基于改进的YOLOv3口罩佩戴检测和识别*
2022-10-28任小康刘行行
任小康,刘行行
(西北师范大学计算机科学与工程学院,甘肃 兰州 730070)
1 引言
随着深度学习目标检测算法的不断改进和优化,研究人员通过研究网络深度、卷积核大小和特征尺度,构造出不同的卷积神经网络并取得了较好的成果。Girshick等人[1]提出了区域卷积神经网络R-CNN(Region-Convolutional Neural Network),在分类任务中将选择性搜索与卷积神经网络相结合,有效地避免了滑动窗口和穷举法产生的冗余候选区域。Fast R-CNN[2]在R-CNN基础上加入了空间金字塔池化SPP(Spatial Pyramid Pooling)[3],实现了多尺度输入。由于Fast R-CNN使用选择性搜索筛选候选框非常耗时,研究人员在其基础上加入了区域候选网络RPN(Region Proposals Network),构建了Faster R-CNN[4],检测速度大幅提升。与上述3种神经网络不同,Redmon等人[5]于2016年提出了YOLO(You Only Look Once),将目标检测作为一个简单的回归问题进行求解,以图像像素作为输入,边界框坐标和类别概率作为输出,即只需检测1遍图像就能预测出物体的类别和位置。由于YOLO存在大量定位误差且召回率较低,以YOLO为基础的YOLOv2[6]在每个卷积层中加入批归一化BN(Batch Normalization)层[6],显著改善了收敛效果并有助于网络模型正则化。在YOLOv2算法的基础上,对数据集进行融合,Redmon等人[6]又提出了一个实时检测算法,能识别超过9 000类对象,该算法被称为YOLO9000。YOLOv3[7]以YOLOv9000为基础,采用Darknet-53作为主干网络并使用多尺度融合进行预测,进一步提高了速度和精确度。当今主流目标检测算法主要分为2类:一类是双步目标检测算法,这类算法先通过选择性搜索算法或RPN网络等获得候选区域,然后再通过分类器进行分类,如Fast R-CNN、Faster R-CNN和Mask-RCNN[8]等;另一类是单步目标检测算法,这类算法的特点是将提取候选区域和分类融合到一个网络中,通过卷积核计算类别分数和位置偏差,如YOLO、YOLOv9000和YOLOv3等。单步目标检测算法的检测速度普遍高于双步目标检测算法,但检测准确率和定位精确度不如双步目标检测算法。
虽然国内疫情基本稳定,但全球疫情仍很严峻。因此,出入公共场所仍需佩戴口罩。为减轻防疫人员的工作量,本文提出了一种改进网络模型Face_mask Net,用于检测公共场所人群是否佩戴口罩。
Face_mask Net以YOLOv3算法为基础,首先对残差块进行改进,增加了少量计算量以提高目标检测精确度;其次,为了减少网络模型计算量并提高训练速度,引入了跨阶段局部网络CSPNet(Cross Stage Partial Network)[9],并将改进后的残差块与CSPNet模块进行融合,替换掉3个尺度上的残差块;接着,采用距离交并比DIoU(Distance-IoU)损失函数[10]以取代交并比IoU(Intersection over Union)损失函数[11],并将NMS(Non-Maximum Suppression)分类器[12]替换为DIoU-NMS[10],DIoU与DIoU-NMS相结合用于抑制冗余候选框,提高对遮挡目标的检测效果;最后,对网络跨尺度融合部分进行改进,以减少不同尺度融合所造成的特征损失。
2 YOLOv3检测算法
YOLOv3算法中的损失函数为IoU损失函数。IoU值表示锚框与目标框的交集、并集的比值,IoU 损失函数如式(1)所示:
(1)
其中,Bgt代表目标框,B代表锚框。当目标框和锚框重叠或不相交时,LIoU为0,这时无法判断目标框和锚框是相交还是重叠,且不相交时无法回传梯度。为提高YOLOv3算法对遮挡目标检测的鲁棒性,本文采用DIoU 损失函数,替换原本的IoU损失函数。
2.1 DIoU
DIoU是在IoU基础上添加了中心点归一化距离,如式(2)所示,公式中不仅考虑了目标框与锚框的重叠面积,还考虑了目标框与锚框之间的中心点距离。
(2)
其中,b和bgt分别代表锚框和目标框的中心点,ρ代表锚框与目标框中心点的欧氏距离,c代表可以同时覆盖锚框和目标框最小矩形的对角线距离。由于DIoU 损失函数能够直接最小化2个目标框之间的距离,因此收敛速度要比广义交并比GIoU(Generalized Intersection over Union)损失函数[13]快。
2.2 SPP模块
由于YOLOv3算法训练的网络模型对小目标检测精确度不高,本文网络模型Face_mask Net在13*13尺度特征提取过程中融入了SPP模块。如图1所示,SPP模块具有4个并行分支,主要由3个最大池化层和1个跳跃连接组成,其中3个最大池化层的卷积核大小分别为5*5,9*9和13*13。SPP模块实现了局部特征和全局特征的融合,融合后的特征图具有更丰富的表达能力,适用于检测目标存在较大差异的情况。图1展示了SPP模块的具体组成,其中DBL(Darknetconv2d_BN_Leaky)是YOLOv3算法的基本组件,由卷积层、BN和Leaky激活函数组成。
2.3 DIoU-NMS算法
在传统NMS中,IoU指标用于抑制冗余预测框,对于遮挡情况经常会产生错误抑制。DIoU-NMS算法将DIoU作为NMS抑制冗余预测框的准则,该准则不仅要考虑重叠区域,还要考虑目标框和锚框的中心点距离。对于得分最高的预测框M,可以将DIoU-NMS算法的得分(si)更新公式定义如式(3)所示:
(3)
(4)
式(4)为DIoU 损失函数的惩罚项,用于最小化目标框和锚框中心点之间的归一化距离。式(3)中si是分类得分,ε是NMS阈值,M是得分最高的锚框。通过同时考虑IoU和惩罚项来移除其他锚框Bi,筛选出最佳锚框。
3 本文网络模型
3.1 改进残差块
深度卷积神经网络在图像分类应用中取得了一系列突破。该类网络将低级、中级、高级特征和分类器以端到端多层方式进行集成,特征的“级别”可以通过堆叠层的数量即深度来丰富。普通网络(Plain Network)思想主要来自视觉几何组VGG(Visual Geometry Group)[14],随着层数的增加,精确度逐渐饱和,然后迅速退化。其中,退化是指随着网络深度增加,精确度不增反降的现象。这种退化并不是由于过度拟合造成的。从理论上分析,网络深度越深越好,但实际上,如果没有残差网络,对于普通网络来说,深度越深意味着网络越难训练。残差网络ResNet(Residual Network)[15]可以解决上述问题,即使网络再深,网络性能也不会衰减。其次,它还有助于解决梯度消失和梯度爆炸等问题。
残差块的主要设计包括2部分:快捷连接和恒等映射。快捷连接是可以跳过一层或多层的连接,它简单地执行恒等映射,并将其输出添加到堆叠层的输出,图2a中弧线箭头表示快捷连接,卷积层间的箭头表示恒等映射。快捷连接能够有效处理反向传播过程中出现的梯度消失问题,这有助于深层网络的训练。YOLOv3残差块只有2层,如图2a所示,由1*1的瓶颈层、3*3的深度卷积层和快捷连接组成,瓶颈层和深度卷积层通过恒等映射连接。为提高YOLOv3检测小目标的准确率,本文对处理13*13特征图的残差块进行了优化。首先,在原来3*3深度卷积层下增加了1*1逐点卷积层,瓶颈层负责减小和恢复特征图维数,使深度卷积层成为输入或输出维数较小的瓶颈,即形成“瓶颈结构”,该结构的作用是增加网络深度的同时提高网络准确性。其次,在快捷连接上增加了1*1逐点卷积层,目的是实现特征图不同通道之间的信息通信并进一步提高准确性,如图2b所示。
YOLOv3在13*13尺度特征图处理上使用了4个残差块,本文则使用了2个改进后的残差块,目的是在不降低检测准确率的同时尽量减少参数量。在处理13*13尺度特征图上,未改进前的YOLOv3残差块总参数量为(1*1*32*64+3*3*64*64)*4=155648,YOLOv3改进后残差块总参数量为(1*1*32*64+3*3*64*64+1*1*64*2)*2=78080,改进前后参数量总量降低了77 568。对比表1中第4组和第5组数据可发现,使用Res_C残差块的网络模型比未使用该模块的YOLOv3-spp-C的平均准确率均值mAP值提高了0.84%,这说明改进后的网络模型在降低残差块参数量的同时并未对网络检测准确率造成负面影响。
3.2 13*13尺度上的残差块
当神经网络变得更深、更宽时,其性能也将逐步变得强大。但是,神经网络的卷积层等基础模块数量也随之增加,导致神经网络的计算量增多,最终影响神经网络检测精确度。本文使用CSPNet模块的主要目的是使网络模型能够实现更丰富的梯度组合,同时减少网络模型的计算量。该模块将特征图处理分为2步:第1步将基础层的特征图划分为2个部分;第2步通过跨阶段层次结构将它们合并。通过分割梯度流,使梯度流通过不同的路径传播,如图3所示。图3a中的特征图只经过n个残差块和瓶颈层处理,而图3b中则是将特征图划分成2部分,Part2特征图经过n个残差块和瓶颈层处理,Part1则是直接与处理后的Part2特征图进行连接,最终到达过渡层。由于只有一半的特征通过残差块,因此不再需要引入瓶颈层。图3中2个模块在每秒十亿次浮点运算BFLOPs(Billion FLoat Operations Per second)相同的情况下,图3b模块内存访问成本在理论上可以得到降低。划分特征图的目的是减少特征图处理的计算量,同时可以保留部分特征图的高层语义特征,提高网络推理速度和准确性。
本文引入CSPNet以增强YOLOv3的学习能力。CSPNet主要有3个优点:(1)提升了网络学习能力,在网络轻量化后仍能保持足够的准确性;(2)改进了残差块和过渡层的信息流,优化了梯度反向传播路径,并为网络每一层平均分配计算量,有效提高了每个计算单元的利用率,进而减少不必要的能耗;(3)提升了网络处理速度并降低了内存占用率。在YOLOv3的基础上,本文将Res_C融入到CSPNet中并替换3个尺度上的残差块,改进后的CSP模块命名为CSP_C,具体结构如图4所示。图4a中DBL模块是YOLOv3算法中的基本模块,它由卷积层、批归一化和Leaky激活函数组成,而ResN则是由DBL和N个残差块组成;图4b由CSPNet模块与N个Res结合而来;图4c以CSPNet模块为基础,在特征图分流中增加了DBL模块,目的是使划分后Part1和Part2的特征图维度、尺度保持一致,以提高网络检测精确度,减少参数量。
从表1中可以看出,第6组含有CSP_C模块的本文网络模型相比第5组不含有该模块的网络模型mAP值提高了1.07%。对比结果表明,改进后的CSP模块有助于提升网络模型准确率。
3.3 改进YOLOv3跨尺度融合
尺度缩小模型是将输入图像编码设计为具有单调递减分辨率的中间特征,该模型无法为检测和定位任务提供足够分辨率的特征。由于特征分辨率低,直接使用尺度缩小模型的顶层特征在检测小物体方面效果不佳。多尺度编码器-解码器架构可以有效解决该问题。将尺度缩小的网络用作编码器,通常将其称为骨干模型。然后,将解码器网络应用于骨干网以恢复其特征分辨率。解码器网络的设计与骨干模型完全不同。典型的解码器网络由一系列跨尺度连接组成,这些跨尺度连接将骨干网中的低层和高层特征组合在一起,以生成强大的多尺度特征图。
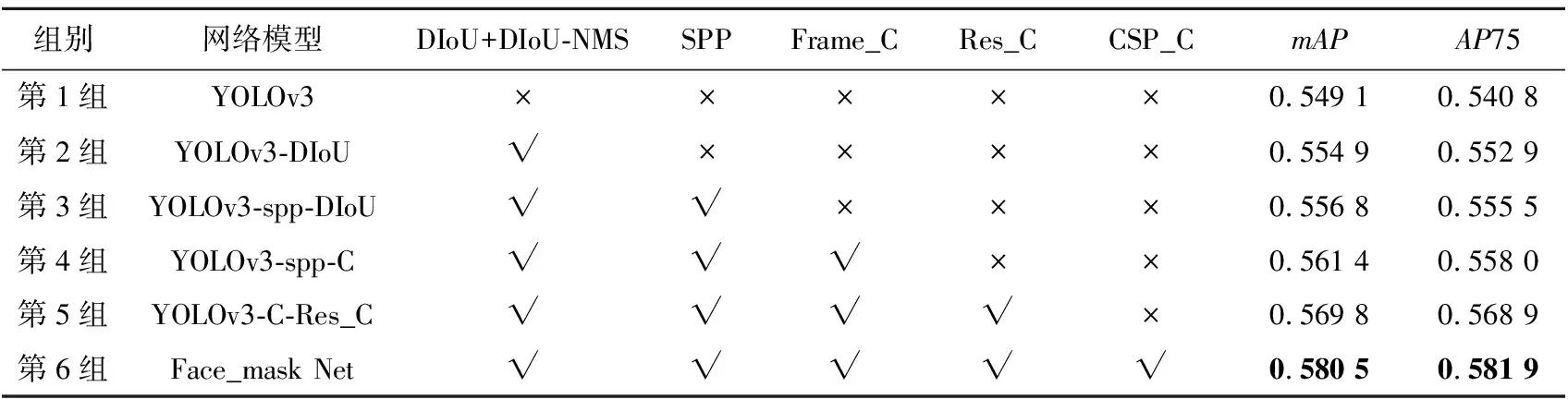
Table 1 Comparison of ablation experimental results
YOLOv3骨干网DarkNet是典型的尺度缩小模型,该网络中引入了特征金字塔网络FPN(Feature Pyramid Network)[16],并采用3个不同尺度的特征图检测目标,3个尺度大小分别为13*13,26*26和52*52。对3个尺度检测的特征图进行融合处理,可以在保留高层图像语义信息的基础上获得更多的低层图像特征信息,但跨尺度融合中会出现部分特征损失,如图5a所示,13*13*512特征图首先经过上采样处理成26*26*256特征图,然后直接与26*26*512特征图进行相加操作,相加后得到26*26*768特征图。最后使用1*1逐点卷积层处理得到26*26*256特征图,该过程特征图的维度从768下降到256,维度下降后部分特征会丢失,进而对目标检测和定位产生影响。为减小该影响,本文对跨尺度融合进行了改进,如图5b所示,首先用3*3深度卷积和1*1逐点卷积层对26*26*512特征图进行降维处理,目的是使处理后的特征图的分辨率和特征维度与目标块相匹配,然后将2个重新采样后的输入特征图逐个相加合并,最后使用1*1逐点卷积层对26*26*512特征图进行处理,特征图维度从处理前的512降低到256。相比YOLOv3算法训练得到的网络模型,本文网络模型在跨尺度融合时产生的特征丢失较少,降低了因跨尺度融合造成的不利影响。本文将改进后的网络模型命名为Frame_C。对比表1中YOLOv3-spp-C和YOLOv3-spp-DIoU的数值可以发现,改进后的网络比改进前的mAP值提高了0.46%。
4 口罩检测实验及结果
4.1 实验数据集
本文所有网络模型训练环境均为Linux系统下的Ubuntu 18.04.3 LTS,使用8 GB内存的NVIDIA Tesla P4显卡,且训练均采用darknet53.conv.74作为预训练权重,其中训练参数设定如下:初始学习率为0.001,再分割数量subdivisions为16,批大小为64,动量为0.9等。本文收集、标记、汇总了口罩检测数据集,并将其命名为Face_mask Dataset。该数据集由9 056幅不同地区行人的照片(如戴口罩行人和未戴口罩行人)组成,并使用LabelImg进行标注,如图6所示。图6a标注了4个目标,其中最右侧人脸为难负例,对应xml文件的〈difficult〉为1。图6b中的〈name〉为类名,〈bndbox〉为目标框坐标信息,〈truncated〉为图像是否经过缩放处理。
本文将该数据集划分为2类:一类命名为face类,如未戴口罩和用手捂脸等非口罩遮挡脸部的人;另一类命名为face_mask类,即正确佩戴口罩的人。face类主要选自WIDER FACE[17]和MAFA[18]数据集,并从中挑选3 114幅图像进行重新标注。face_mask类照片主要来自网络爬虫、行人戴口罩视频截图和RWMFD数据集[19],同样对6 312幅图像进行重新标注。Face_mask Dataset中样本总数为9 056,随机选取8 242幅组成训练集,814幅组成验证集,91幅组成测试集。Face_mask Dataset由戴口罩正脸、侧脸、人脸等图像组成,其中主要增加了人、手等非目标类遮挡口罩的图像,如图7所示,目的是增强数据集多样性,提高网络检测遮挡目标的鲁棒性。
4.2 网络模型性能测试
本文使用查准率P(Precision)、召回率R(Recall)、平均准确率AP(Average Precision)和平均准确率均值mAP(mean Average Precision)作为评价网络模型性能的指标,其定义分别如式(5)~式(8)所示:
(5)
(6)
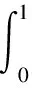
(7)
(8)
其中,TP表示网络模型正确检测出目标类(face类和face_mask类)的数量;FP表示网络模型检测中将非目标类判定为目标类的数量;FN表示样本中存在目标类,但未将其检测出的数量。查准率显示网络模型预测正确的结果的概率,而召回率则显示目标类被找出的概率。一般情况下,随着召回率的上升,查准率会呈下降趋势。式(8)中N表示目标类别的数量。通常AP是指单个类别的平均准确率,而mAP是AP值在所有类别下的均值。为了更直观地表示AP,本文引入了PR曲线,PR曲线所在的坐标系中,横坐标表示召回率,纵坐标表示查准率,PR曲线下方的面积代表某个目标类的AP值。
(1)消融实验结果。
为分析不同网络分支或模块对整个网络模型的影响,本文采用消融实验对比衡量本文网络模型的效果。根据式(6),表1中的mAP值由AP50、AP55、AP60、AP65、AP70、AP75、AP80、AP85、AP90取平均值得到。表1中第1列表示具有不同模块的网络模型,第1组是由YOLOv3算法训练的网络模型;第2组是以DIoU作为损失函数、DIoU-NMS作为分类器的YOLOv3-DIoU;第3组为在YOLOv3-DIoU的基础上加入了SPP模块;第4组是在第3组的基础上对网络跨尺度融合部分进行了改进;第5组是将前一组骨干网上的残差块替换为Res_C;第6组是将第5组的13*13残差块替换为改进后的CSP_C模块。
(2)PR曲线评估。
本文使用AP75对样本进行划分,阈值高于75%的样本为正例,小于75%的样本为负例,进而计算相应的查准率和召回率。根据召回率与查准率呈反比的特点,PR曲线总体呈下降趋势,PR曲线与坐标轴围成的封闭图形面积越大,网络模型分类效果就越好。本文绘制了AP75下的YOLOv3算法训练的网络模型与本文网络模型关于face、face_mask类的PR曲线,如图8所示。从图8a可以看出,虚线(Face_mask Net)与坐标轴围成的面积明显大于实线(YOLOv3)与坐标轴所围成的面积,这表明Face_mask Net在face类上的分类效果优于YOLOv3算法训练的网络模型的。同样,比较图8b中2条曲线与坐标轴围成的面积可发现,本文网络模型在face_mask类上的分类效果也略优于YOLOv3算法训练的网络模型的。
4.3 口罩检测对比实验
4.3.1 正常人脸和佩戴口罩人脸检测效果对比
图9比较了3种网络模型检测正常人脸和戴口罩人脸的检测准确率,可以看出检测未带口罩目标的准确率均达到99%以上,但对戴口罩目标的检测准确率存在差异,其中YOLOv3-C-Res_C比YOLOv3高了约0.5%和2.7%,主要原因是改进后的残差块增强了网络模型对目标检测的准确率,尤其是戴口罩目标。本文网络模型与YOLOv3-C-Res_C相比,检测戴口罩目标和未戴口罩目标的准确率均提高了约1%。YOLOv3-C-Res_C与本文网络模型的差异在于CSP_C模块,该模块使用了特征图分流结构,在一定程度上优化了网络反向传播,进而提高了网络模型检测准确率。从图9中的AP值可以看出,CSP_C和Res_C模块在一定程度上提高了网络模型检测戴口罩目标的准确率。
4.3.2 中、小尺度目标检测结果对比
图10比较了3种网络模型检测中、小尺度戴口罩目标和人脸目标的检测效果。图10a中YOLOv3可以检测出小尺度的人脸目标,但漏检了右侧小尺度戴口罩目标。YOLOv3漏检小尺度目标的主要原因是小目标在图像中所占像素少,经过多层卷积处理之后得到的13*13尺度特征图中的特征极不明显。本文网络模型改进了13*13尺度特征处理中的残差块结构并融合了CSPNet模块,将原有的4个残差块缩减到2个残差块,既减少了卷积层数目,又减少了参数量,便于特征图的分流。YOLOv3-C-Res_C能有效检测出右侧小尺度戴口罩目标,但未检测出小尺度人脸目标。本文网络模型可以检测出小尺度人脸和戴口罩目标,且对中尺度口罩目标检测准确率维持在96%以上。3种网络模型检测结果对比可以得出,改进后的残差块和CSP_C模块提高了网络模型检测小目标的能力。
4.3.3 小尺度戴口罩侧脸目标检测效果对比
图11比较了3种网络模型检测小尺度戴口罩侧脸目标检测效果,YOLOv3和YOLOv3-C-Res_C均只检测出了2个正脸戴口罩目标,而Face_mask Net检测出了另外2个小尺度戴口罩侧脸目标。由此可见,改进后的CSP_C模块增强了网络模型检测小尺度戴口罩侧脸目标的能力。
4.3.4 对严重遮挡目标检测效果对比
为验证DIoU与DIoU-NMS相结合对严重遮挡目标的检测效果,图12着重比较了YOLOv3与本文网络模型。首先,检测密集人群中戴口罩目标被严重遮挡的效果,如图12b和图12c所示。从图12a中可以看到,中间后排有位医生被前面宣誓医生的手挡住了面部,只露出下半部分口罩。YOLOv3漏检了该目标,而本文网络模型可以有效检测出该目标,主要原因是DIoU与DIoU-NMS在选择候选框时同时考虑了目标框与锚框中心点之间的距离、重叠率及尺度,使得目标框回归变得更加稳定,这样可以有效避免目标被严重遮挡时产生的错误抑制。
其次,检测人脸目标被严重遮挡效果,如图13b和图13c所示。从图13a中可以看出,被严重遮挡的目标有4个,但人眼能够区别的遮挡目标只有2个,一个是被电子温度计遮挡的女子,另一个是该女子旁边的戴口罩男子。比较图13b和图13c可发现,本文网络模型能够检测出被严重遮挡的人脸目标,但漏检了被严重遮挡的戴口罩目标,主要原因是该目标遮挡率超过了90%,在数据集标注中属于难负例,因而本文网络模型不能有效检测出该目标。
4.3.5 不同网络模型性能指标对比
为了进一步测试Face_mask Net的检测效率,本节以YOLOv2、YOLOv3-spp等主流单步目标检测算法训练的网络模型作为参照,根据BFLOPs、每秒传输帧数FPS(Frames Per Second)等指标综合评价网络模型性能。对比实验在Face_mask Dataset数据集上进行,测试环境为:AMD R7-4800H处理器,NVIDIA GeForce RTX 2060 6 GB显卡,8 GB内存,操作系统为Ubuntu 18.04,对比结果如表2所示。
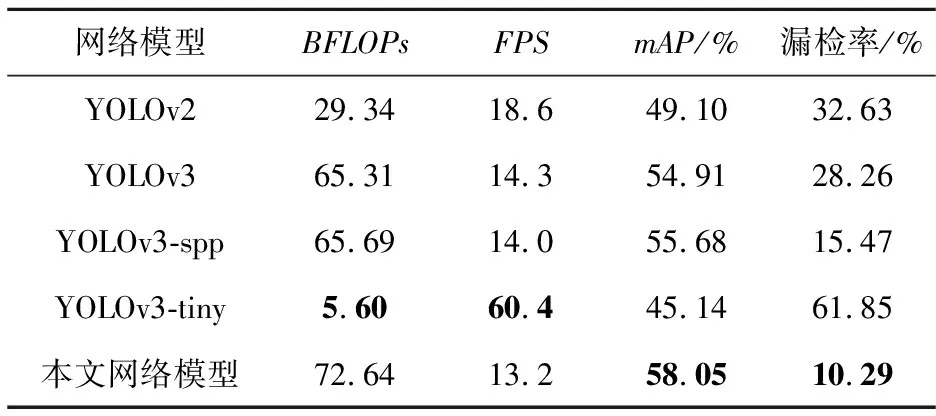
Table 2 Comparison of performance indicators of different network models
对比表2数据可以发现,本文网络模型虽然在BFLOPs上略高于其他网络模型,但准确率上远比其他网络模型高,且漏检率低。本文网络模型漏检率低的原因是测试视频中小目标占比较高,由于改进了网络结构和残差块,本文网络模型漏检小目标的数量明显小于其他网络模型的。对比FPS,本文网络模型比YOLOv3算法训练的网络模型少了约1帧,主要原因是网络模型的BFLOPs大小对GPU浮点运算能力有一定影响。当GPU浮点运算能力固定时,BFLOPs值越大,网络模型检测视频的FPS就越小。本文网络模型由于BFLOPs较大,测试视频的帧数会略有下降。表2中,YOLOv3-tiny由于结构简单,深度为23层,其中卷积层的数量明显少于其他网络模型的,因此FPS会较高,但检测准确率低于其他模型且漏检率高。
5 结束语
本文提出了基于YOLOv3算法的改进Fask_mask Net,着眼于解决小尺度佩戴口罩目标检测困难的问题。首先,为进一步提高检测准确率,本文对残差块进行了改进,改进后的残差块相比改进前的残差块在目标检测准确率上有了一定程度的提高。其次,为减少网络计算消耗并提高训练速度,本文引入了CSP模块,并将改进后的残差块与CSP模块进行融合,替换掉3个尺度上的残差块。再次,采用DIoU损失函数取代IoU损失函数,并将NMS分类器替换为DIoU-NMS,DIoU与DIoU-NMS相结合抑制了冗余候选框,提高了对遮挡目标的检测效果。然后对网络13*13,26*26和52*52跨尺度融合处进行改进,减少了融合后特征的丢失。最后,在Face_mask Dataset数据集上进行网络模型有效性验证和对比实验。实验结果表明,本文网络模型可以有效提升复杂场景中口罩佩戴检测的准确率,AP75下的平均准确率为58%,比改进前的YOLOv3高了4.11%。在接下来的工作中,将继续改进网络结构并优化网络模型,以获得更高的准确率和更低的时间成本,还会继续采集更多的真实场景图像以扩充现有的数据集,以便更好地应用于防疫部门。
