基于改进CDC的实验原始记录匹配算法
2022-09-27蔡伊娜陈新覃志武王歆包先雨彭锦学林泳奇李俊霖
蔡伊娜,陈新,覃志武,,王歆,包先雨,,彭锦学,林泳奇,李俊霖
1)深圳市检验检疫科学研究院,广东深圳 518045;2)深圳海关食品检验检疫技术中心,广东深圳 518045;3)深圳海关信息中心,广东深圳518045
随着实验室检测技术的精细化,如何从大量数据中提取有用信息成为实验原始记录文件处理研究的重点,字符串匹配是最常用的方法之一.经过几十年的发展,字符串匹配已广泛用于文本处理[1]、问答系统[2]和生物信息处理[3]等领域.
目前,实验室用于检测的设备普遍型号多,且存在检测报告需人工录入数据的现象,导致检测时间长和易出现偶然性差错等问题,难以满足现代数字实验室的建设和管理要求.字符串匹配作为文本处理的核心,直接影响数据采集效率.将高效的字符串匹配算法用于数字实验室的数据处理中,是缩短检测时间,减少偶然性差错的有效途径.实验室检测样品时,检测设备一般都会输出一个或多个实验原始记录文件.在形成检测报告前,需对该文件中的部分数据进行匹配和自动提取.由于该文件一般都具有固定的格式,针对此特点,现有的字符串匹配方法已有了一定的应用.但遇到实验原始记录中的大文件或多文件时,则存在计量大匹配速度慢和占用内存大等不足,难以满足现代数字实验室降本提效管理的需求.提高实验原始记录文件中的字符串匹配速度,减少内存占用量,在保证数据匹配准确性的前提下缩短检测时间,这在当前检测业务量日益增加的形势下,解决实验原始记录文件高效匹配的问题刻不容缓.
字符串匹配即在任意一个长度为m的文本串T中,找出给定一组特定的字符串集合Pn(Pn的长度小于m)在T中的所有出现位置[4].在实验原始记录文件中,数据匹配格式是以文本为主.根据模式串数目的多少,现有的针对文本文件的字符串匹配算法可分为单模式匹配算法和多模式匹配算法[5]两类.随着人们对单模式匹配的深入研究,现阶段主要利用模式串具有前缀和后缀的特点来提升算法性能,如王东宏[6]基于后缀数组的单模式匹配建立的可验证模式串匹配方法可靠性高,同时给出扩展方案实现多模式匹配提升了匹配速度.之后,又陆续出现了改进Trie 树的Aho-Corasicsk(AC)优化算法[1]、基于SHIFT 表的modified Wu-Manber(MWM)算法[7]、基于跳跃和确认机制的子集WM 算法[8]等多模式匹配算法.然而,无论是单模式还是多模式匹配算法都追求以1 个参数适用于所有目标文件,因此,不可避免地出现匹配速度低,预处理时间长和内存占用大等问题,难以满足数字实验室高效处理数据的需求.
字符串自适应匹配也是当前研究的一个重点.刘许刚等[9]设定出现频率高且模式串中不包含的u为特殊字符对文本进行分段,但该方法在处理实验原始记录等无高频字符的文件时,无法对目标文本进行分段.黄勇等[10]提出完成在当前窗口匹配后,通过提前预览下一窗口基准字符的偏移信息,以期跳过尽可能多的窗口来进行下一轮匹配,但该算法对模式串具有依赖性,且性能不稳定.
面对上述算法预处理时间长、内存占用大、分段困难和模式串依赖大等问题,董志鑫等[11]提出一种改进的多模式串匹配算法,通过基准长度分段和哈希(hash)算法跳过大量的字符,该方法虽提升了内存占用量,但精确度有所下降.TRIVEDI[12]提出一种优化的Aho-Corasicsk算法,先将潜在的匹配模式串与输入文本进行比较,多次尝试实现匹配,该方法虽操作性佳,但存在内存占用量大、精确度低等问题.
而在数据分块预处理研究中,传统的内容可变长度分块(content-defined chunking,CDC)算法用一个滑动窗口来划分可变长度的数据块,当滑动窗口的hash 值与一个基准值相匹配时就创建一个分块,滑动窗口的大小是固定的,因此,CDC算法局限性主要体现在系统开销大、耗时长和准确率低等问题[13].李建江等[14]提出一种改进CDC的优化算法,首先让滑动窗口向前滑动,忽略窗口内指纹的计算和取值,直到该数据块的长度等于设定的最小长度,之后比较滑动窗口指纹值,同时要保证该数据块的最大长度小于设定的最大长度.若达到最大长度时,该数据块仍不能满足分块条件,则在此位置强制分块.但是,该算法因滑动窗口移动慢且匹配次数过多,分块效率有待提升.此外,BJØRNER等[15]提出local maximum chunking(LMC)算法,通过滑动窗口进行分块,滑动窗口由左窗口、局部最大字节和右窗口3部分组成,但算法存在耗时长的缺陷.
1 原始记录自动抓取
根据数字实验室管理的要求,实验室信息管理系统(lab information management system,LIMS)需要对检测设备所输出的实验原始记录文件实现自动抓取功能.本研究设计了基于栅栏因子的通用实验原始记录文件自动抓取技术(图1).针对实验原始记录文件“当日事当日毕”的管理要求,将时间设置为一个栅栏因子,通过比较文件创建时间和系统时间,初步过滤掉非当日实验原始记录文件.采用完全文件检测(whole file detection,WFD)技术,以文件为颗粒度计算文件的hash 值作为另一个栅栏因子,过滤已读取的文件,防止重复读取文件[16].
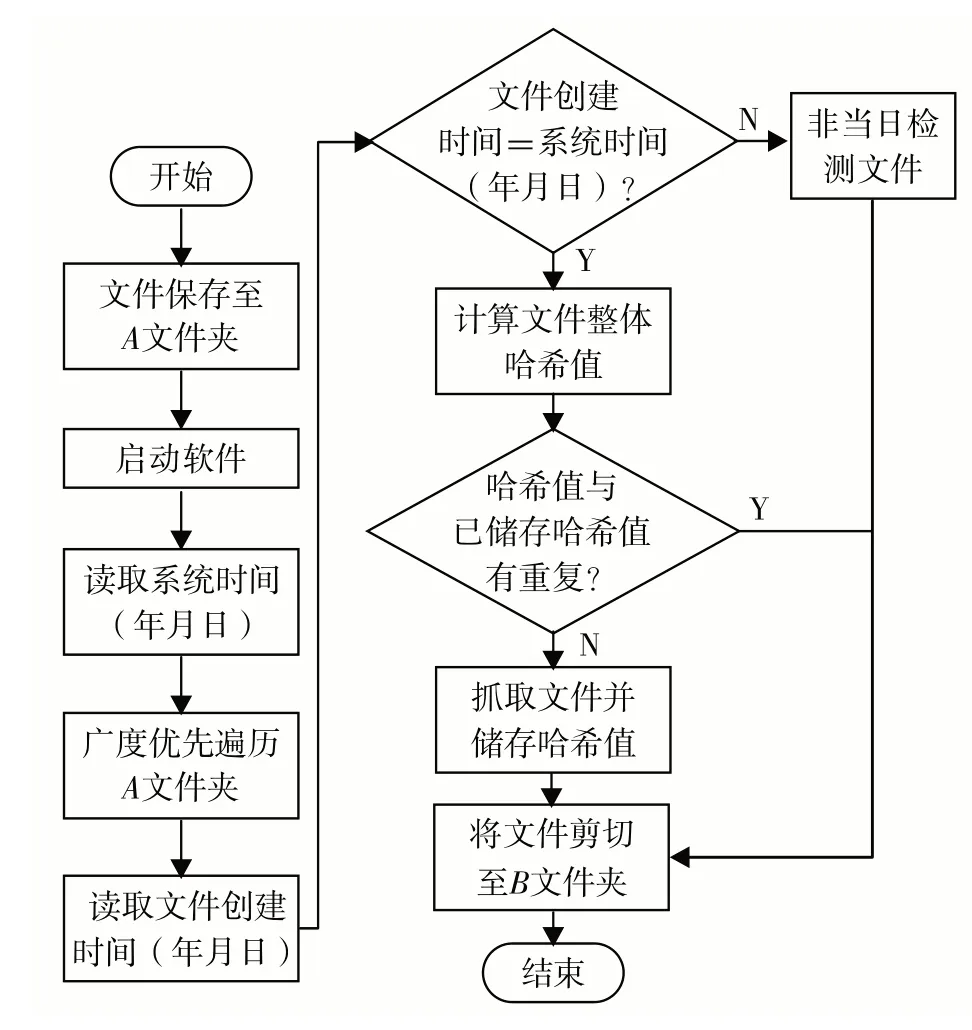
图1 实验原始记录自动抓取流程图Fig.1 Automatic capture process of experimental original records.
抓取步骤具体描述为
1)将实验原始记录文件保存在A文件夹中.
2)全部文件保存完毕后,启动实验原始记录文件智能匹配软件.
3)软件自动读取系统时间,并转换为以8 位数字形式呈现的年月日格式,得到时间栅栏因子.
4)使用队列结构实现广度优先遍历,先从头部取出母文件名打印并移除,然后把母文件夹下的子文件名添加到队列.这样,在遍历的时候,文件名层级相同,从而实现了广度优先遍历文件夹,获取文件.
5)通过指定路径文件所对应的File 对象,提取当前FileInfo 对象的创建时间,并将时间转换为年月日格式.
6)比较文件的创建时间(年月日)与系统的时间栅栏因子是否为当日检测所得的实验原始记录文件.若时间相同,按照步骤7)计算哈希值;否则,表示文件为非当日实验原始记录文件.
7)将整个文件作为一个颗粒度,利用SHA-2哈希算法计算文件的哈希值,得到哈希值栅栏因子.
8)比较文件哈希值与已储存哈希值栅栏因子是否重复.其中,已储存哈希值是指每次读取文件所保存的文件哈希值.若重复,表示之前已读取过该文件;若哈希值不重复,继续下一步.
9)抓取文件并储存哈希值.
10)通过文件搬运的方法,将非当日实验原始记录文件、重复文件和读取过的文件剪切至B文件夹保存,以方便后续读取新文件.
该文件抓取技术建立了文件创建时间初筛和文件哈希值精筛两项栅栏.在初筛时,该技术能以低计算要求和低计算量的优势过滤全部非当日文件;在精筛时,通过计算文件整体哈希值准确过滤当日已读取的文件.
2 匹配算法
字符串匹配算法分为预处理和匹配两个过程.本研究首先通过改进CDC 算法对实验原始记录文件进行分块预处理,再将数据块哈希值、数据块位地址和模式串等构建数据块索引表,使数据块与模式串之间形成映射关系,实现模式串在映射的数据块中进行灵活的字符串匹配.通过引入可变长度分块和建立映射关系,使字符串匹配的效率和效果得到优化.
2.1 基于改进CDC的分块算法
CDC 算法是应用Rabin 指纹将文件分割成长度大小不一的分块策略[16],用一个固定大小的滑动窗口来划分文件,当滑动窗口的Rabin 指纹值与期望值相匹配时,在该位置划分一个分割点,重复这个过程,直至整个文件被划分,最终文件将按照预先设定的分割点被切割成数据块.
检测设备输出的实验原始记录文件有着固定文件格式的特点,因此,本研究通过改进传统的CDC,设计一种适用于格式固定的文件分块算法,流程图如图2.

图2 基于改进CDC的分块算法流程图Fig.2 Flow chart of block division algorithm based on improved CDC.
基于改进CDC的分块算法具体实现步骤为:
1)读取已抓取的文件.
2)设定一个大小为w的滑动窗口,以行与行间距之和的高度为1个单元进行滑动,直至滑动窗口被数据装载完毕.
3)设定滑动窗口内字节值大小范围,在滑动窗口被数据装载完后,比较滑动窗口字节大小是否在设定范围内.若是,跳到步骤4);否则,滑动1个单位并重复步骤2).
4)计算窗口内的Rabin指纹值.
5)比较Rabin 指纹值与循序渐进表中预设的滑动窗口期望指纹值.若两值相等,则继续步骤6);若两值不相等,重复步骤2)滑动一个单位.
6)以滑动窗口下边界作分割线,对文本进行分割.
7)判断滑动窗口是否抵达文件结尾处,即文件是否分块完毕.若是,则文件分块完成;否则,滑动1个单位并重复步骤2).
此过程中循序渐进表先设定模式串对应的期望指纹值,根据文本匹配的模式串种类和顺序确定表格匹配顺序.假设第1个模式串对应的期望指纹值为A,滑动窗口某位置D的Rabin 指纹值为f,当滑动窗口某位置时若fmodD=A,则将D的下边界作为一个分割线,创建1个分块,以此类推.从而使模式串在数据块前段完成字符串匹配,减少了匹配其余文本的操作,从而提高了匹配速度.
与传统的CDC 算法相比,基于改进CDC 的分块算法有以下改进:①设定了以行与行间距之和作为滑动窗口的高度向下移动的1 个单位.传统CDC算法以1个字符为单位向右移动,而本研究算法可大幅减少匹配次数,缩短了分块时间.②规定了滑动窗口内字节大小的范围,初步过滤掉大部分不符合分割条件的滑动窗口位置.传统CDC 算法每滑动1 次滑动窗口,都需要计算1 次窗口的Rabin 指纹值,并与设定的期望值进行比较,而本研究可减少滑动窗口的Rabin 指纹值的计算次数,有效降低分块算法的计算量.③制定了滑动窗口期望指纹值的循序渐进表.传统CDC 算法由于设定固定期望值,易将待匹配数据分属到2个数据块中,导致匹配失败,而本研究算法能更精准地划分文本数据块的大小,有效避免这种情况的发生.
2.2 基于数据块索引的字符串匹配算法
实验原始记录文件具有文本串T大而模式串Pn少的特点,使用传统的字符串匹配方法易出现模式串匹配次数多、匹配时间长和计算复杂度高等问题.本研究提出基于数据块索引的字符串匹配优化算法,在文件分块后,将数据块的Hash 值与模式串和数据块位地址组成数据块检索表.接着,模式串通过数据块索引表快速匹配到相应数据块.最后,模式串利用单模式匹配暴力(brute-force,BF)算法与映射的数据块进行字符串匹配,得到字符串匹配结果.数据块索引表如表1.其中,数据块索引表的每条记录都以数据块身份标识号(identity document,ID)作为主键;数据块位地址表示数据实际的物理位置.数据块索引表中还保存着数据块Hash 值、对应的模式串.所有记录根据数据块ID存放在数据块索引表中,以此来保证查找的速度,降低匹配所需时间.

表1 数据块索引表Table 1 Block index table
模式串与数据块的相互匹配可根据模式串的长短选择适合的单模式匹配算法,以提高匹配效率.当模式串匹配的文本位置较集中时,可将文本划在一个数据块中,将单模式匹配算法转化为多模式进行精准匹配,从而减少分块数量,避免出现过小分块.通过建立模式串与数据块之间对应的映射关系,成功构建灵活多变的模式串匹配算法.该算法不仅可提高字符串匹配效率,还可适用于不同的实验原始记录文件.
3 实验与结果分析
3.1 实验环境
实验硬件环境为:处理器Intel®Core ™i7-2670QM CPU@2.20 GHz,4 核;软件环境为:Ubuntu 16.04(64 bit)、C 语言、GNU C 编译器version 5.4.0.通过内存占用量实验[10]和计算分块吞吐量对基于改进CDC 的分块算法进行测试.实验所用仪器和实验原始记录文件均由深圳海关实验室提供,实验运行时间单位为ms.
3.2 内存占用量实验
因本研究关注的是匹配性能,所以实验比较了分别采用基于改进CDC 的分块算法、优化Aho-Corasick 算法[12]和DKR 算法[11]时所用的内存占用量.实验使用安捷伦液相色谱仪1290Q(D030202)输出的实验原始记录文件,模式串个数分别为100、200、400、800 和1 600,单个模式串长度在2~10.使用最大驻留集的大小来表示程序运行中内存占用量,实验结果如图3.

图3 不同模式串个数对应算法内存占用量Fig.3 The memory consumption under DKR(triangle),optimized Aho-Corasick(cicle),and our algrithm(square).
由图3可见,当模式串个数较少时,基于改进CDC 的分块算法在内存占用量方面比优化Aho-Corasick和DKR算法有明显优势.对于模式串匹配个数不多的实验原始记录文件来说,在实际运用中基于改进CDC 的分块算法在内存占用量上更具优势,能够降低对设备的硬件要求.
3.3 分块吞吐量实验
分块吞吐量(chunking throughput)是通过将数据大小除以处理的数据量和分块文件所消耗的时间量来计算的,即

其中,因为本研究关注的是分块性能,所以此时的分块时间不包括数据读取时间.
为分析本实验在分块方面的性能,比较基于改进CDC 的分块算法、LMC 算法和传统CDC 算法的分块吞吐量.LMC算法使用固定的对称窗口和文件的字节值来检测切割点,规避了传统CDC 算法存在的计算量大的问题.根据深圳海关实验室提供的原始记录文件份数的不同,实验共进行8 组测试,选择实验原始记录文件数据集共4个.为避免因偶然性导致的异常结果,每组匹配测试分别进行10次,并以10 次实验结果的平均值作为最终的分块吞吐量.
由图4可见,本研究提出的基于改进CDC的分块算法的分块吞吐量明显高于传统CDC 算法和LMC算法.

图4 三种算法分块吞吐量对比Fig.4 Comparison of block throughput of CDC(blank),LMC(forward slash),and our algorithm(backslash).
结论
提出基于改进CDC 的实验原始记录匹配算法首先对实验原始记录文件进行抓取,然后改进现有CDC算法实现文本分块,再通过数据块索引表建立模式串与数据块的映射关系,形成了高效灵活的字符串匹配优化算法.该算法在模式串个数较少时,内存占用量少.而在分块吞吐量方面,与DKR 算法和传统CDC 算法相比,本研究提出的算法提升较为明显.因此,该算法可广泛应用于数字实验室中的实验原始记录快速处理.
