机器学习算法在燃料棒温度性能预测中的应用
2022-09-27洪亮金鑫刘虓瀚卫小艳
洪亮,金鑫,刘虓瀚,卫小艳
中广核研究院有限公司,广东深圳518026
机器学习是人工智能研究的核心技术,它从数据中自动分析获得规律(模型),并利用规律对未知数据进行预测.机器学习算法能够处理大量数据,自动调节各因素权重,建立数据与认知之间的直接映射,跳出了“知识”的束缚.随着计算能力的提升、新学习工具的出现和算法的不断改进,机器学习(包括神经网络)逐渐在工业领域得到更加广泛的应用[1-6].
在核电领域,机器学习现已广泛用于堆芯物理参数计算、核素含量预测和堆芯事故诊断等过程.周剑东等[7]基于决策树的模式识别方法对堆芯物理参数进行预测,实现了参数的快速预测并取得了较好的预测精度.黄禹等[8]采用误差反向传播(back propagation,BP)算法基于堆芯核功率、入口温度、流量和压力等变量对堆芯偏离泡核沸腾比(departure from nucleate boiling ratio,DNBR)进行快速预测,并得到了较好的准确性.BAE等[9]采用神经网络在给定初始富集度和燃耗条件下预测压水堆(pressurized water reactor,PWR)的乏燃料的同位素成分.李仕鲜等[10]采用神经网络方法对核电厂的失水事故(loss of coolant accident,LOCA)进行诊断和预测,证明神经网络对破口位置和尺寸的诊断准确率较高且诊断稳定性较好.
燃料棒是反应堆的第1道安全屏障,也是反应堆产热的唯一源泉,其性能直接影响反应堆的安全性、可靠性和经济性,因此,正确预测燃料棒在堆内辐照行为是燃料设计和性能评价的基本要求.由于燃料棒在堆内行为复杂,且各种行为相互耦合,常需要开发专业的燃料棒性能分析软件来预测燃料棒的性能.此类软件的开发过程涉及大量试验数据、复杂的模型建立和模型验证与确认,开发周期通常在10 a左右.其中,包壳外表面温度和芯块中心温度是燃料棒设计需着重关注的重要性能参数.
针对燃料棒性能分析软件开发投入巨大和研发周期漫长的特点,本研究采用机器学习算法构建基于芯块材料类型、包壳材料类型、燃料棒轴向高度、轴向局部功率、堆芯入口温度和包壳水侧腐蚀厚度6个物理特征参数的包壳外表面温度和芯块中心温度性能参数(目标参数)预测模型.采用机器学习方法不需要进行复杂的热力耦合模型开发,而是通过建立特征数据与性能数据之间的对应关系进行参数预测,从而缩短软件开发周期,节约研发成本.用于机器学习算法训练和测试的数据集要求的数据量大且维度多,一般实验数据无法满足该要求.因此,本研究主要关注基于机器学习算法的燃料棒温度模型的训练和测试,探讨机器学习算法在燃料棒性能分析中的应用,采用燃料棒性能分析软件JASMINE[11]的计算结果作为训练和测试数据集.所用机器学习算法分别为k近邻(k-nearest neighbor,kNN)[12]、决策树(decision tree,DT)[13]和集成学习算法AdaBoost[14].kNN算法是基于距离样本特征最近的k个样本的目标平均值来进行预测,参数k对预测准确性有影响.DT算法是基于迭代二叉树3 代(iterative dichotomiser 3,ID3)、C4.5 或分类回归树(classification and regression tree,CART)算法在每个节点上对特征进行判断,从而形成的一种树型结构,本研究采用CART 算法.AdaBoost 算法是一种有效且实用的提升(boosting)算法,其算法原理是通过调整样本权重和弱学习器权值,从训练出的弱学习器中筛选出权值系数最小的弱学习器组合成一个最终强学习器.
1 模型框架
基于Python 的集成开发环境PyCharm,使用Scikit-learn 工具包进行数据处理、模型训练和模型预测.图1为本研究构建的基于JASMINE软件数据预测包壳外表面温度和芯块中心温度的模型框架.该模型由数据集构建、模型训练和模型预测与评估3部分构成.

图1 基于JASMINE软件数据预测包壳外表面温度和芯块中心温度的模型框架Fig.1 Model framework for prediction of cladding outside surface temperature and pellet center temperature based on JASMINE software.
数据集构建.采用JASMINE软件的输入参数和输出结果作为机器学习算法训练和测试数据集,建立输入参数与输出结果之间的函数关系.JASMINE软件的输入参数和输出结果作为原始数据必须先进行处理,再采用保留法被划分为训练集和测试集.本研究中训练集和测试集规模的比例为3∶1.
模型训练和测试,即建立模型并对模型的参数进行调优.kNN 算法的目标函数是欧式距离.DT算法的目标函数是平方误差,AdaBoost算法采用的损失函数是指数损失.本研究采用遍历的方法优化kNN算法的参数k,采用网格搜索对DT算法和模型的参数进行整体调优.
模型预测和评估,通过分别计算模型的均方误差和平均绝对误差,评估模型预测的准确性.为展示模型的真实预测情况,对比误差最小的模型的预测值与目标值,并分别计算两者的最大偏差.
2 数据集构建
本研究基于某核电厂燃料棒的典型输入算例,通过修改芯块类型、包壳类型和堆芯入口温度等参数构建算例.冷却剂入口温度依次设计为286、288、290、292和294 ℃.
JASMINE是中广核自主研发的用于压水堆燃料棒Ⅰ类和Ⅱ类性能分析计算的软件.本研究采用JASMINE 软件对20 个输入算例(2 种芯块× 2 种包壳×5 种冷却剂入口温度)进行计算,并在由输入参数和输出结果形成的原始数据中进行数据的特征工程,分别构成模型的训练数据集和测试数据集.按照此方法,本研究共构建了12 040 个样本数据,其中训练数据9 030个,测试数据3 010个.数据集芯块类型、包壳类型、局部功率、轴向段高度、堆芯入口温度和腐蚀层厚度6个特征参数,以及包壳外表面温度和芯块中心温度2 个目标参数.其中,芯块类型包括UO2和Gd2O3-UO2;包壳类型为Zr-4和M5;局部功率取值范围为0~40 kW/m;轴向段高度取值范围为0~3 600 mm;堆芯入口温度取值范围为286~294 ℃;腐蚀层厚度为0~90 μm.
3 模型训练和测试
分别建立kNN、DT和AdaBoost 3种算法的模型并进行参数调优.回归模型一般采用R2方法来衡量模型的拟合度(即准确性),因此,本研究采用R2来确定模型的最佳参数.R2计算公式为

其中,u为残差平方和,;v为总平方和,;N为样本数量;i为数据样本编号;fi为模型预测值;yi为样本点i实际的数据标签(即包壳外表面温度或者芯块中心温度);为实际数据标签的平均值.
3.1 kNN算法
分别计算当k取不同值时采用kNN 算法构建的预测模型对包壳外表面温度和芯块中心温度预测的准确性(R2),结果如图2.由图2 可见,当k=2时,模型对包壳外表面温度和芯块中心温度的预测准确性最佳.

图2 kNN算法参数k对(a)包壳外表面温度和(b)芯块中心温度预测的准确性趋势Fig.2 Trend charts of parameter k to forecast accuracy R2 for(a)cladding outside surface temperature and(b)pellet center temperature.
3.2 DT算法
图3展示了DT算法的预测准确性(R2)分别随决策树最大深度(max_depth)、叶子节点需要的最小样本数(min_samples_leaf)和执行分裂所需最小不纯度减少量(min_impurity_decrease)变化的趋势.由图3 可知,随着max_depth 增加,预测准确性逐渐增加,并且当max_depth 增大到一定数值后预测准确性不再增加.随着min_samples_leaf 和min_impurity_descrease 增大,预测准确性逐渐降低.为优化这3 个参数,本研究采用网格搜索(GridSearch)的方法进行整体调优.DT 算法的模型最佳参数如表1.

图3 DT算法性能预测准确性R2随参数(a)max_depth、(b)min_sample_leaf和(c)min_impurity_decrease变化趋势Fig.3 Trend charts of performance prediction accuracy R2 of DT algorithm with parameter(a)max_depth,(b)min_sample_leaf,and(c)min_impurity_decrease.The triangle is the cladding outside surface temperature,and the circle is the pellet center temperature.

表1 DT算法预测性能的最佳参数Table 1 Optimal parameters for predicting performance of DT algorithm
3.3 AdaBoost算法
对于AdaBoost算法,本研究只针对最大弱学习器个数(n_estimator)和学习率(learning_rate)进行调参,其他参数采用默认值.AdaBoost算法的预测准确性(R2)分别随n_estimator 和learning_rate 变化的趋势如图4.由图4 可见,随着n_estimator 增加,R2将有少量提高,并且当n_estimator增至50以后,预测准确性增加非常少;随着learning_rate增加,R2值变化非常小.但是,n_estimator和learning_rate的取值还会影响模型训练时间,因此需要权衡考虑.本研究采用网格搜索(GridSearch)得到模型的最佳参数,即包壳外表面温度的目标参数learning_rate=1,n_estimators=300;芯块中心温度的目标参数learning_rate=1,n_estimators=300.
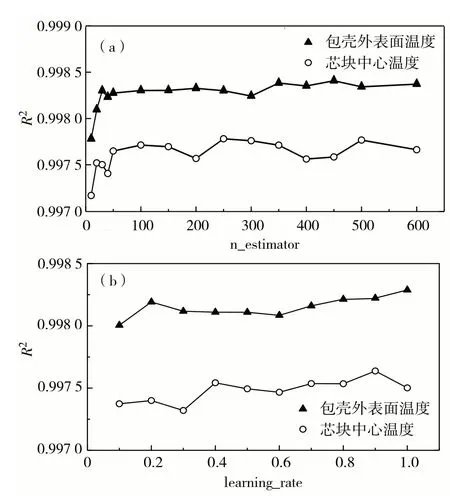
图4 AdaBoost算法性能预测准确性R2随参数(a)n_estimator和(b)learning_rate变化趋势Fig.4 Trend charts of performance prediction accuracy R2 of AdaBoost algorithm with parameter(a)n_estimator and(b)learning_rate.The triangle is the cladding outside surface temperature and the circle is the pellet center temperature.
4 模型预测和评估
4.1 预测误差
为有效评估模型的预测能力,分别计算kNN、DT 和Adaboost 算法预测结果的均方误差(mean square error,MSE)和平均绝对误差(mean absolute error,MAE),计算公式分别为
3 种算法预测包壳外表面遇变和芯块中心温度的结果的误差如表2.由表2 可知,AdaBoost 算法的预测误差最小.
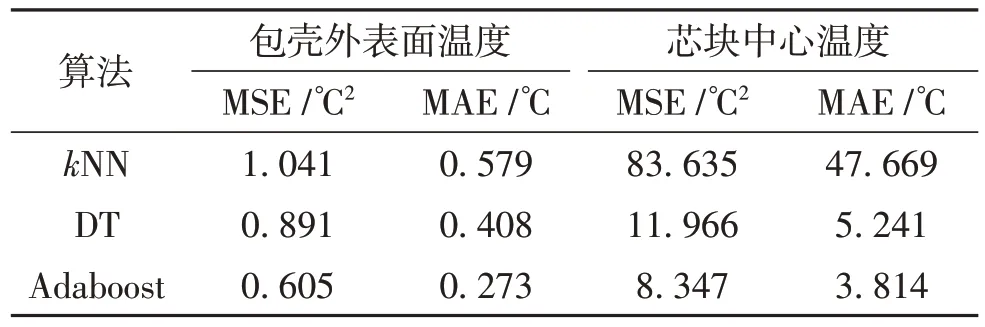
表2 三种算法的模型预测误差对比Table 2 Comparison of model prediction errors of the three algorithms
4.2 结果评价
为直观地展示模型对包壳外表面温度和芯块中心温度的预测情况,图5给出了AdaBoost 算法的预测值和目标值,以及采用AdaBoost进行预测的偏差(预测值-目标值).由于样本量大,图中仅展示芯块为UO2,包壳材料为Zr-4合金,轴向段为第13段的一种入口温度的样本数据.
由图5(a)可见,AdaBoost算法对包壳外表面温度预测的最大偏差为3 ℃,且大部分偏差为0,说明AdaBoost 算法对包壳外表面温度预测偏差非常小.由图5(b)可见,芯块中心温度的预测偏差大部分<10 ℃,表明AdaBoost 对芯块中心温度的预测效果良好.综上分析,AdaBoost算法对包壳外表面温度和芯块中心温度具有较高的预测精度.
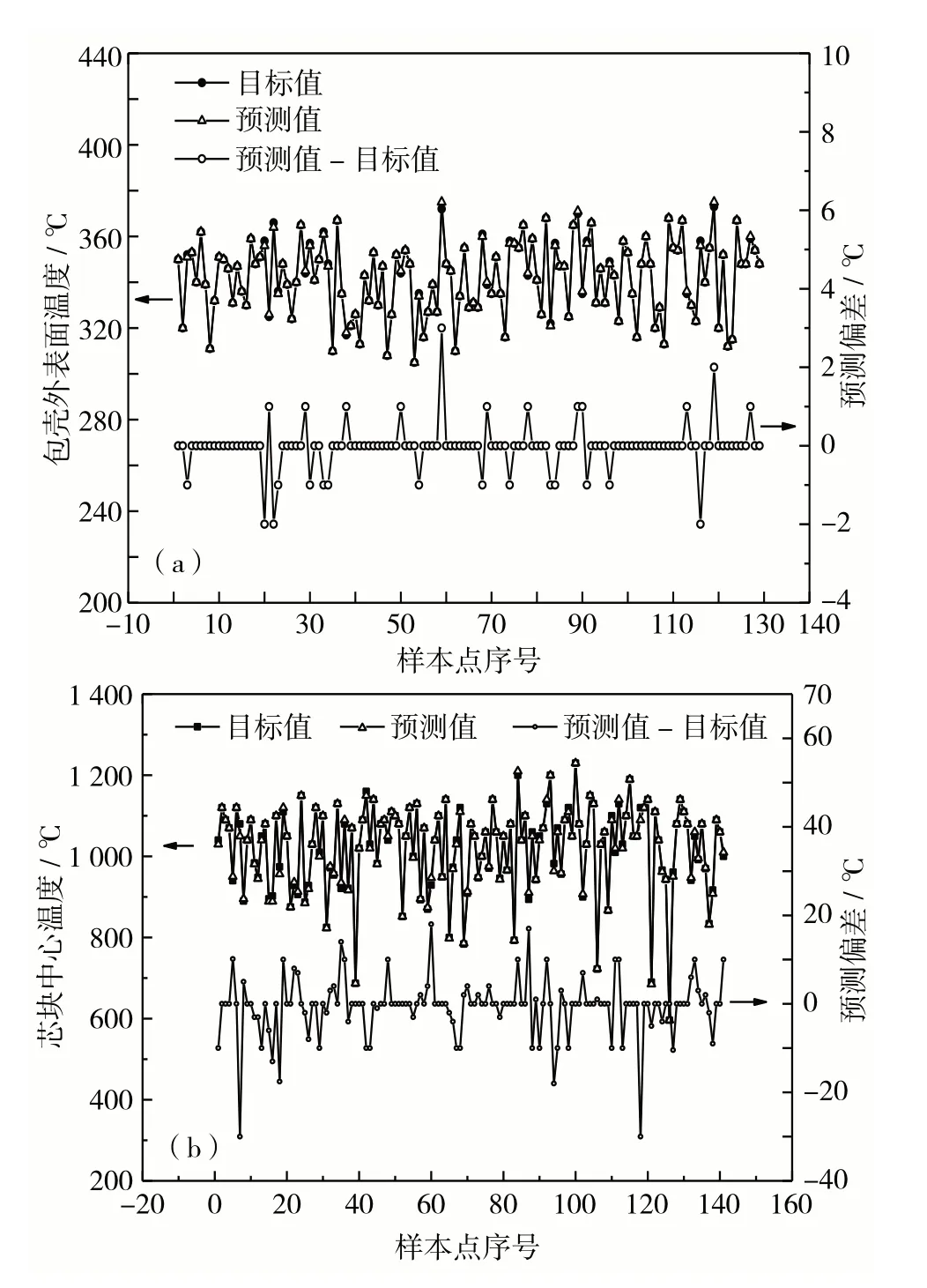
图5 AdaBoost算法对(a)包壳外表面温度和(b)芯块中心温度性能预测Fig.5 Prediction of(a)cladding outer surface temperature and(b)pellet center temperature performance by AdaBoost algorithm.The square is target value,the triangle is predictive value,and the circle is the differente between predictive value and the target value.
结语
1)分别采用kNN、DT 和AdaBoost 3 种机器学习算法实现对包壳外表面温度和芯块中心温度的预测.实验结果表明,AdaBoost 算法的预测精度最高.
2)参数优化后的AdaBoost 算法对包壳外表面温度和芯块中心温度的均方误差分别为0.605 ℃和8.347 ℃,平均绝对误差分别为0.273 ℃和3.814 ℃,预测效果良好.
3)基于Adaboost 算法建立的芯块和包壳温度计算模型与燃料棒性能分析软件的计算结果进行了对比验证,但是模型在应用之前还需要根据试验数据进行确认.
该模型只能对温度性能参数进行预测,而燃料棒性能分析软件包含对热学、力学、腐蚀吸氢、材料物性及辐照性能等进行计算分析,其中热力学是相互耦合,建模相对复杂.若将所提模型嵌入到JASMINE 软件,替换其中的燃料棒温度计算部分,则可以简化燃料棒性能分析软件的模型框架.
