基于改进的Faster R-CNN的小麦麦穗检测识别*
2022-10-04徐博文童孟军
徐博文,童孟军.2
(1.浙江农林大学 数学与计算机科学学院,浙江 杭州 311300;2.浙江农林大学 浙江省林业智能监测与信息技术研究重点实验室,浙江 杭州 311300)
0 引言
小麦产量是评估农业生产力的重要指标之一[1],而其产量统计却一直是一个难题.世界各地的小麦因其生长环境的不同,麦穗颗粒大小、颜色、稀疏程度都各不相同,而且纬度、气候、土壤等因素的不同小麦的种类也各不相同,这些难以调控的因素给小麦的产量统计留下了一个极大的难题,准确地对野外图像进行小麦麦穗检测的难度也是成倍增长[2],此外,外观会因成熟度、颜色、基因型和头部方向而异.小麦是在世界范围内种植的,因此小麦的产量统计从来不仅限于一个地区或一个省市甚至于一个国家,必须考虑不同的品种、种植密度、样式和田间条件[3-11],因此,为小麦麦穗检测的模型需要在不同的生长环境之间进行特征学习并对特征进行概括.
早期对小麦麦穗的检测还基本处于人工识别阶段,计算机发展后加入了数学模型进行检测分析,在神经网络模型被提出后,神经网络同样也被运用到了小麦的识别中,但是识别率不是特别理想,近几年随着机器学习的发展,机器学习方法也被加入小麦的检测中,其中深度学习在目标检测领域受到了许多专家学者的研究,但是对小麦麦穗的检测识别如今还是少数.目标检测方法的代表主要是YOLO[12]和Faster R-CNN[13]两种,其中YOLO方法在检测速度上优势明显,但是对小麦这一类小目标数据集的检测效果欠佳,而Faster R-CNN虽然在检测速度上不如YOLO方法,但是检测精度却是大大优于YOLO方法,特别是在小麦麦穗这一类小目标的检测中优势更加明显,因此本次研究模型选取了Faster R-CNN算法,而传统的Faster R-CNN模型在针对特定的小目标数据集时在检测速度和精度上还是略有不足,本文将就这两个方面对模型进行改进,提升模型检测效率.
本文选取了世界性的小麦麦穗数据集——GWHD数据集作为基础数据集,同时对数据集进行了数据扩充形成本次实验的小麦麦穗数据集.本文在特征提取网络中将VGG16网络用ResNet50网络替代,并在Faster R-CNN算法特有的RPN网络中anchor框的选取引入了K-means聚类算法[14],改变anchor框的固定参数,使其根据先验框的形状和大小生成更适合本数据集的anchor框[15],同时对ResNet50网络引入BiFPN单元进行加权结合.在结束训练后,对几个基础算法和改进后的算法进行了对比,证明其可行性和泛化性能.
1 材料与方法
1.1 实验数据集
实验中使用的数据集为Global Wheat Head Dataset,即全球小麦头数据集,它是由9个研究机构来自7个国家主导:东京大学,日本国立农业研究所,日本国立环境研究所,阿尔瓦利斯大学,埃兹大学,萨斯喀彻温大学,昆士兰大学,南京农业大学,罗瑟斯特德研究所.
训练数据集涵盖了多个区域,有来自欧洲(法国,英国,瑞士)和北美(加拿大)的3 000多张图像.测试数据包括来自澳大利亚,日本和中国的约1 000张图像.同时数据集由7个标签数据集组成,分别为:usask_1,arvalis_1,arvalis_2,ethz_1,inrae_1,rres_1,arvalis.如图1所示.

图1 小麦麦穗数据集示例图Fig.1 Sample graph of wheat head data set
1.2 数据增强
考虑到卷积神经网络在训练中容易出现过拟合问题,降低了模型的泛化能力,本文通过数据增强来降低,具体方法为:翻转、旋转、平移、降噪等.通过一系列数据增强方法,将图片从原来的3 423张扩充到了4 556张,以此增加了数据集的数量,使模型的训练效果更好,另一方面也增加了一些干扰项,如没有目标的目标检测框为0的无用图片,如图2所示,以此减少过拟合现象.

图2 小麦麦穗干扰项示例图Fig.2 Sample graph of wheat head interference term
1.3 实验环境
本文模型实验环境如表1所示.

表1 实验环境配置参数表
1.4 模型参数
为证明本文改进算法的可行性,本文中将使用以VGG16、ResNet50为特征提取网络的两个基础模型与改进后的模型进行对比,所有的算法将会采用一样的评估方法和参数进行对比,验证其有效性,训练过程中的部分参数设置如表2所示.

表2 实验参数设置
关于迭代次数的设置,是根据实际模型训练饱和时的平均次数来决定,由于数据集目标数较多,一次迭代时间较长,同时再增加迭代次数最后的检测结果相差不大,反而可能更差.经过大量实验的验证,最后将本文数据集的模型训练迭代次数设置在了300次.
1.5 实验模型
本文将主要针对Faster R-CNN模型进行改进与实验,它大体上可看成RPN 与 Fast R-CNN的组合,且RPN和Fast R-CNN共享一部分卷积层.将一幅图像送入Faster R-CNN进行检测,conv layers代表基础网络(例如VGG16、ZF)的卷积层,这部分就是RPN与Fast R-CNN共享的结构.图像经过conv layers得到特征图;将特征图送入RPN,得到建议框;将建议框和特征图一起送入从感兴趣池化层开始的剩余网络结构(Fast R-CNN),得到目标检测结果.
Faster R-CNN的网络结构如图3所示.首先,使用VGG16特征提取网络得到特征图.从特征图之后的一个3×3卷积层开始到生成建议框是RPN特有的层,它完成了从特征图中提取建议框的工作.从感兴趣区域池化层开始到网络结束是Fast R-CNN特有的层.尽管Fast R-CNN目标检测方法是由选择性搜索模块和Fast R-CNN两个模块组成的,但这两个模块并不是一个统一的网络.而Faster R-CNN却是一个统一的网络,它由RPN和Fast R-CNN两个模块组成.如果Fast R-CNN需要给定一幅图像,要同时给出图像上的关注点,才能进行目标检测,那么,Faster R-CNN能够自己在给定图像上找到关注点,并对关注点进行检测.
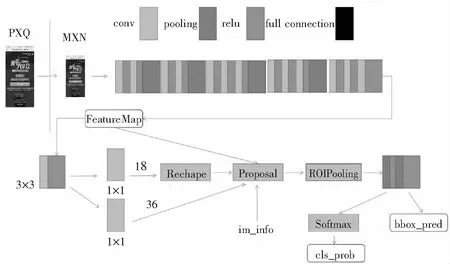
图3 Faster R-CNN网络结构Fig.3 Faster R-CNN network structure
1.6 模型改进
1.6.1 ResNet50网络替换深度卷积神经网络希望通过增加网络层数来提高对样本特征的提取能力,然而事实却不尽如人意.实验证明了深层网络的退化问题:随着网络的加深,模型的性能和精确度确实会有所提高,但是当学习程度达到饱和后,精确性却会突然下降,但并没有出现过拟合现象,不是过拟合造成的退化问题.而原模型中的VGG16网络就出现了这个问题,因此本文使用ResNet网络来代替VGG16网络.
ResNet团队通过实验对此进行了证明:如果迭代次数相同,20层网络的误差率明显比56层网络的误差率低.为了解决这一问题,ResNet团队提出了深度残差学习框架.如图4所示,输入x得到H(x),说明这一浅层模型只是传递了参数值而没有进行计算,所以在加深深度后并不影响结果.于是,ResNet提出了另一个映射:H(x)=F(x)+x.如此,参数可以跳过几层或多层达到输入层,进行通过残差单元的跳层连接.
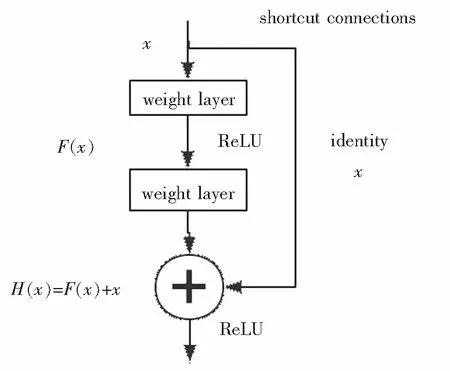
图4 ResNet50残差学习单元Fig.4 ResNet50 residual learning unit
残差模块反复堆叠时,会构成不同深度的网络结构,本文尝试了ResNet18、ResNet34、ResNet50、ResNet101、ResNet152等不同深度的多种网络,考虑到要兼顾实验效果和计算量,最终选用了50层的ResNet50网络,各深度网络测试精度与速度对比如表3所示.

表3 各深度ResNet网络测试结果
1.6.2 ResNet50卷积核改进由于ResNet网络的第一层都是由7×7的卷积核形成的卷积层,其感受野较大,对图像提取的特征满足训练要求.但在本文研究中,数据集通常为小目标检测,为了更精确地提取细微特征,本文将使用3个3×3的堆叠卷积层替换7×7卷积层.通过这一改动,加深了网络深度的同时也减少了参数计算量.同时3个3×3的卷积层的感受野和一个7×7的卷积层是一样的,同样能将特征很好地提取并且传到下一层.因此,改进后的网络能给模型带来更好的性能.
用伪代码来展现改进变量细节如下:
Kernel_size=7→Kernel_size=3
Stride=2→Stride=2
Padding=3→Padding=1
1.6.3 引入FPN后ResNet50与BiFPN的结合本文采用了ResNet50代替了原有的VGG16作为改进后模型的主干网络,并与BiFPN相结合实现多尺度的特征提取.ResNet50可以通过更深的网络深度提高对深层语义特征学习的能力,但是容易丢失图像中较小目标的细节,从而不利于对目标的像素级分割.为了解决这一问题,本文将双向加权特征金字塔网络BiFPN与ResNet50相结合.结合BiFPN后的网络,利用了其双路径的优势,使得深层特征与浅层特征的丢失均减少,且可以采用跳跃连接融合更多的特征,并赋予对模型贡献率不同的各尺度特征不同的权重系数.
二者结合的方式如图5所示,其中左侧为ResNet50的结构图,右侧为BiFPN网络的结构图.

图5 BiFPN与ResNet50结合方式Fig.5 The combination of BiFPN and ResNet50
BiFPN单元的伪代码部分如下(以p3为例):
p3_w1 = self.p3_w1_relu(self.p3_w1)
weight = p3_w1 / (torch.sum(p3_w1, dim=0) + self.epsilon)
p3_out=self.conv3_up(self.swish(weight[0]* p3_in + weight[1] * self.p3_upsample(p4_up)))
从伪代码中可以看出,其实BiFPN单元的功能就是添加了一个简单的注意力机制,再通过各单元的特征值进行跳跃结合给各个层赋予了不同的权重去融合,让网络的注意力集中在更加重要的特征值上,如小麦的麦穗形状、颜色、平均大小等,而且还减少了一些不必要的层的节点连接.
1.6.4 引入聚类的anchor算法改进Faster R-CNN模型中设置了9个固定长宽比和大小的anchor框,对于检测目标较为复杂的数据集来说是一个较为合适的选择,但是针对本文的小目标数据集,相对来说显得略有些不合适,可能不能得到很好的检测效果.但是要设定新的长宽比的anchor框,光凭人工估算来设定肯定是不合理的,因此本文引入了K-means聚类算法,利用聚类算法遍历先验框自适应生成anchor框的长宽比.
步骤1,将所有bounding box的坐标都提取出来;
步骤2,将提取出的bounding box的坐标转化为框的宽高大小,方便后续聚类计算;
步骤3,初始化k个anchor box,本文中使用random函数,在所有bounding box中随机选择k个值作为k个anchor boxes的初始值;
步骤4,计算每个bounding box与每个anchor box的iou值,传统的聚类算法是使用欧几里得距离来衡量差异,如此运行算法的话,在box尺寸比较大的时候,最后算法得到的误差会很大,所以本文引入iou值用来代替欧几里得距离,以便适应bounding box的距离计算;
步骤5,在前面一步计算完成后,可以能够得到每个bounding box对于每个anchor box的误差d(n,k),通过比较每个bounding box其对于每个anchor box的误差{d(i,1),d(i,2),…,d(i,k)},取出误差最小的那个anchor box,将这个bounding box分类给它,对于每个bounding box都需要做这个操作,最后记录下来每个anchor box有哪些bounding box属于它;
步骤6,通过上一步的计算,能知道每个anchor box有哪些bounding box是属于它的,然后对每个anchor box中的bounding box,再求它的宽高中值大小,将其作为anchor box的新尺寸.
步骤7,重复步骤4、5、6,直到bounding box所属的类与之前的anchor box类完全一致,最后得出我们需要预设的anchor的ratios即宽高比,将其用在anchor中,完成针对本次数据集的检测框初始化.
伪代码K-means部分具体表示如下:
rows = boxes.shape[0]
distances = np.empty((rows, k))
last_clusters = np.zeros((rows,))
np.random.seed()
clusters = boxes[np.random.choice(rows, k, replace=False)]
while True:
for row in range(rows):
distances[row] = 1 - iou(boxes[row], clusters)
nearest_clusters = np.argmin(distances, axis=1)
for cluster in range(k):
clusters[cluster] = dist(boxes[nearest_clusters == cluster], axis=0)
last_clusters = nearest_clusters
return clusters
2 结果与分析
2.1 模型评估指标
2.1.1 对数平均误检率(log-average miss rate)假设N幅图片中,误检窗口为k,单图像错误率(false positive per image,FPPI)为k/N,miss rate(1-R)取该FPPI值对应的最小miss rate.各个FPPI和miss rate的得到方式与AP中得到P、R值的方式一样,也是得到所有检测框的置信度,由高到低排列,依次判断top-n.log-average miss rate的计算方法是在9个FPPI值下(在值域[0.01,1.0]内以对数空间均匀间隔)的平均miss rate值.
2.1.2 mAP在介绍mAP之前,需要知道几个样本概念:TP、TN、FP、FN.
TP,即True Positives,表示样本被分为正样本且分配正确.
TN,即True Negatives,表示样本被分为负样本且分配正确.
FP,即False Positives,表示样本被分为正样本但分配错误.
FN,即False Negatives,表示样本被分为负样本但分配错误.
Precision,即精度,表示被正确分配的正样本数占总分配的正样本数的比例,公式为:
Recall,即召回率,表示被正确分配的正样本数占总正样本数的比例,公式为:
mAP,即平均准确率(mean Average Precision),是各类别准确率(AP)的平均值,AP的计算使用了差值平均准确率的评测方法,即Precision-Recall曲线下的面积,AP的计算公式为:
式中:n表示检测点的个数;Pinterpo(r)代表在召回率为r时准确率的数值.根据AP可计算mAP,公式为:
2.2 对数平均误检率结果与分析
经过大量实验和训练,每一种训练方法都训练到模型的学习能力饱和为止,所以得到的最终结果即是各个方法模型的最好的训练效果,首先通过对数平均误检率对各模型和数据集各种类样本的训练情况进行分析,结果如图6、图7、图8所示.
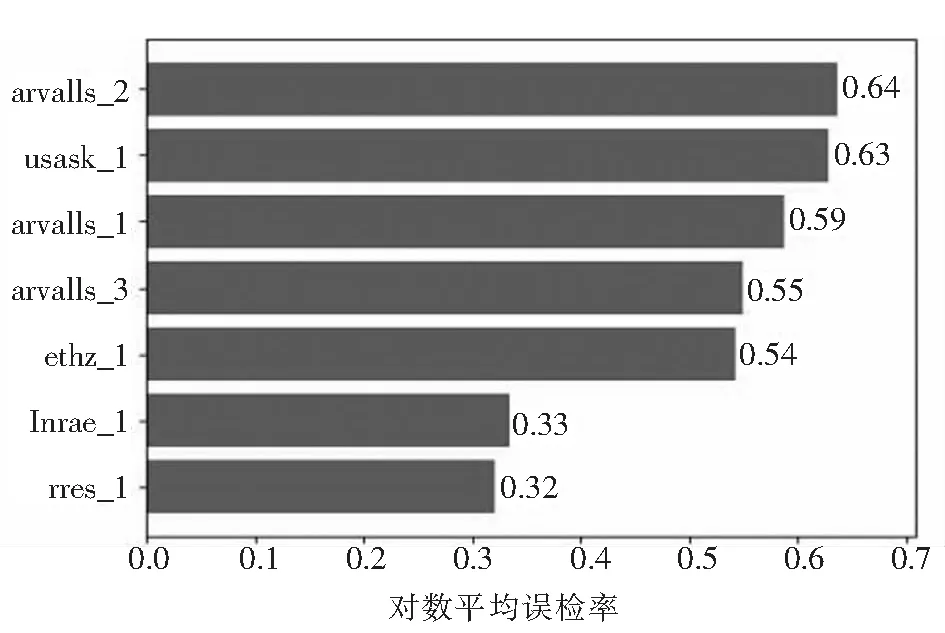
图6 VGG16-lamr图Fig 6 VGG16-lamr
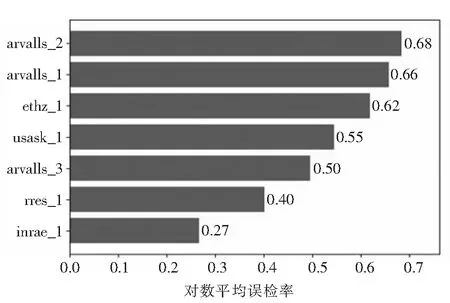
图7 ResNet50-lamr图Fig.7 ResNet50-lamr

图8 改进的ResNet50-lamr图Fig.8 The improved ResNet50-lamr
数据集中标签usask_1、arvalis_1、arvalis_2、ethz_1都是数据量比较大的数据集,而标签inrae_1、rres_1、arvalis_3相对来说数据量较少.从图中可以看出针对数据量较少的数据集VGG16网络优势更大,但是针对数据量较大的数据集,VGG16网络的性能就没有那么可观了,相对而言,ResNet50网络的性能更加出色,从图中对比可以轻易看出使用ResNet50网络后,几个数据量较大的数据集的对数平均误检率明显降低,而改进RPN后的模型的对数平均误检率相对于只使用ResNet50网络的模型又降低了一些.而相对于数据量较小的几个数据集来说,更换网络和改进后的对数平均误检率会有上下浮动,甚至可能会略有增加,可能会导致这个标签的数据集对应的AP略有降低,但是加上几个数据量大的数据集后,它的mAP总体来说还是略有升高的,而mAP是检测一个模型性能最重要的指标之一,能提升mAP而对模型做一些改动是非常可取的.所以总的对比起来,更换网络和改进后的模型的性能是更加优秀的,优于未改进前的网络模型性能.
2.3 mAP结果与分析
根据各模型的对数平均误检率值可以初步预测改进后的模型性能是最好的,但是最终性能如何还是要比较各模型的mAP值大小,各标签数据集的AP值和各模型的mAP值如图9、图10、图11所示.
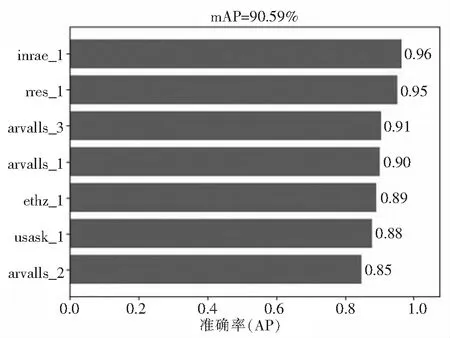
图9 VGG16-mAP图Fig.9 VGG16-mAP
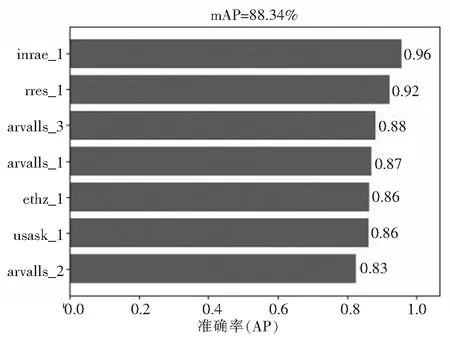
图10 ResNet50-mAP图Fig.10 ResNet50-mAP

图11 改进的ResNet50-mAP图Fig.11 The improved ResNet50-mAP
从图9、图10、图11可知,引入ResNet50网络的模型效果要优于VGG16网络,而改进RPN网络后的模型效果又要优于单纯引入ResNet50网络的模型效果.对于各标签数据集来说,由于数据量较小的几个数据集的检测精度已经较高,所以改进后的模型的精度提升了0.5%,略优于改进前的模型效果.对于数据量较大的几个标签数据集来说,替换网络并且改进RPN后的模型的检测精度有了明显的提升.检测精度较高的数据集再提升精度对于mAP值的影响也并不是非常大,而检测精度低的数据集经过改进后的模型训练,检测精度明显提升,补足了训练模型对于检测效果较差的数据集的检测短板,明显提升的这几个数据集的检测精度,从而使mAP值也跟着有了明显的提升.mAP值的提升也明显说明了改进后模型的可行性.
2.4 检测时间结果与分析
在比较mAP值大小的同时,本文同样注意了单个目标的检测时间和单张图片的检测时间,如表4所示.
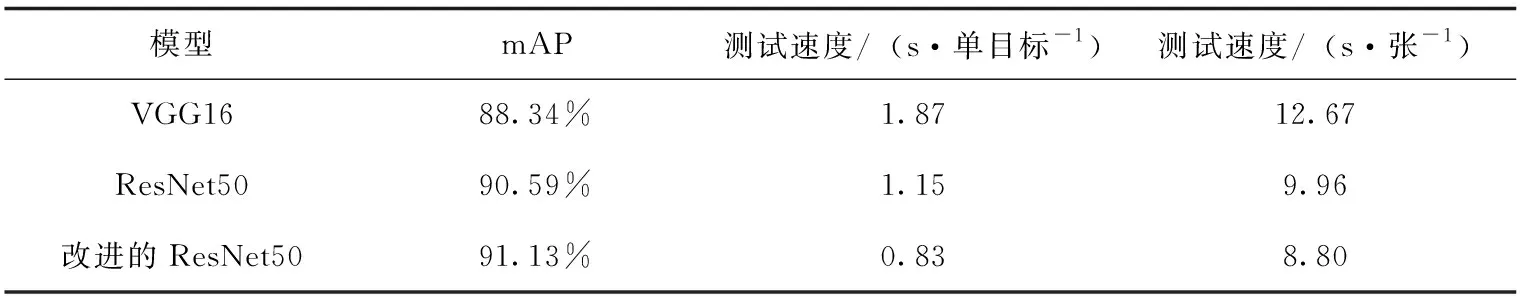
表4 模型训练结果表(训练模型在训练数据集上的测试结果对比)
由表4可知改进后的模型不仅在mAP值上优于其他模型,并且在单个目标的检测速度和单张图片的检测速度也比另外的模型要快.这得益于改进RPN网络后新的anchor宽高比更加适应测试数据集,从而减少了调整anchor框的时间,因此最后呈现出的效果就是改进后的模型的检测时间明显少于未改进前的基础模型.
3 结论
本文提出一种用ResNet50网络替换VGG16网络并且对RPN网络进行改进的Faster R-CNN检测算法.通过特征提取网络的替换和结构改进与anchor处理的改进,提升了数据集的检测精度和检测速度,可以正常识别数据集中的7个标签数据,并具有较高的置信度.通过实验结果表明:
(1) 在数据集识别精度上,改进后的模型对数据集中的7个标签数据集都可以正常识别,并且精度对比使用VGG16作为特征提取网络的模型高了2.25%,相较于只使用ResNet50作为特征提取网络的模型精度提升了0.54%.可以看出对于小麦麦穗这类小目标数据集,改进模型对重要特征的提取和检测效果更好,因此检测精度更高.
(2) 在检测目标识别速度上,改进后的模型的识别速度明显优于未改进前的几个基础模型,无论是从单个目标的识别速度还是单张图片的识别速度乃至整个数据集的识别速度,改进后的模型的识别速度都是占优的.可以看出在提高检测精度的同时,改进模型同样减少了模型复杂度和计算量,故意忽略了一些不重要的特征,来提高计算速度,因此改进后模型的检测速度明显优于原模型.
(3) 从识别精度上来看,改进后的模型识别精度仅仅提升了0.54%,但是在原模型的识别精度已经在90%以上达到行业识别标准的情况下,还略有提升,也是非常可取的.同时在提升识别精度的同时在识别速度上的提升也比较明显,两者结合来看,改进后的模型完全可以满足对小麦麦穗的检测识别,有助于工厂企业更好地统计小麦产量,让训练模型更好地运用到生产生活中.
