面向特定领域文本的重叠关系语料库构建方法
2022-10-24廖湘琳张宏军
刘 凯,廖湘琳,张宏军
(陆军工程大学 指挥控制工程学院,江苏 南京 210000)
0 引 言
现如今,信息抽取领域中,以给定关系模式(schema),通过有监督学习方式对深度学习模型进行训练,进而完成对文本数据信息抽取的过程已被广泛应用,且在重叠关系三元组抽取上有明显效果[1-2]。该文对爬取得到的新闻网络文本进行分析,发现特定领域实体间存在重要的重叠关系,但是受标注语料匮乏问题的制约,信息抽取领域在这方面的研究较少,无法满足国内外研究者们的需求。所以,为了更高效准确地抽取文本中的重叠关系,该文构建重叠关系标注语料库,为信息抽取模型训练提供丰富数据,为当前国内信息抽取语料库构建和完善提供借鉴和参考。
如何完善地构建实体关系模式,如何高效准确地构建特定领域实体重叠关系抽取标注语料库是该文的研究重点。目前网页新闻和网络博客等开放领域是大部分语料库的主要数据来源,如公开的中英文关系抽取语料库DuIE1.0[3],其关系类型主要包含常见的人物关系,CMeIE[4]为医学领域关系语料库, FewRel[5]关系数据集包含多领域的关系类型。该文借助远程监督知识,依据命名实体识别、依存句法分析和触发词词典,基于自定义schema对网络文本中的重叠关系进行语料标注,构建关系抽取语料库。其主要描述作战力量编成部署信息。
1 相关工作
语料库构建工作,过程复杂,形式多样。针对通用语料库的构建工作已经取得很多成果。比如周惠巍等人[6]依据词性和句子结构等信息构建中文模糊限制信息语料库,为事件信息抽取提供资源支持。蒋贻顺[7]构建触发词词典,通过规则匹配实现人物关系三元组抽取。针对特定领域的研究,目前更多的研究集中在地理实体关系[8-9]、医学领域[10-11]和军事领域。苟继承[12]利用远程监督方法,基于规则匹配的方式获得实体关系信息,构建实体关系知识库。蒋序平等人[13]通过定义事件模板,构造触发词词典,形成人工标注种子数据集,经过模型训练迭代生成针对军事想定文本事件抽取的语料库。冯鸾鸾等人[14]制定了一系列标注规范,对收集到的海量互联网文本进行术语语料标注,并且构建出面向国防科技领域的技术和术语语料库。上述方法需要人工构建规则,增加人工标注负担。该文巧妙融合上述研究方法,根据自定义实体关系schema对收集到的特定领域新闻网络文本进行自动回标。该方法避免了大量的人工标注工作,构建出的语料库规模较大,质量较高,有较大实用价值。
2 语料库构建方法
面向特定领域文本的重叠关系抽取语料库构建流程如图1所示。

图1 语料库构建流程
2.1 语料来源
该文将语料限定在特定领域内,为了发现网络文本中重叠关系信息,建立一个通用的、实体覆盖面更广的关系类型模式。通过网络爬虫抓取来自新浪网、光明网、国防科技信息网、武器百科大全网站等超过1 000个网页,获得原始数据约10万条,占用空间资源26.3 M。数据样例如下所示:(1)近日,北京武警放出了使用QMK171瞄准镜的95-1式的照片,意味着QMK171瞄准镜已经大量入役。(2)日前,美国通用动力公司在美国首都华盛顿举行的美国陆军协会年会博览会上展示了其最新的RM277型全自动轻机枪的信息,将采用美军最新研发的6.8毫米弹药,等等。
新闻类语料来源于网页。通过观察网页源代码中的HTML标签和文字分布特点,利用python的爬虫库BeautifulSoup解析网页源代码,对网页中正文较集中的内容块进行文本提取。
正文提取完成后,为方便后续实体关系的抽取,将语料数据进行分句处理。中文语句的一句话通常由句号“。”、问号“?”、感叹号“!”、省略号“……”等符号结尾,利用这些符号作为句子分割条件,得到分句后的无标注文本数据集D,作为语料库构建的数据来源。
2.2 关系模式构建
ACE评测会议于2005年公布了官方标注的关系抽取语料库,包括中文、英文、阿拉伯文的标注语料,其定义了表中的6类大类关系和18类小类关系的关系类型。COAE会议于2016年针对中文领域关系抽取推出包含10种关系类型的中文关系抽取训练集。
但是上面两个数据集的关系体系与特定领域的关系具有一定差异,无法成为构筑特定领域关系体系的基础。通过专家知识和对特定领域文本的分析,根据上述关系分类,对实体关系的筛选,过滤与领域无关的大量内容,经过整理,该文最终预定义了5种命名实体,分别是组织(ORG)、武器(WEAP)、地点(LOC)、行动(ACT)、人员(PER);7种实体关系类别,分别是人员和组织的隶属关系、组织与组织的编成关系、组织与行动的执行关系、组织与地点的部署关系、行动与地点的目标关系、组织与武器的配置关系。关系schema如下:
{"object_type": "ORG", " predicate ": "编成", "subject_type": "ORG"}
{"object_type": "ACT", " predicate ": "执行", "subject_type": "ORG"}
{"object_type": "LOC", " predicate ": "部署", "subject_type": "ORG"}
{"object_type": "LOC", " predicate ":"布置", "subject_type": "WEAP"}
{"object_type": "LOC", " predicate ": "目标", "subject_type": "ACT"}
{"object_type": "WEAP", " predicate ":"配置", "subject_type": "ORG"}
{"object_type": "ORG", " predicate ": "隶属", "subject_type": "PER"}
通过分析语料文本,存在如图2中三种重叠关系,以此为基准进行下一步研究。

图2 重叠关系示例图
2.3 基于自定义关系schema的重叠关系语料标注
2.3.1 实体集构建
根据2.2节中确定的五种实体进行以下分析:首先利用命名实体识别方法和自制的领域专业词典,将2.1节构建的训练语料输入BiLSTM+CRF命名实体识别模型[15]进行实体识别,然后通过启发式规则,比如去掉单字符名词、保留专有名词等进行人工筛选,最后获得备选实体集N,为后续启发式实体关系对齐和关系数据去噪做准备。备选实体集N部分实体如表1所示。

表1 备选实体集N部分实体示例
命名实体识别所用标注数据集由多人进行手动标注并打分评估进行融合所得。
2.3.2 触发词词典构建
触发词词典构建过程为:首先进行特征词抽取(运用LTP工具抽取动词、名词),然后根据schema聚类成触发词词典,最后根据实体对进行启发式关系过滤。
(1)特征词抽取。
通过观察语料库发现,绝大多数产生关系的实体对都可以由其上下文中一般动词或者一般名词触发和描述(统称为特征词),而且这些特征词均与待处理的实体对在依存句法分析树中产生有限的几类关系。
特征词抽取过程是为了抽取语料库中与特定实体对类型下的实例共现,且依存句法分析后具有特定语义关系的动词或名词。然后采用启发式过滤规则,进行特征词集过滤筛选[16]。
词性分析和依存句法分析中,使用哈工大语言技术平台(Language Technology Platform,LTP)的处理模块。LTP处理中文文本具有良好的性能。首先对语料库进行词性标注,抽取出动词或动名词。LTP定义了15个依存句法标签,包括主谓关系(SBV)、动宾关系(VOB)、间宾关系(IOB)、并列关系(COO)等。
具体步骤如下所示:
①根据2.2节中构建的schema,得到特定实体对类型的槽(socket)。对每个实体n∈N,在语料D中检索包含实体的所有句子,保留那些同时包含实体ni和另一个与其形成特定实体对类型的实体nj的句子Sent,由此形成七种关系句子集
②对
Rule1:根据依存句法分析后,动词或名词必须满足与实体对中任一实体存在主谓宾结构SBV-VOB、从属关系结构ATT-ATT、动补介宾关系结构CMP-POB。
③对于每一个w∈R,统计其在第(1)步得到的句子Sent集中出现的频率PS(wk),去掉频率小于常数θ的特征词。
④根据候选特征词wk在D中和特定实体对类型句子集Sent中的分布信息,采用以下公式计算其与实体对类型的相关度Rel(wk)[16],其中PS(wk)和PD(wk)分别表示wk在特定实体对类型句子集和语料库D中的频率。
Rel(wk)=PS(wk)/PD(wk)
⑤根据相关度对候选特征词进行排序,根据排序位置取靠前的Top-K个作为特征词,获得筛选后候选特征词集R。
(2)Schema聚类与触发词词典构建。
一系列具有相同含义和用法的特征词可以体现同一种关系,因此根据2.2节Schema中确定的七种关系词对上述包含七种关系类型的候选特征词集R进行对应聚类,构建触发词词典W,如表2所示。

表2 触发词词典部分触发词示例
2.3.3 语料回标
借助实体识别和触发词规则,基于自定义关系schema的语料标注方法假设:如果训练语料的某一句话包含的实体集中的实体对在触发词词典中有对应的触发词,就认为这句话描述了触发词所表示的schema中的关系类型。基于此假设进行语料自动回标,有助于减少人工标注的工作量。
标注算法流程:首先,根据命名实体识别结果,获得实体和实体类型列表,然后顺序扫描根据领域词典进行结巴分词后的语料文本,依次匹配实体集中的实体,先进行头实体subject匹配,查找到一个实体后转为该文本片段尾实体Object匹配,然后根据schema槽中的实体对类型进行判断,两者是否相关,若相关,则提取关系信息,查找触发词词典,对关系类型标注和保存,否则继续进行实体匹配,此过程在句子集内循环,直到遍历完成单个句子中所有关系。此方法简单有效,标注效率高。算法如下所示:
算法1:重叠关系语料回标算法。
输入:实体集N,触发词词典W,待匹配语料D,schema;
输出:标注文本s。
① forD中的每一句话sdo:
② for 实体集N中的每一个实体和类型type do:
③ 头实体[subject,s_type]匹配
④ if subject=匹配成功 then
⑤ for 实体集N中除subject外的每一个实体和类型type do:
⑥ 尾实体[object,o_type]匹配
⑦ if object=匹配成功 then
⑧ if schema[s_type,o_type] and 对应关系r←W[w] then
⑨ 标注文本←文本串s+关系r+subject+object
3 实验分析
为了保证语料库的专业性和可靠性,首先探讨本语料库数据源的可用性,然后进行标注质量评价并使用基础模型验证语料库的质量。
3.1 数据源可用性分析
对约10万条原始数据进行随机抽取,以评价新闻网站作为构建特定领域重叠关系抽取语料库的可用性。(1)从原始数据中随机抽取1 000条语句;(2)根据语句中包含的实体类型将其划分到文中的实体分类体系中;(3)统计每个实体类型下语句的信息量,结果如表3所示。
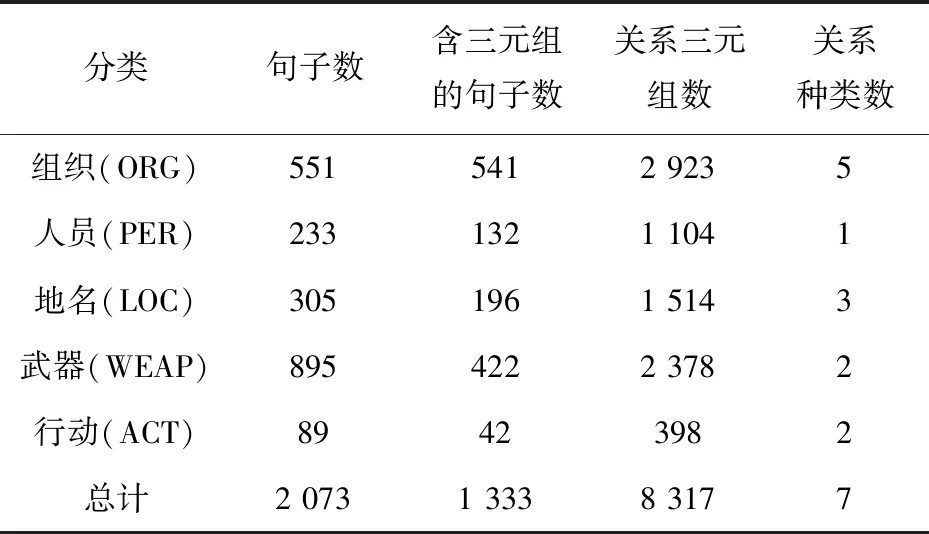
表3 数据源可用性统计
由表3可以看到:(1)从原始数据中随机抽取的1 000条新闻语句中最多有89.5%被成功划分到该文提出的实体分类体系中,但是不同句子中,实体数量分布不均匀;(2)包含关系三元组的语句数约占抽取的句子总数的64.3%,平均每个句子中含有6个关系三元组,涵盖了自定义的7种实体关系。可见通过新闻等网站爬取的原始语料蕴含了丰富的实体关系三元组,为构建实体关系语料库提供了充足的数据资源。
3.2 标注质量评价
基于数据可用性分析结果,从实体集N中分别为实体分类的5个实体类型选取50个实体,共计250个;然后对基于该方法构建的重叠关系语料库和实体识别筛选语料进行统计分析。特定领域的重叠关系语料库成功标注18 750个句子,占实体识别筛选语料的51.3%。此语料库中的知识形式为{“text”: “文本”, “spo_list”: “{subject,predicate,object}”},其中subject表示主语(头实体),object是宾语(尾实体),predicate是谓词(关系的抽象表示)。为了方便查询,依然采用json格式保存三元组信息,标注示例如:{"text": "海军军事学术研究所研究员里奇博士说:“这次建造轻型航母的决定是‘一石二鸟’,这将成为体现‘有效性的韩国海军核心战斗力’”。", "spo_list": [{"predicate": "编成", "object_type":"ORG", "subject_type": "ORG", "object": "海军军事学术研究所","subject": "韩国海军"}, {"predicate": "配置", "object_type":"WEAP", "subject_type": "ORG", "object": "轻型航母","subject": "韩国海军"},{"predicate": "隶属", "object_type":"ORG", "subject_type": "PER", "object": "海军军事学术研究所","subject": "里奇"},{"predicate": "隶属", "object_type":"ORG", "subject_type": "PER", "object": "韩国海军","subject": "里奇"}}。
表4为数据统计信息。其中成功率表示成功匹配包含该实体的三元组的句子数占包含该实体的标注句子总数的百分比;准确率表示正确标注的三元组数占包含该实体的三元组数的百分比。实验中根据250个实体得到了实体识别筛选标注语料中的1 024条语句,通过随机抽样计算,语料库的总体回标成功率为76.7%,总体关系标注准确率为85.8%。
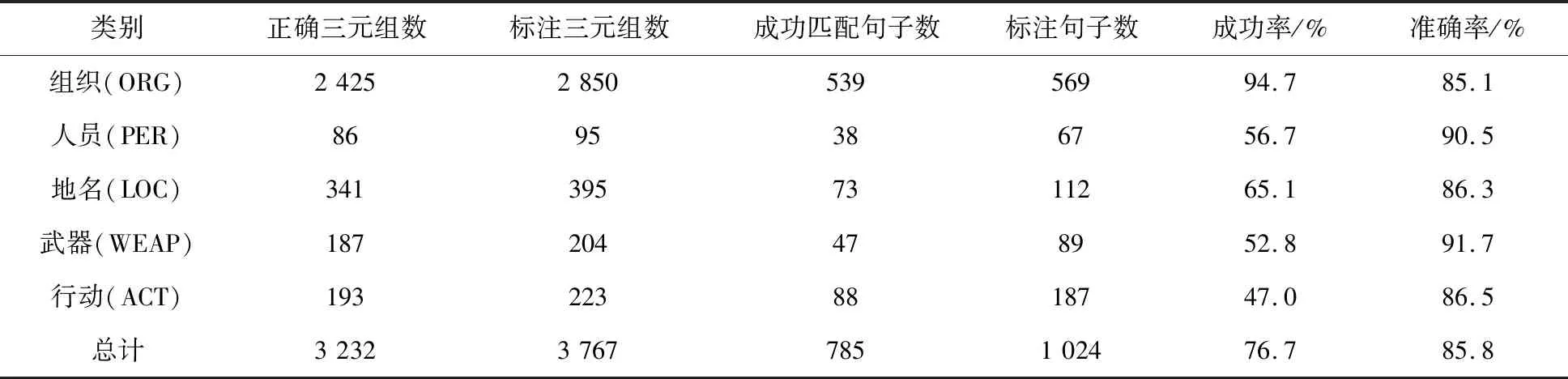
表4 标注质量评价统计
针对标注出的实体关系,进行如下统计展示。图3表示每句话中包含不同三元组数目的句子数;图4反映句子集中包含各类重叠关系的数目及三元组总数。
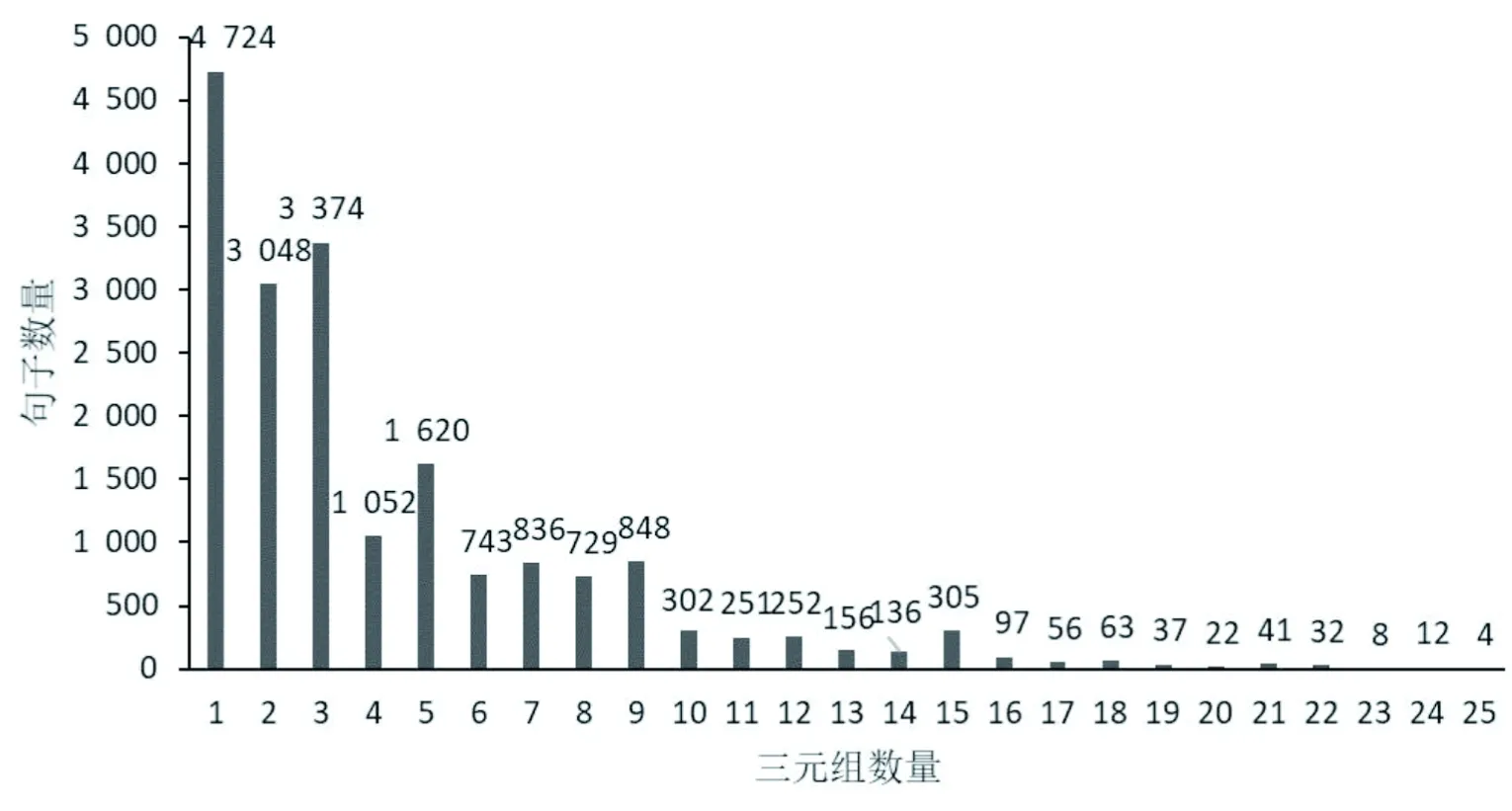
图3 三元组频数统计
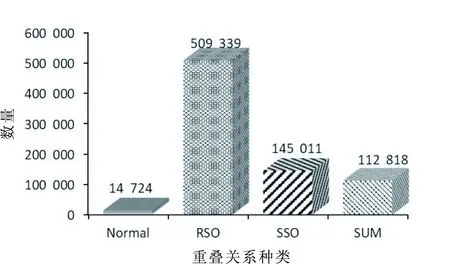
图4 重叠关系频数统计
3.3 信息抽取模型实验
为了说明构建的语料库的可用性,实现对军事新闻中蕴含的作战力量编成部署信息的抽取,该文使用信息抽取基础模型DGCNN+self-attention[17]进行实验。将构建好的语料库按照7∶3的比例进行训练集和验证集的划分,并选择17 942条经过清洗后的语句作为测试集。评测采用传统的召回率(R)、准确率(P)、F1值。模型实验结果显示,利用构建的语料库训练的基础模型,其准确率达到95.98%,召回率达到91.50%,F1值为93.68%,效果较好。
3.4 语料库结果可视化
为更好展示构建的语料库效果,采用neo4j图数据库存储并进行可视化。语料库部分语句各关系可视化如图5所示。
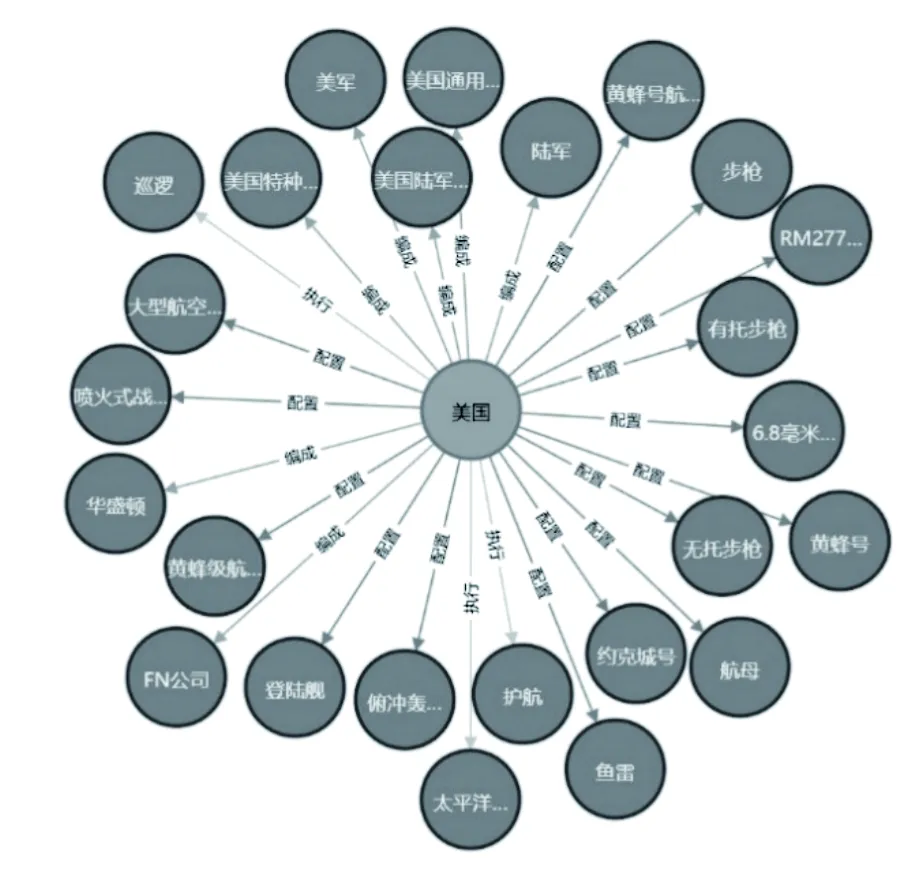
图5 关系三元组可视化
以美国为例:如“美国”存在“美国-编成-美国特种作战司令部”、“美国-配置-黄蜂级航空母舰”、“美国-执行-护航”等三种关系,26个关系三元组。
4 结束语
该文描述了面向特定领域文本的重叠关系抽取语料库构建工作。首先对爬取到的特定领域网络文本进行分析,构建关系模式schema,然后利用命名实体识别模型对文本进行实体识别得到备选实体集,通过依存句法分析和特征词聚类构造触发词词典,最后基于实体集和触发词词典进行语料自动回标,构建出目前规模较大的面向特定领域的实体重叠关系抽取语料库。同时,探究了数据源的可用性和标注质量,语料总体的回标成功率为76.7%,总体关系标注准确率为85.8%,利用基础重叠关系抽取模型进行实验,实验结果F1值达到93.68%。
文中的构建方法减少了人工标注的工作量,标注效率较快,质量较高。但是,由于网络文本的冗杂,构建的语料库仍存在部分实体和不常见实体无法识别,目标等关系数量相对较少,且包含的关系类型较少等问题。未来的工作中,将利用抽取模型进行迭代更新,改进标注质量,并且继续完善标注体系,扩大标注规模,为后续特定领域的信息抽取、知识图谱构建等工作奠定基础。
