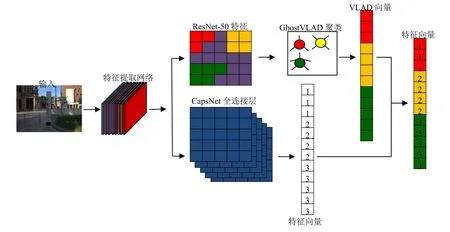
图8 融合胶囊网络和残差网络的特征向量Fig.8 The feature vectors based on capsule network and residual network
如图9所示,通过对融合后的特征进行L2归一化和主成分分析(Principal Component Analysis,PCA)降维,计算图像特征相似性用于闭环检测,剔除数据中的冗余图像特征和噪声,提升计算效率的同时,显著提高了图像的表达能力,有效建立环境一致性地图,提升SLAM系统定位和建图的准确性和鲁棒性。
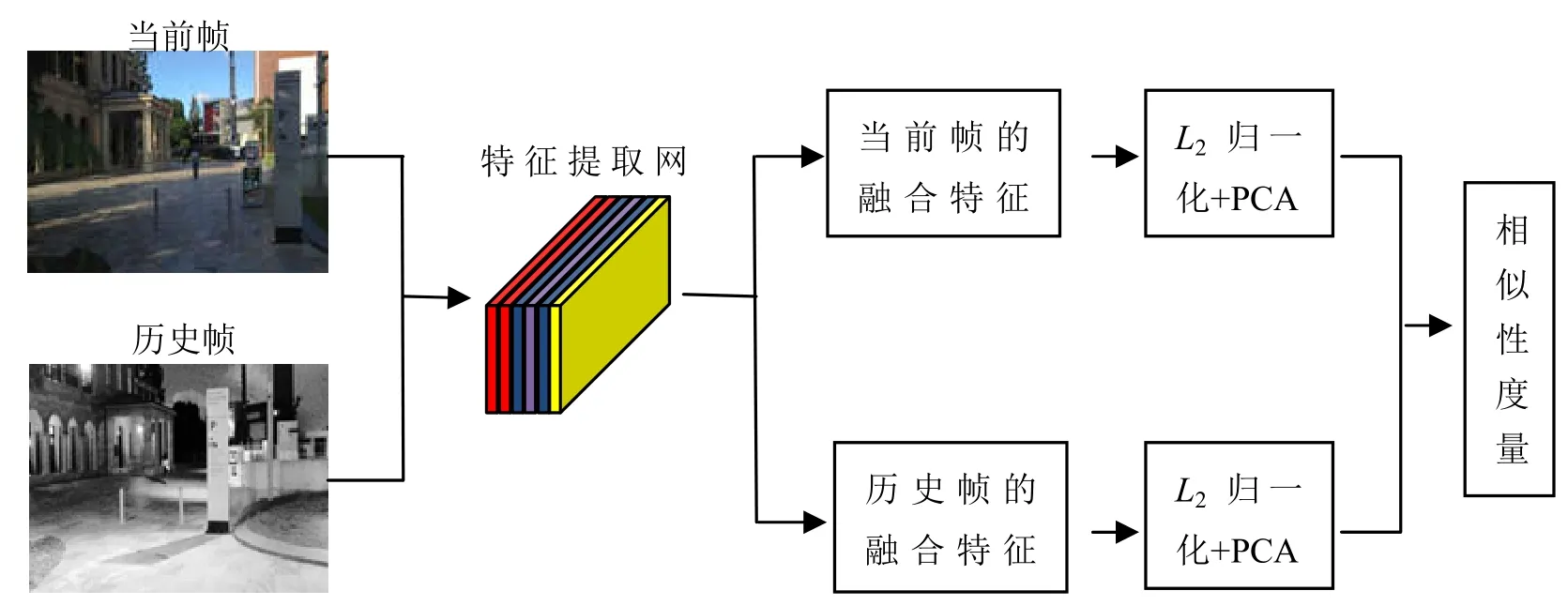
图9 闭环检测流程图Fig.9 The flowchart of loop closure detection
3 实验结果与分析
为验证本文所提出的闭环检测方法的有效性,利用SLAM数据集进行性能评估,Gardens Point和TUM是常用的标准数据集。选用实验平台为:处理器为i7-8750H,运行内存32GB,运行环境为Ubuntu 16.04系统。
3.1 评价指标
1)准确率(precision)和召回率(recall)是评价闭环检测效果的常用指标,以召回率为横轴,准确率为纵轴,使用准确率-召回率曲线评价算法有效性。
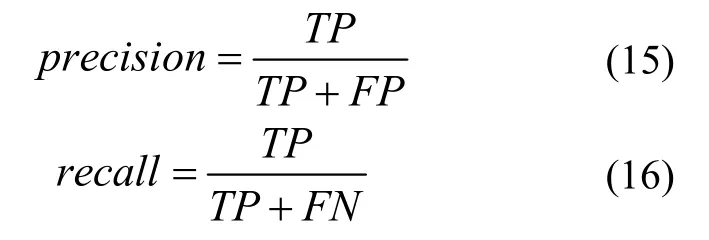
其中,TP为检测到正确的闭环数,FP为检测到错误的闭环数,FN为没有检测到真实的闭环数。
2)准确率-召回率曲线下的面积(Area Under the Curve,AUC)是评价闭环检测的主要指标,AUC值越接近1,表明算法平均准确率越高,性能越好。
3)绝对轨迹误差(Absolute Trajectory Error,ATE) 是评估SLAM定位准确度的主要指标。绝对轨迹误差是估计轨迹与真实轨迹之间的差值。
3.2 闭环检测实验结果与分析
Gardens Point数据集:采集于昆士兰科技大学校园,包含视角变化、光照变化,动态物体及遮挡因素。图像示例如表1所示。

表1 Gardens Point数据集Tab.1 Gardens Point dataset
由三个图像序列组成,其中图像序列day-left和day-right均采集于白天行经道路左右两侧的场景,子图像序列night-right采集于夜晚行经相同道路时右侧的场景。
为验证本文方法(Res-CapsNet)的有效性,分别对Gardens Point数据集进行闭环检测对比实验分析,数据集包含视角、光照、动态物体和遮挡等场景变化。与基于BoVW、GIST、AlexNet、VGG的闭环检测方法进行对比实验,实验结果如图10-12所示,其中,紫色线条表示视觉词袋模型(BoVW),红色线条表示基于全局GIST特征的闭环检测,绿色线条表示基于AlexNet的闭环检测,橙色线条表示基于VGG的闭环检测,蓝色线条表示本文方法(Res-CapsNet)。
图10为Gardens Point数据集的光照相同、视角变化场景下闭环检测实验结果,可以测试方法对视角变化的鲁棒性。基于Res-CapsNet闭环检测准确率-召回率曲线的AUC值为0.97,平均准确率也最高,而基于VGG、AlexNet、BoVW及GIST闭环检测的AUC值分别为0.95,0.97,0.84,0.63,在视角变化场景下,当闭环检测召回率达到80%时,基于Res-CapsNet闭环检测准确率达到96.49%,而对比基于VGG、AlexNet、BoVW及GIST闭环检测的准确率分别为94.97%,96.18%,73.28%,48.69%,采用基于VGG及AlexNet的闭环检测效果相差不大,且准确率高于基于BoVW及GIST闭环检测方法,说明基于卷积神经网络模型提取的特征,对于视角变化场景具有较好鲁棒性。高召回率下基于Res-CapsNet的闭环检测方法仍保持了较高的准确率。
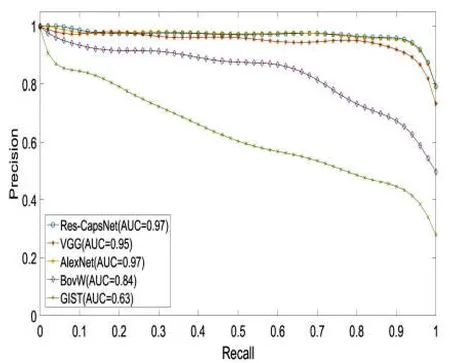
图10 白天-左侧与白天-右侧数据集准确率-召回率曲线Fig.10 Precision-Recall of day-left vs day-right datasets
图11为Gardens Point数据集的视角相同、光照变化场景下闭环检测实验结果,可以测试方法对光照变化的鲁棒性。基于Res-CapsNet闭环检测的准确率-召回率曲线的AUC值为0.81,平均准确率最高,而基于VGG、AlexNet、BoVW及GIST闭环检测的AUC值分别为0.59,0.49,0.37,0.25。随着召回率逐渐增加,准确率逐渐降低。在视角变化场景下,当闭环检测召回率达到80%时,基于Res-CapsNet的准确率达到65.55%,而对比基于VGG、AlexNet、BoVW及GIST闭环检测的准确率分别为43.73%,37.64%,27.80%,49.89%,高召回率下Res-CapsNet准确率较高。
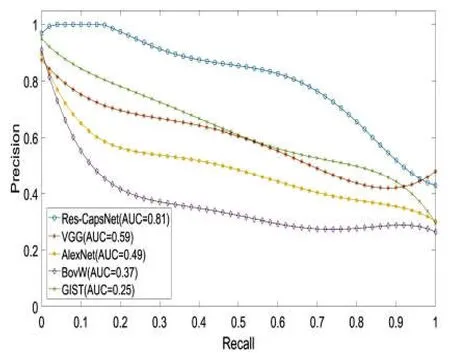
图11 白天-右侧与夜晚-右侧数据集准确率-召回率曲线Fig.11 Precision-Recall of day-right vs night-right datasets
图12为Gardens Point数据集的视角和光照均明显变化场景下闭环检测实验结果,可以测试方法对视角和光照变化的鲁棒性。随着光照及视角的变化,各种方法的性能都有所下降,基于Res-CapsNet闭环检测的准确率-召回率曲线的AUC值为0.75,平均准确率最高,而基于VGG、AlexNet、BoVW及GIST闭环检测的AUC值分别为0.55,0.43,0.16,0.14,在视角和光照变化场景下,当闭环检测召回率达到80%时,基于Res-CapsNet闭环检测的准确率达到57.53%,对比基于VGG、AlexNet、BoVW及GIST闭环检测的准确率分别为32.99%,34.47%,13.72%,14.84%。BoVW和GIST的鲁棒性较低,表明传统特征容易受光照和视角变化影响,由于卷积神经网络提取的图像特征,丢失了空间细节信息,基于AlexNet和VGG闭环检测方法的准确率有所提升,在保证较高召回率的情况下基于Res-CapsNet闭环检测准确率最高。
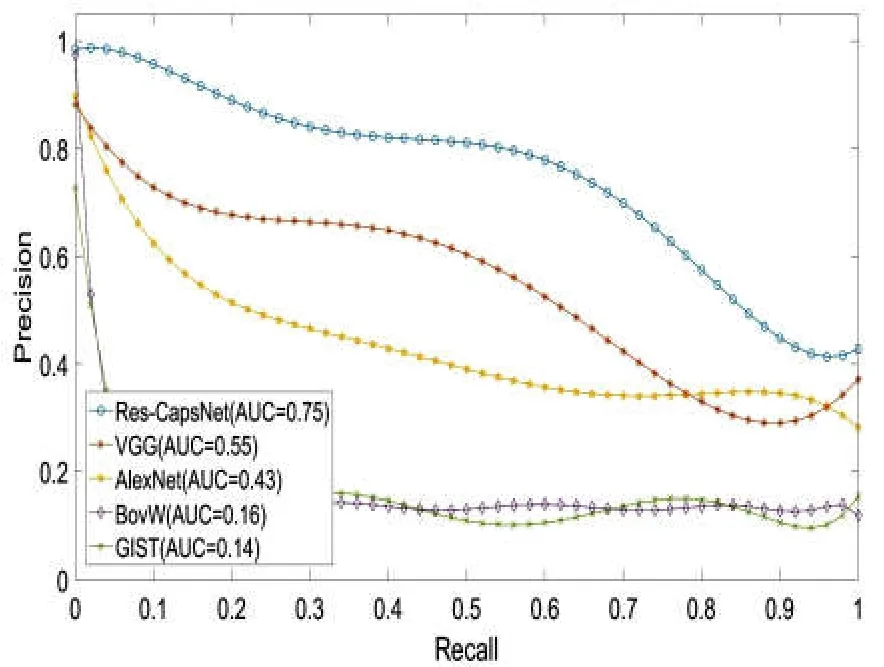
图12 白天-左侧与夜晚-右侧数据集准确率-召回率曲线Fig.12 Precision-Recall of day-left vs night-right datasets
3.3 SLAM系统实验结果与分析
TUM数据集:由德国慕尼黑工业大学采集于室内环境,包含动态和大尺度场景,对运动模糊、旋转、结构,纹理和闭环等情况具有针对性,满足不同测试需求。数据集由Kinect相机采集,包含RGB彩色图和深度图,图像大小为640*480,及相机真实的位姿轨迹文件,参数如表2所示。
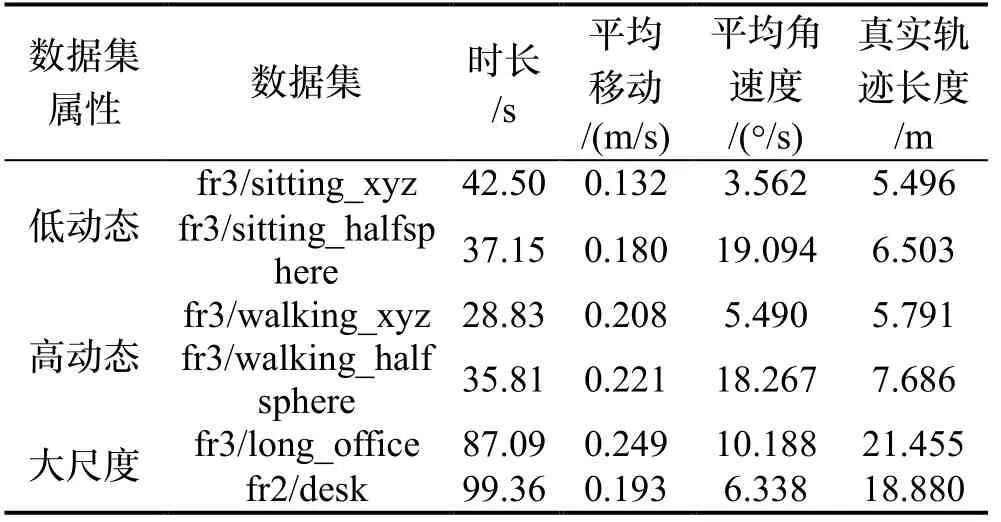
表2 TUM数据集参数Tab.2 Parameters of TUM dataset
其中:“sitting”图像序列包含人体的较小的肢体运动,属于低动态场景。“walking”图像序列包含动态行走的行人,属于高动态场景。“office”图像序列包含轨迹超过18米的办公场景,属于大尺度场景。对图像预处理,采用缩放函数压缩为224*224*3的彩色图像作为特征提取网络(ResNet50)的输入,其中224为图像尺寸,3为RGB三通道。与目前经典的ORB-SLAM2进行对比,采用绝对轨迹误差ATE评价SLAM系统准确性。
TUM数据集提供相机真实位姿,对比估计位姿与真实位姿评价SLAM系统位姿估计的准确性。图13为TUM序列真实轨迹与估计轨迹对比图,其中,黑色曲线表示真实轨迹,红色曲线表示ORB-SLAM2估计轨迹,蓝色曲线表示Res-CapsNet估计轨迹。
图13为Res-CapsNet和ORB-SLAM2算法在低动态、高动态及大尺度场景的SLAM系统轨迹对比结果。如图13(a)、图13(b)所示,在低动态场景下Res-CapsNet和经典ORB-SLAM2方法估计结果较好,均与真实轨迹接近,表明Res-CapsNet和ORB-SLAM2方法在低动态场景下,SLAM系统定位准确性都很好。如图13(c)、图13(d)所示,在高动态场景下ORB-SLAM2的轨迹估计误差较大,是由于相机剧烈抖动或快速移动情况,ORB-SLAM2不能准确区分场景中的静态和动态特征,受动态特征影响导致位姿估计准确性降低。Res-CapsNet估计轨迹更接近真实轨迹,准确性更高。如图13(e)、图13(f)所示,相比ORB-SLAM2,大尺度场景下Res-CapsNet保持着较高的准确性。综上所述,复杂场景下Res-CapsNet保持较高的准确性和鲁棒性。
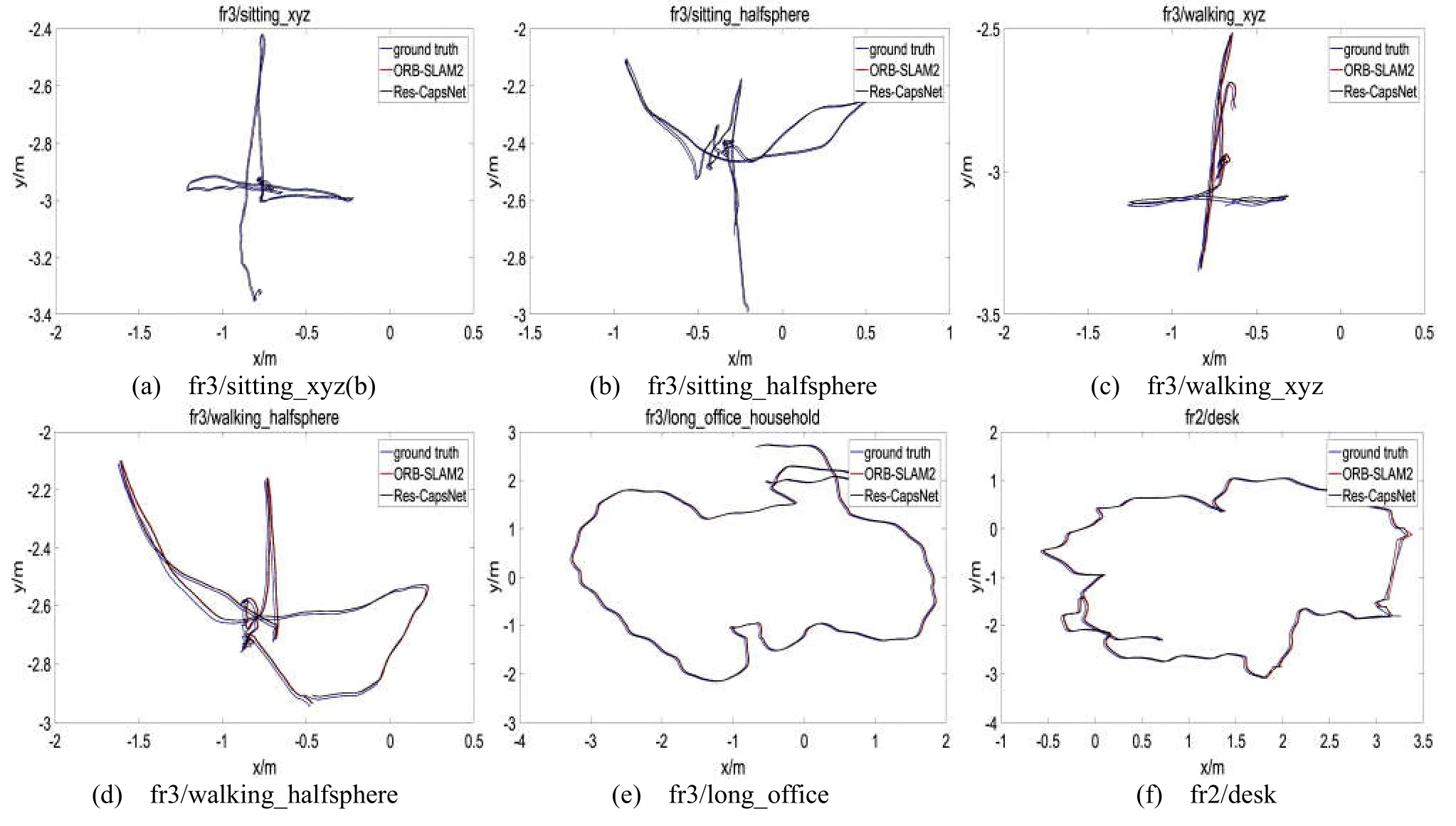
图13 SLAM系统绝对轨迹误差对比Fig.13 Absolute trajectory error comparison for SLAM
表3是ORB-SLAM2与Res-CapsNet在TUM数据集下,真实轨迹和估计轨迹之间的绝对轨迹误差结果。低动态场景下,由于ORB-SLAM2采用RANSAC方法剔除低动态场景外点运动干扰,ORB-SLAM2与Res-CapsNet准确率相差不大,SLAM系统性能没有明显提升;高动态及大尺度场景下相比ORB-SLAM2,Res-CapsNet绝对轨迹误差下降明显,在fr3/walking_ xyz、fr3/walking_halfsphere、fr3/long_ office和fr2/desk序列中,性能分别提升了72.68%、60.73%、20.88%和27.91%,表明复杂场景下,基于Res-CapsNet的SLAM系统定位准确性更高,鲁棒性更好。
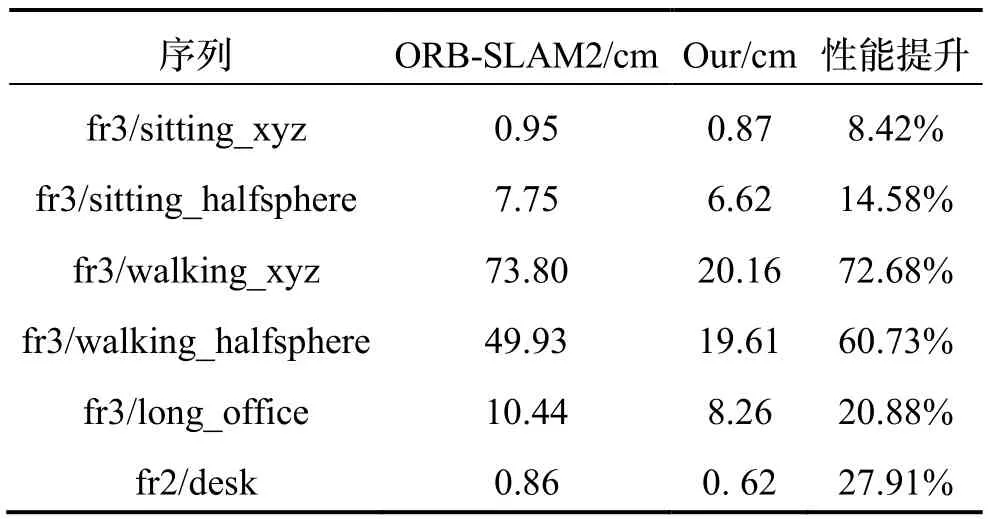
表3 绝对轨迹误差对比Tab.3 Comparison of absolute trajectory error
表4为特征提取速度对比。Res-CapsNet的特征提取时间是256 ms/Frame,虽然高于深度学习发展中经典的AlexNet和Faster R-CNN的计算速度,但是远低于ResNet和VGG16的特征计算速度。可见,Res-CapsNet可以满足复杂场景下SLAM系统的实时性要求。
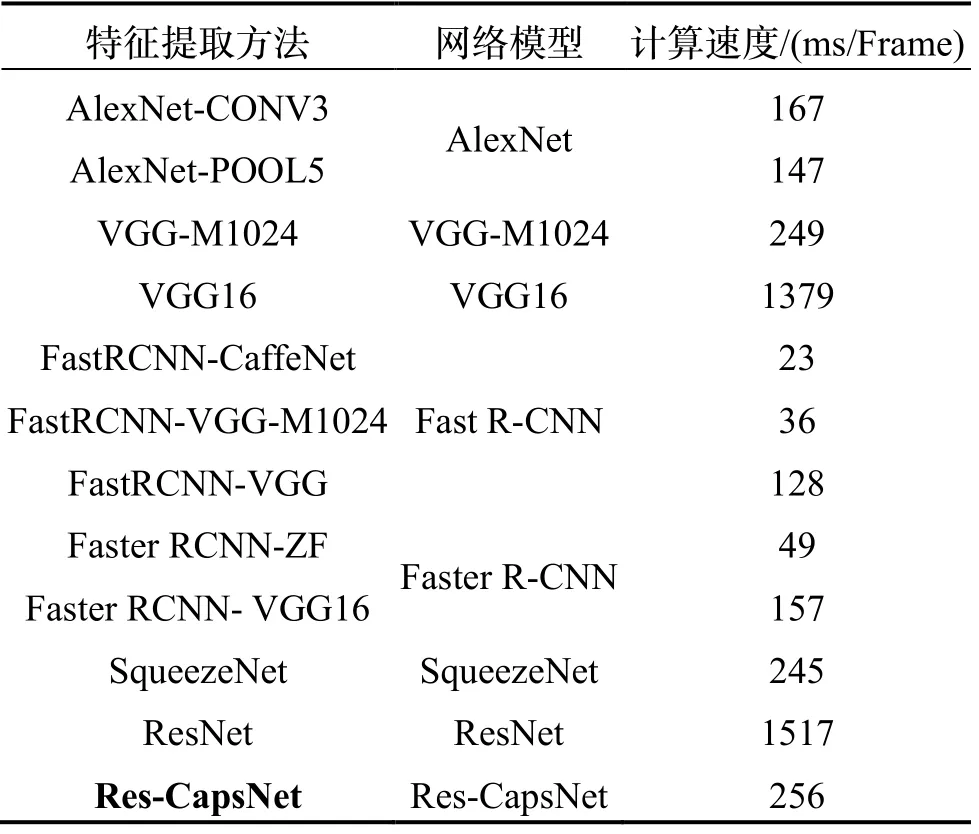
表4 特征提取速度对比Tab.4 Comparison of feature extraction speed
表5为网络模型的内存消耗对比,其中:经典的AlexNet内存消耗为183 MB,VGG内存消耗为229 MB,FastRCNN-VGG内存消耗为367 MB,由于AlexNetb将100个路标以批量方式一次性送入GPU,内存消耗最多,高达880 MB。Res-CapsNet内存消耗为237 MB,可以满足有限GPU内存资源的嵌入式系统,或移动设备上的应用需求。
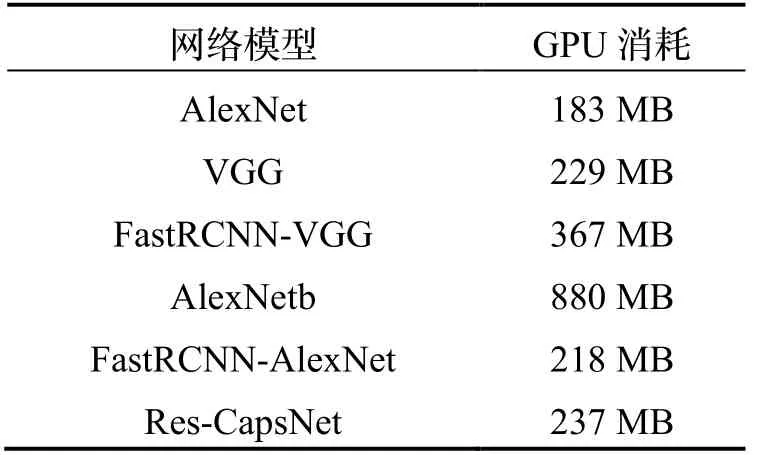
表5 内存消耗对比Tab.5 Comparison of memory consumption
综上所述,Res-CapsNet提升了深层网络对图像特征的识别和描述能力,提高了复杂场景下移动机器人定位及建图的准确性,GPU内存消耗低,可以满足复杂场景下的实时性需求。
4 结论
为实现复杂场景下移动机器人自主定位和建图,提高闭环检测准确性和鲁棒性,减少视觉里程计累积误差,建立全局一致性环境地图,提出了融合特征编码和动态路由优化的视觉定位方法。采用ResNet提取图像深层特征,引入GhostVLAD特征编码实现图像特征聚类,解决了网络的梯度消失和网络退化问题,提升了网络收敛速度;通过优化熵的最小值求解最优截断距离,采用熵密度峰值改善胶囊网络的动态路由机制,提取特征之间的相对空间位置信息;结合全局特征描述符和CapsNet提取的特征向量,提升了深层网络对图像特征的识别和描述能力,保留了特征间的差异性和关联性,提升了网络整体性能。实验结果表明,Res-CapsNet平均准确率最高,有效实现了光照、视角变化和动态场景等复杂场景下移动机器人的闭环检测,提高了移动机器人定位和建图的准确性和鲁棒性。
