面向科技服务的专家推荐模型研究
2022-10-24盖素丽檀改芳
盖素丽,檀改芳,唐 松,董 佳
(1.河北省科学院应用数学研究所,河北 石家庄 050081; 2.河北省信息安全认证工程技术研究中心,河北 石家庄 050081)
0 引 言
关于专家推荐系统,Reichling T等[1]曾提出过一个比较明确的定义,即专家推荐系统是为了满足用户在特定场景下对专家的咨询需要,帮助他们推荐合适专家来解决问题。专家推荐系统一般应用于专业性较强的领域,如科研项目申报[2]、学术论文评审[3]、企业需求对接[4]等应用场景。这些领域大多拥有自己组织内部规范化、结构化的知识库,进行专家推荐时,除了通过人工筛选和关键词查询外,可以借助基本的计算方法如模糊逻辑[5]和向量空间模型[6]来计算用户需求与专家领域的相关性,进而对专家进行排序并完成推荐。
但是,当专家推荐系统由专业机构转向社会公众,用户不再是规范的组织机构,那些推荐算法所依赖的高质量且层次分明的知识库也变成了散乱的知识碎片,它们涉及的学科更加丰富,彼此交叉、渗透,界限模糊。面对科技领域的海量数据资源,用户和工作人员难以快速精准找到满足需求的专家,便会陷入知识困境。此时,任凭专家有多么强的才智能力、多么丰富的知识经验,如果不能满足用户需求,会导致极大的资源浪费。科技领域迫切需要采用一种行之有效的方法去处理日益繁重的专家推荐工作,实现良善的专家推荐目标。
在系统梳理河北省关于专家和用户决策咨询数据关系和程序研究的基础上,该文提出了契合社会公众需求的专家推荐模型,旨在挖掘符合专家研究兴趣的用户需求,并将用户需求有效推荐给可能解答的专家。模型推动专家与用户之间有效开展决策咨询工作,保证推荐专家的专业性以提升用户决策咨询质量,并做出如下工作:
(1)融合多个数据源构建科技服务知识库,对以往案例中需求与专家知识进行有效提取;
(2)提出知识融合模型,将需求与专家进行统一建模,并挖掘二者之间的潜在知识关联;
(3)提出一种基于ALBERT的专家推荐模型。
1 专家推荐算法
近年来,针对推荐算法[7]的研究发展迅速,其中应用最为广泛的主要有以下几种:
(1)基于协同过滤的推荐。
作为应用最早和最为成功的推荐技术之一,协同过滤算法面向用户[8],通过计算用户偏好数据来预测新用户可能喜欢的主题或产品。Javier等[9]在此基础上,融合推荐和文本信息检索任务之间的联系,研究出了社交网络中有效联系人推荐算法的新视角。
(2)基于内容的推荐。
作为信息过滤技术的延续,基于内容的推荐算法一般通过向量空间模型将文档等文本信息表示为多维空间中的向量。随着用户行为产生的标签、评论等文本信息剧增,使得基于内容的推荐显得尤为重要。Wang Donghui等[10]提出的基于卡方特征选择和softmax回归的有效混合模型能够根据手稿摘要内容的优先顺序推荐合适的投稿期刊或会议。
(3)基于效用的推荐。
效用理论认为,决定物品价值的是该物品对人的有用程度,或是人对该物品的价值认可程度,亦即该物品的效用。基于效用的推荐方法建立在用户对物品的满意情况,并依靠对象自身属性和用户偏好来衡量其效用值。将效用函数应用在专家推荐系统[11],可以把用户需求属性和专家兴趣同时进行量化,比依托单一的属性信息进行推荐的方法更加灵活。
(4)其他推荐。
在某一具体问题中为了获得更好的推荐效果,常常需要将两种甚至以上推荐方法组合在一起,即为组合推荐。此外,推荐算法与深度学习[12]尤其是迁移学习的结合,能够轻松处理稀疏数据、捕捉数据间的隐藏关系。跨域推荐[13]则利用迁移学习的方法,将知识从源域(相关领域)迁移到目标域(研究领域),获取用户在不同领域的有效信息,提高目标域的推荐性能。张鼐等[14]提出了一种基于语义扩展的知识推荐方法用于文献推荐。刘鲁等[15]利用维基百科知识作为背景构建专家知识地图,能够直观度量专家知识组成和研究兴趣。
由此可以看出,现有学术资源推荐模型[16]的研究目标是为专家个性化推荐感兴趣的文献或者类似专家。这些推荐模型或研究了文献之间的联系,或研究了专家之间的关系,不能充分捕捉需求、专家与方案三者之间的潜在知识关联(见图1),导致专家推荐的准确性较低。为了解决这个问题,在综合考虑上述推荐方法的基础上,该文重点关注用户需求与专家之间的知识联系,基于预训练语言模型[17-18]对需求描述、专家描述进行特征提取与知识建模,提出了一种深度融合辅助知识的推荐算法。该算法构建知识网络,对需求、专家和案例进行统一建模,并挖掘需求与专家之间的潜在知识关联,最后通过模型对需求进行专家推荐。

图1 需求、专家与方案间潜在知识关联
2 专家推荐模型定义
专家推荐模型的形式化定义:假设RS是所有需求(requirements)的集合,ES是所有专家(experts)的集合,u()函数可以计算专家e(e∈ES)对需求r(r∈RS)的推荐度,还要考虑专家的可靠性等,即u:RS×ES→L,L是一定范围内的全序的非负实数,则:
(1)
即专家推荐平台要研究的问题就是找到推荐度L最大的那些专家e*,专家推荐的核心问题转化为计算u( ),其计算值用来衡量专家对需求的有用程度,称为效用度。
在前述定义了专家科研背景和需求基本特征的基础上,通过计算向量空间余弦夹角来衡量专家研究兴趣与需求之间的匹配程度,效用函数u( )定义为:
(2)
式中,Dr、De是两个待计算相似度的目标对象,即为需求与专家,dkr、dke是对象Dr、De的特征向量权值。通过计算,得到其夹角余弦,值越大,二者相似度越大,反之越小,0≤sim(Dr,De)≤1 。
假设rx为需求集RS中的一个需求样本,ex为专家集ES中的一个专家样本。给定需求-专家对(rx,ex),为它设置一个状态标签yx∈{0,1,2,3},其中0代表未接受需求邀请,3代表接受需求邀请并回答。(rx,ex,yx)是一个训练样本。根据上述定义,n个训练样本就组成了训练数据集,如公式(3)所示:
Dtrain=((r1,e1,y1),(r2,e2,y2),…,(rn,en,yn))
(3)
通过训练数据集Dtrain构建推荐模型,并定义损失函数对模型进行优化,判断当前专家ex是否会接受某个新需求rx邀请的标签yx。对得到的标签yx对所有专家进行排序或者加权等操作,找到最适合需求的专家。
yx=u(rx,ex)
(4)
3 专家推荐模型实现
3.1 特征提取与知识融合
结合专家动态研究兴趣特征将研究重点放在挖掘其学术论文、发明专利、工程案例中的相关知识,获取需求与专家描述的有效信息,构建科技服务知识库。通过文本多特征提取与知识融合可以对需求和专家文本数据进行统一建模,模型结构如图2所示。

图2 知识融合模型结构
知识融合模型主要由局部特征获取、上下文特征获取、多特征融合和分类四部分组成。首先,获取三种不同输入特征,包括词向量表示、词位置特征、句子位置特征;然后,获取上下文特征,增强模型的特征学习能力;最后,将以上特征进行融合,并输入到分类层进行分类,预测并得到类别标签。
该文选取ALBERT模型融合多种特征,并对输入文本进行语义理解,提高文本的表征能力及文本分类的准确率。同时,文本输入时的处理上要充分考虑任务需求,比如输入是句子对,输出是对该句子每个字的包含上下文信息的编码结果。然后,对需求及专家分别进行个性化表征后应用于推荐系统。
3.2 专家推荐模型实现
实现专家推荐模型需要深入分析需求服务案例中的需求与专家,挖掘二者之间的潜在知识关联,然后进行专家推荐。在上述知识融合模型基础上提出一种面向公众决策需求咨询服务的专家推荐模型,结构如图3所示,其具体实现流程如下:
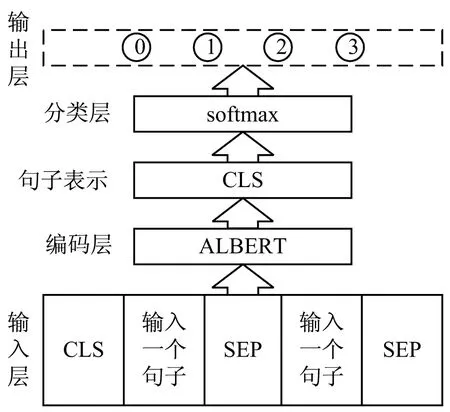
图3 专家推荐模型结构
步骤1:对过往服务案例中需求与专家知识进行有效提取,建立科技服务知识库,筛选训练语料。
步骤2:以标题及内容的知识表征需求,以专业领域及研究成果的知识表征专家,将二者联合信息作为模型输入,获取联合需求属性与专家偏好的深度特征。
步骤3:专家推荐模型的编码层采用在通用领域预训练好的ALBERT模型,并在事先准备好的数据集上进行训练,获取需求与专家的隐性知识关联,使模型由通用领域迁移到科技服务领域。
步骤4:使用验证集评估模型训练效果。在模型通过验证集之后,使用测试集评估训练模型效果,获取最佳模型即为专家推荐模型。
通过该模型可以对需求、专家、案例进行多特征知识融合,并通过理解需求语义信息和学习专家特征之间的关系获取需求与专家的隐藏知识关联,最终获得准确的专家推荐结果。
4 实验及结果分析
4.1 实验数据集
在系统梳理河北省关于专家和用户决策咨询数据关系的基础上,该文融合学术论文、发明专利、工程案例等多个数据源中的有效信息(包括需求信息、专家信息、历史需求服务案例等内容),组成科技服务知识库。然后,经过团队人工标注最终筛选出3 000条专家信息,25 000条历史服务需求专家匹配信息组成实验数据集,按比例8∶1∶1划分为训练集、测试集和验证集三个子集,数据已作脱敏处理。
4.2 实验环境
实验硬件、软件环境如表1所示。

表1 实验环境
4.3 实验对比与分析
该文总共选取了两种不同的预训练语言模型即BERT与ALBERT作为专家推荐模型的编码层,并分别采用softmax与TextCNN作为分类层进行训练模型推荐效果的对比实验,并对相应的推荐结果进行判定。
专家推荐模型在实验环节采用固定的参数配置(见表2),此次对比实验采用谷歌官方发布的中文版BERT及tiny版的ALBERT进行文本特征的提取,并通过数据处理阶段整理出的需求与专家数据集微调模型。

表2 模型参数设置
专家推荐模型的准确度是评价模型的最基本指标,其衡量推荐模型能够准确预测用户需求对服务专家及专家对推荐需求的喜欢程度。本次实验主要考察训练及测试数据的一些统计特性,故采用分类准确率分数(accuracy_score)和多类别交叉熵损失函数(categorical_crossentropy)评价专家推荐模型效果。
由表3可以看出,基于BERT的专家推荐模型能够获得很好的准确率,但是由于BERT模型参数量巨大,模型训练耗时太久。以BERT-TextCNN为基础的专家推荐模型训练耗时有所增加而且推荐效果更差。基于ALBERT的专家推荐模型训练耗时更少,计算成本更低,准确率上能够取得明显的提升。

表3 不同语言模型训练效果对比
由图4可以看出,基于ALBERT的专家推荐模型在上述各类模型中收敛速度更快、准确率更高,能够更高效地推荐出合适的服务专家。

图4 不同语言模型训练效果对比
5 结束语
该文研究了科技领域公众决策咨询专家推荐服务对知识整合和知识推荐的需求,为了解决专家推荐不合理不准确的难题,在对知识整合、知识推荐理论及预处理语言模型进行全面分析的基础上,对推荐服务所需材料进行整合并统一建模,从而将科技领域现有的信息孤岛发展成一个数据库。最终提出了一种面向科技领域用户决策咨询需求服务的专家推荐模型,模型能够深入分析需求服务案例中的需求与专家,并针对隐性知识的特点,挖掘二者之间的潜在知识关联,从而完成对所需服务专家的推荐。通过实验表明该专家推荐模型在使用过程中能够取得很好的推荐效果。
