基于用户行为的超级计算机作业失败预测方法*
2022-10-28唐阳坤杨文祥张晓蓉王耀彬
唐阳坤,鲜 港,杨文祥,喻 杰,张晓蓉,王耀彬
(1.西南科技大学计算机科学与技术学院,四川 绵阳 621010;2.中国空气动力研究与发展中心计算空气动力研究所,四川 绵阳 621050;3.国防科技大学计算机学院,湖南 长沙 410073)
1 引言
随着数据科学的发展与进步,科学研究和工程项目越来越依赖超级计算机。同时,随着高性能计算性能从P级向E级发展,计算结点不断增加,多核执行应用程序的并行规模不断扩大,作业发生故障和错误的可能性也随着软件和硬件上复杂性的增加而增加[1],作业失败事件会影响高性能计算系统的执行效率。
每天都会有大量的作业提交到超级计算机,然而,其中有相当一部分作业不能够正常完成。最近的一些研究分析了Google公司的集群作业负载日志,其中大约有40%的作业不能够正常完成[2,3]。这些作业还占据了大部分集群工作时间(失败或者被杀死)[4-7]。此外,本文分析了一台用于科研的超级计算机的作业日志,在调研的正常终止(完成与失败)的作业中,大约有31%的失败作业。这些不能正常完成的作业会导致系统的计算资源不能够有效利用,同时也会延长正在排队的作业等待时间。如果提前预测出失败作业,并采取一定的应对措施,能够提高系统资源利用率,同时对提升系统的执行效率也至关重要。
机器学习是目前广泛用于预测研究的技术,寻找有利于预测目标和有价值的特征对提升预测效果至关重要。超级计算机的作业调度系统记录了每一个运行作业的历史日志信息。本文对大量历史作业日志进行综合分析,发现了一些新的可用于预测作业失败的特征。除了时间、资源等用于预测作业状态的传统特征外,还可以利用作业名的命名规律及提交行为作为预测模型的输入。
在作业日志中,存在大量语义组成相似的作业名,一般是通过改变尾缀及组成间隔方式标记作业的工作内容,这些组成相似的作业名通常具有相似的工作模式及内容,反映用户的一种工作行为模式。本文根据作业名语义组成提出了一种作业名聚类方法。
最后,农业污染问题突出。近年来,广西很多农产品数量在全国位居前列,但随之而来的是农业投入品如化肥、农药及农膜增加,农业面源污染问题加剧。从表4可知,近年来,广西农业投入品的使用量都出现不同程度的增加(除柴油下降外),且化肥、农药等利用率低、流失率高,加剧了农业面源的污染程度,导致农业农村绿色发展受制约。
表3报告了我们最为关注的三个变量 ——金融发展指标FD、经济增长率Growth与金融开放指标kaopen指数间的相关关系。可见同一样本间的经济增长率与金融发展呈现出显著的负相关关系,这暗示金融发展与经济增长之间可能存在一个反向影响的关系;金融发展与金融开放的相关关系显著为正,这在一定程度上符合先前的文献研究结论:金融开放会极大促进金融资源的跨地配置,并通过金融机构间的竞争促进金融发展。kaopen与经济增长的相关关系没有通过显著性检验。这意味着我们需要通过回归模型来进一步确定两者间的相关关系。
基于作业名,发现同一用户下同一作业名的作业重复提交次数与失败作业的分布存在潜在关系,这种作业的重复提交次数反映了用户的提交行为模式,该特征和潜在模式将在3.1节详细阐述。聚类后的作业名及提交次数被用作预测作业失败的新输入特征。
本文首先分析了作业日志中作业相关属性的作业失败分布状况,同时结合作业特征相关性分析,提出基于树结构模型的综合方法预测作业失败,提升了预测效果。最后,对预测为失败的作业提出可供选择的建议。
2 相关工作
应用程序的有效执行对科学研究和工程项目至关重要。然而,超级计算机的规模和复杂性不断增加导致故障的可能性增加,已有大量的相关研究分析了软件和硬件故障,并提出了故障预测方法。
在软件故障预测方面,Jayanthi等人[8,9]使用神经网络分类器方法对软件可靠性进行预测和对软件缺陷预测进行建模;Padhy等人[10]提出了一种基于遗传算法的具有成本效益和故障弹性的可重用性预测模型;Manjula等人[11]提出了一种基于混合方法的深度神经网络,并使用软件度量标准进行软件缺陷预测。
在硬件故障预测方面,Hamerly等人[12]提出使用朴素贝叶斯分类来预测硬盘故障;Nie等人[13]选用系统特性(如温度、功耗和应用状态)作为预测GPU错误的特征;Das等人[14]通过使用系统日志训练递归神经网络模型来预测节点故障。
大多数故障预测方法都是基于事件设计的。Schroeder等人[15]对HPC系统故障进行研究,该研究表明HPC集群和云集群的故障率正在增加。Snir等人[16]给出的调查结果表明,故障预测器的召回率低于50%。刘春红等人[17]基于支持向量机算法使用动态和静态工作特征预测工作状态。Yoo等人[1]基于随机森林算法使用资源相关特征预测工作状态。Nakka等人[18]使用决策树算法来预测HPC系统中的节点故障。
3 数据预处理及分析
3.1 数据来源及介绍
中国空气动力研究与发展中心CARDC(China Aerodynamics Research and Development Center)致力于计算流体力学CFD(Computational Fluid Dynamics)研究工作。本文分析了该中心一台超级计算机一年的历史作业日志。
本文研究的超级计算机中的作业调度系统是SLURM[19]。每一条作业的执行记录都单独保存在日志的一行中,其中包含了很多字段,如作业ID(JobID)、执行状态(State)、用户ID(UID)、请求CPU数量(ReqCPUS)、作业名(JobName)、分配CPU数量(AllocCPUS)、使用节点数量(NNodes)、使用节点列表(NodeList)、作业名(JobName)、提交时间(Submit)、开始时间(Start)、结束时间(End)和退出码(ExitCode)等。
为了保护用户的隐私,本文中所展示的所有数据信息均已脱敏。
3-吲哚基环氧丙烷和3-咔唑基环氧丙烷单体的合成不同于前三种聚醚的对应单体的合成,其合成方法要简单很多,通过四丁基溴化铵(TBAB)作为催化剂,使反应在常温下进行[24,31].这类单体通过阴离子聚合得到的聚醚同样是单手性螺旋结构并能稳定存在于溶液中(见图6).该类聚醚一样具有光学活性,通过比旋旋光,圆二色谱和紫外可见光谱数据显示聚醚能在溶液中保持螺旋构像.
3.2 定义与说明
作业失败通常定义为当系统中的错误行为导致错误输出时发生的事件。在本文中,作业失败由作业调度器定义,适用范围更加广泛,定义和说明如下:
根据每个用户提交的作业,统计出同一作业名的重复提交次数,本文研究的日志数据集中同一作业名提交的最高次数为12 824。失败作业的分布也呈现出一种潜在的模式。如图1所示,在大约6 000次以内,失败作业的数量占比大部分不高于50%;在大约7 500次后,失败作业的数量占比开始出现100%的情况。可以发现,失败作业的占比随着提交次数的增加表现出了增加的趋势。在本文中,提交次数将作为一个新的学习特征,并命名为NSubmission。
定义1成功作业:在SLURM作业日志中执行状态为COMPLETED,即正常完成的作业。
定义2失败作业:在SLURM作业日志中执行状态为FAILED,即失败的作业。
定义3提交次数:同一用户下同一作业名的作业重复提交的次数。
定义4作业类型:具有相似作业名的作业属于同一作业类型。
在作业日志中,作业名可能由用户命名,或者由软件命名,代表着某一应用,作业名相同并不意味着这些作业内部结构完全一致,也许更改了参数,或者调整了数据规模等。同一用户下存在对相同作业名重复提交的情况,这反映了用户对作业的一种行为模式。此外,作业日志中有大量相似的作业名,它们之间只存在细微的差别,这些作业可能存在相似的特性,为了降低其自身冗余性,将对作业名进行聚类处理,一类作业名属于同一种作业类型。
从作业日志中筛选出只包含成功作业和失败作业的记录。在预测实验中,需要将数据切分为测试集和训练集,然而这2种状态的作业比例不均衡,失败作业大约占比为31%,采用随机切割法可能会导致模型学习更倾向于预测为成功作业,非常不利于机器学习预测。因此,本文对作业日志采用分层切割的方法,保留训练集和测试集的失败作业占比与原始失败作业占比一致,同时需要过滤一些无意义的、样本数据异常的和不利于切分的用户作业记录,以保证实验结果的有效性。
3.3 数据预处理
同时,作业日志中存在很多状态的作业记录,除了成功作业和失败作业,还有已取消的、正在排队的和正在运行的作业。本文主要针对作业的失败进行预测,因此只关注作业日志中的成功作业和失败作业,即State字段为COMPLETED和FAILED的作业为预测对象。
3.4 作业失败影响因素分析
SLURM作业日志中所记录的所有字段(特征)中,有一部分只有在作业终止时才可以获得,比如结束时间、退出码等。本文研究的目的是提前预测作业的失败,因此这些作业终止后才能获得的特征不能作为作业失败预测模型的输入特征。
在余下的可选特征中,关注了一些与作业属性相关的传统特征,如表1所示。
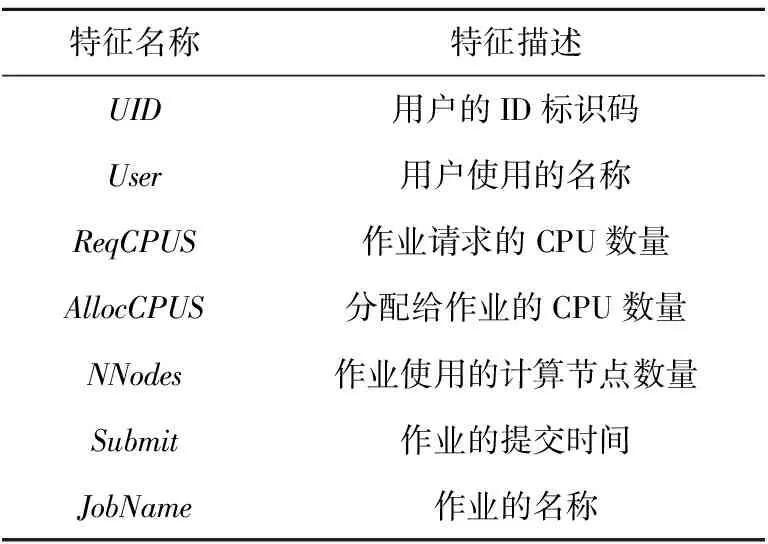
Table 1 Traditional features related to job attributes
ReqCPUS和AllocCPUS均与作业的资源需求有关,作业失败通常是由于软硬件因素所导致的,这2个特征可能会是作业失败的影响因素。
网络口碑是在社交网络兴起的背景下出现的,其满足了消费者之间互动的需要。消费者之间的互动不仅可以提升消费者价值,而且可以满足其自我表达的需要。另外,消费者之间的互动能够让消费者产生内在的愉悦感。根据Baloglu等[27]研究,与专业建议、广告和书籍(电影、新闻)等媒体相比,网络口碑对顾客感知特定品牌形象的影响最大,高达76%的消费者在购买决策时会受到网络口碑的影响。这意味着,无论消费者在哪里交流,他们在社交网站上传递可靠的信息可能会改变其他消费者的行为和态度。
NNodes代表了作业所使用的计算结点数量,与作业的规模相关。通常作业使用的结点数量越多,并行规模越大,程序交互行为就越复杂,可能受到环境噪声的影响程度就越大。
如表2所示,单结点作业中成功作业数量占82.71%,失败作业数量占17.29%;多结点作业中成功作业数量占66.69%,失败作业数量占33.31%。
多结点作业的失败率相对于单结点作业的明显更高,这说明,作业在多个结点上并行执行,由于结点之间需要相互通信,它们的交互性和复杂性更强,相对于单结点作业也越容易失败。因此,NNodes这个特征可以用于预测作业失败。
试验鸡来自北京市华都峪口禽业有限责任公司,挑选体重相近、体况健康的9周龄“京红1号”蛋种鸡1 260只,饲养试验在华都峪口禽业有限责任公司鲍官庄养殖基地进行。

Table 2 Distribution of single-node and multi-node job state
Submit为当前作业的提交时间,在作业日志中的记录样式为:2020-01-01T10:24:36。日志分析中发现,同类型作业在提交时间上比较接近。如大量相似的作业同时提交,说明这些作业很可能来自于用户的同一工程项目或研究;在非常接近的时间里提交的相似作业,其工作应用模式也具有相似性,在一定程度上反映了作业的工作特点。
作业日志中JobName是当前作业的一种标识,与作业内容意义相关。如表3所示,存在大量的相似作业名,比如,字符串中只有数字符号不一样,其他内容都非常接近,这些作业的工作特性可能比较相似。如果能够有效地对作业名进行聚类处理,将会大大减少冗余信息,提升预测效率。

Table 3 Two types of similar job names
4 作业失败状态预测方法
4.1 特征向量
(1)作业名聚类。
在作业日志中,有1 564条不同的作业名,这些作业名主要是由字母、数字及下划线等特殊字符组成。其中,数字代表版本或者编号等,下划线等特殊字符起间隔作用,对作业的应用意义不大。因此,为了降低计算开销,只保留字母并将其小写化。通过使用最长公共子序列LCS(Longest Common Subsequence)算法[20]来计算不同作业名之间的相似长度,其计算公式如式(1)所示:
(1)
其中,i和j分别代表x和y字符串的长度,c[i,j]表示x和y这2个字符串的最长公共子序列的长度。为了防止因不同作业名之间的相似长度的量纲不一致而对聚类结果产生影响,采用将相似度数据量纲控制在0~1,其相似度计算公式如式(2)所示:
(2)
通过式(2)可以计算得到2个作业名之间的相似度。对两两作业名计算相似度可以得到相似度矩阵。相似度矩阵的样例如下所示:
然后,以相似度矩阵作为输入,采用k-Means聚类算法[21]对作业名进行聚类,其中k-Means聚类算法的k值表示最终聚类的类别数,由聚类的目的确定。本文当同一类作业名之间的相似度均大于0.8时为最佳k值。最终得到了507类作业名(作业类型),在本文中,将聚类后的作业类型命名为JobType。
(2)构建特征。
除了作业日志中的原始特征外,本文还探索出一种新的特征,即同一用户下同一作业名的重复提交次数,反映了用户的一种作业提交行为模式。
在作业日志中,并没有对用户的提交行为进行定义,本文是基于作业名和用户ID来确定用户的作业提交行为。用户多次提交相同作业存在多种原因,如有的用户需要逐步改变作业内部参数,或者是在用同一作业测试某一项工作等。
从图2剥落断口宏观形貌可以看出,断面出现呈弯曲并相互平行的沟槽状花样,与裂纹扩展方向垂直,是裂纹扩展时留下的微观痕迹,属于明显弧形疲劳辉纹,其反向指向裂纹源(A区域),疲劳裂纹从A区域向B方向扩展,形成一个疲劳扩展带(AB),与此同时AB裂纹两侧向C方向扩展,最终导致大面积剥落,疲劳扩展带见图2中光滑的氧化区域所示。从剥落断口宏观形貌进行分析得出,剥落裂纹的起始位置处于支承辊淬硬层厚度位置,然后沿着剪切应力方向扩展,直至剥落。因此,该支承辊失效形式属典型的疲劳剥落失效。剥落是从支承辊次表层开始,由疲劳裂纹顺着剪切面扩展而形成。
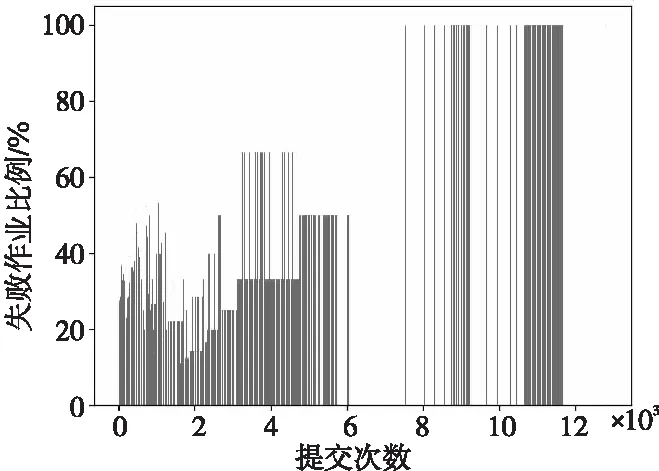
Figure 1 Proportion of failed jobs under different submission times
在ET和RF中,NSubmission和JobType的特征重要性排名前三。在2种方法中,UID和JobType的重要性占比非常接近,说明JobType和UID对模型预测作用起到了良好的效果,同时NSubmission和JobType的综合重要性均超过了40%,即2个特征在决策子树产生分支过程中起到了重要作用。
通过前文的分析和探索,得到如表4所示的特征作为本文预测模型的输入特征。

Table 4 Attribute and name of each feature
在这些特征中,可能会存在一些冗余特征,影响预测效果。由于本文的预测属于分类问题,因此需要过滤离散程度相近且呈线性相关的特征。离散度计算公式如式(3)所示:
项目来源有多种,如教师的科研项目、某些领域的研究热点、发明专利,等等。就目前我们开展的项目来看,基本是软件和硬件结合的项目。项目开发的目标是参加各种竞赛及形成科研成果,如发表学术论文、申请专利。
(3)
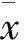
Figure 2 Degree of dispersion of each feature(logarithmic display)
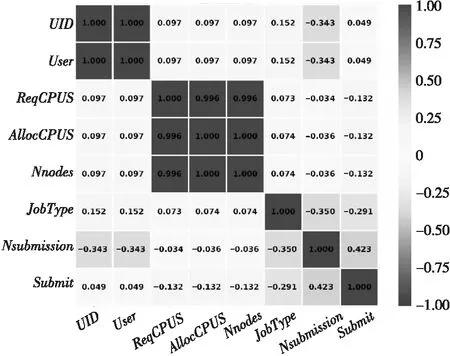
Figure 3 Correlation matrix
使用Pearson系数[22]计算特征之间的相关性,其计算公式如式(4)所示:
(4)
其中,x,y分别代表n维特征向量。
相关系数矩阵如图3所示。相关系数的范围在0~1,系数的绝对值越接近于1,说明2个特征的相关性越强。
正确识别出大多数成功作业能够大幅提升准确率,但在实际应用中,希望能够发现更多可能失败的作业,以及时做出有效应对措施。因此,基于2种评估指标和实际应用情况,本文又提出了加权平均S分数(S_score)。在S分数中敏感度的权重大于特异性,其计算公式如式(9)所示:
(2)设置检查点:预测为失败的作业将得到用户更多的关注,建议用户在作业中设置检查点,这样可以在失败的作业重启时从最近的检查点开始执行,不用从头开始执行,这样可以节约系统资源。
4.2 机器学习算法
集成学习是目前应用非常广泛的机器学习算法,通过构建多个学习模型,然后集成所有学习模型的建模结果作为输出结果。
第二个驱动是终端用能结构优化。电能替代是终端用能结构优化的重要途径。前三季度,全国累计完成电能替代量1 216亿千瓦时,对用电增长的贡献率达29.1%。工农业生产、居民生活、交通运输领域电能替代量分别占77%、11%、8%。
随机森林RF(Random Forest)[23]是一种装袋式(Bagging)集成学习算法,通过构建多个独立的决策树,每棵决策树有放回地随机从训练数据集中抽取数据训练决策树。对于分类决策树,选择决策树结果为多数的类别作为随机森林的决策结果。
在随机森林算法中,每棵树通过计算不纯度产生分裂节点,即子节点不纯度应低于父节点。在本文中,随机森林使用基尼系数(Gini Impurity)作为不纯度计算方法,计算公式如式(5)所示:
(5)
其中,t表示指定的节点,c表示样本类别数,p(b|t)表示分类标签b在节点t上的占比。
极端随机树ET(ExtraTrees)[24]也是多个决策树集成学习算法。与随机森林不同的是每棵树都使用整个学习样本进行训练,且自上而下的节点划分是随机的,不计算每个特征的最优划分点,而是从特征经验范围内均匀随机选取。在所有随机的划分点中,选择其中分叉值最高的作为节点的划分点。
二是在建设农渠时优先选址在林地内以节约耕地资源。目前累计节约耕地2500亩。渠道建好后及时在两边植树造林,做到渠成林成,形成“渠内碧水流,渠边绿树幽;树木站两边,树影映悠悠”的景象,实现“渠在林中”。
5 实验与结果分析
5.1 预测方法
在预测实验中,倾向于发现更多可能失败的作业。本文设计了综合预测框架E-R(Extra-Random),如图4所示,分别使用ET和RF训练预测模型,将2个模型的子结果相结合得出最终的预测结果。2个模型的作业失败预测结果以逻辑“或”方式组合,如表5所示,如果2个模型对作业预测都为成功,则该作业被预测为成功作业,在其他情况下都被预测为失败作业。
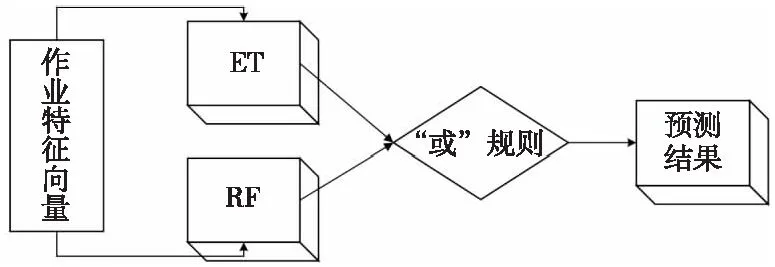
Figure 4 E-R prediction framework
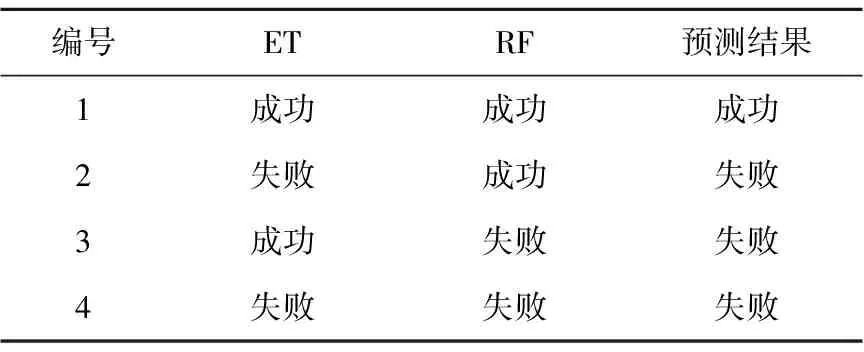
Table 5 “OR” rule of E-R prediction framework
5.2 实验设置与评估指标
将预处理后的数据集按照7∶3的比例划分为训练集和测试集。由于分类样本的不均衡性,为了保证数据样本类别的平衡性及数据信息的完整性,对失败作业采用上采样的方式对训练集进行处理,其中所有输入特征均在维持原始时间序列下进行计算。
在预测实验中,失败作业为正样本(Positive),成功作业为负样本(Negative)。同时采用3折交叉验证的方式来增强预测模型的鲁棒性。将实验数据中的作业状态及预测的结果进行比较,预测结果共分为4类,如表6所示。其中,TP、FP、TN和FN分别表示真正例、假正例、真负例和假负例。假正例为将负样本错误地预测为正样本,假负例为将正样本错误地预测为负样本。
根据NETMAKETSHARE的统计数据[3],Android和iOS已占据手机操作系统98%以上的市场。由于Android和iOS的开发技术完全不同,早期很多企业必须针对这2个平台开发具有相同功能的APP,会耗费大量的人力和财力资源,增加开发和维护成本。
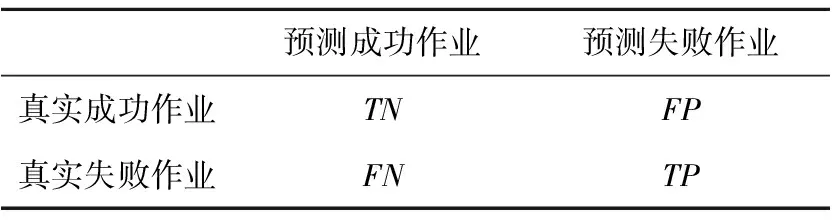
Table 6 Four kinds of prediction results
通常在作业失败预测研究中,除了关注准确率(accuracy)外,还会关注成功作业和失败作业的预测效果,因此在实验中还通过特异性(specificity)和敏感度(sensitivity)2个指标对成功作业和失败作业的预测效果分别进行评估。特异性反映了模型能够正确识别成功作业的效果,敏感度反映了模型能够正确识别失败作业的效果,评估指标的计算分别如式(6)~式(8)所示:
(6)
(7)
(8)
通过图2和图3可以发现,UID和User的离散程度一致且极度相关,因此只保留了UID。此外,AllocCPUS和ReqCPUS的离散程度相近。分析发现,AllocCPUS始终大于或等于ReqCPUS,不存在CPU数量分配不足的情况。ReqCPUS和NNodes的相关性弱于AllocCPUS与NNodes的相关性,且ReqCPUS与NNodes的离散程度不一致,因此保留了ReqCPUS和NNodes。
(9)
5.3 实验结果与分析
使用本文探索出的特征向量分别在RF、ET和E-R综合框架中进行预测实验,其结果如表7所示。

Table 7 Effect of each prediction method
ET在每种指标上都表现平稳。RF在准确率、特异性和敏感度上均优于ET。在E-R综合框架中,敏感度相较于其他2种方法预测效果有一定提升,准确率和特异性在可接受范围内有所下降。
所有输入特征在ET、RF的决策子树产生分支的过程中起到了一定的作用,并且每一次产生分支都会选择更为重要的特征。输入特征在ET和RF中的重要性分别如图5和图6所示。
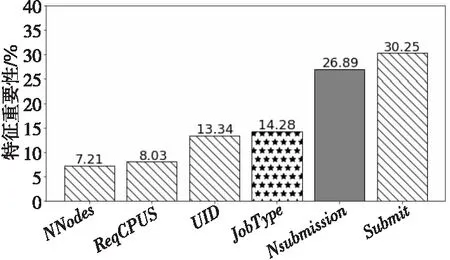
Figure 5 Proportion of importance of each feature in ET

Figure 6 Proportion of importance of each feature in RF
(3)去除冗余特征。
环境要素中的基准指代与传统意义上的指代有所不同,存在指代关系的两个要素并不是指向同一实体,而是一种关联关系,即通过先行环境要素来确定照应环境要素的具体位置.从表2中可看出,这种类型的指代占整个环境要素指代的16%,所以其识别与否对于指代消解系统的性能有显著的影响.在已标注的语料中,对这种指代关系进行统计得出,照应环境要素基本上都是以“周围”“附近”“外面”这种抽象的地理位置词开头,可以通过构建一个抽象环境要素的词典进行识别,然后再找出其对应的先行要素.这仅仅是初步的构想,具体实现还要综合各种因素进行考虑.
本文使用S分数对3种方法的最终预测结果进行比较,如图7所示,E-R的S分数达到了87.78%,相较于RF和ET的,分别提高了0.67%和1.98%。
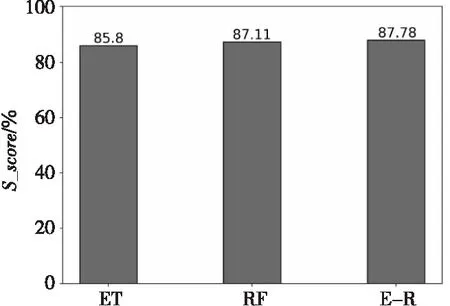
Figure 7 Prediction results under S_score
E-R能够发现更多的作业失败情况,预测出了88.9%的失败作业,准确率达到了85.22%,在最终的评估指标S分数中表现最好。
5.4 对比实验
在高性能计算系统的故障预测研究方面,一些研究使用逻辑回归LR(Logistic Regression)[25]和朴素贝叶斯NB(Naive Bayes)算法[26]预测软硬件故障,使用支持向量机SVM(Support Vector Machine)算法[17]预测作业失败,然而,这些预测方法并未对作业名进行聚类操作,也没有通过作业名确定用户的作业重复提交行为。
由“读若”线索可得出“介”通过音同借了“丯”草的意义,并由此引申出“微小”的意义。但是解释假借单凭声音关系是不够的,还要结合字形来分析。
在去掉输入特征NSubmission和JobType的情况下,使用上述预测方法与前文E-R结果进行比较,实验结果如表8所示,RF的预测效果优于LR、NB和SVM的。其中,LR和NB预测效果非常差,显然不适合该实验数据。SVM通过提高特征维度的方式,在高维空间拟合核函数(径向基)寻找决策平面,计算开销大,虽然准确度可以达到73.48%,但对作业失败的预测效果较差。
该项目规划占地面积69亩,总投资8850万元。救灾物资储备库、救助管理站、未成年人救助保护中心、社会福利院、大平山农村养老服务中心、儿童福利院、社会福利院老年养护楼、老年人活动中心等已建成投入使用;二期项目将建设老年公寓。
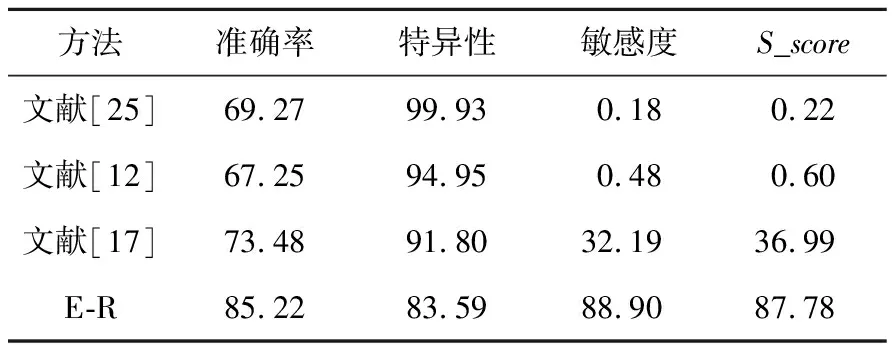
Table 8 Prediction effect of different methods
5.5 建议
通常对于预测失败的作业会采取提前终止的方式,让更多的成功作业能够被执行,然而这对用于科研生产的超级计算机是不友好的,因为这样会损失大量失败作业产生的错误和中间输出信息。这些信息对于用户而言非常重要,用户可以根据这些信息更好地调试,直到作业成功完成。因此,本文提供一些可选的建议和措施,在保证生产的同时,也能够提高系统的资源利用率:
(1)调整调度优先级:在超级计算机中,采用先来先服务和回填调度的策略调度作业执行顺序。超级计算机上可能存在空闲资源。如果这些空闲资源不能满足等待队列中的头作业,那么系统将始终保留空闲资源。然而,所保留的空闲资源可能满足后续队列中其他短而小的作业需求。一般情况下,失败作业的运行时间会比正常完成的运行时间短,因此可以有选择地将一些适合回填插空的失败作业优先执行,这样可以让用户更快地知道结果,方便用户调试作业。
最终,本文保留了UID、ReqCPUS、NNodes、JobType、NSubmission和Submit这6个特征。
6 结束语
确保作业的有效执行能够尽可能地提高超级计算机的资源利用率,因此,对作业失败做出有效的预测并采取有效的措施是至关重要的。本文通过对作业日志的探索和分析,挖掘出了与用户行为相关的特性,即作业名聚类及作业提交次数,这2种特性分别反映了用户的工作行为模式和提交行为模式。基于挖掘出的行为模式,提出了E-R综合预测方法。该方法的预测准确率达到了85.22%,敏感度达到了88.9%,优于其他相关研究方法。
