联合迁移学习和强化学习的不平衡分类方法
2022-10-17侯春萍华中华于笑辰王伟阳
侯春萍,华中华,杨 阳+,于笑辰,王伟阳,于 鑫
(1.天津大学 电气自动化与信息工程学院,天津 300072; 2.国家电网辽宁省电力有限公司 丹东供电公司,辽宁 丹东 118000)
0 引 言
在疾病诊断[1]、垃圾邮件检测[2]和软件缺陷检测[3]等应用问题中,由于其异常样本出现频率低、总体数量少,数据集中的正常、异常样本数量往往都是不平衡的。利用这种不平衡样本对机器学习模型进行训练,会导致模型在少数类样本上产生极大的过拟合,训练好的模型在少数类样本上的识别性能不好,模型最终的分类准确率下降。因此,研究不平衡样本的二分类问题,对少数类样本的正确分类具有重要的意义。
当前研究不平衡数据二分类问题的大多数方法主要是从模型和数据两个层面对算法进行设计。模型层面方法的典型算法有代价敏感算法和集成算法。代价敏感算法以整体误分类代价的最小化作为训练目标,通过引入代价矩阵,赋予少数类样本较大的权重,以降低分类器在少数类样本上的错误率。文献[4]提出的基于代价敏感的间隔分布学习机,利用成本敏感的间隔均值和惩罚项,以使高代价的样本被错误分类的概率降低。Khan等[5]提出了代价敏感深度神经网络,该网络同时优化代价敏感因子和网络参数,以提高不平衡数据的分类效果。Alam等[6]将多数类样本划分为多个子集并分别进行训练,然后集成所有的子分类器,提升了不平衡样本的分类效果。模型层面的算法的特点是,不改变原始数据的分布,避免了合成或删除样本引进的误差。但是,由于不同的数据集的不平衡度不同,各类样本的重要程度不同,这类算法的优化较为困难。
数据层面的方法主要通过改变训练集中多数类和少数类样本的数量,减轻训练过程中的过拟合现象,从而提升不平衡分类的效果。改变样本数量的方式一般有两种,一种是对多数类样本进行下采样,另一种是对少数类样本进行上采样。文献[7]采用的合成少数类算法(synthetic minority over-sampling technique,SMOTE),在少数类样本及其邻近样本之间进行线性插值,生成新的少数类样本。文献[8]提出了自适应合成采样算法(adaptive synthetic sampling,ADASYN),根据数据分布情况为不同的少数类样本生成不同数量的新样本。Zhu等[9]在SMOTE算法的基础上,提出了SMOM算法,该算法基于少数类样本的K近邻计算出选择权重,进而控制该方向合成样本的概率。文献[10]提出的G-SMOTE算法,在选定的少数类样本周围生成样本,一定程度上避免了SMOTE算法生成样本的随机性。文献[11]提出的Hybrid Sampling算法,首先利用基于密度的聚类方法(density-based spatial clustering of applications with noise,DBSCAN)和K近邻算法(K-nearest neighbor,KNN)剔除多数类中的模糊样本,然后采用SMOTE算法对少数类样本上采样,达到平衡数据集的目的。Shi等[12]提出的SDS-SMOT算法,首先对原始数据集进行下采样:丢弃远离决策边界的多数类样本和噪声样本;然后采用SMOTE算法对少数类实样本进行上采样,使数据集基本平衡。Wu等[13]提出的基于SVM分类超平面的混合采样算法,利用决策面计算少数类样本的重要程度,并分别对多数类样本和较为重要的少数类样本进行下采样和上采样从而平衡数据集。数据层面的方法虽然能够通过建立样本平衡的数据集解决训练中的过拟合问题,但是,下采样方法在删除噪声的过程中可能会丢失多数类样本关键信息,上采样方法不能保证新增样本对模型分类效果的贡献程度,最终分类模型的性能严重依赖于特定的下采样/上采样方法。
Kang等在文献[14]中指出,不平衡的训练数据集的样本数量和样本特征分布并不完全耦合,高质量的类别表征是提高不平衡样本分类效果的关键。但是由于样本数量的不平衡度较大,高质量的类别表征难以获取。在基于上采样方法实现的不平衡分类算法中,生成样本虽然数量较多,但是样本质量参差不齐,部分生成样本与多数类样本的特征分布距离较近,反而容易降低少数类的类别表征质量,使得分类更加困难。
考虑到Al-Stouhi等[15]采用基于实例的迁移学习方法,对源域数据赋予不同的权重,提升少数类类别表征质量,可以有效提升分类模型性能的情况,本文提出了一种联合迁移学习和强化学习的不平衡样本分类方法。所提模型采用少数类上采样的方法,将生成样本集看作源域,已有训练集看作目标域,通过建立强化学习智能体,对源域知识进行捕获并引入目标域中,来解决不平衡样本少数类类别表征质量差的问题。由于对生成样本进行了筛选,本文提出的方法能够克服传统上采样不平衡分类的算法中部分生成样本质量较差导致类别表征质量较差的问题,在测试过程中,智能体能够自动地将生成样本集中有利于少数类表征强化的样本挑选进训练集,在降低训练集中样本不平衡度的同时,提升了少数类别的表征质量,达到了提升不平衡样本分类效果的目的。
1 模型结构
设二分类不平衡数据集表示为X={xi|xi∈n,i=1,2,…n}, 多数类和少数类对应的样本数量分别为m0,m1, 不平衡度为m0/m1。 采用SMOTE算法生成少数类样本集Xg,Xg中的样本数量为 |Xg|=m0-m1。 本文中将为生成样本集Xg视为源域,用Ds表示;将当前训练集Tt视为目标域,用Dt表示,在初始迭代时刻,即t=0时,当前训练集即为原始不平衡样本集,即T0=X。
本文模型结构由先验知识获取模块、生成样本选择模块和分类器模块3部分组成,如图1所示,这3个模块依次串行连接,通过前两个模块的不断迭代,训练集不断地从源域中引入有助于提升分类性能的样本,提升最终分类器在不平衡样本上的分类效果。整个模型的输入是不平衡数据集X和生成样本集Xg, 输出为训练好的目标域分类器Ctar。 首先,利用Tt对先验知识获取模块中的源域分类器Csou进行预训练,将Xg输入训练好的Csou, 获取到生成样本xi∈Xg的分类结果,并将其作为Ds先验知识,用于向Dt传递。然后,生成样本选择模块中的智能体Agent根据xi的分类结果,赋予xi一定权重,根据权重对其进行筛选,将权重大的xi添加进训练集得到筛选后数据集Tt+1。通过反复迭代,对每一个生成样本xi∈Xg进行筛选。最后,将Tt作为Ts, 并利用Ts训练目标域分类器Ctar, 在测试集上验证分类效果。本章节将分别对先验知识获取模块、生成样本选择模块和训练分类器3部分进行详细介绍。
1.1 先验知识获取模块
先验知识获取模块结构如图2所示,包含了一个源域分类器Csou。 在初始状态,Csou以T0作为训练集进行预训练,训练结束后,对xi进行分类并得到结果。在每次迭代中,xi会不断引入Tt(t=0,1,2…epoch), 训练集的更新会导致Csou不断更新。在每次迭代时,xi都能够根据Csou的变化而输出不同的分类结果,利用该结果可以计算当前样本对分类问题的贡献度r, 并将r作为先验知识输入到生成样本模块,当r较大时,表明当前样本对分类问题的贡献度较大,反之则较小。受到Lin等[16]的启发,为了缓解训练初期样本不平衡度过高引起的模型过拟合,采用Focal loss作为评价当前样本贡献度的损失计算函数。该模块的训练过程如算法1所示。
算法1:先验知识获取算法
输入:当前状态训练集Tt, 当前状态生成样本集Xg, 生成样本xi∈Xg。
输出:生成样本xi的分类贡献度r。
步骤1 在当前状态训练集Tt上训练Csou_t, 在集合Tt∪xi上训练Csou_t+1;
步骤2Csou_t在Xg上测试,并计算平均Focal loss,记为ave_Focallosst;Csou_t+1在Xg
步骤3 返回生成样本xi的先验知识r=ave_Focallosst-ave_Focallosst+1。
1.2 生成样本选择模块
生成样本选择模块包括一个强化学习智能体Agent,其功能是判断是否将生成样本xi∈Ds加入到Tt中,生成样本选择模块在执行中的流程如图3所示。整个生成样本选择模块的作用是,基于前序模块输出的先验知识,判断当前xi是否有助于提升不平衡分类的效果,并通过引入贡献度大的xi, 提升训练数据集Tt中的样本量与多样性。
如图3所示,在每一次迭代过程中,Agent执行是否选择xi的动作,并获得对应的动作奖赏R。生成样本选择模块在状态(S)-动作(A)-状态(S′)的迭代过程中学会对生成样本的选择策略。本文采用强化学习来解决这种不可微分的优化问题。
强化学习的智能体Agent采用“试错”的方式与环境ENV交互,在环境的某一状态下,Agent选择一个动作执行,环境状态发生变化同时反馈一个奖励信号,Agent根据奖励信号和当前环境状态再选择下一个动作使受到正奖励的概率增大。
本文中Agent与ENV交互的过程可以近似看作用元组
在迭代结束后,不平衡数据集X和生成样本集Xg经过本模块之后得到筛选后样本集Ts。 本文利用强化学习算法DQN[17]来优化生成样本选择模型,设Q网络Qθ(st,at), 网络参数为θ, 经验记忆M, 记忆容量为N, 衰减因子为γ。 利用强化学习智能体对样本进行选择的过程如算法2所示。
算法2:生成样本选择算法
输入:不平衡数据集X, 生成样本集Xg。
输出:筛选后样本集Ts。
步骤1 初始化Q网络参数为θ, 目标Q网络Q′参数θ′=θ, 经验记忆M, 筛选后样本集Ts=∅, 更新频率C, 当前状态st=st+1=xi∈Xg,Tt=X;
步骤2 当前状态st=st+1;
步骤3 在Q网络中输入st, 得到所有动作的Q值。采用ε-贪婪算法在当前Q值输出中选择动作at;
步骤4 执行动作at, 并转化至下一状态st+1。 如果选择加入当前生成样本xi, 则
Tt=Tt∪{xi},Xg=Xg
(1)
步骤5 计算动作回报rt=Information(xi,Tt);
步骤6 保存记忆M=M∪{st,at,st+1,rt};

yj=rj+γmaxa′Q′(s′j,a′j)
(2)
步骤8 使用如下均方差损失函数更新Q网络参数θ
(3)
步骤9 每迭代C次,更新目标Q网络参数θ′=θ;
步骤10 重复步骤2至步骤9,直至迭代结束;
步骤11 返回Ts=Tt。
1.3 分类器训练
分类器训练部分如图4所示,包括一个目标域分类器Ctar, 通过Ctar的分类效果来评价本文模型在不平衡二分类问题上的性能。Ctar的输入为生成样本选择模块的输出Ts,Ctar经过训练后,在测试集上检验分类效果。为了更好评价本文模型的性能,避免偶然性,采用多次测试的平均值作为实验结果。
2 数据集
2.1 数据集描述
为验证本文算法有效性,本文从UCI数据库中选择了7组数据集page-blocks0、pima、segment0、vehicle1、yeast1、vowel0、wisconsin进行测试,其中少数类样本的标签为“1”,多数类样本的标签为“0”。各数据集信息见表1。
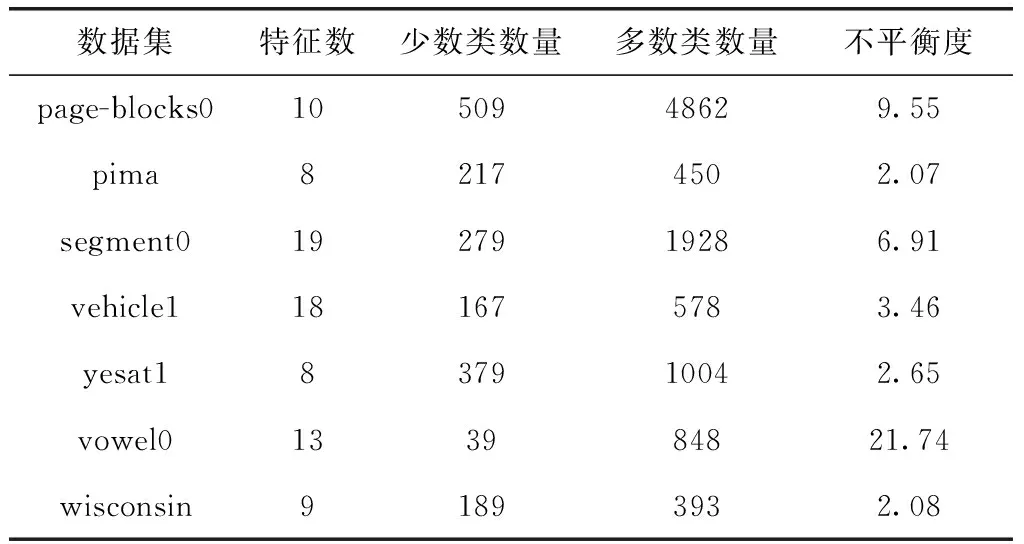
表1 数据集信息
从表1可以看出,在本文所选的数据集中,特征数最多为19,最少为8;不平衡度最高为21.74,最低为2.07。这些数据集之间的差距较大,分类难度不同,可以有效验证本文模型的有效性和泛化性。
2.2 评价指标
对于不平衡数据分类问题,分类器将所有样本都预测为多数类,就能够达到较高的正确率,因此不能采用正确率作为评价指标。为了更好评价分类器的性能,本文基于表2所示的混淆矩阵计算了G_mean作为评价指标,G_mean的计算方式如下
(4)
G_mean同时考虑了少数类和多数类的准确率,其中,TP/(TP+FN) 称作召回率Recall, 表示正确分类的正类个数占实际正类个数的比例;TN/(TN+FP) 称作特异性Specificity, 表示正确分类的负类个数占实际负类个数的比例。G_mean是一个综合的分类器性能指标,能够更好评价分类器的分类效果。当分类器将所有的样本都预测为正类或负类时,G_mean为0,只有当正类样本和负类样本的分类正确率同时较高时,G_mean才能取得较大值。

表2 混淆矩阵
3 实验结果与分析
3.1 实验分析
本文实验设置如下:源域分类器Csou为支持向量机(support vector machines,SVM),目标域分类器Ctar为多层感知机(multi-layer perceptron,MLP)。实验使用64位的Ubuntu16.04系统,处理器型号为Intel(R) Core(TM) i7-7700K CPU @4.20 GHz,内存8 G,显卡型号为 GeForce GTX 1080Ti,显存11 G。算法的实验基于python语言和Pytorch深度学习框架。
为了验证本文所提算法的有效性,共选取了12种对比算法进行了验证。对比算法包括SMOTE、RANDOM OS、ADANYS、Border SMOTE、SMOTE ENN、SMOTE TOMEK、RANDOM US、NEAR MISS、ENN、ALL KNN、OSS。所有对比算法的数据集设定与本文所提算法实验保持一致,并同样以相同的Ctar作为分类器,以G_mean作为评价指标。实验对所有的方法分别执行了10次,并对10次的结果取平均值作为算法最终结果,提升了实验的可信度。
按照上述设置在表1所列7个不平衡数据集上进行实验,不同数据集上各算法的结果见表3。
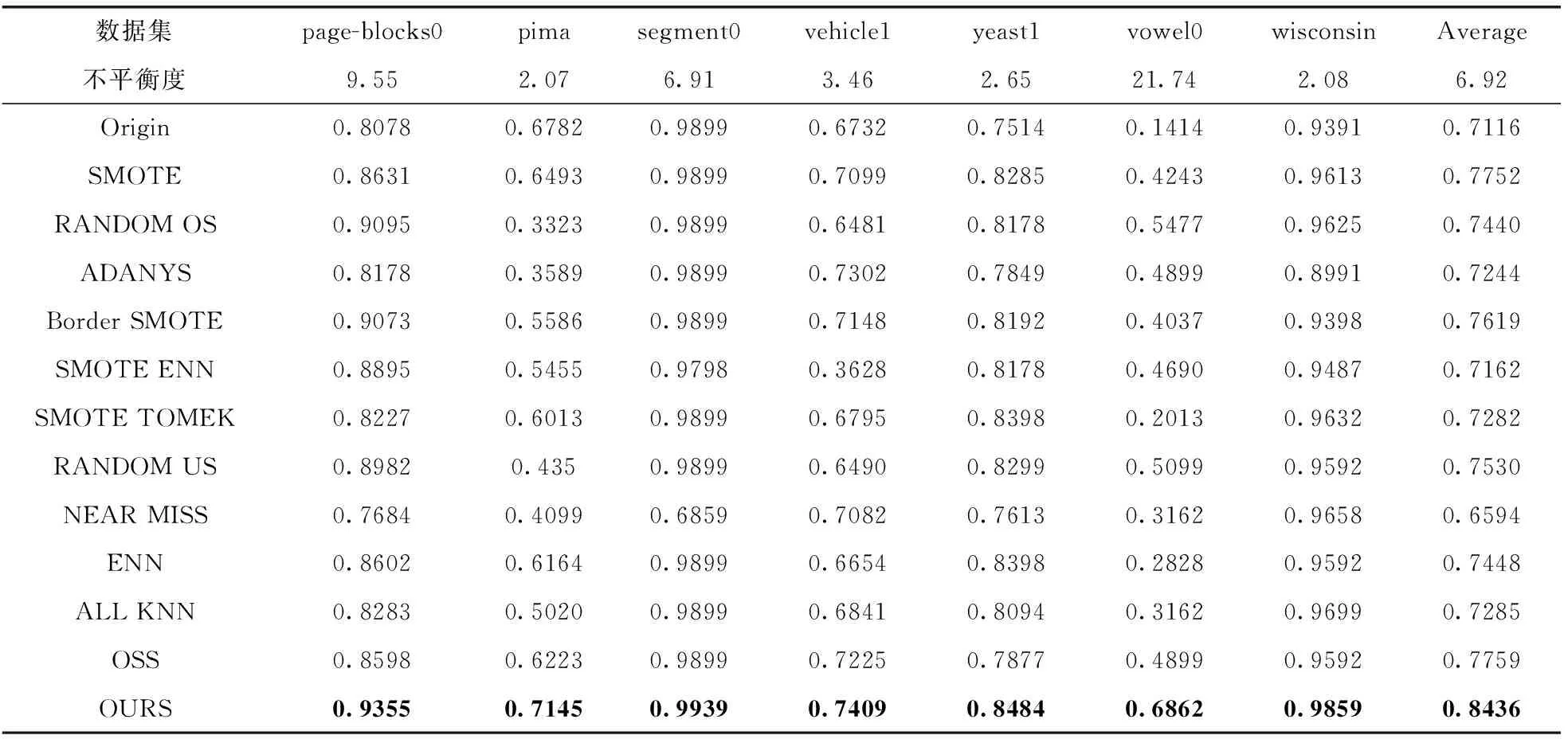
表3 各数据集上对比算法与本文算法的分类结果
从表3中可以看出,与上采样算法(SMOTE、RANDOM OS、ADANYS、Border SMOTE)、下采样算法(RANDOM US、NEAR MISS、ENN、ALL KNN、OSS)和混合采样算法(SMOTE ENN、SMOTE TOMEK)相比,本文算法在7个数据集上的平均值均高于其它对比算法,这一结果验证了本文算法的有效性。在样本特征数和不平衡度各不相同的数据集上均能有较好的分类结果,这表明了本文算法针对不同平衡度的数据集同样具有较好的分类能力。
统计发现,本文算法分类效果与SMOTE算法的分类效果密切相关,例如在pima和vehicle1原始不平衡数据集上, 分别为0.6792,0.6732;采用SMOTE算法之后, 分别为0.6493,0.7099;采用本文算法后, 分别提高至0.7145,0.7409。在两个原始不平衡数据上非常接近,但是由于SMOTE算法在pima数据集上效果较差,甚至降低了,导致本文算法的提升效果也较低。这是因为生成样本的质量对分类效果的影响,关于样本生成算法的讨论见3.5节。
从表3中还可以看出,在不同数据集上,整体上各算法的性能呈现相同的趋势,例如在segment0数据集上,由于该数据集样本数较大,特征数量较多,分类难度较低,各算法的分类效果普遍较优,大多数算法的G_mean都可以达到0.98以上,而在vowel0数据集上,由于该数据集不平衡度很高,样本数目较少,分类难度较大,各算法的分类效果都不尽如人意, 最高仅为0.6862。
另外,在page-blocks0数据集上,Border SMOTE算法性能优于SMOTE算法,但是在pima数据集上,SMOTE算法性能优于Border SMOTE算法,这是因为相对于SMOTE算法,Border SMOTE算法更加注重对边界样本上采样,pima数据集中样本数量较少,边界样本的数量更少,影响了Border SMOTE算法的性能。在segment0数据集中,NEAR MISS算法的分类效果明显低于其它算法,这是因为该数据集初始的类别表征质量较好,采用基于KNN的下采样方法来删除多数类样本,导致多数类样本的关键信息丢失。
3.2 先验知识获取方法的有效性分析
为验证本文模型利用不同类型的源域分类器Csou和目标域分类器Ctar来获取先验知识的有效性,首先在本文模型的基础上将Csou改为与Ctar相同类型的MLP,其它结构不变,修改后的模型记为R-Transfer,然后在表1所列7个不平衡数据集进行实验,各数据集的评价指标G_mean如图5所示。
从图5中可以看出,在所有数据集上,本文模型的分类效果都优于R-Transfer模型,验证了Csou和Ctar为不同类型的分类器的必要性:利用不同类型分类器之间的知识迁移,获得的先验知识更有利于生成样本的筛选。
3.3 生成样本选择方法的有效性分析
为验证本文模型利用强化学习算法对样本进行筛选有效性,将本文模型改成非MDP过程,对本文模型进行如下修改:先验知识模块中Csou停止更新,将生成样本选择模块中的Agent删除,利用阈值截断方法对生成样本xi进行筛选,当r>0时选择该样本,否则丢弃该样本。修改后模型记为R-RL,然后在表1所列7个不平衡数据集进行实验,各数据集的评价指标G_mean如图6所示。
从图6中可以看出,本文模型在所有数据集上的分类效果都优于R-RL模型,验证了本文模型采用强化学习算法进行样本筛选的必要性:生成样本选择模块利用强化学习算法,通过先验知识获取模块得到当前生成样本xi在当前训练集Tt中的先验知识,更有利于生成样本的筛选。
3.4 不同类型源域分类器对分类效果的影响分析
为了比较不同类型源域分类器Csou对分类效果的影响,在本文模型的基础上将Csou分别修改为朴素贝叶斯(Naive Bayes,NB)、自适应提升算法(adaptive boosting,AdaBoost)、决策树(Decision Tree,DT)、逻辑回归(logistic regression,LR)、梯度提升(gradient boosting,GB)、随机森林(Random Forest,RF)、KNN。然后在表1所列7个不平衡数据集进行实验,各数据集的评价指标G_mean见表4。

表4 不同类型Csou分类结果
从表4中可以看出,在各数据集上,与原始数据和未筛选样本的SMOTE算法相比,更换不同类型Csou的本文模型总能取得较好的分类结果,验证了本文模型的有效性。对于不同类型的Csou, 本文模型都能从Ds中获取到先验知识,并利用先验知识对生成样本进行筛选来平衡样本特征分布,提升类别表征质量,提高不平衡数据的分类效果。
此外,表4还可以看出,在不同的数据集上,不同类型的Csou对分类结果的影响不同。例如,在pima数据集上,Csou为KNN时的分类效果比Csou为NB时的效果好,但是在page-blocks0上,Csou为KNN时的分类效果比Csou为NB时的效果差。在大多数数据集上,本文算法(Csou为MLP)能够比Csou为其它类型分类器的分类效果好。
3.5 不同样本生成方法对分类效果的影响分析
为了比较不同样本生成方法对分类效果的影响,在表1所列7个数据集上,分别采取了ADANYS、Border SMOTE算法进行上采样得到生成样本集,用本文模型对生成样本进行筛选并分类,分类效果见表5。
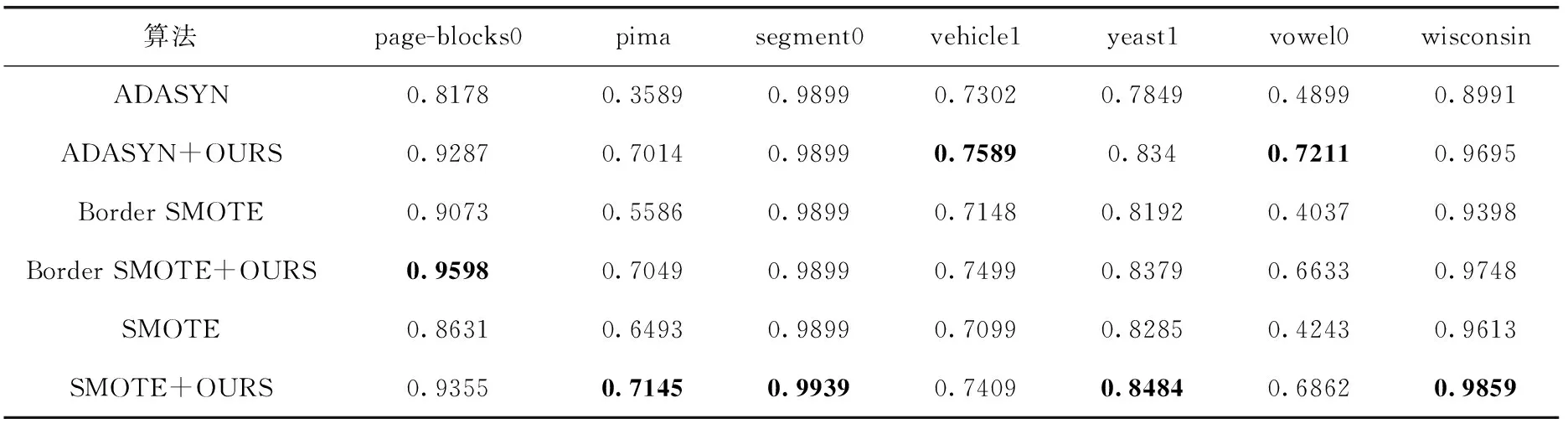
表5 不同样本生成方法分类结果
由表5可以看出,在各数据集上,不同的样本生成算法与本文模型相结合都能取得更优的结果,验证了本文模型具有较好的泛化能力。对于不同算法产生的生成样本,本文模型都能利用Ds中的先验知识,对其进行筛选来平衡样本特征分布,提升类别表征质量,提高不平衡数据的分类效果。
此外,从表5中还可以发现,分类效果与样本生成算法密切相关,生成样本的算法越好,生成样本经过本文模型后的分类效果越好。例如,在pima数据集上,SMOTE算法分类效果优于ADASYN算法和Border SMOTE算法,G_mean为0.6493;经过本文模型,对生成样本筛选后,SMOTE算法的分类效果也较优,G_mean提高至0.7145。
4 结束语
本文对不平衡数据分类问题进行了研究,针对上采样生成样本的质量参差不齐,少数类的类别表征不好的问题,提出了一种联合迁移学习和强化学习的不平衡数据分类方法。所提模型采用少数类上采样的方法,将生成样本集看作源域,已有训练集看作目标域,通过建立强化学习智能体,对源域知识进行捕获并引入目标域中,来解决不平衡样本少数类别表征质量差的问题。在测试过程中,智能体能够自动地将生成样本集中有利于少数类表征强化的样本挑选进训练集,在筛选后的数据集中,两类样本特征分布之间的距离较大,数量较为平衡,容易获得高质量的类别表征。实验结果表明,本文方法具有较好的泛化能力,可以有效提高分类器的在不平衡分类问题上的性能。未来的研究将面向多类别的不平衡分类问题,尝试从多种源域分类器获得先验知识,进一步提高不平衡数据分类的效果。
