融合用户-项目的邻居实体表示推荐方法
2022-11-07季德强王海荣李明亮钟维幸
季德强,王海荣,李明亮,钟维幸
(北方民族大学 计算机科学与工程学院,宁夏 银川 750021)
0 引言
大数据背景下,为帮助用户从海量数据中快速、准确地获取感兴趣的信息,推荐算法发挥着重要的作用。Rendle 等人[1-2]最早使用矩阵分解方法(Bayesian Personalized Ranking from Implicit Feedback,BPR)和因子分解机方法(Factorization Machines with libFM,LibFM)进行推荐实验,BPR利用用户和项目的交互学习向量表示;LibFM 使用基于推荐预测分量的贝叶斯排序模型,实现了三种数学算法与推荐的结合,证明了模型的性能和可行性。He等人[3]提出了一种新型神经因子分解机模型(Neural Factorization Machines for Sparse Predictive Analytics,NFM),将用户历史与项目分解为用户-项目交互对,并利用神经网络预测点击率。Cheng等人[4]将传统的宽度线性通道与深度非线性通道结合成一种深度和宽度网络推荐模型(Wide&Deep Learning for Recommender Systems,Wide&Deep),使模型同时拥有记忆和泛化能力,并在实际应用场景Google Play上进行了验证。
上述基于矩阵分解或深度学习网络的推荐方法存在数据稀疏和冷启动问题,而将知识图谱作为辅助信息的推荐方法可以很好地避免此类问题。因此,基于知识图谱的路径、嵌入、混合推荐算法研究受到广泛关注。Yu等人[5]提出了基于异构网络的个性化元路径推荐方法(Personalized Entity Recommendation:A Heterogeneous Information Network Approach,PER),在异构信息网络中提取元路径特征来表示用户和项目之间的连通性,推荐结果可由原始项目沿元路径查找,推荐具有语义可解释性。Ma等人[6]构建了联合优化的可解释性推荐模型(Jointly Learning Explainable Rules for Recommen-Dation with Knowledge Graph,RuleRec),根据路径传播方法来挖掘项目之间的关联规则。Zhang 等人[7]提出的协同知识库嵌入模型(Collaborative Knowledge Base Embedding for Recommender Systems,CKE),在知识图谱中融合协同过滤方法提取结构性知识、文本知识和视觉知识丰富用户表示。Wang等人[8-9]设计了嵌入情感的签名异构信息网络模型(Signed Heterogeneous Information Network Embedding for Sentiment Link Prediction,SHINE)和深度感知网络模型(Deep Knowledgeaware Network for News Recommendation,DKN),SHINE可在异构网络中提取用户的潜在表示以挖掘隐藏的用户兴趣;DKN 使用多通道单词与实体对齐的卷积神经网络(KCNN),结合实体嵌入和单词嵌入扩展用户表示。混合推荐模型中实体传播模型[10](Propagating User Preferences on the Knowledge Graph for Recommender systems,RippleNet)通过汇集用户历史实体在图谱传播的邻域实体扩展实体集,叠加形成用户相对于候选项的偏好分布。基于标签传播算法的图神经网络推荐模型[11](Knowledge-aware Graph Neural Networks with Label Smoothness Regularization for Recommender Systems,KGNN-LS)结合图神经网络和知识图谱提出标签传播算法,探索用户和项目的关系,挖掘用户的细粒度兴趣。图注意力网络推荐模型[12](Knowledge Graph Attention Network for Recommendation,KGAT)将用户二部图与知识图谱连接,通过图卷积网络(Graph Convolutional Network,GCN)分别聚合用户、项目嵌入,并挖掘用户和项目的关系。基于负采样的知识图谱推荐模型[13](Reinforced Negative Sampling Over Knowledge Graph for Recommendation,KGPolicy)首次将负采样模型与知识图谱融合,利用知识图谱挖掘负样本。推荐模块仅用矩阵分解方法就实现了推荐性能的大幅提升。
综上可知,传统的协同过滤和基于深度学习的推荐方法存在数据稀疏和冷启动问题,基于知识图谱的推荐方法虽然在一定程度上可以解决此类问题,但多数采用挖掘路径和单一的用户或项目表示方法,特征嵌入表示不能准确拟合用户兴趣,导致模型的次优表示。只有同时针对用户和候选项表示,并探索实体间的关系,才能挖掘出更深层次的用户兴趣。因此,本文使用GCN 方法聚合项目嵌入表示,使用实体传播方法扩展用户嵌入表示,通过注意力机制关注用户和项目的相对关系,达到将用户兴趣放大、项目噪声减少的目的,进而实现细粒度推荐。
1 汇集邻居实体的表示推荐方法
本文方法通过用户历史实体传播与候选项实体聚合图谱实体以扩充用户特征空间,在实现用户兴趣挖掘的同时,防止数据稀疏和冷启动问题。实体传播是将用户历史项目映射为知识图谱的实体,利用距离翻译模型TransR 在知识图谱中传播,扩展用户的嵌入表示;实体聚合利用GCN 网络聚合知识图谱中候选项目实体周围的邻居实体扩展项目嵌入表示。方法模型如图1所示。
图1中,实体传播是以用户u的交互历史项目作为输入,将其通过实体映射文件映射到知识图谱,并作为最初的扩展源实体,源实体被视为三元组的头实体,传播方式是使用TransR 模型表示头实体、关系和尾实体。同时,注意力权重的获取等价于尾实体相对当前用户的重要性分值,将权重加权在尾实体上,获得一次用户传播实体集的表示,迭代传播k次,将每层实体表示累加得到u的嵌入表示。实体聚合是将项目v映射为知识图谱的实体并将v视为被聚合对象,采样距该项目实体为k及以内的实体集,每层实体使用GCN 从最外层向内聚合k次,获得项目嵌入表示。聚合过程中同样需要计算项目与用户的重要性权重,并加权到每个聚合对象中。最终,将用户嵌入表示与项目嵌入表示通过内积运算计算候选项分值。
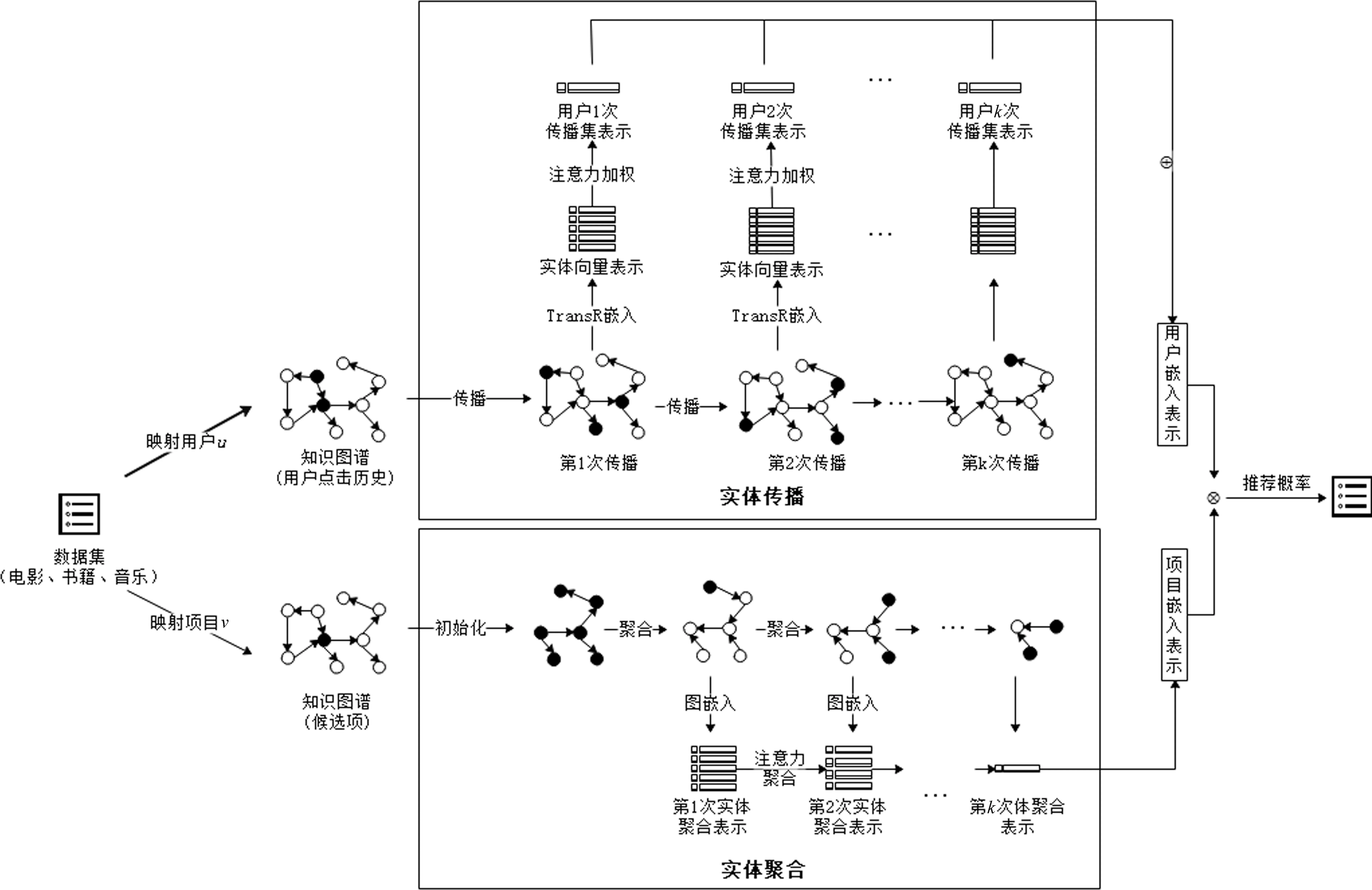
图1 汇集邻居实体的表示推荐模型
汇集邻居实体的表示推荐方法包含用户嵌入表示、候选项嵌入表示与推荐预测三个核心部分。
1.1 用户嵌入表示
给定知识图谱G与用户交互矩阵Y,将Y中正样本作为G中的源实体并进行实体传播。Y与用户的第k次实体传播集表示分别如式(1)、式(2)所示。
其中,k表示传播次数,当k=0,ε0u={U}时,可以将其看作初始化的用户点击历史项。实际上,扩展实体集会随着k增加呈指数级递增,所以本模型设计采用限制采样邻居的方式,采样大小不再是实体e周围所有邻居集合N(e),而是遵循项目对用户重要性由高到低取样邻域实体,以得到偏向用户兴趣的传播实体集,将每层的采样邻域定义为S(e),则S(e)的实体集和三元组表示如式(3)、式(4)所示。
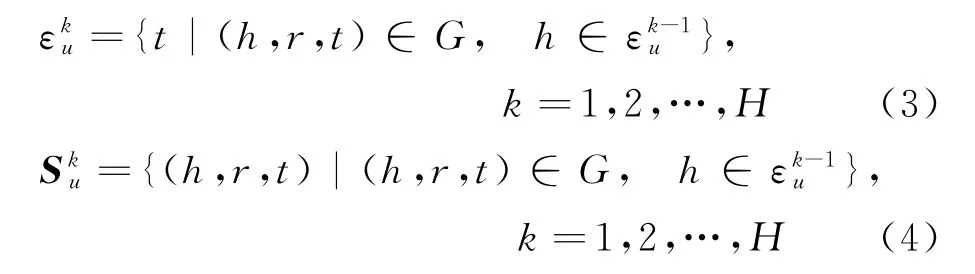
其中,h、r、t分别表示三元组的头实体、关系、和尾实体,最大跳数H的初始值设为2。其中注意力机制针对的是每个实体对用户的重要性。每个三元组分配注意力权重可表示如式(5)所示。

其中,Ri和Hi分别表示关系ri和头实体hi的嵌入向量,关联概率Wi表示关系空间R中测量的项目v和用户历史实体的相似值。由于项目实体用不同的关系测量可能有不同的相似性,所以计算权重需要考虑关系嵌入矩阵。获得Wi后,针对第一次扩展集的向量S1u加权,得到用户的第一层传播表示,如式(6)所示。

其中,Ti表示尾实体ti经TransR 映射后的嵌入,具有与R相同的维度。向量U1为u对项目v的一阶特征表示,使用U1继续传播一层,可获得用户u的二阶特征表示U2,重复此过程,获取S0u扩展H次的特征表示U1,U2,…,UH,累计每一层特征表示得到用户嵌入表示,如式(7)所示。
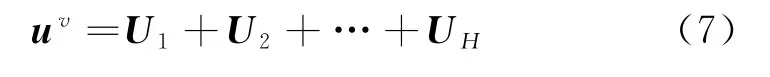
每层特征表示都包含上一层的特征,所以UH包含了之前传播的所有特征,但是为了防止传播过程中信息丢失,最终采用累加每一层Ui计算u的嵌入表示uv。
1.2 候选项目嵌入表示
本文方法将候选项v映射到知识图谱中视作被聚合对象E(v),通过聚合其一定距离内的邻居实体信息,以挖掘潜在的高阶、高质量的用户偏好。获取E(v)周围k跳实体集如式(8)所示。
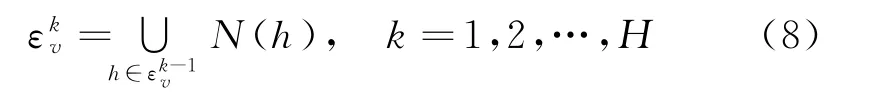
其中,N(h)表示需要聚合的邻域实体,与用户历史实体传播同理,为防止邻域实体数目增长过快,限制采样邻域(见式(3)),将E(v)的采样邻域表示为。聚合过程中的注意力权重计算如式(9)所示。

其中,u和r分别表示用户和关系的向量表示。将注意力加权后,每层邻域表示如式(10)所示。
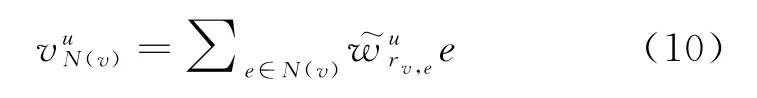
其中,rv,e表示E(v)和周围实体e的关系,是归一化后的用户关系权重。具体计算如式(11)所示。
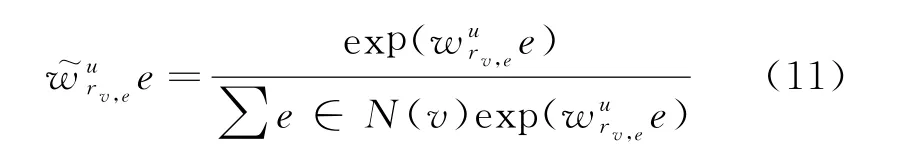
项目v周围的每层邻域实体被表示,整体形成一种拓扑邻域结构。因此,将实体及邻域通过GCN 聚合方法由外向内聚合成单个向量,用来表示E(v)汇集的k跳邻域信息。本文主要使用基于Sum 的聚合方法,计算方法如式(12)所示。
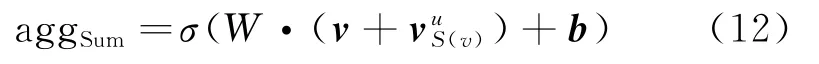
其中,W、b分别表示权重和偏差,σ()是ReLU 激活函数,S(v)为候选项的聚合实体集。
1.3 推荐预测
实体传播后得到用户嵌入表示uv,实体聚合后得到候选项嵌入表示vu,推荐分值基于内积函数计算方法。得分函数如式(13)所示。

1.4 模型训练
该模型的训练过程如算法1所示。
算法1

Algorithm 1 Learning Model Input:interaction matrix Y,knowledge graph G,sampling neighborhood S,number of transmissions H and K,dimension d//输入数据和相关参数。Output:F(u,v|Θ,Y,G);//预测函数1:Begin:2:for(u,v)in Y,G do//在Y、G 中采样正负样本和正负三元组3: {Sku}Hk=1;//用户u 的第H 层的扩展集4: {Uk}Hk=1;//用户H 层扩展集的嵌入表示5: uv ←∑H Uk;//用户嵌入表示6:while limH→k vu(H)! →vu(H)do//收敛性判断7: for(u,v)in Y do 8: {ε[i]}Hi=0←Entity_set(v);//聚合域获取9: eu[0]←e,∀e∈ε[0];//项目聚合表示10: for k∈(1,2,...,H)do 11: for e∈ε[k]do 12: euS(e)[k-1]←∑d∈S(e)w~ure,d du[k-1];//邻域注k=1意力获取13: eu[k]←agg(euS(e)[k-1],eu[k-1]);//GCN 聚合邻域实体14: vu←eu[H];//项目嵌入表示15:y^uv=f(uv,vu);//计算预测概率16:Function Entity_Set(v)//邻域实体获取函数17: ε[k]←ε[k+1];18: for k∈(1,2,...,H )do 19: ε[k]←ε[k+1];20: forε∈ε[k+1]do 21: ε[k]∈ε[k]∪S(e);//待聚合实体集22:return{ε[i]}Hi=0;23:End
用户历史项目在图谱中传播,形成用户嵌入uv(见式(3)~式(7)),候选项在图谱中聚合形成项目嵌入vu(见式(8)~式(12))。为了提高计算效率,训练过程中使用了图谱负采样策略获取数据的负采样分布。因此,模型损失函数如式(14)所示。
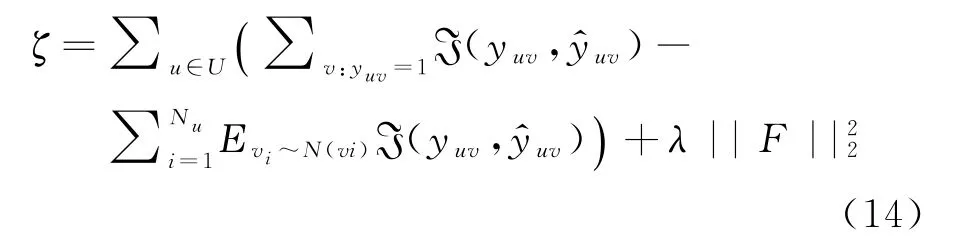
其中,ℑ是交叉熵损失,N是负采样分布,Nu是用户u的负样本数,N和Nu服从均匀分布,λ||F||22是为防止过拟合的正则化项。
2 实验对比与分析
为了验证本文提出的方法,在MovieLens-20M、Book-Crossing 和Last-FM 三个数据集上进行了实验。
2.1 数据集与实验环境
实验中三种数据集的基本统计如表2所示。
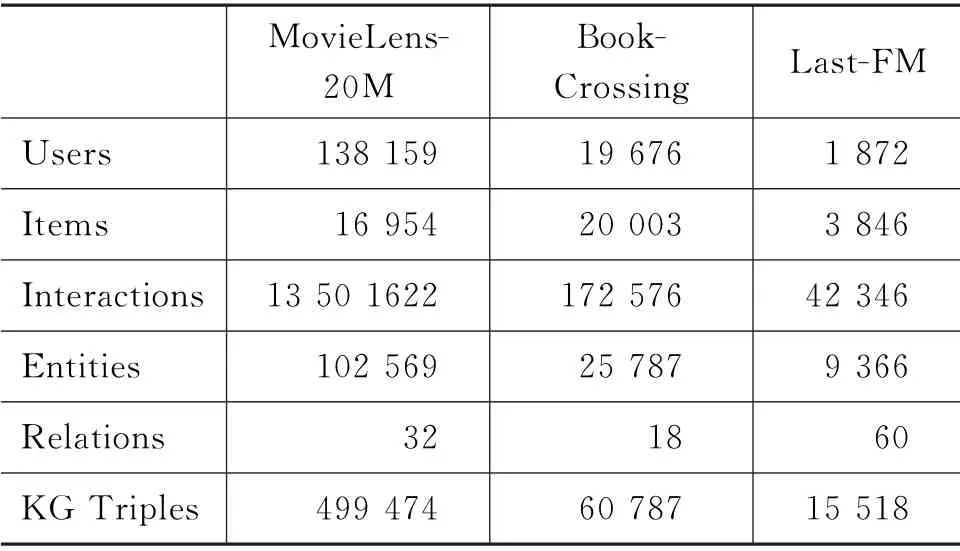
表2 三种数据集的统计数据表 (单位:个)
数据集MovieLens-20M 包含大约100万个分数在1至5之间的评分。Book-Crossing包含了其社区内的172 576个交互。Last-FM 包含1 872个用户与3 846个项目的42 346次交互。由于实验中需要将交互评级转换为隐式表示,所以MovieLens-20M 的评级阈值设置为4;Book-Crossing和Last-FM由于数据稀疏,不设置阈值。阈值处理后的数据集构成用户交互矩阵,其中,标记为1的条目表示用户的正评级,0表示负评级。
实验环境本次实验基于Linux系统,使用Python语言、TensorFlow 框架。所有数据集划分训练集、评估集和测试集的比率为6:2:2,平均每个实验重复3次,每次训练20 轮数,统计平均性能。另外,一些主要的实验参数设置如表3所示。

表3 模型参数
实体传播部分设置图谱的实体更新方式(Item_Update_Mode)为累加变换,实体嵌入权重(KGE_Weight)设置为默认值0.01;TransR 的嵌入维度(Dim_Rip)必须与GCN 聚合的嵌入维度(Dim)保持一致,以防止用户嵌入和项目嵌入的维度不匹配问题;每个波纹集大小(N_Memory)的初始设置为32;实体传播的最远距离(N_Hop)设置为2。GCN聚合器设置的默认值是Neighbor聚合方法。另外,项目聚合的最远距离(N_Iter)、正则化损失权重(L2_Weight)、学习率(LR)设置的默认值均为不同数据集测试的最佳值。
2.2 方法验证与结果分析
为了验证本文方法的性能,使用指标曲线下面积(AUC)和精确率(ACC)来评价模型性能。AUC计算如式(15)所示。

其中,rankinsi表示第i个项目的序号,M和N分别为正、负样本的个数。ACC 计算如式(16)所示。
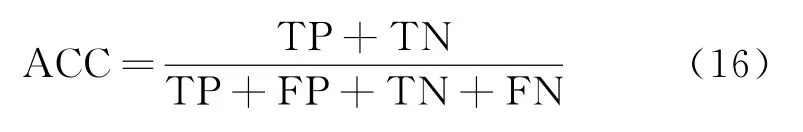
其中,TP 为真正例,FP 为假正例,TN 为真反例,FN 为假反例,TP+FP+TN+FN 表示所有样本的数量。
为验证本文方法的有效性,与Lib FM、Wide&Deep、PER 等10种模型进行了对比实验,结果如表4所示。
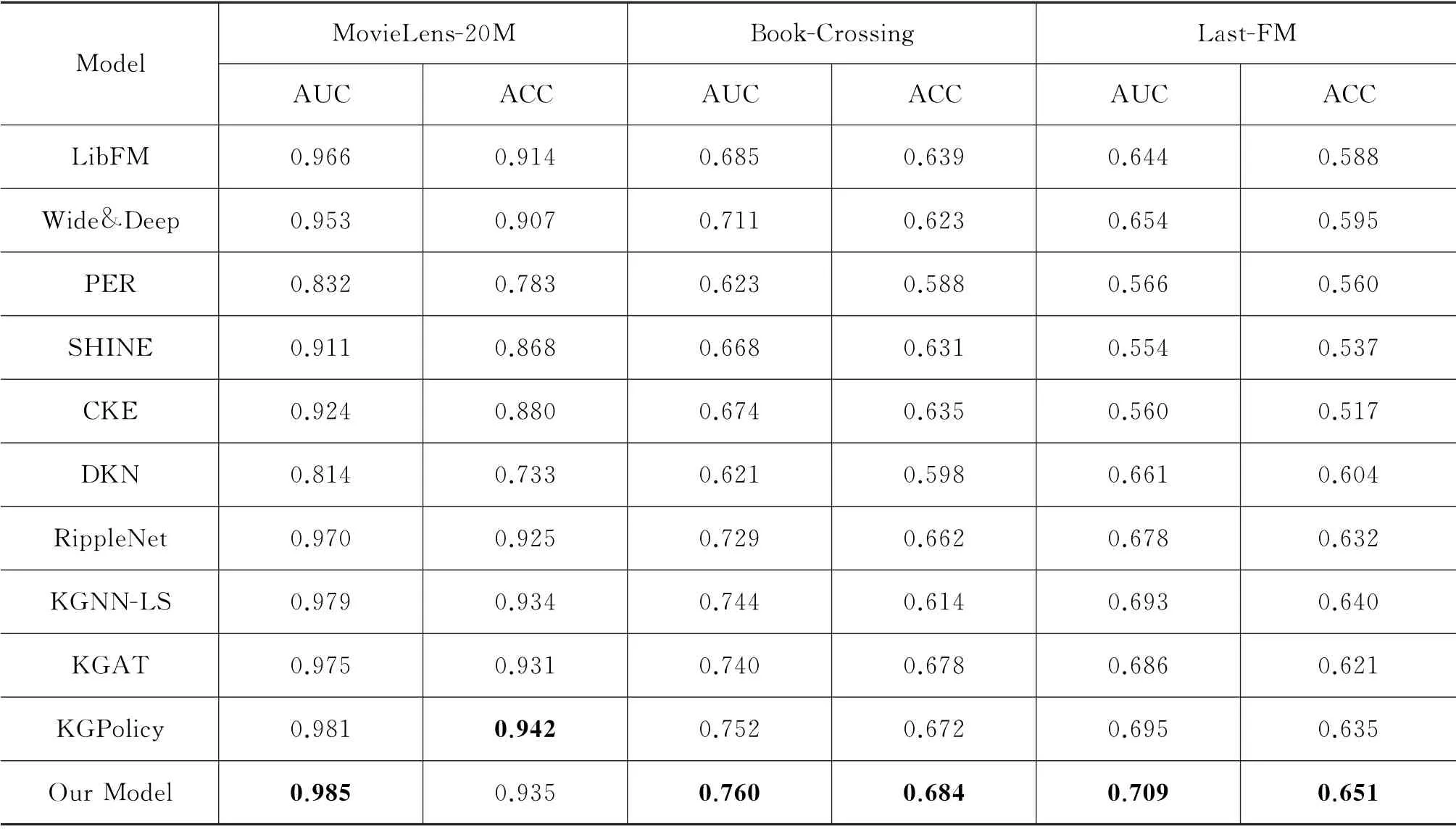
表4 实验结果对比分析
本文模型同表中其他各类推荐模型相比,推荐性能显著提升。经分析可得,各类模型的平均性能在电影数据集中比在书籍和音乐数据集上更优,是因为Movie Lens-20M 的数据更稠密,用户特征空间表示更充分。Lib FM 与Wide&Deep分别基于神经网络和深度学习方法,在三个数据集上均表现良好,但是在实际场景中,此类模型的性能会因为数据稀疏和冷启动问题而迅速降低。CKE 为协同知识库推荐方法,利用知识图谱扩充用户特征,相比传统协同方法Lib FM、Wide&Deep 等,性能大幅提升。SHINE与CKE原理类似,都是通过扩充特征空间实现推荐概率预测。与本文模型相比,SHINE 与CKE仅扩充用户嵌入表示,没有重视用户和项目关系的重要性,ACC降低约7%~13%。DKN 在三个数据集中表现最差,因为DKN 的主要任务是提取高质量的原始特征,所以在新闻数据集中,性能才存在优势。RippleNet模型的综合指标相比基于嵌入的模型SHINE、CKE、DKN 和基于路径的模型PER 性能更优,因为RippleNet属于混合模型,融合了嵌入和路径两类推荐方法的优点。KGAT 使用GCN 同时探索了用户和项目的表示,但是模型训练质量较差,AUC 和ACC 分别降低约2%。KGNN-LS将GNN 应用于推荐,独特的图嵌入方法可探索每个项目的交互,在各类数据集上的性能均较高。KGPolicy首次在知识图谱中执行负采样策略,在Movie Lens-20M 中的ACC超过此模型,证明了负信号对推荐性能提升的重要性。本文模型的AUC和ACC相比其他所有模型在Movie Lens-20M中提升区间为0.4%~17.1%、-0.7%~20.9%;在Book-Crossing 中 提 升 区 间 为0.8% ~13.9%、0.6%~9.6%;在Last-FM 中提升区间为1.4%~ 15.5%、1.1%~13.4%。相比之下,本文模型在获取用户嵌入和项目嵌入时皆利用注意力机制,使用户和项目的特征空间得以扩充,用户兴趣得以充分挖掘。实验数据显示的推荐性能的大幅提升,证明了模型的可行性。
聚合方法对模型的影响为了证明本文模型使用的Sum 聚合方式和GCN 聚合各类方法对模型的影响,分别对Sum 与Neighbor、Concat、Avg 方法进行实验对比,实验结果如表5所示。
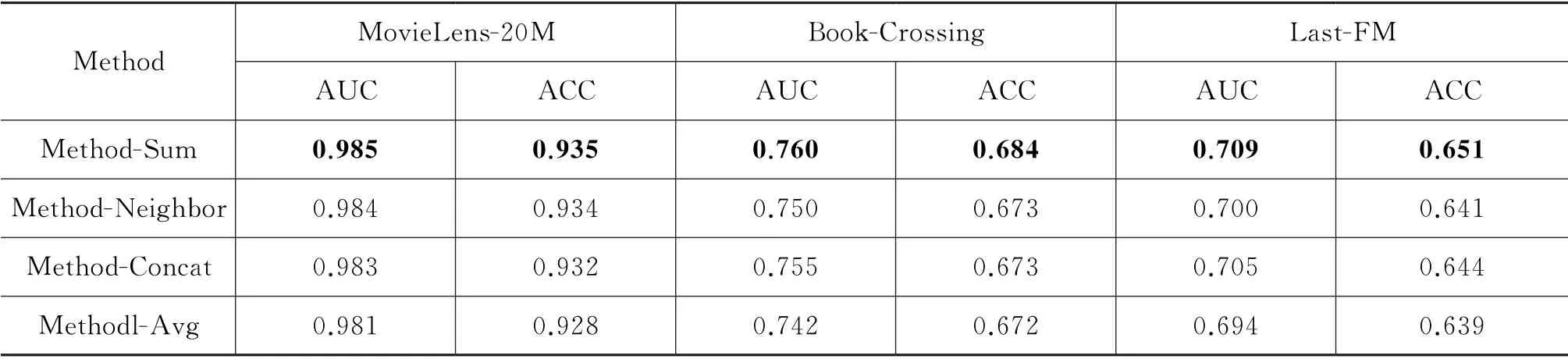
表5 GCN 聚合方法比较
其中,Method-Sum、Method-Neighbor、Method-Concat和Method-Avg是设置GCN 聚合器中聚合节点实体的四种方法。分析实验结果可得,模型使用Sum 聚合在各个数据集中表现最优,因为相比Neighbor聚合,Sum 不仅包含邻域特征,还含有本身实体的特征,不会造成信息丢失。相比Avg和Concat方式聚合,Sum 所具有的侧重性计算特点能间接捕捉用户的个性化偏好和知识图谱的语义特征,更有利于推荐。
数据稀疏和冷启动对模型的影响为了验证对数据稀疏和冷启动问题的应对能力,选用稠密程度不同的数据集MovieLens-1M 和MovieLens-20M做对比实验,并统计性能变化。选用Wide&Deep和LibFM 方法对比,实验结果如表6所示。
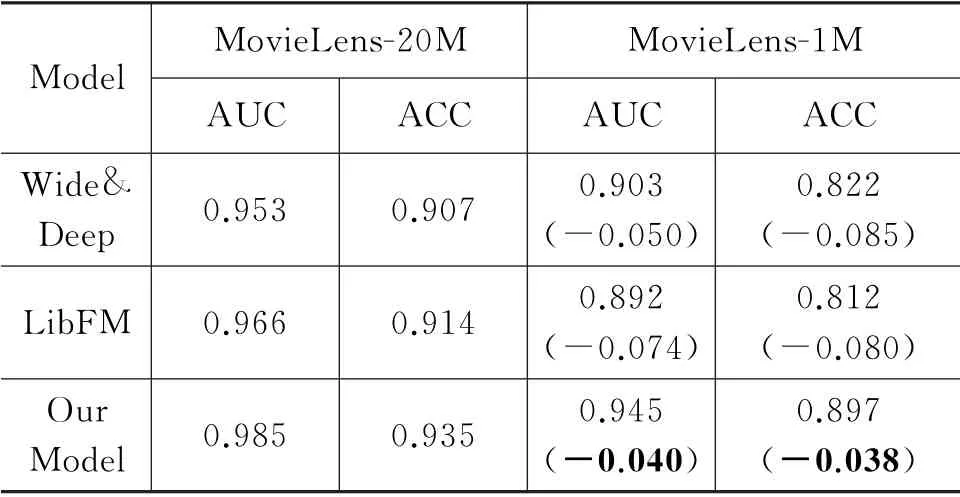
表6 MovieLens-1M 与MovieLens-20M 的实验结果
Movie Lens-1M 与Moview Lens-20M 同属电影数据集,Movie Lens-1M 含有6 036个项目和2 045项目的753 772 次交互;Moview Lens-20M 包含138 159个用户与16 954个项目的13 501 622次交互,明显MovieLens-20M 的数据更为稠密。比较两个数据集上模型的指标不难看出,本文模型在数据量降低时,AUC分别下降0.040和0.038,下降幅度相对其余两个模型更小,证明了基于知识图谱的推荐模型可以更好地解决数据稀疏问题。相比协同过滤、因式分解机、深度网络等推荐模型,本文模型在数据冷启动时,可以利用知识图谱提供的额外实体推荐候选项,不会因为冷启动而导致新用户推荐内容为空的问题。
另外,实验还探索了聚合和传播模块的应用位置对模型的影响。将传播模块用于项目嵌入表示和将聚合模块用于用户嵌入表示,实验结果说明两者偏差不大,且本文模型的性能更优。
3 总结
本文提出的融合用户-项目的邻居实体表示推荐方法,结合实体传播与聚合获取用户和候选项嵌入表示,其注意力机制可以针对用户和项目关系,选择性地汇集图谱中目标实体的领域信息,挖掘更深层的用户兴趣。且本文模型采用负采样策略,过滤了噪声数据,为模型训练提供优质的负信号。经验证,本文模型相比传统模型性能提升显著。
在今后的工作中,首先,将聚焦于捕获每一个用户和项目之间的细粒度关系,获取用户的高阶偏好信息。其次,采用基于知识图谱的负采样策略,选用GNN 网络提取特征,提升推荐性能。
