基于开放运算语言加速的数字全息卷积重建算法实现
2022-09-22罗洪艳周珞一冯晓波
罗洪艳 周珞一 赵 震 郭 洪 冯晓波
①(重庆大学生物工程学院 重庆 400044)
②(生物流变科学与技术教育部重点实验室 重庆 400044)
1 引言
由于数字全息重建算法计算复杂度高,特别是数字全息图所包含的数据量随着光电传感器分辨率不断提高而急剧增加,采用传统的中央处理器(Central Processing Unit, CPU)串行计算整个全息重建极为耗时,已成为制约数字全息技术广泛应用的重要因素,尤其是在要求高时效性的应用场景[5,6]。
针对相关需求,研究者提出了多种加速策略。比如马静等人[7]利用共享存储并行编程对数字全息3维重构过程进行了提速,但由于多核CPU内存资源和功耗的限制,其加速效果相比于经典单核计算模式并不显著。Chen等人[8]利用现场可编程逻辑门阵列硬件架构实现了一种低功耗的自动对焦数字全息重建算法,但由于该硬件技术开发周期长,设计成本高,不利于推广。与此同时,拥有大量运算单元可支撑高效并行计算,兼具内存带宽大、价格相对低廉等优势的图形处理单元(Graphics Processing Unit, GPU)飞速发展,在加速数字全息重建方面受到广泛关注。例如刘海等人[9]针对粒子3维速度矢量场重建问题,提出基于统一计算设备架构(Compute Unified Device Architecture, CUDA)的并行加速运算;Shin等人[10]借助CUDA加速了使用频域零填充的菲涅尔重建法; Doğar等人[11]研究了CUDA架构下实现3种重建算法以达到实时性重建的目的。然而CUDA架构仅适用于英伟达(NVIDIA Corporation, NVIDIA)公司GPU,无法实现跨平台部署。相比于CUDA,由苹果(Apple)、NVIDIA、英特尔(Intel)和超威半导体(Advanced Micro Devices,AMD)等多家公司联合开发的技术架构-开放运算语言(Open Computing Language, OpenCL),属于一种通用性计算框架,能向不同厂商的GPU计算设备提供支持,可运行在包括多核CPU,GPU,FPGA和数字信号处理器等在内的多种异构计算架构上,具有良好的跨平台特性。
因此,本文提出一种基于OpenCL架构的跨平台异构加速策略,旨在实现基于GPU底层的卷积重建算法加速,以提高数字全息重建算法的执行效率和通用性。
2 OpenCL简介
OpenCL是一个在异构平台上编写并行程序的开放框架标准,通常抽象成平台、内存、执行和编程等4个模型。其中,平台模型主要由1个主机和与之相连的1个或多个计算设备组成。内存模型主要包括全局内存、常量内存、局部内存以及私有内存等4种类型,其对应的大小和访问权限各不相同,且访问速度依次递增,其使用方式是否得当直接决定程序性能的高低。执行模型主要由在主机上执行的主机端程序和在计算设备上执行的内核程序组成。主机端程序可对多个支持OpenCL的计算设备进行统一调度管理,并且配置并行程序的执行环境。内核程序主要负责算法的并行化设计过程。在创建内核程序时,主机端会预先创建一个N维索引空间,索引空间中的每个工作项对应执行内核的实例,多个工作项组成工作组。编程模型主要分为数据并行和任务并行两种类型。前者是将同一个任务并发到各个数据元素上,通过工作组实现分层化的数据并行。后者是由设计者直接定义和处理并行任务,并将多个并行任务映射到一个工作项来执行,从而在整体上起到加速的效果。
3 数字全息卷积重建算法的OpenCL设计与实现
3.1 卷积重建算法原理
本文选用在经典的全息重建算法中执行效率最低、最为复杂的卷积重建算法[12],以便更好地体现GPU技术的加速特性。根据瑞利-索末菲衍射积分公式,全息图经由重建光照射后的衍射光波在再现面上的复振幅分布可表示为


其中,k=2π/λ。
3.2 卷积重建算法的异构加速设计
卷积重建算法的异构加速设计包括搭建异构加速平台和算法并行化实现两大部分。为了更好地利用硬件资源,本文在设计异构加速策略时,从CPU和GPU的计算特性出发分配各自的任务。计算量小且逻辑性复杂的任务,比如OpenCL平台的初始化、数字全息图的预处理、归一化等过程,交给CPU端串行处理。而计算量大且逻辑相对简单的卷积重建任务,交给GPU端并行处理。
在业务员提出离职时,销售经理并没有反思自己的处事方式,反而对将要离职的业务员更加不友好。例如:克扣工资、提成等,这种敌对态度一定程度上激化了业务员的逆反心理。
据此设计的重建加速算法的实现流程如图1所示。由图可知,在GPU端并行计算的重建算法从内部分解为g(x,y)初始化、2维傅里叶正变换、2维傅里叶逆变换、点乘、零频点移到频谱中心、取模等多个步骤。这些步骤顺序执行,适合采用数据并行编程模型,通过合理分配工作组的方式实现异构加速计算。并且整个过程只包含两次数据传输,1次传入全息图和所需参数,另一次传出重建结果,计算的中间结果始终存储于GPU端,可有效避免因多次数据交换导致的计算性能瓶颈。整个并行处理过程的GPU内部实现如图2所示,分为FFT的并行化和算法其他部分的并行化两部分。
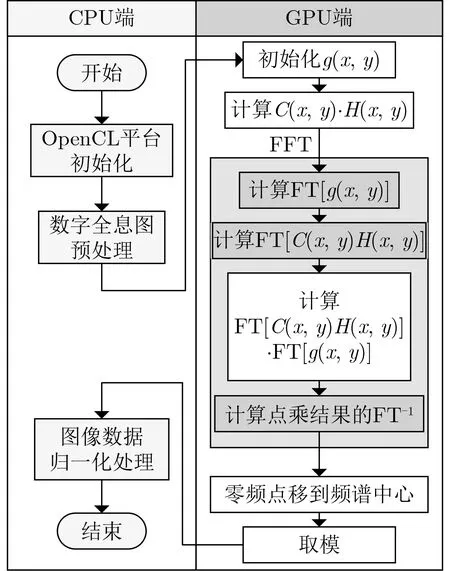
图1 基于CPU+GPU架构的卷积加速重建算法流程图
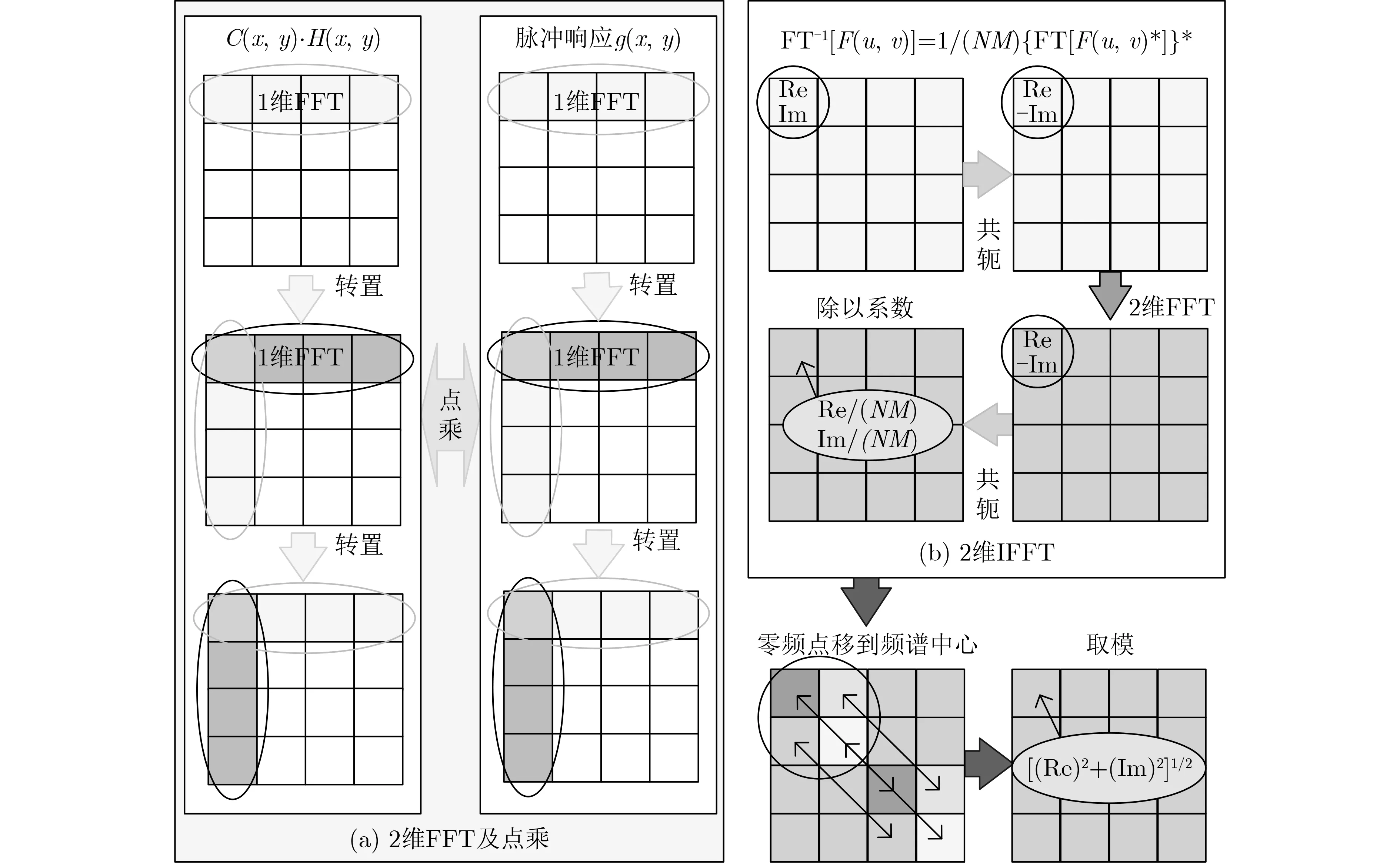
图2 卷积加速重建算法的GPU实现示意图
3.2.1 FFT的并行化
2维离散傅里叶正变换、逆变换的公式分别为
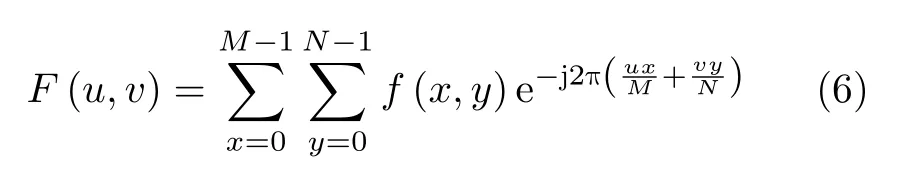

通过以上分析,只需开辟尺寸为M×N/2的工作组并行化计算g(x,y)矩阵的蝶形运算,每一个工作项分配一个蝶形运算。并且采用原址计算的方式,将每一级蝶形运算的输出存放于原输入数据的位置。根据旋转因子计算公式知,其与数据本身互不关联,所以分配1个工作组、N/2个工作项即可。考虑到局部内存是GPU中的高速存储器,保存在其中的数据可被这个工作组中的所有工作项共享,而且其读取数据速度快于全局内存,若多次从全局内存读取旋转因子数据会降低效率,进一步将旋转因子存储在蝶形运算工作组的局部内存中,以达到工作项共享旋转因子和提高计算速度的目的。这样通过合理设置索引空间维度和工作组大小,并且合理使用局部内存,不仅可以加快执行速度,还可以避免不必要的资源浪费。
3.2.2 算法其他部分的并行化
除了傅里叶变换环节,算法还涉及g(x,y)初始化、点乘、零频点移到频谱中心及取模等操作的并行化处理。由式(5)可知,g(x,y)的值只与重建再现距离、像元尺寸、光源波长及数据矩阵尺寸有关,可通过欧拉公式转换成复数矩阵,并将复数的实部和虚部当成一个向量进行计算,提高计算性能。OpenCL编程语言支持多种从C语言中派生的数据类型,但并非所有平台都支持全部数据类型。例如部分AMD显卡并不支持doublen数据类型,因此本文在涉及向量数据的运算时均采用floatn数据类型,以提高程序兼容性。
如图2所示,点乘是将两个相同大小的矩阵点对点相乘。零频点移到频谱中心是将图像中心点作为2维坐标轴的原点,对2维傅里叶逆变换的结果进行1,3象限和2,4象限的互换。取模是对任意一个M行N列的矩阵元素的实部平方加上其虚部平方再开方。以上都是对矩阵的每一个数据进行相同操作的过程,且各数据之间没有依赖关系,满足数据并行和工作项并行的要求,按照矩阵大小分配工作项大小即可。
4 实验与分析
4.1 实验环境
为了充分验证本文所提出的基于OpenCL架构的跨平台加速策略(即OpenCL版本)的有效性,采用具有NVIDIA公司GPU的加速平台1(CPU1+GPU1)和具有AMD公司GPU的加速平台2(CPU2+GPU2)对不同分辨率的数字全息图进行了并行重建测试及各自对应CPU下的串行重建测试。操作系统为Windows 10 64位,软件平台为Qt5。表1列出了两种加速平台的具体信息。

表1 两种GPU加速平台参数
此外,在加速平台1上还测试了卷积重建算法并行加速的CUDA版本程序,以对比分析两种不同架构的加速性能。
4.2 实验结果
实验测试图像为直径20 μm聚苯乙烯微粒的同轴数字全息图,分辨率为3264×2448,如图3所示。图4展示了全幅重建结果及局部区域对应的显微镜图像结果。

图3 20 μm聚苯乙烯微粒的同轴数字全息图

图4 全幅重建结果与局部区域的显微镜对比图
从图3中截取6个分辨率递增的局部区域全息图像,分别在两个加速平台及其对应CPU下各进行3次OpenCL版本的并行、串行重建测试,以及在加速平台1上进行3次CUDA版本的并行重建测试,所得总执行时间的平均值如表2所示。
根据本文提出的OpenCL版本CPU+GPU异构型并行化设计策略(见图1),加速平台的全息重建总执行时间实际由CPU端的串行运算用时、CPU端与GPU端之间的数据传输用时和GPU端的并行运算用时等3个分项构成。表3列出了针对不同分辨率全息图,在不同加速平台进行重建的各分项用时。
根据表2和表3,可进一步计算得到OpenCL版本下两个GPU加速平台相对于CPU平台的重建耗时总加速比(即CPU总执行时间与前者总执行时间之比)、并行运算加速比(即CPU执行卷积重建的串行运算用时与GPU执行卷积重建的并行运算用时之比)随全息图像分辨率的变化曲线,如图5所示。两个加速平台下各分项用时占总执行时间的百分比随全息图像分辨率的变化曲线如图6所示。
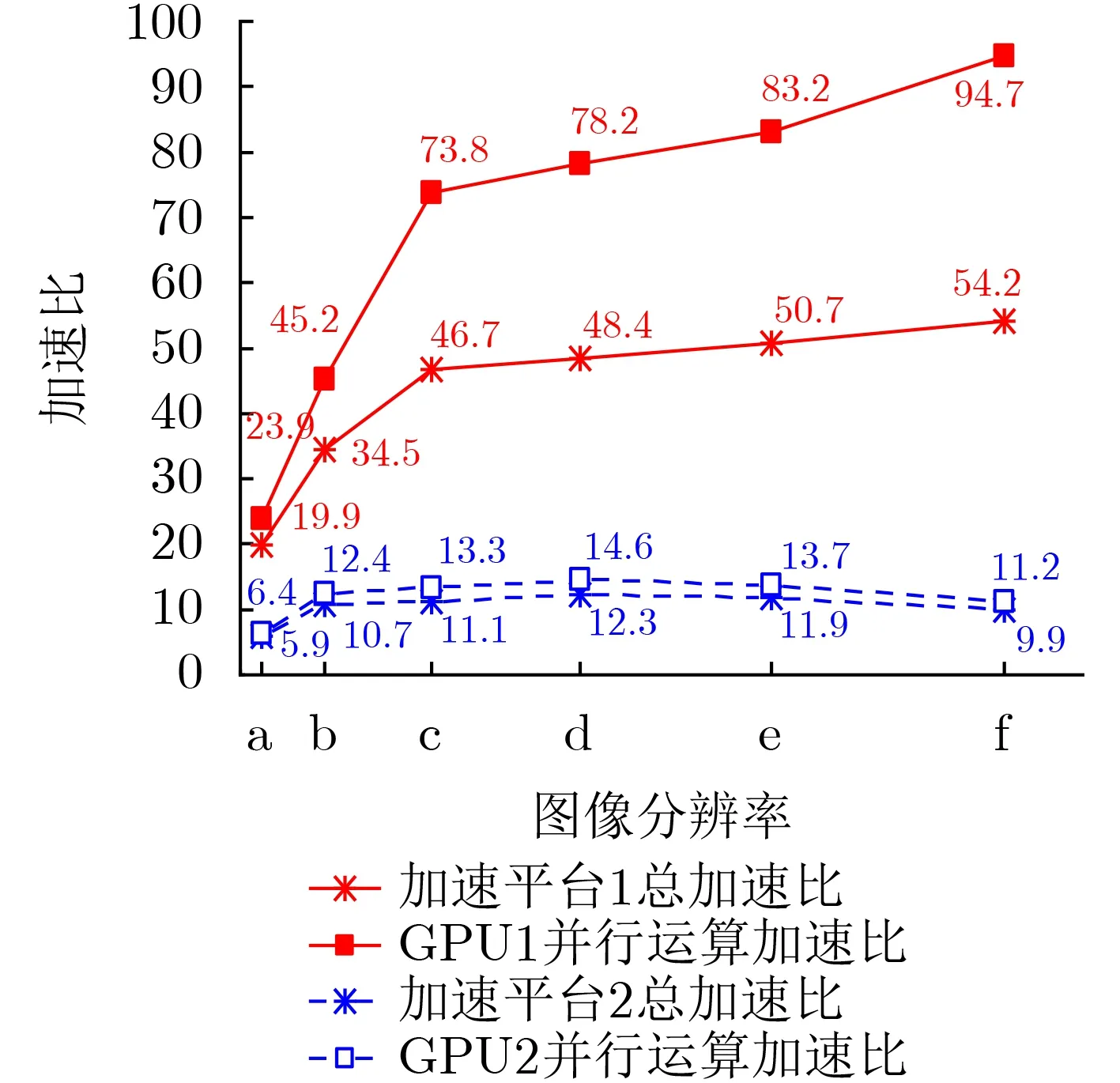
图5 不同加速平台的加速比(OpenCL版本)
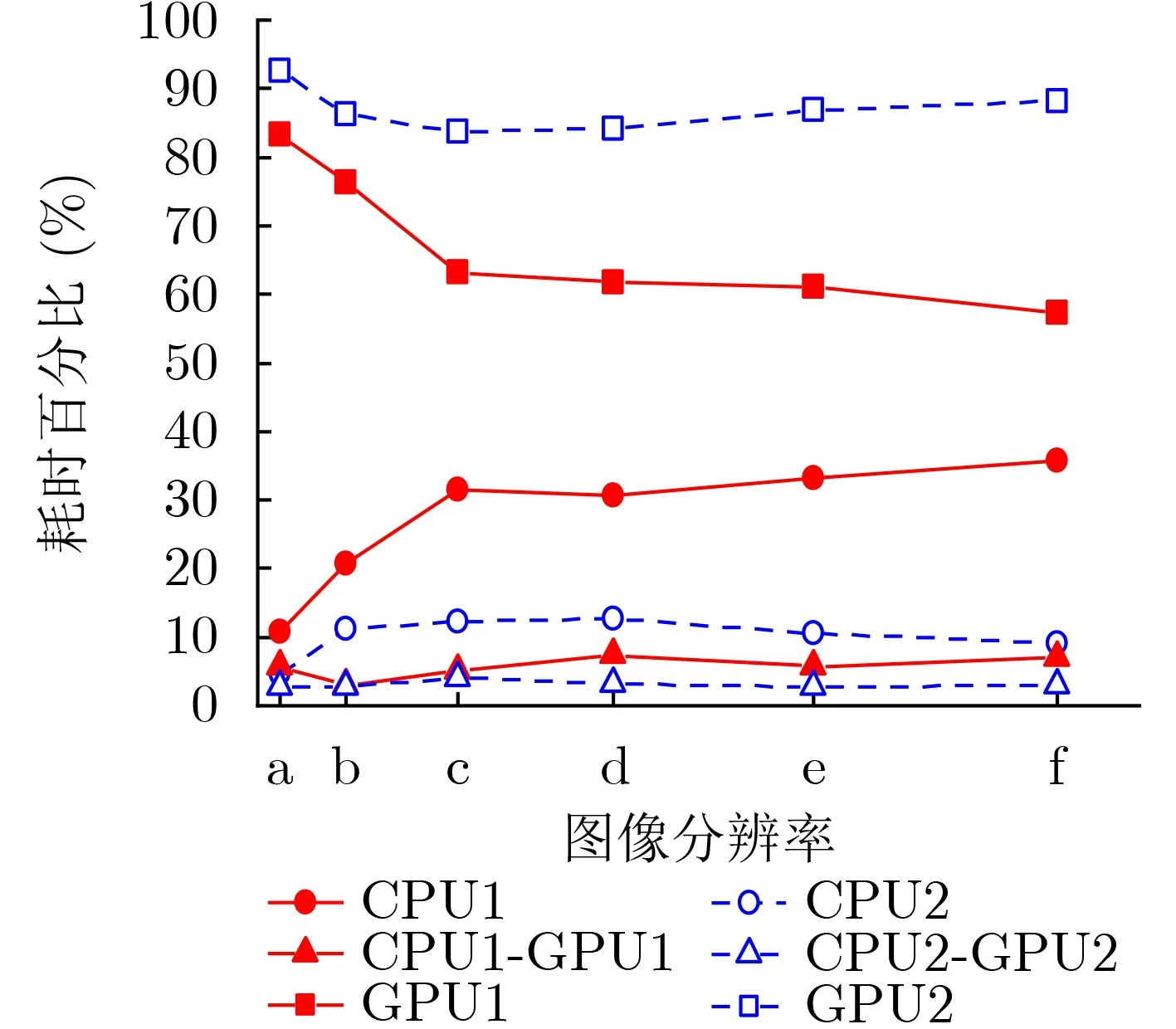
图6 不同加速平台的内部耗时百分比(OpenCL版本)
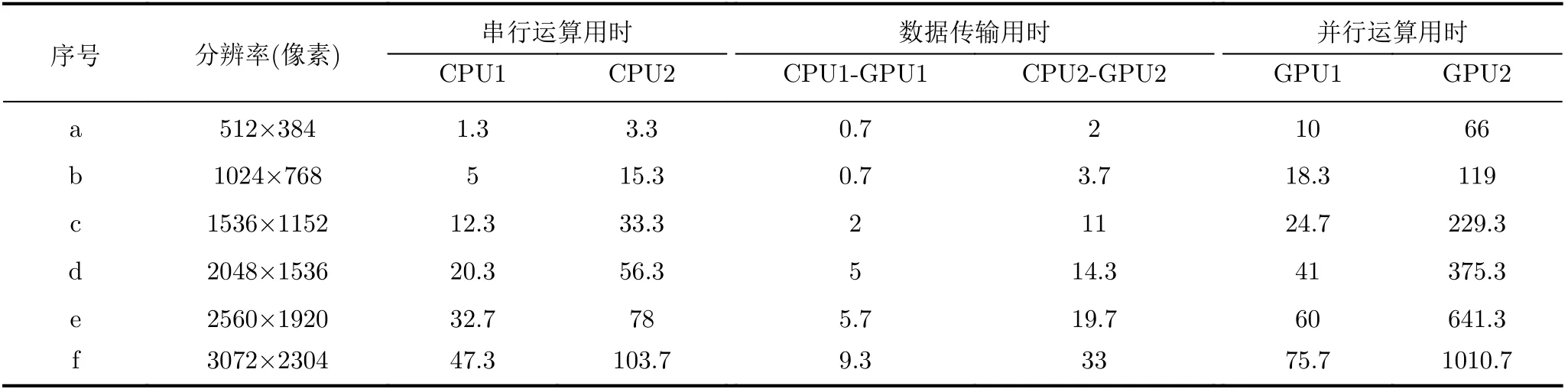
表3 不同GPU加速平台下全息重建的分项执行时间对比(OpenCL版本)(ms)
4.3 结果分析
(1) 由图4可见,重建还原的聚苯乙烯微粒形态呈现圆形,与真实微粒相近,且大小均匀,轮廓清晰,再现像质量与显微镜图像相当,表明本文设计实现的卷积重建加速算法正确有效。
(2) 对比表2所列OpenCL版本的执行时间,可观察到两个GPU加速平台针对不同分辨率全息图的重建运算总用时均明显低于CPU平台。以3072×2304最大分辨率全息图为例,前者约为后者的1.8%和10.1%。由此可见,基于OpenCL的异构加速策略能显著提高全息重建的时效性,且具有良好跨平台特性。

表2 不同CPU与GPU加速平台的全息重建总执行时间对比
(3) 观察图5可知,在OpenCL版本下,两个GPU加速平台的总加速比、并行运算加速比均先随着图像分辨率的提高而增大,且初期增长迅猛,随后增速减缓,特别是加速平台2在图像尺寸增至2048×1536时达到峰值,此后开始降低,整体变化趋势与文献报道相符[13,14]。这表明,一方面GPU加速具有规模增长性,即全息图像分辨率越高,得到的加速比越大,加速效果会越显著;另一方面,这种规模增长性又受到GPU所配置的并行运算资源的限制。随着全息图像分辨率的提高,数据规模越来越大,重建运算对GPU资源的需求量也增大,而所能利用的GPU资源将逐渐接近饱和状态,因此加速比从初始阶段的陡增变为中间阶段的缓增直至峰值。此后对于更大分辨率全息图像的重建,GPU资源将进入过饱和状态,超负荷运行,意味着并行任务之间也需要排队竞争资源,从而导致加速比开始下降。值得注意的是,在OpenCL的这种异构加速策略中,CPU端负责的平台初始化、全息图像预处理及归一化过程并没有经过加速处理,因此仅统计GPU端执行卷积重建核心计算过程的并行运算加速比高于总加速比,且能更真实地反映GPU的加速效果。对比两个GPU加速平台的硬件配置和加速比曲线,不难发现高配置的加速平台1具有更为优秀的加速表现,其重建不同分辨率全息图像的运行耗时均比低配置的加速平台2低一个数量级,在3072×2304最大分辨率下总加速比达到54.2是后者的5倍以上,并行运算加速比更是高达94.7,是后者的8倍以上,且尚未达到其规模增长上限。由此可见,GPU的计算资源配置对于并行加速策略所能达到的加速性能有至关重要的影响。
(4) 由表3可见,两个GPU加速平台下,Open-CL版本测试的数据传输用时最少,串行运算用时次之,并行运算用时最多,且各分项的运算用时均随着全息图像分辨率的增加而增大,尤以串行运算用时的增幅最为显著,达到30倍以上。同时,观察图6可以发现,在两种GPU加速平台下,数据传输用时占比均最低,分别低于8%,4%,且随图像分辨率变化微小,因此相比其他两项用时几乎可以忽略不计。对于高硬件配置的GPU加速平台1,其串行运算用时占比随全息图像分辨率上升趋势明显,从10.8%增长至35.8%,而并行运算用时占比则从83.3%降低至57.2%,减势显著。结合图5所示的加速比变化曲线,表明串行运算用时逐渐成为制约其总加速比进一步提高的主要因素,这也是总加速比远低于并行运算加速比且差距逐渐加大的原因。对于低硬件配置的GPU加速平台2,其串行运算用时占比呈现出先略增后持续降低的变化趋势,最大占比也仅为12.6%,而并行运算用时占比的变化趋势与之相反,即先略降再持续上升,数值始终在83.8%以上,表明并行运算用时始终对其加速效果起着决定性作用,而串行运算用时的影响几乎可以忽略不计,这也导致了其总加速比与并行运算加速比相近。由此可见,加速平台的硬件配置差异及全息图像的分辨率差异对数据传输用时的影响极为有限,而后者对加速性能几乎没有干预能力。加速平台所能达到的加速效果主要取决于GPU端的配置性能,但在GPU并行计算资源相对充足的情况下,CPU的配置性能会成为GPU加速规模效应的制约因素。因此,在实际应用中需要根据具体的加速需求合理配置GPU和CPU硬件资源。
(5) 对比表2中OpenCL版本与CUDA版本并行加速算法在GPU加速平台1上针对不同分辨率全息图像的重建总执行时间,可见后者比前者用时更少。且随着全息图像分辨率的增加,CUDA版本运行效率的提高更为显著,特别是在3072×2304最大分辨率全息图时,用时缩短了26.7%。这与文献报道的在大多数NVIDIA公司GPU上,CUDA的运算性能明显优于OpenCL[15-17],运行效率增幅高达30%相吻合[17]。造成这种差异的原因,一方面是OpenCL的内核可以在运行时进行编译,从而增加了运行时间[15]。另一方面专用于NVIDIA公司GPU的CUDA显然得到了厂商的优先支持,能更好地匹配其硬件的计算特性,从而提供更好的性能。而随着NVIDIA公司更新其OpenCL驱动程序,后者表现不佳的情况将会有所改善[16]。同时,也有不少文献报道[17-20]指出,上述的性能差异源自对CUDA和OpenCL的不公平比较。在许多情况下,通过减少两者存在的编程模型差异、本地内核不同优化、架构相关差异和编译器差异,将两个版本应用程序调到同等水平,OpenCL的性能可与CUDA媲美。此外,计算资源配置不同的GPU在性能上的差异其实更加显著[18],这一点在本文测试结果中也得到了印证。
5 结论
本文基于OpenCL架构提出了一种数字全息卷积重建算法的并行化加速策略,对卷积重建算法的异构型并行化设计进行了理论分析和工程实现,并在不同的GPU平台上完成了加速重建测试及与CUDA架构加速策略的对比测试。实验结果表明,与CPU串行方式相比,OpenCL架构的GPU并行方式加速成效显著,具有规模增长性,并且在不同的异构平台下都能实现很好的加速,全息图重建效果清晰,满足跨平台加速需求。通过系统的代码调优,有望达到与CUDA架构相近的运算性能。此外,GPU端的硬件配置性能对异构加速策略所能达到的加速效果起着决定性作用,但对于高分辨率全息图像的加速重建,CPU端的硬件配置性能也不容忽视。
