SPDR:基于片段预测的多轮对话改写
2022-11-07陈建文
朱 帅,陈建文,朱 明
(华中科技大学 电子信息与通信学院,湖北 武汉 430074)
0 引言
对话系统近年来受到越来越广泛的关注和研究,在工业界主要存在两种应用形态,即客服机器人(如阿里小蜜[1]、支付宝助理等)和聊天机器人(如天猫精灵、小爱同学、微软小冰[2]等)。当前的对话系统在处理单轮对话问题时效果显著,而在处理与上文相关的用户问题时则表现比较一般,主要原因在于人们的日常对话中每个轮次之间并非孤立的,每一轮对话都可能会存在指代(pronoun)或者省略(ellipsis)的情况,这时如果只基于用户当前轮的输入进行回复,则会忽略掉上文的一些重要信息,导致回复结果不符合上下文语境。文献[3]对2 000条日常对话数据进行过统计,发现其中存在33.5%的指代和52.4%的省略现象,指代和省略是导致多轮对话场景下回复质量较差的主要原因。
近来,多轮对话改写任务得到越来越多的研究,这个任务的目的是根据用户的历史输入对当前输入进行改写,确保改写之后的句子能够表达更完整的语义信息,将对话系统中的多轮问题转化为单轮问题。多轮对话改写实际上主要想要解决两个问题,即指代消解和省略补全。表1展示了两个常见的多轮对话场景。场景一是一个典型的任务型对话场景,最后一轮用户咨询穿衣建议,但是省略了问题的背景,通过补全后就可以知道用户咨询的地点是“杭州”,依据是“今天天气”这两个重要信息。场景二是一个常规的闲聊对话,通过对最后一轮进行补全就可以知道“他”指代的对象是“周杰伦”,用户表达的情感是“喜欢”。由此可见,通过上文对用户当前输入进行改写,使用一句较简短的话就可以表达完整的语义信息,便于机器人理解并给出合适的回复。

表1 多轮对话场景改写示例
多轮对话改写任务提出以来,由于和指代消解任务的相关性,多采用指代消解的方法来解决。最近有研究[3-5]相继提出采用指针生成网络的方法来解决多轮对话改写问题,开辟了一种新的思路。指针生成网络首先通过编码器编码,然后使用解码器采用束搜索(beam search)的方法逐字生成,本质上是一个串行的过程,效率问题比较明显。
受到BERT[6]模型解决阅读理解任务方法的启发,本文提出采用基于片段预测的模型SPDR 来解决多轮对话改写问题。一方面,避免了编码器-解码器(encoder-decoder)网络耗时较长的问题;另一方面,可以更方便地使用目前主流的预训练模型,只需要少量的数据就可以得到比较好的效果表现。该模型使用BERT 作为编码器,将对话历史信息和用户当前轮的输入进行拼接,作为模型输入,预测当前轮输入中指代或者省略的内容在对话历史信息中对应的起始位置和结束位置,最后通过后处理对用户当前输入进行补全。实验表明,该模型在Restoration-200K 数据集以及客服场景下的业务数据上都得到了更优的结果,同时大大提高了推理速度。
此外,受到文献[7-8]工作的启发,本文提出了两种新的预训练任务,即分类任务(判断当前输入语义是否完整)和检测任务(判断当前输入哪个位置缺少内容),来提升SPDR 模型的表现,实验表明,在经过两种任务预训练后的模型上微调,效果提升明显。最后,本文根据改写任务数据的特点,提出了一种新的评价指标sEMr来评价对话改写模型的效果。
本文组织结构如下:第1节介绍对话改写任务的相关研究及预训练模型的研究进展;第2节介绍基于BERT和指针网络的SPDR模型的细节和结构;第3节介绍模型新的评价指标、实验设计及实验结果;第4节总结本文的工作,并对未来工作进行展望。
1 相关工作
对话改写任务主要有两种方法,即基于流水线的方法和基于端到端的方法,本节将介绍两种方法的代表工作。
1.1 基于流水线的方法
基于流水线的对话改写方法将改写任务分成两个子任务,即检测任务(指代和省略位置检测)和消解任务(指代消解和省略补全)。
检测任务目的是找到当前轮语句中指代和省略的位置。传统的方法是基于规则的方式,通过匹配找到代词的位置,以及采用规则模板找到省略的位置,这种方法简单直接,但是泛化能力较弱。文献[9]中提到采用序列标注的方法来解决指代和省略定位问题,具体来说定义了3种标签:“0”表示常规词,“1”表示指代或者省略的边界词,“2”表示指代。通过对语句中每个字进行序列标注,即可找到指代和省略的位置。
通过检测任务找到指代和省略的位置之后,需要从历史对话中找到合适的词填充或者替换到这个位置。文献[10]提出采用文本匹配的方式,首先对检测到的位置进行双向编码,然后对对话历史中的候选词进行局部编码和全局编码,将待消解位置的编码和候选词的两个编码拼接,再拼接一些人工特征,经过线性层分类。类似地,文献[11]在匹配过程中引入了注意力机制(attention mechanism),文献[12-13]又分别将强化学习(reinforcement learning)和先验知识(prior knowledge)融合到匹配过程中。文献[14]提出基于完形填空的消解方法,直接将待消解位置映射到词表中的一个单词上,根据预测的答案词遍历上文中候选片段,如果答案词是某个候选片段的首词,那么该片段即为预测结果。
1.2 基于端到端的方法
虽然基于流水线的方法流程清晰,但是存在误差累积的问题,检测模型的性能决定了消解模型的上限,而端到端的方法则避免了这个问题,因此端到端的方法成为目前业界探索的主要方向。端到端的方法主要分为:基于联合训练的方法、基于序列标注的方法及基于指针生成网络的方法。
文献[9]提出基于联合训练的方法,将检测任务和消解任务融合到一个模型中,并将两个损失函数相加,共同训练。文献[14]提出基于序列标注的方法,主要目的是解决摘要类型的问题,定义了类似保留(KEEP)、删除(DELETE)、增加(ADD)等类型的标签,将历史对话和当前轮输入拼接,预测每一个单词的标签,再经过后处理得到改写后的语句。文献[3]提出采用指针网络(Pointer Network)来解决对话改写的问题,首先将历史对话和当前轮输入拼接后送入编码器,然后使用解码器逐步解码,解码时并非从全量词表中选词,而是限制只能从历史对话或者当前轮对话输入中选择。文献[4-5]分别提出一种两阶段的模型,将预训练模型应用到了多轮对话改写的任务中。
2 模型
本节主要描述模型SPDR(Span Prediction for Dialogue Rewrite)的结构和原理。多轮对话改写问题可以定义为:基于对话历史信息H和用户当前轮输入Ut,根据对话历史信息将当前轮用户输入改写成U*t,即(H,Ut→U*t),目标是模型改写的结果U*t和标注结果R尽可能一致。SPDR 采用基于片段预测的方式来对当前轮用户输入Ut进行补全,具体来说:对话历史信息H={h1,h2,…,hm},其中{hj}mj=1表示单词序列,m表示对话历史信息中单词的数量,不同轮次之间使用[SEP]分隔。用户当前轮输入Ut={u1,u2,…,un},其中n表示用户当前轮输入中的单词数。对于每一个{ui}ni=1,SPDR预测其要填充的片段在对话历史信息H中的起始位置和结束位置。模型结构如图1所示。
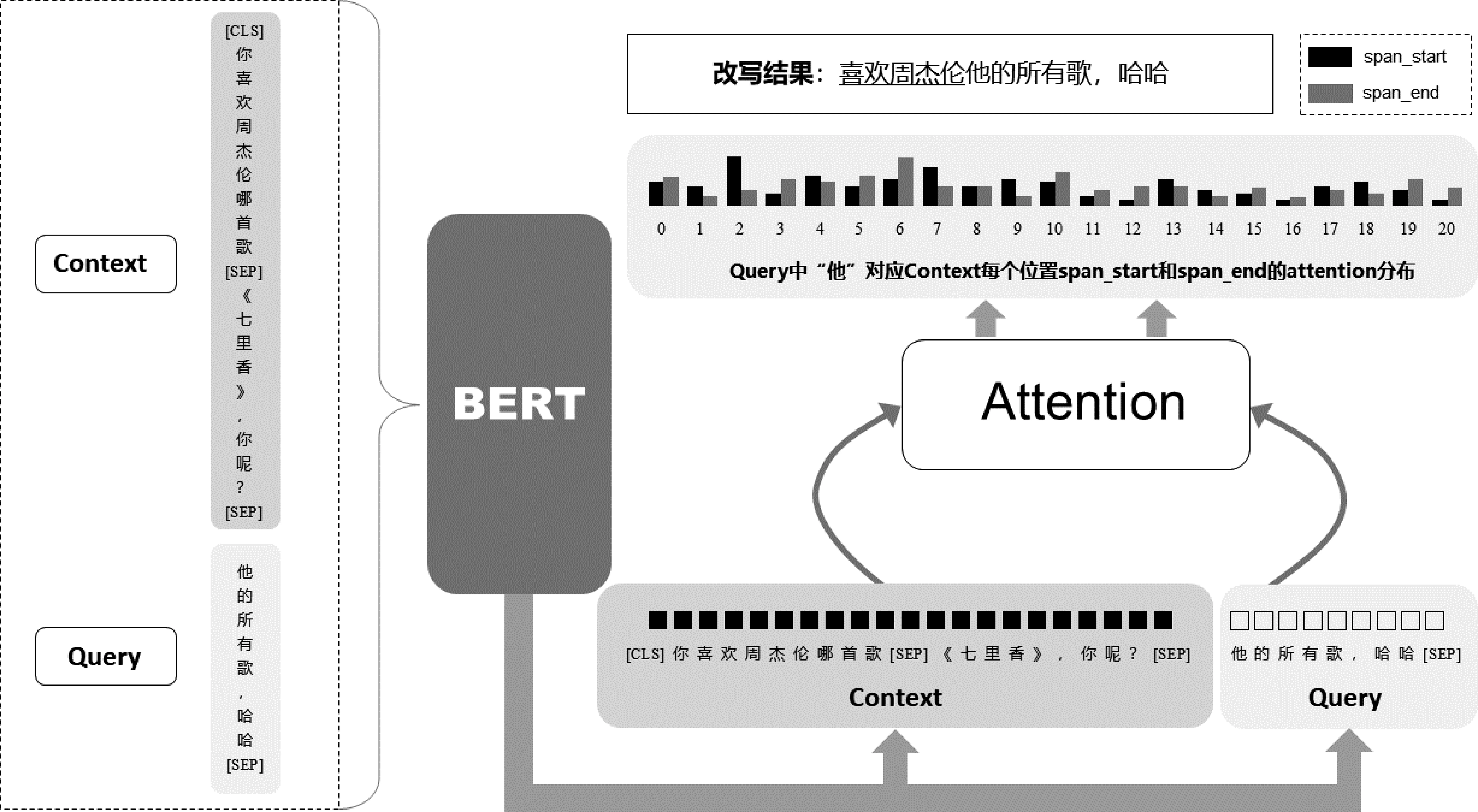
图1 模型结构图
2.1 标签构造
当前数据集中的标签为人工标注的改写之后的句子R,为了得到Ut中每一个单词{ui}ni=1对应的起始标签和结束标签,同时找到每个位置要填充的内容。本文为SPDR 设计一种标签构造算法,具体流程为:①采用计算最长公共子序列的方法,在标注结果R中找到用户当前轮输入Ut中每一个单词出现的位置,没出现则用“-1”表示;②根据上一步计算的位置找到Ut中需要消解的位置,并在R中找到每一个待消解位置填充的内容;③根据找到的填充内容在对话历史信息H中的位置,从最近轮次向前找到填充内容出现的起始位置和结束位置。具体的算法流程如算法1所示,起始位置和结束标签示例如表2所示。考虑到Ut中大部分单词前面都是不需要填充内容的,此时对应的起始位置和结束标签都为0,即指向H中[CLS]。

算法1:计算{ui}ni=1起始位置和结束标签输入:历史对话信息H当前对话信息Ut标注改写结果R输出:Ut 的起始标签向量s Ut 的结束标签向量e 1 m[i]=-1,s[i]=0,e[i]=0,∀i=1,2,…,n 2 k=0 3 计算Ut 和R 的最长公共子序列,找到每一个ui 在R 中出现的位置pos;4 while k<n 5 if(pos[k]is pronoun or ellipsis)6 m[k]=1 7 end if 8 for k∈[0,n)9 if m[k]==1 10 span=find_span_in_R(m,R,pos)11 s,e=label_in_H(m,span,R,H)12 s[k]=s 13 e[k]=e 14 end if 15 return s,e
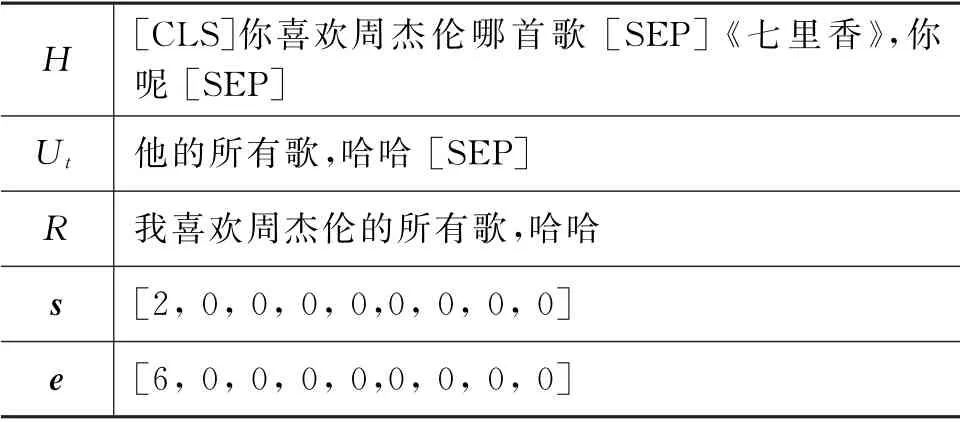
表2 起始标签和结束标签示例
2.2 编码器
2017年文献[15]提出了Transformer的编码器-解码器结构,采用多头注意力机制(multi-head attention)来捕捉句子中单词之间的关联。之后,文献[6]采用Transformer编码器模块作为基本结构,定义了掩码语言模型(Masked Language Model,MLM)和下句预测(Next Sentence Prediction,NSP)两个预训练任务进行预训练,刷新了多项NLP任务的最佳效果。本文使用文献[6]提出的BERT 模型作为句子的编码器。
首先,将历史对话信息H和用户当前轮输入Ut拼接成Input= {h1,…,hm,u1,…,un}这样的输入序列,经过嵌入矩阵得到每一个单词对应的嵌入表征,本文在嵌入层定义了4个不同的嵌入矩阵:
•单词嵌入:从单词索引到嵌入表征的哈希映射矩阵,使用BERT 预训练的参数将每一个单词映射成高维表征。
•位置嵌入:输入序列每个位置对应一个位置索引,将每一个位置索引映射成表征不同位置的嵌入表征,维度和单词嵌入相同。
•序列嵌入:用“0”表示历史对话信息H,用“1”表示用户当前轮输入Ut,然后嵌入到高维表征,维度和单词嵌入相同。
•轮次嵌入:考虑到历史对话中可能包含多个轮次,所以每个单词都有对应的轮次索引{0,…,t-1},当前轮输入对应轮次为t,通过映射之后得到轮次的嵌入表征。
因此,对于输入对话语句中的每一个单词w∈{h1,…,hm,u1,…,un},将上面4种嵌入相加,得到输入的嵌入表征,如式(1)所示。
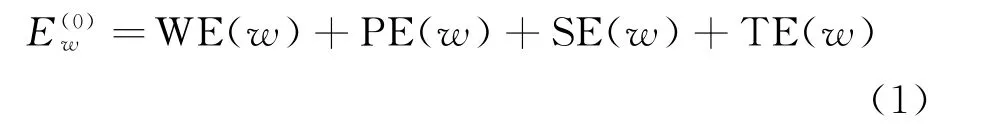
其中,WE 表示单词嵌入,PE 表示位置嵌入,SE 表示序列嵌入,TE 表示轮次嵌入。将4个嵌入相加之后得到了预训练模型BERT 的输入,经过BERT之后得到所有输入单词的上下文表征如式(2)所示。
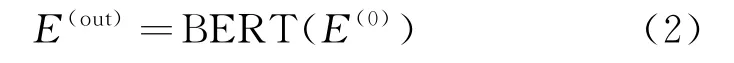
最终得到单词序列的上下文表征E(out)并分成两个部分,即历史对话信息表征及用户当前轮输入的表征
2.3 输出概率分布
文献[6]中提到通过预测问题在篇章中对应的起始位置和结束位置来完成阅读理解任务,本文采用了类似的思路。基于得到的上下文表征和,预测Ut中每一个单词{ui}ni=1前面要填充的内容,在对话历史信息H中对应的起始位置和结束位置。文献[3]中提出通过指针网络[16]的方法,解码器解码时只计算当前时间步在对话历史信息H和用户当前输入Ut上的概率分布,即每一个时间步的单词只能来自H或者Ut。考虑到在计算每一个{ui}ni=1填充内容在历史对话H中的起始位置和结束位置时,H中所有单词概率分布存在相关性,本文采用指针网络的方法来计算每一个{ui}ni=1填充内容对应的起始位置和结束位置概率分布,即:
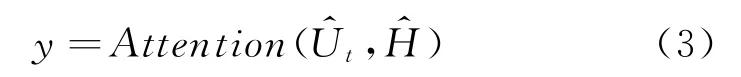
本文采用带有参数的注意力方法——双线性注意力机制(Bi-linear Attention Mechanism)来计算起始位置和结束位置的概率分布。对于起始位置和结束位置的注意力模块,W1和W2表示计算注意力分布的参数矩阵,基于上下文表征和计算用户当前输入Ut中的每一个单词在对话历史信息H上的概率分布:
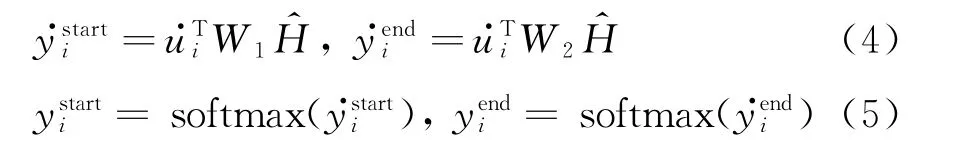
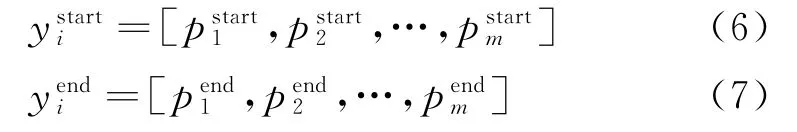
最后,采用负对数似然概率计算起始位置的损失和结束位置的损失,将两者相加得到最终的损失,即:
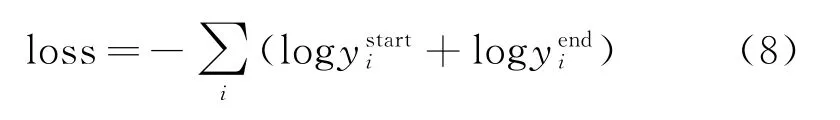
2.4 预训练任务
文献[8]通过在情感分析任务中定义情感词预测、单词情感极性预测及属性-情感对预测三个预训练任务,来增强预训练模型对情感的感知能力,表明特定场景的预训练任务对于核心任务会带来一定的效果提升。文献[7]在多个不同领域的数据上进行实验,发现在特定领域上使用领域数据继续使用MLM 任务预训练,大部分情况下也会带来一定的效果提升。因此,本文提出了两个预训练任务,使用对话改写任务的数据集先预训练再对改写任务进行微调,这两个预训练任务分别是分类任务和检测任务。
(1)分类任务(ClassifyTask):将对话历史信息H和当前输入Ut拼接之后输入预训练模型BERT,然后使用[CLS]对应的上下文表征进行二分类,判断当前输入Ut是否需要补全。
(2)检测任务(DetectionTask):将对话历史信息H和当前输入Ut拼接之后输入预训练模型BERT,得到当前输入Ut的上下文表征=,对于其中的每一个进行二分类,判断其前面是否需要填充内容。
3 实验
本节主要介绍实验采用的数据集、评价指标、对比模型及实验结果,并对实验结果进行分析。
3.1 数据集
本文主要基于两个数据集进行实验,分别是Restoration-200K[4]和客服场景下业务数据集,前者是开放域闲聊场景下的数据集,后者是特定领域下的对话数据,两组数据集的统计信息如表3和表4所示。为了保证样本比例的均衡,在这两组数据集中,无论是训练集、验证集还是测试集,需要改写的样本和不需要改写的样本各占比50%。这种方式有效避免了样本不均衡问题对不同模型潜在的影响。
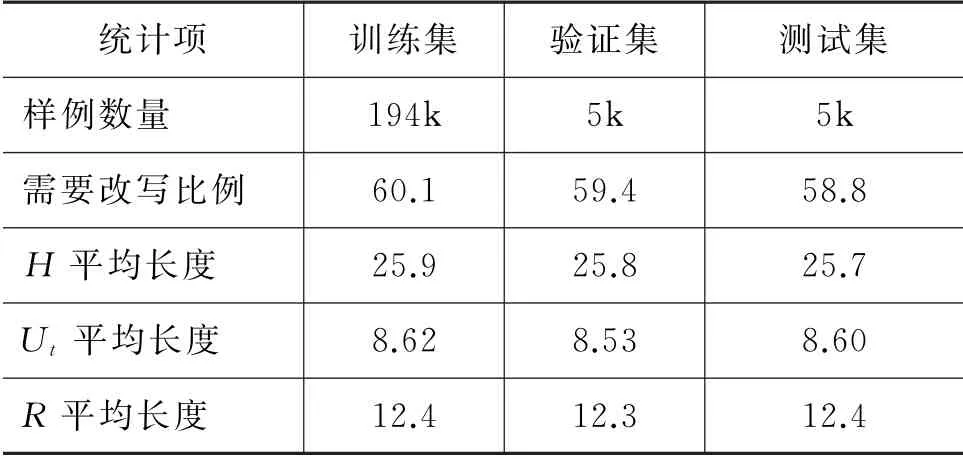
表3 Restoration-200K 数据集统计信息
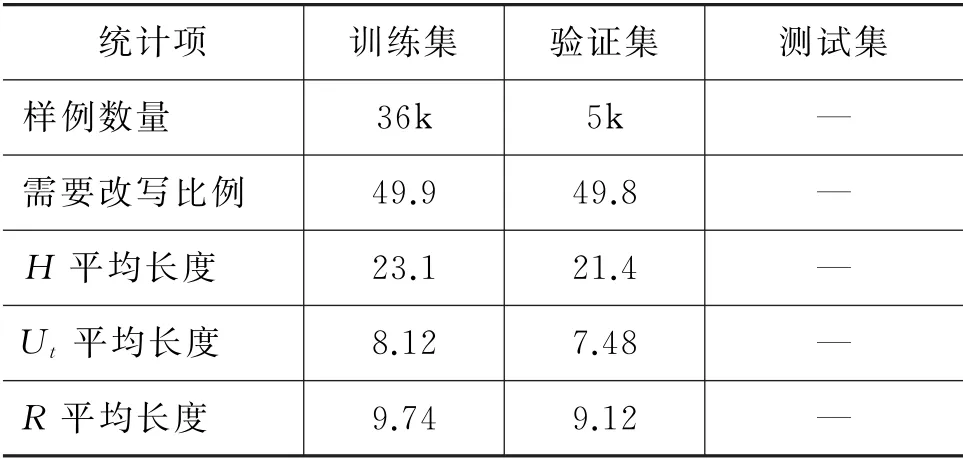
表4 业务数据集统计信息
3.2 实验设置
本文代码基于Pytorch、Allen NLP及Hugging-Face的Transformers库实现。实验采用了3种不同的预训练模型来初始化编码器,对比不同预训练模型的效果以及推理时间。这3个预训练模型分别是RoBERTa-wwm[17]、RBT3[17]以及ALBERT-tiny[18],不同模型的参数设置如表5所示。主要区别在于RoBERTa采用的是12 层的Transformer结构,而RBT-3是3层,ALBERT-tiny则是4层的结构。本文中实验的硬件配置如下:CPU 采用英特尔E5-2682 v4,GPU 为Tesla P100-PCIE 16GB。

表5 预训练模型训练参数设置
3.3 评价指标
与文献[4-5]类似,本文在Restoration-200K 数据集上采用BLEU、ROUGE 以及Restoration分数作为评价指标。其中Restoration分数这个指标[4]主要关注那些至少包含一个待还原的单词的N-grams,而排除其他N-grams,对应的还原之后的N-gram 的准确率(Precision,P)、召回率(Recall,R)以及F值的计算如式(9)、式(11)所示。
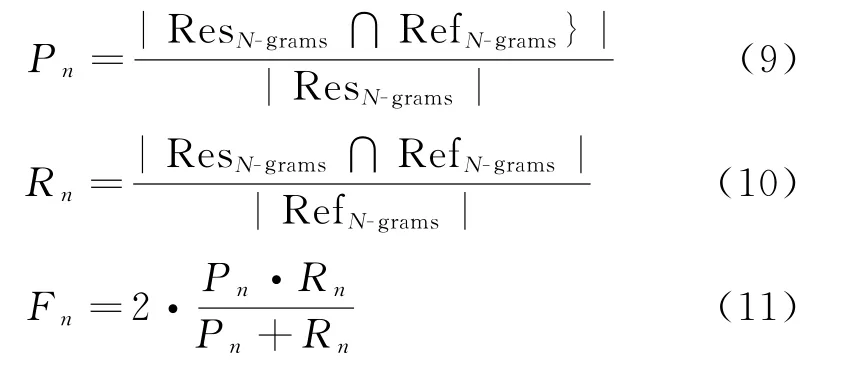
其中ResN-grams表示改写之后的文本包含待还原单词的N-grams,RefN-grams表示参考文本中包含待还原单词的N-grams;∩表示计算两个N-grams集合的交集,|·|表示计算集合中元素的数量。
考虑到数据集中标注改写结果R中大部分单词都来自于用户当前轮的输入Ut,即改写的目的是在不损失当前轮信息的前提下增加有用的信息,因此本文提出一种新的评价指标sEMr(soft Exact Match Rate)。对于模型改写的结果U*t,如果标注结果R中的所有单词都在U*t中出现并且出现的顺序和R中一致,即认为是sEM(soft Exact Match)。在sEM 的前提下,U*t的长度越接近于R,说明其中的无效信息越少,于是sEMr的表达式如式(12)所示。
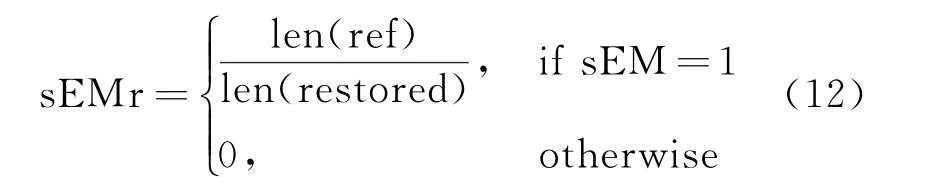
其中,Ref表示标注改写结果R,restored表示模型改写的结果U*t,len()表示计算字符串的长度。
3.4 对比模型
本文对比了SPDR 模型和以下4种模型在各指标上的表现。
•PAC[4]:该模型采用两阶段的方式,首先将对话历史信息H和用户当前轮输入Ut拼接,经过预训练模型对H中每个单词进行序列标注,表示是否是省略的单词;然后将标注的结果拼接到(H,Ut)后面,经过指针生成网络得到补全后的结果。
•T-Ptr-λ[3]:该模型采用编码器-解码器的思想,基于指针生成网络逐个时间步生成单词,每次生成的时候只能从对话历史信息H和用户当前轮输入Ut中选词。该模型采用 了6 层Transformer 编 码 器 和6 层Transformer解码器,在解码阶段,为了区分H和Ut,采用了双流注意力的方法。
•UniLM[19]:UniLM 提出了既适合自编码任务,又适合自回归任务的预训练模型,其核心方法是使用不同的掩码矩阵来控制任务的类型。
•SARG[5]:该模型将文献[3]和文献[14]的方法进行了结合。首先将对话历史信息H和用户当前轮输入Ut拼接,然后预测Ut中每一个单词的标签;接着,对于那些标签为CHANGE 的单词,采用指针生成网络的方法预测其后面需要添加的内容。
3.5 实验结果
在Restoration-200K数据集上的实验结果如表6所示,在客服场景下业务数据集上的实验结果如表7所示。
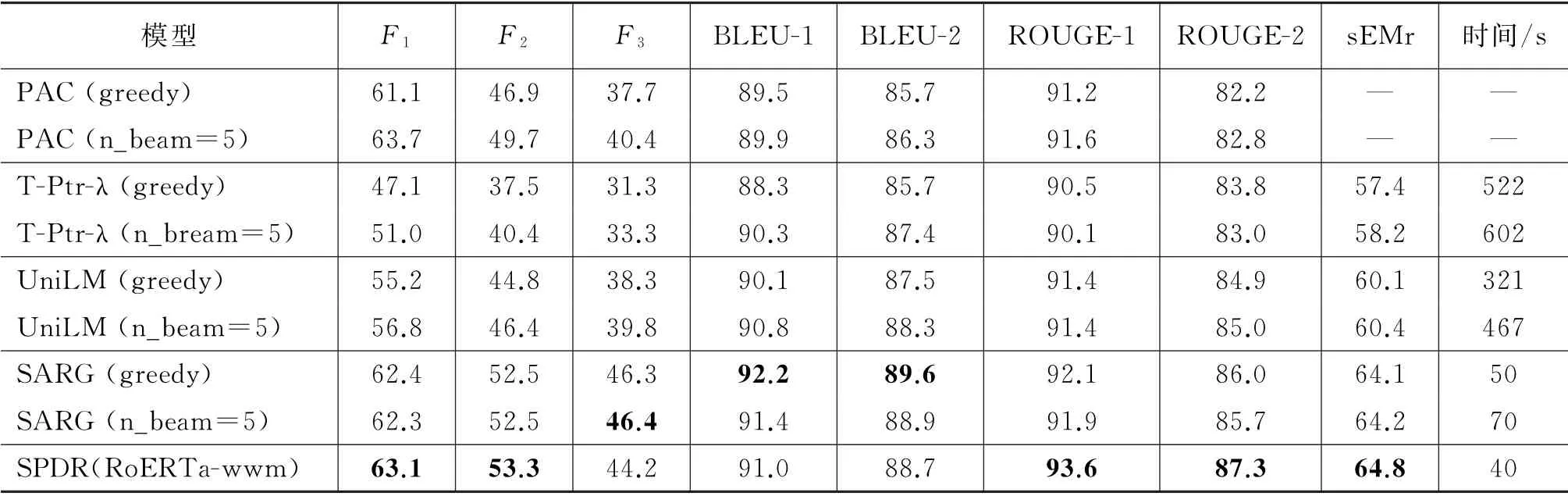
表6 Restoration-200K 数据集上各模型指标对比

表7 客服场景下业务数据集上主要模型指标对比
从表6中各个模型在Restoration-200K 数据集上的表现,可以看出:
(1)SPDR 模型在7个评价指标中有5个超过了之前最好的SARG 模型。其中restoration分数中F1、F2及ROUGE 指标都有1%左右的提升;BLEU 指标相较于SARG 模型有1%左右的下降,主要原因是:SPDR 模型通过预测片段的方式来对当前轮输入进行改写,容易引入一些标注结果中不存在的单词;而SARG 等生成类型的模型是逐词生成的,所以避免了这种情况;而BLEU 指标主要关注改写结果中n-grams的精确率,所以会有一定的下降。相反,ROUGE 指标更关注n-grams的召回率,所以SPDR 模型在该指标上表现更好。
(2)SPDR 模型在验证集上的推理速度明显快于其他模型。之前以UniLM 为代表的改写模型采用的都是逐词生成的方式,这种串行的预测方式导致其推理时效率比较低;SARG 模型相较于纯粹的生成模型,引入了部分生成的思想,在一定程度上缓解了推理阶段的效率问题。SPDR 模型则采用完全并行预测的方式,默认保留用户当前输入的所有内容,同时预测每个位置前面需要添加的内容,解决了串行预测方法的效率问题,大大提升了推理阶段的速度,便于在低时延限制的系统中使用。
Restoration-200K 数据集中训练集的数据量比较大,而实际场景中对话改写数据标注比较困难,所以在少量训练集情况下模型的表现同样值得关注。表7展示了主要模型在客服场景下业务数据上的各项指标,从中可以看出:
(1)SPDR 模型在训练数据较少的情况下表现仍然出色,在除F3之外的其他6个指标上均明显优于T-Ptr-λ模型,其中sEMr指标提升了6.7%。和SARG 相比,sEMr也有1.7%的提升。而F3指标表现略逊色的主要原因是:验证集中人称代词和指示代词的样例比较多,而SPDR 模型并不会去除这些代词,因为这些代词并不是完全没用的,相反在下游自然语言理解任务中,人称代词能够提供一些正向信息(比如人物的性别);而由于代词比较多,并且大部分补全的内容比较短(表4),所以在N-gram较长的指标上表现就会稍微逊色。
(2)SPDR 模型推理一个样例速度明显提升,使用12层的BERT 模型推理速度相较于生成模型提升了接近100%。考虑一些生产环境对时延严格限制的情况,还可以使用轻量级的预训练模型作为编码器,推理速度会进一步改进,当前相应的指标也会略有下降。但是,即便在使用轻量级编码器的情况下,SPDR 模型在sEMr指标上仍然明显优于T-Ptr-λ模型,略逊色于SARG 模型。
综上所述,SPDR 模型无论是在训练集数据量充足的情况下,还是在训练集数据比较少的情况下,均能取得比较优异的效果,大部分指标都明显优于之前的模型,同时SPDR 模型没有使用编码器-解码器的结构,大大提升了模型在推理时的速度,便于在生产环境中使用。
3.6 消融实验
在2.4节中本文提出了两个预训练任务,用于提升SPDR 模型的表现。本节主要对预训练任务进行消融实验,研究不同预训练任务对于模型表现的影响。除此之外,针对业务数据集训练数据较少的问题,本文还提出了一种简单的自动化数据扩充方法,具体来说:在历史对话信息H中,有的轮次的语句并没有单词出现在补全结果中,删除这些轮次的语句便得到了一个新的样本。本节也会考察自动化数据扩充的方法对于模型最终效果的影响。
在消融实验中,本文使用的是客服场景下的业务数据集,编码器使用轻量级的ALBERT-tiny 模型。最终,消融实验结果如表8所示。
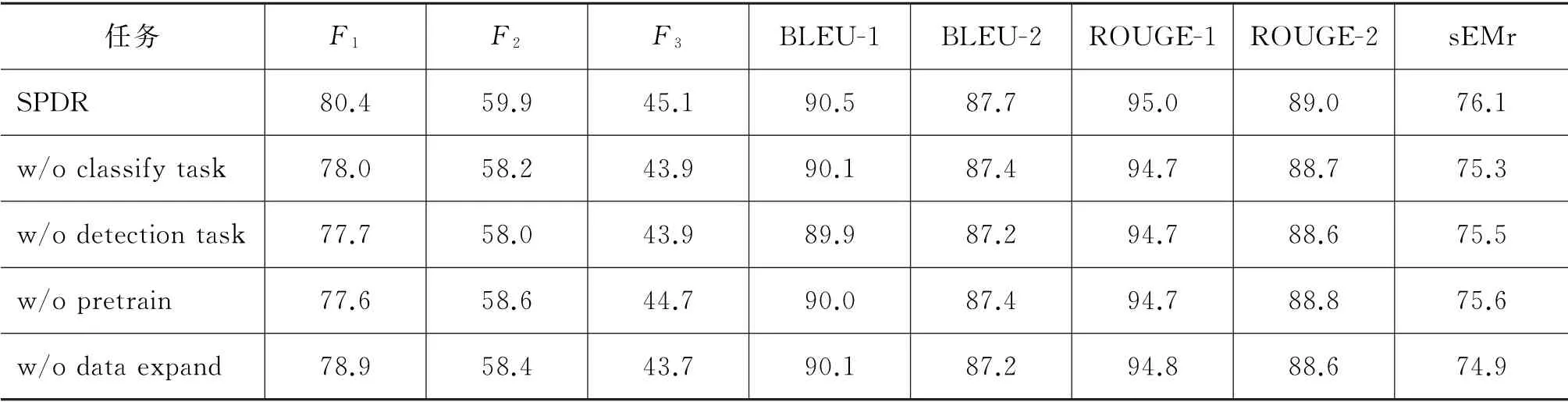
表8 消融实验结果
通过消融实验可以发现,分别使用分类任务和检测任务对模型进行进一步预训练,相较于不经过预训练的结果,提升并不明显,说明只使用其中某一个预训练任务可能会引入一些无效的先验信息,反而给模型带来了负面影响。而同时使用分类任务和检测任务两个任务预训练,则效果提升明显,主要原因可能是分类任务能够捕捉历史对话信息和当前轮输入P句子间的关系,而检测任务能够捕捉当前轮输入各个单词之间的关系,两个任务具有一定的互补性,提供了有效的先验信息。从最后一行可以看出,在数据较少的场景下,本文提出的数据扩充方法能够明显提升模型最终的表现。
3.7 样例分析
本节主要展示不同模型在测试集上的预测结果,并选择其中几个有代表性的样例进行分析,具体如表9所示。

表9 对话补全测试集样例

续表
在样例1中,T-Ptr-λ模型漏掉了原始输入中重要的极性词,直接导致语义发生了改变,改写之后的结果反而不如原始输入的语句,另外两个模型也或多或少丢失了用户当前输入的部分信息。而SPDR模型默认保留原始输入中的所有单词,避免了丢失信息的情况,同时还原了关键词“etc”。
在样例2中,T-Ptr-λ丢失了原始语句A3中的信息,并且补充的信息也不完整;UniLM 补全之后语句比较连贯,但是补充的信息和正确结果有一定差距;SARG 采用部分生成的方式,预测对了需要补全的位置,但是补充的内容不连贯。SPDR 模型采用的是片段预测的方式,预测的填充内容不仅可以是单词,也可以是短语,表达的信息更完整,表明了其建模片段语义的能力。
3.8 人工评估
自动化评估指标能够从不同角度体现对话改写的效果,但是无法反映改写结果语义的完整性和流畅性。在人工评估阶段,本文从Restoration-200k测试集中随机采样了200个样本,并请3名有经验的标注人员对不同模型的改写结果进行打分。打分的维度主要有两个,语义完整性(Integrity)及语句的流畅性(Fluency),打分可选值为[0,1,2]。0分表示效果很差,无法接受;1分表示效果一般,可部分接受;2分表示效果很好,完全可以接受。
人工评估结果如表10所示,从中可以看出,在语义完整性指标上,SPDR 模型得分优于其他模型,主要因为SPDR模型采用片段预测的方式能够有效保证信息召回率,这对于下游任务非常重要,这也与自动化评估结果一致。而在语句流畅性指标上,SPDR 模型则略逊色于SARG 模型,主要是因为SPDR 没有去除人称代词和指示代词,同时某些位置片段预测错误也会导致语句不太流畅。
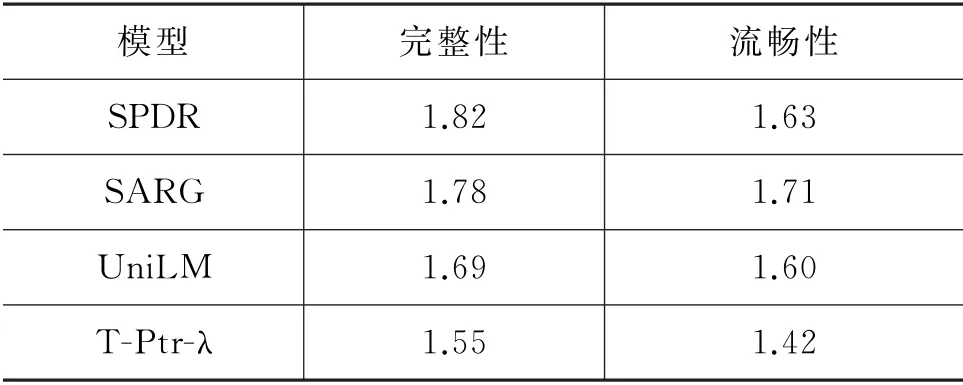
表10 人工评估结果
4 总结与展望
本文提出了采用片段预测的方法进行多轮对话改写,摒弃了传统的编码器-解码器结构,大大提升了推理阶段的速度。同时,本文提出的SPDR 模型,无论是对于训练数据充足的Restoration-200K数据集,还是数据量较少的客服场景下的业务数据,在一些主要指标上,相较于之前的最好结果,均有明显的提升。本文还提出了一种新的多轮对话改写结果的评价指标sEMr,用于对比不同模型多轮对话改写的效果。最后,SPDR 模型可以采用不同大小的编码器,满足不同时延限制场景的需求。
当然,本文还存在一些不足,比如改写结果中没有去掉代词,同时补充的内容必须在上文中出现过,这可能导致某些改写结果在流畅性上表现一般,这也是该模型之后改进的方向。此外,本文对改写结果和数据进一步分析发现,特定领域场景下,大部分填充的词都是领域内的实体词,因此将领域的知识信息融入改写过程也是未来将会继续探索的方向。
