改进的麻雀搜索优化算法及其应用*
2022-10-28尹德鑫张达敏蔡朋宸秦维娜
尹德鑫,张达敏,蔡朋宸,秦维娜
(贵州大学大数据与信息工程学院,贵州 贵阳 550025)
1 引言
近些年来,数值优化经常被用来处理工程中的一些复杂问题,群智能算法在数字优化领域发挥着重要作用。当前的主流群智能算法有:鲸鱼优化算法WOA(Whale Optimization Algorithm)[1]、灰狼优化算法GWO(Grey Wolf Optimizer)[2]和蝗虫优化算法GOA(Grasshopper Optimization Algorithm)[3]等。麻雀搜索算法SSA(Sparrow Search Algorithm)是由Xue等[4]在2020年提出的一种新兴群智能算法,具有求解精度高、收敛速度快和稳定性好等优点,但在面对多峰问题时仍然存在寻优精度低、收敛速度慢和易陷于局部最优等缺点。
对于改进群智能优化算法中种群多样性不丰富、易陷于局部最优和寻优精度低等问题的研究工作有很多:文献[5]通过改进位置更新公式和非线性控制来增强灰狼优化算法的寻优精度;文献[6]提出一种改进的蝗虫优化算法,用高斯混沌映射来生成初始种群,增加种群多样性;文献[7]提出基于随机替换和混合变异的蜻蜓算法,引入随机策略来提高收敛速度;文献[8]提出将粒子群优化算法和差分算法混合,利用彼此的优势来避免过早收敛的问题;文献[9]提出基于Levy飞行的鲸鱼改进算法,利用Levy飞行增加种群多样性,防止过早收敛;文献[10]提出一种基于动态对立学习的竞争粒子群优化算法,每次迭代随机选择2个粒子来进行竞争,然后根据对立学习或者竞争学习来扩大搜索范围,使粒子群可以跳出局部最优值,获得更快的收敛速度。
以上改进算法在一定程度上提高了全局搜索能力,避免了过早收敛。但是,通过深入研究算法发现仍存在寻优精度不足,随着搜索空间维度增加收敛速度变慢等问题。针对这些问题,本文提出一种改进的麻雀搜索算法ISSA(Improved Sparrow Search Algorithm),首先,将反向学习策略用于生成初始种群,丰富种群多样性;然后,对步长控制参数进行优化,提高SSA的寻优性能;最后,将Levy飞行引入到侦查预警麻雀位置更新公式中,加快收敛速度,避免局部最优。
2 麻雀搜索算法
麻雀搜索算法的主要思想是通过模仿麻雀的觅食和反捕食行为,来进行局部和全局搜索,麻雀觅食过程就是算法寻优过程。SSA由3种类型的麻雀组成:发现者、加入者和侦察者。发现者通常拥有较高的适应度值,负责为加入者提供觅食区域和方向;加入者为了得到更好的食物会一直跟随发现者,同时监视发现者并争夺食物,以此保证他们的捕食率;当侦察者发现捕食者后立即发出报警信号,全体麻雀做出反捕食行为[11]。
(1)发现者的位置更新公式如式(1)所示:
(1)
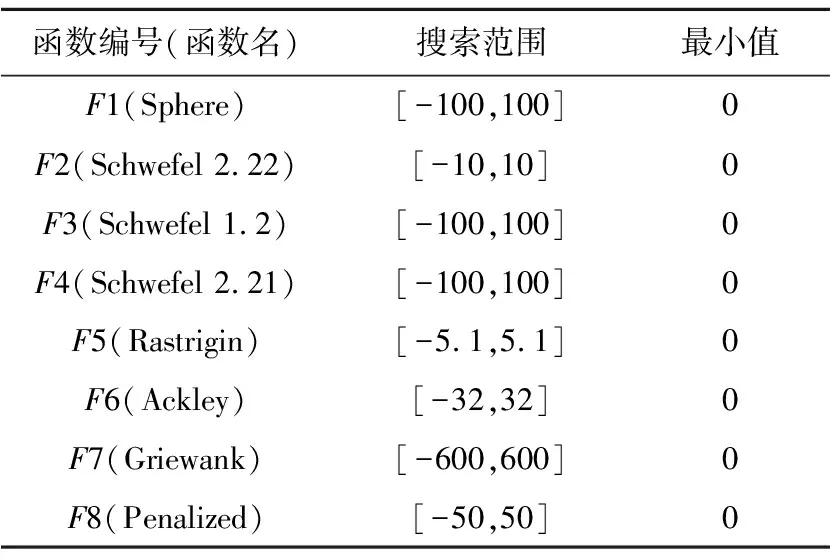
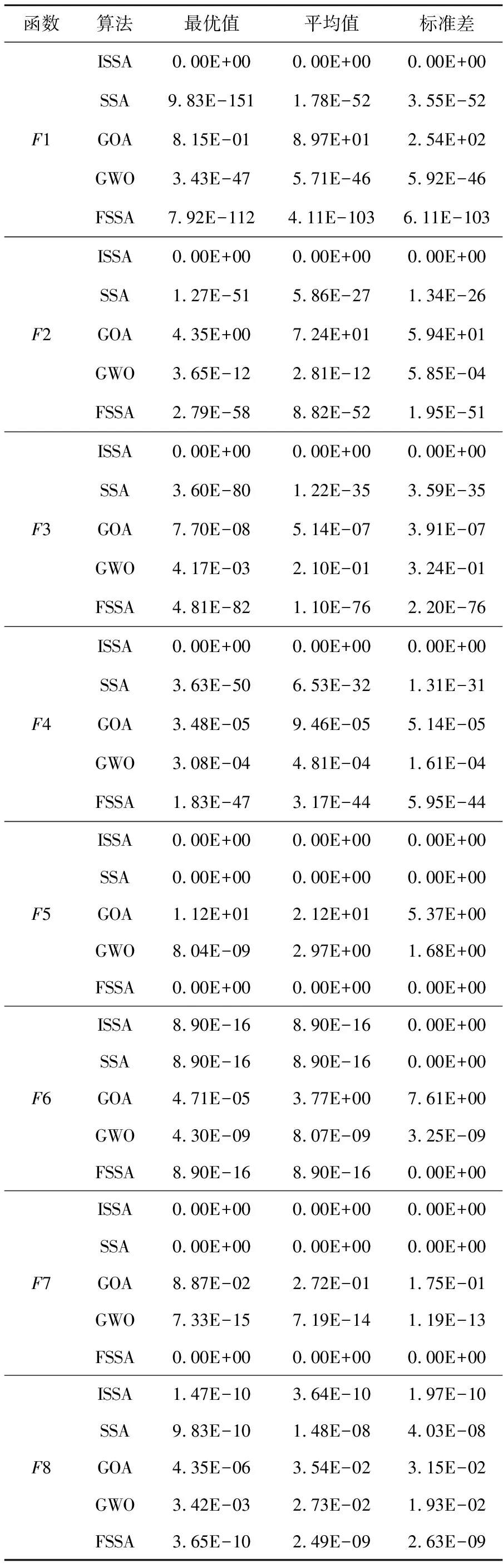
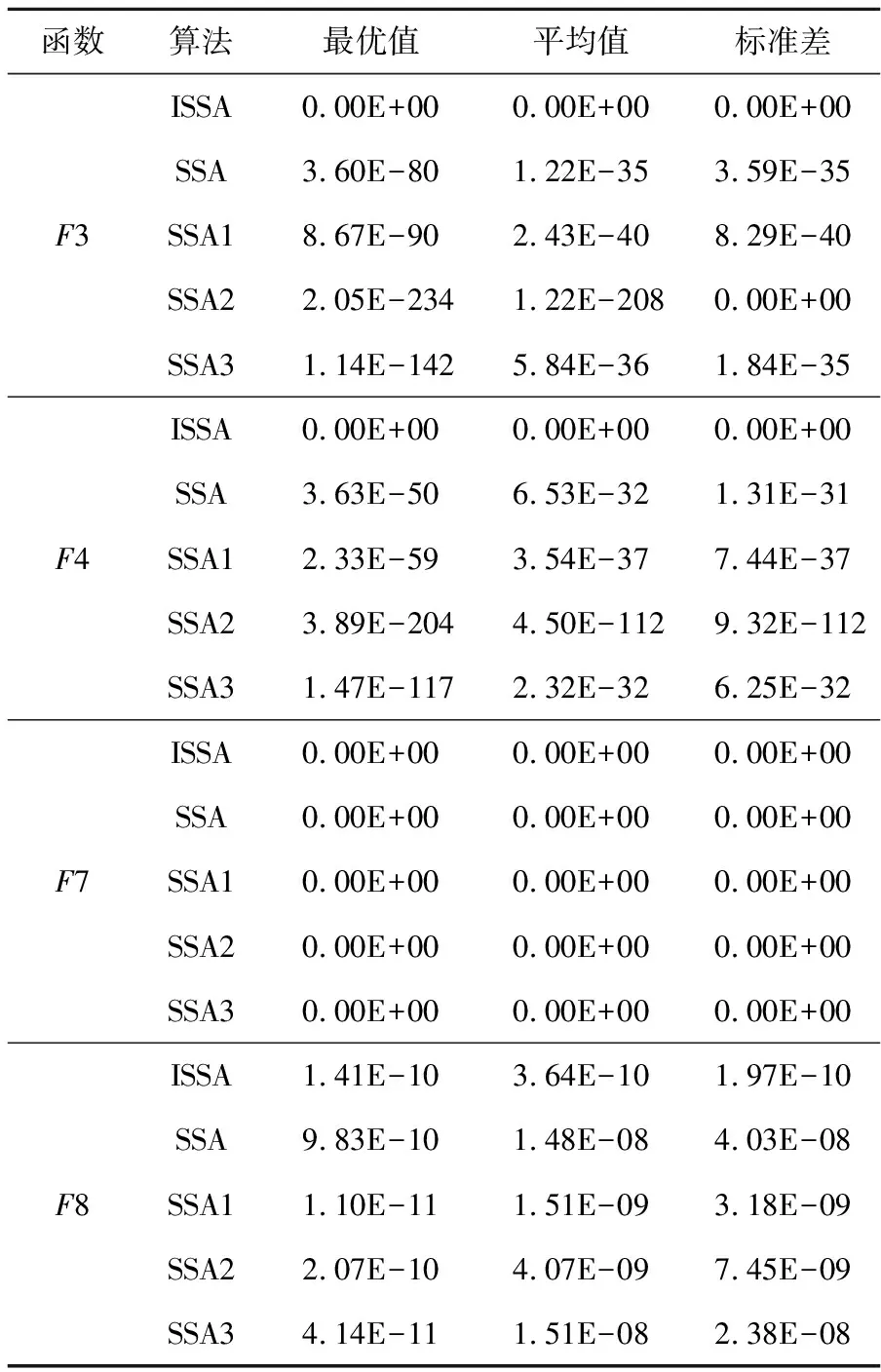
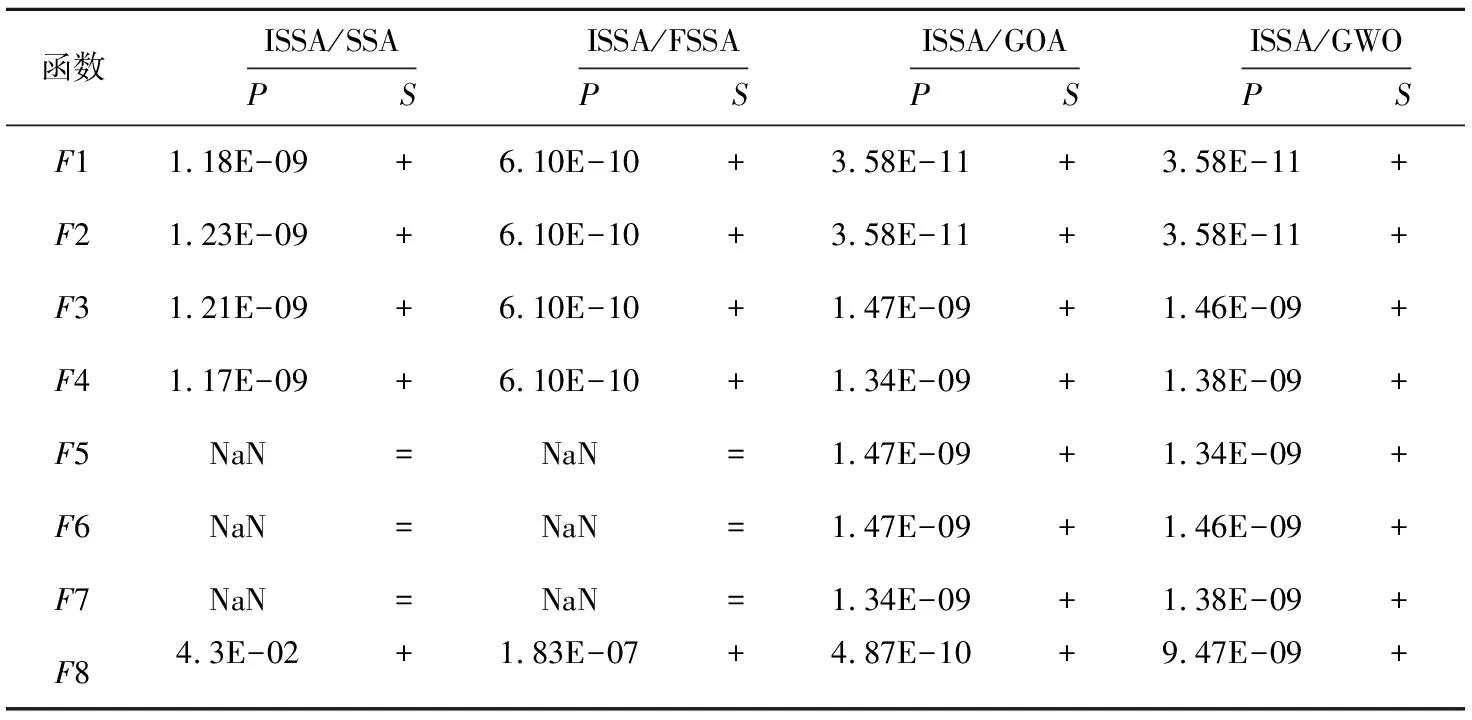
其中,t表示当前迭代次数,T表示最大迭代次数,Xi,j(t)表示第i只麻雀在第j(1≤j≤d)维迭代次数为t时的位置信息,d为空间维度,α为[0,1]的随机数,R2∈[0,1]表示预警值,ST∈[0.5,1]表示安全值,Q为服从正态分布的随机数,L表示一个1×d的矩阵,其中内部每个元素都为1。当R2 (2)加入者的位置更新公式如式(2)所示: (2) 其中,Xworst(t)表示当前全局最差位置;Xpest(t)表示发现者占据的最佳位置;N为种群数量;A+=AT(AAT)-1,A表示一个内部元素随机分配为1或-1的1×d矩阵,AT为A的转置。当i>N/2时,表示适应度值较差的第i只加入者处于饥饿状态,它需要飞往其他方向寻找食物。 (3)负责侦查的麻雀一般占种群的10%~20%,其位置更新公式如式(3)所示: Xi,j(t+1)= (3) 其中,Xbest(t)表示当前全局最优位置;β为服从均值为0,方差为1的正态分布随机数的步长控制参数;K∈[-1,1]表示麻雀运动方向,也是步长控制参数;fi表示当前麻雀的适应度值;fg和fw分别表示当前全局最优值和最差值;e为一个常数,是为了避免分母为0。当fi>fg时,表示麻雀处于种群的边缘地段,易受到捕食者攻击;当fi=fg时,表示处于种群中间位置的麻雀意识到危险,需要靠近其他麻雀来降低被捕食的概率。 SSA中采用的是随机生成初始种群,这样生成的种群分布不均匀,导致种群多样性不丰富,种群质量不高,影响算法的收敛速度,因此本文改进的麻雀搜索算法ISSA采用反向学习策略来解决这一问题。反向学习OBL(Opposition-Based Learning)策略是由Tizhoosh[12]提出的。该策略提出了对点的概念,用对立搜索代替了随机搜索。利用反向学习策略生成种群的主要思想是:首先随机生成初始种群,然后根据初始种群生成其反向种群,从中选择较优的种群作为下一代种群。反向学习策略会选择更靠近最优位置的个体作为种群的最初个体,这样每个个体都离最优解更近一步,以便提高种群中所有个体的收敛速度。此外,反向学习策略还可以通过搜索更多有效区域来提高群体的多样性,增强算法的全局搜索能力。 (4) 其中,ub为搜索空间的上界,lb为搜索空间的下界,rand为[0,1]的随机数。将随机生成种群和反向种群合并为一个新的种群后,求新种群的适应度函数,并将适应度值按升序排列,取前N个最优初始解作为新的麻雀初始种群。 在SSA中,式(3)中的步长控制参数β和K在平衡全局搜索能力与局部开发能力方面发挥了重要作用,但因为β和K都是随机数,无法使麻雀充分探索空间,可能导致SSA陷入局部最优。因此,需要对步长控制参数β和K进行优化,使较大的控制参数便于全局搜索,较小的控制参数促进局部开发[13]。对步长控制参数β和K的改进如式(5)和式(6)所示: β=fitnessbest-(fitnessbest- (5) K=(fitnessbest-fitnessworst)· (6) 其中,fitnessbest是最佳适应度值,fitnessworst是最差适应度值,T为最大迭代次数。从式(5)可知,改进后的步长控制参数呈非线性递增变化,因为在SSA的迭代早期阶段,种群具有较高的多样性,这意味着探索全局空间的能力较强而探索局部空间的能力较弱。因此,本文将控制参数的值设置为较小的值,以加强局部开发能力。在迭代后期当所有麻雀都被当前的全局最优吸引,没有足够的搜索空间探索时,它们可能会过早收敛,因此将控制参数的值设置为较大的值,避免陷入局部最优,有利于进一步探索。从式(6)可知,步长因子K在迭代前期递增后期快速减少,这有利于SSA在前期充分探索搜索空间,后期提高收敛速度。动态调整步长控制参数可以平衡SSA全局搜索与局部开发能力,在提高寻优精度的同时避免出现局部极值。 Levy飞行[14]是一种非高斯随机步态,步长服从重尾概率分布,其飞行特点为长时间进行小步长随机游走,偶尔会出现大步长[15]。从文献[4]可知,标准SSA可能会陷入到局部极值,以致无法找到全局最优解。在寻找最优解过程中,Levy飞行不仅可以在短距离中进行局部搜索,还可以在长距离中进行全局搜索。因此,在搜索到最优值附近时,Levy飞行能起到增强局部搜索能力的作用,有效解决了标准SSA可能陷入局部最优的问题。本文将Levy飞行策略引入式(3)中的麻雀最优位置,改进后的SSA根据当前位置与麻雀最优位置的距离来进行位置更新,这样大大降低了麻雀陷入局部最优的风险,而且仍然能充分执行局部探索,改进公式如式(7)所示: (7) 其中,d为空间维度。Levy计算公式如式(8)和式(9)所示: (8) (9) 其中,Г为伽马函数,θ为常数,r1和r2为[0,1]的随机数。 ISSA的伪代码如下所示: 1)设置种群数量为n、发现者数量为PD、侦察者数量为SD、预警值为R2、安全值为ST和最大迭代次数为T; 2)使用反向学习策略初始化种群; 3)计算每个麻雀的适应度值,并找到当前最佳个体和最差个体; 4)While(t 5)fori=1:PD 6) 根据式(1)更新麻雀位置 7)endfor 8)fori=(PD+1):n 9) 根据式(2)更新麻雀位置 10)endfor 11)forl=1:SD 12) 根据式(5)~式(7)更新麻雀位置; 13)endfor 14) 得到当前更新位置; 15) 如果新的更新位置大于当前更新位置,则更新它; 16)t=t+1; 17)endWhile 18)返回目标函数值。 为了验证本文ISSA在求解优化函数上的优越性,对8个测试函数进行仿真。表1为维度均是30的测试函数,F1~F4为单峰函数,F5~F8为多峰函数,单峰函数用于测试算法收敛速度,多峰函数因为有多个局部最优值,易使算法陷入局部极值,所以多峰函数用于测试算法的寻优能力。 Table 1 Benchmark fuctions 将ISSA独立运行30次求解的测试函数结果同SSA[4]、GOA[3]、GWO[2]和另一改进麻雀搜索算法FSSA(F Sparrow Search Algorithm)[16]的结果相比。设置每种算法的共同参数最大迭代次数T=300,种群规模N=30。基于上述8个测试函数,将算法的最优值、平均值和标准差作为评价指标,仿真结果如表2所示。 从表2可以看出,对于单峰函数F1、F2、F3和F4,ISSA算法的求解精度都可以达到理想最优值,寻优性能明显强于SSA、GOA、GWO和FSSA,且ISSA标准差都为0,说明ISSA的稳定性也强于其他算法。对于多峰函数F5和F7,ISSA和SSA的求解精度最高,寻优精度都达到了最优值,且标准差为0,GOA性能最差,GWO次之;对于多峰函数F6和F8,从平均值可以看出,ISSA收敛精度最高,FSSA次之,GOA最差,从标准差来看,ISSA的稳定性最高,这说明相比其他算法,ISSA具有更强的全局搜索能力、稳定性和鲁棒性。 图1和图2展示了单峰函数F3和F4的收敛曲线,图3和图4展示了多峰函数F7和F8的收敛曲线。从图1可知,ISSA的收敛精度最高,FSSA次之,相较其他算法,ISSA最先收敛,并且寻优精度达到了最优值。从图2可知,ISSA的收敛速度最快且它的寻优效果也达到了理想状态,这说明同其他算法相比,ISSA不仅有良好的全局搜索能力而且不易陷入局部最优,平衡了全局探索能力与局部开发能力。从图3可以看出,在相同寻优精度下,相比SSA和FSSA,ISSA的收敛速度更快,这说明ISSA在一定程度上改善了SSA收敛速度上的缺陷。从图4可以明显看出,ISSA的寻优精度明显高于其他算法,这说明ISSA在求解多峰函数上规避了局部最优的风险,提高了全局搜索的能力,增强了跳出局部最优值的能力。 本节将ISSA与结合步长因子动态调整策略的SSA1、结合Levy飞行策略的SSA2、融合反向学习策略的SSA3进行对比,以验证不同改进策略的有效性,实验结果如表3所示。由表3可知,ISSA对单峰函数寻优时,单峰函数F3和F4的3个性能评价指标均达到了理想值,而对于多峰函数F7,ISSA和其他改进算法的寻优精度均达到理想值;ISSA对于多峰函数F8的寻优精度虽没有达到理想值,但比起标准SSA和其他改进算法,ISSA也在一定程度上提高了寻优精度。 Table 2 Test function simulation results 总的来说,SSA2和SSA3对F3和F4的有效性显著,从3个评价指标可看出,结合Levy飞行策略的更新策略和融合反向学习的策略可有效提高算法的寻优能力;SSA1对单峰函数的寻优结果是3种改进策略算法中最差的,但其寻优精度相比于SSA也得到了一定提升;SSA1和SSA3对于求解多峰函数F8的最优值效果最好,但在标准差方面,不如SSA2算法稳定,相比SSA,3种改进算法在稳定性和寻优性上都得到了提升。表3的实验结果表明,在单峰函数和多峰函数中,融合3个改进策略的ISSA能有效增加种群多样性,提高算法寻优精度。 Wilcoxon秩和检验[17]是一种非参数统计检验方法,本文用来判断ISSA与其他算法是否有显著性区别。本文将ISSA、SSA、GOA、GWO和FSSA均独立运行30次的平均值进行秩和检验,其结果如表4所示,其中P表示检验结果,S表示显著性判断结果。当P<0.05时,S显示为“+”,表示ISSA的显著性强于其他算法;当P>0.05时,S显示为“-”,表示ISSA的显著性弱于其他算法;当P=0.05时,S显示为“NaN”,表示无法进行显著性判断。 从表4可以明显看出,ISSA除了与SSA和FSSA在F5、F6和F7函数上无法进行显著性判断外,对于其他算法不管是单峰函数还是多峰函数上的检验结果,P值都远远小于0.05,且S都为+,这说明比起SSA、GOA、GWO和FSSA,ISSA具有显著性优势。 Table 3 Test function comparison results 随着5G通信的普及,无线通信业务量大幅增加,频谱资源的短缺和固定的频谱分配方式导致频谱利用率低和频谱资源严重浪费。因此,Joseph Mitola 博士提出用认知无线电CR(Cognitive Ra-dio)[18]来解决频谱利用率低的问题。本文针对大多数算法收敛速度不够快,过于早熟,导致频谱分配的系统效益不高和用户间的公平性低等问题,提出用ISSA来优化频谱分配。将频谱分配[19]映射到麻雀种群中每只麻雀的位置,算法迭代结果中的最优种群解对应于频谱分配的系统效益和认知用户之间的公平性指数,其系统效益与公平性分别如式(10)和式(11)所示: Table 4 Results of Wilcoxon (10) (11) 其中,sp,m∈{0,1}为无干扰分配矩阵的元素,当sp,m=1时表示信道m可以被非授权用户p占用;ep,m为效益矩阵的元素,表示某认知用户在信道上获得的效益;P表示认知用户数;M表示可用信道数。 为了验证ISSA在频谱分配上的有效性,将ISSA与SSA[4]、蜘蛛猴算法SMO[20]和二进制粒子群优化算法BPSO[21]进行对比。实验参数设置如下:网络区域范围为10×10;可用频谱M=10;主用户K=5;认知用户数P=10;传送功率最大值和最小值分别为1 dB和4 dB;主用户覆盖半径Dp=2。 为说明ISSA在不同网络环境中均具有更好的优化性能,在认知用户数与可用信道数都为10时,将4种算法在30种不同信道环境中进行仿真,得到不同环境中的公平性,如图5所示。从图5可以看出,在不同的信道环境中,ISSA的公平性均大于SSA、SMO和BPSO算法的。 表5为4种算法在可用信道数和认知用户数相等的情况下,独立运行30次的系统总效益值,可以看出,ISSA的系统效益最高。总之,不管在公平性方面还是在系统总效益方面,ISSA都优于SSA、SMO和BPSO,这说明了ISSA的有效性。 Table 5 System benefit comparison 麻雀算法作为一种新兴群体智能算法,受到广泛的关注。本文提出了一种改进的麻雀搜索算法,使用反向学习策略来解决麻雀算法初始化种群时造成的种群分布不均匀问题,丰富了种群多样性;为了更好地平衡SSA的探索能力和开发能力,对步长控制参数进行优化,同时对麻雀最优位置引入飞行算子,提高了麻雀的收敛速度和寻优精度。ISSA在8个单峰函数和多峰函数中进行了测试,并进行了秩和检验分析,实验结果表明,ISSA的仿真结果更优越,这说明ISSA具有很高的探索开发能力和稳定性。此外,将ISSA应用到认知无线电频谱分配优化中,以系统总效益和认知用户公平性为评价指标与SSA、SMO和BPSO进行对比,结果表明,ISSA优于其他算法,可获得更高的网络效益和公平性。3 改进的麻雀搜索算法ISSA
3.1 反向学习策略
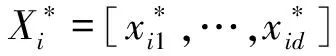
3.2 步长因子动态调整策略
3.3 Levy飞行策略
3.4 ISSA伪代码
4 仿真实验与结果分析
4.1 算法对比分析
4.2 不同改进策略对比
4.3 Wilcoxon秩和检验
5 ISSA在认知无线电中的应用

6 结束语
