An Adaptive Padding Correlation Filter With Group Feature Fusion for Robust Visual Tracking
2022-10-26ZihangFengLipingYanYuanqingXiaandBoXiao
Zihang Feng, Liping Yan, Yuanqing Xia,, and Bo Xiao
Abstract—In recent visual tracking research, correlation filter(CF) based trackers become popular because of their high speed and considerable accuracy. Previous methods mainly work on the extension of features and the solution of the boundary effect to learn a better correlation filter. However, the related studies are insufficient. By exploring the potential of trackers in these two aspects, a novel adaptive padding correlation filter (APCF) with feature group fusion is proposed for robust visual tracking in this paper based on the popular context-aware tracking framework.In the tracker, three feature groups are fused by use of the weighted sum of the normalized response maps, to alleviate the risk of drift caused by the extreme change of single feature.Moreover, to improve the adaptive ability of padding for the filter training of different object shapes, the best padding is selected from the preset pool according to tracking precision over the whole video, where tracking precision is predicted according to the prediction model trained by use of the sequence features of the first several frames. The sequence features include three traditional features and eight newly constructed features. Extensive experiments demonstrate that the proposed tracker is superior to most state-of-the-art correlation filter based trackers and has a stable improvement compared to the basic trackers.
I. INTRODUCTION
VISUAL tracking plays an important role in computer vision and finds various applications such as video surveillance, autonomous driving, unmanned plane and human-computer interactions [1]-[3]. The main challenge for robust visual tracking is to learn valid and diverse differences between the target and the background. Although visual tracking research has achieved remarkable advances in the past decades, it remains a difficult task to develop robust algorithms to estimate object locations in the consecutive sequences with challenging situations such as non-rigid deformation,heavy occlusion, illumination change, background clutter and rotation [1].
Recently, there has been a significant breakthrough in discriminative model for visual tracking by introducing correlation filter (CF) based trackers, which are used in many applications [4]-[6]. Intensive samples and efficient computation make CF based trackers achieve good performance at high speed.
Due to the success of deep convolutional neural networks on other computer vision tasks, several trackers based on deep convolutional layer features and correlation filters have been developed [7]. More recently, Siamese networks are used to obtain a response map and object location, which benefits from the correlation option and learning ability in the embedding space. It is a common fact that the convolutional neural network (CNN) based trackers and the Siamese based trackers outperform methods based on hand-crafted features.Despite achieving good performance, these trackers are seriously limited by their computation cost and the expensive device with parallel computing cells.
Even only taking account of traditional features, many improved versions of CF based trackers make state-of-the-art results on large object tracking benchmark datasets introduced by [1], [8], [9]. Boosted by the representation ability of multiple features, many results have shown remarkable performance [10]-[15]. Some of them are also supported by the effective handling of the boundary effect [12]-[17], which is explained in detail in Section II-B. Multi-feature and multisample CF based trackers are difficult to compute because they can not be computed in the Fourier domain as a traditional CF does [11]. To handle this problem, Mueller et al.[16] propose an acceptable framework by reformulating the original optimization problem and providing a closed form solution for single and multidimensional features in the primal and dual domain.
Padding, a dominant parameter related to the boundary effect, has not attracted sufficient attention. Most of the CF based trackers employ the sample bounding box determined by the given target bounding box and the sample parameter paddingp. The sample bounding box is centered at the target and the size of it isp+1 times larger than the target bounding box. An interesting fact is that the padding of most trackers in their open codes takes a fixed value such as 1.5, 2.0 and 2.1.Although the difference of paddings can be explained by many reasons including the difference of features and the difference of optimization criteria for training, the truth is that padding is desired to make the sample bounding box provide enough background information for the tracker training to precisely deal with the boundary effect. In [18], Maet al.systematically analyze the effect of the size of surrounding context area for designing effective correlation filters, where they give the proper padding corresponding to the best precision for each video and plot the average precision curve and the standard deviation with changeable padding as anx-axis for all videos to show that the performance of the tracker is sensitive to the padding size of the surrounding context on target objects. Although the CF based trackers can achieve appealing performance, the adaptive padding can conserve adequate discriminative information and avoid retaining too much background or too distracting background for the objects of different shapes.
The extension of features sometimes causes more frequent appearance feature distraction. Previous trackers introduce some features, like color-naming space features (CN) given in[10] and the output of the intermediate layers of CNNs [19].Features treated equally improves the tracking performance when the features are reliable over time. Once single feature encounters obvious change, the risk of drift increases. Considering the complementary properties of different single features, feature fusion could obtain more effective tracking results. In particular, a tracker that fuses the intensity gradient features and color features can deal with illumination variation, in-plane rotation and deformation very well, because the intensity gradient is stable in the case of illumination variation and the color is stable in the case of in-plane rotation and deformation.
Considering the adaptive ability of padding for different object shapes and the robust tracking property of feature fusion, a novel adaptive padding correlation filter (APCF)with feature group fusion is proposed. To achieve the goals, a tracking precision prediction model is presented to select the best padding from the preset pool of trackers with different paddings in the manner of time series data classification. In the model, the multi-channel time series data contains the inputs and the intermediate variables of the tracker in the tracking process. The predicted attribute of the time series is the tracking precision over the video. Meanwhile, a novel fusion approach for response maps of feature groups and a novel updating strategy based on the fused response map are employed to deal with the challenging situations, such as illumination variation, in-plane rotation and deformation of the target. The fusion concerns the histogram of oriented gradient(HOG), the color-naming space (CN) and the histogram of local intensity (HI), where HI is extracted after Gamma correction.
The main contribution of this paper can be summarized as follows. 1) The proposed feature group fusion tracker alleviates the distraction caused by the abrupt change of the single features especially in the challenging situations of illumination variation, in-plane rotation and deformation. 2) The proposed adaptive padding method uses the predicted tracking precision to select the best padding, which improves the adaptability of tracker training for targets of different shapes.The predicted tracking precision is obtained by an effective support vector model using 11-channel features of the first several frames, where eight types of features are designed in this paper. 3) A thorough ablation study is provided to verify the contribution of the above two aspects. Qualitative and quantitative experiments show the effectiveness of the proposed APCF tracker.
The rest of this paper is organized as follows. In Section II,the work related to the proposed trackers is reviewed. In Section III, the APCF with the feature group fusion is elaborated in detail. Extensive experiments are carried out and analyzed in Section IV. Finally, Section V draws the conclusion.
II. RELATED WORK
A. Correlation Filters About Feature Extension and Framework Modification
Bolmeet al.[20] first introduce correlation filter theory into the field of visual tracking. Henriqueset al.[11] introduce a strong feature for pedestrian detection and a feature which represents the space for human-like color discrimination, i.e.,HOG and CN [21], respectively. The abundant representation ability of these features improves tracking performance. Maet al.[18] use HI in addition to the commonly used HOG features to train a translation filter, in which a modified scale filter, a long-term memory filer and a re-detector are combined to improve efficiency, accuracy and robustness. Recently,some researchers work on the fuzzy reliability to further improve the robustness of CF trackers [22], [23]. Multiple trackers are integrated into a framework in [24], and a more effective tracker is constructed. In [25], the features of different layers are fused with different response maps defined by the prior knowledge of the network. Our proposed tracker obtains the final response map by the group fusion of the normalized response maps calculated by the HOG, CN and HI feature groups. Instead of using two filters to search the translation and scale change as in [18], our proposed tracker jointly determines the translation and the scale based on the pyramid final response maps, in which CN is fused with HI and HOG to improve the robustness of the joint search.
B. Correlation Filters About Region Adaptation
The CF based trackers are effective for speed and performance. However, these methods have a trick for the classification problem. Although the samples for training and searching are numerous, their information is limited because they are shifted and constructed by the single base sample in the frame.The trick leads to the so-called boundary effect.
Many trackers try to alleviate the boundary effect in filter training. In the correlation filter learning toward peak strength(PS) [12], L1-norm is added into the primary problem with the label fitting term and L2-norm regularization term. The activated filter parameters are gathered by the L2-norm and selected by the L1-norm. Xuet al.[14] apply structured spatial sparsity constraints to multi-channel filters and update the filters locally to preserve the global structure to learn adaptive discriminative correlation filters (LADCF). Danelljanet al.propose the learning spatially regularized correlation filters(SRDCF) [13], which imposes a Gaussian function penalty to the regularization term, so that the parameters in the boundary region have stronger limitations than those in the central region. The strict regularization allows very large padding for SRDCF. In [25], the reference features and the search features are transformed to the initial features and the current central features, respectively, to make the tracker focus on the central region. Guoet al.use dynamic spatial regularization[26] to control the influence of context. References [27] and[28] employ the saliency information. Liet al.[29] propose an effective online adaptive spatio-temporal regularization term to make DCF focus on the learning of trust-worthy parts of the object and use global response map variation to determine the updating rate of the filter. The context-aware correlation filter(CA) [16] obtains a similar effect on the regularization of boundary parameters as SRDCF and has a lower computational cost by adding four background base samples for training instead of using direct regularization. In a word, the above discriminative models, whose parameters are trained to be activated in the central region, are considered to alleviate the famous boundary effect in CF based trackers. This shows that the correlation filter should focus on the discrimination of the base sampleX0and all the shifted samples in the central region.
Different from the above, this paper focuses on the validity of padding to alleviate the boundary effect caused by the circulant samples of different object shapes. The initial target bounding box is usually the horizontal circumscribed rectangle of the target, in which the interior region may not be filled with the target appearance. Then, the sample bounding box without adaptive padding is unsuitable for filter training. As a simple example, with fixed padding, the best tracker for a car has difficulty in robustly tracking a human being. The reason is that the former target bounding box filled with the car has no background information but the latter box supported by human limbs has rich background information.
C. The Application of Correlation Filter in Deep Learning Tracking
Many neutral networks introduced from other computer vision tasks have some limits in the tracking process. Fundamentally, elaborate networks for object detection are supervised by classification information (the labels of training data), which do not consider how to use previous images of the object to enhance discriminative ability between the object and the background and to update networks. This leads to too many parameters to be trained, and there is no specific method designed for updating in the continuous inference stage.Advanced tracking algorithms usually extract reference features and search features based on modern backbone networks and put them into the modified network to track the object represented by reference features in the search space supported by the search features. Danelljanet al.[30] use simple two-layer convolution to transform the search features into the response map for robust localization, which is similar to the fast localization step of correlation filters. It is noted that the two-layer convolution is generated by the reference features and updated by the designed fast back propagation. The robust localization method using the correlation filter is simple yet powerful and can be trained online, which provides high robustness against distractive objects in the scene [30].Many algorithms are developed based on the robust localization network, such as [31]-[33]. These modern networks running on an expensive device with parallel computing cells are introduced to verify the advantage of correlation filters in the tracking process. Our tracker based on the traditional correlation filter allows for competitive performance without GPU workstation.
III. PROPOSED TRACKER
In this work, we propose a novel tracker, which consists of two components: 1) A feature group fusion module that makes good use of the maximum value and the L2norm of the response maps to alleviate the distraction caused by the abrupt change of single features shown in Fig. 1(a); 2) An adaptive padding method that provides suitable-to-learn discriminative information for the feature group fusion tracker to improve the adaptive ability for the objects of different shapes shown in Fig. 1(b). These two components improve the robustness of the proposed tracker from different aspects. In Section III-A,the context-aware correlation filter toward peak strength is mentioned as the basic tracker, which is named as PSCA[17]. In Section III-B, the novel feature group fusion and the novel updating strategy are integrated based on PSCA. In Section III-C, the proposed adaptive padding method uses machine learning techniques to predict tracking precision of different paddings and select the best padding. To explore the potential of trackers in the fusion of features and the solution of the boundary effect, the two components are integrated in the tracking framework in Section III-D.
A. Basic Peak Strength Context-Aware Correlation Filter
The superiority of a context-aware tracking framework [16]is mentioned in Section II-B. Our baseline PSCA extracts the target featuresA0and the external background featuresAi,i=1,2,...,mat every frame [17]. For simplicity and effectiveness, the sample method crops the images by the sample bounding box with four-direction offsets of target size.Namely,m=4. Integrated withAiand L1-norm of the filter,the objective function in PSCA is

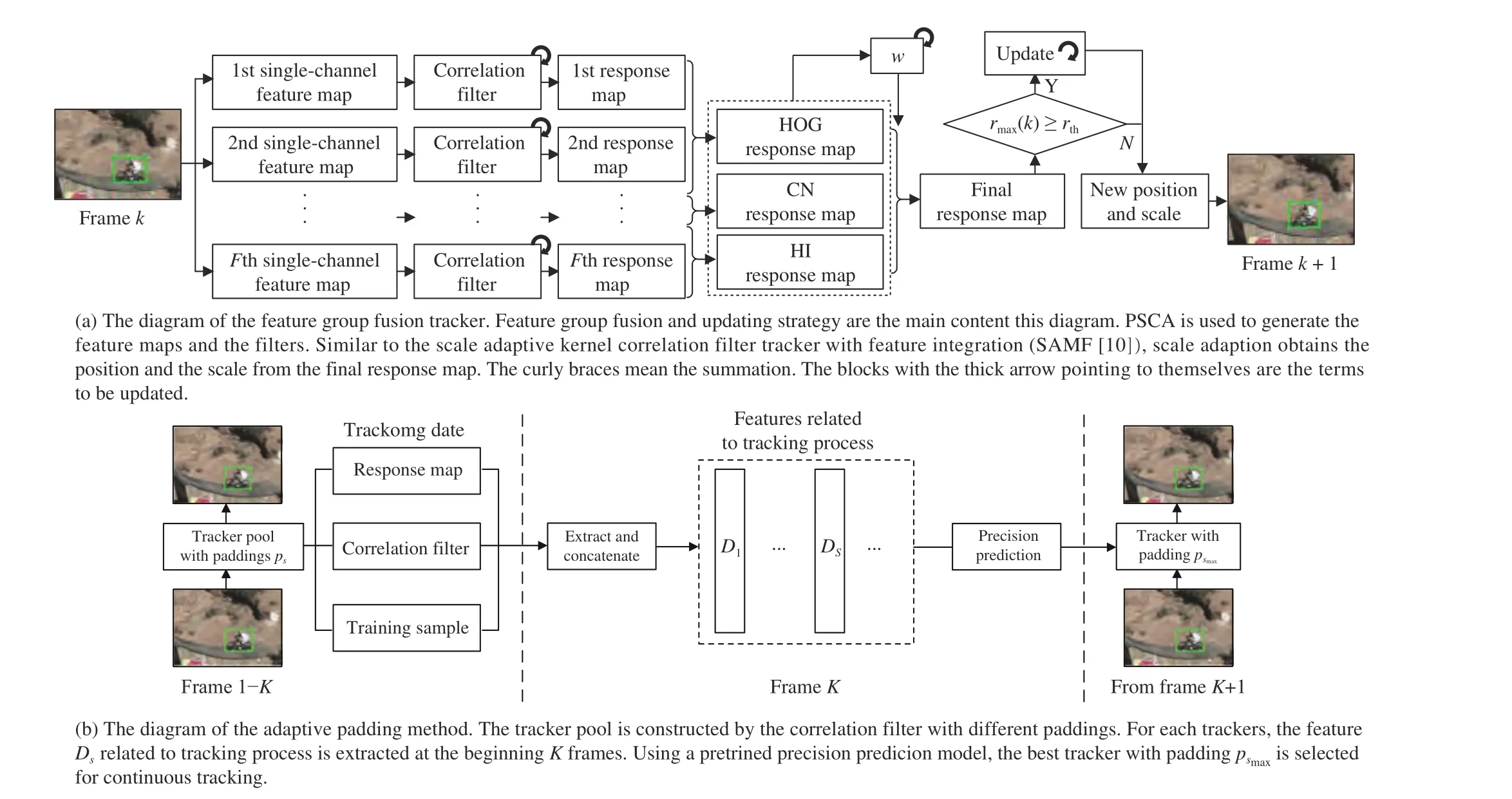
Fig. 1. The diagrams of the proposed APCF tracker. The tracker consists of the feature group fusion tracker in (a) and the adaptive padding method in (b).

B. The Proposed Feature Group Fusion Tracker
Current features are increasingly rich, such as histogram of oriented gradient (HOG), color naming (CN) and histogram of local intensity (HI). In the CA framework, every channel is used to train a filter and obtain a response map using (9). The similarity betweenzand the target is represented by the summation of all response maps. However, rich features may not lead to good representation ability. To use the features more effectively and to improve the tracking performance, the summation is replaced by the presented feature group fusion method. A small change of online model updating enables the tracker to be adaptive to the fused response. The diagram of the improved tracker is shown in Fig. 1(a).
Considering the extracted multi-channel features, (1) is extended to the multi-sample and multi-feature case



Remark 1:There is one thing to be declared. In fact, CA trackers and other trackers with the results of (9) can be modified by the feature group fusion strategy. Moreover, PSCA in this section is the advanced version of CA trackers to our knowledge. The experiment is carried out using PSCA to achieve the highest precision and verify the effectiveness.
C. The Proposed Adaptive Padding Method
Because the padding is fixed in the online tracking process,it is necessary to determine the best padding by the first several frames. Based on the beginningK-frame tracking process,the proposed method uses machine learning techniques to predict tracking precision of different paddings in the preset padding pool and select the best padding for the subsequent tracking frames. The diagram is shown in Fig. 1(b). For the prediction task, eight novel features related to the tracking process are presented together with the three traditional features. The precision prediction model is obtained by the following four steps.
· Padding setup: The paddingsps∈P are determined by the sample box scaless∈S, which are appropriate for tracking based on the experience of the parameter adjustment (detailed in Section IV-B).
· Data collection: One type of tracker can generate specific trackers for object tracking using different paddings. The trackers are tested on the Object Tracking Benchmark dataset(OTB 2015 [8]) and the tracker data of the firstKframes are collected (detailed in Section IV-B).
· Feature extraction: Eight novel features related to the tracking process are presented together with the three traditional features, namely, the maximum of the response map,peak to side-lobe ratio andQindex of the response map.
· Model training: A support vector machine is trained to predict the tracking precision based on the features of the beginningKframes.
1) Feature Extraction of Tracking Process:In the sequel,three features related to tracking process are introduced, and another eight features are proposed in this paper to describe more notable aspects of the tracking process. All of them are extracted from the data of the firstKframes. They are simple but effective. The following “(k)” means the data at framek.
a) Features from response maps:The final response map
r(k)is the fusion of the convolution between the correlation filter αf(k) and the feature mapsZf(k) using (9) and (13). The higher the response map value is, the more similar the target and the shifted patch are. There are three traditional features from response maps. Since there is only training phase and no tracking phase at the first frame,r(1) does not exist.
i) Maximum value of response map:The location of the maximum value of the response map is the most possible location of the target. Its value is a directly related measurement for the tracking precision at one frame. Hence, the first feature we introduce is the summation of the maximum values of the firstKframes.

b) Features from correlation filters:The following features concentrate on the evaluation of the parameters of the tracker in the central region. The training and updating of discriminative model α(k) are the core of the whole tracking process.The filter values are activated in the regions that have significant discriminative features and mainly inhibited by the regularization terms in other regions. As most boundary effect alleviating methods aim to maintain the activated filter values in the central region, the featuresd4,d5,d6,d7are proposed to measure the quantity and the ratio of the activated values in the central region. Technically, the central region is inside the target bounding box.
i) Quantity and ratio of central extreme value points:In the visualization of the correlation filter, the curved surface around every peak is approximate to a 2D Gaussian function.The extreme point could be the representation of activation in its surrounding region. The extreme point (i,j) is the maximum point in the local 1 1×11 pixels satisfying
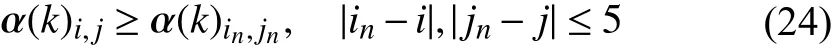
where α (k)i,jis the element of theith row and thejth column,andi,j,in,jnare positive integers.
The quantity and the proportion of the extreme points in the central region can represent the model activation from two aspects. The former is the activation degree in the central region and the latter is model attention on the central region.



c) Features from base samples:Features can also be extracted from training samples and tracking samples. The training samples should be clear, representative and properly different to facilitate the robust correlation filter. The tracking samples illustrate the complexity of the tracking process,because it is used to test the discriminative ability of model.
i) The difference of training samples and tracking samples:
The difference is a measure of the tracking complexity. It is defined as the difference between the last frame training sample feature mapA0,f(k-1) and the current frame tracking sample feature mapZf(k)


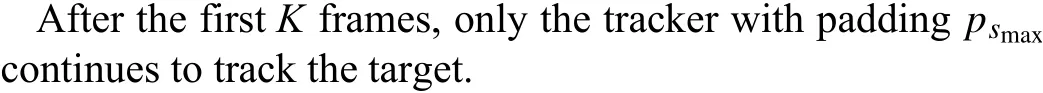
Remark 2:The proposed adaptive padding method uses data in the first several frames to make a desirable prediction of tracking precision. The CF based tracking process has two properties. a) The discriminative model is established at the first frame without any other prior information. b) Every frame tracked successfully is sampled to train a new model to update the old one. Since the model at the first frame is of vital importance, features of the model in the first several frames are noteworthy for the prediction of tracking performance.
D. The Adaptive Padding Tracker With Feature Group Fusion
The proposed tracker collects the tracking process data of the firstKframes, and selects the adaptive padding at frameK. The selected padding will be used in combination with feature group fusion over a video. To show the tracking processing more clearly, some functional pseudo code is given in Algorithm 1, where function “TRACK” is about the adaptive padding method and function “FUSIONUPDATE” is mainly about the feature group fusion.

Algorithm 1 Adaptive Padding Correlation Filter With Feature Group Fusion Require: Parameters in Table I, SVM model, scale pool ,padding pool , initial location at frame 1, video sequence Sscale P={ps,s ∈S} x1 Ensure: tracking results xk 1: function INITIALIZE( )x1 2: Crop the base samples with αf x1 3: Train the filters by the optimal problem (8)w 4: Initialize the feature group weight by (14)αmodel ←{αf,f ∈F} wmodel ←w 5: return ,6:αmodelwmodel xk-1 7: function TRACK( , , k, )k <K P ←P 8: if then k=K 9: else if then Ds 10: Construct from the previous tracking frames 11: Determine the best padding by (38)P ←{psmax}psmax 12:13: for do xk ← αmodelwmodel xk-1 ps ps ∈P 14: FUSIONUPDATE( , , , )15: return 16:xk 17: function FUSIONUPDATE( , , , )sscale ∈Sscale αmodelwmodel xk-1 ps 18: for do 19: Crop the base samples with , and rf αmodel xk-1 sscale ps 20: Compute responses by the filter and (9)w 21: Compute the weight and the final response r 22: by (12) and (13)sscale, xk 23: Determine by (18)xk αf 24: Crop at and train the filters by (8)αmodelwmodel rmax 25: Update , by and (16), (17)αmodelwmodel xk 26: return , ,
IV. ExPERIMENTS
In this section, the data collection for Section III-C is carried out on the Object Tracking Benchmark 2015 (OTB 2015[8]), and the evaluations of the proposed algorithms are carried out on the OTB 2015, the Visual Object Tracking 2018 Challenge (VOT2018 [9]) and the Benchmark and Simulator for UAV Tracking (UAV123 [39]). The proposed trackers are the feature group fusion tracker (FF), adaptive padding correlation filter (AP) and adaptive padding correlation filter with feature group fusion (APCF). For comparison, the basic tracker PSCA and other advanced trackers are also tested with proper parameters.
A. Implementation Details
1) Feature Selection:Color videos choose HOG, CN and HI as three feature groups. In gray videos, CN of one pixel becomes a 1-D grayscale feature instead of a 12-D color naming posterior probability vector. CN and HI combine into one feature group. In a word, gray images choose HOG and CN+HI as two feature groups.
2) Feature Extraction Parameters:HOG is extracted with 9 oriented bins, 18 non-oriented bins and a 4×4 cell size. The mapping matrix in [21] is used in transformation from RGB to CN. HI considers 1 2×12 neighborhood and 9 intensity bins.Note that, before HI extraction, Gamma correction with a parameter of 0.5 is carried out for the sample patch. HI is calculated in a 3×3 neighborhood after down sampling according to the cell size of HOG to reduce computation cost.
3) Tracker Parameters:The sample box scale pool is generated by adjusting the padding. The base sample with a padding of 2 is three times larger than the target bounding box. When the scale 0.85 is desired, padding is adjusted to fitp0.85+1=0.85×(2+1). If the scale is less than 1, offsets stay as far as the sample bounding box of the base sample.
The other parameters of the gray videos and color videos are the same as shown in Table I. In Table I,m1andm2refer to the width and the height of the target, respectively.

TABLE IPARAMETERS USED IN ALL ExPERIMENTS

All the parameters in our trackers are fixed for different benchmark datasets. The tracking performance prediction SVM model is trained by the data extracted from OTB 2015,where 60% positive samples and 30% negative samples are used to train. The experiments across three datasets demonstrate the robust performance of the proposed methods.
4) Hardware Environment: All trackers proposed in this paper and Staple run on the same workstation using MATLAB2018a with 3.0-GHz CPU and 16-GB memory. Accurate tracking by overlap maximization (accurate tracking by overlap maximization (ATOM) [30]) and discriminative model prediction with residual learning network ResNet-18 (DiMP18[31]) run on the workstation using 3.0-GHz CPU, 16-GB memory and GTX 1660. The results of other trackers are obtained from the raw results provided by the references.
B. Padding Setup and Data Collection
Based on the proposed tracker in Section III-B, seven trackers are obtained with different paddings in the pool. To generate enough samples for tracking performance prediction in Section III-C, the trackers are tested on the OTB 2015 [8].Besides the padding, the other parameters are given in Section IV-A.
1) Padding Pool:Padding is the multiple to scale up the target bounding box to the sample bounding box. The padding pool P is determined by the scale pool S of sample box relative to the standard sample box with the standard paddingpstd=2.

It should be noted that the other parameters corresponding to the target size are not changed, like the Gaussian label parameterσ.
2) Tracking Results, Data and Labels in the Pool:The performances of the seven trackers with different paddings are shown in Fig. 2. Obviously, the tracker with standard padding has the best performance from the perspective of all test videos. However, the standard padding can't be determined as the best padding for a specific video. There is still such a possibility that the blindly fixed padding is not desirable. It is necessary to analyze the tracking performance from each video. Table II shows the effect of the specific padding on several videos in the OTB 2015 dataset.
To make the effect more intuitive, only the videos where the effect of adaptive padding is easy to verify are listed in Table II.The bold terms refer that the corresponding scales have the best precision among all the scales in the pool and the terms on the last but third column represent the precision of the proposed tracker without adaptive padding. From Table II, it can be clearly seen that the padding selected properly instead of blindly leads to obvious improvement of the precision. In other words, the adaptive padding contributes to the tracking performance improvement when the tracker is given an unsatisfactory target box input.
Meanwhile, the data of trackers are collected, such as the base samples, the correlation filters and the response maps of the firstKframes, from the tracking process of seven trackers in 100 videos. 700 pieces of multi-channel time series are collected as samples. To learn the ability of tracking precision prediction, all 700 pieces of tracking precision are classified into two classes and labeled asYpred∈R700. One is given the label “1 ” when the precision is larger than or equal to 0.8 and the other is given label “ -1” when the precision is smaller than 0.8. For each piece of sample, the features mentioned in Section III-C are involved by a column vector. The data matrix is composed by the feature vectors of samples and is denoted byDpred∈R11×700.
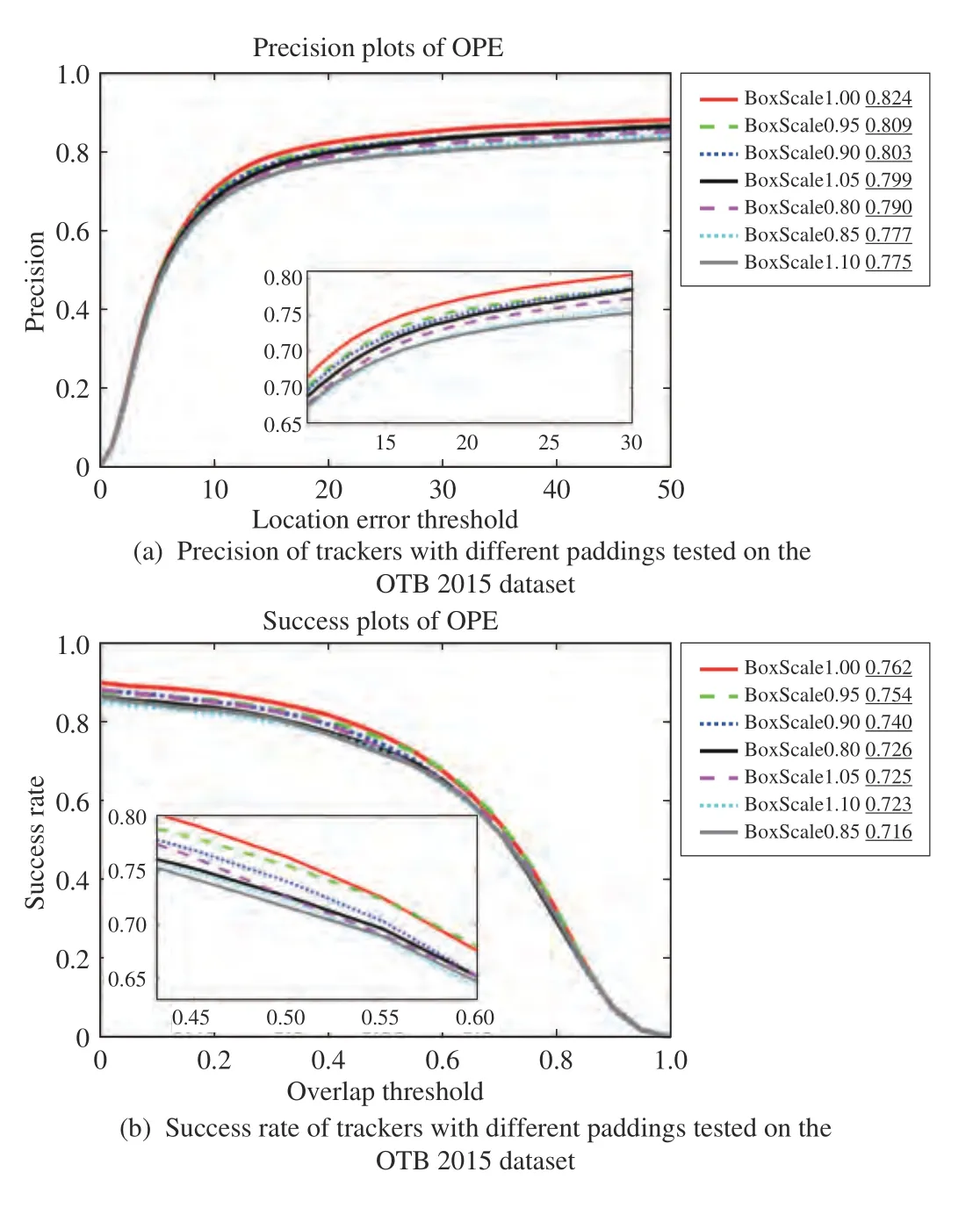
Fig. 2. Precision and success rate of trackers with different paddings tested on the OTB 2015 dataset. The definition of the two evaluation indices can be seen in Section IV-D. Simply speaking, if one curve is above the other everywhere, the tracker corresponding to the curve is better.
Remark 4:The ideal tracker should have good tracking performance of which the discrimination ability for the central region can deal with the diverse samples. For an example, in the manual adjustment of the padding for tracking human beings, one effective strategy is to use a small padding.Observing Table II, one can find that the tracker with the padding of 0.9 has good performance for the videos such as“Diving”, “Gym”, “Human2” and “Human6”. The padding makes the tracker focus more on the body, which is more stable than the limbs. In our work, the adaptive padding can be further determined by the machine learning method considering of the tracking process data including the performance at the level of response, the discrimination in the central region and the sample diversity. That is, the adaptive padding is determined by the predicted tracking precision.
Remark 5:The range of the sample box scale pool is determined by the experience of the parameter adjustment. To track a person, a tracker is more stable with a smaller sample box to exclude some unnecessary background information. To track a subregion, typically a poster on the wall, the tracker is more stable with larger sample box which contains more information, and whose location changes with the target. Extensive experiments show that the scale pool set as (41) can achieve the best performance.
C. Qualitative Analysis
Qualitative results are illustrated in Fig. 3, which shows the effectiveness of APCF compared with ATOM [30] and PSCA[17] using different snapshots taken from videos of the OTB 2015 benchmark and the UAV123 benchmark. Most of them are included in the results at the end of the video to show thesuccess of the tracking. Some of them are at the frame after tracking drift happens to show failure. APCF is better than ATOM in the situations where the region surrounding the target exists similar object. To further verify the effectiveness,the key frames in the video sequences “Box” and “Diving” are selected from the OTB 2015 for qualitative analysis.
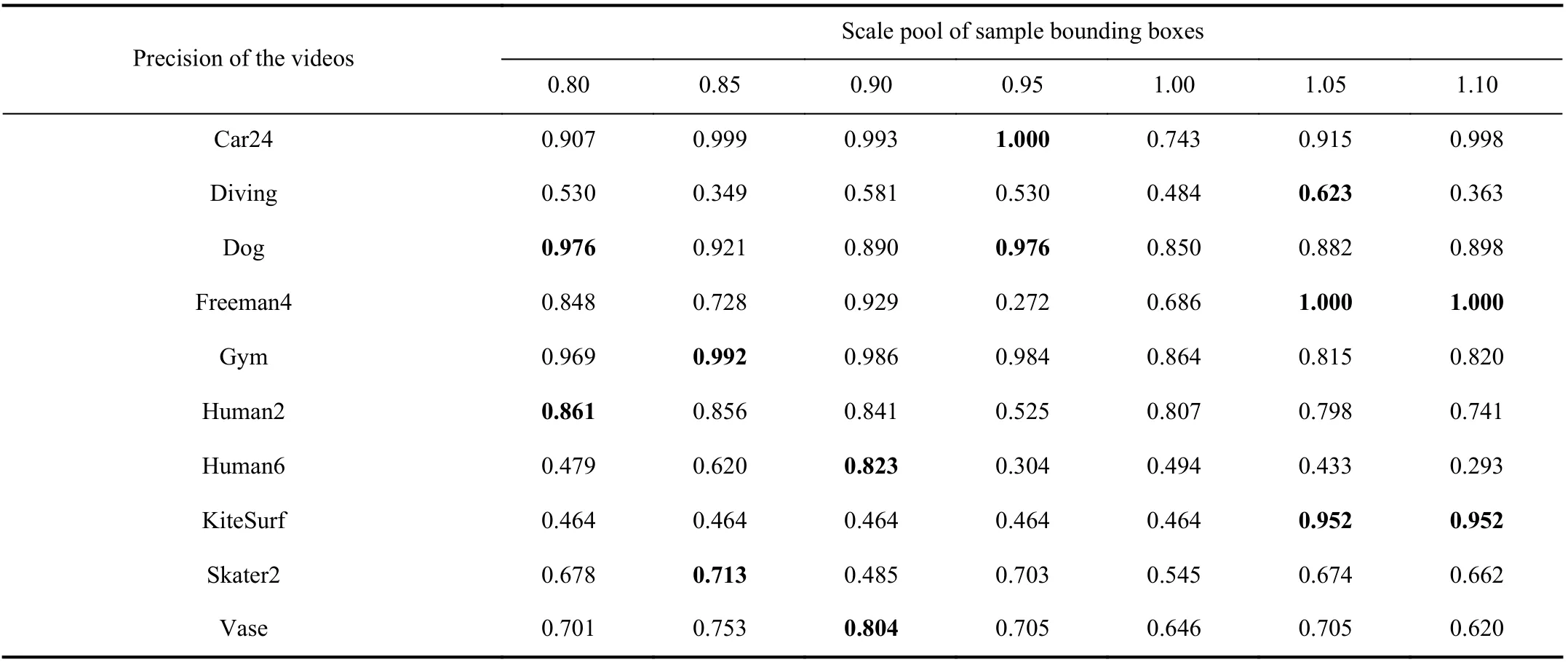
TABLE II TRACKING PRECISION WITH DIFFERENT PADDINGS. EACH ROW SHOWS THE EFFECT OF ADAPTIVE PADDING ON ONE SPECIFIC VIDEO

Fig. 3. Qualitative results for the proposed tracker (APCF), compared with the top-performing ATOM and PSCA. These pictures are taken from the videos of the OTB 2015 benchmark and the UAV123 benchmark. APCF outperforms PSCA usually and ATOM sometimes.
The challenging situations of the video “Box” includes illumination variation, occlusion, scale variation, out-of-plane rotation, out of view and background clutter. At the key frames in Fig. 4, these trackers perform well tracking. After the occlusion at 470th frame, PSCA does not consider the distraction of color features and the noisy samples in model updating, which leads to tracking drift. In contrary, the proposed APCF has good performance over the video sequence.
The challenging situations of the video “Diving” are scale variation, occlusion, deformation and in-plane rotation. It can be clearly seen from Fig. 5 that the three trackers can capture the diver at the take-off stage. When the diver completes a somersault in the air, PSCA fails to track. While, APCF focuses on the shoulder and the thigh of the diver and ATOM concentrates on the body and the thigh, which have good performance facing challenging situations.
D. Evaluation on the OTB 2015 Benchmark

Fig. 4. Qualitative results for the proposed tracker (APCF), compared with the top-performing ATOM and PSCA on the video “Box”.

Fig. 5. Qualitative results for the proposed tracker (APCF), compared with the top-performing ATOM and PSCA on the video “Diving”.
All trackers are evaluated by the two indices, precision and success rate, as defined in [8]. Precision is the index to measure the location error between the tracking bounding box and the ground truth bounding box. In the precision plots, the accepted error for tracking is varied along thex-axis and the percentage of successful tracking is plotted on they-axis whose error is less than the threshold. 20 pixels is the common accepted error to evaluate precision rank. Success rate measures the intersection over the union of the tracking bounding box and the ground truth bounding box. In the success rate plots, the minimum allowed overlap is varied onx-axis and the percentage of successful tracking is plotted ony-axis.
The proposed trackers are the feature group fusion tracker(FF), adaptive padding correlation filter (AP) and adaptive padding correlation filter with feature group fusion (APCF).The counterpart trackers are PSCA [17], the sum of the template and pixel-wise learners (Staple [40]), SRDCF [13],SRDCF with convolutional features (DeepSRDCF [41]), fullyconvolutional Siamese network (SiamFC [42]), convolutional residual learning tracking (CREST [43]), hierarchical convolutional features tracking (HCFTs [44]), ATOM [30] and DiMP18 [31]. PSCA is the basic tracker for the proposed trackers. All trackers are discriminative model based trackers.Tracking performance is reported in one-pass evaluation(OPE), utilizing precision plots and success rate plots.
1) Evaluation on all Videos:Fig. 6 shows the comparison on tracking performance of the proposed trackers and the counterparts on 100 video sequences of the OTB 2015. The tracker APCF running on the CPU outperforms the six stateof-the-art trackers and is competitive with other three trackers.APCF achieves the performance in this experiment with a precision of 85.1% and a success rate of 78.4%. It should be noted that the adaptive padding determined by the precision prediction model also benefits in the improvement of performance on overlap.
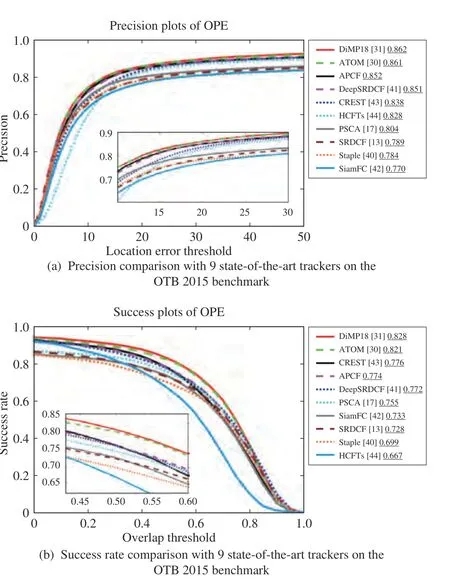
Fig. 6. Tracking performance of the proposed trackers and 9 state-of-the-art trackers on the OTB 2015 benchmark.
The tracking speed is evaluated in Table III. “G” indicates that the tracker is running on the GPU. ATOM and DiMP18 are tested on the GTX 1660 for algorithm validation. The others are directly obtained from the referenced paper with workstation using the GTX Titan.
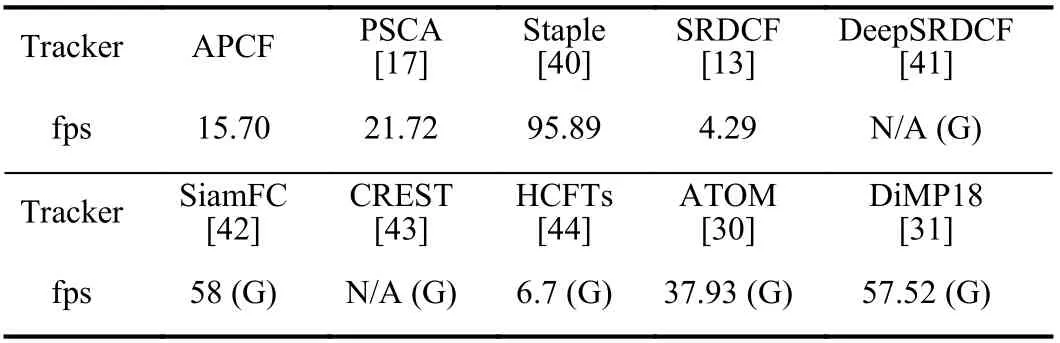
TABLE III RUNNING SPEED (IN FRAME/S) ON THE 100 VIDEO SEQUENCES OF THE OTB 2015 BENCHMARK
APCF runs quasi real-time (more than 15 fps) with the competitive precision and success rate on CPU. At the firstKframes, APCF tracks the object with seven scale factorssscaleand seven paddingspswhile PSCA just usessscale. This leads to a lower speed than PSCA. APCF is faster than SRDCF because the padding of SRDCF is set as 4 and the sample patch is about 5/3 times larger than that of APCF. The more parameters that need to be determined and the more features that need to be extracted from the larger sample patch increase the computation cost of the tracker.
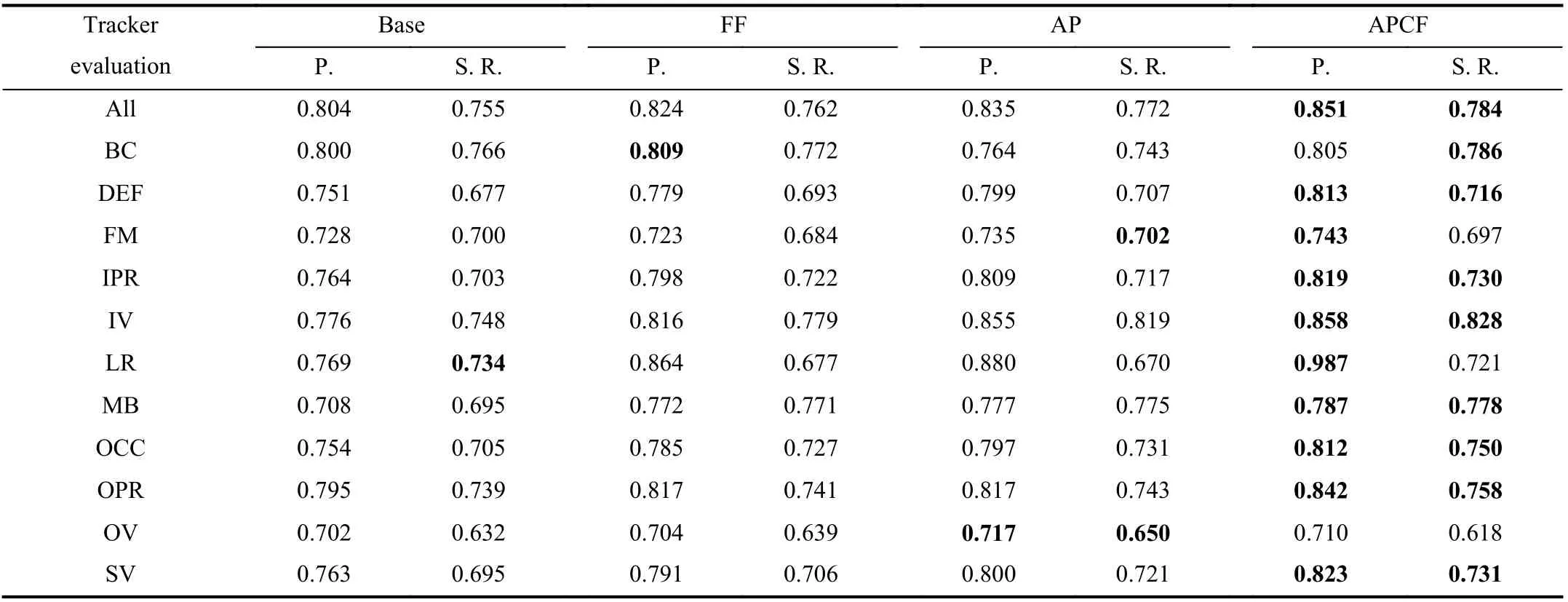
TABLE IVTRACKING PERFORMANCE OF THE PROPOSED TRACKERS IN ABLATION STUDy ON THE OTB 2015 BENCHMARK
2) Evaluations on the Ablation Study and Attributed Videos:The proposed algorithm contains feature group fusion and adaptive padding in the CA framework. In order to verify the contribution of each component, the performance of FF, AP,and APCF are compared in the degree of ablation analysis.The results of OTB 2015 benchmark are listed in Table IV,where the challenging situations are background clutter (BC),deformation (DEF), fast motion (FM), in-plane rotation (IPR),illumination variation (IV), low resolution (LR), motion blur(MB), occlusion (OCC), out-of-plane rotation (OPR), out-ofview (OV) and scale variation (SV).
In Table IV, “P.” and “S. R.” represent the precision and success rate, respectively. The bold numbers represent the best evaluation indices of the challenging situations. Based on the basic algorithm, AP and FF show better performance on the OTB 2015 benchmark. APCF has the best precision and success rate over the 100 videos and improves the performance in almost all challenging situations except for BC and OV. The experimental results indicate that the two components contribute to the tracker performance.
From the challenging situation perspective, the precision increase in the low resolution situation is much more than the average of 4.7%. In the nine videos in low resolution situations, only “Car1” and “Walking” change the padding less than 1.0. The small objects (both sides are about 30 pixel length) obtain large padding, whether they are the part of the big object or the intact target.
The average padding of the 100 videos is 0.948 and the average paddings of each situation are near to this value. The paddings are almost uniform in the three intervals [0.8, 0.85],[0.9, 1] and [1.05, 1.1]. This result represents that the best padding according to the tracking precision prediction model is not seriously related to several main challenging situations on OTB 2015. The improvement of the precision performance is mainly due to the padding adaptive to object shapes,Gamma correction of HI to eliminate the problem of small intensity and feature group fusion to alleviate the single feature distraction.
Two experiments are carried out to further analyze the tracking precision prediction model. One is for the features used in tracking precision prediction. The other one is for the influence of differentK. The tracking precision results are listed in Tables V and VI.

TABLE V TRACKING PERFORMANCE OF APCF IN ABLATION STUDy FOR DIFFERENT FEATURES USED IN THE TRACKING PRECISION PREDICTION MODEL ON THE OTB 2015 BENCHMARK

TABLE VI TRACKING PERFORMANCE OF APCF IN ABLATION STUDy FOR DIFFERENT K FRAMES USED IN THE TRACKING PRECISION PREDICTION MODEL ON THE OTB 2015 BENCHMARK
Table V shows the tracking precision of trackers with the prediction models using different features.d1,d2,d3are the features from response maps.d4,d5,d6,d7are the description about the distribution of the filter parameters.d8,d9,d10,d11are the features of the base samples. From Table V, one can find that the more features used in the tracking precision prediction, the better the tracking performance.
The results of the experiment for the influence ofKare listed in Table VI. When using the average to represent the information from the firstKframes, frames of too long or too short time result in the decline of tracking precision. On the one hand, the reason might be that the moving average tracker does not match the average feature, that is, a better attention mechanism is needed to process the information of the firstKframes. On the other hand, the proposed features might confuse the estimation of tracking precision when extracting information for a period of long time. APCF with 5 or 10 frames used in tracking precision prediction has the best two performance on the OTB 2015 benchmark.
E. Evaluation on the VOT2018 Challenge
To further confirm the validity across different datasets,APCF is compared with some state-of-the-art trackers on the VOT2018 challenge [9] without parameter adjustment. The counterparts consist of 1) basic trackers: structured output tracking with kernels (Struck [45]), kernelized correlation filters (KCF [11]), discriminative scale space tracking (DSST[46]); 2) advanced trackers with traditional features: SRDCF[13], Staple [40], PSCA [17], FF; 3) advanced trackers with convolutional features: SRDCF with convolutional features(DeepSRDCF [41]), CSRDCF [47] with convolutional features (DeepCSRDCF), learning adaptive discriminative correlation filters (LADCF [14]), ATOM [30]; 4) trackers based on Siamese network: SiamFC [42], DiMP18 [31], visual tracking with Siamese region proposal network (SiamRPN [48]) and 5)multi-resolution fusion tracker: efficient convolution operators for tracking (ECO [19]), and convolutional features for correlation filters (CFCF [49]). There are three kinds of performance measures.
1) Accuracy: The accuracy is the average overlap between the bounding box predicted by the tracker and the ground truth bounding box in all successful tracking frames.
2) Robustness: The robustness measures failure times during tracking. A failure is indicated when the ground truth and the proposed bounding box have no intersection parts. Thexaxis can be explained as the probability of success for tracking 100 consecutive frames.
3) Expected Average Overlap: The expected average overlap (EAO) is related to accuracy and robustness to rank the trackers. After initialization, the overlap of consecutive frames longer than a certain number is collected to calculate the EAO. EAO measures the average overlap in the successful one-pass tracking process.
The VOT2018 challenge has a special methodology to reduce the bias in performance measures. The tracker is re-initialized five frames after failure to reduce the bias in robustness measure. To improve the validity of accuracy measure,ten frames after re-initialization are ignored in computation.
Fig. 7 shows that the proposed methods outperform most advanced trackers with traditional features and all basic algorithms, and are competitive with SiamFC without a GPU workstation. APCF improves the performance based on the basic tracker PSCA. Because of the good representation ability of deep networks, the trackers based on Siamese networks and multi-resolution fusion tracker have higher accuracy and robustness with a GPU workstation.
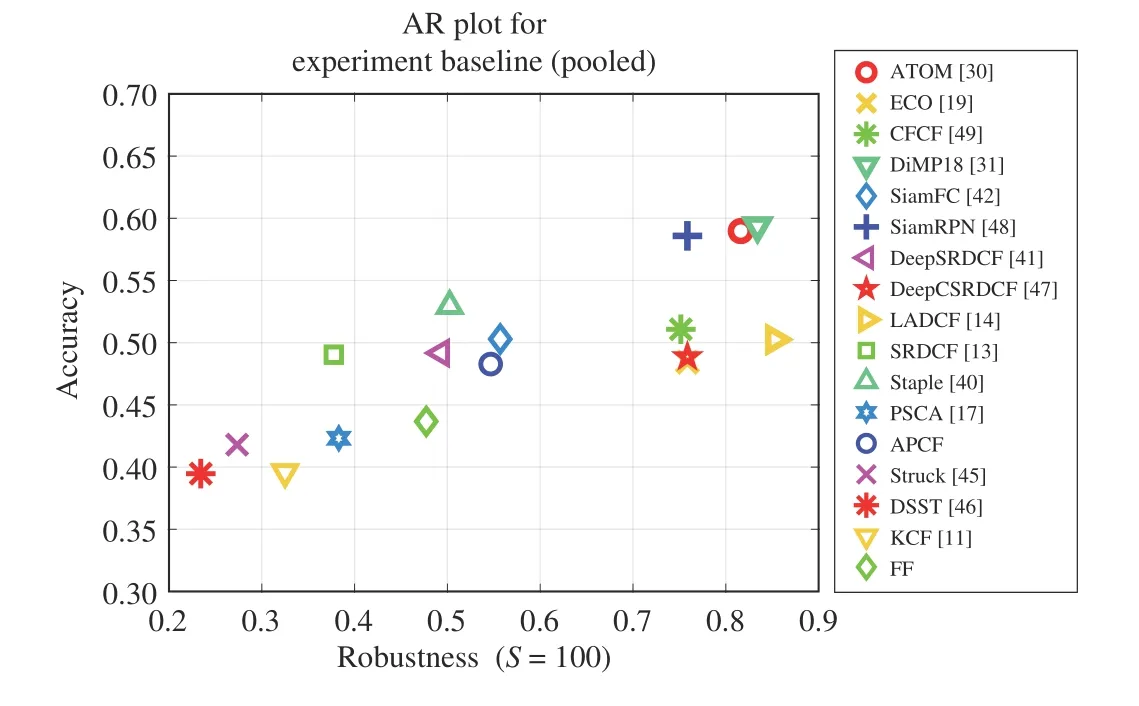
Fig. 7. Accuracy-Robustness plot on the 60 videos on the VOT2018 dataset.
With regards to accuracy, APCF achieves 4 8.28%, which is better than FF (4 3.67%) , PSCA (4 2.31%) , Struck (4 1.80%),KCF (3 9.59% ) and DSST (3 9.47%). Its accuracy is close to SRDCF (4 9.03%) , DeepSRDCF (4 9.17%) and SiamFC(5 0.29%).
Considering the robustness, APCF is 54.66% withS=100.00 , which is better than Staple (5 0.24%), DeepSRDCF(4 9.31% ), FF (4 7.72% ), PSCA (3 8.29%) , SRDCF (3 7.76%),KCF (3 2.50% ), Struck (2 7.33% ) and DSST (2 3.42%). Its robustness is 1.85% less than SiamFC (5 5.69%).
The EAOs of different trackers are shown in Fig. 8. The proposed tracker achieves larger average expected overlap compared to all advanced trackers with traditional features and basic trackers except Staple.
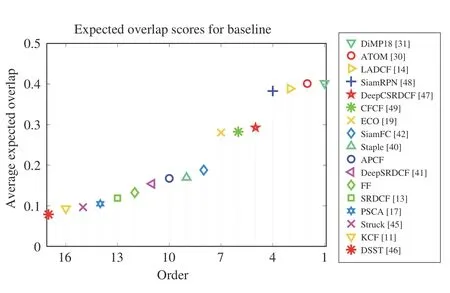
Fig. 8. Expected overlaps on the 60 videos on the VOT2018 dataset.
The AR plot and EAO of Staple are obtained from the referred raw results of the VOT2018 challenge [9]. This version of Staple is adapted for VOT2018. However, the proposed trackers perform well on different datasets while using the same parameters and the same tracking performance prediction SVM model. In a word, the accuracy and the robustness of APCF are better than advanced trackers with traditional features and basic trackers, and are competitive to SiamFC across the different datasets.
F. Evaluation on the UAV123 Benchmark
In this part, APCF is compared with DiMP18 [31], ATOM[30], SiamFC [42], HCFTs [44], automatic spatio-temporal regularization filter (AutoTrack [29]), spatial-temporal regularized correlation filter (STRCF [50]), SRDCF [13], Staple[40], PSCA [17] and SAMF [10] on the Benchmark and Simulator for UAV Tracking (UAV123 [39]). The benchmark includes 123 videos from an aerial viewpoint and provides upright bounding boxes. The evaluation indices are taken as precision and success rates which are the same with the indices on OTB 2015. Fig. 9 shows the performance comparison. Although without deep learning features and GPU workstations, APCF shows competitive performance compared with state-of-the-art trackers except ATOM and DiMP18. The performance is effectively improved from FF and PSCA.Through three experiments on these datasets, it is verified that the performance of APCF is competitive and stable across different datasets.
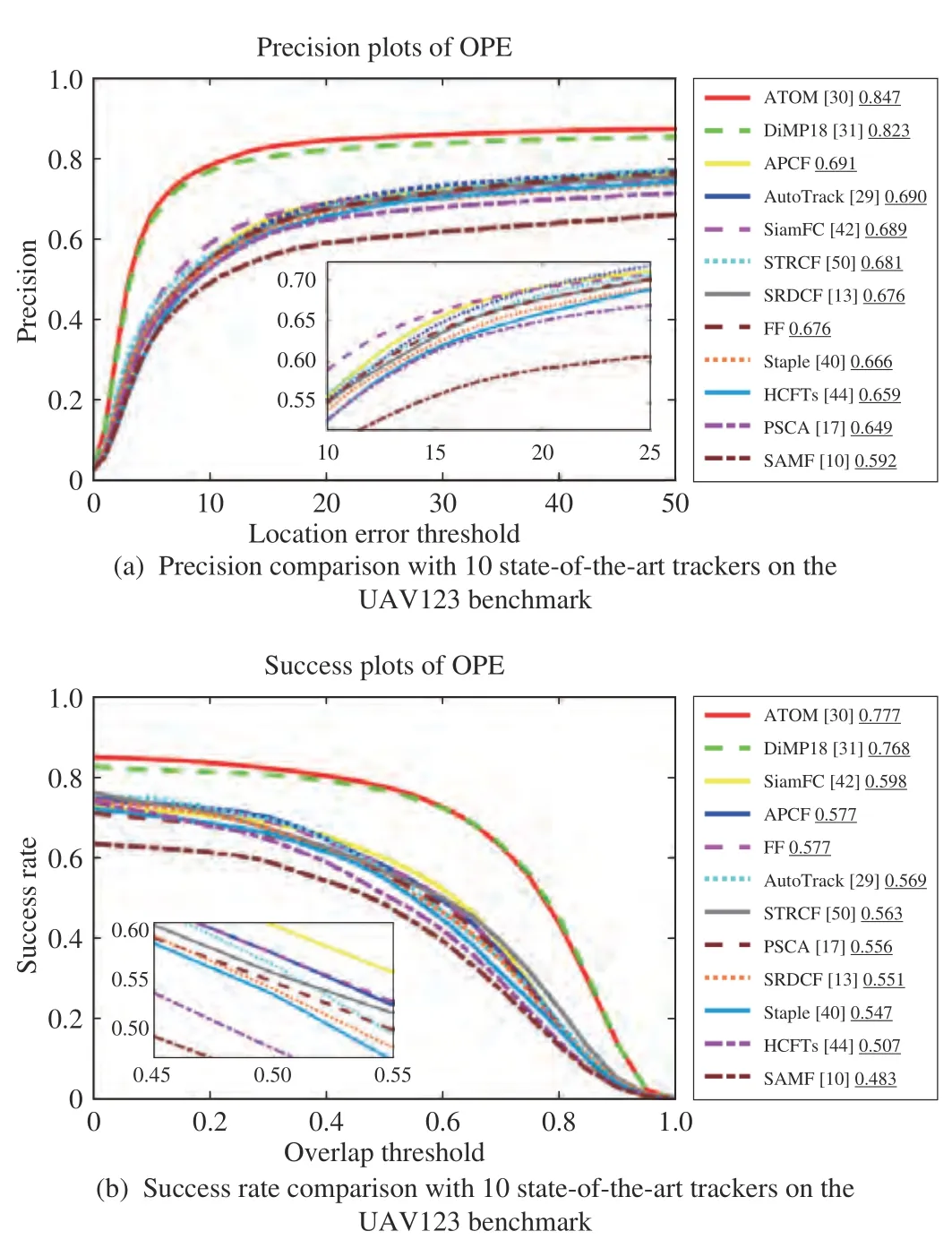
Fig. 9. Tracking performance of the proposed trackers and 10 state-of-theart trackers on the UAV123 benchmark.
V. CONCLUSIONS
This paper presented a novel adaptive padding correlation filter with feature group fusion for robust visual tracking. The powerful feature groups such as HOG, CN and HI are dynamically fused to further boost the robustness in more compli-cated situations. The fused response resists the bad effects caused by single group of features and achieves satisfactory tracking results. Moreover, an SVM model predicts tracking performance of trackers in the preset pool and selects the adaptive padding to include the proper negative samples for the filter training to track different objects. Extensive experimental results on the three benchmark datasets demonstrate the effectiveness and robustness of the proposed algorithm against the state-of-the-art trackers. The proposed APCF outperforms the trackers in various challenging situations and achieved a precision of 0.851 on the OTB 2015 dataset at quasi real-time speed. On the OTB 2015, VOT2018 and UAV123, APCF has a stable improvement compared to the basic trackers and outperforms the advanced trackers with traditional features.
For future works, there are still some topics to explore.Some layers of the Siamese networks have similar functions as the correlation filter. Since the great representation ability of deep learning is verified by many applications, the padding modification of alleviating the boundary effect in this paper is valuable and can be extended to deep learning tracking. The proposed algorithm running at quasi real-time speed has potential value in many application fields, such as video surveillance, autonomous driving and target tracking.
[1]A. W. Smeulders, D. M. Chu, R. Cucchiara, S. Calderara, A. Dehghan,and M. Shah, “Visual tracking: An experimental survey,”IEEE Trans.Pattern Analysis and Machine Intelligence, vol. 36, no. 7, pp. 1442–1468, 2013.
[2]X. Yuan, L. Kong, D. Feng, and Z. Wei, “Automatic feature point detection and tracking of human actions in time-of-flight videos,”IEEE/CAA J. Autom. Sinica, vol. 4, no. 4, pp. 677–685, 2017.
[3]J. H. White and R. W. Beard, “An iterative pose estimation algorithm based on epipolar geometry with application to multi-target tracking,”IEEE/CAA J. Autom. Sinica, vol. 7, no. 4, pp. 942–953, 2020.
[4]M. Zhang, X. Liu, D. Xu, Z. Cao, and J. Yu, “Vision-based targetfollowing guider for mobile robot,”IEEE Trans. Industrial Electronics,vol. 66, no. 12, pp. 9360–9371, 2019.
[5]Y. Liu, Z. Meng, Y. Zou, and M. Cao, “Visual object tracking and servoing control of a nano-scale quadrotor: System, algorithms, and experiments,”IEEE/CAA J. Autom. Sinica, vol. 8, no. 2, pp. 344–360,2021.
[6]I. Ahmed, S. Din, G. Jeon, F. Piccialli, and G. Fortino, “Towards collaborative robotics in top view surveillance: A framework for multiple object tracking by detection using deep learning,”IEEE/CAA J.Autom. Sinica, vol. 8, no. 7, pp. 1253–1270, 2021.
[7]C. Ma, J. Huang, X. Yang, and M. Yang, “Robust visual tracking via hierarchical convolutional features,”IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 41, no. 11, pp. 2709–2723, 2018.
[8]Y. Wu, J. Lim, and M. Yang, “Object tracking benchmark,”IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 37, no. 9, pp.1834–1848, 2015.
[9]M. Kristan, A. Leonardis, J. Matas,et al., “ The 6th visual object tracking VOT2018 challenge results,” inProc. European Conf.Computer Vision, Springer, 2018, pp. 3-53.
[10]Y. Li and J. Zhu, “A scale adaptive kernel correlation filter tracker with feature integration,” inProc. European Conf. Computer Vision,Springer, 2014, pp. 254–265.
[11]J. F. Henriques, R. Caseiro, Martins, and J. Batista, “High-speed tracking with kernelized correlation filters,”IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 37, no. 3, pp. 583–596, 2014.
[12]Y. Sui, G. Wang, and L. Zhang, “Correlation filter learning toward peak strength for visual tracking,”IEEE Trans. Cybernetics, vol. 48, no. 4,pp. 1290–1303, 2017.
[13]M. Danelljan, G. Hager, F. Shahbaz Khan, and M. Felsberg, “Learning spatially regularized correlation filters for visual tracking,” inProc.IEEE Int. Conf. Computer Vision, 2015, pp. 4310-4318.
[14]T. Xu, Z. Feng, X. Wu, and J. Kittler, “Learning adaptive discriminative correlation filters via temporal consistency preserving spatial feature selection for robust visual object tracking,”IEEE Trans. Image Processing, vol. 28, no. 11, pp. 5596–5609, 2019.
[15]G. Zhu, Z. Zhang, J. Wang, Y. Wu, and H. Lu, “Dynamic collaborative tracking,”IEEE Trans. Neural Networks and Learning Systems, vol. 30,no. 10, pp. 3035–3046, 2019.
[16]M. Mueller, N. Smith, and B. Ghanem, “Context-aware correlation filter tracking,” inProc. IEEE Conf. Computer Vision and Pattern Recognition, 2017, pp. 1396-1404.
[17]T. Bouraffa, L. Yan, Z. Feng, B. Xiao, Q. M. J. Wu, and Y. Xia,“Context-aware correlation filter learning toward peak strength for visual tracking,”IEEE Trans. Cybernetics, vol. 51, no. 10, pp. 5105–5115,2021.
[18]C. Ma, J.-B. Huang, X. Yang, and M.-H. Yang, “Adaptive correlation filters with long-term and short-term memory for object tracking,”Int.J. Computer Vision, vol. 126, no. 8, pp. 771–796, 2018.
[19]M. Danelljan, G. Bhat, F. Shahbaz Khan, and M. Felsberg, “ECO:Efficient convolution operators for tracking,” inProc. IEEE Conf.Computer Vision and Pattern Recognition, 2017, pp. 6638-6646.
[20]D. S. Bolme, J. R. Beveridge, B. A. Draper, and Y. M. Lui, “Visual object tracking using adaptive correlation filters,” inProc. IEEE Computer Society Conf. Computer Vision and Pattern Recognition,2010, pp. 2544-2550.
[21]J. Van De Weijer, C. Schmid, J. Verbeek, and D. Larlus, “Learning color names for real-world applications,”IEEE Trans. Image Processing, vol. 18, no. 7, pp. 1512–1523, 2009.
[22]S. Liu, S. Wang, X. Liu, C. T. Lin, and Z. Lv, “Fuzzy detection aided real-time and robust visual tracking under complex environments,”IEEE Trans. Fuzzy Systems, vol. 29, no. 1, pp. 90–102, 2021.
[23]S. Liu, C. Guo, F. Al-Turjman, K. Muhammad, and V. H. C. de Albuquerque, “Reliability of response region: A novel mechanism in visual tracking by edge computing for IIOT environments,”Mechanical Systems and Signal Processing, vol. 138, pp. 1–15, 2020.
[24]M. K. Rapuru, S. Kakanuru, M. Venugopal, D. Mishra, and G. R. S.Subrahmanyam, “ Correlation-based tracker-level fusion for robust visual tracking,”IEEE Trans. Image Processing, vol. 26, no. 10, pp. 4832–4842, 2017.
[25]Q. Guo, W. Feng, C. Zhou, R. Huang, L. Wan, and S. Wang, “Learning dynamic siamese network for visual object tracking,” inProc. IEEE Int.Conf. Computer Vision, 2017, pp. 1763-1771.
[26]Q. Guo, R. Han, W. Feng, Z. Chen, and L. Wan, “Selective spatial regularization by reinforcement learned decision making for object tracking,”IEEE Trans. Image Processing, vol. 29, pp. 2999–3013, 2999.
[27]W. Feng, R. Han, Q. Guo, J. Zhu, and S. Wang, “Dynamic saliencyaware regularization for correlation filter-based object tracking,”IEEE Trans. Image Processing, vol. 28, no. 7, pp. 3232–3245, 2019.
[28]R. Han, Q. Guo, and W. Feng, “Content-related spatial regularization for visual object tracking,” inProc. IEEE Int. Conf. Multimedia and Expo, 2018, pp. 1-6.
[29]Y. Li, C. Fu, F. Ding, Z. Huang, and G. Lu, “Autotrack: Towards highperformance visual tracking for UAV with automatic spatio-temporal regularization,” inProc. IEEE Conf. Computer Vision and Pattern Recognition, 2020, pp. 11920-11929.
[30]M. Danelljan, G. Bhat, F. S. Khan, and M. Felsberg, “ATOM: Accurate tracking by overlap maximization,” inProc. IEEE Conf. Computer Vision and Pattern Recognition, 2019, pp. 4655-4664.
[31]G. Bhat, M. Danelljan, L. Van Gool, and R. Timofte, “Learning discriminative model prediction for tracking,” inProc. IEEE Int. Conf.Computer Vision, 2019, pp. 6181-6190.
[32]M. Danelljan, L. Van Gool, and R. Timofte, “Probabilistic regression for visual tracking,” inProc. IEEE Conf. Computer Vision and Pattern Recognition, 2020, pp. 7181-7190.
[33]A. Lukežič, J. Matas, and M. Kristan, “D3S a discriminative single shot segmentation tracker,” inProc. IEEE Conf. Computer Vision and Pattern Recognition, 2020, pp. 7131-7140.
[34]C. Ma, X. Yang, C. Zhang, and M.-H. Yang, “Long-term correlation tracking,” inProc. IEEE Conf. Computer Vision and Pattern Recognition, 2015, pp. 5388-5396.
[35]X. Wang, Z. Hou, W. Yu, L. Pu, Z. Jin, and X. Qin, “Robust occlusionaware part-based visual tracking with object scale adaptation,”Pattern Recognition, vol. 81, pp. 456–470, 2018.
[36]M. Guan, C. Wen, S. Mao, C.-L. Ng, and Y. Zou, “Real-time eventtriggered object tracking in the presence of model drift and occlusion,”IEEE Trans. Industrial Electronics, vol. 66, no. 3, pp. 2054–2065, 2019.
[37]J. Choi, H. Jin Chang, S. Yun, T. Fischer, Y. Demiris, and J. Young Choi, “Attentional correlation filter network for adaptive visual tracking,” inProc. IEEE Conf. Computer Vision and Pattern Recognition,2017, pp. 4807-4816.
[38]J. Lopez and J. R. Dorronsoro, “Simple proof of convergence of the SMO algorithm for different SVM variants,”IEEE Trans. Neural Networks and Learning Systems, vol. 23, no. 7, pp. 1142–1147, 2012.
[39]M. Mueller, N. Smith, and B. Ghanem, “A benchmark and simulator for UAV tracking,” inProc. European Conf. Computer Vision, Springer,2016, pp. 445-461.
[40]L. Bertinetto, J. Valmadre, S. Golodetz, O. Miksik, and P. H. Torr,“Staple: Complementary learners for real-time tracking,” inProc. IEEE Conf. Computer Vision and Pattern Recognition, 2016, pp. 1401-1409.
[41]M. Danelljan, G. Hager, F. Shahbaz Khan, and M. Felsberg,“Convolutional features for correlation filter based visual tracking,” inProc. IEEE Int. Conf. Computer Vision Workshops, 2015, pp. 58-66.
[42]L. Bertinetto, J. Valmadre, J. F. Henriques, A. Vedaldi, and P. H. S.Torr, “Fully-convolutional siamese networks for object tracking,” inProc. European Conf. Computer Vision Workshops, 2016, pp. 850-865.
[43]Y. Song, C. Ma, L. Gong, J. Zhang, R. W. H. Lau, and M. Yang,“CREST: Convolutional residual learning for visual tracking,” inProc.IEEE Int. Conf. Computer Vision, 2017, pp. 2574-2583.
[44]C. Ma, J. Huang, X. Yang, and M. Yang, “Robust visual tracking via hierarchical convolutional features,”IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 41, no. 11, pp. 2709–2723, 2019.
[45]S. Hare, S. Golodetz, A. Saffari, V. Vineet, M. Cheng, S. L. Hicks, and H. S. Torr, “Struck: Structured output tracking with kernels,”IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 38, no. 10, pp. 2096–2109, 2016.
[46]M. Danelljan, G. Häger, F. S. Khan, and M. Felsberg, “Discriminative scale space tracking,”IEEE Trans. Pattern Analysis and Machine Intelligence, vol. 39, no. 8, pp. 1561–1575, 2017.
[47]A. Lukezic, T. Vojír, L. C. Zajc, J. Matas, and M. Kristan,“Discriminative correlation filter with channel and spatial reliability,” inProc. IEEE Conf. Computer Vision and Pattern Recognition, 2017, pp.6309-6318.
[48]B. Li, J. Yan, W. Wu, Z. Zhu, and X. Hu, “High performance visual tracking with siamese region proposal network,” inProc. IEEE Conf.Computer Vision and Pattern Recognition, 2018, pp. 8971-8980.
[49]E. Gundogdu and A. A. Alatan, “Good features to correlate for visual tracking,”IEEE Trans. Image Processing, vol. 27, no. 5, pp. 2526–2540,2018.
[50]F. Li, C. Tian, W. Zuo, L. Zhang, and M.-H. Yang, “Learning spatialtemporal regularized correlation filters for visual tracking,” inProc.IEEE Conf. Computer Vision and Pattern Recognition, 2018, pp.4904-4913.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- A Survey of Output Feedback Robust MPC for Linear Parameter Varying Systems
- Evaluation of the Effect of Multiparticle on Lithium-Ion Battery Performance Using an Electrochemical Model
- Geometric-Spectral Reconstruction Learning for Multi-Source Open-Set Classification With Hyperspectral and LiDAR Data
- Push-Sum Based Algorithm for Constrained Convex Optimization Problem and Its Potential Application in Smart Grid
- A Domain-Guided Model for Facial Cartoonlization
- S2-Net: Self-Supervision Guided Feature Representation Learning for Cross-Modality Images