A Domain-Guided Model for Facial Cartoonlization
2022-10-26NanYangBingjieXiaZhiHanandTianranWang
Nan Yang, Bingjie Xia, Zhi Han,, and Tianran Wang
Dear Editor,
This work investigates the issue of facial cartoonlization under the condition of lacking training data. We propose a domain-guided model (DGM) to realize facial cartoonlization for different kinds of faces. It includes two parts: 1) a domain-guided model that contains four different interface networks and can embed an image from a facial domain to a cartoon domain independently; and 2) a one-toone tutoring strategy that uses a sub-model as a teacher to train other interface networks and can yield fine-grained cartoon faces. Extensive qualitative and quantitative experimental results validate our proposed method, and show that DGM can yield fine-translated results for different kinds of faces and outperforms the state of the art.
Introduction: Facial cartoonlization is a promising and interesting topic and can be used to image processing, secure computing, social media, the internet of things, and finance. CycleGAN [1] uses a cycle consistency loss to realize facial cartoonlization [2]–[7] based on generative adversarial networks [8], [9]. U-GAT-IT [10] proposes a module named class activation map (CAM) that guides a model to focus on key regions to realize facial cartoonlization. Photo2cartoon[11] is Minivision’s open-source mini-program, which is built on UGAT-IT and can be used to enhance the generative ability. These mentioned methods can only work well based on sufficient data, and can not realize a fine translation when lacking data. Besides, collecting different kinds of faces is very difficult and suffers from data imbalance, which leads to mode collapse in training phase and impedes facial cartoonlization. Therefore, two issues must be solved:1) how to translate different kinds of faces in one training phase without affecting each other? 2) how to obtain fine-grained facial cartoonlization under insufficient or lack of data? This motivates us to develop a novel model that can: 1) realize facial cartoonlization for different kinds of faces with one model and without affecting each other; 2) yield fine-grained translated results under insufficient or lack of data.
After a rigorous statistical analysis of the dataset used by the above methods, we find that most of the existing data are for young women,not men, kids, and the elderly. In this work, we regard a young women dataset as a support set that is used to train a domain-guided model. We treat the model as a teacher for translating men, kids, and the elderly. It is reasonable since these faces are all in the facial domain despite they are different from those of men, kids, and the elderly. Therefore, we redesign a generative framework and detach four different interface networks for 1) young women, 2) men,3) kids, and 4) the elderly, respectively. The interface networks aim to extract and translate different features in which their middle layers are shared with young women networks. Furthermore, we propose a one-to-one tutoring strategy to train these interface networks. Experimental results show that the proposed domain-guided model and strategy can well translate men, kids, and the elderly to cartoon faces without affecting each other. The creative contributions are:
1) We propose a domain-guided model based on the design idea of modularization, which consists of four different interface networks and describes the independence of networks. The model is flexible and can embed different kinds of faces into cartoons without affecting each other. It solves the issue of using only one detached model to realize facial cartoonlization for different kinds of faces.
2) We propose a one-to-one tutoring strategy, which uses the domain-guided model to train four different interface networks and describes the similarity of these networks. A well-trained women sub-model can guide the other sub-models to find an optimal initialized translation domain. It yields fine-grained results for men, kids,and the elderly as achieved for young women. It solves the issue of realizing fine-grained facial cartoonlization under the conditions of lacking data.
Experimental environment: The models involved in the experiments are trained on a workstation equipped with an Intel(R) Xeon(R) CPU @2.20GHz and two NVIDIA Tesla V100 dual-channel GPUs. All experiments are performed under the Pytorch 1.7 environment, Cuda 10.0.44, and cuDNN 10.0.20.
Proposed framework: The whole framework is shown in Fig. 1. It contains five modules, i.e., four different interface networks, hourglass blocks, a CAM module [12], a discriminator, and a classifier.The interface networks receive different input faces and output their corresponding translated cartoon faces. The sky-blue interface network receives young women’s faces, which is regarded as a teacher to guide the other interface networks. The purple, yellow, and gray interface networks correspond to men (Student 1), kids (Student 2),and the elderly (Student 3), respectively. The hourglass blocks are fully considered to improve the extracted and translated performance in a progressive way. Notice that the sky-blue background denotes that the parameters of the teacher’s hourglass blocks are shared with other students. The CAM module can be used to distinguish different facial domains by paying more attention to discriminative image regions. The discriminator is applied to distinguish whether a cartoon face is real or translated.

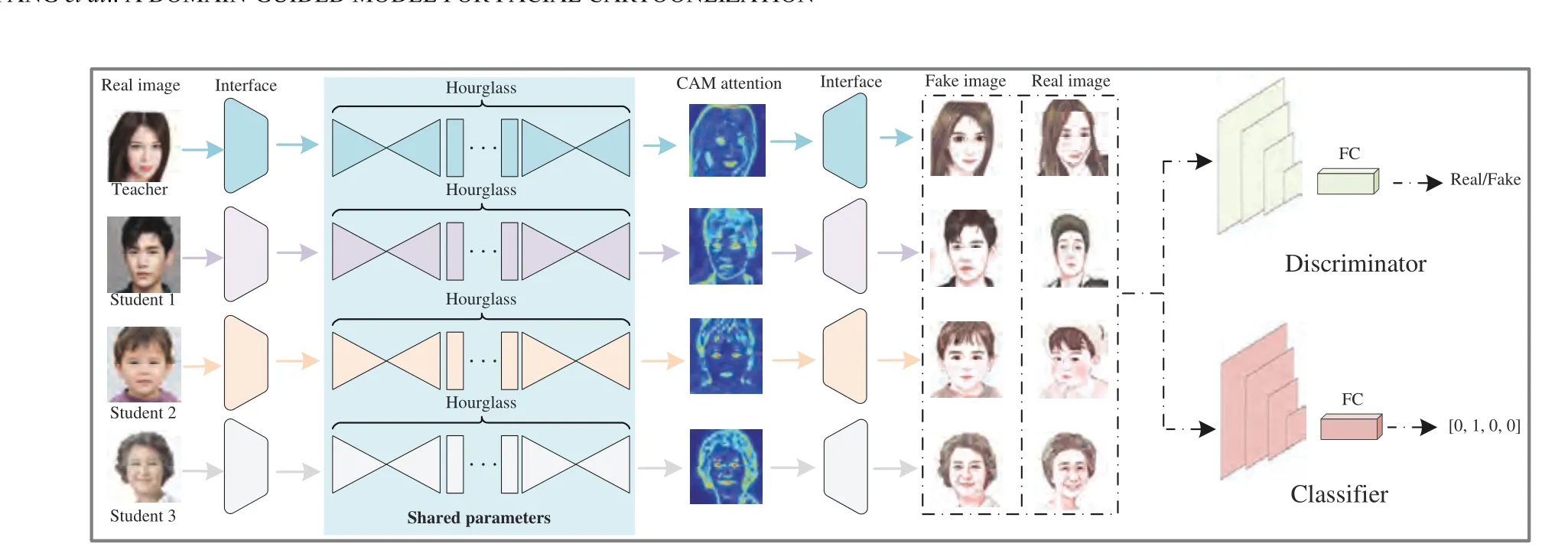
Fig. 1. The framework of DGM, which receives four different kinds of faces and can translate these faces to cartoons well. Details are described in proposed framework.

Comparison: We compare DGM with CycleGAN, U-GAT-IT,Photo2cartoon, and group-based method (GP) [13], these methods are the most recent and the best ones. The last one proposes a groupbased method for few-shot cartoon face generation. The results are shown in Fig. 2. We have three observations: 1) DGM can well translate real faces to cartoons for men, kids, and the elderly, despite lack of training data; 2) DGM can well preserve the facial identity, outline, and local details, i.e., lipstick and hair color; 3) The translated results for different kinds of faces without affecting each other. The favorable translation is owing to our detached domain-guided model and one-to-one tutoring strategy.
The detached domain-guided model contains four different interface networks, which ensures that other sub-models are trained with supervision from the sub-model of women in one training process.The one-to-one tutoring strategy is an online one, which can adjust the model’s parameters in real-time.
Table 1 shows the experimental results on spatial and computational complexity: 1) Trainable model parameters (TMP); 2) Model size (MS); 3) Floating-point of operations (FLOPs); 4) Amount of multiply-adds (MAdd); 5) Memory usage (MemR); and 6) Inference time (IT).

Fig. 2. The qualitative comparison results with CycleGAN [1], U-GAT-IT[12], Photo2cartoon [11], and Group [13].

Table 1.The Results on Model Complexity. M/u Denotes a Metric M and its Corresponding Unit
Ablation studies: We expect to evaluate DGM in two aspects: 1)its effectiveness; and 2) whether the one-to-one tutoring strategy improves the performance. Therefore, we set two configurations:DGM with and without the one-to-one tutoring strategy. The results show that DGM with the strategy eliminates image artifacts and further improves the translated quality for facial cartoonlization.Besides, we fully evaluate the translated faces for domainsf→candc→fbased on many full-reference metrics [14]. The quantitative results are shown in Tables 2 and 3. DGM outperforms all the compared methods on SSIM, PSNR, MSSSIM, VSI, VIF, FSIM, GMSD,LPIPS, and DISTS [8], [14]–[19].
Discussion and conclusion: In this letter, we propose: 1) a detached domain-guided model that translates different kinds of faces in one model and without affecting each other; 2) a one-to-one tutoring strategy that realizes fine-grained facial cartoonlization under the conditions of lacking data. However, our method may have some failure cases, e.g., it has obvious distortions, especially in the eyes.We also do not fully consider edge detection. Besides, the evaluation metrics are subjective since cartoon faces have no specific groundtruth. We plan to study a novel attention module by considering edge detection to improve translated performance.
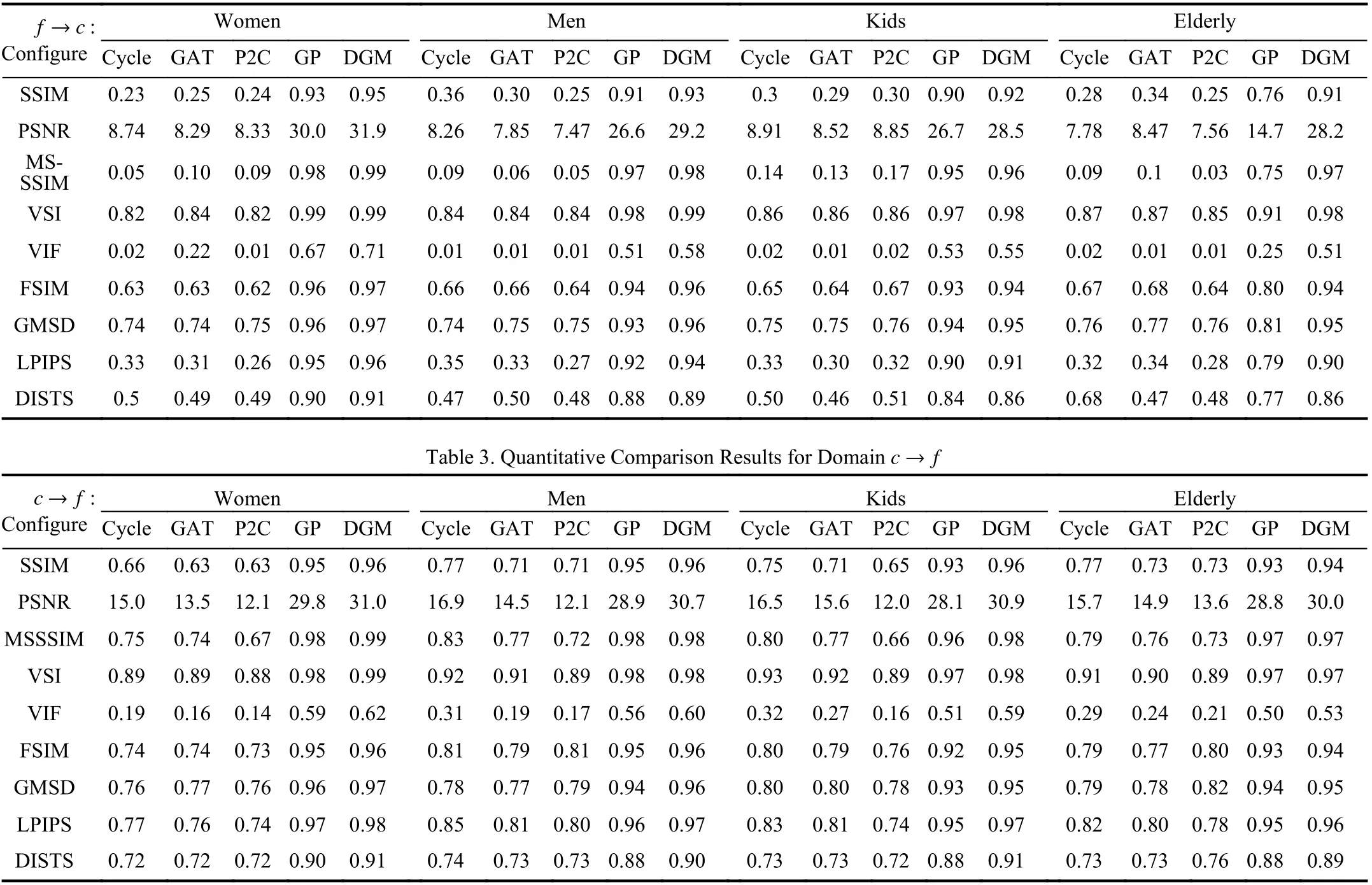
Table 2.Quantitative Comparison Results for Domain f →c. Methods With the Best and Runner-Up Performances are Colored With Red and Blue, Respectively. The Higher the Metric Value, the Better the Performance
Acknowledgments: This work was supported by the National Natural Science Foundation of China (61903358).
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Distributed Cooperative Learning for Discrete-Time Strict-Feedback Multi Agent Systems Over Directed Graphs
- An Adaptive Padding Correlation Filter With Group Feature Fusion for Robust Visual Tracking
- Interaction-Aware Cut-In Trajectory Prediction and Risk Assessment in Mixed Traffic
- Designing Discrete Predictor-Based Controllers for Networked Control Systems with Time-varying Delays: Application to A Visual Servo Inverted Pendulum System
- A New Noise-Tolerant Dual-Neural-Network Scheme for Robust Kinematic Control of Robotic Arms With Unknown Models
- A Fully Distributed Hybrid Control Framework For Non-Differentiable Multi-Agent Optimization