面向软件在线升级过程的信任链机制
2022-10-01安美芳季宏志贺丽红
安美芳,季宏志,朱 琳,贺丽红
(1.北京交通大学 计算机与信息技术学院,北京 100044;2.中国铁路信息科技集团有限公司 网络安全部,北京 100844;3.中国网络安全审查技术与认证中心 综合与质量部,北京 100020;4.北京朋创天地科技有限公司 技术研发部,北京 100089)
0 引 言
信任链机制是可信计算最核心的内容之一。信任链是指系统将运行控制传递给下一级可执行代码之前,需要确认被调用代码是可信的。通过信任链机制,系统的运行完整性得到保证,比如它能够有效阻止系统被恶意代码感染和破坏,或者对使用人员安装和运行软件的行为进行有效规范和控制等,保证系统运行状态符合预期。
传统信任链机制实现都是通过可信标记方式来验证被调用代码是否可信。可信标记是在代码运行前通过多种方法对代码是否可信进行检测和分析。但是软件在线升级对上述信任链机制实现是一个严重挑战。因为软件在线升级后,系统在调用新升级的代码时,会存在代码不能通过可信验证的问题。但是在线升级能力对大多数软件已经是一种不可或缺的自我修复和自我提升机制,如果信任链机制不能很好地支持软件在线升级能力,那么可信计算技术的应用和推广必将受到极大的限制。
本文对软件在线升级过程中的信任链机制进行研究,提出一种软件在线升级代码的识别和实时可信判断方法,该方法无需对可执行代码本身的结构和行为进行分析,判断速度快,实时性好,不影响代码调用性能,保证良好的用户操作体验。本文研究结果对可信计算技术的应用和推广有极大的推动作用和十分重要的现实意义。
1 相关研究
信任链机制研究中的几类关键问题包括:①可信代码的标识和验证;②可信代码的运行完整性保证;③可执行代码的可信检测、分析和确认。
可信代码的标识一般常采用可信标签或可信代码清单等方式来表示,可信标签可以是与可执行代码相关联的数字签名(由可信的权威机构针对该代码文件签发)。为了保证可信代码清单的真实性和完整性,系统在引用可信代码清单之前会验证相关的数字签名。
为防止可执行代码在验证时可信,在运行过程中被破坏的情况发生(比如通过DMA方式向代码内存区域注入恶意代码),Intel、AMD和ARM等CPU厂商分别从硬件上提供了可信隔离保护支持基础,保证系统从加电引导到应用运行过程中具有一定适应能力的代码可信传递,同时通过新的指令集扩展和访问控制机制,保证应用程序能够运行在一个相对安全隔离的地址空间环境中,防止应用敏感数据被外部读取或破坏。在前述硬件支持的基础上,研究人员也针对可信运行环境(trusted execution environment,TEE)领域开展了大量研究,并提出不同方式和颗粒度的工程实现方法[1-4]。
可信代码的传递和运行环境保护获得保证后,剩下的信任链机制的关键问题就是如何判断被调用的可执行代码是可信的。目前常见方法有以下几种:信任模型方法、静态代码分析方法和动态代码行为分析方法等。
信任模型方法一般适用于对第三方软件的信任度量和信任度计算,信任模型可以采用基于软件来源、口碑、推荐、服务可靠性、权威认证等多种信任因子或这些信任因子的加权组合来建立。信任模型的研究是针对开放网络中参与方身份的信任验证问题,提出了基于其它网络节点推荐值的定量化信任度估计模型和方法。随着网络技术和应用的发展,信任模型的应用领域不断扩展,比如社交网络(social network)[5,6]、P2P网络(peer-to-peer)、云计算(cloud computing)[7,8]、物联网(Internet of Things)[9,10]、无线和自组织网络[11]等。
静态代码分析方法对程序源代码或目标代码进行检查和分析,判断软件是否有程序错误、安全漏洞或恶意目的的特征,从而确定软件是否可信。随着技术发展,静态代码分析方法也不断发展。早期对恶意代码的识别主要依靠对软件中恶意代码签名(signature)特征的检测和匹配,这种方法效率高,误报率低,但是恶意代码作者通过代码变换(比如软件加壳和代码混淆)就可以逃避这种检测。随着人工智能相关理论技术的发展和成熟,人们也将自然语言处理、机器学习和神经网络等技术方法应用在恶意代码签名特征的学习和分类中,以应对恶意代码作者对恶意代码签名特征的隐藏[12,13]。
相比恶意代码的签名特征,人们发现代码的行为特征能更好地反映出恶意代码的目的和恶意操作方式,因此动态代码行为分析方法采用行为特征作为恶意代码检测和分析中的判断依据,常见的恶意代码行为特征包括恶意代码的机器码序列、API调用序列和系统调用序列[14,15];为了克服代码混淆的干扰,研究人员让这些代码在沙箱和虚拟机等环境中实际运行,从而截获其行为序列特征,或采用静态代码分析和动态分析相结合的方法得到代码的行为序列特征[16]。
除了以上行为序列特征外,还有一些其它行为特征被采集并用于恶意代码的检测。比如通过对ROP/JOP攻击中配件出现的频率来检测代码重用攻击[17],或通过“污点”数据标记和跟踪,并提取非法操作时刻的系统快照作为特征来检测经过混淆的恶意代码。近年来以机器学习、神经网络和深度学习为基础的恶意代码检测和分析研究成为热点,这些研究基于高维复杂的特征对代码的可信度进行分类,可能更适合于恶意代码不断演变以隐匿自身逃避检测的安全现状[18,19]。
实施翻转课堂教学模式,活跃了课堂气氛,加强了学生的参与度,带来了课堂的高效性;大幅度增加了课上课下的互动时间,带来了师生和生生的深度互动性;激发了学生的学习兴趣,带来了学生学习的主动性;学生可自定学习步调,实现了学生学习的个性化;有充裕的时间培养合作学习、探究学习等,提高了学生协作沟通、创新等能力的培养;网络教学平台记录了所有学生学习的全部信息,实现了课程考核的过程化。
以上对可执行代码的可信度量和评价方法都存在各种局限性。基于恶意代码签名特征的检测方法难以应对攻击变种和代码混淆等方式攻击,其它方法要么需要独立的检测环境(比如沙箱或虚拟机等),要么在分析性能上不满足实时性要求,因此很难应用于软件在线升级等实际系统运行场景中。在软件在线升级这类场景中,新的升级代码在被下载到本地到被调用之前,系统往往对其相关信息一无所知,无法提前在独立环境中对它们进行检测分析,也难以承担在系统运行过程中开展代码实时分析所导致的系统运行延误(甚至中断)等严重影响系统运行稳定性和用户体验的后果。
(2)以人工的方式进行大致的摊铺。摊铺系数控制在1.2~1.3之间,不能抛掷材料。摊铺时,若出现材料成团,则需要及时的进行松散处理。
2 软件在线升级代码的识别和可信评价
系统程序是指操作系统提供的程序,或被广泛安装和应用的平台程序,比如.net平台。系统程序是一种公共服务型软件,用户可以用它们调用和创建(比如复制、下载等)任何其它程序,也可以被任何其它程序调用。比如Windows系统中的explorer.exe、svchost.exe、service.exe、cmd.exe等。
其中αi,βi,δi,σi和ki(i=1,2,3)都是待定常数。令Tan、Tanh和exα1+yβ1+tδ1+σ1等项的系数为零可得
在进入具体研究内容之前,我们给出两个可信假设。第一个假设是:可信软件的升级代码可以被认为是可信的。尽管这一假设可能存在安全漏洞,比如可信软件提供商出于其不正当的商业利益,在其在线升级代码中暗藏恶意代码,在后台收集用户主机中的敏感信息,但是在实际系统中,我们的可信假设仍然有十分重要的现实意义和合理性。
第二个假设是:当前运行系统支持信任链传递机制,即只有那些被认为是可信的可执行代码才可以被系统调用运行,比如这些可信的代码带有可信机构签发的数字证书,或者在可信代码清单中。
同时,我们对一些术语进行非严格定义的说明。软件是指一组服务于特定功能目的的可执行代码及其运行环境参数文件,一般可能包括主程序代码文件、动态链接库文件、运行参数文件等等,比如一个软件安装包安装之后,会在系统相应位置存放与软件功能相关的各种可执行代码和参数文件;程序是一类可独立被系统调用和运行的可执行代码,比如cmd.exe,系统中还有一些不会被独立调用和运行的可执行代码,比如动态链接库文件等,但是为了描述方便,并考虑习惯,本文对程序和可执行代码并不总是严格区分。
本文还给出一个关于同族程序的定义,两个程序是同族程序是指它们都来源于同一个软件安装包,并服务于同一服务目标。一般情况下,符合规范的软件都有其固定的一个或几个私有文件夹,包括它们在系统临时文件夹下的子文件夹,这些软件在安装完成后,它们的可执行代码文件都位于这些私有文件夹中。通过判断两个程序对应文件所在的位置,可以确定它们是否为同族程序。
另外,本文提到的可信标记是指在确认可执行代码可信后,将其放入到可信代码清单中,或者为其加上被系统认可的数字签名,或者加上其它系统能够辨识的标记,系统通过它们可以快速确认相关的可执行代码是可信的。
还有一点需要说明,某些第三方管理工具类软件(比如某类电脑管家)能够通过检测互联网资源,在发现特定软件版本发生变化后,自动下载和安装新版本的软件安装包。这一升级方式不属于我们前面定义的软件在线升级,因为它本质上是第三方下载和安装软件的过程,而不是软件代码自身检测升级并下载安装的过程。
本章首先对程序进行分类,然后对各类程序的特点进行分析和总结,进而提出一种识别可信软件在线升级代码的方法(software upgrade code identifying method,SUCIM)。
2.1 程序分类
SUCIM将程序按照其特点,分为以下3个类型:系统程序、工具类程序和一般应用程序。
在系统运行过程中,对被调用的未知代码进行判断,分析它们是否属于可信软件的在线升级代码,进而确定其是否可信,对支持可信软件的在线升级十分关键和重要,这也是本节的主要研究内容。
(3)递归生成模型,该模型中每个词的左子结点和右子结点分别由各自的马尔柯夫模型顺次产生:左子结点的产生方向是自右向左,右子结点的产生方向是自左向右的。每一个子结点的生成建立在支配词和它前一个子结点上,是自顶向下的递归生成式模型。
工具类程序是指非操作系统自带的,甚至是第三方机构提供的服务型软件,比如第三方FTP文件下载工具等。工具类程序具有一定的公共性,即操作人员可以通过它们调用和创建任何其它程序;但是与系统程序不同,它们不一定在每个用户主机系统中都有安装,即使安装也不一定像系统程序那样有众所周知的安装位置,因此它们往往是依靠操作人员手动调用,很少被程序自动调用。工具类程序的特点表明它们大概率会被用来创建和调用非同族程序。
一般应用程序是指非操作系统自带的,服务于特定功能并具有一定封闭性特征,它们能够被其它程序调用,但是不会调用除系统程序和同族程序之外的其它程序,也不会创建非同族程序。
2.2 程序类别标注
根据各类程序的特征,可以通过系统程序判断函数、数字签名识别或人工标注等方法对程序进行类别标注。系统程序判断函数能够识别指定程序文件是否属于操作系统程序;数字签名识别是通过对可执行代码文件的数字签名进行验证,确认它们是由操作系统厂商或平台软件厂商发布;人工标注指由管理人员基于可执行代码文件的特征,确定它们是否属于系统程序,并对其进行标注。
工具类程序的判断和标注要相对复杂,一般可以通过程序调用关系和代码创建关系来判断。比如,假定A为代码创建程序(或主调用程序),B为被创建代码(或被调用程序),如果A和B不同族,且A不是系统程序,那么A可以被判定为工具类程序。
未被标注为系统程序和工具类程序的其它程序都“暂时”被认为是一般应用程序。这里的“暂时”表示有些工具类程序还没有为人所知,被认为是一般应用程序。一旦它们调用或创建了非同族程序,就应该被标注为工具类程序。一旦程序被标注为系统程序或工具类程序后,除非管理人员手动修改,否则不可能被重新标注为一般应用程序。
式中:x和y分别为代码创建程序和被创建代码;p(x,y)是x和y的路径名相似度判断函数, 0≤p(x,y)≤1, 值越大,表示x和y的路径名越相似,p(x,y) 有多种实现方法,比如采用NLP、余弦相似度、正则表达式等,具体选择还要取决于这些方法对系统性能的影响;q(x,y) 是基于文件命名可读性、存放位置和代码创建频率等因子的代码规范性函数,0≤q(x,y)≤1, 值越大,表示x和y所属软件的规范化程度越高,意味着x和y是同族程序的可能性越大。
2.3 软件在线升级代码的识别和处理
SUCIM中,当代码创建程序为一般应用程序时,如果被创建代码与代码创建程序是同族程序,那么可以认为该被创建代码是代码创建程序所属软件的在线升级代码,因此应该被添加到可信代码清单中。
根据同族程序的定义,可以通过比较两个程序的路径名是否相似来判断它们是否同族。
2.2节和2.3节过程流程如图1所示。
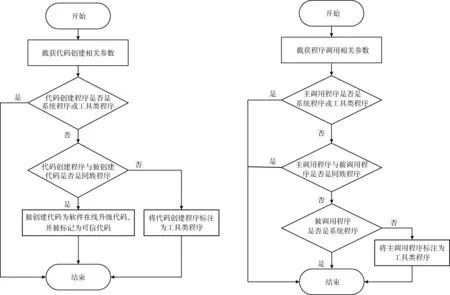
图1 SUCIM对程序创建和程序调用的处理流程
2.4 风险分析
本节从恶意攻击、用户不规范操作和应用正常升级被误拦截等3个角度对SUCIM展开风险分析。
2.4.1 恶意攻击
恶意攻击是指攻击者利用SUCIM机制本身将恶意代码伪装成可信软件的升级代码,从而使它们被加入到可信代码清单中。
SUCIM通过同族程序关系确定被创建代码是否为软件在线升级代码,因此针对SUCIM的恶意攻击会利用以下方法来实现攻击:①通过系统程序或工具类程序将不可信程序(比如恶意代码)复制(或下载)并保存到系统任意位置,并试图调用和激活它们;②通过一般应用程序将不可信程序(比如恶意代码)复制(或下载)并保存到同族的文件夹中,并试图调用和激活它们。
虽然一部分特色农产品企业已经认识到了英语标准化翻译的重要性,但在实际中却存在很多问题。如拼音的过度使用、片面的中式英语翻译、错误翻译等,使农产品英语标准化翻译成为空谈,极大地影响
从中国经济宏观环境来看,中美贸易摩擦对峙,短期内可能会对中国经济发展带来负面影响,如加剧通货紧缩的压力,增加人民币贬值的可能性,影响劳动力就业率等。
第一种攻击方法会被SUCIM阻止。复制(或下载)程序的过程本质上是一个代码创建过程,由于代码创建程序是系统程序或工具类程序,因此无论不可信程序被复制或下载到系统任何位置,SUCIM都不会将它们添加到可信代码清单中。
第二种攻击方法只有在以下情形下可能成功:①复制或下载不可信程序的一般应用程序实际上是一个还未被标注的工具类程序,因为它与被创建代码是同族关系,所以被创建代码(不可信程序)会被添加到可信代码清单中,成为可信代码,因此可以被成功调用。SUCIM应该提高对工具类程序的自动发现和标注能力,只有这样才可能有效阻止这种攻击方式;②复制或下载不可信程序的一般应用程序有安全漏洞,攻击者熟知并利用这些漏洞,将不可信程序复制或下载到同族文件夹下,从而被加到可信代码清单中并成为可信代码,要防范这种攻击,需要发现或了解应用程序的安全漏洞。
2.4.2 用户不规范操作
同样,用户不规范操作带来的无意识攻击与恶意攻击在实际操作中并没有本质区别,主要差异体现在攻击者和一般用户在攻击位置、攻击执着程度等方面的不同。比如,攻击者对软件漏洞的了解程度高于一般用户,对攻击的成功要求也高于一般用户;而一般用户的违规操作则往往是一种浅尝辄止的试探行为,攻击成功的范围和概率也因此较小而且随机。
陈升茶厂成立于2006年,经过12年的发展,已经成为一家拥有300余名员工,数百户签约农户,集普洱茶精制加工、生产、销售及茶文化和民族风情为一体的省级产业化重点龙头企业。而陈升茶厂所在的勐海县被称作“中国普洱茶第一县”,吸引着大批企业家投资设厂,其中包括一些不规范的代加工企业,他们在规范化生产、人力、设备等各方面投入成本低,有些甚至存在虚开发票等违法行为,严重影响和扰乱了市场秩序,对大型民营企业发展也造成了很大压力。
2.4.3 应用正常升级被误拦截
实际系统中,有些软件可能包括不止一个祖宗目录,比如有些软件还在系统临时文件夹下创建自己的子文件夹等。对于这种情况,可以根据多个祖宗目录的相似程度来确定它们是否为同族程序。
3 同族程序判断方法
基于以上风险分析可以看出,对同族程序的判断准确程度决定了SUCIM的实际有效性。如果将本是同族程序关系的一般应用程序误判为工具类程序,那么正常的软件升级过程就会被SUCIM拦截;如果将工具类程序等漏判为一般应用程序,那么就可能导致不可信的程序被标记为可信代码。本文研究的目标是确保在不可信程序不会被SUCIM标记为可信代码的前提下,尽量减少可信软件正常升级被SUCIM拦截的概率。
3.1 基于程序路径名相似度的同族程序判断方法
政府方,优选财政实力较强的市或区级政府,须查看经财政部门审核下发的部门预算文件。商业银行还需开展再评估工作,结合区域内全部 PPP 项目规划方案,统计未来年度财政支出责任,确保每一年度本级全部 PPP 项目从一般公共预算列支的财政支出责任,不超过当年本级一般公共预算支出的10%。
判断两个程序的路径名是否相似,首先要排除操作系统的文件路径。系统文件路径的获取方法比较简单:在一个原生(未安装应用软件)的操作系统中,对系统的文件目录进行递归扫描即可获得。通过这种方法获得的系统文件路径具有一定的通用性,可以应用在同样操作系统版本的主机环境中。比如,在一个原生的Windows10系统中, C:Windows 及其下一级目录、 C:ProgramFiles(x86) 及其下一级目录、 C:ProgramFiles及其下一级目录等都被视为系统文件路径。
将开始区分于系统文件路径的第一级文件目录(包括根目录)定义为同族程序的祖宗目录,即同一祖宗目录下的程序都属于同族程序。比如, C:ProgramFiles(x86)adobe 是Adobe Reader软件的祖宗目录,该目录及其各级子目录下的程序被认为是同族程序。
观察组:采取生化检验法,在检查前一晚,病患遵医嘱禁食禁饮,第2天早晨保持空腹状态进行采集静脉血,剂量5 mL。采用医疗专业设备全自动生化分析仪,对病患的TC(血清总胆固醇),TG(甘油三酯),2 hPBG(餐后2 h血糖)和葡萄糖耐量情况进行观察。
SUCIM可能会导致某些应用在正常升级后被误拦截。比如有些应用软件的开发过程不够规范,其升级下载的代码可能因为与代码创建程序不是同族关系,没有被SUCIM加入到可信代码清单中,并因此被系统拒绝运行。
我国数据信息比较丰富,政府掌握着80%以上的数据,但是政府有关部门没有正确认识到数据资源的巨大价值,缺乏对数据资源挖掘利用的意识,不能有效发挥数据资源的应有作用。主要是长期以来我国政府管理模式是以经验为主的行政体制,政府机构以科层制的管理模式运行,政府大数据治理理念缺乏,数据管理意识落后,不愿意共享开放,仍然沿袭着传统的管理思路,认识不到数据对政府治理能力建设的重要性,传统的思维意识与管理理念影响了大数据深入应用,阻碍政府治理创新发展。
3.2 改进的同族程序判断方法
由于上述实现只是对SUCIM的原理可行性进行一个初步验证,因此对a和b没有特别训练,而只是简单的都设置为1,f(x,y) 的临界值也设置为1,当f(x,y)≥1时,x和y被认为是同族程序,否则x和y不同族。
根据大量软件样本分析,一个有良好开发规范的软件会在程序命名和存放位置上有好的惯例。比如,软件升级过程经常利用系统临时目录存放(或暂存)所下载的程序代码,但是,基于良好开发规范的软件与不规范软件(或恶意代码)有明显区别,后者在文件命名、文件数量和文件保存位置等方面更加随意,更倾向于故意隐藏自身,比如,文件命名没有规律导致缺乏可读性或可理解性,或者存放在其它软件的文件保存目录中,以让分析人员无法正确判断其功能目的或身份来源。
改进的同族程序判断方法在基于程序路径名相似度的同族程序判断方法基础上,更多地将软件开发习惯和规律等因素纳入算法判断中,比如前面提到的文件命名、系统临时目录使用方式、文件创建频率和存放位置等因素,比如代码创建程序在同一个目录位置中创建代码文件的频次如果大于一个阈值,远超人工创建文件的正常速度,那么这个代码创建程序为工具类程序的可能性就相对较低。
本文提出一个改进的同族程序判断算法,用于验证SUCIM的技术可行性,算法框架如下
f(x,y)=a*p(x,y)+b*q(x,y)
在SUCIM的实现中,程序的调用和创建过程及其相关参数可以通过系统钩子机制截获和实时分析,比如在Windows系统中的文件过滤驱动层设置钩子机制,可以截获程序创建过程的各种信息,包括程序的位置、类型等。
a、b分别为函数p(x,y) 和q(x,y) 在结果函数f(x,y) 中的权重,a、b≥0,a+b=1。
f(x,y) 可以表示为一个0或1的二值函数:a*p(x,y)+b*q(x,y) 大于一个预设的(或者通过训练得到的)临界值时,f(x,y)=1, 表示x和y是同族程序;否则f(x,y)=0, 表示x和y不是同族程序。
3.1节基于程序路径名相似度的同族程序判断方法在实际应用中还存在较大的误差,可能导致SUCIM将很多一般应用程序标记为工具类程序,从而将正常的软件升级过程拦截。出现这一问题的原因是因为基于程序路径相似度的同族程序判断方法不能完全反映软件开发的习惯和规律。
按照实验方法测定钴产品生产过程CoCl2净化液(样品5)和Co(NO3)2净化液(样品6和7)中Cu、Fe、Ni、Cd、Zn、Mn、Mg、Si、As,并与标准方法YS/T 281—2011所规定的检测方法结果进行对照,结果见表13。
4 实验验证
对SUCIM的效果和性能要通过实验进行验证。要验证的内容和目标包括:
(1)可信软件在线升级精确率。即正确判断可信软件在线升级代码数量占所有判断为可信软件在线升级代码数量的比例,它也反映了SUCIM将不可信程序判断为可信软件在线升级代码的比例,基于SUCIM的功能目标,这个精确率需要达到100%。
(2)可信软件在线升级召回率。在所有被测试的可信软件中,能够被正确判断出来的比例。在精确率达到100%的前提下,尽量提高召回率,因为召回率越高,可信软件在线升级成功的比例越高。
4.1 实验环境和实验数据来源
由于目前还没有相应的开源数据集可以用来对SUCIM进行训练和验证,所以只能从互联网上下载各类软件,对基于3.2节改进的同族程序判断方法所实现的SUCIM进行测试和验证。
为了保证测试环境的可重复性,同时保证有足够的测试环境数量,实验环境采用了基于KVM的虚拟桌面系统,包括多个实验母本,包括Windows7和Windows10两种操作系统;每个母本安装不同的测试用软件,这样既可以很方便地测试多个应用软件,而且还能够通过虚拟机还原到母本状态,保证实验的可重复性和可验证性。
Study on solid liquid separation technology of human fecal water
测试应用软件包括办公、游戏、视频、浏览器、聊天、输入法、音乐、图片、系统、编程等各种类型。其中一部分通过杀毒软件检测,确认为非恶意代码后,被加入到可信代码清单中(共41个);另一部分则作为不可信软件用例(共6个)。
在北大,我也碰到个别有负面情绪的年轻人,他们不是抱怨工资太低,领导对自己不好,同事缺点太多,就是抱怨社会不公平,自己没有机会。试想一下,这样的人怎么可能工作顺畅,事业成功呢?
4.2 实验结果和讨论
实验结果中,6个不可信软件都没有被SUCIM标记为可信软件,符合我们的目标;41个可信软件的升级过程中,有36个顺利完成,5个被SUCIM拦截。可以得出SUCIM的精确率和召回率分别约为87.8%和100%。
我们对不成功的软件升级过程进行深入分析,发现这些升级被拦截的软件都有一个共同点,它们都习惯在系统文件夹或公共文件下创建文件,并且文件命名也非常随意,导致它们被SUCIM判定为工具类程序,进而认为它们所创建的程序不属于可信程序。
我们还发现,这些升级被拦截的软件,有些行为特征与恶意代码的隐匿特征非常相似,其中很大一部分软件(如某些浏览器和终端安全/管理类软件)的确也存在一些不良行为,虽然SUCIM导致它们自动在线升级失败,但是从另一个角度分析,这一结果对于用户以及恶意代码发现也不失为一件好事。
5 结束语
SUCIM的核心算法是同族程序判断方法,截至目前,我们只是基于自身对软件开发的一些惯例和规律(以及对恶意软件的一些特性)的认识和经验,人工设计了一套判断规则及其相关参数,实现一个初步的同族程序判断算法,显然,这个初步实现难免存在各种不足。
下一步的研究中,我们将重点从两个方向继续深入,一是采用多节点分布式截获代码调用和代码创建过程信息,然后可信软件在线升级过程进行综合判断,这样能减少或避免单节点环境中的可能误判;二是建立有更多、更合理测试样本的软件用例库,并提取和建立有效特征库;在算法设计中,引入机器学习和神经网络等技术,在大样本空间的基础上,避免过于依靠人工经验,得到更准确的同族程序判断模型,从而进一步提高SUCIM的实用性。
