基于自动编码器的内部威胁检测技术
2022-10-17孙小双
孙小双,王 宇
(1.航天工程大学 研究生院,北京 101416;2.航天工程大学 航天信息学院,北京 101416)
0 引 言
相比于外部威胁,内部威胁具有隐蔽性、多样性及高危性。内部威胁活动通常分布在大量正常行为中,而且内部威胁需要处理和分析大量不同类型的数据,从网络流量、文件访问日志、电子邮件记录,到员工信息等,如何从海量数据中挖掘关联信息、识别内部威胁依然是内部威胁检测技术面临的难题。
基于行为特征的内部威胁检测主要是从数据中提取行为特征向量或者对行为序列建模,在此基础上进行异常检测。由于异常行为和异常用户具有未知性,异常检测方法通常采用无监督学习方法。而传统的无监督机器学习方法受到特征维度限制,本文提出基于自动编码器的内部威胁检测方法,旨在通过深度学习模型从广泛的审计数据中学习非线性相关性,检测异常行为。
1 相关研究
内部威胁检测相关研究较为丰富。文献[1-3]从不同视角梳理了内部威胁的发展历程、技术研究和挑战等。内部威胁检测技术发展过程中运用的主要方法包括基于规则的方法、统计分析法、图算法、机器学习等。统计分析法运用数学方式建立模型,不需要与领域相关的先验知识,对异常事件较为敏感,但是由于主观确定阈值存在有限性和静态性。基于规则的方法利用专家库生成规则识别内部恶意人员,在结果固定且类别较少的分类中是很有意义的,但是它严重依赖领域知识,需要不断对规则库进行更新以应对新威胁。图算法通过数据间的关联关系构建图结构,根据图结构的变化识别恶意行为。例如,Gamachchi等[4]提出了一个基于图形化和异常检测技术的恶意用户隔离框架。该架构主要由图形处理单元(GPU)和异常检测单元(ADU)两部分组成,将多维数据源的数据格式化并送入GPU,GPU生成网络信息资产关系图,并为每个用户计算图参数。然后将计算图和时变数据输入ADU,执行隔离森林算法,输出每个用户的异常分数作为判断标准。文献[5-9]采用浅层机器学习的方法,例如K-means、Support Vector Machine(SVM)、Isolation Forest等,机器学习是在统计学的理论基础上发展起来的,相比于统计分析法,机器学习会牺牲可解释性获得强大的预测能力,在实际应用中具有更高的准确度;而相比基于规则的算法,机器学习可以不断学习新的规则,不需要人工更新规则库。但是面对体量庞大且结构日益复杂的审计数据,传统机器学习方法受到特征维度等因素的限制,研究者又将目光转向深度学习。
目前,应用于内部威胁检测的深度学习模型[10-14]包括卷积神经网络模型(CNN)、长短期记忆神经网络模型(LSTM)、自动编码器神经网络模型(auto-encoder)等及其改进或组合模型。文献[10]使用卷积层从输入样本中捕获局部特征,然后使用LSTM层考虑这些给定特征的顺序。文献[14]利用集成的深度自编码器对重构误差进行学习实现异常检测。文献[14]采用LSTM模型和多头注意力机制来检测异常网络行为模式,并利用Dempster条件规则对信念进行更新,用于融合证据,实现增强预测。与传统机器学习相比,深度学习不需要复杂的特征工程,算法适应性强;而且随着数据量的增大,深度学习在学习能力和检测指标上有着更好的表现。
2 基于自动编码器的内部威胁检测模型
基于自动编码器的内部威胁检测模型采用树结构分析方法,从大量审计日志中分析并构建基于树结构的用户行为特征图,并将树节点表示为用户特征向量。采用自动编码器模型对特征向量进行学习,将输入和输出之间的重建误差作为异常分数,利用Z-score方法判断异常等级。其整体工作流程如图1所示。
2.1 基于树结构分析的特征向量生成
由于审计数据体量大、数据类型多样、结构复杂,本文采用树结构方法[15]分析用户审计数据。通过层层属性分析,形成树形结构,建立的树节点可以用特征向量表示。其优势在于分析速度快,具有良好的扩展性,而且为所有用户提供了行为特征的一致性表示。
如图2所示,先按照时间域和行为域对每条行为记录分类。时间域从工作时间与非工作时间上进行划分,工作时间和非工作时间是通过学习用户日常上下班时间得到的。行为域包括用户的登录行为、网站访问、邮件收发、文件操作、设备使用等,不同行为域的活动变化反映了用户不同的意图。可以根据实际情况对行为域进行扩展,从而更全面地刻画用户行为特征。
在行为域下,行为记录接着按照设备-活动-属性的树结构进行分析。设备是指用户登录的设备型号;活动是指用户在某行为域下的具体操作,例如文件的复制、粘贴、删除等;属性指操作行为附带的特征,例如收发邮件的附件大小、数量等。
通过树结构分析,如果得到的节点在原树结构中存在,则节点的计数值增加,如果不存在,则插入该新节点,最后得到用户在一段时间内的基于树结构的行为特征图。行为特征图可以编码为特征向量,长度取决于树结构分析中的节点数目。由于不同节点间存在时间或行为的关联关系,可以通过对不同节点进行组合获取新的特征向量,例如非工作时间的活动频率为不同行为域下非工作时间活动频率的总和。
2.2 基于自动编码器的异常检测
2.2.1 模型原理及算法
内部威胁检测属于异常检测的一类,通常采用无监督学习方法,而传统的机器学习方法受特征维度限制,随着维度数升高,检测性能受到影响。本文选择基于自动编码器的异常检测方法,它是一种基于神经网络的无监督学习算法,是PCA类型的模型的非线性扩展,适用于高维数据。通过训练正常数据,自动编码器学习到正常数据的有效特征和内在联系,在对异常数据进行重构时会产生较大误差,有利于检测未知攻击。
设D维样本x(n)∈RD, 1≤n≤N, 自动编码器将数据映射到特征空间,得到样本的编码z(n)∈RM, 1≤n≤N, 并通过这组编码重构原来的样本。最简单的自动编码器是两层神经网络。其中,输入层到隐藏层用来编码,隐藏层到输出层用来解码,层与层之间是全连接关系,自动编码器的网络结构如图3所示。编解码过程中,隐藏层的活性值z为x的编码,x′为自动编码器的输出重构数据,即
z=f(W(1)x+b(1))
(1)
x′=g(W(2)x+b(2))
(2)
其中,W(1)、W(2)为权重矩阵,b(1)、b(2)为偏置,f、g为激活函数。令W(1)=W(2)T, 通过捆绑权重的方式减少自动编码器的参数,易于学习,并在一定程度上起到正则化的作用。
当特征向量输入到自动编码器中,编码器通过学习将数据有效压缩至低维空间,解码器将有效特征重构出与输入特征相近的拟合数据,拟合数据与输入数据的差值为重构误差(reconstruction error)。自动编码器正是通过最小化重构误差来有效学习网络参数的,即重构数据趋近于真实数据。异常检测中把重构误差作为异常分数来识别异常用户。其计算方法如下所示
(3)
基于自动编码器的异常检测算法步骤如下:
输入:按时间顺序依次输入某用户第i天的行为特征向量xi=[xi,1,xi,2,…,xi,m],m为特征向量的长度。
步骤1 初始化函数。
步骤2 对特征向量进行归一化处理。
步骤3 输入训练数据,通过反向传播学习确定参数W、b。
步骤4 输入测试数据,计算重构误差。
输出:按时间顺序依次输出某用户第i天的行为特征向量的重构误差。
2.2.2 模型体系结构及参数
自动编码器体系结构的设计对自动编码器的性能有重要影响。主要需要考虑以下几个方面:
(1)神经网络深度。神经网络深度加深能增强特征的抽象程度和网络的表达能力,但同时网络中的超参数会增多,从而提高计算复杂度和训练难度。本文通过实验对比不同网络结构的自动编码器,既可以得到良好的特征表达,又能降低计算复杂度;
(2)损失函数。为了最大化正常和异常用户行为之间的可分性,选择损失函数来惩罚结构差异。因此,与熵相关的损失函数,如交叉熵损失函数(cross-entropy loss function)等,可能优于传统的距离度量指标,如均方误差(mean squared error)等。而且,交叉熵损失函数在误差大时权重更新快,误差小时权重更新慢,可以解决均方误差损失函数权重更新过慢的问题;
(3)dropout rate。在输入层和隐藏层后分别加入dropout层,使输入数据和隐藏层神经单元按一定概率随机从网络中暂时丢弃,相当于减少中间特征的数量,增加每层特征之间的正交性,防止模型的过拟合,增强模型的泛化能力。
2.3 基于Z-score方法的异常等级分类
Z-score是一种低维特征空间中的参数异常检测方法。它假定数据服从于高斯分布,异常值通常是分布尾部的数据点,远离数据的平均值。距离的远近取决标准差分数zi和设定阈值zth间的关系
(4)
其中,μ为原始数据的均值,σ为原始数据的标准差,zi表示了给定数据距离其均值的相差的标准差个数。这种方式将数据归一化,提高了数据的可比性。
内部威胁行为类别多样,异常分数与正常行为的分数差值也大小不一。部分异常行为隐藏在大量正常行为中,其经过异常检测所得的异常分数与正常行为差较小,如果阈值设置过高可能会忽略这部分异常行为,而阈值设置过低则会导致误判率升高,所以本文中的zth选取了1、2、3这3个不同的阈值,对用户异常行为进行了等级划分,根据不同异常等级的行为出现的频次综合判定用户是否异常。
3 实验分析
3.1 实验准备
3.1.1 实验设计
通过相关理论研究,本文对autoencoder的神经网结构和各项参数进行实验设计,并将结果进行对比。另外,分别对PCA、isolation forest、autoencoder等异常检测方法进行实验设计,并将结果进行对比。通过准确率、精确率、召回率、ROC曲线和PR曲线对以上方法进行评估。
3.1.2 环境配置
实验环境信息描述如下:系统环境为Windows操作系统;硬件配置为Inter(R)Core(TM)i7-7700H CPU@2.7 GHz,NVIDIA GeForce GTX1060,16 G内存IT硬盘;实验框架为TensorFlow 2.1深度学习框架;开发语言为Python。
3.1.3 数据集选取
内部威胁数据在检测算法的研究中至关重要,没有可靠合适的数据,任何检测技术都很难达到预期的效果。本文采用卡耐基梅隆大学CERT项目的内部威胁数据集进行实验。
该数据集数据类型丰富,包括了主机日志、网络日志、员工心理评价以及人力资源信息等,包含了1000名用户502天时间里的320 770 727条行为记录,是一个比较全面的内部威胁检测数据集,其具体内容见表1。

表1 CERT-IT数据集
CERT-r4.2数据集从真实企业环境中采集,并加入了人工制造的攻击行为,例如数据泄露、系统破坏等。其所包含的攻击场景概括如下:
(1)用户开始在非工作时间登录账户,使用可移动存储设备,并向某些网站上传数据,存在数据泄露的风险;
(2)用户频繁浏览求职网站,并频繁使用可移动存储设备拷贝数据,存在窃取数据并跳槽的风险;
(3)用户下载一个键盘记录程序,然后用可移动存储设备把它传送到他上司的设备上。根据收集到的键盘日志,以上司的身份登录账户,并群发邮件,在组织中引起恐慌。
3.2 评价标准
本文采用准确率(accuracy)、精确率(precision)、召回率(recall/TPR)、ROC曲线和PR曲线作为评测指标。准确率、精准率和召回率是根据混淆矩阵中的TP(true positives)、FP(false positives)、TN(true negatives)、FN(false negatives) 等计算得到的,见表2。

表2 混淆矩阵
准确率表示预测正确的样本在总样本中的比例,精确率表示真阳性样本占预测为正样本的比例,召回率表示真阳性样本占实际为正的样本的比例,计算公式如下
(5)
(6)
(7)
(8)
ROC曲线是分类问题的一种性能度量,AUC则是曲线下的面积,表示分离度,AUC值越大,模型的分类效果越好。但是,当数据样本不平衡时,ROC曲线不能很好地反映模型性能,而PR曲线能解决这个问题。PR曲线展示的是以精确率为横坐标、以召回率为纵坐标的曲线,PR曲线与ROC曲线的相同点是都采用了TPR,都可以用AUC来衡量分类器的效果。不同点是ROC曲线使用了FPR,而PR曲线使用了精确率,因此PR曲线的两个指标都聚焦于正例。由于数据不平衡问题中主要关心正例,所以在此情况下,PR曲线被广泛认为优于ROC曲线。
3.3 实验结果及分析
通过对用户数据的树结构分析生成了用户每日的特征向量,对特征向量求和即得该用户当日的活动频率。如图4所示,左图展示了用户CCL0068在268天时间中的活动频率变化(为方便观察,数据中不包含周六、周日的活动),从图中可以观察到用户大致在第250天左右的活动频率增加,表明该用户可能存在异常行为。
将特征向量按时间顺序输入自动编码器中,得到用户每日的异常分数,异常分数越高表示用户行为异常的可能性越大。右图展示了用户CCL0068的异常分数变化情况。从图中可以观察到第250天左右的异常分数明显偏高,说明该用户存在异常行为,其异常行为的具体时间域需要进一步分析。
但是,由于内部人员具有合法身份,内部攻击行为可能只有几个细微的异常动作,并隐藏在大量正常行为中,难以发现;而且内部人员熟悉系统的安全防护机制,可以有效规避安全防护检测。如图5所示,左图展示了用户BSS0369在219天时间中的活动频率变化,几乎很难从活动频率的变化中发现异常情况,但在右图展示的该用户的异常分数变化中,可以明显看出该用户某几天的行为中存在异常,需要进一步对其各项活动进行分析。
为了验证基于自动编码器的异常检测方法的有效性,本文将自动编码器与PCA方法[15]进行了对比,其中PCA中的n_components值为3,自动编码器的具体参数见表3。前期,对特征向量进行归一化处理,使两种方法具有相同的输入值,比较两种方法的ROC曲线和PR曲线及其覆盖面积大小。
两种方法的ROC曲线和PR曲线对比如图6、图7所示,曲线覆盖面积对比见表4,从面积覆盖值中可以看出,自动编码器的检测效果要好于PCA方法。
由于内部威胁行为类别多样,异常分数的判别阈值也不是固定的。从实验中可以发现固定判别阈值,如果阈值设置过高可能会忽略部分异常行为,而阈值设置过低则会导致误判率升高,所以本文采用Z-score方法,其中Zth选取了1、2、3这3个不同的阈值,对用户异常行为进行了等级划分,1、2、3分别表示了低、中、高3个异常等级,结合其出现的频率判断异常用户。
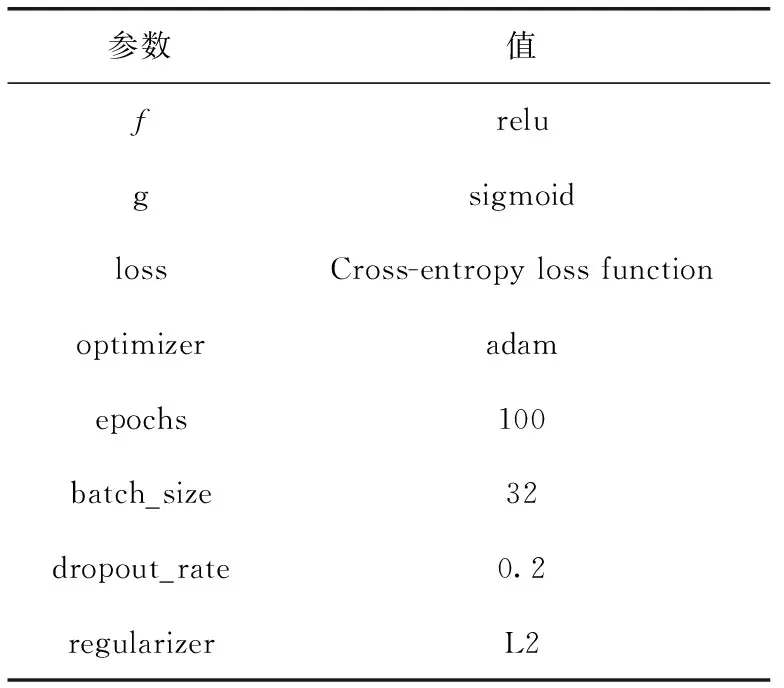
表3 实验参数设置
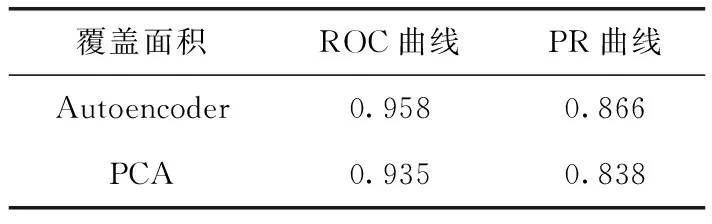
表4 曲线覆盖面积对比
实验中,将70名异常用户和剩余正常用户中随机挑选的70名用户混合进行测试,结果如图8所示。其中,正常用户与异常用户均判断正确,7名疑似用户需要进一步结合其它数据进行分析。
4 结束语
本文采用基于自动编码器的内部威胁检测方法,首先对用户数据进行树结构分析,对于大量多源异构数据的处理速度快且可扩展性高。树结构分析得到的特征向量输入异常检测模型中,异常检测模型将自动编码器和Z-score方法相结合,通过自动编码器得到异常分数,采用Z-score方法对异常分数分级后判断异常用户。自动编码器能学习到正常数据的有效特征和内在联系,且随着特征扩展,也适用于高维数据。实验结果表明,该方法是一种有效的检测方法。
下一步工作将扩展内部威胁检测中的行为特征,对上述实验中的疑似用户进行进一步判断,提高准确率并降低误判率;进一步研究用户行为特征间的关联关系,对用户的攻击行为和攻击意图进行全面分析,结合用户画像技术对用户的攻击行为建立画像模型。
