基于IIGA 的分布式装配置换流水车间调度*
2022-11-10王志彬
董 海 王志彬
(①沈阳大学应用技术学院,辽宁 沈阳 110000;②沈阳大学机械工程学院,辽宁 沈阳 110000)
近年来,由于分布式制造系统在提高生产效率和降低成本中起到了关键的作用,生产制造开始从集中式向分布式转变。分布式装配置换流水车间调度问题(distributed assembly permutation flowshop scheduling problem,DAPFSP)是分布式置换流水车间调度问题和装配流水车间调度问题的结合,在计算复杂度上,分布式装配置换流水车间已被证明属于NP-hard 问题。DAPFSP 通常以最小化最大完工时间(makespan)和最小化总流经时间(total flowtime,TF)为优化目标,两种优化目标既涉及机器的平衡使用,又涉及工件的快速处理。对于以最小化最大完工时间为优化目标,Sara H[1]等建立了混合整数线性规划(mixed integer linear program,MILP)模型,提出了多个启发式方法用于构造初始解,并设计变领域下降算法进行求解。Lin J 等[2]提出1 种回溯搜索超启发式(backtracking search hyper-heuristic,BS-HH)算法进行求解,并与文献[1]以及分布估计等智能优化算法进行比较,突出了BS-HH 算法的有效性。Pan Q K 等[3]提出了一个混合整数线性模型,列出了3 种不同结构的启发式算法,最后通过与其他16 个已有算法进行仿真实验,验证了所提算法在算法性能和运算时间两方面的优越性。黄佳琳[4]等提出了一种改进的生物地理学(modified biogeography-based optimization,MBBO)优化算法进行求解,与现有的12 种启发式算法以及基本生物地理学优化算法进行比较,证明了MBBO 算法的优越性。对于以最小化总流经时间为优化目标,Fernandez-Viagas V[5]等首先提出了这个问题,并提出18 种启发式算法和1 种进化算法进行求解。Pan Q K[6]等提出了3 种构造性启发式和4种元启发式进行求解。Sang H Y[7]等设计了3 种离散的杂草入侵算法,该算法具有很强的自适应性和鲁棒性,可以有效求解最优解。张梓琪等[8]针对低碳分布式装配流水车间调度问题,提出一种基于多维分布估计算法(multidimesnsional estimation of distribution algorithm,MEDA)进行求解。
综上所述,在问题求解层面,该问题具有大规模、强耦合和不确定等复杂性,目前基于分布式装配置换流水车间调度模型的各类优化目标研究得非常广泛,但以总流经时间为优化目标的DAPFSP 研究还十分有限。因此,对其研究具有重要的学术意义和工程应用价值。
迭代贪婪(iterated greedy,IG)算法是由Jacobs L W[9]等提出的一种结构简单、参数少以及快速有效的智能优化算法,通常在当前解的邻域内不断地进行局部搜索来获得最优解,并在此基础上,通过破坏和重构策略加强对较好解所在局部领域的搜索能力,IG 算法针对不同的优化目标和不同的流水线调度问题都展现出其优异的性能。Lin S W[10]等提出1 种改进IG 算法解决以最小化最大完工时间为目标的DPFSP,增加了解的质量。Fernandez-Viagas V[11]等针对以最小化最大完工时间为优化目标的DPFSP,提出一种有界搜索IG 算法进行求解。Huang Y Y[12]等针对以总流经时间为优化目标的DAPFSP,提出一种基于群体思维的改进迭代贪婪(groupthink iterated greedy,GI)算法。钱斌[13]等针对以最小化总延迟时间为优化目标的 DPFSP 问题,建立问题排序模型,并提出混合迭代贪婪算法(hybrid iterated greedy,HIG)进行求解。
以上研究均使用了IG 算法求解流水车间的相关调度问题,其在局部邻域搜索上展现了良好的效果。然而,仅仅采用局部邻域搜索难以使解在迭代过程中跳出搜索范围,降低了解的多样性。传统IG 算法使用模拟退火准则来提高解的多样性,但实验效果并不明显。针对DAPFSP 问题,构建以最小化总流经时间为目标的数学模型,提出一种改进的迭代贪婪(improved iterated greedy,IIG)算法。该算法主要通过结合NEH 算法和CDS 算法提出一个新的初始化方法以获得高质量的初始解,为加快算法效率、降低问题复杂性,设计了新的两段销毁、构建和本地搜索方法,增加了解决方案的多样性且扩大了搜索空间;最后通过仿真验证改进的迭代贪婪算法求解DAPFSP 的有效性和鲁棒性。
1 分布式装配置换流水车间问题
1.1 问题模型
分布式装配置换流水车间调度问题包括2 个阶段:生产阶段和装配阶段,并且可以概括为3 个子问题:工件调度、产品调度和工厂分配,如图1 所示。

图1 分布式装配置换流水车间调度
在生产阶段,有n个工件和f个相同的工厂。工件j∈{1,2,···,n}需要分配给任意工厂l∈{1,2,···,f}进行加工;每个工件都能在所有工厂进行加工,并且只能在一个工厂加工;每个工厂都配有m台相同的机器,所有工件都需要根据机器i∈ {i1,i2,···,im}的顺序依次在相同的路径中加工;工件j在机器i上加工时记作Pi,j。在装配阶段只有一个装配工厂,所有的工件在生产加工完毕后都会运输到装配工厂进行产品的组装;在装配阶段,有s个产品和一台装配机器,每种产品r∈{1,2,···,s}均具有已定义的组装程序;产品的装配只能在其包含的作业完成且装配机空闲时开始;属于同一产品的作业是连续处理的,下一个产品的操作只能在属于同一产品所有作业处理完毕后才能执行。解决DAPFSP 的关键是确定任务分配给工厂、每个工厂中任务生产顺序以及产品装配顺序,从而使整个操作的TF 最小化。
根据上述问题描述并参考文献[12]建立TF 数学模型及其相关约束条件
式中:Xj,k表示二进制变量,如果作业j是作业k的前身,则等于1;否则,Xj,k=0。对于Yr,t也是如此。如果产品r是产品t的前序,则等于1;否则,Yr,t=0。Ci,j是机器i上作业j的完成时间,Cr是产品r的完成时间。Pr是产品r的装配时间,zr是产品序列中第一个r产品中包含的作业总数。此外,g是一个足够大的正数,nt是产品t中包含的作业数。
式(1)表示TF 最小化;式(2)和(3)表示每个作业必须只有一个前置作业和一个后续作业;式(4)和(5)表示虚拟作业0 的前置作业和后续作业被强制执行f次;式(6)表示一个作业不能同时是另一个作业的前置作业和后续作业;式(7)表示连续处理属于同一产品作业;式(8)表示作业j在机器i上处理后,只能在机器i上处理;式(9)表示如果作业j是作业k的后续任务,则作业j只能在作业k处理完成后在机器i上处理;式(10)和(11)表示每个产品只能有一个前置产品和一个后续产品;式(12)表示一个产品不能同时是另一个产品的前置产品和后续产品;式(13)表示每个产品所包含的作业部分在尚未生产之前,产品无法进入装配阶段;式(14)表示如果产品t是产品r的前置任务,则产品r在产品t完成之前无法开始装配操作;公式(15)定义TF;式(16)~(19)定义决策变量的域。
为了更好地理解上述问题,引用1 个例子。假设有6 个工作岗位、2 台机器、2 个工厂和3 种产品。表1 列出产品和作业之间的关系、机器处理的时间,图2 是调度甘特图,从甘特图中可以清楚地看到一个产品与其包含的作业具有相同的颜色。作业3、1、4 分配给工厂1,其他作业在工厂2 生产,TF是每个产品完成时间的总和。

图2 两个阶段的调度甘特图示例
表1 产品的处理时间和关系
2 迭代贪婪算法
迭代贪婪算法自提出以来已在各种调度环境中获得了许多成功的应用,本文提出一种改进的IG算法解决DAPFSP,与传统的IGA 不同,该算法首先使用所提出的初始化过程生成一组解的集合ϑ,并对集合ϑ中的最优解进行局部搜索;然后算法进入迭代阶段,在迭代过程中,使用选择机制在集合ϑ中选择解φ;将破坏阶段应用于解φ获得两个部分序列,一个是被移除的产品和工作所组成的序列φD,另一个φR是解的剩余部分;对φR进行产品的本地搜索,生成次优解将移除的产品和作业重新插入,该过程称为构造阶段,并重新生成完整的解φ′,对φ′执行作业的本地搜索生成解φ″;最后,使用接受准则来判断新解φ″是否符合标准,具体过程如下。
2.1 解的表示
解决方案分为两部分内容,产品序列和作业序列,每一部分都对应一个产品。只有当一个产品中包含的所有作业都生产完成后,才能进行下一个产品作业的生产。当产品中包含的所有作业完成时,允许产品进入装配阶段进行加工。假设1 个解表示为φ,其中产品序列记录为Δ={Δ1,Δ2,···,Δs},以及产品Δr中包含的作业序列πr={πr1,πr2,···,πrn},其中n指产品Δr中包含的作业数量。
2.2 基于CDS 和NEH 的启发式算法
初始解的质量可能会影响IGA 的性能,因此本文提出一种基于 CDS 方法和NEH 的初始化启发式方法(CDS-NEH)。CDS 方法是通过将机器m分为2 组,反复使用Johsnon 算法对2 台机器上的作业进行排序,从而基本上将流水车间中n个作业问题划分为m-1 个两台机器作业问题的集合,得到尽可能多的替代作业序列,然后以最小化总流经时间排序,选取最佳序列。NEH 已被证明是解决流水车间问题最有效的启发式方法之一,并且已被扩展到以最小化完工时间和最小化总流经时间为优化目标的DPFSP。其具体步骤如下:
步骤1:使用CDS 方法初始化每个产品的作业序列,找到最佳序列πorigin={π1,π2,···,πm}。
步骤2:计算每个产品的装配时间和其包含的所有作业的总处理时间r∈{1,2,···,s}。
步骤3:按照Pr对各工件进行降序排序,得到初始序列Δorigin={Δ1,Δ2,···,Δs}。
步骤4:随机取产品Δu将其插入到Δ 中所有可能位置并测试其TF值,最终将产品插入到使TF最小的位置pt处。
步骤5:从Δ 中抽取位置pt-1或pt+1的产品h,重复执行步骤4,直到所有工件都被考虑。
该启发式算法具有一定的随机性质,在初始化步骤中重复使用CDS-NEH 算法生成多个初始解。如图3 所示为工件数n=100,机器数m=5,工厂数F=4 和产品数s=30 的一组DAPFSP 标准实例,采用随机初始化和CDS-NEH 方法的对比图,从图中可以明显看出改进后的初始解更优。

图3 初始解对比图
2.3 本地搜索
对于组合优化问题,每个最优解都是所有邻域结构下的局部最优解,本文基于传统IG 算法提供了两种本地搜索过程,一个用于产品,另一个用于作业。
(1)假设φ代表当前解,其产品序列为Δ={Δ1,Δ2,···,Δs},随机且不重复抽取1 个产品Δr将其插入Δ 中所有可能的位置,若所生成的邻域解中的最优解优于当前解(φ*<φ),则将当前解替换为最佳邻域解,重复这一过程,直到所有产品都被考虑,且没有更好的新解决方案生成。
(2)根据产品序列Δ 对每个产品的作业执行本地搜索操作,假设Δr中的作业序列为πr={πr1,πr2,···,πrn}。随机且不重复抽取πr中一道工序,将其插入所有可能位置并计算TF值,找到使TF 最小所生成的新序列,重复这一过程,直到所有工序都被考虑。
2.4 破坏与重构阶段
破坏阶段的设计是为了增加解的多样性,并为随后的局部搜索阶段增加搜索空间。首先针对产品,从当前产品序列Δ 中随机删除d个产品,得到两个产品序列ΔD和ΔR,然后随机删除序列ΔD中每个产品的α个作业,得到2 个作业序列。
在重构阶段,产品和工作将从破坏阶段被重新插入到剩余的解决方案中,以生成完整的解决方案。因此,与破坏阶段类似,重构阶段也分别针对产品和工作。首先将移除的产品序列ΔD中的产品插入序列ΔR中,每当插入1 个产品时,该产品删除的作业序列 πD r也将被插入到序列中。重复这一过程,直到生成1 个新的完整的解决方案。产品的插入规则为:假设要插入的产品是Dr,r∈{1,2,···,d},首先测试其插入到ΔR中每个可能位置时的TF值,然后比较这些TF值,最终将产品插入到TF值最低的位置,作业的插入规则与产品相同,具体操作步骤如下:

步骤4:每次插入后检测其TF值,产品最终将插入到TF值最低的位置,持续执行步骤3,直到生成一个完整的解决方案。
图4 所示[14]为1 个长度为5 的完整方案随机取出2 个工件,得到一个长度为3 的部分序列,将取出的工件逐个重新插入到序列中,插入过程中同时检验其TF值,重复这一过程,直到得到完整的解决方案。

图4 破坏重构操作示意图
2.5 选择和接受准则
选择机制每次在迭代开始时从解集ϑ中选择一个解φ,然后对其进行破坏,重构阶段,TF值和迭代次数经常被用作选择因子。因此,提出一种新的选择机制:在集合ϑ中随机选择两个解,然后选择TF值比较低的解或者选择迭代次数较小的解。
接受准则是用于判断算法通过局部搜索后生成的解是否可以进入集合ϑ。比较集合中最差的解决方案和新的解决方案的TF值。如果新的解决方案的TF值较低,并且与当前集合中的所有个体不同,那么将新的解决方案替换,并将其迭代次数增加1。否则,新的解决方案将被丢弃。
2.6 算法流程
根据上述描述,整个算法流程如图5 所示:

图5 改进IG 算法流程图
3 仿真实验
3.1 实验设置
算法程序是在Matlab2018b 进行编程,实验运行环境为Intel(R)Core(TM)i5-7300HQ 2.50 GHz 12 GB 内存的计算机。
为验证改进迭代贪婪算法求解DAPFSP 的有效性,本文选取文献[15]验数据作为参考,并对其进行修正和扩充,得到如下实验数据:工件数n={100},机器数m={5,10},工厂数F={4,6,8}和产品数s={30,40,50},一共18 组测试问题,每组实例包含10 个具有不同处理时间的实例。评价指标采用平均相对百分比偏差(average relative deviation,ARD)。

式中:TFbest表示最佳解决方案,每个测试独立运行20 次进行比较。因此,独立运行的数量R为20,TFr表示20 次独立运行中第r个实验的解。
3.2 参数设置
所提出的算法需要确定3 个重要参数,初始化生成种群中解的个数ω,在销毁阶段移除的产品数d以及在销毁阶段与移除的作业数有关的参数β。根据初步实验,将ω设置为6、8、10 和12 四个级别,d分为3、5、7 和9 四个级别,β分为1、2 两个级别。该算法参数校准共有32 种不同的配置,在测试过程中,为了避免结果出现过拟合现象,每组参数独立运行5 次,当运行时间大于(20×m×n)ms 时,算法退出迭代。最后,通过使用方差因素分析(ANOVA)方法研究实验结果,进而确定了算法最佳关键参数组合为:ω=6,d=5,β=2。
3.3 算法比较
为验证改进迭代贪婪算法的有效性,选取文献[16]中的竞争模因算法(competitive memetic algorithm,CMA),文献[4]混合生物地理学算法(hybrid biogeography-based ptimization,HBBO),文献[7]混合搜索的离散入侵杂草优化算法(hiscrete invasive weed optimization with hybrid search,HDIWO)和文献[17]种群迭代局部搜索算法(group iterated local search,GILS)进行比较,其中GILS 算法已被证实在求解DAPFSP 问题上优于单纯的IG 算法,每种算法在相同的时间下进行性能比较,运行停止标准都为(n×m×20)ms,对18组(每组10 个)实例均进行20 次独立实验,表2为18 组实例各算法平均ARD实验结果和每组实例中得到最优值的运行时间,图6 为对比算法95% 置信区间。

表2 各算法ARD 结果对比

图6 对比算法95%置信区间
由表2 可知,ARD值越小算法所得总流经时间性能越优,每组实例最佳结果用粗体标出。本文所提出算法在ARD值方面的性能明显优于其他4 种算法,仅在第8 组实例中平均ARD值与GILS 算法相等,在第3 组、第9 组和第13 组中得到最小TF值运行时间略大于GILS 算法,其余测试问题中都表现最好;GILS 算法表现仅次于所提出的算法,CMA 算法在5 种算法中表现最差。根据表2 中数据结果对比,绘制如图6 所示各算法类型的95% 置信区间,可以看出本文所提出的算法与CMA、HBBO、HDIWO 和GILS 有显著差异。
为了更详细地分析特征之间的关系,图7~9 分别绘制了算法类型与m、f和s之间的95%置信水平显著差异的交互图。从图5 中可以清楚地看到,当机器数较小时,各种算法的ARD 表现得更好。从图7~8 可知,工厂和产品的数量越多,这3 个因素对IIGA 的影响小于其他4 种算法,实验结果更优。

图7 算法类型与m 置信区间交互关系
综上,本文通过提出一种IIGA 解决DAPFSP问题,且在上述测试问题中取得较好的结果。实现了协调各个不同工厂的任务分配,进行合理的资源能力配置,有效降低了分布式车间调度中企业的生产成本。为解决新型DAPFSP 提供了一种新的途径和方法。
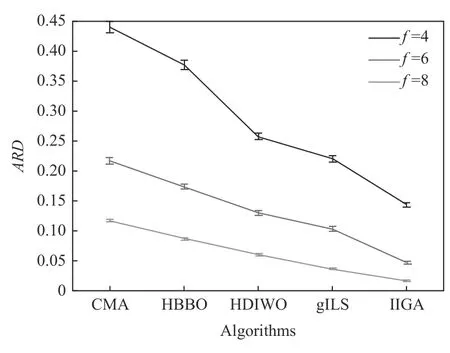
图8 算法类型与f 置信区间交互关系
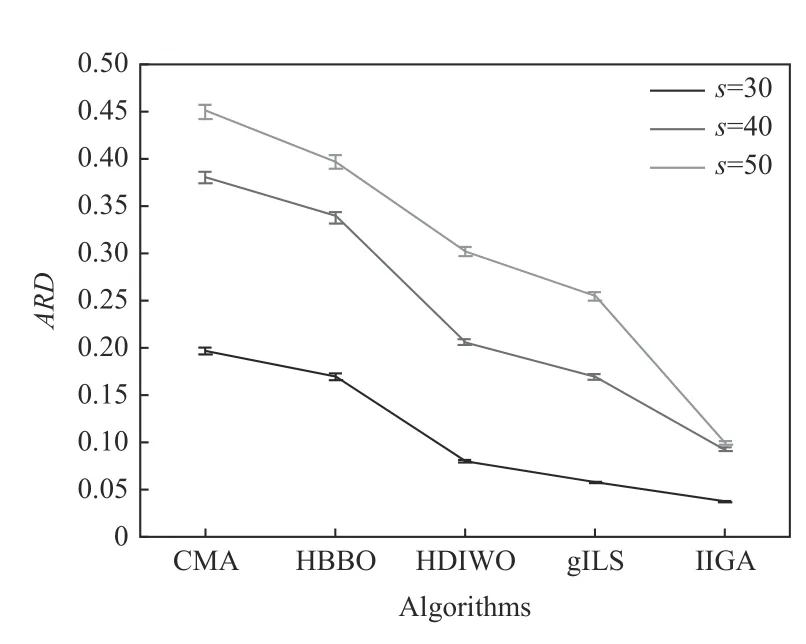
图9 算法类型与s 置信区间交互关系
4 结语
本文针对分布式装配置换流水车间调度问题,建立基于改进的迭代贪婪算法的分布式装配置换流水车间调度模型。针对传统IG 的缺点,提出一种新的初始化方法,提升初始解的质量;设计了一种新的破坏重构过程,同时考虑工厂之间和工厂内的分配规则,扩大了搜索空间,提高了种群的多样性;最后,通过180 个不同规模的仿真实例进行比较,验证了本文提出的改进的迭代贪婪算法求解DAPFSP问题的有效性。本文所提出算法还具有一定的局限性,如改进的迭代贪婪算法在初始化阶段只生成一组解,会导致种群中的个体之间高度相似,不利于后续的搜索和优化,且初始化时间过高,今后可以从该方面做深入研究。
