Structured Sparse Coding With the Group Log-regularizer for Key Frame Extraction
2022-10-26ZhenniLiYujieLiBenyingTanShuxueDingandShengliXie
Zhenni Li, Yujie Li, Benying Tan, Shuxue Ding,, and Shengli Xie,
Abstract—Key frame extraction based on sparse coding can reduce the redundancy of continuous frames and concisely express the entire video. However, how to develop a key frame extraction algorithm that can automatically extract a few frames with a low reconstruction error remains a challenge. In this paper, we propose a novel model of structured sparse-codingbased key frame extraction, wherein a nonconvex group log-regularizer is used with strong sparsity and a low reconstruction error. To automatically extract key frames, a decomposition scheme is designed to separate the sparse coefficient matrix by rows. The rows enforced by the nonconvex group log-regularizer become zero or nonzero, leading to the learning of the structured sparse coefficient matrix. To solve the nonconvex problems due to the log-regularizer, the difference of convex algorithm (DCA) is employed to decompose the log-regularizer into the difference of two convex functions related to the l1 norm, which can be directly obtained through the proximal operator. Therefore, an efficient structured sparse coding algorithm with the group log-regularizer for key frame extraction is developed, which can automatically extract a few frames directly from the video to represent the entire video with a low reconstruction error. Experimental results demonstrate that the proposed algorithm can extract more accurate key frames from most SumMe videos compared to the stateof-the-art methods. Furthermore, the proposed algorithm can obtain a higher compression with a nearly 18% increase compared to sparse modeling representation selection (SMRS) and an 8% increase compared to SC-det on the VSUMM dataset.
I. INTRODUCTION
KEY frame extraction, which selects a small set of the most representative frames for a specific video sequence,plays an important role in robotics and computer vision[1]–[3]. The sparse-coding-based key frame extraction framework can extract a few (sparse) frames while preserving the essential content of the original video [4]–[7]. In the model of sparse-coding-based key frame extraction, the sparse coefficient matrix is required to learn, and thus the original video can be expressed as a linear combination of a few selected key frames [6], [8], [9]. The fewer non-zero elements of the sparse coefficient matrix, the more compressed key frames with less redundant information that can be extracted to reconstruct the entire video. Hence, the sparsity, i.e., the number of zero coefficients, is an important indicator of effectiveness in sparsecoding-based key frame extraction.
Although sparse-coding-based key frame extraction has recently attracted increased attention, it faces two challenging issues. The first is how to choose a suitable sparsity regularization for selecting fewer (sparser) frames that approximate the video frames with a low reconstruction error. The second is how to reliably and automatically select key frames because general sparse coding lacks structure information.


Existing studies [9]–[12], [16] have shown that it is difficult to reliably and automatically select the key frames according to the obtained sparse coding coefficients because they lack structure information [20], [21]. In reality, the extracted key frames based on sparse coding are expected to correspond to the rows of the coefficient matrix, which requires the structured sparsity.
To tackle the above two issues, we design a novel sparsecoding-based key frame extraction model that can consider suitable sparsity regularization and structure information simultaneously. The hinge point between suitable sparsity regularization and structure information is the nonconvex group sparsity. In this study, a nonconvex group log-regularizer is introduced to formulate the model of structured sparse-coding-based key frame extraction, wherein thel2norm is used for each group, and the log function [22] is used between groups to zero out groups with a strong sparsity and low reconstruction error (Fig. 1(b)). To automatically extract the key frames, a decomposition scheme is introduced to separate the sparse coefficient matrix by rows, and each row is arranged as a group. The rows in the sparse coefficient matrix enforced by the nonconvex group log-regularizer will become zero or nonzero, leading to learning the structured sparse coefficient matrix in Fig. 1(b) (the matrix in Fig. 1(a) is a nonstructured sparse matrix). The indices of the selected key frames can be estimated automatically according to the nonzero rows in the learned structured sparse coefficient matrix, without additional operators. Based on the decomposition scheme, the entire optimization problem is transformed into a set of subproblems with respect to the groups. Furthermore, to solve the nonconvex subproblems arising from the nonconvex log-regularizer, the difference of convex algorithm (DCA) [23], [24] is employed, wherein the nonconvex function is decomposed into the difference of two convex functions. Specifically, the log-regularizer is decomposed into the difference of two functions related to thel1norm. Thus,solving the subproblems can be reduced to the proximal operator which can obtain the closed-form solutions directly.Hence, we develop an efficient DCA-based structured sparse coding with the group log-regularizer (DSSC-log) algorithm for key frame extraction. The proposed algorithm for key frame extraction can not only automatically obtain fewer (i.e.,sparser) key frames, but also improve the accuracy of the estimations with less reconstruction error. Experimental results on real-world datasets demonstrate that the proposed algorithm performs favorably compared to thel1norm algorithm SMRS(sparse modeling representation selection) [10] and the determinant method SC-det (sparse coding with the determinant constraint) [16].
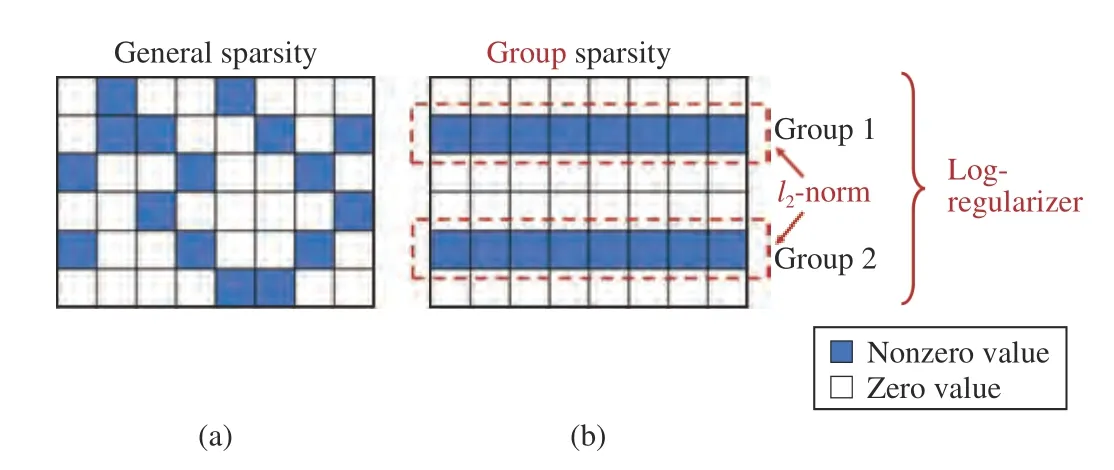
Fig. 1. Sparse matrix with general sparsity and group sparsity. (a) Nonstructured sparse matrix; (b) Structured sparse matrix, it has group sparsity(all the rows of the matrix are zero or nonzero).
To the best of our knowledge, this is the first study that tackles structured sparse-coding-based key frame extraction employing the group log-regularizer using the DCA method.Our contributions can be summarized as follows:
1) To extract compressed and accurate key frames from videos, we propose to use the nonconvex group log-regularizer for formulating the structured sparse-coding-based key frame extraction model that can zero out rows of the coefficient matrix with a low reconstruction error.
2) To extract key frames automatically, the decomposition scheme is designed to separate the sparse coefficient matrix by rows, and the entire optimization problem can then be transformed into a set of subproblems with respect to the rows. The structured sparse coefficient matrix can be obtained and the nonzero rows from the learned structured sparse coefficient matrix correspond to the indices of the selected key frames.
3) To overcome the nonconvexity of the subproblems owing to the log-regularizer, we employ the DCA, wherein the nonconvex log-regularizer is decomposed into the difference of two convex functions related to thel1norm, and thus the closed-form solutions can be acquired directly using the proximal operator, which leads to an efficient algorithm for structured sparse-coding-based key frame extraction with the group log-regularizer.
The rest of this paper is organized as follows. Related works are reviewed in Section II. Section III introduces the proposed model and algorithm. Firstly, the sparse-coding-based key frame extraction is introduced. Secondly, the proposed structured sparse coding with the group log-regularizer is introduced. Thirdly, the optimization of structured sparse-coding-based key frame extraction using DCA is described. In addition, the convergence analysis of the proposed algorithm is given. Section IV demonstrates the outperformance of the proposed algorithm on SumMe dataset, VSUMM dataset, and robot vision. Finally, Section V presents the conclusion.

II. RELATED WORK
Traditional key frame extraction methods can be mainly classified into shot-based or segment-based approaches. A shot-based algorithm determines a reference frame, and subsequently, each frame in the shot is compared with this reference frame to detect the key frame [25], [26]. In contrast, the segment-based algorithm selects the key segment that is obtained from the region around each key frame, providing an additional discriminative capability through dynamic patterns within short time intervals [27]. For example, Uniform sampling (Uni.) is widely used as a baseline for key frame extraction evaluation. Attention-based video summary (Attn.) [28] is a recently proposed key frame extraction approach that uses visual attention. Interestingness-based video summary (Intr.)[29] refers to a supervised approach in which the weights of multiple objectives are optimized on the SumMe dataset. Leeet al. [30] developed an algorithm to discover and segment foreground object(s) in a video. They discovered object-like key-segments to obtain similar or higher quality key frames.In addition, key frames can be extracted using deep neural networks [31]–[33]. Deep semantic features video summary(DFS) [31] selected key frames using the deep features of the video frames. VGG (visual geometry group)-based video summary [34] obtained key frames using deep semantic features from the VGG. However, these approaches cannot achieve sufficiently compressed and accurate key frames for video processing.
Very recently, several algorithms for sparse-coding-based key frame extraction have been proposed [10], [12], [16],[35], [36]. These methods do not require segmentation/shot detection or semantic understanding and can be used to adaptively extract the best samples [12]. In [10], the authors studied a sparse modeling representation selection (SMRS), which has been proven to be efficient for video classification and summarization. The authors of [10] used thel1norm as a sparse constraint to reconstruct the problem formulation and select key frames from the sparse modeling representation. Liet al. [9], [11] developed thel1norm based key frame extraction method using multiple types of information instead of using only pure video information. However, thel1norm cannot promote a sufficiently sparse and unbiased solution. Moreover, Tanet al. [16] developed a novel key frame extraction algorithm, SC-det, which employed the determinant measure for a more efficient sparsity measure. The determinant measure is a convex and differentiable sparsity constraint, which is easier to solve. However, the determinant measure cannot guarantee a sufficiently strong sparsity for videos. In addition,the determinant measure needs an additional row constraint,which means each row of the coefficient matrix should sum to one, to extract key frames from videos. The above approaches do not consider the structure sparsity, and it is difficult to automatically select the key frames according to the learned sparse coefficient matrix. The groupl2,1optimization model was proposed to select key frames from a video clip [20],[37], wherein thel2norm was used for the coefficients within each group, and thel1norm was used for the groups. Thus, a structured sparsity primarily depends on thel1norm.
In this study, to automatically extract fewer (sparser) frames directly from the video to represent the entire video with less reconstruction error, we employ the nonconvex group log-regularizer instead of the traditionall0,l1, orl2,1norms and design a reasonable decomposition scheme, for learning the structured sparse coefficient matrix. Based on the DCA, the closed-form solutions can be obtained directly, developing an efficient structured sparse coding algorithm with the group log-regularizer for key frame extraction.
III. PROPOSED MODEL AND ALGORITHM
The sparsity-inspired key frame extraction [13], [38], [39]represents the original redundant video frames using linear combinations of a few key frames selected by the sparse coefficient matrix. In this study, we propose the structured sparsecoding for extracting the key frames automatically as shown in Fig. 2, which is different from the traditional sparse models[11], [12], [16]. From Fig. 2, the original video frames can be described as the linear combination of a few key frames selected by the structured sparse coefficient matrix (namely,all the rows of the matrix are zero or nonzero). The nonzero rows of the structured sparse coefficient matrix correspond to the indices of key frames, achieving extracting key frames from the entire video automatically, without any additional operator. Thus, there exist only a few key video frames that are used to represent the video.
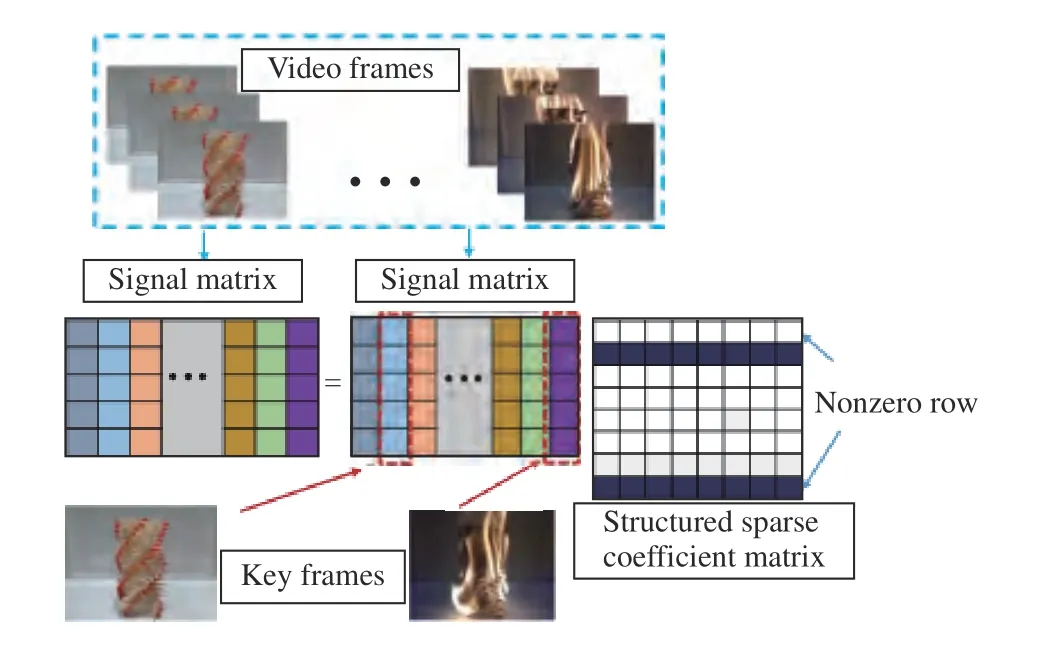
Fig. 2. Model of structured sparse-coding-based key frame extraction.
A. Sparse-Coding-Based Key Frame Extraction
Given the video matrixY∈Rr×Nincluding each frame features as its columns, we formulate the objective function of sparse representation to determine the indices of key frames as follows:
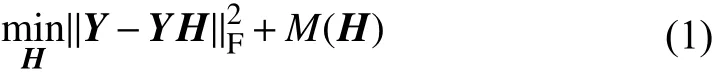
whereHdenotes a coefficient matrix andM(H) is a sparsity regularizer, the characterris the feature dimension andNis the number of frames in the video. The subscript F means the Frobenius norm ofY-YH.

B. Structured Sparse-Coding-Based Key Frame Extraction With the Group Log-Regularizer


C. Structured Sparse-Coding-Based Key Frame Extraction Using DCA
To efficiently address the nonconvex optimization of (6)arising from the log-regularizer, we employ the difference of convex (DC) decomposition which decomposes a nonconvex log-regularizer into the difference of two convex functions as shown in Fig. 3.
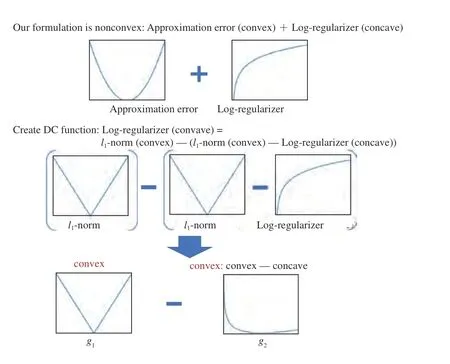
Fig. 3. Illustration of DC functions for nonconvex sparse coding problem.


Thus, we can update the coefficient matrixHby sequentially optimizing the set of {hk}.
For the sparse-coding-based key frame extraction problem(1), we used the decomposition scheme and the group log-regularizer for formulating the novel structured sparse-codingbased key frame extraction given in (4). The problem (4) contains the nonconvex log-regularizer. To overcome the nonconvexity of the subproblems owing to the log-regularizer, we employed the DCA. Then, the nonconvex log-regularizer is decomposed into the difference of two convex functions related with thel1norm, and thus the closed-form solutions can be acquired directly using the proximal operator, instead of the gradient-based method. This led to a more efficient structured sparse-coding-based key frame extraction algorithm. The proposed algorithm is summarized in Algorithm 1.It is noted that the tradition DCA is actually the gradientbased method. As we know, the gradient-based method needs several iterations for convergence [24], [47]. The complexity for each iteration of the proposed algorithm isO(Nr), whereNis the number of frames in the video, andris the feature dimension of each frame. The complexity of the proposed algorithm is similar to that of SMRS (O(Nr)) and much lower than that of SC-det (O(N2r)). To make the proposed algorithm more readable, we illustrate the workflow in Fig. 4.
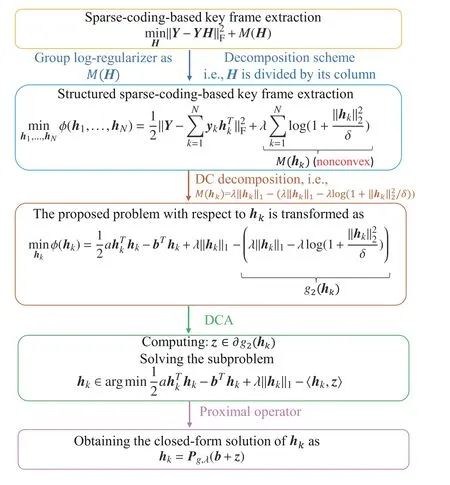
Fig. 4. Illustration of workflow for the proposed algorithm.

Algorithm 1 DCA-based structured sparse coding with the group log-regularizer (DSSC-log)1: Input: raw video matrix Y, whose columns contain frames. The positive parameters λ and δ.H ∈RN×N 2: Initialize the random sparse coefficient matrix 3: Repeat k=1,2,...,N 3: For do z ∈∂g2(hk)4: Compute bT =yTk Y-∑Nl,l≠k yTk ylhTl 5: Compute 6: Compute 7: End for 8: Until stopping criterion is met.Output: H.9: Find the non-zero rows in H, which are the corresponding indices of the key frames for the entire video.hk=Pg,λ(b+z)
D. Convergence Analysis of DSSC-log


IV. ExPERIMENTS
In this section, we evaluate the performances of the proposed DSSC-log for extracting key frames from 19 videos of SumMe dataset1http://www.vision.ee.ethz.ch/gyglim/vsum/.[29] and one video of VSUMM dataset2https://sites.google.com/site/vsummsite/download.[48].In addition, we apply the proposed algorithm on the robot version. We compare DSSC-log primarily with thel1norm-based SMRS [10] method, the determinant-based SC-det [16]method, and four additional existing algorithms coupled with a random baseline. SMRS and SC-det methods need to perform additional operator, i.e., the affine constraint (SMRS) or row constraint (SC-det), to extract the key frames. While the proposed DSSC-log can automatically extract key frames directly from the video without additional operators. Selected key frames are assessed quantitatively with the metrics of summary length andF-measure. In addition, we study the extracted key frames’ positions of one video for qualitative evaluation. Furthermore, the correlations between these key frames and the sparse coefficient matrix are also studied.
In our experiments, we coded all programs in MATLAB and ran the codes using MATLAB (R2016b) on a PC with a 3.3 GHz Intel Core i7 CPU and 16 GB of memory, on the Microsoft Windows 10 operating system.
A. Performance on SumMe Dataset
The SumMe dataset includes 25 videos covering festivals,events, and sports. However, because of the limitation of the running memory of our computer, we used 19 videos (except the six longest videos) in SumMe to execute our experiments that are listed in Table I. All videos are labeled and summarized by humans. The lengths of these 19 videos range from 0.5 to 6 min.
1) Metrics:
a) Summary length:Although there exist no mature metrics for evaluation of the key frame extraction tasks, we introducethe summary length as a measure to assess the quality of selected key frames. A lower summary length corresponds to fewer key frames being extracted from the video and a higher video compression ratio. We define the summary length as follows:

TABLE I THE OVERVIEW OF THE SUMME DATASET

c) F-measure:We use theF-measure [49] as the third metric for evaluating the quality of key frame extraction. To assess the performance of extracted key frames, the tradeoff between the precision and recall needs to be considered.Fmeasure is a widely used metric to measure the accuracy of the key frame extraction [16], [31]. For a key frame selection indexed byi, theF-measure is defined as follows:

wherepijis the precision andrijis the recall of key frame with indexiusing framejas a ground truth. We calculate recall and precision on every frame basis. TheF-measure balances the recall and the precision by considering the harmonic average. Moreover, the result is better if theF-measure is higher.
2) Performance of“Kids Playing in Leaves”:To evaluate the performance of the key frame extraction algorithms, we adopt one video from the SumMe dataset, “Kids playing in leaves (Kid)”, as a leading example. We first extract the frame features from the entire video “Kid”. There are 3074 frames in this video in total. Subsequently, the proposed algorithm DSSC-log is applied to extract the key frames from the 3074 frames. The parameterλis the regularization parameter, which balances the approximation error and the sparsity regularizer.The parameterδaffects the property of the log function. In the experiment,λandδare selected offline depending on the performances of the summary lengths. The summary lengths of the proposed DSSC-log under different values ofλandδare shown in Fig. 5. We selected λ=6.9×10-6and δ=0.3 with the lowest summary length.
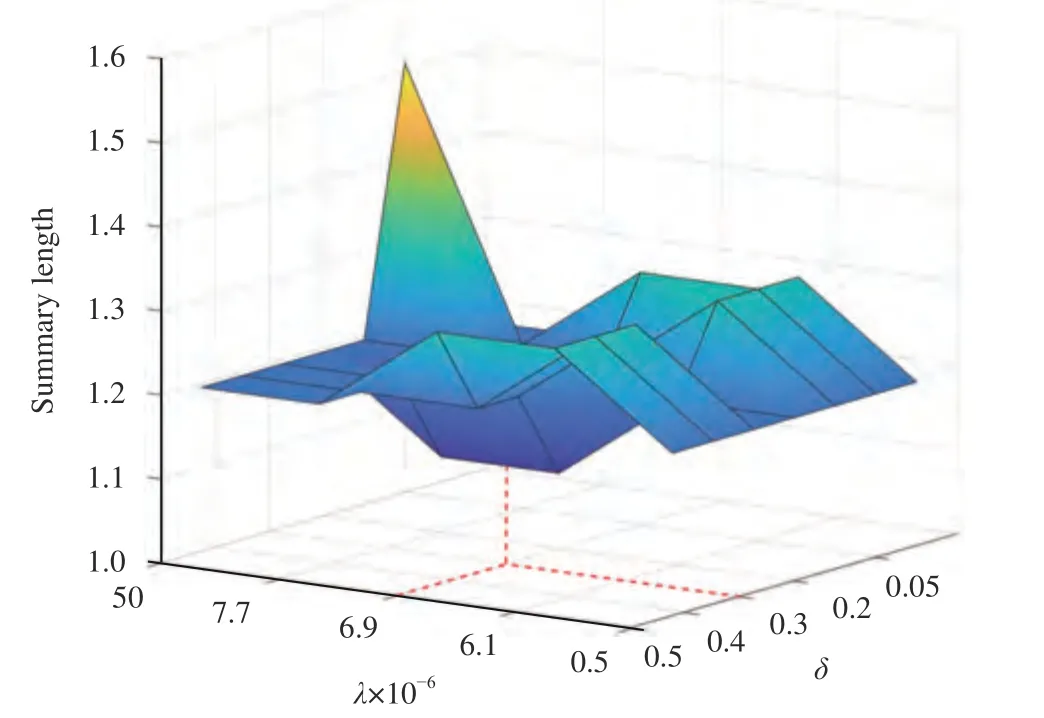
Fig. 5. Summary length versus different λ and δ values.
The total key frames extracted via DSSC-log are shown in Fig. 6. From Fig. 6, we can identify the process of three kids playing in leaves. Fig. 7 shows the first two and the last two key frames as well as their neighboring frames, wherein only those labelled with red rectangles are chosen as the key frames, while the remaining are abandoned. The experimental results show that our proposed DSSC-log can effectively extract a few key frames that can successfully represent the contents of the entire video.
The summary length of the video “Kid” by DSSC-log is 1.01%, which is shorter than those of the other algorithms(SC-det’s 1.11% and SMRS’s 1.20%). Thus, these results demonstrate that the proposed algorithm based on the log-regularizer can obtain more compressed key frames with less redundant information. In addition, the relative error when using the DSSC-log is much lower than those by the SC-det and SMRS algorithms, demonstrating that our log-regularizerbased algorithm can obtain a more accurate estimation. Therefore, DSSC-log performs quantitatively better than the other two sparse-modeling-based methods, SMRS and SC-det. In addition, the running time by the proposed method is 11 285 s,which is slightly less than that of SMRS (11 937 s) and much less than that of SC-det (14 497 s).

Fig. 6. Key frames selected from the “Kids playing in leaves (Kid)” video by the proposed DSSC-log method.

Fig. 7. Examples of the first two and last two key frames extracted from the video of “Kids playing in leaves (Kid)” by the proposed DSSC-log method.
3) Performance of Visual Examination:To further evaluate and intuitively investigate the performance of our DSSC-log algorithm, a visualization based examination was conducted.We demonstrate the correlation of the learned sparse coefficient matrix and the selected key frames from the video “Kid”dataset using the proposed DSSC-log algorithm.
Fig. 8 shows the first 11 key frames for “Kid” with coefficients from the first 1000 frames in the video “Kid”. The line chart in Fig. 8 shows the mean sparse coefficients with time,representing the probability of key frame indices. The red circle indicates the index of the selected key frames, for example, the 58th frame of the video is selected as the first key frame. Note that the key frames contain the leaves, grass,three kids, and a woman. From the line chart in Fig. 8, only two key frames are extracted from the first 1/3 of the video,which is a static period. Furthermore, the third key frame is extracted after the 400th frame and it shows three kids (with a pile of leaves). Lastly, many key frames can be extracted from frames 650 to 800 of the video, which is a rapid scene transformation period. Interestingly, we confirmed that the indices of the key frames are always related to the elements with high values from the sparse coefficient matrix.
4) Performance of All Videos:To further evaluate the robustness of our proposed algorithm, we conducted our experiments using all videos from the dataset. Table II shows the summary lengths of all 19 videos in the SumMe dataset using different algorithms. The results in Table II show that our proposed algorithm performs slightly better than the other algorithms in terms of the summary length in 7 videos (total 19 videos), and performs the best in term of the relative error for most videos (17/19). The results further demonstrate that the proposed DSSC-log can extract more compressed and accurate key frames.
Table III shows theF-measure of 19 videos in the SumMe dataset compared with a random baseline (uniform sampling(Uni.) [31]) and other existing approaches, including the traditional key frame extraction methods (i.e., VGG [34], attention-based video summary (Attn.) [28], deep semantic features video summary (DFS) [31]), interestingness-based video summary (Intr.) [29]), and the sparse-coding-based methods(SC-det and SMRS). Table III shows that our proposed DSSC-log performs the best in 7 videos (out of 19 videos) of the SumMe dataset in term ofF-measure. Furthermore,although our proposed method, DSSC-log, is an unsupervised method, it can achieve a higher averageF-measure than current existing algorithms.
B. Performance on VSUMM Dataset
The VSUMM dataset includes videos from websites such as YouTube. The videos are distributed among several classes such as sports, news, cartoons, and TV-shows. There are ground-truth key frames in this dataset.
We extracted the key frames using the proposed DSSC-log,and compared them to the ground-truth key frames. Fig. 9 shows an example of the extracted key frames, which are almost the same as the ground-truth key frames. This video contains 1332 frames in total; we extracted 23 key frames using the proposed algorithm. The summary length of this video is 1.73%. SMRC obtained 28 key frames (the summary length is 2.10%) and SC-det obtained 25 key frames (the summary length is 1.88%). It can be seen that the proposed DSSClog can achieve more compressed key frames (lower summary length) compared with SMRS and SC-det. This result also demonstrates that the proposed DSSC-log is efficient in key frame extraction for the VSUMM dataset. Note that there are no labels for calculating the F-measure in this dataset,thus, we only compare our results with the ground-truth key frames.
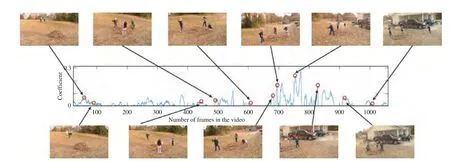
Fig. 8. The positions of the key frames selected from “Kids playing in leaves (Kid)” by DSSC-log, together with a sparse coefficient plot.
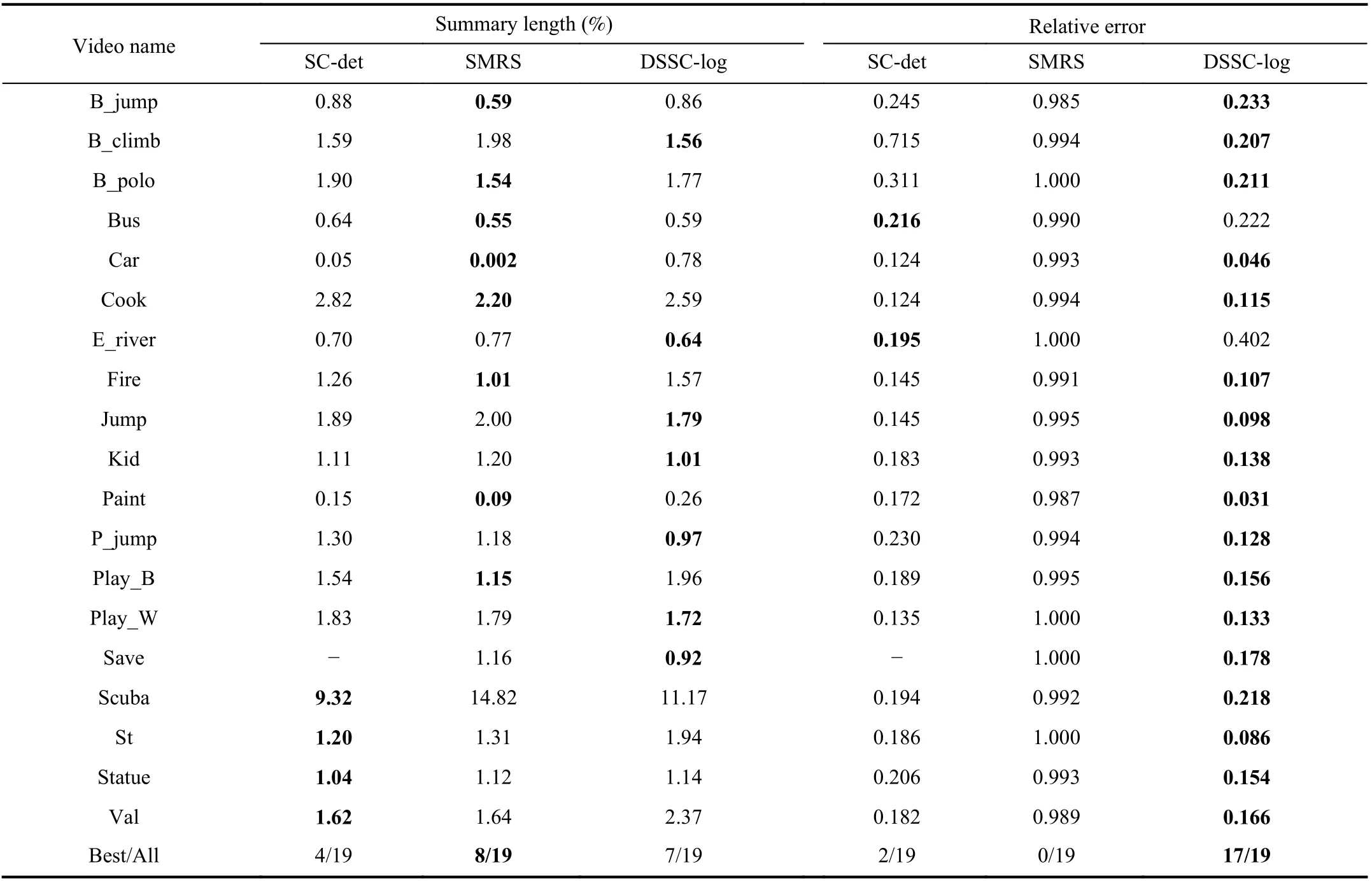
TABLE II SUMMARy LENGTH AND RELATIVE ERROR OF VARIOUS VIDEOS OBTAINED By SC-DET, SMRS, AND DSSC-LOG
C. Application for Robot Vision
The ability to extract key frames is very useful for robot vision. For example, the actions that are determined by the selected key frames can be used as key actions, which are performed by the robot. First person vision videos are obtained by wearable cameras which simulate robot vision. First person vision videos are long, unstable, and noisy, and this poses a technical challenge when dealing with long recordings; processing the entire data can be futile as the entire video includes both unimportant and interesting parts. The interesting patterns (key frames) can be discovered using the proposed DSSC-log method. To demonstrate the performance of the proposed DSSC-log algorithm, a first person video, which simulates cooking actions, was used. In this video, the subject cooks sandwiches and performs actions such as “take bread”and “take jam”. There are 2123 frames in the entire video. We extracted 43 key frames from the entire video using the proposed DSSC-log; the summary length is 43/2123=2.03%.Fig. 10 shows the examples of extracted key frames by the proposed DSSC-log, which are five key actions (“Takebread”, “Take jam bottle”, “Take knife”, “Take jam from bottle”, and “Spread jam”) of the video. Thus, the proposed key frame extraction approach is efficient in extracting key actions from robot vision. We can extend the proposed approach to robot vision processing, which can lead to the robot saving important recordings (key frames) from the large daily life recording videos.

TABLE III F-MEASURE OF VARIOUS VIDEOS OBTAINED By DIFFERENT VIDEO SUMMARy APPROACHES (SC-DET, SMRS, UNI., VGG, ATTN. [28], INTR.[29], DFS). THE RESULTS OF THESE ExISTING METHODS WERE ADOPTED FROM TABLE 4 OF [16].

Fig. 9. Key frames extracted from VSUMM dataset by DSSC-log, together with the ground-truth key frames.
D. Discussion

Fig. 10. Examples of extracted key frames from the first person video using DSSC-log.
Based on the experimental results, we see the effectiveness of the proposed DSSC-log for key frame extraction. In specific, the detailed performances are listed as follows:
1) The results in Table II show that our proposed algorithm performs the best in terms of the relative error for most videos(17/19) in the SumMe dataset, as compared with SMRS and SC-det. The results demonstrate that the proposed DSSC-log can extract compressed and accurate key frames.
2) Table III shows that our proposed DSSC-log performs better in 7 videos (out of 19 videos) of the SumMe dataset in terms of theF-measure in comparison with the existing approaches. This demonstrates that the proposed DSSC-log can obtain accurate key frames from most videos.
3) The proposed algorithm can obtain a higher compression with a nearly 18% increase compared to SMRS and an 8%increase compared to SC-det on the VSUMM dataset. This result also demonstrates that the proposed DSSC-log can extract more compressed key frames.
V. CONCLUSION
In this study, we proposed an efficient key frame extraction algorithm based on the group log-regularizer and the decomposition scheme, and thus the structured sparse coefficient matrix can be learned for automatically achieving accurate extraction of a few frames to represent the entire video. First,the group log-regularizer was introduced to enforce the strong sparsity for extracting more compressed (sparser) key frames with low relative error. Second, we separated the sparse coefficient matrix by rows (groups) and then the whole optimization problem was transformed to a set of subproblems with respect to groups. The selected key frames can be estimated automatically according to the nonzero rows in the learned structured sparse coefficient matrix. Third, we adopted the DCA to decompose the nonconvex function into the difference of two convex functions related tol1norm and to solve the resulting convex subproblems by proximal operator,thereby obtaining strong sparsity-promoting closed-form solution directly. Therefore, the structured sparse coefficient matrix can be learned accurately for extracting key frames automatically.
The experimental results demonstrate that the proposed algorithm can extract key frames from most SumMe videos more accurately than the compared state-of-the-art methods.Furthermore, the proposed algorithm can obtain a higher compression with a nearly 18% increase compared to SMRS and an 8% increase compared to SC-det on the VSUMM dataset.Furthermore, the proposed algorithm is efficient in extracting key actions from robot vision. In future work, we will attempt to extend the proposed DSSC-log to more complex video-processing tasks, such as 3D videos. In addition, we will develop a deep sparse coding based key frame extraction algorithm to obtain high-level semantic information from a video.
杂志排行

IEEE/CAA Journal of Automatica Sinica的其它文章
- Distributed Cooperative Learning for Discrete-Time Strict-Feedback Multi Agent Systems Over Directed Graphs
- An Adaptive Padding Correlation Filter With Group Feature Fusion for Robust Visual Tracking
- Interaction-Aware Cut-In Trajectory Prediction and Risk Assessment in Mixed Traffic
- Designing Discrete Predictor-Based Controllers for Networked Control Systems with Time-varying Delays: Application to A Visual Servo Inverted Pendulum System
- A New Noise-Tolerant Dual-Neural-Network Scheme for Robust Kinematic Control of Robotic Arms With Unknown Models
- A Fully Distributed Hybrid Control Framework For Non-Differentiable Multi-Agent Optimization