基于多特征语义匹配的知识库问答系统
2020-08-06赵小虎赵成龙
赵小虎,赵成龙*
(1.矿山互联网应用技术国家地方联合工程实验室(中国矿业大学),江苏徐州 221008;2.中国矿业大学信息与控制工程学院,江苏徐州 221116)
(*通信作者电子邮箱zhaochenglong@cumt.edu.cn)
0 引言
随着大规模知识库的出现,基于知识库问答(Question Answering over Knowledge Base,KBQA)研究得到了快速发展。知识库(Knowledge Base,KB)是一种专门用来存储结构化知识的数据库系统,结构化知识通常被叫作三元组(主语、谓语、宾语),其中主语和宾语代表知识库中的节点,谓语被用来连接主语和宾语。知识库中大量三元组的连接构成一个有向图,主语和宾语代表图中的节点,谓语是从主语指向宾语的有向边。如何根据知识库中海量的事实三元组来实现知识问答成为目前研究的热点,基于知识库问答任务在于根据用户提出的自然语言问题从知识库中得到匹配的事实三元组,并返回三元组中的宾语作为问题的答案。由于自然语言问题表达的多样性,它与知识库中结构化的三元组事实存在语义差异,比如问题“王辉是干什么的”,可以通过知识库中的三元组“王辉|||职业|||广东省广播电影电视局官员”来回答。但是“职业”跟“干什么的”之间的语义联系机器很难捕捉。
现有的方法大多将知识问答任务分为实体识别和谓语匹配两部分。首先根据实体识别得到问题的核心主题,然后将核心主题与知识库中的主语节点进行链接,检索得到与核心主题相关的所有三元组为问答任务的候选三元组。然而实体识别的错误引起的误差传播导致所有的相关三元组都是错误的,从而无法获取问题的正确答案。在谓语匹配时将候选三元组中的谓语和问题(去掉核心主题)映射到同一语义空间的高维语义向量,然后通过语义向量的相似度来衡量谓语和问题的匹配程度,该方法并没有将答案的信息加入到语义匹配中去,从而丢失了部分语义信息。针对上面问题,本文提出的系统的创新性主要在于:1)提出一种端到端的解决方案,通过BM25 算法[1]来计算问题和知识库中三元组的相关性来生成候选三元组,从而有效避免实体识别错误带来的错误传播;2)由于部分三元组的宾语也和问题具有语义相关性,把答案信息加入到三元组和自然语言问题的语义匹配中,来提高匹配的精度;3)提出多特征语义匹配模型,分别通过双向长短时记忆网络(Bi-directional Long Short Term Memory Network,Bi-LSTM)和卷积神经网络(Convolutional Neural Network,CNN)捕捉问题和三元组语义相似度和字符相似度,并通过融合来对三元组进行排序,最后在NLPCC-ICCPOL 2016 KBQA 测试集上的平均F1达到了80.35%,接近了现有最好办法的性能。
本文的知识问答系统如图1 所示,首先给出问题“你可以告诉我虎门销烟的时间吗?”,通过BM25 算法在知识库中进行检索得到的部分候选三元组如图1 左下方所示。然后根据多特征语义匹配模型(Multi-Feature Semantic Matching Model,MFSMM)进行候选三元组排序,发现最相关的三元组为“虎门销烟|||时间|||清朝道光年间”,从而得到问题的最终答案“清朝道光年间”。
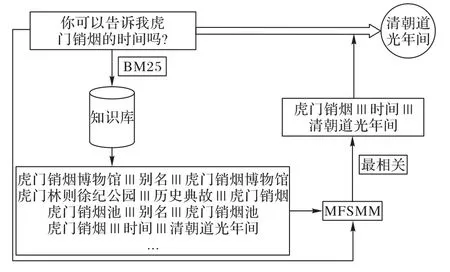
图1 知识问答架构Fig.1 Architecture of KBQA
1 相关工作
知识问答中候选三元组生成的方法主要包括两种:语义解析和序列标注。Berant 等[2]通过解析器将输入的问题解析为逻辑表达,再基于这种结构化的表达从知识库检索出候选三元组;Yih 等[3]通过将语义解析转换成查询图的生成,利用simpleλ-DCS 来缩小候选三元组搜索的范围;Zettlemoyer 等[4]以及Wong 等[5]提出了基于词典学习的问答方法,这些方法需要人工标注和固定模板的构建。上述语义解析的方法都需要详尽的语义推理,无法在问答中做到完善。在序列标记方法中,翟社平等[6]应 用Bi-LSTM 和条件随机场(Conditional Random Field,CRF)来进行命名实体识别虽然极大地提高了准确率和可扩展性,但是实体识别的错误会导致错误传播。
自然语言问题和事实三元组匹配的方法通常通过语义相似度模型来进行计算。语义相似度模型首先利用神经网络对问题和候选三元组进行深层语义向量的计算,随后通过余弦相似度等来衡量语义向量之间的相似性来找到最佳匹配。例如,Bordes 等[7]使用记忆网络将问题和事实三元组编码到相同的表达空间,并对它们的相似性进行评分。Yin等[8]使用两个独立的带有注意力最大值池化的字符级和单词级CNN 模型进行相似性计算。Dai 等[9]提出一种通过前后两步来进行条件概率估计问题,并使用双向门控循环单元(Bi-directional Gated Recurrent Unit,Bi-GRU)网络来实现问题和关系的匹配。
由于NLPCC-ICCPOL 2016 KBQA任务中发布了大规模的中文知识库,基于中文知识库的知识问答得到了发展。Wang等[10]使用了卷积神经网络和门控循环单元(Gated Recurrent Unit,GRU)模型对问句进行语义层面的表示;Yang 等[11]先通过特征工程来挖掘特征,再使用梯度提升决策树(Gradient Boosting Decision Tree,GBDT)模型对命名实体进行研究,最后结合了朴素贝叶斯和支持向量机(Naive Bayes and Support Vector Machine,NBSVM)以及卷积神经网络进行谓语映射;Lai等[12]使用基于词向量的余弦相似度计算,并利用多种人工构建的规则和特征,最后也取得了不错的结果。
2 系统介绍
系统主要由两部分组成:候选三元组生成和候选三元组排序。为了避免传统命名实体识错误带来的误差传播,首先通过BM25 算法直接计算问题和知识库中三元组的相关性来生成候选三元组;然后通过本文提出的多特征语义匹配模型进行三元组的排序,MFSMM分别通过Bi-LSTM和CNN实现语义相似度和字符相似度的计算,并通过融合来对三元组进行排序
2.1 候选三元组生成
在NLPCC-ICCPOL 2016 KBQA数据集中事实三元组一共大约43 000 000 个,受Gupta 等[13]启发,在候选三元组生成时应用BM25过滤出相关性得分最高的k个事实三元组,有效减少候选三元组的数量。
定义自然语言问题和事实三元组的相关性得分如式(1)所示:

其中:S(Q,T)代表自然语言问题和事实三元组的相关性得分,R(Qi,T)代表问题中的第i个字符Qi和三元组T的相关度值,wi代表字Qi的权重,通过其在整个文档空间中的IDF(Inverse Document Frequency)值来设置wi。
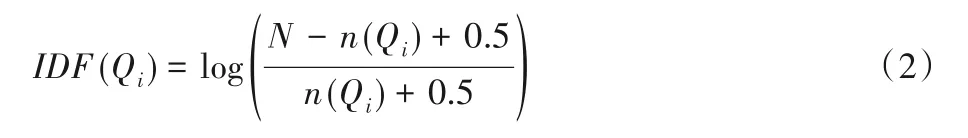
其中:N是三元组的总数,n(Qi)代表包含字Qi的三元组的总数。
问题中的字Qi和三元组T的相关度值如式(3)所示:
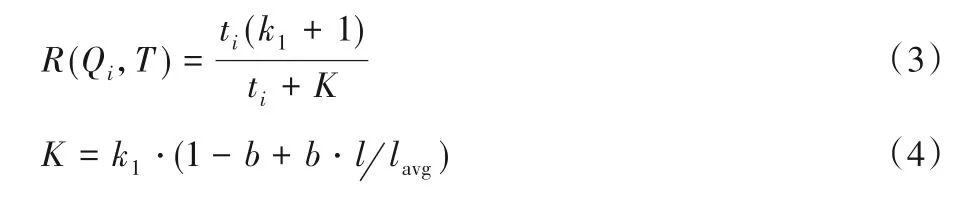
其中:k1和b是设置的先验参数,k1用来表示Qi在三元组T中出现次数的影响程度,b主要用来调节三元组长度对结果的影响程度,本文设置k1=2,b=0.75。ti代表Qi在三元组T中出现的次数。l和lavg分别代表三元组T的长度和所有知识库中所有三元组的平均长度。
2.2 候选三元组排序
传统问答方法在三元组排序时将三元组中谓语和问题进行语义匹配。如图1中的问题“你可以告诉我虎门销烟的时间吗?”,传统方法首先识别问句中的命名实体“虎门销烟”,然后通过知识库可以检索到“虎门销烟”相连的谓语为“时间”“地点”等,再进行问题和谓语的匹配实现排序。
本文提出端到端的三元组排序模型(MFSMM)将答案的信息加入到模型中,直接匹配问题和三元组的相关性。例如图1中“虎门销烟|||时间|||清朝道光年间”中的答案“清朝道光年间”和问题“你可以告诉我虎门销烟的时间吗?”之间也有语义相关性。
2.2.1 语义相似度
首先将自然语言问题和事实三元组转换成Qv=两个序列,其中是问题的第m个字符的嵌入向量,eTn是三元组第n个字符的嵌入向量,m和n分别是问题Q和三元组T的长度。然后通过Bi-LSTM 提取问题和三元组的语义特征,其中Bi-LSTM 由两个LSTM 拼接而成包含一个正向输入序列和反向输入序列来同时考虑了上下文的序列内容,将Qv和Tv分别输入到Bi-LSTM模型提取问题和三元组的语义特征。对于问题Q第i时刻的语义特征qi提取过程如式(5)~式(7)所示:

同样三元组T的语义特征tj提取过程如式(8)~式(10)所示:

如式(11)、式(12)所示,通过连接各个时刻问题和三元组的语义特征得到各自的语义矩阵HQ和HT。

其中:qm表示问题在第m时刻的语义特征,tn表示三元组在第n时刻的语义特征,m和n分别是问题和三元组中字符的长度。
问题和三元组的全局语义向量根据语义矩阵在上下文的最大池化生成。问题的全局语义向量表示为vQ,三元组的全局语义向量表示为vT。

为了能够从多种维度来捕获自然语言问题和三元组之间的语义相关性,模型分别通过v1、v2和v3获取它们之间的联系,并通过全连接层(Fully Connected Layer,FCL)自动学习和组合特征,最后得到问题和三元组的语义相似度z1如式(15)所示:

其中:v1是问题和三元组全局语义向量的绝对差|vQ-vT|,v2代表向量之间的点乘|vQ⊙vT|,v3代表向量之间的绝对占比|vQ/vT|。其中为图2中全连接网络中随机初始化第一层和第二层网络的权重矩阵和偏置,σ为激活函数ReLU(Rectified Linear Unit)[14]。
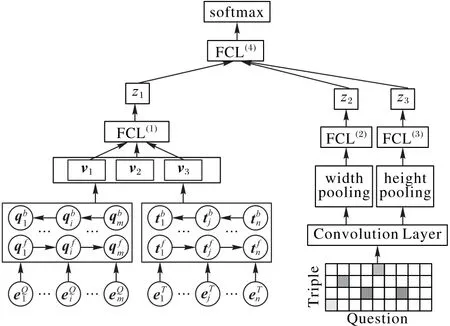
图2 多特征语义匹配模型Fig.2 Multi-feature semantic matching model
2.2.2 字符相似度
除了上述提取的问题和三元组语义相似度特征外,受韩萍等[15]的启发,本文将字符相似度的特征应用到中文知识库问答中去。首先构建字符相似度矩阵S捕捉字符之间的相似度,其中sij如式(16)所示代表问题中第i个字符和三元组中的第j个字符之间的相似性,即之间的内积,分别代表问题第i个字符和三元组第j个字符的嵌入向量。

其中:⊗代表向量之间的内积,然后通过卷积层提取字符匹配特征。
特征提取过程如图3 所示,例如针对问题“西游记属于什么类型的书呢”和三元组“西游记|||类型|||奇幻”建立字符相似度矩阵,其中黑色代表字符之间的相似性,颜色程度代表两者的相似程度,通过如图3中所示不同的卷积核(虚线框内)来提取特征dk。
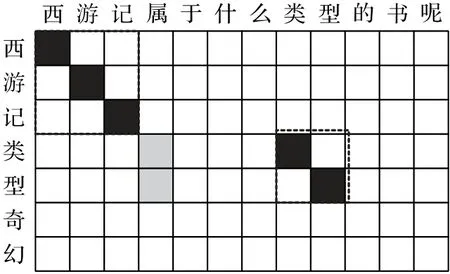
图3 字符相似矩阵Fig.3 Character similarity matrix
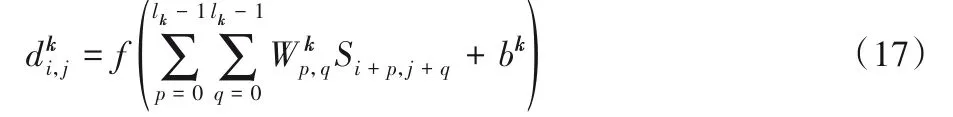

通过全连接网络生成字符相似度特征z2和z3如式(20)、式(21)所示。

2.2.3 融合
通过图2中全连接网络FCL()4 融合语义相似度特征和字符相似度特征如式(22)所示:
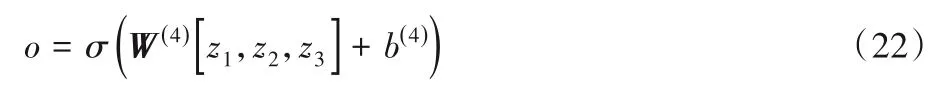
其中:σ表示Sigmoid函数,z1为语义相似度特征,z2和z3为字符相似度特征,W(4)和b(4)为图2中全连接网络FCL(4)随机初始化的权值矩阵和偏置。
3 实验和评估
将数据集分前80%作为训练集,剩余20%作为验证集,其中训练集、验证集和测试集的数目分别为11 536、2 884 和9 542。保存在验证集上效果比较好的模型在测试集上评估。
在训练过程中,目标是最小化训练集中所有问题属性的交叉熵。
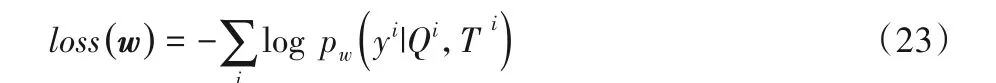
其中:Qi和Ti分别表示训练集中的自然语言问题和候选三元组的样本;yi表示该候选三元组是否是问题的答案;w代表模型中的所有参数;pw为三元组是问题答案的概率值,是通过上面融合后的输出o经过softmax函数归一化后的概率值。通常通过第一步候选三元组生成后的三元组数目为n,其中只有一个答案是正确答案,针对本题a个问题即有a×n个样本,其中只有a个样本是正样本。
实验在Ubuntu 16.06 系统中进行,其中CPU 为i7 6700k,GPU 为GTX1080Ti。模型训练过程在GPU 上开展,实验的代码采用Tensorflow深度学习框架。
在实验中输入词向量的维度为200,MFSMM中使用双向LSTM中每个方向的单元数为80,隐藏节点维度为100,CNN模型卷积核的尺寸为g×g,其中g的取值为3,使用16种不同的颜色通道;参数优化使用Adam 优化器,设置其学习率为0.000 5;Batch Size 设置为64。根据官方给出的评价指标为平均F1值,由于每个样例的标准答案样例的标准答案和候选答案均为集合的形式,因此每个样例都可以得到一个F1 值,最后取所有样例F1值的平均值作为结果(见表1)。

表1 训练集、验证集、测试集的平均F1 单位:%Tab.1 Average F1 value on training,validation and test sets unit:%
为了验证该系统的先进性,分别将经典的文本语义匹配模 型Bi-LSTM[16]、双向LSTM结合注意力机制(Bi-LSTM Attention,Bi-LSTM_ATT)[17]、增 强LSTM(Enhanced LSTM,ESIM)[18]、卷积神经网络对排序(Pairs with CNN Ranking,PairCNN Ranking)[19]、基于注意力机制的CNN(Attention-Based CNN,ABCNN)[20]在该数据集上进行实验,实验结果如图4所示。
对比经典语义匹配模型和其他论文在该数据集上的表现,如表2所示,本文模型取得了较好的表现。
如表2 所示,对比经典的基于循环神经网络以及融合注意力机制的模型如Bi-LSTM、Bi-LSTM_ATT 以及ESIM,本文模型平均F1 值分别提高了10.40、8.85、8.50 个百分点;对比基于卷积神经网络和注意力机制的模型PairCNN Ranking 和ABCNN 分别提高了5.98、3.90 个百分点。本文模型在该数据上的表现远远优于经典文本匹配模型在该数据上的表现。
同时对比在该数据集上发表的论文(Wang 等[10]和Xie等[21]),分别提高了1.21、0.78 个百分点。该数据集上现有最好的方法[12]的评测结果为82.47%,但是它通过复杂的数据清洗、规则和构建模板等方法,耗费了大量的人工,本文在没有使用复杂人工特征的情况下取得了相当的效果,验证了本文模型的有效性和可扩展性。

图4 经典文本语义匹配模型和本文模型在NLPCC-ICCPOL 2016 KBQA数据集上的性能Fig.4 Performance of traditional text semantic matching model and the proposed model on NLPCC-ICCPOL 2016 KBQA dataset
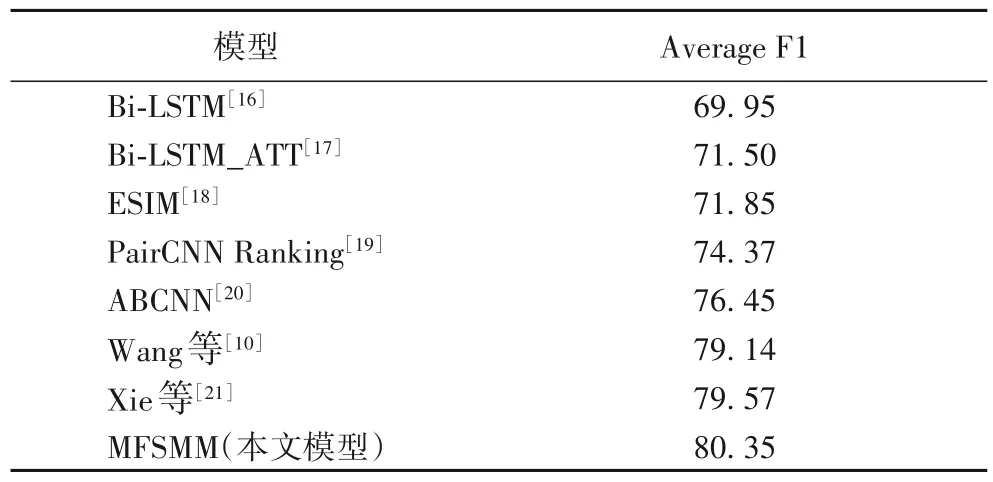
表2 NLPCC-ICCPOL 2016 KBQA数据集上平均F1值的对比 单位:%Tab.2 Comparison of average F1 value on NLPCC-ICCPOL 2016 KBQA dataset unit:%
除了模型在重要指标F1上的对比,本文还在训练时间和预测时间上进行了对比,如表3 所示。因为本文组合了Bi-LSTM和CNN,所以训练和预测时间高于Bi-LSTM以及以CNN为基础模型的PairCNN Ranking,但是在核心指标F1上分别高了10.40个百分点和5.98个百分点。对比使用了注意力机制的模型Bi-LSTM_ATT、ESIM 和ABCNN 本文在时间和核心指标上都具有先进性。

表3 NLPCC-ICCPOL 2016 KBQA数据集上训练和预测时间的对比 单位:sTab.3 Comparison of training time and predication time on NLPCC-ICCPOL 2016 KBQA dataset unit:s
4 结语
现有的知识问答方法大多将该任务分为实体识别和谓语匹配,但是命名实体识别的错误直接影响到后面的谓语匹配和答案检索。在谓语匹配时仅通过匹配谓语和问题(去实体后)的高维语义向量之间余弦相似度或者全连接网络进行相似度的计算,这样会丢失部分语义相似度信息。为了解决上述的问题,本文提出端到端的解决方案直接匹配自然语言问题和三元组的相关性来避免命名实体识别的误差传播;同时在候选三元组排序阶段充分利用问题和三元组的语义相似度和字符相似度信息,并将答案的信息加入到模型中进一步提高了知识问答的准确率。最后在NLPCC KBQA 2016 数据集的平均F1 值达到了80.35%,接近了现有最好的办法。相比最好方法通过复杂的规则和构建别名词典等方法,需耗费大量的人工,本文仅通过简单的处理,模型结构也没有堆叠很深的网络,证明了模型的可用性和扩展性。
