手语到情感语音的转换*
2022-10-28王伟喆郭威彤杨鸿武
王伟喆,郭威彤,杨鸿武,
(1.西北师范大学物理与电子工程学院,甘肃 兰州 730070;2.西北师范大学教育技术学院,甘肃 兰州 730070;3.互联网教育数据学习分析技术国家地方联合工程实验室,甘肃 兰州 730070)
1 引言
语音在人类的正常生活中起着至关重要的作用,具有方便、快捷和直接的特点。由于种种原因,我国存在着数量众多的语言障碍者。语言障碍者与其他人主要通过手语进行交流,而大部分的正常人不懂手语,这影响了语言障碍者的正常生活,也给社会带来了一定的压力。因此,将手语转换为语音的研究受到越来越多的关注。
起初,手语到语音的转换主要以数据手套为主。文献[1]利用带有模拟数字板和3D追踪器的数据手套将手指的自由度转换为二进制数,再通过模式匹配转换为对应的字符,最后利用声卡将字符转换为语音。文献[2]利用装载在手套上的14组三轴加速器实时采集手势的动作数据,通过串口和蓝牙将数据传输到嵌入式系统进行手势特征提取和匹配,最终使用语音引擎输出语音。文献[3]使用内嵌柔性传感器和惯性测量装置的手套进行手势识别,并通过语音引擎生成音频输出。近年来,随着机器学习技术的发展,基于机器视觉的手语到语音转换以其设备便宜和使用方便的优势得到了一定的发展。其中,基于神经网络的方法依靠其极强的分类能力和抗干扰能力,在手势和人脸的表情特征提取和识别方面取得了重大突破[4,5],是目前手势识别和人脸表情识别的主流方法。同时,基于深度学习的统计参数语音合成方法被广泛应用到情感语音合成中,能够在模型参数数目相近的情况下显著提高合成的情感语音的自然度[6]。Oyedotun等[7]提出了一种3D卷积神经网络CNN(Convolutional Neural Network)对手势的时空特征进行建模。Zhu等[8]将手势的短期时空特征和长期时空特征结合起来进行建模,实现多模态手势识别。Zhang等[9]提出身份启发卷积神经网络I2CNN(Identity-Inspired CNN),以整个或者局部面部的微小区域作为I2CNN输入,使用支持向量机SVM(Support Vector Machine)进行分类。文献[10]利用CNN搭建人脸表情图像的多帧融合网络结构,对输出结果进行融合。文献[11]对中性、快乐、愤怒和悲伤4种情感分别建立基于长短时记忆LSTM(Long Short-Term Memory)-循环神经网络RNN(Recurrent Neural Network)的情感声学模型,并利用多说话人语音数据训练说话人无关声学模型来初始化情感相关的LSTM-RNNs模型,合成的情感语音与基于隐马尔科夫模型HMM(Hidden Markov Model)的方法相比具有较好的自然度。文献[12]提出了一种采用全局风格标记进行半监督训练的端到端情感语音合成方法,合成的情感语音客观评测优于Tacotron模型。文献[13]使用基于传感器的手势识别模块识别英文字母和少量单词,并利用基于HMM的语音合成器转换为语音。文献[14]利用CNN对阿拉伯手语字母进行识别,并通过深度学习模型将识别结果转换成语音。
现有的手语到语音转换的方法中,基于数据手套的方法识别率较高,但使用者需要穿戴复杂且昂贵的数据手套和嵌入式设备。基于机器视觉的方法只对简单的字符手语到语音的转换进行了研究,且忽略了感情色彩在信息交流中的重要作用。文献[15]结合SVM与受限玻尔兹曼机对深度模型进行调节,并利用说话人自适应训练技术训练基于HMM的语音合成系统,实现了30种静态手语到汉藏双语语音的转换。文献[16]分别将深度置信网络DBN(Deep Belief Network)和深度神经网络DNN(Deep Neural Network)与SVM结合,得到手势文本和人脸表情情感标签,并利用说话人自适应训练技术实现了基于HMM的语音合成系统,实现了手语到语音转换。文献[17]利用DNN实现手语到情感语音的转换。本文进一步利用在图像识别领域取得较好成就的卷积神经网络实现手势识别和人脸表情识别;同时,以普通话声韵母为合成基元,训练混合LSTM的情感语音合成模型,实现手语到情感语音的转换。
2 系统框架
手语到情感语音转换的系统框架图如图1所示,主要包括模型训练和测试2个阶段。训练阶段,首先对输入的手势图像和人脸表情图像进行预处理,然后通过卷积神经网络提取手势特征和人脸表情特征,训练手势识别模型和人脸表情识别模型。从多说话人情感语料中获取语音的声学参数和文本的上下文相关标注,用于训练说话人无关的情感语音声学模型。在测试阶段,将手势图像和人脸表情图像分别输入训练阶段得到手势识别模型和人脸表情识别模型,得到手势对应的文本和人脸表情对应的情感标签。通过文本分析得到手势文本对应的上下文相关标注,接着将该标注信息和得到的情感标签输入训练好的情感语音声学模型,得到语音特征,最后通过语音合成得到情感语音,最终实现手语到情感语音的转换。
3 手语到情感语音的转换过程
3.1 手势识别和人脸表情识别
首先依据手势图像和人脸表情图像的颜色突变、空间纹理和几何形状等特性进行图像边缘检测。然后将手势图像和人脸表情图像转换为灰度图像。处理之后的图像大小全部调整为64×64,并进行归一化处理。模型训练过程中,对原始图像进行平移操作实现数据扩充,以避免过拟合问题。
手势识别和人脸表情识别模型是一个深度卷积神经网络DCNN(Deep Convolutional Neural Network)结构。DCNN结构是由Krizhevsky等[18]于2012年首次提出的,在大型图像分类上取得了非常好的效果。本文的网络结构信息如表1所示,包含12个深度神经层,前9个是卷积层,后3个是全连接层。最后一个全连接层的输出通过Softmax分类器对手势图像和人脸表情图像进行分类。
网络训练过程中,首先随机初始化网络参数,然后根据网络输出的标签和样本的真实标签计算损失函数并不断更新网络参数。网络结构中除最后一层其他层全部使用Leaky ReLU作为激活函数,以均方误差作为损失函数,使用小批量随机梯度下降算法进行模型训练,小批量的大小为256。在隐藏层中增加2个Dropout层进行正则化,每一层都对隐藏层的输入进行批量归一化处理[19]。
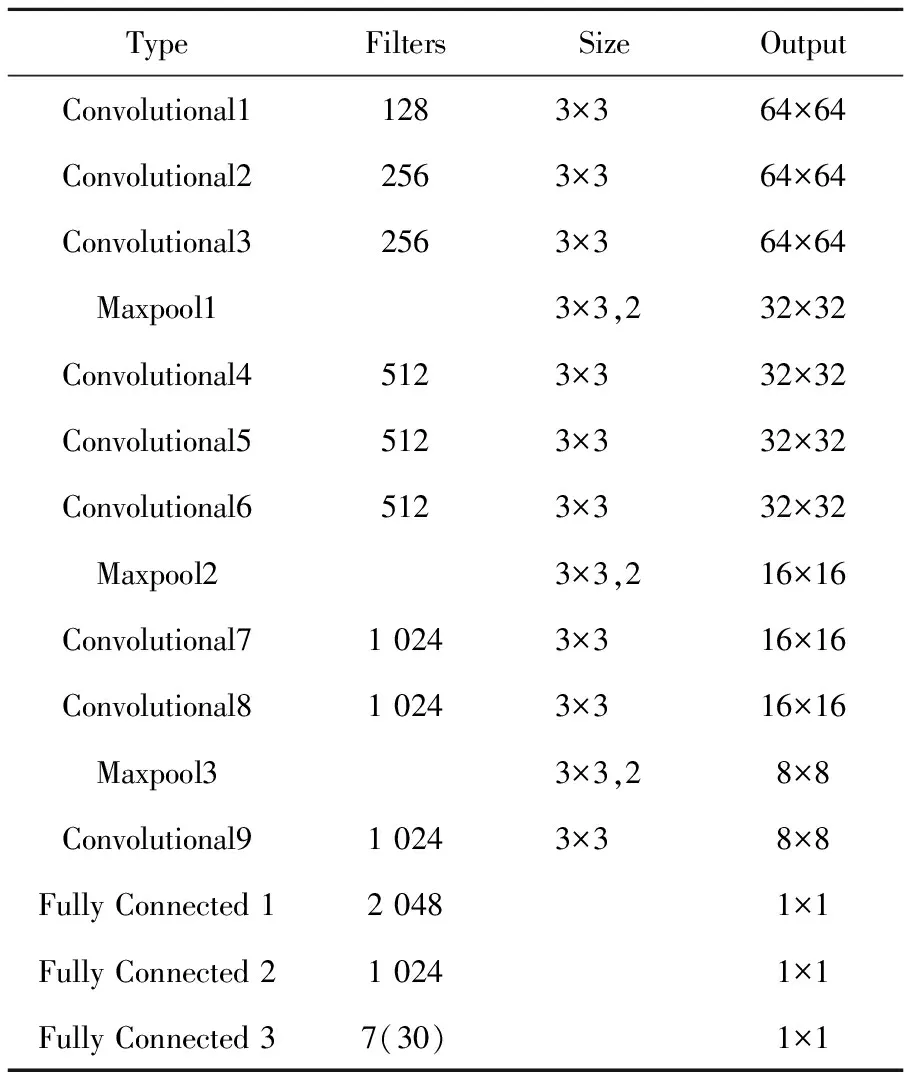
Table 1 Information of gesture recognition model and facial expression recognition model
3.2 情感语音合成
在情感语音合成过程中,利用说话人自适应训练技术训练了DNN和DNN与LSTM混合网络2种情感语音合成模型,训练过程如图2所示。
首先,从包含多个说话人的情感语料库中的情感语音中提取对数基频(LF0)、广义梅尔倒谱系数MGC(Mel-Generalized Cepstral)和频带非周期分量BAP(Band A Periodicity)3种模型训练所需要的声学参数。情感语音对应的文本借助词典和语法规则,经过语法分析、字音转换、韵律分析和文本规范化等文本分析过程获得文本的声韵母信息、韵律结构信息、词信息和语句信息等语境信息,最终得到声韵母、音节、词、韵律词、韵律短语和语句6层上下文相关标注。然后,将语音声学参数、浊音/清音和文本声韵母的上下文相关标注信息输入神经网络进行说话人无关平均音模型训练。在平均音模型训练过程中,2种网络的DNN层在不同的情感说话人之间共享隐藏层进行语言参数建模,通过反向传播算法对时长与声学特征进行建模,并使用非线性函数对语言特征和声学特征之间的非线性关系进行建模。
接着,从一个目标说话人的情感语料中提取声学参数,通过说话人自适应变换,获得说话人的情感声学模型。最后,利用人脸表情识别获得的情感标签选择对应的说话人情感声学模型,利用文本分析获得的6层上下文相关标注信息作为说话人情感声学模型的输入,采用最大似然参数生成算法生成目标情感语音的声学参数,利用WORLD声码器合成情感语音。
情感语音合成网络训练过程中,所有网络的输入由425维特征向量组成。该向量包括416维反映语言特征的上下文相关特征和9维数字特征。所有的输入特征被归一化到[0.01,0.99],所有网络的输出特征包括60维MGC、1维LF0、1维BAP,及其一阶差分和二阶差分特征,1维元音/辅音V/UV(Voiced/Unvoiced)特征,共187维特征。
4 实验与结果分析
4.1 实验数据
4.1.1 手势数据
邀请10名不同的人录制30种不同的手势,每种手势录制50次,以此创建一个包含15 000幅手势图像的数据库。所有采集到的手势图像保存为jpg格式,并按照手势对应的文本进行命名。实验中随机选取14 000幅图像作为训练集,剩余数据作为测试集。
4.1.2 人脸表情数据
人脸表情数据来自CK+[20]表情数据库和JAFFE[21]表情数据库,从中提取愤怒、厌恶、害怕、高兴、悲伤、惊讶和中性7种表情图像共计1 462幅。然后对所有数据进行平移增强处理,创建一个包含5 000幅人脸表情图像的混合数据集。随机选择4 500幅图像用于训练集,剩余的用作测试集。
4.1.3 情感语音数据
7种人脸表情对应的每种情感,以陈述句为主设计1 000句文本,内容涉及人文、时政、生态、娱乐和日常交流。语料基本覆盖所有的普通话发音现象。语句长度适中,平均句长为13个音节,最短句长2个音节,最长句长32个音节。同时,语料不包含数字、字母和特殊符号。然后让说话人观看每种情感对应的特定场景视频片段以激发说话人的情感。当说话人的情感被激发后,进行情感语音录音。语音录制中邀请10名女性普通话说话人按照设计的文本语料录音,每名说话人录制每种情感语音各100句,建立一个包含7 000句普通话情感语音的语料库。语音数据均采用16 kHz采样,16位量化,存储为单声道WAV格式。实验过程中随机选取50句语料作为测试集,50句语料作为验证集,其余语料作为训练集。
4.2 实验结果与分析
4.2.1 手势识别
本文方法在进行手势图像处理时利用了卷积神经网络的局部连接、权值共享、池化和多层网络4个关键属性,自主学习手势图像中抽象的特征表达向量。利用卷积层对特征图的局部连接进行探测,池化层将相似的特征进行融合。实验进行了5次交叉实验对DCNN在手势识别中的效果进行验证,实验结果如表2所示。同时,将本文提出的方法与文献[16]中基于DBN的方法、文献[17]中基于DNN的方法进行比较,实验结果如表3所示。结果显示,DCNN通过表达能力更强的网络结构来自动学习区分力更强的手势特征,使得模型具有更强的泛化能力,因此,在手势识别中表现出了更好的识别效果。

Table 2 Experimental results of gesture recognition

Table 3 Experimental results of gesture recognition with different methods
4.2.2 人脸表情识别
本文在混合表情数据集上也进行了5次交叉验证实验,实验结果如表4所示。并从混合数据集的测试集中随机取出每种表情20个进行测试,根据每种表情对应的识别结果构建混淆矩阵,实验结果如表5所示。

Table 4 Experimental results of facial expression recognition
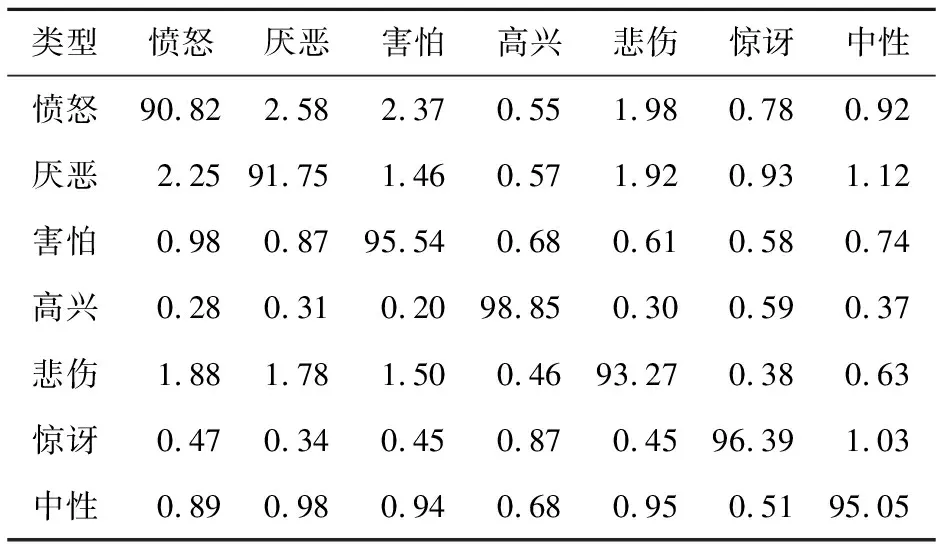
Table 5 Confusion matrix of facial expression recognition on mixed dataset
愤怒、厌恶和悲伤3种表情非常相似,模型在这3种表情之间出现识别混淆。同时,在CK+数据集上识别7种基本人脸表情,表6对采用相同实验设置获得的识别准确率进行了汇总,结果表明本文方法在人脸表情单帧图像上的识别准确率达到95.98%,仅次于GCNET和WGAN 2种方法的,可用于人脸表情识别任务。

Table 6 Recognition rate of different methods on CK+ dataset
4.2.3 情感语音合成
使用9名女性说话人的情感语言语料训练平均音模型,1名女性说话人的情感语言语料进行说话人自适应。
DNN模型包含4个隐藏层,每层512个单元,混合LSTM模型在DNN第4个隐藏层之后增加加一个包含256个记忆单元的LSTM层,使用基于时间的反向传播算法对模型参数进行随机初始化和训练。2种模型结构的输出层均采用线性激活函数,其余各层均采用ReLU激活函数,以均方误差为损失函数,使用小批量随机梯度下降算法进行声学模型训练,小批量的大小为256,并且使用Adam优化。在隐藏层中增加2个Dropout层用于正则化。在平均音训练时,前10个epochs的学习率为0.004,然后减半。在说话人自适应时,前10个epochs的学习率为0.002,然后减半。
(1)客观评测。
通过计算原始语音的声学参数与每个模型下合成的情感语音的声学参数的失真来评测合成的情感语音的质量。评测的声学参数包括F0的均方根误差、梅尔倒谱失真MCD(Mel-Cepstral Distortion)、BAP失真和V/UV误差,客观评测结果如表7所示。结果表明,混合LSTM模型合成的情感语音的质量优于DNN模型的。
(2)主观评测。
邀请年龄在24~26岁的母语为普通话的15名男性硕士研究生和15名女性硕士研究生作为受试者,从测试集中随机选取20句测试语音进行评测。利用情感平均意见得分EMOS(Emotion Mean Opinion Score)、情感差异平均主观得分EDMOS(Emotion Degradation Mean Opinion Score)和AB偏好测试来评价合成情感语音的质量。
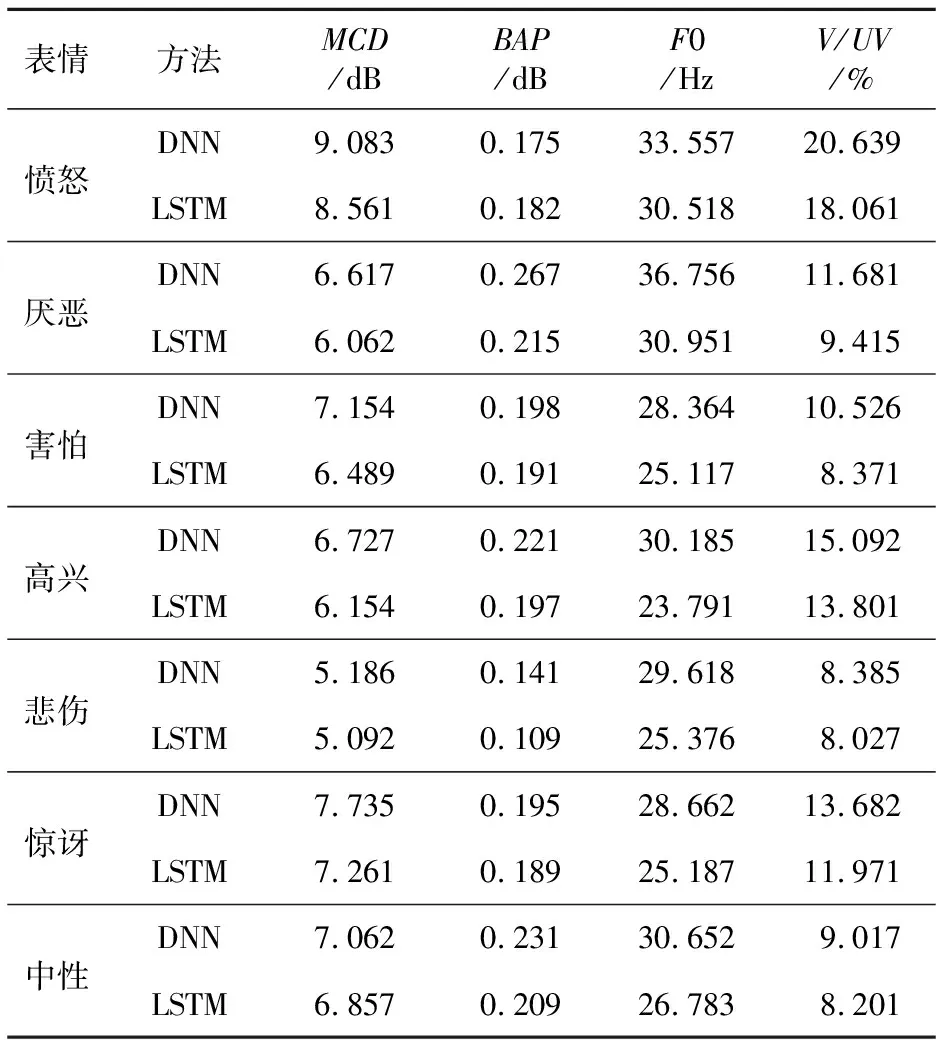
Table 7 Objective evaluation results on the synthesized emotional speech with different models
在EMOS测试中,受试者要求使用5分制来评估合成情感语音的自然度。合成情感语音在95%置信区间的平均EMOS如图3所示。
在EDMOS测试中,合成情感语音与对应的原始录音为一对文件,每一对语音文件按照原始录音在前、合成情感语音在后的顺序随机播放。要求受试者仔细比较2段语音,并在5分范围内评估合成情感语音与原始语音的相似度。5分表示合成语音与原始语音非常接近,而1分表示相差很大。95%置信区间下不同模型的合成情感语音平均EDMOS如图4所示。
在AB偏好测试中,随机播放2种模型合成的同一句情感语音,要求受试者求给出下列3种选项中的一种:(1)A更自然,(2)没有偏好(NP),(3)B更自然。对合成的情感语音的偏好结果如表8所示。
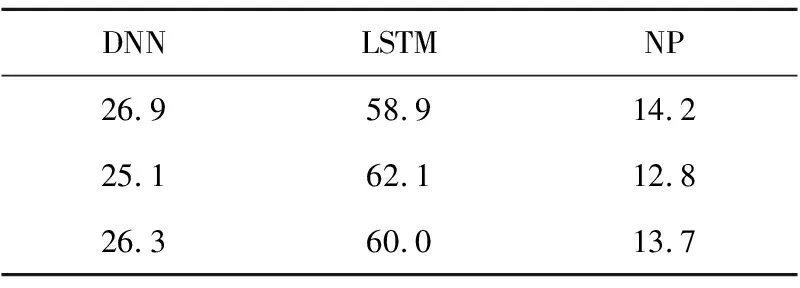
Table 8 Subjective AB preference score(ρ<0.01)
从评测结果可知,2种情感语音合成模型均合成出了高质量的情感语音。但是,混合LSTM模型中通过DNN的多层结构将语言特征逐帧映射到语音特征,LSTM层可以捕获给定语音帧的前向输入特征,因此更适合构建情感语音合成模型的语音声学模型,合成的情感语音具有更高的质量和偏好性。
4.2.4 手语到情感语音转换评测
准备30组手势(包括词语15组和句子15组)及其转换得到的情感语音,并邀请母语为普通话的男性硕士研究生和女性硕士研究生各15名作为受试者。本文对受试者播放手势转换得到的语音,要求评测人根据听到的语音从A、B、C和D4个选项中选择对应的文本(不考虑情感),通过与标准答案对比计算手语到语音转换的正确率,结果如表9所示。

Table 9 Accuracy rate of sign language to speech conversion under different speech synthesis models
2种模型都获得了较高的手语到语音转换的正确率。由于词属于孤立词间的转换,而句子是一个完成的表达,更加具备上下文相关特性,所以手语到情感语音的转换中句子的转换正确率更高。
此外,本文还采用简化版的PAD(Pleasure-displeasure, Arousal-nonarousal, Dominance-submissiveness)情感量化表[26]对预先准备的人脸表情图像及其转换的情感语音在PAD的3个感情维度进行评分。按照5分制分别在愉悦度、激活度和优势度3个维度上进行打分,最后将打分结果归一化到[-1,1]。通过对比人脸表情图像的PAD值与转换的情感语音的PAD值的差异来评测转换的情感语音对人脸表情的情感表达程度。人脸表情图像和转换的情感语音为一组文件,每组文件按照先人脸表情图像、后转换语音的顺序进行播放,要求受试者根据观测到表情图像和听到情感语音时的心理感情状态完成PAD情感量表。最终将每种人脸表情和转换的情感语音在3个维度进行比较,结果如图5所示。从图5中可知,2种情感语音合成模型均合成出了与人脸表情情感相似度较高的情感语音。但是,混合LSTM网络结构以其在处理时序信号中的优越性,合成的情感语音对人脸表情的情感表达程度更高。
5 结束语
本文提出了一种基于神经网络的手语到情感语音转换的方法,解决语言障碍者与健康人交流困难的问题。利用DCNN实现手势识别和人脸表情识别,采用DNN和混合LSTM模型来提高合成的情感语音的质量。实验结果表明,本文提出的方法不仅能够以较高的正确率实现手语到情感语音的转换,转换出的情感语音也能够准确传达人脸表情的情感。同时,将本文方法的结果与其他人的工作进行比较,本文方法表现出更佳的效果。未来工作的重点是扩大手势语料库和人脸表情语料库,通过大规模的语料库实现更多种类的手语到情感语音的转换,并尝试研究动态手语到情感语音的转换,以提高手语到情感语音转换的表现力。
