半结构装配数据的知识抽取及机床装配知识图谱构建方法研究
2022-11-10尹昱东王保建
尹昱东 王保建
(西安交通大学机械工程学院,陕西 西安 710049)
机床装配信息分布分散,格式众多,不易于数字化管理,且对工人装配水平要求高,理清装配零部件之间的相互关系需要长时间的人工分析。
知识图谱可以将机床当中的零部件信息以及部件之间的关系以图谱的形式展示,能够更为有效获悉零部件周围相连的部件信息以及当前零件定位细节,又可以辅助工厂数控机床装配,解决装配数据分散、无规范以及装配效率低下等机床现状问题。
机床装配知识图谱构建过程中的主要难点在于:数据来源、知识抽取和知识推理。本文采用以3DXMLl 格式数据为数据基础,使用SAX 解析器从装配体信息流当中提取实体信息和装配信息,并将文件内容信息分为实体属性信息和实体关系信息,使用基于图的结构,完成知识推理环节,实现从原先的两种关系衍生出新的关系,丰富知识库的内容,最后使用Neo4J 完成装配信息的知识图谱构建,实现以图的形式展示装配信息。通过该知识图谱,操作人员无须掌握专业知识就可以很好地了解机床内部结构。此外,将分散的信息集中存储到图数据库当中,有利于工厂实现数字化管理。
1 研究背景
1.1 知识图谱
为了提高搜索引擎的性能,Google 公司在2012 年正式提出知识图谱的概念[1],实现互联网知识的有效利用,为搜索引擎实现语义化搜索与知识互联引出新的路径[2]。通过图的结构,实现从数据当中提取实体、关系等信息,建立基于事务之间的关系模型。在那之后,多个知识图谱相继诞生,常见的通用知识图谱有Freebase、Wikidata、DBpedia和YAGO 等[3-4]。行业知识图谱有IMDB、MusicBrainz和ConceptNet。国内知名度高的知识图谱有阿里巴巴与浙江大学团队开发的面向淘宝服务平台的知识图谱,其中实现了基于客户购买记录的商品推荐系统、商品搜索引擎以及小蜜的智能问答系统。
知识图谱的构建技术主要集中在知识抽取、知识表示、知识融合以及知识推理这4 个环节,其中知识提取主要指的是从开放数据领域当中实现自动抽取所需要的知识。知识抽取包括实体抽取、关系抽取以及属性抽取。
1.2 装配领域知识图谱
知识图谱在制造业和工业领域还处在初探阶段,装配知识图谱属于专业知识图谱,具有行业壁垒高、专业性强等特点,并且由于装配相关数据来源复杂,有结构化数据、非结构化数据和半结构化数据3 种,本文主要针对半结构数据构建装配知识图谱进行尝试,研究思路如图1 所示。

图1 半结构数据构建知识图谱研究思路
确定知识图谱装配模型的信息组成形式为“实体-关系-实体”和“实体-关系-属性”两种三元组,使用以上两种三元组来表达装配体的实体信息与装配信息。同时将装配元素定义为总装配体、子装配体和零件。
2 半结构数据获取
2.1 数据来源
装配数据主要以半结构化数据为主,如三维模型,其次是大量分布在装配文档的非结构化数据。
装配模型的文件格式有很多,比如DWG、STL,但这些格式大文件庞大,而且有些没有装配信息,如STL 格式,STL 格式删除装配信息,保留模型信息和数据量高的几何实体信息,但文件仍然很大,不利于装配图谱的构建。而3DXML 文件只保留模型实体信息和装配信息,采用ZIP 算法对模型进一步压缩,其具体文件组织结构如图2 所示。通过3DXML 格式保存的三维模型具备充分的装配信息且所需内存少。

图2 3DXML 多文件组织结构图
另外,可以使用XML 接口进行文件解析,装配信息集中分布在描述产品结构树的文件当中。因此,可以使用3DXML 作为数控机床装配信息知识图谱的数据来源。
2.2 3DXML 文件解析
在3DXML 文件中关于装配信息主要有<Reference3D>、<Instance3D>、<IsAggregatedBy>、<IsInstanceOf>,其 中 <Reference3D>引 用 节 点 和<Instance3D> 实例节点描述零件、装配体的实体信息,<IsAggregatedBy> 和 <IsInstanceOf> 描述装配信息[5]。为了方便解析,本文将<IsAggregatedBy>命名为关系标签1 号,<IsInstanceOf>命名为关系标签2 号。
实例节点既是某一引用节点的组成部分,同时也是另一个引用标签的实例,这两个不同引用节点的ID 属性值分别存储在实例节点的关系标签1 号子节点和关系标签2 号子节点中[6],如图3 所示,这个思想也是解析3DXML 文件的关键。
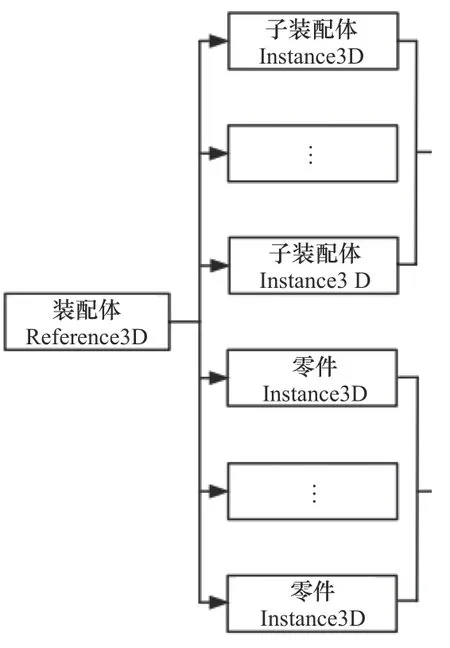
图3 装配文件结构图
在这一环节,需要准备3DXML 文件,通过使用SoildWorks 三维建模软件将事先准备好的数控机床三维装配模型转换成3DXML 格式,之后使用反ZIP 算法对3DXML 文件解压,得到表示三维模型实体信息和装配信息的一系列文件,为下一步知识抽取环节做准备。
3 装配知识抽取
3DXML 以XML 为基础,可以通过解析XML文件的解析器进行解析,提取实体信息和装配信息,本文使用了常用的SAX 解析器。SAX 解析器采用顺序的方式依次访问XML 文件当中的标签,其中会用到3 个主要的重载函数,具体如表1 所示。解析器读取不同XML 标签标记时会执行相应的操作,例如访问开始标记,会执行startElement 函数。通过重载函数,可以存储保留在标签内的装配实体信息,通过characters 函数记录建模时产生的零件特定编号,通过编号来区分不同零件,同时也是用来抽取零件装配信息的关键。
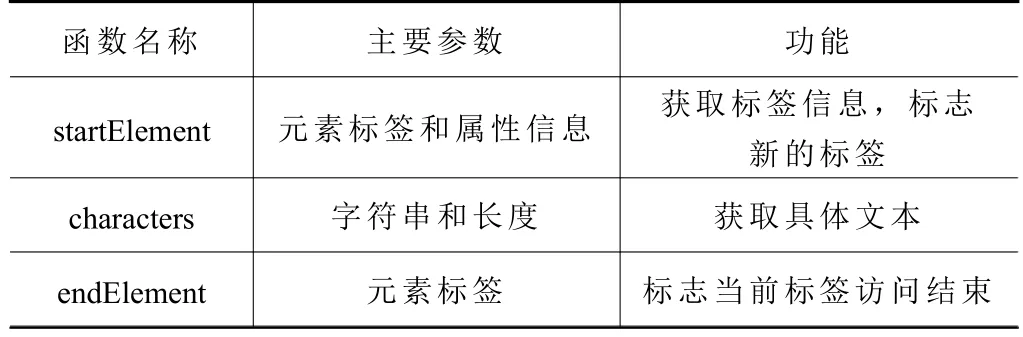
表1 SAX 解析主要重载函数表
SAX 访问描述实体信息标签(包括引用节点和实例节点),记录实体信息,包含零件编号、零件名、零件类型,得到实体属性三元组,同时由于实例节点标签内部还有两层描述关系的标签,因此当访问到实例节点还需记录描述关系信息的编号,最终得到实体关系三元组,具体的SAX 解析流程如图4知识抽取流程图所示。
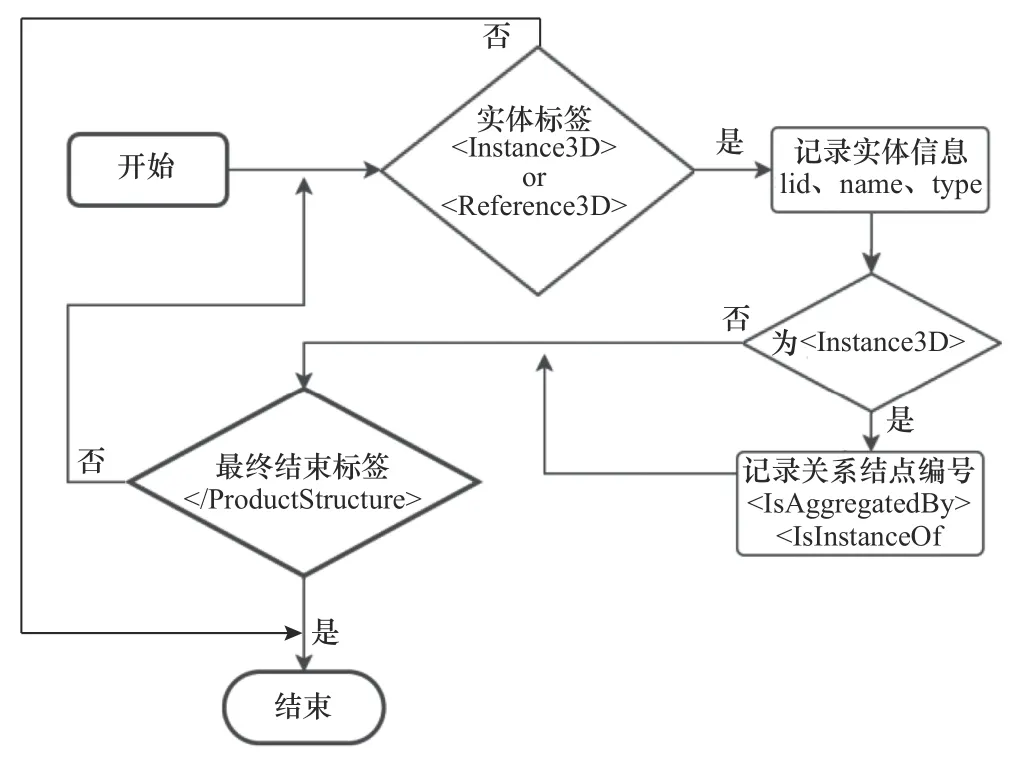
图4 知识抽取流程图
通过上述操作,单一数控机床模型得到177 个实体三元组和197 个关系三元组,结果如表2 和表3所示,数据来源模型如图5 所示。

图5 数控车床三维模型

表2 部分关系提取结果

表3 部分实体属性提取结果
其中,表2 记录实体关系信息,第一列代表装配关系起始实体,第二列为装配关系的终止实体,第三列为两个实体之间的关系。表3 记录实体属性特征信息,第一列代表每个实体特定的编号,该标号用来区分不同的实体,对应独一的实体,既可以通过实体找到编号,也可以通过编号找到对应的实体。第二列为实体的名称信息,第三列代表该实体的属性信息,指明当前实体是引用实体还是实例实体。
4 知识推理
知识推理可以从知识库当中的关系数据推理得到新的关系,能够丰富知识网络。通过知识抽取环节得到的三元组信息并不能完整展示零部件、子装配体以及总装配体之间的关系。知识推理相关方法[7]如图6 所示。
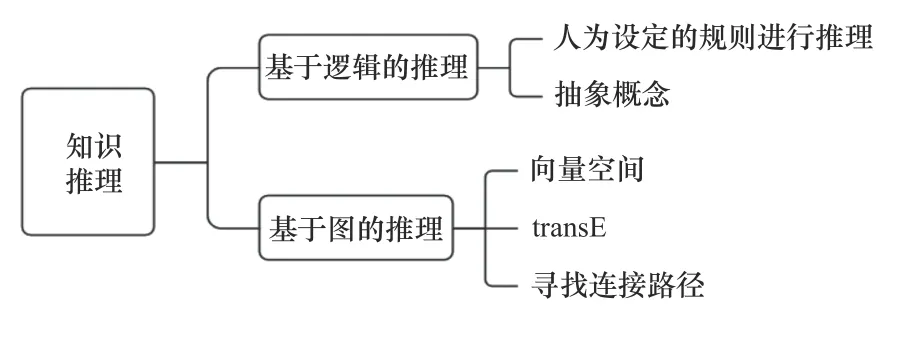
图6 知识推理方法
从表3 中的实体属性提取结果不难发现只有两种关系不易于图谱关系理解。因此需要进一步知识推理,依靠这两种关系推理出包含hasPart 和被包含partOf 两种关系。知识推理有基于逻辑的推理和基于图的推理。基于逻辑的推理主要是根据人为规定的规则进行推理,适用于抽象概念。而基于图的推理是使用神经网络模型,将知识映射到向量空间,使用神经张量网络模型进行关系推理[8]。常见的transE 模型,其核心理念是实体1 向量与关系1 向量相加得到实体2 向量,那么实体1 和实体2 之间存在关系1。也有采用图的形式,如图7 所示,寻找两个实体间是否存在一条连通路径,来推测两者当中潜在的关系,例如(X,hasPart,Y),(Y,hasPart,Z),据此可以推理X 包含于Z[9]。

图7 图推理
本文采用基于图的方式进行推理,在将上文提到的两种三元组导入Neo4J 数据库当中之后,采用深度优先探索策略,挖掘潜在关系,通过实例节点以及其周围的关系1 号标签和关系2 号标签来推测实例节点周围的引用节点之间的关系,最终推测出潜在的hasPart 和partOf 两种包含与被包含关系,具体推理流程图如图8 装配结构类节点关系推理所示,推理结果如图9 所示。
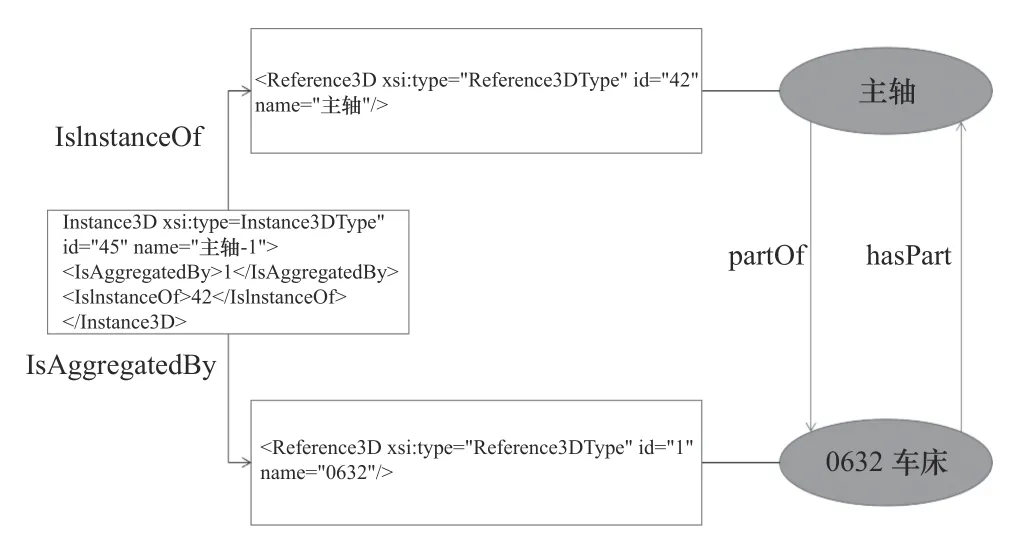
图8 装配结构类节点关系推理
5 知识存储与可视化表达
三元组是构建知识图谱的核心,常见的知识图谱如维基百科拥有上百亿的三元组。本文采用Neo4J 图数据库存储三元组数据,借用其专业平台来构建机床装配知识图谱,三元组信息以csv 格式存储,并存放于import 路径,使用LOAD CSV 方式导入数据库,使用Cyther 语言实现图谱可视化。部分知识图谱如图10 所示。从图10 中不难发现,图谱通过单向边展示了零件与装配之间的关系,记录尾座、主轴、相关垫圈与机床的关系,同时还记载着尾座子装配体内部零件信息。

图10 部分装配图谱展示图
6 结语
本文首先介绍了机床装配信息的来源,比较了不同CAD 模型存储格式,分析了选择3DXML 作为半结构化装配数据来源的原因,随后使用SAX从装配模型文件抽取实体以及装配关系信息,通过基于图的推理方式丰富知识网络,推测出零件、子装配体以及总装配体之间的关系,最终采用Neo4J实现知识存储,以及知识图谱的可视化表达,完成数控机床装配知识图谱的构建。
机床当中的零部件信息以及部件之间的关系以图谱的形式展示,能够更为有效地获悉零部件周围相连的部件信息以及当前零件定位细节,又可以辅助工厂数控机床装配,解决装配数据分散、无规范以及装配效率低下等机床现状问题。
