基于Yolov3网络的无人驾驶汽车车辆目标的检测*
2022-10-04罗国荣
罗国荣
(广州科技职业技术大学 自动化工程学院,广州 510550)
0 引言
随着我国人们生活水平的提高,汽车已普遍进入千家万户,而城镇化的快速发展导致城市人口越来越密集,以致道路交通压力也不断上升.与此同时,道路阻塞、安全事故频发等问题严重影响了人们的出行和生命安全,人们为解决这些问题设计开发无人驾驶汽车.无人驾驶汽车安全稳定,不会因人为因素造成交通事故,因此越来越受人们关注.无人驾驶汽车的发展需要道路目标检测技术的支撑,目标检测技术可分为传统的目标检测算法和基于深度学习的目标检测算法.传统的目标检测算法主要依赖人为设计特征,首先从图像中利用穷举法选取候选区域,然后提取其特征,最后利用分类器对其进行分类,然而人为设计特征的泛化性和鲁棒性差,难以适应复杂的实际场景;并且利用穷举法提取候选区域的时间复杂度高满足不了实时性.
基于深度学习的目标检测算法又分为基于候选区域(两阶段)和基于回归(一阶段)两类.基于候选区域的算法主要包括R-CNN、Fast R-CNN、Faster R-CNN等,张昭等针对Faster R-CNN对远距离小目标车辆的检测效果较差的问题,提出了反卷积反向特征融合Faster R-CNN算法.不仅降低了训练难度,而且有效改善梯度消失问题,提高对远距离小目标车辆信息的多尺度特征的提取和表达能力[1];龚强在Cityscapes数据集上,使用Mask R-CNN算法与关键点检测算法进行训练和测试,对道路前方的目标进行检测,提升Mask R-CNN的准确度[2];张晓雪为了提高目标检测精度,使用目标检测分割的经典算法Mask R-CNN,通过在其算法的基础上将浅层特征图与高层特征图相融合来对算法进行优化,最终达到提高Mask R-CNN算法在目标识别的精确度[3],此类检测算法速度普遍较慢,在交通场景中检测的实时性还不能满足,但检测精度在不断提升.
基于回归的算法主要包括Yolov1、Yolov2、Yolov3、SSD等,周慧海等为检测道路场景中远距离的小目标,提出一种改进网络RFG_SSD算法,首先在原SSD主干部分和检测部分之间引入改进特征金字塔网络,其次在检测层使用全局平均池化层替换全连接层,降低参数从而提高检测速度,小目标检测个数相较于原SSD检测个数高出3倍多,小目标检测性能效果显著提升[4];袁不平等针对Yolov3对中小目标检测效果不理想的问题,提出改进算法DX-Yolo(densely ResneXt with Yolov3).首先对Yolov3的特征提取网络Darknet-53进行改进,使用ResneXt残差模块替换原有残差模块,在Darknet-53中引入密集连接,利用K-means算法对数据集进行维度聚类,最后通过试验获得较好的效果[5].蔡英凤等提出了一种SLSTMAT(Social-LSTM-Attention)算法,创新性地引入目标车辆社交特征并通过卷积神经网络提取,建立了基于深度学习的车辆行为识别模型,应用注意力机制来捕捉行为时窗中的多时步信息,实现了周边车辆行为准确识别[6];隗寒冰等提出一种基于网状分类器与融合历史轨迹的多目标检测与跟踪算法,该算法考虑各目标之间的遮挡关系,利用具有目标融合功能的网状分类器对多尺度滑动窗获取的待检窗口进行多目标检测,在处理目标遮挡的复杂场景时具有较好的识别效果[7];罗玉涛等提出一种由摄像头采集的图像信息与激光雷达采集的点云信息进行空间匹配与特征叠加后生成的稀疏彩色点云结构,通过改进的PointPillars神经网络算法对融合后的彩色稀疏点云进行运算,提升了识别平均精度[8];高春艳等提出一种改进的Yolov3目标检测算法,该方法分别从多尺度图像训练、增加Inception-res模块和省去大尺度特征输出分支3个方面对Yolov3网络进行改进,能够更好地检测出藏匿于车底部位的危险品目标[9];程腾等本文提出一种基于特征融合的多层次多模态融合方法,提取针对不同大小目标的层级特征,在此基础上进行多模态的多层次特征融合,并进行6次对比实验验证,取得较好的效果[10];陈琼红等提出一种针对雾天环境下车辆和行人的检测方法.将AOD-Net去雾算法与SSD目标检测算法相结合,实现了城市交通雾天环境下的车辆和行人检测[11].此类算法检测速度快、实时性较好,但是检测精度与准确度相对于两阶段的算法还是较差[12].
为了无人驾驶汽车能在道路上实时检测车辆目标,本文提出一种改进Yolov3算法,该算法是将ResNet50网络代替Darknet-53网络作为基础特征提取网络,舍弃ResNet50网络中第5组及后面的网络,再在此基础上增加2个检测网络,最后设置6个边界框,以提高目标定位的准确率.
1 Yolov3目标检测算法
Yolov3是基于回归的一类目标检算法,其最大特点是检测速度快,能满足实时性要求.其核心思想是将一幅图像划分为互不重叠的网格块,通过回归分析来确定目标及其位置,克服了基于候选区域目标检测算法滑动窗口带来的检测速度慢的缺点.Yolov3结构可分为特征提取块和目标检测块两部分.如图1所示.
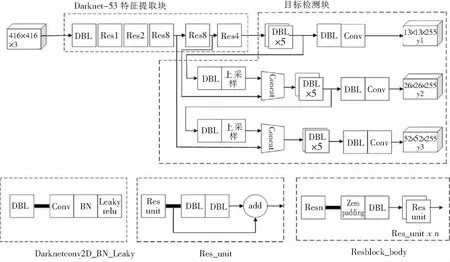
图1 Yolov3结构图Fig.1 Structure diagram of Yolov3
特征提取块采用Darknet-53网络的架构,由DBL(卷积网络)和Resn(残差网络)堆叠而成.卷积网络(DBL)由Conv(卷积)层、BN(归一化)、Leaky relu(激活函数)组成.残差网络(Resn)中的n表示数字,此处分别表示1、2、4、8,由zero padding(零填充)、DBL(卷积网络)和res unit(残差单元)组成.残差单元通过引入shortcut(短路连接),这样可以增加网络深度,同时可以保证网络性能不下降.
目标检测块分别由y1、y2、y3三个不同尺度的检测网络组成.由于浅层卷积网络的卷积计算得到的是物体的边缘信息,边缘信息包含物体的尺寸和位置;而深层卷积网络的卷积计算得到的是物体更为抽象的语义信息,但物体的尺寸和位置随着卷积层的深度增加而逐渐丢失.为了检测图像中不同尺寸的物体,Yolov3的分别由上述三个不同尺度的检测网络,主要方法是将深层特征先进行上采样,使得图像尺寸与不同层次的残差网络的输出特征相同,再将两者进行连接.这种方法即可将深层特征与浅层特征进行融合,实现对场景中不同尺度大小的物体进行检测.
2 改进的Yolov3目标检测算法
目标检测算法的优化主要是从修改Yolov3的基础网络、边界框两个方面进行.
2.1 特征提取网络优化
Darknet-53网络架构的残差单元虽然能在网络加深时抑制收敛变慢的问题,但仍存在训练困难、梯度消失的情况.为了进一步提升网络的特征提取性能,本文在原残差单元的基础上增加1个卷积层,使得网络能够提取出更丰富的特征信息,如图2(b)所示的Res_b结构.改进的残差单为减少通道数量,先在第一层使用1×1卷积核,接着采用3×3卷积核进行特征提取,最后采用1×1卷积核恢复通道数量,这样在不增加参数的情况下拓展了卷积网络的宽度,因此降低了模型的复杂度,提高了网络的运行效率.另外,为了防止残差单元输入和输出的维度不同导致残差单元之间不能连续串联,在短路连接处增加1个卷积层,用于改变残差单元的输出维度,方便后续的残差单元串联,如图2(b)所示的Res_a 结构.
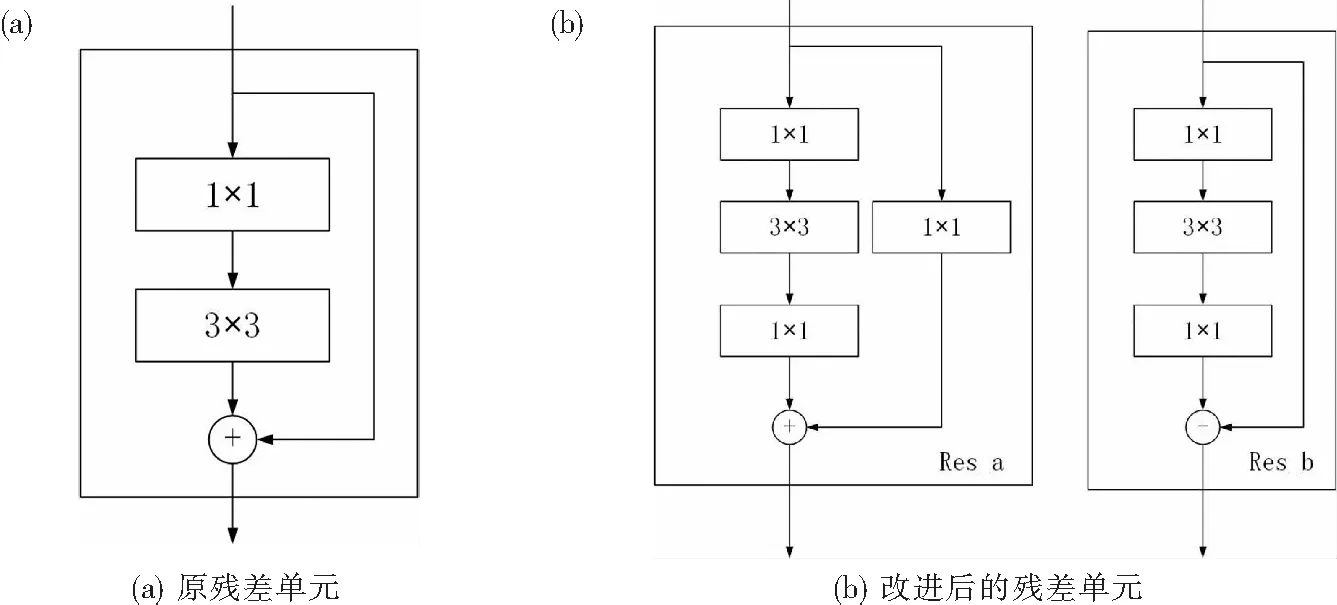
图2 残差单元结构图Fig.2 Structural diagram of residual cells
在改进后的残差单元的基础上用ResNet50网络代替Darknet-53网络作为基础特征提取网络,并舍弃第5组及后面的网络,然后在ResNet50网络中第Res4组的第2个res_b后增加一个Yolo2检测输出网络,然后在第4组的最后1个block再连接一个Yolo1检测输出网络,以提升车辆目标的检测准确率,其中Yolo1与Yolo2网络结构相同,基础特征提取网络框架如图3所示.
2.2 边界框优化
边界框大小是采用一种基于交并比(IoU)距离度量的K-均值(K-means)聚类算法进行计算.首先统计图像数据集中的真实标注框,方法是计算每幅图像真实标注框的纵横比和面积,组建一个纵横比-面积数据集,并绘制纵横比和面积关系图,如图4所示.
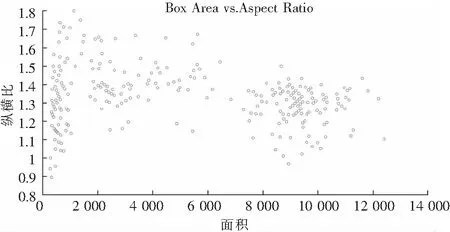
图4 纵横比与面积关系图Fig.4 Horizontal and horizontal ratio and area relationship
从图4可以看出,具有相似纵横比和面积的标注框聚集在一起,此处利用K-均值聚类距离的算法对边界框的大小进行计算,其计算公式为:
d=1-IoU,
(1)
(2)
式中:d为边界框与标注框的距离;IoU为边界框与标注框的交并比;A为边界框;B为标注框;area(A∩B)为边界框与标注框相交的面积;area(A∪B)为边界框与标注框相并的面积.
K-均值聚类算法流程如下:
(1)采用K-means ++ 算法选择K个均值聚类初始簇中心集合α={α1,α2,α3,…,αk}.
(2)针对纵横比-面积数据集中每个样本xi,计算它到K个聚类中心的距离并将其分到距离最小的聚类中心所对应的类中.
(3)针对每个类别ci,重新计算它的聚类中心,计算公式如下:
(3)
式中,x是属于类别ci的一个数据点.
(4)重复步骤2到3,直到簇分配不变,或达到最大迭代次数.
由于K-means算法的初始聚类中心需要人为确定,而且不同的初始聚类中心会产生不同的聚类结果.为了改善K-means算法,采用了K-means ++ 算法自动地确定聚类初始簇中心集合.其算法流程如下:
(1)从输入的数据点集合中随机选择一个点作为第一个聚类中心,表示为α1.
(2)对于数据集中的每一个点xi,计算它与最近聚类中心(指已选择的聚类中心)的距离,表示为d(xi,αj).
(3)选择一个新的数据点作为新的聚类中心α2,选择的原则是:d(xi,αj)较大的点,被选取作为聚类中心的概率较大.
(4)重复(2)和(3)直到K个聚类中心被选出来.
最后设置6个边界框,以提高目标定位的准确率.
3 实验与结果
3.1 实验环境设置
开发环境使用win10操作系统,软件环境平台为matlab2021.在硬件配置上CPU使用英特尔酷睿i9-7900X; GPU为英伟达GTX 1080Ti 11G显存.
实验采用的图像是通过对行车记录仪记录的视频按一定的时间间隔进行截取,包含市区、乡村和高速公路等场景采集的真实图像数据,共350张,通过图像数据增强技术,对原始图像进行旋转、移动、缩放、倒影、剪切变换、颜色抖动增强等变换,如图5所示.

图5 图像数据增强Fig.5 Image data enhancement
变换后的图像集为2 800张,并将数据集以7∶1∶2的比例分成训练集、验证集和测试集.并应用matlab内置的“image labeler”标注工具将每张图像的汽车对象标注出来.
训练设置如下:最大世代(epochs)次数为80,最小批尺寸大小为8,学习率为设置为动态,分指数上升期、稳定期和下降期三个阶段,其中初始学习率为0.001,训练期间学习率的变化如图6所示.
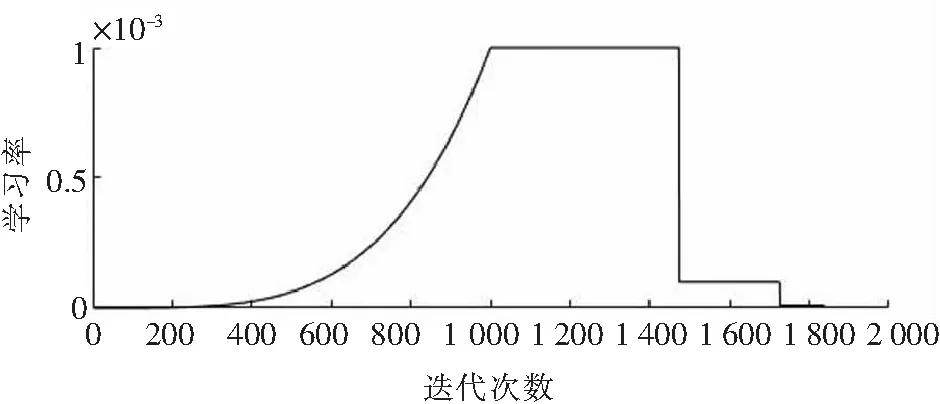
图6 训练学习率Fig.6 Training learning rate
L2正则化因子设置为0.000 5,惩罚阈值设置为0.5,与真实值重叠小于0.5的检测将被惩罚,采用随动量变化的随机梯度下降(SGDM)的求解算法沿着损失函数的负梯度方向更新网络参数.
3.2 实验结果及分析
训练损失由边界框、置信度和分类这三种部分构成的误差组成,其中边界框采用均方差计算,置信度和分类采用二值交叉墒计算,其损失函数计算公式为:
(4)
(5)
(6)
totalloss=boxloss+clsloss+objloss,
(7)

训练损失结果如图7所示.可以看出,整个训练期间,边界框损失和分类损失维持在低值范围,说明边界框和分类的预测较准确,而置信损失经过200次迭代从1 180下降到90,说明训练收敛速度较快,而且逐渐接近0,说明训练学习率的设计较为合理.三者叠加起来的总损失能使模型训练损失接近0,说明模型的训练是成功的.
模型训练结束后,需要对模型进行评估,评估指标采用平均精度(mAP)、精确率(precision)和召回率(recall),结合本文场景,平均精度(mAP)计算如下:
(8)
式中:Ci为单张图片中目标检测的精确率;n为图片总数.
精确率(precision)计算如下:
(9)
式中:TP为模型预测为正样本,实际为正样本,即是被正确检出的样本数;FP为模型预测为正样本,实际为负样本,即是被错误检出的样本数.
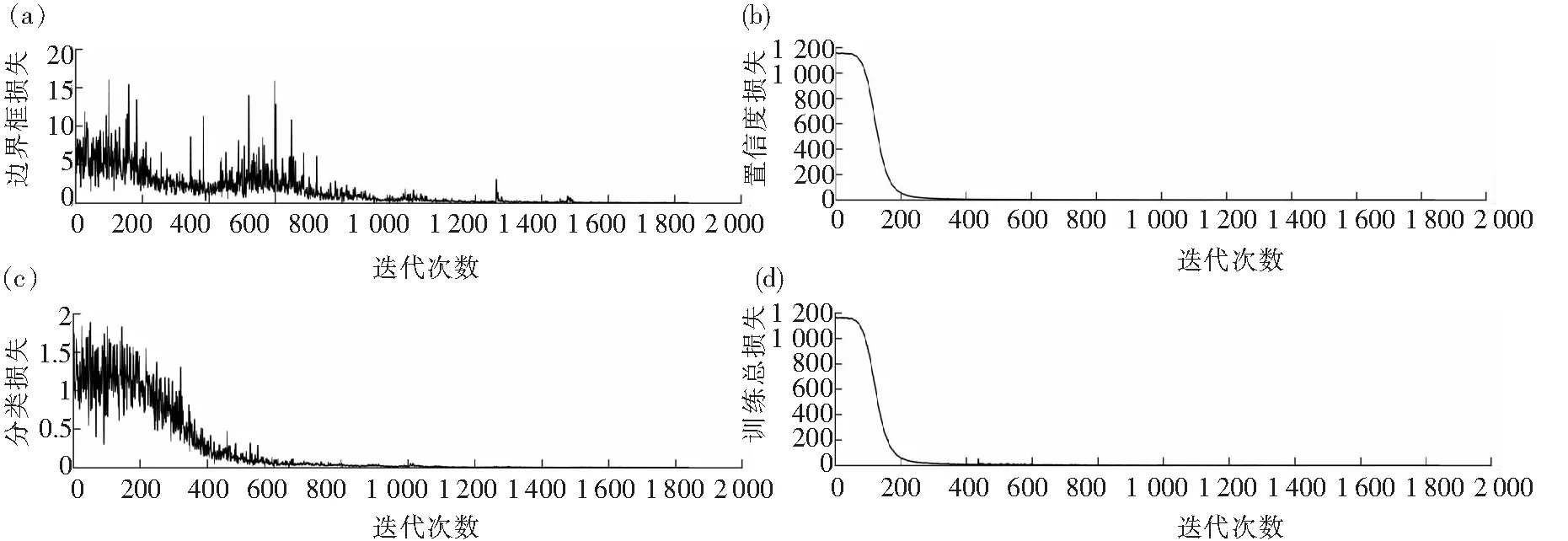
(a)边界框损失;(b)置信度损失;(c)分类损失;(d)训练总损失图7 训练损失结果Fig.7 Training loss results
召回率(recall)计算如下:
(10)
其中,FN表示模型将预测为负样本,实际为正样本,即是被漏检的样本数.
本文使用相同的数据集和训练参数分别对以基于ResNet50为基础网络的改进Yolov3模型、以Darknet为基础网络的原Yolov3模型进行训练,两种模型评估的P-R(精确率-召回率)曲线如图8、图9所示.
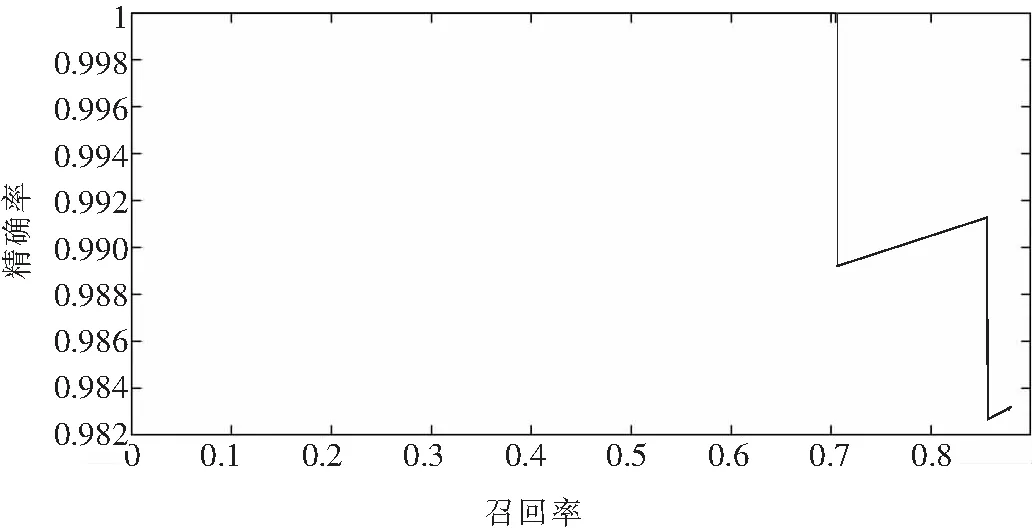
图8 以ResNet50为基础网络的改进Yolov3模型Fig.8 An improved Yolov3 model with a ResNet50-based network
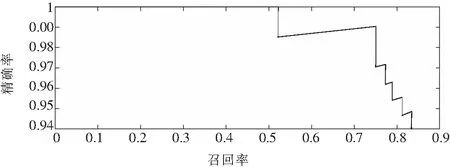
图9 以Darknet为基础网络的原Yolov3模型Fig.9 The original Yolov3 model with the Darknet-based network
由图可以看出,改进后Yolov3模型的平均精确度比原Yolov3模型提高了0.5%.在P-R曲线中,曲线接近坐标(1,1)位置,说明精确度和召回率都很高,就越说明模型性能越好.当召回率为0.7时,改进后Yolov3模型的精确度比原Yolov3模型高,同时曲线比原Yolov3模型更接近坐标(1,1)位置,这说明改进后的Yolov3模型综合性能更好,检测准确率和定位精度更高.当对大小为1 280×720像素的mp4格式的视频进行检测时,帧速率不低于40帧/s,可以满足对视频实时检测的要求.
4 结语
本文基于Yolov3网络,修改了残差网络单元,在基础特征提取网络中,利用ResNet50网络代替Darknet-53网络,剪切了ResNet50网络中第5个残差模块,最后添加了2个Yolo检测网络,组合成一个新的改进型Yolov3网络.
通过K-means聚类算法选择边界框和通过数据采集和处理,进行模型训练实验,结果显示,在验证集中获得较好的精确率和召回率,同时对训练数据之外的数据也获得良好的检测效果.
