基于双重情感感知的可解释谣言检测
2022-11-07葛晓义张明书
葛晓义,张明书,魏 彬,刘 佳
(1.武警工程大学 密码工程学院,陕西 西安 710086;2.武警工程大学 网络与信息安全武警部队重点实验室,陕西 西安 710086)
0 引言
社交媒体的快捷性和便利性等优点给工作、生活和学习带来了巨大的便利,为用户发布、分享和获取各种信息提供了便捷的渠道。目前社交媒体已成为各国发布外交政策和相关评论的重要平台,也演变成网络认知战的主战场。然而不可忽视的是,社交媒体的谣言泛滥,严重影响了网络的良性发展,甚至影响着社会、经济和文化的发展。新冠肺炎疫情防控期间,博人眼球的虚假消息,对疫情防控造成了一定干扰。有效检测谣言有利于净化网络空间和维护社会稳定,具有重要的现实意义[1],为了遏制谣言传播,消除谣言带来的影响,越来越多的学者致力于谣言检测任务[2]。
情感分析作为文本分析中确定文本表达情感极性和强度的部分,常被用于谣言检测任务中。Wu[3]等人考虑到谣言和用户评论之间存在情感关联和语义冲突,提出了自适应交互融合网络来实现特征之间的交叉交互融合,从而捕获帖子和评论之间的相似语义和冲突语义。Guo[4]等人分别提取谣言和用户评论的语义及情感特征进行谣言检测,取得较好效果。Zhang[5]等人通过情感字典获取谣言和用户评论的情感表示来探究二者之间的情感差,将情感特征作为增强特征进行谣言检测。
然而上述方法仍有一定的局限性。首先,没有考虑谣言和用户评论的情感相关性,以及谣言语义和用户评论情感的相关性。用户评论往往是较短的句子,导致语义特征不够丰富,而用户评论中蕴含着对谣言明确的态度,情感更加丰富,因此用户评论的情感倾向更能反映检测内容的真假[6]。其次,没有从局部角度获取谣言和用户评论的情感特征。社交媒体中谣言和用户评论的句子往往较短,情感特征通常体现在个别情感色彩丰富的词汇上,因此获取局部情感特征更能表达情感倾向[7]。最后,在已有的可解释谣言检测模型中,仅利用谣言文本和用户评论[8]、转发用户序列和用户信息[9]等提供合理解释,忽视了从情感角度提供合理的解释。
针对现有研究的不足,本文提出一种基于双重情感感知的可解释谣言检测模型。为了从全局角度探究谣言语义和用户评论的相关性,首先,利用双向门循环单元(Bidirectional gate recurrent unit,Bi-GRU)和注意力(Attention)获取谣言语义特征和用户评论情感特征;其次,通过Co-Attention 获取谣言语义特征与用户评论情感特征的相关性,以筛选与谣言语义相关的用户评论情感特征并进行融合,利用协同注意力(Co-Attention)权重提供解释。为了从局部角度探究谣言和用户评论的情感相关性,首先,通过卷积神经网络(Convolutional Neural Network,CNN)提取谣言和用户评论的情感特征,其次,通过Co-Attention学习谣言与用户评论的情感相关性,旨在获取与谣言情感相关的用户评论情感特征进行融合,并利用Co-Attention权重提供解释。本文的贡献如下:
(1)提出一种新的可解释谣言检测模型,分别从谣言语义和用户评论情感以及谣言情感和用户评论情感出发进行谣言检测。
(2)通过Co-attention机制学习谣言语义与评论情感的相关性,以及谣言情感与评论情感的相关性,通过Co-attention权重从情感角度产生合理的解释。
(3)在真实数据集上的实验表明,与先进的模型相比,具有较好的检测效果和合理的解释性,实验代码开源在码云①https://gitee.com/wj_gxy/dual-emotion_aware。
1 相关工作
1.1 谣言检测
谣言检测根据特征通常分为基于谣言内容、基于社会上下文及基于混合特征的方法。谣言内容可以分为文本和视觉两个方面,文本方面指根据谣言的语言风格[10]、写作风格[11]和情感[12-14]等提取文本特征和情感特征,例如刘[13]等人提出使用卷积神经网络提取文本特征进行的谣言检测模型,Cui[14]等人通过实验表明,情感分析对系统性能的影响最大。视觉特征则是从视频或图片中提取特征[15]。基于社会上下文的检测方法一般可以分为基于用户和基于网络。前者是根据谣言发布者和转发用户的特点进行建模[11,16],特征主要包括用户性别、粉丝数、用户配置;后者通过社交网络中的转发或关注结构的特征进行谣言检测,如:Bian[16]等人利用双向图神经网络模型学习嵌入谣言传播。基于混合特征的方法是融合多模态或者多重特征进行谣言检测,如Wu[17]等人分别学习文本和图像的表示,利用模态的上下文注意力网络融合模态内(Intra-modality)和模态间(Inter-modality)的关系进行谣言检测;Zhang[5]等人在通过情感词典获取发布者情感、用户评论情感和情感代沟,作为假新闻检测器的补充特征,取得了很好的效果。
近年来的研究趋向于可解释谣言检测[18],主要通过提取用户信息[19]、转发序列[9]、新闻内容和用户评论[8]等来提供解释。Lu[19]等人利用两次协同注意力机制通过突出可疑的转发者以及他们关注的话语来生成解释。Jin[20]等人通过对微妙线索的细粒度建模来提高检测的,准确性和可解释性。
1.2 深度学习可解释性
虽然深度学习模型在越来越多领域得到应用,却常因不具备透明度、可信度以及不符合伦理道德标准等遭诟病,因此对深度学习可解释性的需求也越来越高[21]。近年来,深度学习可解释性模型开始在越来越多的领域应用,如网络安全[22]、推荐系统[23]、医疗[24]、社交网络[19]等。深度学习可解释性模型一般是指模型决策结果以可理解的方式呈现,能够帮助理解复杂模型的内部工作机制以及模型做出特定决策的原因[25]。可解释性一般分为内在可解释性和事后可解释性[26]。内在可解释性[8]是通过构建将可解释性直接纳入其结构的自解释模型来实现的,而事后可解释性[27]需要创建第二个模型来为现有模型提供解释。在谣言检测中应当更倾向于内在可解释性,在检测结果中就存在着自解释的信息。
2 本文模型
本文提出的可解释谣言检测模型分别从全局和局部对谣言和用户评论在情感上的关系获取特征,进行谣言检测。模型如图1所示,主要由四部分构成:①https://github.com/Embedding/Chinese-Word-Vectors嵌入层,利用词嵌入向量和情感嵌入向量对谣言和用户评论进行向量表示;②特征提取层,通过Bi-GRU 与Attention获取谣言的语义表示和用户评论的情感表示,通过CNN 获取谣言和用户评论的情感表示;③双重情感感知层,分别依据谣言语义特征与用户评论情感特征,以及谣言文本情感特征与用户评论情感特征,通过Co-attention获取谣言语义特征与用户评论情感之间的相关性和谣言情感特征与用户评论情感特征的相关性;④预测层,将Co-attention 获取的特征进行拼接,通过Softmax分类。

图1 可解释谣言检测模型框架
2.1 嵌入层
在进行特征提取前,首先对每个词进行词向量嵌入和情感向量嵌入。英文词向量嵌入采用Robyn[28]等人预先训练好的Numberbatch词向量,在词向量相似性上优于Word2Vec[29]和Glo Ve[30],中文词向量采用预训练的微博词向量①。
受情感建模工作文献[31]的启发,本文将情感元素融入到预先训练好的词向量中获取情感嵌入向量。该方法基于NRC 情感词典创建了两组约束,一组用于与情绪(例如绑架,悲伤)具有积极关系的单词,另一组用于跟踪与该情绪相反的每个单词(绑架,喜悦),喜悦是悲伤的反面。
通过增加一个新的训练阶段,使用情感词汇和基本情绪词汇将情感信息拟合到预训练的Numberbatch词向量中获取情感向量。在训练情感嵌入时采用的正面与反面的约束字典以及中英文向量大小统计如表1所示。
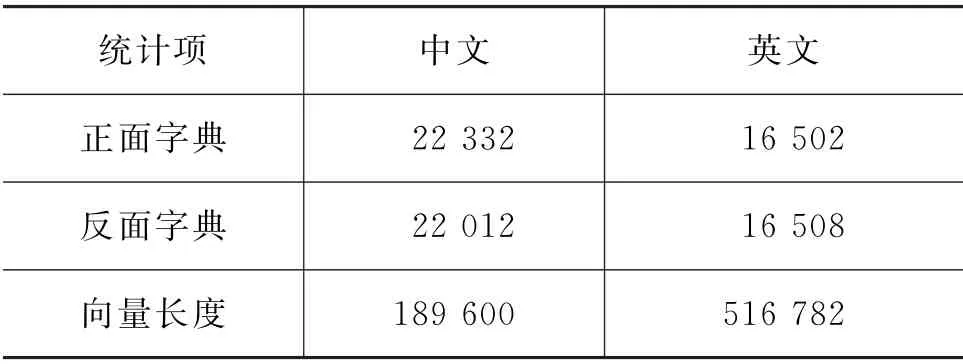
表1 字典统计
2.2 特征提取层
经过数据预处理后,一条谣言由M个句子组成,其中每个句子s由m个词组成si=[xi1,xi2,…,xim],一条谣言对应的用户评论由N个句子组成,其中每个句子e由n个词组成ej=[xj1,xj2,…,xjn]。经过预训练的词向量和情感向量表示后用于提取语义特征和情感特征。
2.2.1 语义特征提取
理论上RNN 能够捕获长期依赖,但在实践中,旧的记忆会随着序列变长而消失。为了捕获RNN的长期依赖关系,使用GRU 来确保更持久的内存。虽然词中都包含上下文信息和整个句子的信息,但是句子中每个词的重要性不同。具体如图2所示。

图2 语义特征提取过程
谣言中的词汇往往与上下文具有关联性,具有较强的双向语义依赖,因此逆序处理十分必要,采用Bi-GRU 从词的两个方向建模获取谣言语义特征。词嵌入的向量si=[wi1,wi2,…,wim]通过Bi-GRU可以得到,如式(1)所示。

通过连接前向隐藏状态和后向隐藏状态,获取词的特征表示通过注意力机制学习词的重要性来获得句子向量s∈R2d×m如式(2)所示。

其中αit衡量tth单词对新闻内容s的重要性,αit计算如式(3)所示。
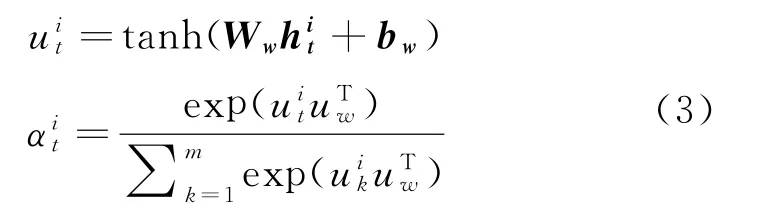
其中,uit是通过完全嵌入层从隐藏状态hit获得的,Ww和bw是可训练的参数,uw为权重矩阵。
2.2.2 情感特征提取
在模型中共提取三部分情感特征,图中一部分用户评论的情感特征与谣言语义特征提取方法相同,采用Bi-GRU 与Attention的方法获得用户评论的情感特征E=[e1,e2,…,eN]。
其中谣言情感特征与另一部分用户评论情感特征采用CNN 模型提取,CNN 模型能够较好地提取局部特征,并且模型训练的效率高,因此选用一维卷积神经网络提取谣言情感特征U=[u1,u2,…,uM]与用户评论情感特征V=[v1,v2,…,vN],具体方法如图3所示。
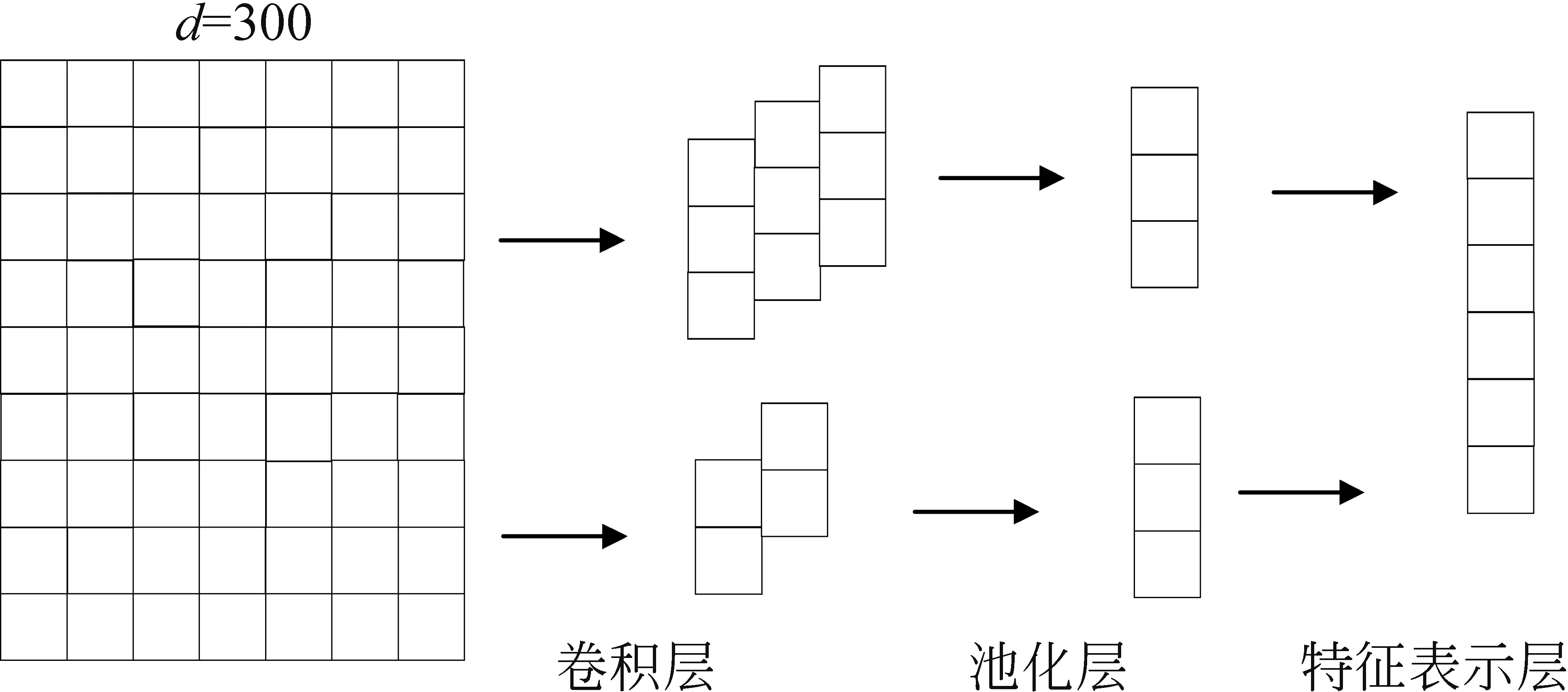
图3 基于CNN 的特征表示
对用户评论中某一行评论情感嵌入后的向量ej=[wj1,wj2,…,wjn]∈Rn×d进行卷积操作:

其中,W∈Rλ×d是可学习的参数矩阵,b是偏置项,ReLU 是激活函数。对卷积得到的hj进行最大池化可得到每一句评论的情感特征:
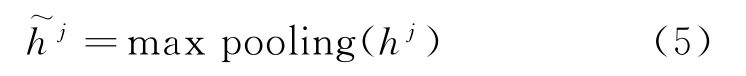
CNN 层使用两个过滤器(λ∈{2,3})来获取多个特征,将不同的输出连接起来,形成vj作为用户评论的单个表示。最后可以得到用户评论中每个评论的情感特征,形成用户评论的情感矩阵V=[v1,v2,…,vN]。
2.3 双重情感感知层
用户评论中往往包含着大量的与谣言相关的信息,但它们信息量较小,噪声较大。因此利用谣言自身进行谣言检测和解释谣言真假是薄弱的,而评论中情感丰富,与语义特征相比,情感特征更加突出,更有利于谣言检测,并能通过情感反映谣言真假的原因。通过协同注意力机制学习评论情感与谣言的相关性,利用情感的注意力权重和谣言中的词汇来进行谣言检测和谣言解释,具体过程如图4所示。

图4 协同表示过程
谣言表示为:S=[s1,s2,…,sM],评论情感特征表示为:E=[e1,e2,…,eN]。
首先计算相似矩阵F=tanh(EWseS),其中,F∈RN×M,Wse∈R2d×2d,是可学习的参数矩阵。将相似矩阵作为一个特征,则可以学习谣言语义特征和用户评论情感特征的协同表示。

Ws、We∈Rk×2d为可学习的参数矩阵,可以学习谣言文本和评论情感特征的注意力权重:
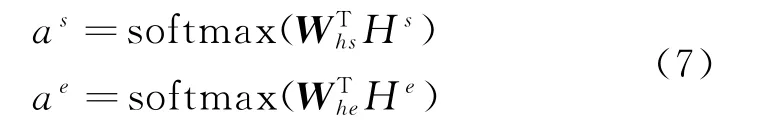
其中,as∈R1×M,ae∈R1×N分别是谣言中每个词和评论的情感特征中每个评论的注意权重。Whs、Whe是可训练权重。最终,通过加权协同表示。
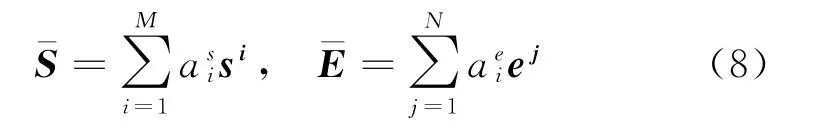
利用协同注意力机制对谣言情感特征和用户评论情感特征计算相似矩阵,获取对应的权重分别生成协同表示。
2.4 预测层
将提取到的特征通过全连接层输出,最后通过softmax函数来获得分类的结果,如式(9)所示。
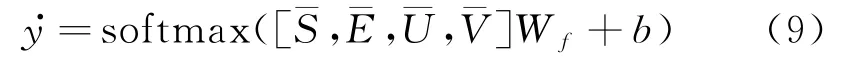
其中,为softmax函数计算的概率值,Wf为权重矩阵,b为偏置项。
3 实验结果与分析
3.1 实验数据
Twitter15和Twitter16[32]数据集选择“真”和“假”标签数据,数据集中都包含谣言内容、用户评论和相应的转发用户序列等信息。Weibo20由Zhang[5]等人在Weibo16[33]的基础上通过聚类算法去重,并增加了2014年4月至2018年11月被微博社区管理中心认定的虚假信息,形成新的数据集。Weibo20数据集包含谣言内容、用户评论和标签三部分信息。数据集的统计如表2所示。
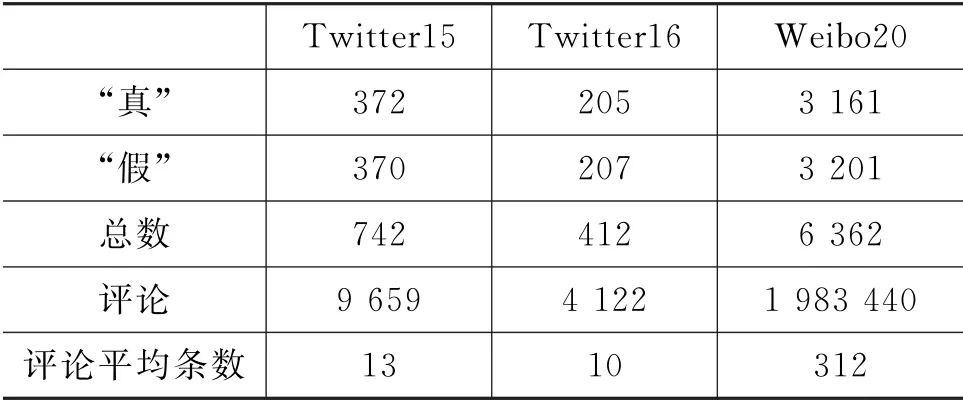
表2 数据集统计
3.2 实验设置
为突出本文方法的先进性,在上述数据集进行实验,将实验结果与先进模型进行比对和分析。
•RNN[33]:一种基于RNN 的方法,将社交上下文信息建模为可变长度的时间序列,用于学习谣言的连续表示。
•text-CNN[34]:一种基于卷积神经网络的文本分类模型,利用多个卷积滤波器来捕获不同粒度的文本特征。
•HAN[35]:一种基于层次注意力网络的文档分类模型,利用词级注意力和句子级注意力来学习新闻内容表示。
•dEFEND[8]:一种基于协同注意力的假新闻检测模型,学习新闻内容和用户评论之间的相关性,并利用Co-attention的权重从谣言文本和用户评论给出解释。
•PLAN[9]:一种关注用户交互的可解释谣言检测模型,将谣言及转发评论作为Transformer的输入,并利用延迟时间嵌入代替的位置嵌入进行谣言检测,通过Attention为帖子和标签提供解释。
•DualEmotion[5]:一种基于双重情感特征的假新闻检测模型,通过学习谣言情感特征、评论情感特征及情感特征差作为假新闻检测器的补充特征。
在Twitter15与Twitter16数据集中,d EFEND模型中谣言文本句子个数为1,长度为32,评论句子分别选取12 和9 条,长度为32;为了对比公平,Dual emotion模型利用Bi-GRU 提取文本特征,分别选择12和9条评论提取情感特征;本文所提模型,谣言文本个数为1,长度为32,评论个数分别为12和9条,长度为32,其他模型参照原文设置。
在Weibo20数据集中,dEFEND 模型中谣言文本句子个数为1,长度为64,评论句子选取100条,长度为32;由于数据集中不存在延迟时间,因此PLAN 模型不再对比;为了对比公平,Dual emotion模型利用Bi-GRU 提取文本特征,选择100条评论提取情感特征;本文所提模型的谣言文本个数为1,长度为64,评论个数为100条,长度为32,其他模型参照原文设置。
3.3 实验结果
数据集按照6:2:2的比例划分为训练集、验证集、测试集,每一个数据集中的样本比例为1∶1。实验使用Adam 更新参数,学习率分别为0.001与0.005,L2正则化系数为0.001。词向量与情感词向量维度均设置为300。设置常用的评价指标为:正确率Accuracy、准确率Precision、召回率Recall以及F1。在Twitter15、Twitter16 和Weibo20 上 的实验结果如表3~表5所示,表中加黑数据为最优结果,下划线数据为次优结果。
从表3、表4与表5可以发现,在Twitter15、Twitter16与Weibo20 数据集上,本文所提模型在各个指标上都显著优于其他模型,在Twitter15与Twitter16上的F1分别提高了约4.1%与3.0%,在准确率上分别提高了约3.9%与3.3%;在Weibo20上F1提高了约4.3%,在准确率上提高了约4.4%。实验结果证明,本文所提模型不仅优于基于单一特征的方法,更是优于基于混合特征的方法,充分体现了模型的优越性。
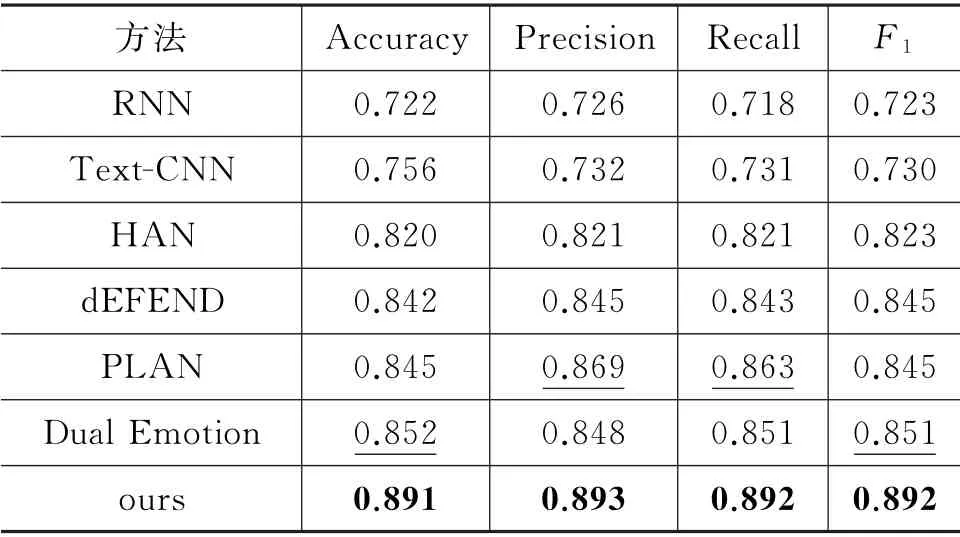
表3 Twitter15上不同模型的结果对比

表4 Twitter16上不同模型的结果对比
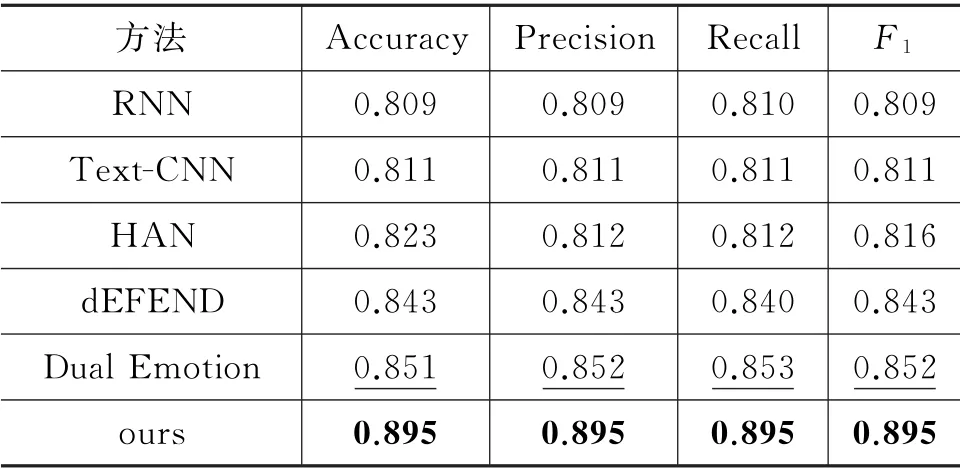
表5 Weibo20上不同模型的结果对比
在RNN、text-CNN、HAN 三种基于单一特征的方法中,HAN 模型效果更好,说明在提取语义特征方面,HAN 模型更具有优势。d EFEND、PLAN、Dual Emotion三种基于混合特征的方法明显优于基于单一特征的方法,这说明基于混合特征的模型利用不同的方法融合更多的特征往往具有更好的效果。在基于混合特征的模型中,PLAN 模型将位置嵌入替换为延迟时间嵌入进行谣言检测,取得优于d EFEND 模型仅考虑谣言和用户评论的效果。Dual Emotion模型在不采用Attention的情况下,仅利用谣言语义特征与情感特征融合就取得更好的结果。
该模型与基于混合特征的方法相比,也具有明显的优势。本文所提模型优于dEFEND 模型和PLAN 模型,说明同样仅利用谣言和用户评论,提取语义特征和情感特征取得更优结果,这表明选取更有效的特征是检测谣言的关键。本文所提模型优于Dual Emotion模型,说明同样以文本与评论情感作为谣言检测器特征,Co-Attention提取特征相关性更具有优势。不可否认的是,Dual Emotion模型提取情感特征更具有全面性,因为当前社交媒体中的用户评论更喜欢用表情或者一些图片表达自己的情感倾向,Dual Emotion模型在获取情感特征时能够针对表情对应的情感特征一并提取,但忽视了谣言文本情感与用户评论情感的内在关系。各个模块对模型性能的影响将在消融实验部分详细阐述。
3.4 消融实验
消融实验主要研究两部分内容:①评论数量对模型性能的影响;②模型各模块对模型性能的影响。
实验一分别选择不同的评论数量提取情感特征,实验结果如图5所示。

图5 用户评论数目的影响
可以发现,随着评论数量的增加,模型检测性能有所提高,在推特数据集中,评论数量基数较少,随着评论数目的增加,检测性能随之提高,但是在微博数据集中,评论基数大,随着评论数目的增加,性能提升相对较小,这是因为微博数据集中,相同的评论较多。
实验二是探究模型中各模块对模型性能的影响,“-S”:仅有谣言语义特征和用户评论情感特征的模型;“-E”:仅有谣言情感特征和用户据评论情感特征的模型;“-B”:所有特征由Bi-GRU 与Attention提取;“-C”:表示所有特征均由CNN 提取的模型;“-A”:本文所提模型;实验结果如图6所示。
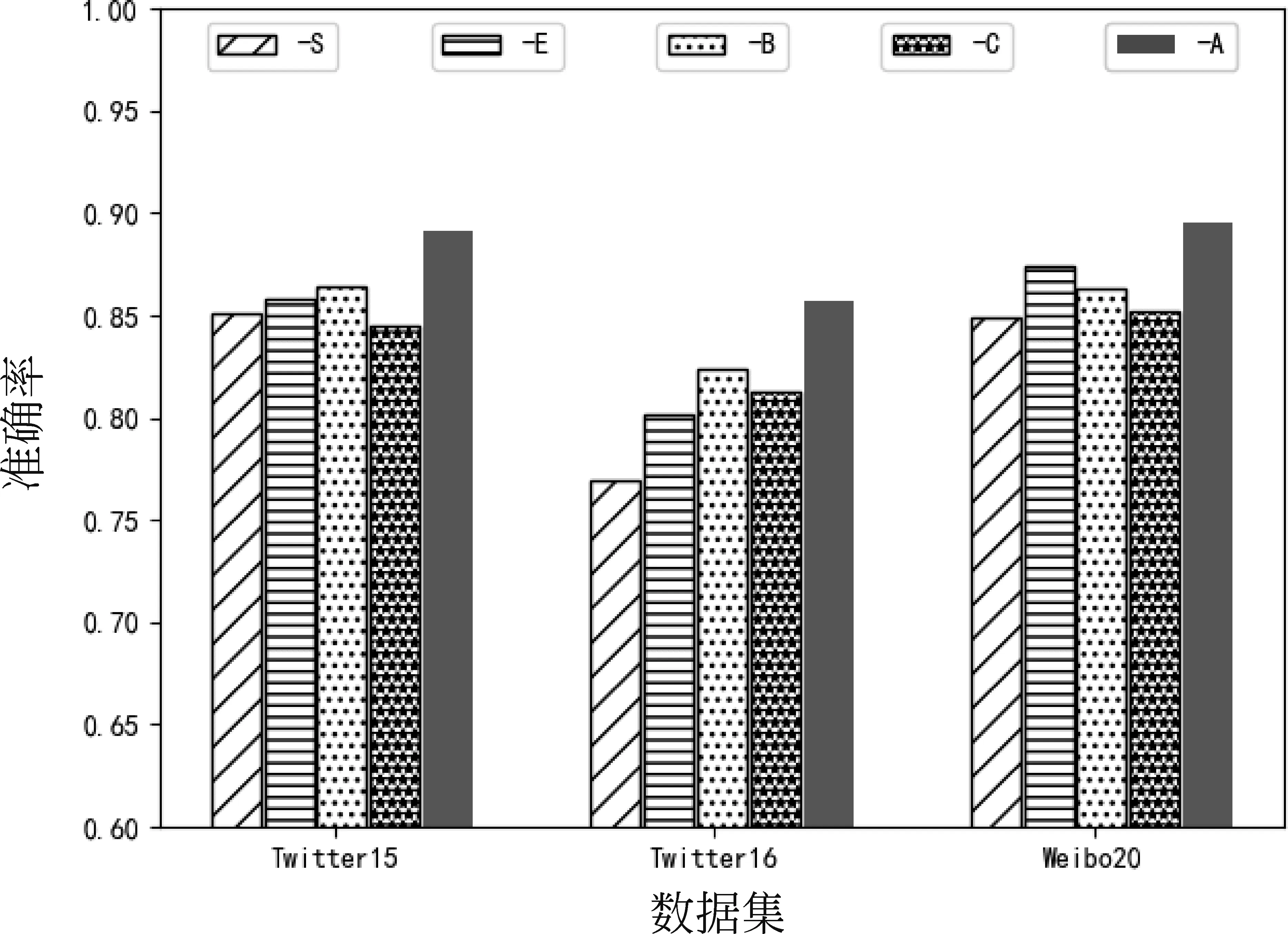
图6 模型中各模块的影响
实验结果表明,模型中的每一个模块都具有重要的作用,同时特征的提取方式发生改变会严重影响模型的性能。“-B”与“-C”模型虽然都提取了所有特征,但是准确率依然没有本文所提模型高,这是因为“-B”模型提取的是整体特征,“-C”模型提取的是局部特征,而本文模型是整体特征与局部特征的结合,就整体与局部而言,仅提取局部特征的“-C”模型较“-B”模型具有更好的效果。尤其是当去除情感特征提取模块时,模型的准确率会显著下降,同时将“-S”模型与dEFEND模型对比可以发现,利用用户评论的情感特征比用户评论语义特征效果更好,这说明在模型中情感特征比语义特征具有更好的作用。
3.5 可解释性分析
在2.3节介绍的Co-attention权重使模型具有可解释性,根据权重分布的位置,可以揭示谣言检测在谣言文本和用户评论中的证据词,下面分别对模型中两个Co-attention权重进行案例分析。
3.5.1 CNN 提取特征的可解释性
通过CNN 提取谣言情感特征和用户评论情感特征,Co-attention权重可以揭示谣言文本和用户评论中关注的句子,用户评论中的权重分布如图7和表6所示。

表6 Weibo案例分析的权重分布(一)

图7 Twitter案例分析的权重分布(一)
在图7中,发现第2句和第6句的权重最大,上述两句评论中均包含对谣言文本信息的否定态度,均能对此做出解释。在NRC的情感字典中,分别有与情绪有着正反关系的词汇,在第二句中的“sensationalist”与“sadness”对应,“crash”与“anger”对应。
通过表6中权重选择的前6条用户评论可以发现,每一句都直接对谣言文本中的内容表示怀疑和否定的态度。
3.5.2 Bi-GRU 与Attention提取特征的可解释性
利用Bi-GRU 与Attention分别提取谣言语义特征和用户评论情感特征,具体如图8和表7所示。
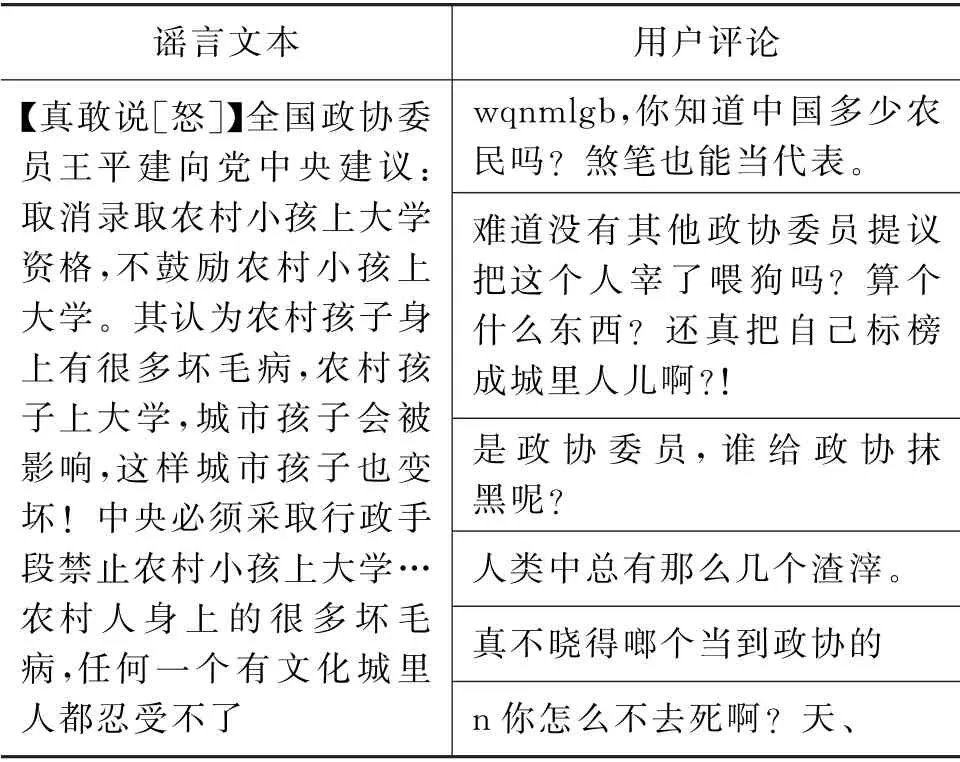
表7 Weibo案例分析的权重分布(二)
通过图8可以看出,在选择用户评论情感和谣言文本语义时,权重更倾向于与谣言文本语义匹配信息的选择,也从另一角度给出解释。
通过表7可以发现,权重所选择的前6条用户评论与之前完全不同,更倾向于事实的选择,其中3条评论与“政协”相关,其他的也都是契合谣言文本的语义信息。
3.5.3 全局与局部的可解释性
对比两种权重分布可以发现,Weibo20数据集的用户评论基数大,两种权重选择前6条用户评论完全不同,Twitters数据集的用户评论基数小,虽然前2条评论都是第2句和第6句,但是先后顺序、权重分布也不同。从全局看,基于Bi-GRU 与Attention提取特征的可解释性是从谣言语义特征和用户评论情感特征角度出发,选择用户评论更多的是与谣言文本相关的内容,如上述案列中,用户评论中包含“政协”“农民”等词语;从局部看,基于CNN 提取特征的可解释方法是从谣言情感特征和用户评论情感特征角度出发,选择用户评论更多的是对谣言文本所持的态度,如上述案列中,用户评论中包含“辟谣”“真的假的”“真相”等词语。
4 总结
考虑到谣言和用户评论中具有强烈的情感倾向,本文提出了一种基于双重情感感知的可解释谣言检测模型,分别提取谣言语义特征,谣言情感特征和用户评论情感特征进行谣言检测,并提供解释。实验结果表明,该模型具有较好的检测结果和较合理的解释性。同时,该模型还可以用于社交媒体上的其他任务,尤其是当前社交媒体上认知战正越演越烈,可以利用该模型进行仇恨语言检测、意识形态检测等任务。在下步工作中,我们将根据谣言的特点进行仇恨语言检测和立场检测的多任务实验,进一步研究社交媒体中认知偏移的规律。
