基于深度自编码的医疗命名实体识别模型
2022-09-25侯旭东滕飞张艺
侯旭东,滕飞,张艺
(西南交通大学计算机与人工智能学院,成都 611756)
0 引言
医疗信息化的蓬勃发展带来了大量以患者为中心的医疗数据,电子病历系统作为医疗信息化建设中的重要一环得到了广泛普及。病历主要包含医疗机构对门诊患者和住院患者的诊疗记录和工作记录,现行卫生行业标准WS445—2014[1]对电子病历数据及其元数据属性进行了规范,利用电子病历系统给病历带来了记录、存储、查阅上的便利。虽然记录过程实现了信息化,但目前电子病历仍由半结构化格式的记录元信息与非结构化的医疗文本段落组成,以自然语言的形式被记录于病历信息系统中。随着电子病历管理[2]和应用[3]的逐步完善,我国开始着力推进医疗信息现代化与智能化建设。
面对自由文本形式存在的海量病历数据,亟须利用信息抽取技术将病历文本数据转化为结构化病历数据以再供利用,然而结构化病历的构建需要具有医疗语义的短语作为支撑。统一医学语言系统(Unified Medical Language System,UMLS)[4]对生物医疗领域的语义词汇开展了整合工作,促进了医疗语义短语的抽取工作的发展。通常电子病历中拥有特定医疗语义的短语被称为医疗实体,根据医疗概念划分出了病种诊断、药物治疗、手术治疗和实验室检验等语义类别,故一篇病历的关键信息在一定程度上可由其包含的实体集合来表示。
医疗命名实体识别(Medical Named Entity Recognition,MNER)是利用实体识别技术对在医疗命名体上开展识别工作。在英文领域,自2004年起,I2B2(the Center for Informatics for Integrating Biology and the Beside)开始建立面向医疗领域的自然处理任务研究,在I2B2-2009[5]、I2B2-2010[6]、I2B2-2012[7]和I2B2-2014[8]的评测任务中基 于不同角度开展了各类MNER 的评测。英文领域MNER 研究开展较早,实现和方法上也逐步成熟,中文领域MNER 尚处于发展阶段,杨锦锋等[9]尝试结合中文病历的语言特点,为建立中文医疗命名实体数据集和标注规范提供了重要参考。中国知识图谱与语义计算大会(China Conference on Knowledge Graph and Semantic Computing,CCKS)自2017 年起开始发布中文临床医疗命名实体识别任务,为研究中文医疗命名实体识别提供了宝贵的实验数据。
面向电子病历的MNER 研究对于实现病历结构化,助力医疗智能化十分关键。深度语言模型的进步为实体识别任务带来了新的提升,但先进语言模型的参数规模达到上亿,致使识别精度与算力要求间出现了不平衡、不充分的问题。知识蒸馏做到了压缩语言模型规模与精度损失上的平衡,但其自身网络和针对下游任务的解码器均需要精巧设计。因此,研究基于轻量语言模型的高识别精度医疗命名实体识别模型充满了挑战;特别是在当前中文领域的医疗命名实体识别上公开的数据和评测较少的背景之下,对于医疗信息现代化和智能化的快速发展将会产生重大意义。
本文的主要工作如下:
1)提出了级联思想将实体识别过程拆分的方法。该方法可以改善对序列式识别在标签错误转移错误和标注标签增长控制上的不足,控制标签随实体类别和标注方式带来的标签增长为很小常数。
2)构建了级联多任务解码器。级联多任务解码器能够显著弥补蒸馏与非蒸馏语言模型带来的差异,级联多任务解码器仅结合轻量语言模型RBT6[10],实现了高精度识别模型。
3)设计了CasSAttMNER(Cascade Self-Attention Medical Named Entity Recognition)模型与各基线模型的对比实验。CasSAttMNER 模型可以在实体类别判断的上下文中加入实体提及词汇整体的信息,能表示级联式识别中提及词汇和其类别之间的隐信息,实验结果表明该模型提高了医疗命名实体识别的精度。
1 相关工作
MNER 的早期工作依靠医学领域的词典与规则[11]。随着对医学概念上的编码工作推进,国际疾病分类(International Classification of Diseases,ICD)[12]、SNOMED(Systematized Nomenclature of Human and Veterinary Medicine Reference Terminology)[13]等医学编码工作形成了海量医学词典,发展出了MedLEE[14]、MedKAT(Medical Knowledge Analysis Tool)[15]、cTAKEs(clinical Text Analysis and Knowledge Extraction system)[16]等专家系统。以专家系统形成了符号主义的医疗智能,但面对医学领域的发展,病种、治疗、药物等方面的新发现与新治疗,专家系统往往不能快速地将其包含,且其相对应的识别规则制定也十分复杂,故人们的研究目光开始转向使用统计机器学习的方式进行。
Li 等[17]尝试了使用条件随机场(Conditional Random Fields,CRF)与支持向量机(Support Vector Machine,SVM)的医疗命名实体识别工作,实验结果表明,CRF 及其采用序列标注式的识别效果好于SVM 及其短语分类方式的识别,为MNER 采用序列标注式识别作为主流方式奠定了基础;Clark 等[18]使用规则与基于CRF 和最大熵的联合机器学习方式,在I2B2-2010 的MNER 任务上取得了0.934 3 的评测值;Cohen 等[19]提出了使用无标数据中获取的词语义分布来优化CRF 中的条件概率转移限制,这种方式为使用语料建模词分布表示来实现实体识别奠定了基础。
使用机器学习算法为解决MNER 问题带来了显著进步,但统计机器学习方式的识别模型需要依赖特征工程,特征计算的来源为特定语料库或者任务本身的数据,这也限制了机器学习对新实体的发现能力,若预测的文本中包含着模型从未见过的词语组成的命名实体,便无法识别,此问题在中文领域更为凸显。故对特征工程依赖和未登录词限制,使得使用机器学习方式解决MNER 问题存在着明显的上限。
而采用深度学习的预训练语言模型能够突破机器学习方法的限制,因此,很多工作开始转向使用神经网络与机器学习的方式来进一步提升MNER 的效果:Wu 等[20]使用词嵌入和深度 神经网络来解决MNER;Huang 等[21]提出了BiLSTM-CRF(Bi-directional Long Short-Term Memory-Conditional Random Field)神经网络来优化标注预测;Xu等[22]基于此架构将其应用于MNER 任务中;Ji 等[23]尝试用多个神经网络混合的方式来增强MNER 效果。在通用领域,Baevski 等[24]在神经实体识别上引入完形填空模式驱动的网络结构;Liu 等[25]从上下文增强的角度来尝试提升神经实体识别模型的识别精度;Li 等[26]使用对抗神经网络来设计神经实体识别网络。
在面对层出不穷神经网络所设计出的MNER 模型时,除了考虑特定领域语言特点所适用的网络结构外,仍需考虑除识别精度外的算力要求和推理时间等成本因素。目前,使用动态语言模型来解决MNER 任务也成为获取高精度识别的一种主流方式,但语言模型的参数量以亿级别为单位,这使得基于语言模型来解决MNER 时,需要考虑算力的经济性。深度语言模型为实现高精度的实体识别带来了潜在机会。各项任务上评测精度越来越接近原始语言模型效果的语言模型轻量化工作也为实现算力与识别精度上的平衡带来可能。基于这样的背景,本文将利用轻量语言模型开展一系列研究,构建适用于医疗命名实体识别领域的模型,并尝试平衡识别精度外的算力要求与推理时间、空间使用等成本因素,以达到实用性和精准度间的平衡。
2 模型构建
本章将使用级联视角来审视实体识别任务,并有依据地对问题进行公式化表述,在此基础上提出了级联式多任务实体识别算法,构建了基于自注意力机制的级联医疗命名实体识别模型CasSAttMNER。
2.1 级联式识别
2.1.1 实体识别任务的级联目标
如何控制标注标签的增长,对解决复杂的实体识别任务十分关键。在此,借用数据库中级联操作的思想来引入一个全新的视角去审视实体识别任务。形式定义如下:假定规模为J的实体识别训练数据集为D,用xj来表示D中的第j条文本,用ej表示文本xj中出现的实体集合。
设文本xj中共包含N个实体,1 个实体ent由包含了位置信息的实体提及t和类别信息实体类别c两部分,此时存在实体表示为:

则给定来自训练集合D的文本xj,其对应包含N个实体的实体集ej可表示为:
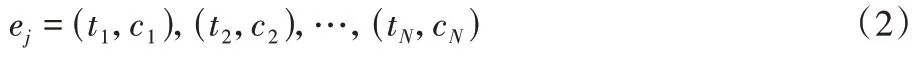
则对于实体识别训练数据集D中的一条数据,数据d由xj和ej组成。此时d和D可表示为:

级联式识别需要描述实体提及和其潜在的语义类别之间存在相关性的函数。式(5)对这个过程进行了描述。
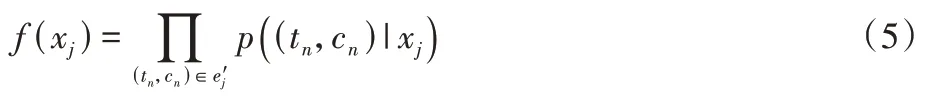
对于数据集D,需要最大化D中的所有潜在实体出现概率,式(6)描述了这种概率:

根据概率链式法则,式(6)可转变为式(7):

根据上述描述,级联式识别的求解过程可做这样的描述。实体ent′由(tn,cn)表示,tn为实体ent′的实体提及表示,cn为ent′的实体类别表示。(tn,cn) ∈表示第j条数据中的第n个实体。cn∈|tn刻画了在e'j中已知实体提及为tn下,实体类别为cn的对应关系,这种对应关系在真实的ej中存在1 个或0 个,预测中存在0 个、1 个或多个,目标是在求解中最大限度地接近1 个或者0 个,具体则取决于真实的ej。
式(7)揭示了级联式识别的任务目标,便是最大化式(7)在训练集D上的联合概率,即目标为最大化地计算文本xj包含实体提及tn的概率与此实体提及tn对应的实体类别为cn的概率,使之解得的最大限度地接近ej。
2.1.2 级联式识别架构
级联式医疗命名实体识别(Cascade Medical Named Entity Recognition,CasMNER)模型标注过程为图1 所示。

图1 级联式医疗命名实体识别模型的标注过程Fig.1 Labeling process of cascade medical named entity recognition model
级联式识别借用关系型数据库中的级联(Cascade)思想,将文本序列作为一对多关系中的一文本序列同时映射到实体提及识别和实体类别识别两过程中,此时句子中的每一个字词都将对应两个输出预测。
设实体提及的标签数量为N,实体类别的标签数量为M,级联式识别需要的标注标签集合S的数量L为:

级联式识别每增加一个实体提及标签,模型预测输出时便仅需要一个提及标签;每增加一个类别标签,模型预测输出便仅需要一个类别标签。相比序列式识别,这种方式有效控制了标注标签的增长到常数级。
2.2 基于自注意力机制的CasMNER
2.2.1 基于自注意力机制的解码器优化
采用级联方式的实体识别中,实体提及得到的词汇及其上下文信息,对于待提取的实体词汇的类别判断自然地存在一种上下文关系。本节对于如何在实体类别判断的上下文中加入实体提及词汇整体的信息,提出了使用自注意力机制来表示级联式识别中提及词汇和其类别之间的隐信息CasSAttMNER 对实体类别解码器进行了重新设计。
实体提及抽取中由式(9)获得隐解码信息:
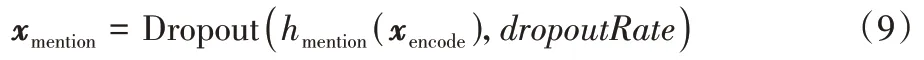
其中:h代表BiLSTM 网络结构;xencode为解码过程的输入,由文本序列集合经分句、嵌入,再使用经过蒸馏的Transformer语言模型RBT6[10]得到。解码过程中,首先使用BiLSTM 对xencode进行解码,得到序列信息编码后的第一层解码情况,同时结合Dropout[27]方法对解码结果进行选择性使用,得到初步解码。Dropout 函数可根据超参数dropoutRate来归零BiLSTM 输出向量上的随机维度来控制解码信息的稠密。
在实体类别判断中由式(10)获得隐解码信息:
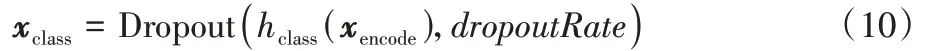
式中:h代表BiLSTM,这里的BiLSTM 不与实体提及抽取过程共享使用。
为完成实体提及序列标注,需完成式(11)、(12)所示的步骤计算:

其中:式(11)中的函数g是线性变化函数,目的为控制hiddent的输出尺寸和下一步相同;式(12)中φ代表条件随机场(CRF)[28]。CRF 条件模型通过一个观察序列X*选择条件概率p(Y*|X*)最大的标签序列Y*,这类判断式方法使得推理过程中观察序列的依赖可以被正确地表示,而且不会生成无关推断。CRF 的求解目标即给定观察序列x的标签序列为y的条件概率p(y|x)为:
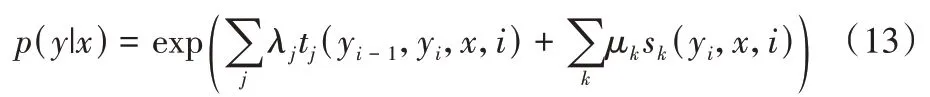
其中:tj(yi-1,yi,x,i)是整个观察序列在位置i-1 到i的标签从yi-1转移到yi的转移特征函数,sk(yi,x,i)为观察序列位置i的标签为yi的状态特征函数,λj与μk为训练过程的参数估计。
函数tj(yi-1,yi,x,i)与sk(yi,x,i)均为二分判断函数,且所有的特征均来自观察序列中是否为真值,则函数可被表示为:

式(14)中的wi表示某给定的位置;式(15)中的Tagq和Tagw为给定的标签。
式(7)中的p(cn|tn,xj)表明了实体提及对实体类别存在联合条件概率上的影响。在此,本节设计使用自注意力机制[29]来构建两者间的关系信息,即:

式(17)用来计算自点积注意力。自注意力机制的输出并不改变上一层网络输出的空间尺寸,因此xclass与hsatt的空间尺寸相同。式(18)使用xclass和hsatt的连接来对实体类别中增加xmention的信息,Concat 操作是在二者最后一个维度上进行连接。式(19)使用Softmax 网络对hconcat进行非线性转换,得到实体提及在各预设类别上的概率分布,取分布中数值最大者作为实体类别结果。此时的类别标签的计算由式(17)~(19)描述。
2.2.2 CasSAttMNER的网络架构
对于输入文本序列xj,首先将经过字级别的Character-Embedding 进行嵌入表示;随后在语言模型中得到序列的深度表示,此深度表示将共享输出到实体提及解码器Entity Mention Decoder 和实体类别解码器Entity Class Decoder 中。在实体提及部分将经过两次的解码操作得到所需的实体提及标签序列。在实体类别部分,利用实体提及的第一步解码输出的自注意力矩阵,与实体类别中的第一步解码得到的矩阵进行连接,通过Softmax 网络来输出类别。两个输出序列的组合将成为xj的输出结果序列yj,两序列的长度以及内容一一对应。CasSAttMNER 的网络结构如图2 所示。
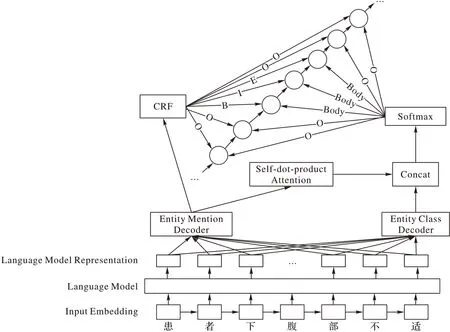
图2 CasSAttMNER的神经网络结构与推理示例Fig.2 CasSAttMNER’s neural network structure and reasoning example
3 实验及结果分析
将CasSAttMNER模型与各基线模型在CCKS-19[30]和CCKS-20[31]数据集上进行对比实验,评估输入与输出操作的效果,并进行实验结果分析。
3.1 环境配置与评估指标
本文的实验环境为Windows10 操作系统,CPU 为Intel Gold 6138,GPU 为Nvidia Quadro RTX 6000,CUDA版本为9.0。
描述实体识别任务的识别精准度评估采用精准率(Precision,P)、召回率(Recall,R)、F值度量(F1 score measure,F)三个指标进行判断。数据在被预测时会出现真正(True Positive,TP)、真负(True Negative,TN)、假正(False Positive,FP)和假负(False Negative,FN)的4 种情况。针对模型会出现偏差的情况,使用P 来统计TP 在预测数据中的占比,使用R来统计TP在真实数据中的占比,F 反映了P 和R间的平衡。
精确匹配用来度量模型的预测序列结果转换出的实体集合和人工标注的实体集合的匹配程度,是在实体集级别的匹配,在精确模式下的F 值度量为FE。在精确模式下的精准率PE、召回率RE和F 值度量FE的计算定义如下:
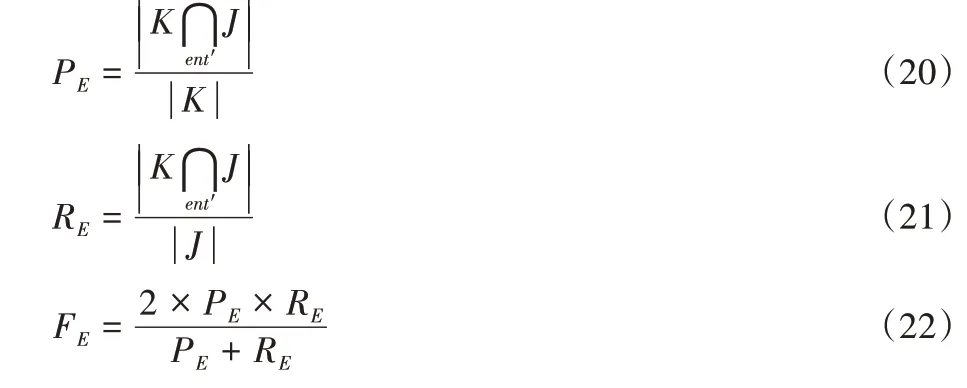
其中:J=ent1,ent2,…,entT为真实实体集;ent'为模型预测出的实体短语,包含模型预测的实体在文本中的位置和类别信息;K=,,…,为预测出的实体序列。
3.2 数据集
本次实验使用CCKS 在2019 年与2020 年的中文医疗命名实体识别评测任务的两个中文医疗实体数据集,文中分别简称为CCKS-19[30]和CCKS-20[31]。
CCKS-19 提供了1 000 例病历语料作为数据集,CCKS-20提供了1 050 例病历语料作为数据集,均含有6 种医疗实体类型。表1 提供了CCKS-19 和CCKS-20 两数据集的相关统计信息。
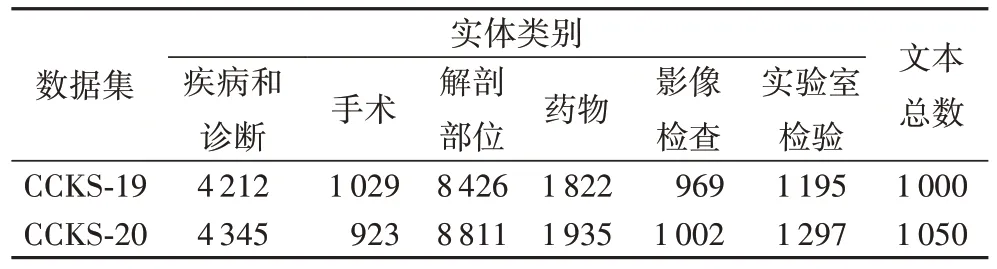
表1 数据集中的实体类别与数量统计Tab.1 Entity class and quantity statistics in datasets
3.3 数据集划分
针对模型的训练与验证,实验将数据集的训练与验证部分划分比例统一为90%与10%,且在对所有模型训练和验证中不调整数据内容。
3.4 模型超参数设置
CasSAttMNER 模型所使用的语言模型为RBT6[10],训练方式为自动检查点机制,若当前epoch 的结果好于当前最优记录,将自动地将此轮epoch 学习到的参数进行转储,并更新最优记录。本次训练中模型的最优epoch 基本在30~80 的区间内。本次实验统一训练的优化函数为adam[32]。使用度量函数衡量模型整体的输出准确率和损失函数评估预测与实际的偏差程度。由于确定实体类别的过程被视为多分类任务,故引入了分类精准度categorical_acc 和分类损失估计categorical_loss:分类精准度categorical_acc 用于计算预测中预测为真占所有预测情况的比值;分类损失categorical_loss为分类交叉熵,计算了在一个批量中各个实体类别的平均交叉损失熵。
为控制变量的复杂程度,本次训练过程设置了统一的学习率1E -5 与批尺寸8。除此之外,两个BiLSTM 网络层的输出尺寸均为64;Dropout Rate 均为0.35;CRF 网络层的输出尺寸为5;Softmax 网络层的输出尺寸为7。
3.5 结果与分析
级联思想将实体边界和实体类别标注过程分解,尝试探索轻量语言模型的多任务开发能力。
为验证级联式识别存在识别精度优势,CasSAttMNER 将在3.2 节中介绍的两个数据集上进行评估,使用CCKS 在2019 年与2020 年的中文医疗命名实体识别评测任务中的优秀模型作为对比基线。表2 统计了各模型的F 值度量表现,CasSAttMNER 将MNER 的识别精度FE指标提升了3~8 个百分点。
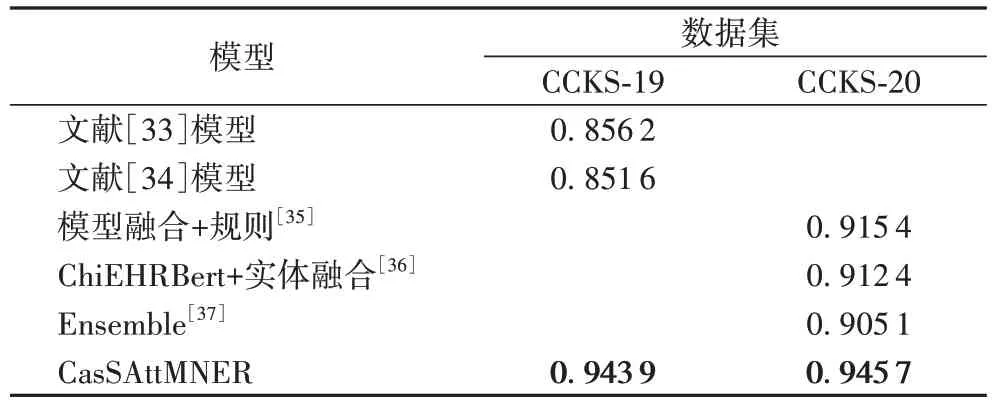
表2 各模型的FE评测统计Tab.2 FE evaluation statistics of each model
表3 统计了各模型在精确匹配下各类别实体的F 值度量表现。级联式识别进一步提升了MNER 任务的识别精准度,采用自注意力机制优化的CasSAttMNER 模型,有效地表示了实体提及与实体类别之间的隐关系。基于非蒸馏的语言模型BERT 设计的医疗命名实体识别模型[35-36]与基于蒸馏的Transformer 语言模型RBT6[10]设计的CasSAttMNER 模型进行对比实验,在识别精度上提升了约3 个百分点,证明了多任务解码器能够打破蒸馏与非蒸馏的语言模型间的差异,提升蒸馏语言的模型表现。级联多任务方式的解码器结合轻量语言模型RBT6[10],便可实现高精度的识别任务,显著提升了算力经济性。

表3 各模型的实体F值度量表现统计Tab.3 Entity F value measure statistics of each model
4 结语
本文针对序列式识别在标签错误转移错误和标注标签增长控制上的不足,引入级联思想将实体识别过程拆分,提出了一种基于深度自编码的医疗命名实体识别模型。传统的序列式实体识别改变标注方式易带来标签预测空间和标签错误传播的增长过快问题,这限制了识别精度的提升。本文模型首先对级联式实体识别进行公式化表述,随后设计了对应的网络结构。该模型延续编码与解码间深度差平衡策略,使用轻量语言模型作为编码器减小编码深度以及降低对训练和应用上的算力要求,使用长短期记忆网络与条件随机场网络提出了级联式多任务双解码器,并添加自注意力机制进行优化得到模型CasSAttMNER。实验结果表明,CasSAttMNER 模型的解码器能力得到了进一步提升,在两个中文医疗实体数据的F 值度量可达到0.943 9 和0.945 7。相关实验证明了级联多任务解码器能显著弥补蒸馏与非蒸馏语言模型带来的差异,级联多任务解码器仅结合轻量语言模型,便达成实现高精度的识别模型,显著提升了模型算力经济性。
对于编码器与解码器的设计,本次使用的轻量语言模型RBT6[10]是面向通用领域,若使用面向医学知识的轻量语言模型作为编码器应能继续提升医学实体识别的精准度。本次解码器优化设计主要基于标准的LSTM 网络与Attention 机制结合的方式,未来可继续探究其变种网络或者其他类型网络对解码器的优化能力。
