基于细粒度视觉特征和知识图谱的视觉故事生成算法
2022-11-07李朦朦江爱文龙羽中王明文
李朦朦,江爱文,龙羽中,宁 铭,彭 虎,王明文
(1.江西师范大学 计算机信息工程学院,江西 南昌 330022;2.九江学院 计算机与大数据科学学院,江西 九江 332005)
0 前言
近年来,随着计算机视觉和自然语言处理技术的不断发展,以及图像内容描述(Image Captioning)这一任务的逐渐成熟,视觉故事生成(Visual Storytelling)任务逐渐引起了人们的研究兴趣和广泛关注。
视觉故事生成任务是一项计算机视觉与自然语言处理交叉领域的多模态学习任务。简单来说,其要求算法模型能够对多张图片所组成的序列内容进行理解,并表述为与图像序列内容相关且逻辑合理的一段故事文本。可以认为视觉故事生成是图像内容描述任务的衍生,在面向图文游记自动生成、教育、视障人士辅助等领域具有较好的科学意义和应用价值[1-3]。
与图像描述任务[4-5]相比较,视觉故事生成任务所生成的故事文本除了要能够对图像序列中每幅图像进行客观描述外,还要尽可能考虑不同图像描述语句之间的连贯性、图像之间的事件关联性、整个段落的故事描述一致性等。因此,文字描述的前后逻辑和想象力是高质量故事生成的基本要求。
当前视觉故事生成任务的研究主要存在以下两个比较突出的问题。
首先,现有的视觉故事生成模型对于图像视觉特征的利用还不够充分,特别是对于图像区域的细粒度视觉特征信息表达较少。当前视觉故事生成算法对视觉特征提取的有效性主要依赖于目标检测模型的性能。因此,所生成的故事文本对于图像中细粒度特征描述较为薄弱。特别是,端到端的视觉故事生成模型效果总体不佳,生成的故事文本多样性偏低,文字内容的丰富程度也不够。
其次,多数视觉故事生成方法采用编码器-解码器结构,即先将图像编码为抽象的中间特征向量表示,然后进行解码,生成故事文本。在整个故事生成过程中,输入的图像视觉信息被高度抽象。因此,图像内容的语义概念表达不直观,故事生成机制也缺乏可解释性。
为了缓解上述问题,本文提出了一种有效的、基于细粒度视觉特征和知识图谱的视觉故事生成算法。其中,算法在进行细粒度视觉信息表示时,采用场景图关联不同的局部视觉元素,采用图卷积的方式学习嵌入场景关系的局部视觉特征,可以较好地解决视觉信息表示不充分、不具体的问题;同时,在图像语义概念学习阶段,算法引入Visual Genome外部知识图谱,采用图像自扩充和图像序列关联扩充的方式来丰富图像的语义概念,可以较好地解决生成故事文本的多样性和图文相关性问题。本文算法在目前已公开的、规模最大的视觉故事生成数据集(VIST)Visual Storytelling[6]上进行了评测。通过与主流先进算法进行实验对比发现,本文算法生成的故事在保证对图像序列内容描述正确的前提下,增强了故事文本的丰富多样性、图文相关性、逻辑合理性。特别是,在故事文本的图文相关性和故事逻辑性方面,比之前的工作有较明显的优越性能。
本文的贡献主要体现在以下三个方面:
(1)本文基于场景图学习提出的关系嵌入型图像细粒度视觉特征,能够用于弥补以往模型中普遍存在的视觉信息表达不够细致或过于全局抽象的不足,在一定程度上解决了生成故事文本与图像内容关联较小的问题。
(2)本文在Visual Genome数据集的基础上构建出适用于当前任务的常识知识图谱,并提出了较为有效的语义概念词集扩充策略。通过利用知识图谱丰富的与图像内容相关的语义概念,能够较有效地解决故事文本词汇多样性不够的问题。
(3)基于图像的细粒度视觉特征和外部知识图谱,本文提出了一种新的、有效的视觉故事生成算法,在公开的大规模数据集VIST 上取得了较同期业内先进算法更为优越的故事描述性能。
1 相关工作
视觉故事生成任务是当前计算机视觉和自然语言处理交叉领域跨模态信息处理的研究热点。近年来,无论是视觉故事生成任务,还是与视觉故事生成密切相关的先行任务——图像描述,均涌现了不少优秀的算法。我们将主流视觉故事生成算法大致分为端到端(End-to-End)生成和多阶段(Multi-Stage)生成两大类方法。
1.1 端到端的方法
受机器翻译领域中Seq2Seq模型[7]的启发,早期的视觉故事生成模型大多采用端到端的“编码器-解码器”结构。基本思路是,使用预训练好的卷积神经网络(Convolutional Neural Network,CNN)模型作为编码器提取图像的视觉特征,用循环神经网络(Recurrent Neural Network,RNN)对图像序列进行编码,然后用新的循环神经网络作为解码器并行或依次对每幅图像进行描述,最后将所有描述按照图像顺序串连成故事的完整文本。
代表性的工作有:Kim 等人[8]提出的基于全局-局部注意力和上下文级联机制的GLAC 模型。其中,视觉信息包含每幅图像的Res Net特征及图像序列经过BiLSTM[9]后输出的信息,最后逐幅图像使用LSTM 进行级联解码生成故事。Wang等人[10]提出对抗奖励学习(AREL)模型,将强化学习应用到解码反馈过程。该模型利用预训练卷积神经网络提取图像的视觉特征,解码过程则基于GRU-RNN[11]使用视觉特征编码和上下文向量进行文本生成。
端到端方法的优点是,对图像序列中单幅图片内容的描述正确性较好,但是生成的故事在词汇丰富程度和故事想象力方面表现较差,生成的往往是比较单调的句子文本,限制了生成故事的文本多样性和故事内容的生动性。
1.2 多阶段生成的方法
不同于端到端方法的“编码器-解码器”结构,多阶段故事生成方法的常见做法是,显式地学习图像序列中间层信息表示,并进行某种形式的优化或迭代,最后再送入解码器进行故事生成。根据是否引入外部知识,我们又将多阶段生成的方法分为两个子类:一类是不引用外部知识,仅将图像转换为中间信息表示后直接输入解码器生成故事;另一类是在将图像转换为中间信息表示后,引入外部知识数据,对图像的中间信息表示进行处理,再输入解码器生成故事。
1.2.1 不引用外部知识的多阶段生成方法
代表工作主要有:Wang等人[12]提出采用场景图的形式来丰富图像的语义表示。因为场景图能够显式地表示图像的语义对象和关系,他们首先将每幅图像转换成场景图,并在单幅场景图上进行图卷积和聚合操作,丰富图像局部区域的表示,最后用时序卷积网络(TCN)来提取包含一定图像序列上下文关联的表示,进行最终故事文本的生成。Jung等人[13]提出采用一种三阶段训练的课程学习方式来完成视觉故事生成。该方法通过逐步随机隐藏零张、一张或两张图片的视觉信息来训练“想象模块”,提高模型的合理想象能力,细化图像具体语义之间的关系,最后采用循环神经网络GRU 和非局部自注意力机制解码讲述每幅图像对应的描述语句,并连成故事。
1.2.2 引入外部知识的多阶段生成方法
随着近年来知识图谱在人工智能各个领域如计算机视觉、自然语言处理和机器学习等领域逐渐被广泛应用并取得优秀性能[14-16],最新的一些工作陆续开始引入外部知识辅助故事生成,以缓解文本词汇多样性不足的问题,代表性工作是Hsu 等人[17]提出的KG-Story模型。该模型在第一阶段通过术语生成器对图像进行术语词集提取,第二阶段利用外部大型的Visual Genome数据集对第一阶段生成的术语词集进行丰富,最后根据第二阶段扩充的术语词集,使用Transformer 模型进行故事生成。Hsu等人[18]提出的PR-VIST 模型首先将输入图片序列统一表示为基于图结构的数据,然后训练故事线预测器从所构建的图结构数据中寻找故事线的最佳路径,最后通过迭代生成的方式,基于Transformer解码器模型生成故事。Yang等人[19]提出了一种基于常识驱动的视觉故事生成模型,该模型从外部知识库中引入关键的常识数据,提升所述故事的合理性与多样性。Chen等人[20]提出的CKVS 模型,一方面对图片进行概念词提取,并根据外部知识图谱Concept Net[21]对概念词进行扩充建图;另一方面,利用残差网络ResNet抽取图像的全局视觉特征,用循环神经网络学习视觉序列信息;最后将视觉特征和概念词输入至解码器进行故事生成。
多阶段生成的方法的优势在于,能充分挖掘图像丰富的内在语义信息,或利用外部辅助知识,提升图像序列故事描述的多样性和想象力。
2 本文所提出的视觉故事生成算法
2.1 任务描述与模型框架
给定一串图片序列I={I1,I2,I3,I4,I5},视觉故事生成任务即要求算法通过理解图片内容及相互之间的序列关系,生成一段连续流畅的故事文本S={S1,S2,S3,S4,S5}。S表示生成故事中句子集合。
算法模型框架如图1所示。本文所做工作集中在如何对图像内容进行充分挖掘和扩展表示上,主要包括图像细粒度视觉特征生成器Gf和图像语义概念词集合生成器Gc两方面。
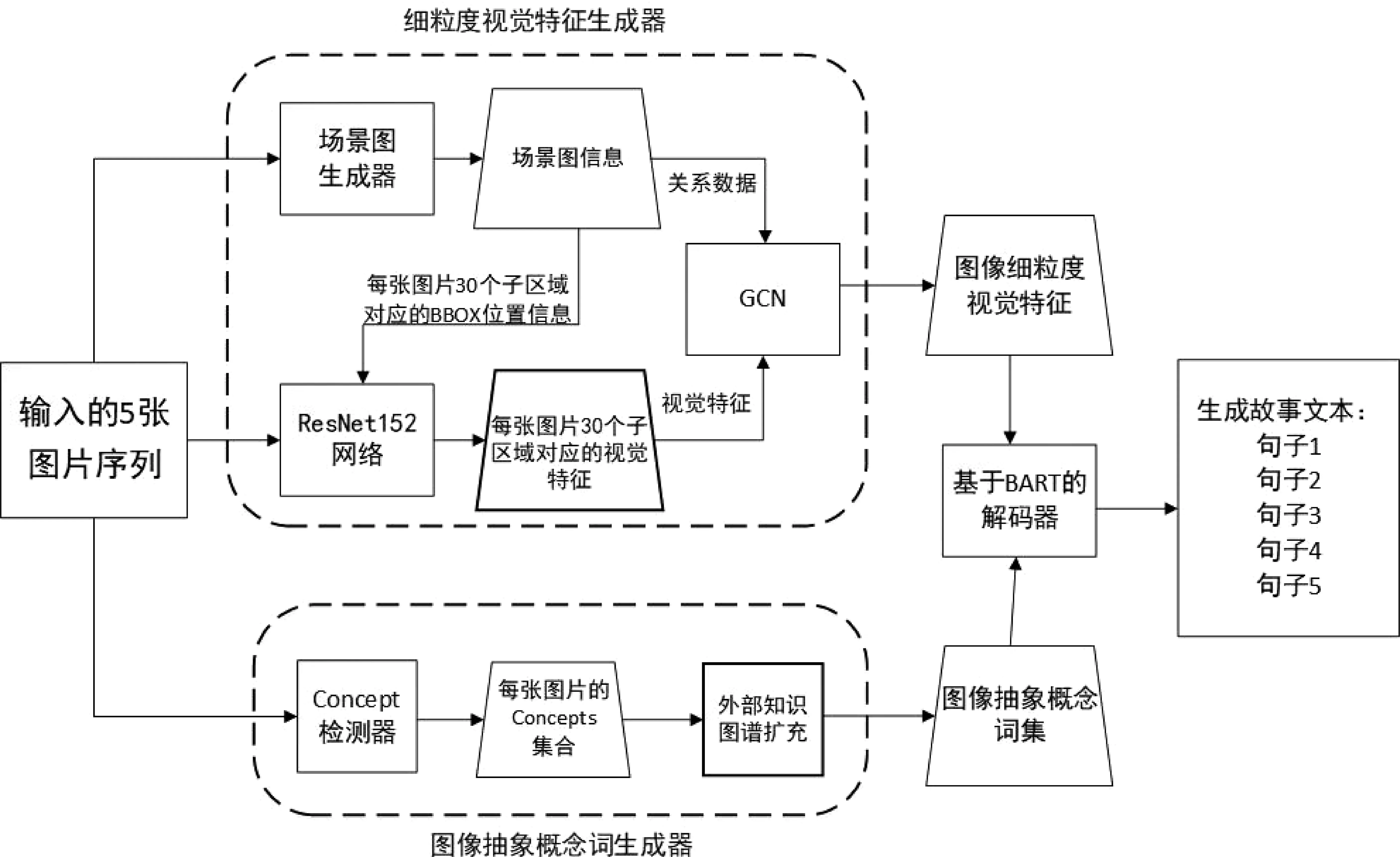
图1 基于细粒度视觉特征和知识图谱的视觉故事生成算法模型框架
图像细粒度视觉特征生成器首先使用预训练好的场景图生成器Gs对图像进行场景图生成,得到每张图像的场景图表示SG={O,B,R},其中,O表示图像中的所有对象节点的集合,B表示每个对象节点对应的区域位置信息,R表示实体与实体之间的关系三元组。然后,我们将图像I和每个对象节点O对应的区域位置信息B一起输入Resnet152网络模型[22]进行局部视觉特征提取,得到每个对象节点O对应区域的视觉特征,即图像的局部视觉特征集合。最后,基于场景图中目标物的邻接关系,我们利用图卷积操作对这些局部视觉信息进行关系嵌入学习,所得的新的关系嵌入型细粒度视觉特征集合即作为对应图像的视觉表示f。
类似地,将图像序列中的5张图片依次处理,并将所得到的视觉特征按顺序集合,最终得到包含5张图片序列的细粒度视觉特征信息集F。
图片语义概念词集生成器用于生成能够表示图像丰富内容的概念词集合。首先,我们基于Visual Genome数据集构建外部常识知识图谱KGE,同时利用Clarifai外部工具来生成初始语义概念词集Cori;然后,利用构造出的外部常识知识图谱KGE对初始语义概念词集Cori进行扩充,得到最终的扩充语义概念词集Cf。
故事生成的解码部分基于预训练好的BART模型[23]。我们将图片的细粒度视觉特征信息集F和图像对应的扩充语义概念词集Cf输入至BART模型,由BART 模型对其进行解码,生成最终的故事文本S。
2.2 图像细粒度视觉特征生成器
图像细粒度视觉特征生成器由图像场景图生成器Gs、图像局部视觉特征检测器Gp和图像细粒度视觉特征学习器Gf组成。
2.2.1 图像场景图生成器
场景图通常用于描绘图像中对象、对象属性及关系,可支持关系推理等高级任务,如图像描述和视觉对话生成[24]。在本文中,场景图生成模型采用Xu等人[25]提出的迭代消息传递模型,通过对象检测和关系推理得出场景图。
场景图生成器Gs的输入为单张图片,输出为场景图数据SG={O,B,R},其中包含了图像中检测到的对象节点集合O,以及每个对象节点对应的区域位置信息B,还有所有实体之间关系三元组集合R,例如<man,holding,cup>。具体如式(1)~式(4)所示。

其中,BBOX_i为第i个节点对应区域的边界框坐标和大小信息。考虑到从图像中检测出的对象节点区域数量可能较多,在本文中,我们经验性地保留分数最高的前30个对象区域,可以较好地涵盖图片的绝大部分有用信息。
2.2.2 图像局部视觉特征检测器
在以往的图像描述任务中,获取图像视觉特征的常见做法是,将单张图片输入预训练好的卷积神经网络模型[26],抽取图像的整体视觉特征。这种方式在一定程度上会丢失图像中某些显性较差的对象信息,使得最后可能因为图像视觉内容表示不充分而导致生成描述语句不全面、不丰富等问题。
为了减少图像视觉特征信息丢失问题,我们利用图像局部视觉特征检测器Gp,对图像进行局部的细粒度视觉特征提取,得到图像中更多更具体的视觉特征信息,具体做法是:将图像I和图像场景图生成器得到的每个对象节点对应的区域位置信息B同时输入至ResNet152网络,对每个对象节点区域进行局部视觉特征提取,从而得到每个区域的局部视觉特征fp。
2.2.3 细粒度图像视觉特征学习器
根据图像场景图生成器Gs,我们得到了图像中对象节点之间的关系三元组R;根据图像局部视觉特征检测器Gp,我们得到了每张图像中对象节点的视觉特征fp。为了能够将对象节点之间的关系应用到后续的实验过程中,即在故事生成阶段能够使用到图像中对象节点之间的关系,我们将对象节点对应的视觉特征fp和对象节点之间的关系三元组R输入至图卷积神经网络GCN[27],最终学习得到带有对象节点之间关系的细粒度图像视觉特征表示F,具体如式(5)所示。
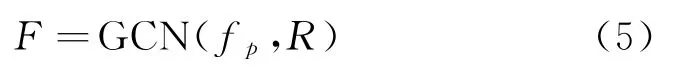
2.3 基于知识图谱的图像抽象概念词集生成器
知识图谱是人工智能的重要分支技术,在信息检索、自然语言处理、智能助手、电子商务、医学等领域发挥着重要作用[28-29]。为了能够在视觉故事生成的过程中充分模拟人类讲故事的方式和思路,我们希望借助外部知识来充当人类大脑的想象力这一角色,使得在故事生成的过程中不再局限于对图片内容的简单描述,而是在对图片内容的理解基础上,增加想象力,生成相对丰富多彩的故事。2.3.1 外部常识知识图谱构建
我们以Visual Genome数据集作为外部知识的数据来源。该数据集中提供了108 077张图片所对应的1 531 448 组“节点-关系-节点”三元组<subject,relation,object>信息。每张图片包含有subject、relation、object等数据字段,三元组信息表示“subject”节点与所指向的“object”节点存在关系“relation”。
为了得到具有代表性的常识知识图谱数据,我们从Visual Genome数据集中选取出现频率大于100次的关系三元组(共计保留2 840组)用于构建本文所使用的外部常识知识图谱KGE,如表1所示。

2.3.2 基于常识知识图谱的图像语义概念集扩充
首先,使用Clarifai①http://www.clarifai.com概念词检测器提取每张图片的初始语义概念词集合。综合考虑算法效率和语义信息表示的充分性,我们选取置信度较高的前30个概念词作为概念集合的初始元素Cori={c1,c2,…,c30}。然后,使用已构建的外部知识图谱KGE对其进行合理扩充,得到扩充后的中间概念词集Cm;最后,为了建立图片序列中相邻图片之间的语义联系,我们对相邻两张图片的概念词集进行了关联度查找,得到每张图片对应的最终语义概念集合Cf={c1,c2,…,cn},其中n为语义概念词集合大小。在本文,n设置为最大不超过60。
具体地,语义概念词集合扩充过程包括对单张图像的语义概念集自扩充和相邻图像之间的关联性扩充两项操作。
(1)单张图像的语义概念集自扩充
基于初始语义概念词集Cori,从外部知识图谱KGE中检索并筛选出与Cori中ci相关联的三元组信息<ci,relation*,objectj>,将其对应的objectj加入至Cori,得到自扩充集合Cm。
(2)相邻图片之间语义概念集关联性扩充
在已知相邻两张图片的自扩充语义概念集Cm1和Cm2的基础上,对于相邻两张图片I1和I2中的任意语义概念词ci1和cj2,如果在外部常识知识图谱KGE中存在<ci1,relation*,cj2>,则将cj2加入Cm1,直至在KGE中全部查找完毕,最终得到图片I1最终的语义概念关联性扩充后集合Cf1。
3 实验与评估
3.1 数据集
3.1.1 VIST 数据集
VIST 数据集[6]包含图像和文本两部分数据。图片数据包含20 211个图片序列,共计81 743张图片。文本数据包括针对单张图片的描述性语句(Description-in-Isolation,DII)及其在图像序列中的故事性叙述语句(Story-in-Sequence,SIS)。每个故事包含了5张图像序列和与之对应的5句故事性叙述语句,即一段连贯的故事描述,故事描述能够基本正确、丰富地将图像序列的内容进行描述。在本文中,我们主要用到的是VIST数据集中的图片数据和故事性叙述语句(SIS)来进行模型的训练和测试。
3.1.2 Visual Genome数据集
Visual Genome数据集[30]包含108 077 张图片,380万个对象实例和230万个关系。该数据集将结构化的图像概念和自然语言文本进行关联,构建起较为庞大的多模态知识库。
数据集由以下四个部分组成:①图像局部区域描述:每张图片被划分成多个区域,每个局部区域都有标注并与之对应的一条自然语言描述语句。②局部场景图:每个图像的局部区域中的对象、属性、关系被提取出来,构成局部的场景图。③图片全局场景图:由图片中的所有局部场景图合并成一个全局场景图。④视觉对话:针对单张图片的问答对话。其中,问题主要分为两类,一类是针对图片局部区域来提问,另一类是针对整张图片来提问。在本文中,我们主要使用该数据集的图像描述数据进行外部常识知识图谱的构建,主要包括主体(subject)、客体(object)及主客体之间的关系(relationship)数据。
3.2 实验细节
本文模型使用Py Torch 1.7版本实现。细粒度视觉特征维度为2 048,语义概念词的词嵌入向量维度为512。
本文与近期主流的视觉故事生成模型进行对比。所对比的基线模型主要有:①采用端到端结构的PR-VIST[18]模型;②采用中间层Term 语义词集的多阶段故事生成模型KG-Story[17];③采用知识图谱及BART 模型作为解码器的故事生成模型CKVS[20]。
3.3 自动指标评价及结果
视觉故事生成任务与传统的机器翻译等自然语言处理任务相比,从本质上来说有着较大的差异。相较于机器翻译任务所追求的翻译准确率,视觉故事生成任务考虑更多的是,在保证故事内容和视觉图像语义相关的基础上,生成更加丰富多样的文本,而不是仅考虑保持和“参考故事(Ground-Truth)”在字词上的完全一致。
在本文中,我们主要采用多样性指标Distinct-N[31]和TTR(Type-Token Ratio)[32]对生成的故事文本的多样性进行评价。
Distinct-N计算测试数据集中所有生成的故事叙述语句中具有唯一性的N-gram[33]短语的百分比。分数越高意味着故事间词汇的重复值更低。生成故事文本的词汇多样性指标Distinct-N评价结果如表2所示。其中,Gold为VIST 数据集中提供的人工撰写的故事文本。
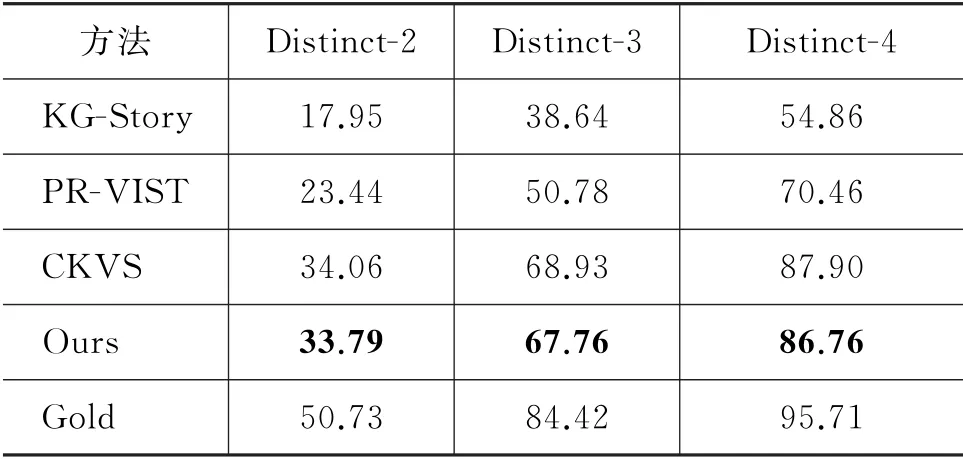
表2 故事文本多样性Distinct-N 评价对比结果(单位:%)
从表2的实验数据可以看出,在VIST 数据集的测试集上,在Dist-2、Dist-3、Dist-4 指标中,本文算法较KG-Story模型分别提升了15.78、28.12、31.90,较PR-VIST 模型分别提升了10.29、16.98、16.30,均具有较大幅度的提升。与CKVS模型相比,本文模型在多样性指标Distinct-n上虽然略有偏低,但差距非常小,说明了本文模型能有效地生成词汇丰富的故事。
值得说明的是,CKVS模型对所检测的概念词采取了较为复杂的选择策略,并且在故事生成阶段分配给每张图片的概念词集合的词语个数为100,而本文的抽象概念词个数仅在60个以内。本文在词语数量较少的情况下,仍然能够取得与CKVS较为接近的多样性指标性能,很大程度上得益于本文在概念词集方面的简单有效的关联扩充方式。
多样性评价指标TTR 是用于评价作家或演讲者使用词汇丰富程度的一种多样性度量方法。通过使用单个词的类型数量除以整个词的数量计算类型词汇的覆盖情况。但TTR 指标对文本长度比较敏感。一般情况下,文本越长,出现新词类型的可能性就越低。因此,为了计算TTR,我们还一并计算了每个生成故事的平均词语(Words)个数和唯一词(Terms)个数。我们对基线模型生成的故事和本文模型所生成的故事进行了TTR指标、平均Words个数,平均Terms个数的对比。具体结果如表3所示。
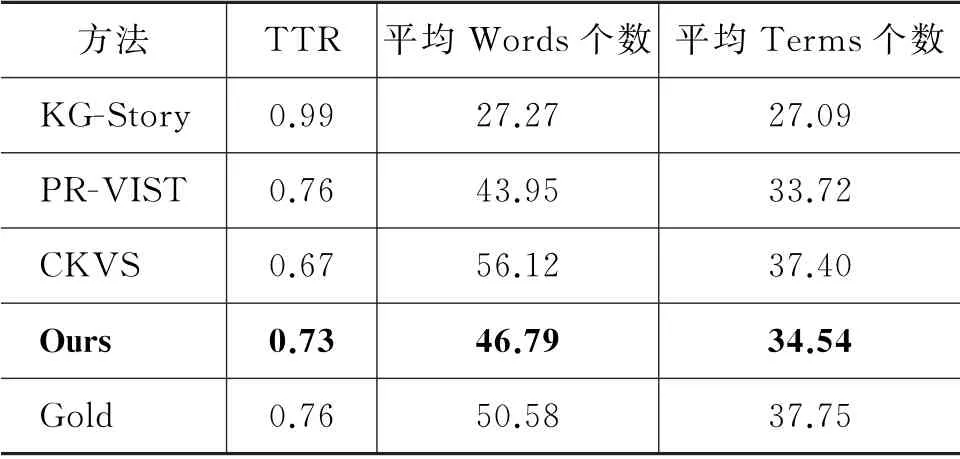
表3 故事文本丰富性TTR 评价对比结果
需要指出的是,KG-Story生成的故事文本平均Words个数最少,仅为27.27,远远低于其他模型,因此虽然其对应的TTR 值接近1,但我们认为不具有对比意义。相比之下,PR-VIST,CKVS 以及本文模型,文本长度和Terms类型的数量均与“Gold”文本接近,因此,TTR 指标对该三个模型具有一定的可比性。
从表3的实验结果我们可以看出,PR-VIST 模型虽然TTR 指标略高于本文算法,但是其平均Words个数和平均Terms个数均低于本文模型。尽管CKVS模型的平均Words个数最多,但是其TTR值并不高,我们的模型较CKVS模型TTR值提高了9%。
综合表2和表3的结果来看,本文模型生成的故事在多样性指标上较当前主流的方法有了较大的提升,特别是与没有引入外部知识图谱的方法相比,多样性得到了显著提升。这不仅得益于本文考虑了细粒度视觉特征,更多的是由于引入了外部知识数据并构造合理的知识图谱,并将构造的知识图谱与已有的图像抽象概念信息结合,因此取得了较好的多样性效果。从后续的人工评价结果中也可以再次证明我们的模型生成的故事文本,在保证图文相关性和准确性的基础上,具有较好的文本丰富性。
3.4 人工评价及结果
对于视觉故事生成任务,没有任何指标能够完美地衡量生成故事的好坏[10]。为了更好地评估生成故事的质量,我们对生成的故事进行了了人工评价,将多个模型的成对输出进行比较。
我们从测试集中随机抽取100个图像序列,并使用每个模型生成故事。对于每个样本故事对,有两名评价员参与判断,评价员需要选择每个样本故事对,在图文相关性、故事逻辑性、文本丰富性方面对其中一个故事的偏好。其中,“文本丰富性”主观评价与“Distinct-N”客观指标所度量的意义有相似之处。
为了保证评价员自身的水平及选取评价员的合理性和有效性,我们招募了具有良好英文水平的在校大学生作为评价员进行人工评价。结果如表4所示。其中,“中立”表示对比的两个模型结果不相上下,没有倾向。

表4 人工评价结果
表4的结果表明,本文模型所生成的故事文本在图文相关性、故事逻辑性、文本丰富性上均远超过KG-Story和PR-VIST 模型。与CKVS模型相比,本文模型在图文相关性、故事逻辑性两方面具有较明显的优势,在文本丰富性上略高于CVKS 模型。文本丰富性评价的结论与前述“Distinct-N”指标的结论接近,这也从侧面反映了本文的人工评价结果质量较高,具有良好的合理性。
3.5 消融实验
为了评估细粒度视觉特征和外部知识图谱在模型中的作用,我们以本文模型为基线模型进行消融比较。
人工撰写的故事叙述“Gold”最大的优势就在于文字逻辑性强、句式丰富、图文内容相关性强等。我们使用自然语言处理领域常用客观评价指标BLEU、METEOR、ROUGE、CIDEr来评估所生成的故事与人工撰写的故事在词句上的相似性,从而衡量所生成的故事文本与人工撰写版本的忠实还原程度。
3.5.1 消融实验1:细粒度视觉特征的有效性
本文模型将细粒度视觉特征作为视觉信息输入,以经过外部知识图谱扩充后的抽象概念词集作为文本信息输入,基于BART 解码器生成故事。“全局视觉特征变体模型”是将本文模型中的细粒度视觉特征替换为全局视觉特征的变体模型,其他设置如解码器和概念词集合等均保持不变。实验结果如表5所示。
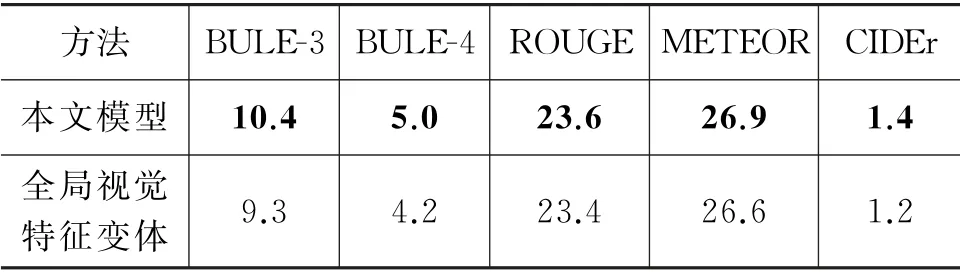
表5 在VIST数据集上,细粒度视觉特征消融实验在5种客观评价指标上的性能对比
表5的结果表明,在不改变基线模型框架的前提下,采用细粒度视觉特征相较于采用全局视觉特征,在 BLEU[34]、METEOR[35]、ROUGE[36]、CIDEr[37]等指标评价上均有所提升,其中BLEU-3提升了11.8%,BLEU-4提升了19.0%,ROUGE 提升了0.9%,METEOR 提升了1.1%,CIDEr提升了16.6%。这说明采用细粒度视觉特征所生成的故事文本在词句表达方面比采用全局视觉特征更忠实于人工撰写的故事文本,即在图文相关性上表现更好。
3.5.2 消融实验2:外部知识图谱扩充的有效性
我们将本文模型中的外部知识图谱删除后的变体模型与基线模型进行比较。
本文模型将细粒度视觉特征作为视觉信息输入,以经过外部知识图谱扩充后的抽象概念词集作为文本信息输入,基于BART 解码器生成故事。“无外部知识图谱变体模型”是将本文模型中的外部知识图谱删除,即对抽象概念词集不利用外部知识图谱进行任何丰富性扩充操作后的变体模型,其他设置如细粒度视觉特征和解码器等均保持不变的变体模型。实验结果如表6所示。
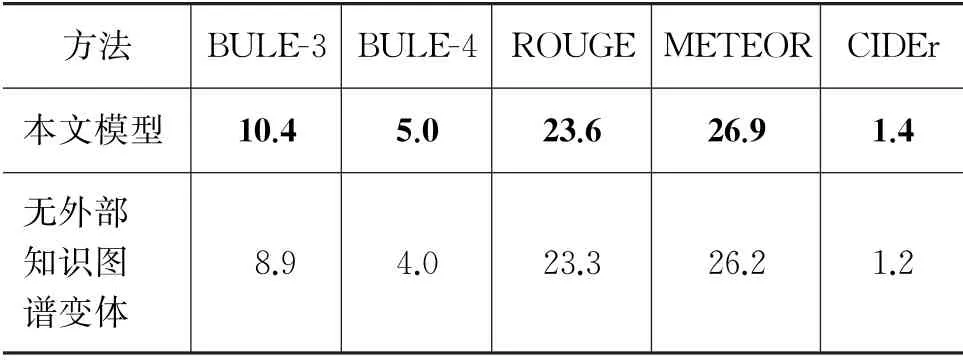
表6 在VIST数据集上,有关外部知识图谱扩充的消融实验在5种客观评价指标上的性能对比
结果表明,模型采用外部知识图谱对抽象概念词集进行丰富性扩充后的概念词集合,相较于不使用任何外部知识进行处理的抽象概念词集作为输入,在BLEU、METEOR、ROUGE、CIDEr等指标评价上均有所提升,其中BLEU-3提升了16.8%,BLEU-4提升了25.0%,ROUGE提升了1.3%,METEOR提升了2.6%,CIDEr提升了16.6%。
3.6 可视化故事生成示例
为了更好、更形象地展示我们生成的故事质量和词语丰富性,我们提供了使用VIST 数据集训练的基线模型和本文模型实际生成的示例,如表7所示。总体而言,相比基线模型,本文模型所生成的故事文本更加忠实于图像视觉内容,而且语句之间的逻辑性更好,表达也更为自然、流畅。我们在表7的示例中也可以看出,本文模型故事文字所表达的语境比“Gold”文本还要自然一些。

表7 在VIST数据集训练的基线模型和本文模型实际生成的示例

续表
综上所述,本文模型所生成的故事文本兼具多样性高、图文相关性强、故事逻辑性好的优势,能够较好地解决前述的目前视觉故事生成任务存在的两个突出问题。
4 总结
本文提出了一种有效的、基于细粒度视觉特征和知识图谱的视觉故事生成算法。算法通过图像实体关系场景图学习关系嵌入型细粒度视觉特征,利用外部知识图谱丰富扩充序列图像的高层语义概念表示,能够有效地对图像内容进行充分挖掘。本文算法在公开的VIST数据集上与主流先进算法进行了测试比较。实验结果表明,本文算法在图文相关性、故事逻辑性、文字多样性等方面均取得较大领先优势。结合图像细粒度视觉特征和外部知识图谱,可以有效地增强对图像细节的识别,提升生成故事文本的丰富多样性、逻辑性和想象力。
