图神经网络在冷启动推荐中的实现
2022-10-01朱风兰李大舟周河晓陈思思
高 巍,朱风兰,李大舟,周河晓,陈思思
(沈阳化工大学 计算机科学与技术学院,辽宁 沈阳 110142)
0 引 言
在互联网快速发展的时代,推荐系统的出现刺激了互联网经济的爆炸增长。由于数据的高度稀疏性,推荐系统中存在用户冷启动和项目冷启动两个严重问题。用户冷启动主要解决了如何为新用户提供个性化推荐的问题。当新用户进入平台时,该平台没有行为数据,因此无法基于其历史行为进行预测,而导致不能提出个性化推荐。项目冷启动无法向有兴趣的用户推荐新启动的项目。解决用户冷启动和项目冷启动问题成为了当前研究领域的热点。相关研究可以提高企业的收益率、平台的留存率和用户的使用舒适度。实现冷启动推荐对企业、用户和平台的发展具有重要意义。
1 相关工作
推荐系统面临着稀疏性和冷启动[1,2]问题。解决该问题的传统方法是对矩阵分解[3,4]的目标函数进行正则化,但并没有为电商提供良好的推荐结果。此外,在解决具有多模态、大规模、数据稀疏等复杂特征的冷启动问题工作中,利用辅助信息能够比矩阵分解带来更好的效果,例如上下文信息[5]、用户和项目的关系[6,7]。推荐系统中的用户信息和项目信息在本质上具有图结构。可以构建同构图和异构图的图神经网络体系结构[8]便开始被应用于推荐系统。
YING等[9]提出一种采用局部卷积的可伸缩的图卷积算法,即PinSage算法,该算法解决了模型训练时间复杂度大的问题。ZHANG等[10]提出了一种层叠和重构的图卷积网络,即STAR-GCN结构,该结构提高了推荐的效果。LEE等[11]提出了一种基于优化的元学习MeLU算法,解决了图卷积神经网络难以设置较深的层数学习节点表征形式的问题。LU等[12]提出了一种采用元学习支持集的MetaHIN算法,解决了元学习者在任务特定参数之前适应全局参数的问题。吴等[13]提出了一种基于用户与项目节点间关系的图神经网络算法,提高了冷启动推荐的效果。
2 基于图神经网络的冷启动推荐模型(IGNN)
在用户冷启动和项目冷启动推荐系统中,难点在于缺少用户和项目的偏好信息即历史交互。对于此难点,可以使用用户或项目的特征来表示属性信息,但仍存在两个问题。一是如何将属性表示转换为偏好表示,二是如何有效聚合邻域中节点的不同模态属性。由于推荐系统的大部分数据本质上有图结构,并且图神经网络技术在捕获节点间的连接和图数据的表示学习方面有强大的功能。此外,图神经网络可以构建同构属性图,解决稀疏度高的问题。因此,本文提出了一种同构属性特点的图神经网络的冷启动推荐模型,即信息图神经网络(infographic neural network,IGNN)。IGNN模型结构如图1所示。
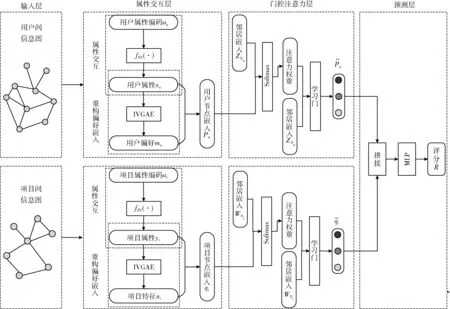
图1 本文提出的IGNN模型结构
IGNN模型由4部分组成:输入层、属性交互层、门控注意力层和预测层。输入层对原始数据进行独热编码,构造用户间信息图和项目间信息图,两图均为同构属性图,解决了属性信息的表示问题;属性交互层对图中的节点进行高阶交互,并使用改进的图变分自编码器重构偏好嵌入,解决了如何将属性表示转换为偏好表示和偏好缺失问题;门控注意力层使用门控注意力聚合器,解决了聚合邻域中节点不同模态的多属性问题;预测层拼接用户和项目的聚合表示并利用多层感知机(multilayer perceptron,MLP)解决过拟合、梯度弥散等问题,得到最终的评分分数。
2.1 输入层
输入层由图1中用户间信息图和项目间信息图两个部分构成。图1中用户间信息图,圆圈表示用户,连接线表示用户与用户之间的关系;项目间信息图,圆圈表示项目,连接线表示项目与项目之间的关系。以用户间信息图为例,信息图包含着属性信息和结构信息两种信息,两者分别描述了信息图中节点的固有性质和节点之间的关联性质,这两者对信息图中节点和全图的刻画起着关键作用。项目间信息图结构特点、内容与用户信息图相似。输入层的输入为原始数据,输出为用户间信息图和项目间信息图。
(1)输入层中对每个用户和项目的属性信息进行独热编码,并且不考虑之间的交互关系,将多个属性的独热编码简单的连接为一个长向量,以构成原始数据的每个用户和每个项目的一组信息关联。以用户u为例,其原始数据分别为性别:男、年龄段:16岁~25岁、用户等级:4、注册时间:2016年,即共有4个属性。用户属性信息独热编码中具有特征的位置标记为1,没有的标记为0,而用户属性信息多热编码则是独热编码的简单连接,图2是用户u的属性信息编码示例。项目属性信息独热编码和多热编码的原理与用户编码方法相似。

图2 用户u信息编码
(2)对于用户,若两个用户有相似的属性信息,例性别、年龄等;对于项目,若两个项目有相似的属性信息,例品牌、型号等,则定义用户与用户之间、项目与项目之间有较高的属性相似度。对于用户,若两个用户有相似的行为记录列表,则定义用户与用户之间有较高的偏好相似度;对于项目,若两个项目有相似的记录列表,则定义项目与项目之间有较高的偏好相似度。属性相似度和偏好相似度都可以使用修正的余弦距离来测量。修正的余弦相似度在余弦相似度的基础上,进一步把所有评分都减去该评分所对应的用户的评分均值,结果越大,相似度越高。计算方法如式(1)所示

(1)
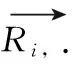
(2)
式中:att为属性相似度,pre为偏好相似度。
(3)输入层将与目标节点具有top p%的总体相似度sim的所有节点都添加到候选池。在接下来的每轮训练中,根据相似度对节点的邻居从候选池采样,为保证邻域多样性使用年龄作为决定邻居的主要因素,若没有年龄,则选择用户等级作为主要因素进行动态图构建策略,一旦图被构造,将保持固定数量的邻居。得到图1中输入层的用户间信息图和项目间信息图。
2.2 属性交互层
属性交互层由图1的属性交互和重构偏好嵌入两部分构成。由于在构造的用户间信息图和项目间信息图中,每个节点都包含多热属性编码和表示身份唯一的独热编码,并且推荐系统中的用户和项目数量众多,导致节点的独热编码表示维数较高,因此属性交互层目标是减少独热编码的维数,并学习多热信息编码表示的高阶信息交互。以用户u和项目i为例,定义用户属性为xu、用户偏好为mu、项目属性为yi和项目特征为ni。对于冷启动节点来说,由于新用户和新项目没有交互信息,因此用户偏好和项目属性不存在,所以需要对图1中属性交互层节点进行重构偏好嵌入。
(1)属性交互
图1中的属性交互层首先将节点的独热编码转换为低维的密集向量并构建查找表。查找表对应于用户的参数矩阵M和项目的参数矩阵N两个参数矩阵。属性交互层然后使用双向交互池操作捕获高阶属性间的交互,最后增加了线性组合操作。属性交互层采用的双向交互和线性组合操作定义如式(3)所示
(3)
式中:ai和aj是属性编码,vi和vj是属性编码中的第i类属性和第j类属性的嵌入向量,⊙表示按元素乘积。
在二阶交互和线性组合之后分别使用一个全连接层,实现了对高阶特征交互的学习,fFC函数计算方法如式(4)所示
(4)
式中:Wfc,bfc和LeakyReLU分别是权重矩阵、偏置向量和激活函数。用户u的属性编码au和项目i的属性编码ai分别被馈入fFC函数,产生了用户的属性嵌入xu和项目的属性嵌入yi,如式(5)所示
xu=fFC(au),yi=fFC(ai)
(5)
(2)重构偏好嵌入
重构偏好嵌入是图1中的属性交互层的第二部分。对于用户冷启动和项目冷启动问题,则是由于新用户和新项目缺少历史交互引起的,即缺少偏好。针对上述问题,本文提出改进的变分图自编码器(improved variational graph autoencoder,IVGAE)从用户和项目的信息分布中重构偏好,其结构包含3个部分:①推断模型;②生成模型;③近似模型。以用户u为例,如图3所示。
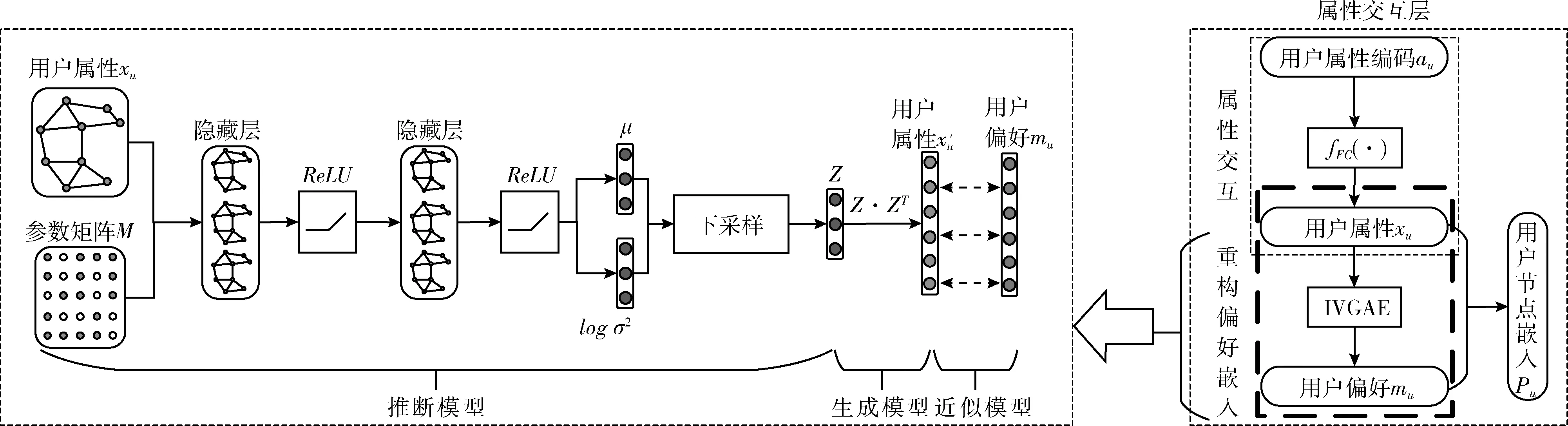
图3 改进的变分图自编码器(IVGAE)结构
推断模型又称为编码器,由图卷积神经网络(graph convolutional network,GCN)[14]组成,由图3的推断模型部分看出,对于用户u, 它以用户属性xu和参数矩阵M作为输入,输出embedding空间的变量Z。ReLU函数用于推断模型,可以克服梯度消失并且加快训练速度,第一个隐藏层生成一个低维特征矩阵。GCN的计算方法如式(6)所示
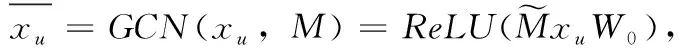
(6)
第二个隐藏层生成μ和logσ2, 如式(7)所示
(7)
联立第一个隐藏层和第二个隐藏层,可以得到编码器的计算,如式(8)所示
(8)
下采样以μ,logσ2的分布作为输入,输出embedding空间变量Z,如式(9)所示
Z=μ+σ×ε,ε~N(0,1)
(9)
生成模型又称为解码器,生成模型由embedding变量Z之间的内积定义;由图3的生成模型部分看出,解码器的输出是一个重构的用户属性x′u, 计算过程如式(10)所示。引入生成模型的所有参数,参数化为多层感知机。同理,项目i重构的项目特征为y′i
x′u=sigmoid(ZZT)
(10)
从图3的近似模型部分看出,属性交互层将用户重构嵌入x′u约束为用户偏好嵌入mu, 项目重构嵌入y′i约束为项目特征嵌入ni。 综上,可以得到mu~x′u和ni~y′i。
最后,本文将偏好嵌入和属性嵌入融合到节点嵌入中,使每个节点既包含历史偏好又包含其自身的信息,计算过程如式(11)所示。其中 [;] 表示向量级联运算,Wu和Wi分别为用户u和项目i的权重矩阵,bu和bi分别为用户u和项目i的偏置向量,mu是用户u的偏好,ni是项目i的特征。项目在属性交互层的操作过程和用户相似。属性交互层的输出为用户节点嵌入Pu和项目节点嵌入qi
Pu=Wu[mu;xu]+bu,qi=Wi[ni;yi]+bi
(11)
2.3 门控注意力层
门控注意力层的目的是有效的聚集邻域中不同模态的各种属性,包括多头注意力和学习门两部分。
针对邻域聚集问题,门控注意力层采用了键值注意力机制和点积注意力,计算一个附加软门在0(低重要性)和1(高重要性)之间,赋予每个磁头不同的重要性,结合多头注意力聚合器,得到了本文设计的门控注意力网络结构[15]。门控注意力网络结构如图4所示,以两个用户的中心节点的三头门控注意力聚合器为例,不同的颜色代表不同的注意头,在学习门中,深色的门代表较大的值。
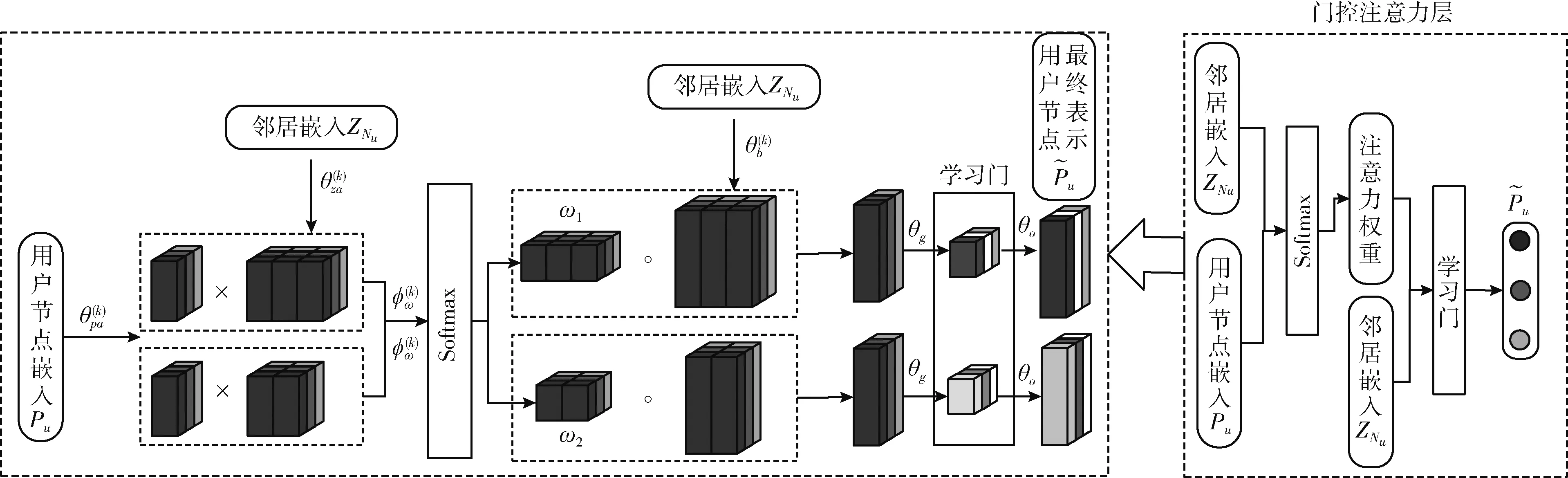
图4 门控注意力网络结构
本文给定一个用户节点u, 其节点嵌入为Pu,Nu为节点u的相邻节点,ZNu={Zv|v∈Nu} 是相邻节点中参考矢量的集合。用户节点的邻居聚合和节点更新过程包含以下3个步骤:
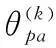
(12)
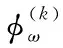
(13)
步骤2 图4中的学习门以邻居嵌入ZNu和步骤1得到的注意力权重作为输入,进行细粒度聚合操作。为了确保增加门不会引入太多的附加参数,门控注意力层使用卷积网络ψg, 该卷积网络采用中心节点和相邻节点的特征生成门值。计算过程如式(14)所示
(14)
本文结合了平均池和最大池来构建卷积网络,如式(15)所示
(15)
式中:θm将相邻特征映射到dm维向量,然后取元素方向的最大值,θg将连接的特征映射到最终的K门。
通过设置一个小的dm, 用于计算门的子网的计算开销可以忽略不计。
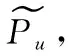
综合3个步骤可以得到门控注意力聚合器的公式,如式(16)所示
(16)

2.4 预测层
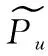
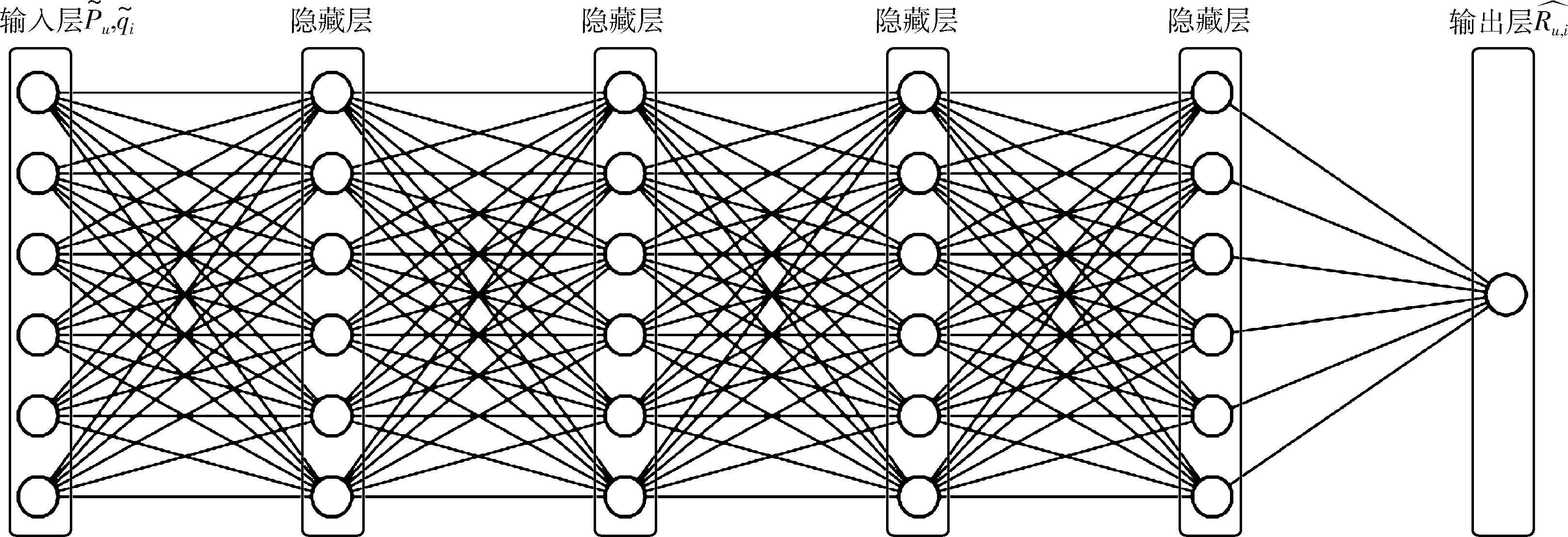
图5 MLP的模型
本文将用户u对项目i的预测评分计算如式(17)所示
(17)
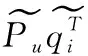
3 实验设计
3.1 实验环境
本实验在Ubuntu18.02系统下进行,使用Intel@i5-7200U作为计算单元,内存为8 GB。模型使用Pytorch框架进行搭建,版本为1.8.1。基于Pytorch框架进行用户和项目评分预测模型的搭建和训练,使用DGL库来进行图神经网络的构建。本文的实验环境配置见表1。
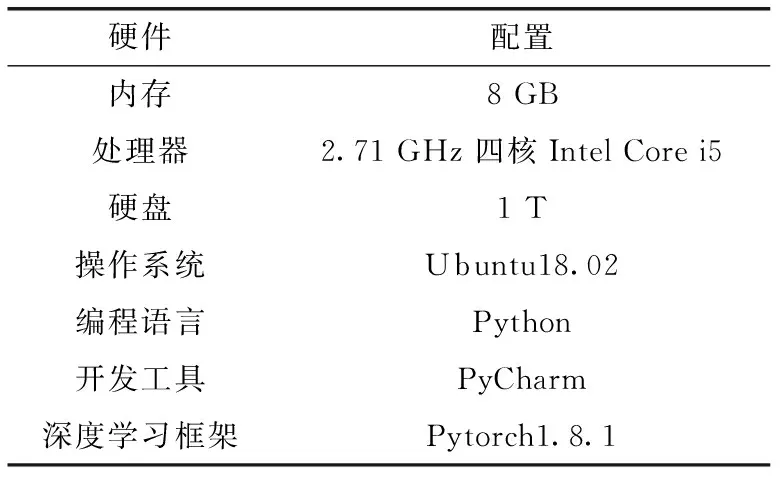
表1 实验环境配置
3.2 实验数据集
本文使用京东2016年2月至4月的高潜用户购买意向预测数据集来评估提出模型。京东数据集由103 525个用户、17 181个商品、2 861 262条评分信息组成。数据集由5个文件组成,各个文件信息见表2。本文对数据进行清洗,将用户行为数据文件合并为一个文件JData_Action。

表2 数据集基本信息
3.3 评价指标
本文采用了广泛用于评分预测任务的3个评价指标:均方误差(mean square error,MSE)、均方根误差(root mean square error,RMSE)和平均绝对误差(mean absolute error,MAE)。
(1)均方误差(MSE)
均方误差是线性回归中最常用的损失函数。MSE可以评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。MSE的定义如式(18)所示
(18)
(2)均方根误差(RMSE)
均方根误差衡量的是预测值与真实值之间的偏差,并且对数据中的异常值较为敏感。RMSE的定义如式(19)所示
(19)
(3)平均绝对误差(MAE)
平均绝对误差是绝对误差的平均值,它其实是更一般形式的误差平均值。因为如果误差是[-1,0,1],平均值就是0,但这并不意味之系统不存在误差,只是正负相互抵消了,因此要加上绝对值。MAE的定义如式(20)所示
(20)
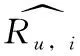
3.4 参数设置
本文提出的IGNN模型,按照经验设置批次大小为128、LeakyReLU的斜率为0.01和初始学习率为0.0005。本文讨论了模型计算结果中隐藏向量维数D和候选集阈值p在构造用户间信息图和项目间信息图过程中的最优参数的设定问题。实验初始设置方式如下:隐藏向量维数D=40, 候选集阈值p=5。
在优化隐藏向量维数D的过程中,实验通过更改不同维度的集合 {10,20,30,40,50} 来进行讨论。实验首先将候选集阈值p设置为5,然后改变隐藏向量维数D。 隐藏向量维数D的参数优化调整结果如图6所示。
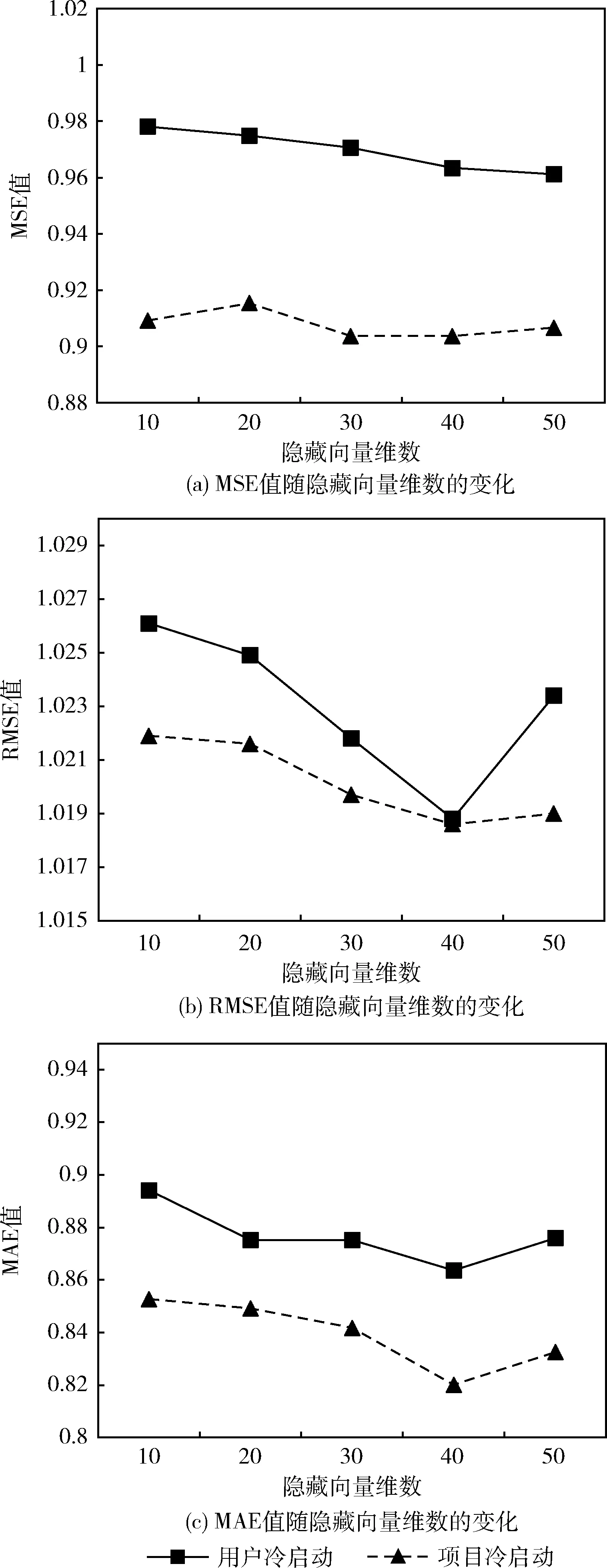
图6 隐藏向量维数D的参数优化调整结果
从图6可以看出,随着隐藏向量维数的增加,性能呈总体上升趋势。图6(a)中用户冷启动的MSE值随隐藏向量维数的增加数值平稳降低,性能呈上升趋势;项目冷启动的MSE值随隐藏向量维数的增加先降低,在40维后降低,40维后又上升。图6(b)中用户冷启动的RMSE值随隐藏向量维数的增加数值大幅度降低,在40维后数值迅速增加;项目冷启动的RMSE值随隐藏向量维数的增加数值大幅度降低,在40维后数值缓慢增加。图6(c)中用户冷启动的MAE值随隐藏向量维数的增加数值大幅度降低,在40维后数值缓慢增加;项目冷启动的MAE值随隐藏向量维数的增加数值大幅度降低,在40维后数值缓慢增加。综合两个冷启动的比较,隐藏向量维数为40时,IGNN模型的性能最好。这表明较大的维度可以捕获用户、项目及其各自信息的更多隐藏因素,从而产生了节点更好的表示能力。
在优化候选集阈值p的过程中,实验从候选集的阈值 {1,5,10,15,20} 中进行挑选。实验首先将隐藏向量维数D设置为40,然后改变候选集的阈值p。 候选集阈值p在构造用户间信息图和项目间信息图过程中的参数优化调整结果如图7所示。
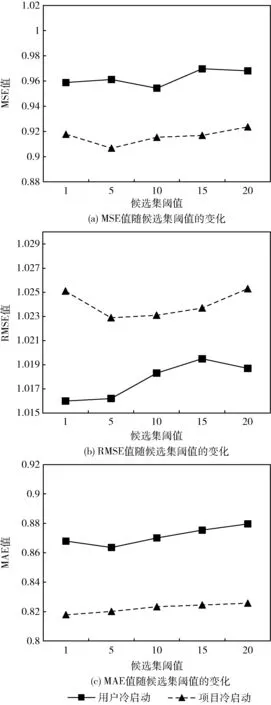
图7 候选集阈值p的参数优化调整结果
从图7中可以看出,在大多数情况下,p取值为5时,在候选范围内取得最优结果。图7(a)中用户冷启动的MSE值随候选集阈值的增加数值先增加再下降,以此规律反复;项目冷启动的MSE值随候选集阈值的增加先降低后持续增加。图7(b)中用户冷启动的RMSE值随候选集阈值的增加数值先增加,在第15个后开始下降;项目冷启动的RMSE值随候选集阈值的增加先下降后持续增加。图7(c)中用户冷启动的MAE值随候选集阈值的增加数值先降低,在第5个后开始增加;项目冷启动的MAE值随候选集阈值的增加持续增加。当从候选集采样时,被选择概率与候选集大小无关,因此排名靠前的样本始终具有较高的被选择概率。因此,p=5时被选为最优设定。
3.5 实验结果与分析
在用户冷启动过程中,训练集来自于JData_user文件中80%的用户以及JData_Action文件中80%的行为数据,测试集来自于JData_user文件剩余20%的用户。在项目冷启动过程中,训练集来自于JData_Product文件中80%的项目以及JData_Action文件中80%的行为数据,测试集来自于JData_Product文件剩余20%的项目。评价指标采用均方误差(MSE)、均方根误差(RMSE)和平均绝对误差(MAE),实验结果如图8所示。从图8中可以看出,随着迭代次数的增加,IGNN模型的MSE值、RMSE值和MAE值总体趋于降低的趋势;在迭代40轮前,IGNN模型的3个评价指标数值变化明显,从40轮后,评价指标趋于平缓和稳定。
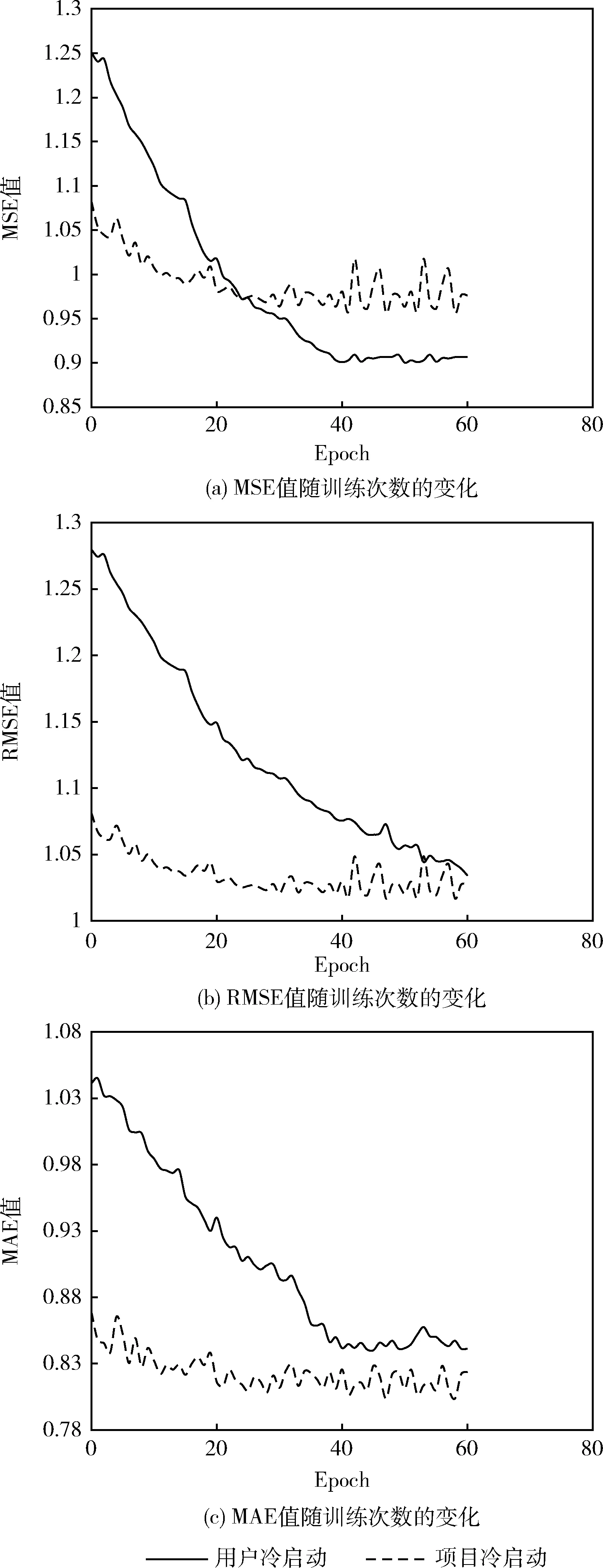
图8 评价指标MSE、RMSE和MAE随训练次数的变化
从图8(a)中可以看出,用户冷启动在前40轮迭代MSE值呈明显下降趋势,从40轮迭代后逐渐趋于稳定,最优MSE值为0.9612,横轴为训练次数,范围为[0,60],纵轴为MSE值,范围为[0.900 754,1.250 817],可以看出MSE值下降了27.9%;项目冷启动在前40轮迭代MSE值呈下降趋势,从40轮迭代后有较小幅度波动,最优MSE值为0.9067,横轴为训练次数,范围为[0,60],纵轴为MSE值,范围为[0.956 769,1.082 582],可以看出MSE值下降了11.6%。用户冷启动和项目冷启动在第24轮迭代时两个MAE值相等,在这之后,用户冷启动处于下降状态,项目冷启动则开始处于波动状态。
从图8(b)中可以看出,用户冷启动一直趋于降低趋势,最优RMSE值为1.0472,横轴为训练次数,范围为[0,60],纵轴为RMSE值,范围为[1.034 216,1.279 592],可以看出RMSE值下降了19.2%;项目冷启动在前40轮迭代RMSE值呈下降趋势,从40轮迭代后有较小幅度波动,最优RMSE值为1.0294,横轴为训练次数,范围为[0,60],纵轴为RMSE值,范围为[1.017 509,1.081 228],可以看出RMSE值下降了5.9%。
从图8(c)中可以看出,用户冷启动在前40轮迭代MAE值呈明显下降趋势,从40轮迭代后有较小幅度波动,最优MAE值为0.8636,横轴为训练次数,范围为[0,60],纵轴为MAE值,范围为[0.840 633,1.044 911],可以看出MAE值下降了19.5%;项目冷启动在前20轮迭代MAE值呈下降趋势,从20轮迭代后有较小幅度波动,最优MAE值为0.8201,横轴为训练次数,范围为[0,60],纵轴为MAE值,范围为[0.803 610,0.868 817],可以看出MAE值下降了7.5%。
本文实验选择6种常用于解决冷启动的方法,分别为STAR-GCN、MetaHIN、DropoutNet、LLAE、HERS和MetaEmb,与本文提出的模型IGNN作比较。图9和图10分别表现了用户冷启动模型、项目冷启动模型的实验结果对比。
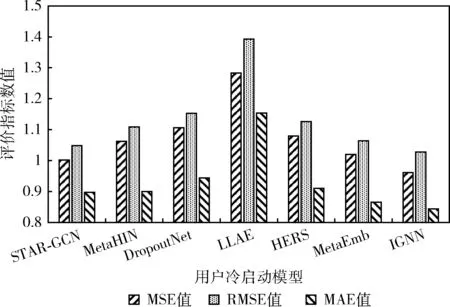
图9 用户冷启动模型实验结果对比
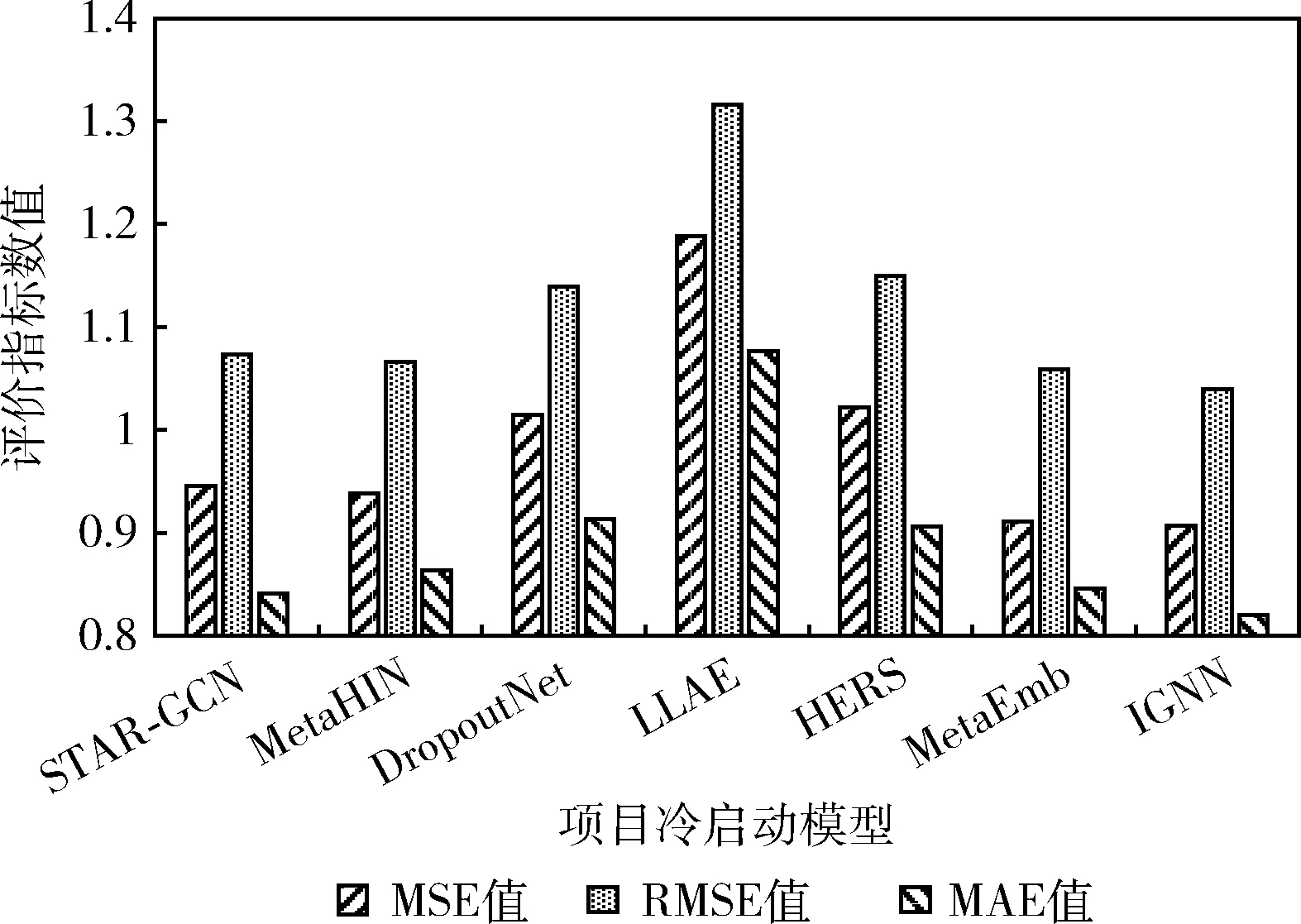
图10 项目冷启动模型实验结果对比
从图9中可以看出,在7个用户冷启动基线中,本文提出的IGNN模型性能最佳。IGNN的MSE值、RMSE值和MAE值对比于其它6个基线的最优值分别降低了4.05%、2.02%和2.47%。STAR-GCN在用户和项目的二部图上使用了图卷积网络,可以将信息聚合到节点嵌入中,MSE值和RMSE值表现性能次佳。在MAE值指标下,MetaEmb性能相对STAR-GCN较好,因为其通过元学习嵌入生成器,可以适应冷启动场景。LLAE的表现非常差,因为其目标是使用户的整个评分适合所有项目,并且有根据用户属性重构的向量,而评分预测是优化每个用户和项目对的评分。
从图10中可以看出,在7个项目冷启动基线中,本文提出的IGNN模型性能最佳。IGNN的MSE值、RMSE值和MAE值对比于其它6个基线的最优值分别降低了0.47%、1.80%和2.46%。MetaEmb通过基于梯度的元学习方法训练嵌入生成器,模型性能次佳。MetaHIN性能一般,因为它需要一套支持集以适应先验知识。DropoutNet效果并不好,因为DropoutNet需要内容信息来近似矩阵分解的结果,并且其性能取决于预训练的偏好嵌入。HERS性能表现和DropoutNet相似。LLAE的表现最差,因为其目标是使用户的整个评分适合所有项目,并且有根据项目属性重构的向量,而评分预测是优化每个用户和项目对的评分。
综上所述,在最优基准改进1%具有统计学意义,用户冷启动模型提升效果较为明显,项目冷启动提升效果一般,但优于目前基线方法。通过将属性图应用于用户冷启动和项目冷启动推荐场景,结果验证了本文提出的IGNN体系结构的性能优越性。
4 结束语
互联网金融产业对国民经济产生巨大影响,产生巨大经济效益并有巨大社会影响。互联网金融在快速发展过程中,强烈依赖于推荐系统。推荐系统为互联网金融注入了强有力的新鲜血液和留存了用户使用率。在推荐系统的实现中,解决冷启动问题对提升企业的经济效益,保留平台的用户留存率有着直接的影响效果。本文尝试将深度学习技术应用于京东电商平台商品推荐的研究中,提出了基于图神经网络结构的信息图神经网络。该模型利用改进的变分图自编码器重构偏好嵌入解决了偏好缺失问题,而且通过门控注意力结构提高模型容量,解决细粒度邻居聚合的问题。在MSE、RMSE和MAE评价指标下,与多种冷启动模型相比较,本文提出的IGNN模型在用户冷启动至少改进了2%左右,在项目冷启动至少改进了1%左右,有着更好的性能表现。
