基于注意力机制的多尺度全场景监控目标检测方法
2022-09-22张德祥袁培成
张德祥 王 俊 袁培成
①(安徽大学电气工程与自动化学院 合肥 230601)
②(安徽三联学院电子电气工程学院 合肥 230601)
1 引言
随着城市的快速发展,城市人口数量越来越大,各类交通工具数量激增,导致安全隐患也逐渐增多。为了更好地对城市进行安全管理,在城市的交通路口、街道以及社区都开始安装监控摄像头。近些年,城市监控设施逐渐完善,记录的视频数量呈爆发式增长,仅仅通过人力很难处理这种海量级别的数据。为此,借助计算机视觉技术对监控视频中的目标进行自动化提取和分类是非常有必要的,这将有助于促进智慧城市的建设,有效协助政府部门提升城市管理水平。
传统的目标检测方法的核心方法是通过手工设计[1]的特征算子提取目标特征,通常使用方向梯度直方图(Histogram of Oriented Gradient, HOG)[2]、尺度不变性特征转换(Scale-Invariant Feature Transform, SIFT)[3]等方法提取目标特征。再通过分类器将提取到的特征做进一步的分类和归纳,得到图像中目标的位置和类别信息,对于不同类型的任务采用的分类器也有所不同,目标检测任务使用较多的是支持向量机、Softmax这两种分类器。随着深度学习的快速发展,一系列基于卷积神经网络的目标检测算法被提出[4],这些算法与传统方法相比较,具有速度快、泛化性能强等优点,从而迅速成为目标检测算法研究热点,并已经取得了可观的成果。目前基于深度神经网络的目标检测方法主要分为Anchor-based和Anchor-free两种类型:Anchor-based的目标检测框架又主要分为两阶段类型和1阶段类型,其中两阶段的算法是将候选框的提取和窗口位置回归、分类任务分开进行,代表算法为R-CNN系列[5]、SPPNet[6]和R-FCN[7]等。1阶段的算法是端到端类型的任务,即图片通过这种检测框架可以直接输出其中的目标位置和类别,代表算法为YOLO[8]系列和SSD[9]系列等,1阶段的算法提出的目的是以最小的精度损失为代价来最大限度地提升检测的速度;另一种基于Anchor-free类型的检测框架则丢弃掉Anchor-based的思想,采用密集预测和关键点检测等方法[10]来确定目标的位置,代表算法有CenterNet[11]和ExtremeNet[12]等。
尽管目前基于神经网络的目标检测算法已经具有较好检测精度和检测速度,但是仍然难以适应复杂的城市监控场景,主要存在以下问题:城市监控的场景多变,加上目标遮挡以及各类天气的影响,导致出现目标特征表现不明显的问题;目标类型多,不同种类的目标尺寸差异大,同类目标的尺寸变化大,同一目标在远景和近景处的尺寸相差能达到十几倍。
本文采用Yolov5s网络作为基础框架,针对监控场景目标的特点,提出一种基于注意力机制的多尺度目标检测网络(Multi-scale Object Detection Network Based on Attention Mechanism, MODNBAM),通过引入多尺度检测结构来改善监控场景目标尺寸变化大的问题,同时在网络中融入了通道注意力机制,通过计算特征的通道权重来增强目标特征,从而改善监控场景目标特征表现不明显的问题。
2 基于注意力机制的多尺度目标检测网络
2.1 Yolov5s结构
Yolov5网络共有4种不同深度和宽度的结构,其中Yolov5s是宽度和长度最小的网络,其网络结构如图1所示。Yolov5s采用CSPDarknet作为主干特征提取网络,CSPDarknet引入了跨阶段局部网络结构(Cross Stage Partial Network, CSPNet)[13],增加了网络宽度的同时剔除了大量冗余的梯度信息,并提升了网络的传播速度。在主干网络中,共进行了5次下采样,其中Yolov5s采用Focus结构对输入图片进行第1次下采样,这样保证了在下采样的过程中不会造成信息的丢失。随后在Head网络中,Yolov5s采用了路径聚合结构(Path Aggregation Network, PAN)[14]对不同尺度的特征进行融合,当输入大小为640 px×640 px时,融合的特征大小分别为80 px×80 px, 40 px×40 px , 20 px×20 px ,再用融合后的特征进行检测输出。
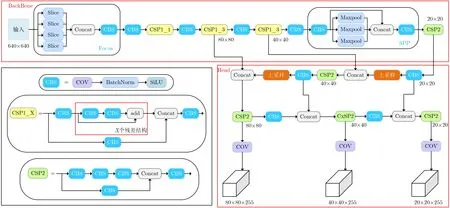
图1 Yolov5s网络结构
2.2 多尺度检测结构
在全景监控场景下,由于摄像头安装位置以及目标种类多等原因,实际目标的尺寸差异较大,使用3种尺度检测结构会存在目标漏检的情况,尤其对于摄像头远处的小目标而言效果不是很好。本文针对目标尺寸多变的特点,另外考虑到增加更大尺寸的检测结构会增加大量计算的问题,在主干网络中增加了1次下采样操作,并在预测模块中增加尺度为10 px×10 px大小的检测层,用来负责预测大目标,而原来的3个尺寸的检测层则用来负责预测更小的目标。这样不仅能够多增加一种尺寸的预测层,而且不会增加过多的计算量,使网络能更好地适应多尺度的目标。
如图2所示,本文提出的多尺度检测结构先通过在主干网络中增加一次下采样操作,使用最后4次下采样得到的特征图尺寸作为目标检测的4个尺度。再将特征图进行3次上采样,与主干网络中的特征进行拼接融合,形成特征金字塔网络(Feature Pyramid Network, FPN)[15]。然后在FPN上采样的基础上,增加了一条下采样特征融合路径,构成PAN结构,最后得到大小为80 px×80 px, 40 px×40 px , 20 px×20 px, 10 px×10 px的多尺度特征融合图。自顶向下的特征融合丰富了特征语义信息,使整个网络具有更强的特征表达能力,而自底向上的特征融合使深层网络可以获得浅层网络中丰富的位置信息。
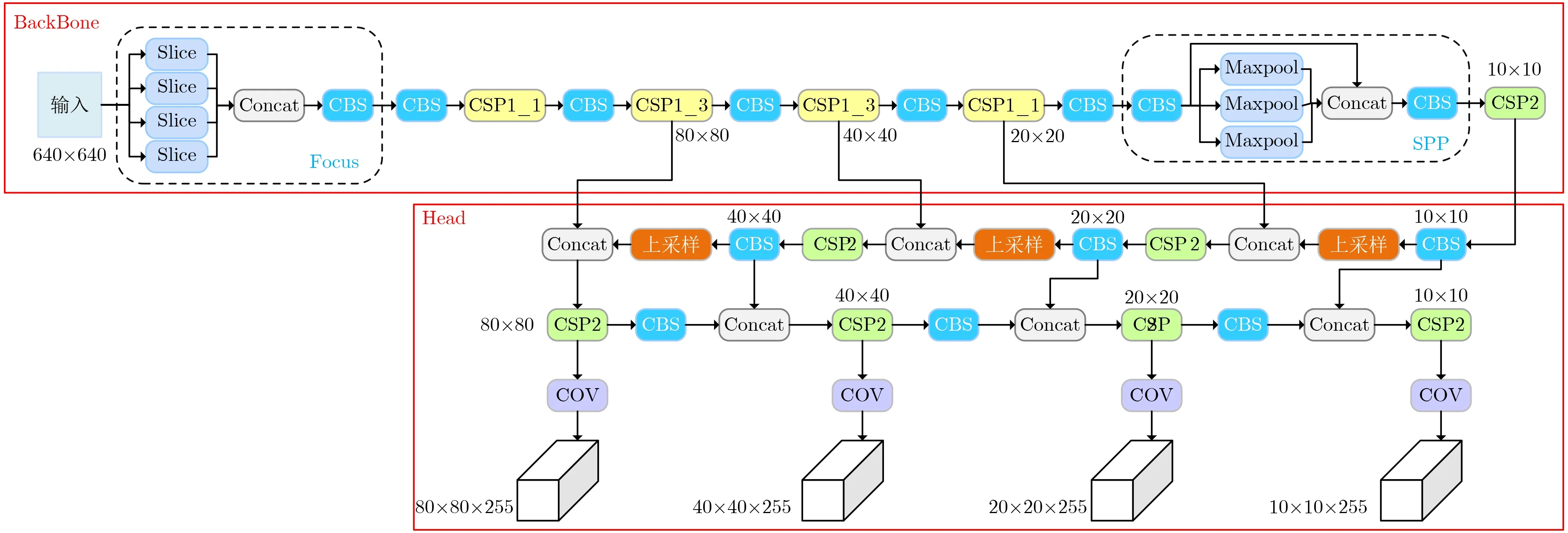
图2 多尺度检测网络结构
2.3 SE-CSPNet
随着卷积网络深度的增加,网络退化的问题越来越严重,导致浅层的网络反而能达到比深层网络更好的效果,为了解决这个问题,何凯明等人提出了残差网络,有效地缓解了随着网络加深而导致的网络退化问题。但是随着网络加深带来的巨大计算量使模型的实际部署变得十分困难,于是便提出了CSPNet,该结构主要是从网络设计的角度去解决推理过程中需要大量推理计算的问题。CSPNet易于实现,并且足够通用,在Yolov4[16]中,通过将Yolov3[17]中的DarkNet53与CSPNet结合,提出了CSPDarknet,取得了显著的效果。
监控场景由于遮挡、天气等原因导致目标特征表现不明显的问题,针对这个问题,本文在主干网络CSPDarknet中添加通道注意力机制,以增强网络的特征提取能力。通过在CSP结构中引入挤压(Squeeze-and-Excitation, SE)[18]模块,构建了新的特征提取模块SE-CSPNet。SE模块主要是从特征的通道关系之间入手,通过全连接层和Sigmoid函数来获得特征图通道的权重,再根据这些权重抑制那些无用的通道特征,而更加关注有益的通道特征,从而提升网络的检测性能,如图3所示为SE模块的结构图。
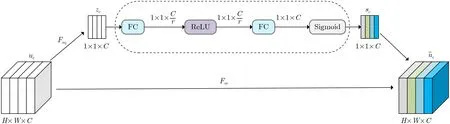
图3 SE模块结构图
SE模块分为3个操作,分别为Squeeze, Excitation和Reweight:
(1)首先将输入大小为H×W×C特征uc通过全局平均池化得到大小为1×1×C的压缩特征zc,见式(1)。特征zc的通道大小为C,与输入特征相同,对于输入特征具有全局的感受野,它能够表示输入特征在通道级的全局分布信息
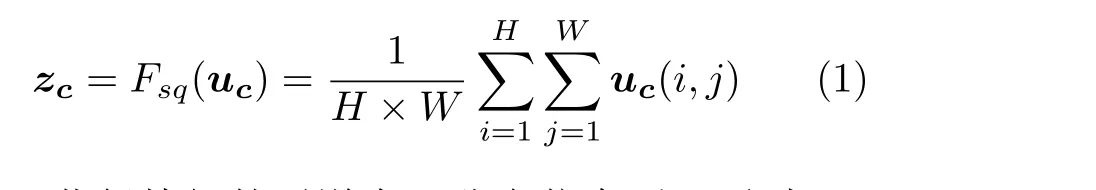
(2)获得特征的通道全局分布信息后,通过Excitation操作来获得特征通道之间的非线性交互关系,对每个通道的重要性进行预测,并赋予不同权重。通过式(2)先将特征zc通过全连接层进行降维,其中W为全连接层的权重参数,r为降维系数,值为16,目的是减小特征的通道数从而降低计算量,将降维后的特征经过ReLU激活函数,再通过一个全连接层恢复输入时的通道维度,最后经过Sigmoid函数得到权重sc
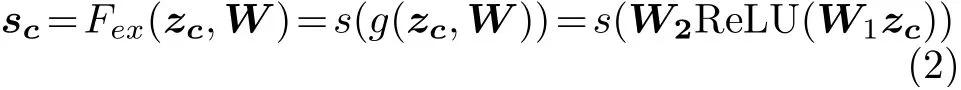
(3)将Excitation操作得到的权重sc当作特征uc每个通道的重要性,最后再通过Reweight操作将权重sc与特征uc相乘,完成在通道维度上对输入特征的重新标定,实现了注意力机制,见式(3)
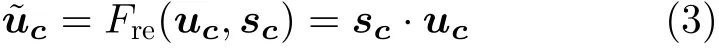
本文通过在CSP模块中嵌入SENet,构建的SE-CSPNet模块如图4所示,其中图4(a)SECSPNet1_X是在CSP1结构中嵌入SENet,图4(b)SE-CSPNet2是在CSP2结构中嵌入SENet。
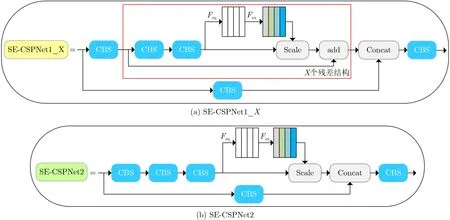
图4 SE-CSPNet
3 实验结果及分析
3.1 实验数据集
本文在公开数据集COCO和Open Images v6进行实验,其中Open Image v6是谷歌公司在2020年2月提出的数据集,该数据集包含900万张标注图片,标注类别600个,从中选取VOC数据集中20个类别的图片,剔除其他类别的标签,共6万张图片进行实验。本文另一部分实验数据采集于全景监控数据,其中包括了城市交通路口监控、高速监控、社区监控、园区卡口等环境下的监控视频,通过视频解码从中挑选了12000张图片进行手工标注,标注行人(person)、小汽车(car)、货车(truck)、公共汽车(bus)、自行车(bicycle)、摩托车(motorcycle)、狗(dog)、猫(cat)共8个目标类别。数据集中包含了全天24小时的图片,其中白天的图片8500张,夜间图片3500张,另外数据集中包含了晴天、阴天以及雨天等天气下的图片,整个数据集具有一定的代表性,数据集的部分图片如图5所示。

图5 数据集示例图片
由于数据集中的图片取自监控场景,其中公共汽车、狗、猫的类别数量比与其他类别数量较少,容易导致过拟合问题。因此本文在监控数据集的基础上,融合了VOC数据集,从中挑选包含公共汽车、狗、猫的图片,同时剔除8个类别以外的其他类别,选取了3000张图片。本文采用的监控数据集共包含15000张图片,其中随机选取12000张作为训练集图片,3000张作为验证集图片。
3.2 评价指标
本文使用多项指标对模型进行评价,其中包括平均精度均值(mean Average Precision, mAP)、推理时间以及每秒检测帧数(frames per second,fps)。计算mAP时需要先得到准确率(Precision,P)和召回率(Recall, R),计算方法见式(4)和式(5)
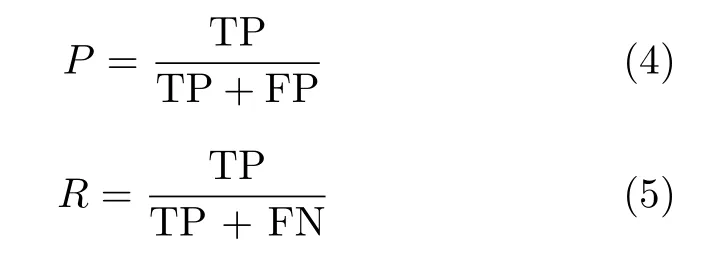
在目标检测任务中:TP表示模型检出的正样本中真实目标的个数;FP表示模型预测的正样本中不是真实目标的个数;FN表示模型没有检出的真实目标个数;准确率P表示检出的真实目标占模型预测的正样本的比例;召回率R则表示检出的真实目标占实际所有真实目标的比例,即检出率。这里的TP, FP, FN的划分条件是预测目标框与真实目标框的交并比(Intersection of Union, IoU)阈值,当IoU阈值取0.5时,在不同置信度下分别计算P, R的值,再以P和R为坐标轴绘制曲线,曲线与坐标轴之间的面积是平均精度(Average Precision,AP),求出每个类别的AP后取平均值就能得到mAP50。将IoU阈值从0.5开始每次增加0.05,一直到0.95之间取10个阈值[19],分别求出相应的平均精度均值后再求平均就能得到mAP。
3.3 模型训练
本文的实验是在CenterOS系统下进行的,显卡型号为NVIDIA TESLA P100,显存16 GB,CUDA10.2,CUDNN7.6.5,采用Pytorch深度学习框架,版本为1.7.0。
训练时使用随机梯度下降(Stochastic Gradient Descent, SGD)[20]进行模型优化,并且采用Mosaic数据增强方法,将4张图片通过随机缩放、翻转操作后拼接成一张图,这样在一定程度上增加了batch-size的大小,不仅丰富了数据集,而且减少了GPU资源的消耗。置信度损失和类别损失采用交叉熵函数计算,目标定位损失函数采用CIOU[21]函数。输入图片大小为640 px×640 px,batchsize设为64,在COCO数据集上训练300个epoch,在Open Images v6数据集上训练200个epoch,初始权重采用Kaiming[22]初始化方法进行初始化。
训练监控数据集前,使用K-means聚类算法计算初始锚框大小,使用合适尺寸初始锚框可以使网络更容易学习,提升检测精度。分别计算3个尺度和4个尺度的锚框,每个尺度得到3种尺寸大小的锚框。训练监控数据集时采用迁移学习的思想,加载COCO数据集上训练的权重,进行参数微调,训练200个epoch。
3.4 结果分析
3.4.1 公开数据集上的结果
使用本文提出的MODN-BAM首先在COCO数据集上进行消融实验,引入注意力机制时,分别在主干网络和Head网络中将不同数量的CSP结构替换为SE-CSPNet,实验对比结果见表1。
表1中Attention1是在主干网络中的所有CSP结构中嵌入SENet,Attention2是只在主干网络的所有CSP1结构中嵌入SENet,Attention3是在Head网络中的所有CSP2结构中嵌入SENet,Attention4是只在Head网络中的最后3个检测头的CSP2结构中嵌入SENet。通过4组实验数据可以看到通过在主干网络中的CSP1结构中引入注意力机制的方式对于性能的提升最好,即Attention2,对比第1行的数据,第3行引入注意力机制的mAP50和mAP分别提升了1.4%和0.7%,速度下降0.2 ms,其他3种方式在精度上均有不同程度的下降。再对比第1行和第6行的数据,加入多尺度检测结构后模型的mAP50和mAP分别提升了3.6%和2.6%,速度下降0.5 ms。第7行是本文提出的同时引入注意力机制和多尺度检测结构的MODN-BAM,其中引入注意力机制的方法采用的是Attention2的方式,通过比较第1行的结果,mAP50和mAP分别提升了4.7%和3.7%,尽管检测速度有所下降,但仅仅下降了不到1 ms的时间。
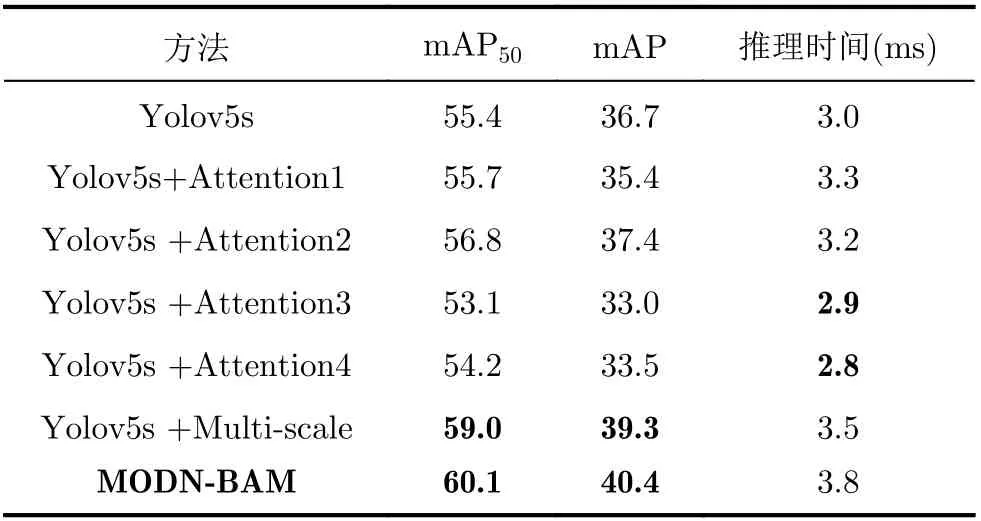
表1 COCO数据集上的消融实验结果
在COCO数据集上的消融实验结果来看,采用MODN-BAM方法后的模型检测精度有非常大的提升,为了验证在不同数据集上MODN-BAM的有效性,在Open Images v6数据集上再次进行了消融验证实验,实验结果见表2。
从表2的数据中可以看到,在Open Images v6数据集上,引入Attention2注意力机制后mAP50和mAP提升了0.9%和1.5%,引入多尺度检测结构后mAP50和mAP提升了3.4%和5.7%。对于MODNBAM,即同时引入Attention2和多尺度检测结构后模型的mAP50和mAP分别提升了4.5%和6.5%。
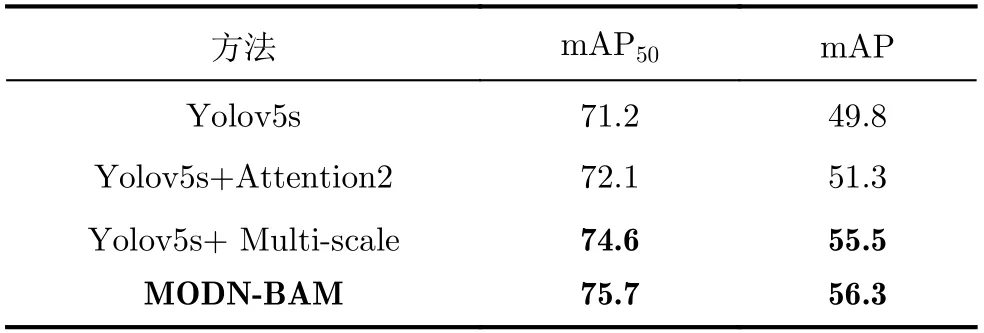
表2 Open Images v6数据集上的消融实验结果
为了进一步验证MODN-BAM的有效性,将MODN-BAM其他目标检测算法RetinaNet-ResNet101[23], YOLOF[24], YOLOF-ResNet101[24],RDSNet[25], Yolov3, Yolov3-SPP[17], NAS-FPN[26],EfficientDet-D1[27], Yolov5s等进行对比,结果见表3。表中所列出的指标数据均是在COCO数据集上得出,其中mAP75为IoU取0.75时的平均精度均值,mAPs, mAPm, mAPl分别为COCO数据集中划分的小目标、中目标和大目标所对应的平均精度均值。
从表3的数据中可以看到,RetinaNet-ResNet101,YOLOF, YOLOF-ResNet101在输入尺寸最小为800的情况下,各项精度指标以及fps均低于MODNBAM,和其中精度指标最接近的 YOLOF-Res-Net101算法相比,MODN-BAM的fps高出8.3倍。
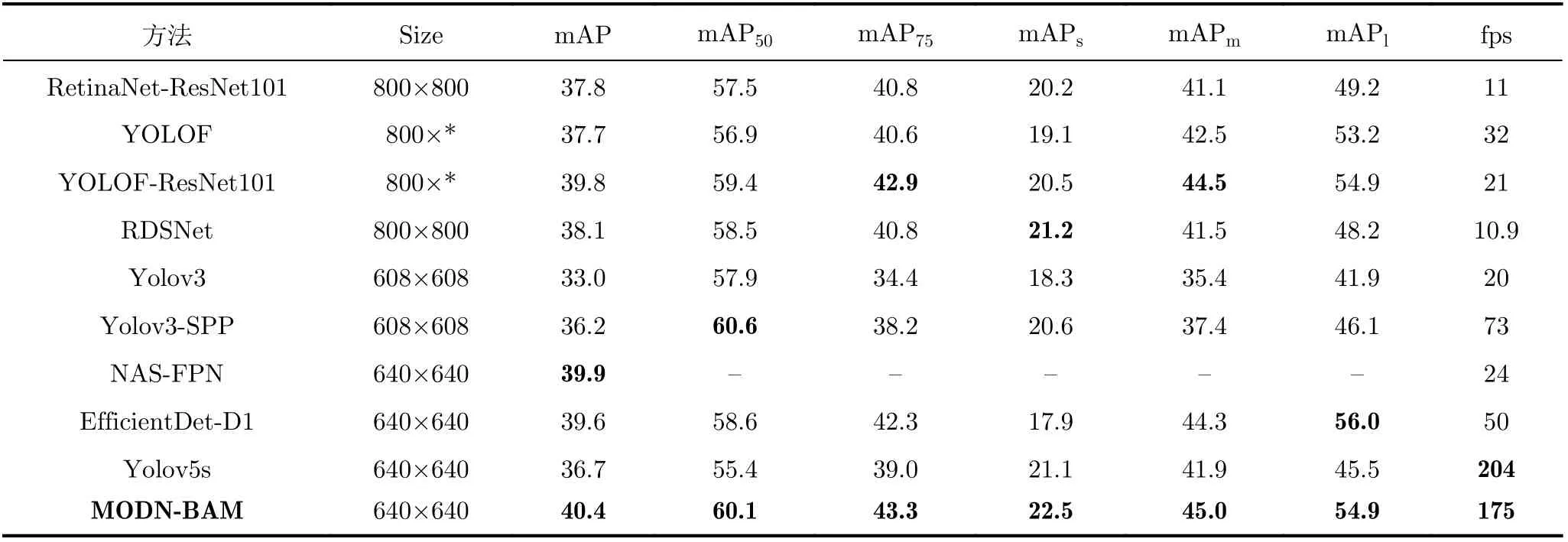
表3 COCO数据集上与其他算法的对比结果
在输入尺寸为640×640的情况下,MODN-BAM的检测速度要比NAS-FPN, EfficientDet-D1分别高出7.3倍和3.5倍。检测精度上,仅仅在大目标的检测精度上比EfficientDet-D1低1.1%,对于小目标的检测,MODN-BAM的精度要高出4.6%。相比较于基础框架Yolov5s,牺牲了1.2倍的检测速度,但其他各项精度指标均有较大的提升。
对于输入尺寸为608×608的目标检测算法,MODN-BAM对比Yolov3的提升效果最大,仅mAP就提升了7.4%,小目标的检测精度提高了4.2%,并且在速度上要比Yolov3快8.7倍;对比Yolov3的改进版算法Yolov3-SPP,MODN-BAM只有mAP50低了0.5%,但包括mAP在内的其他精度指标都高于Yolov3-SPP,fps也高出2.4倍。
从表3的数据来看,MODN-BAM的各项指标处于中上水平,在保持较高检测精度的情况下,检测速度仍然具有明显的优势,在检测精度和检测速度之间达到了一个非常好的平衡。
3.4.2 全景监控数据集上的结果
从COCO和Open Images v6数据集上表现结果来看,MODN-BAM是一个有效的目标检测网络。为了验证MODN-BAM在城市的全场景监控下的应用效果,在全场景监控数据集上进行消融实验,实验结果见表4,表中的frame size为测试视频的分辨率大小。
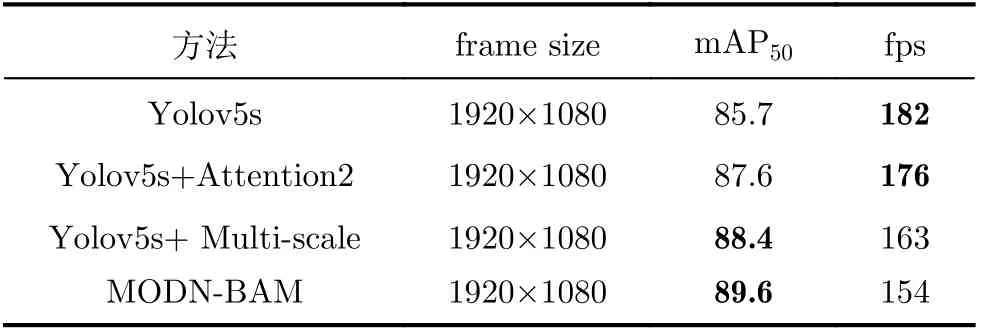
表4 全场景监控数据集上的消融实验结果
通过表4的实验数据可以看到,分别引入多尺度检测结构和注意力机制后,模型在全场景监控数据集上的mAP50分别提升了2.7%和1.9%。同时引入两种方法的MODN-BAM在全场景数据集上的mAP50达到了89.6%,平均每秒可以处理154帧图片。
在测试数据集中选取3张城市监控拍摄的图片,分别使用Yolov5s和MODN-BAM进行目标检测,检测对比结果如图6所示,从中可以看到本文提出的MODN-BAM与Yolov5s相比较检出率有明显的提升。在图6(a)右侧中间的两辆摩托车和一些远处的汽车以及图6(b)中左侧墙角的自行车和小狗,这些漏检的目标通过MODN-BAM都可以成功地检测出来。夜间的检测对比结果如图6(c)所示,能够看到MODN-BAM对于夜间的目标也有非常好的检测效果。

图6 检测结果对比
4 结束语
为了提高监控场景下目标监测性能,本文提出一种基于注意力机制的多尺度全场景监控目标检测方法。本文采用Yolov5s作为基础框架,分析监控场景下的目标具有尺寸变化差异大的特点,提出了一种多尺度目标检测结构,提升网络对目标尺寸变化的适应能力。设计了一种基于注意力机制的特征提取模块,并将其融入到主干网络中,提升网络的特征提取能力,有效地改善了监控场景下目标受到遮挡、环境以及天气等影响导致的特征表现不明显问题。采用K-means聚类方法计算监控数据集的初始锚框,提升检测精度,加速模型的收敛。
通过在不同数据集上验证实验,MODN-BAM在COCO数据集上的mAP50和mAP分别提升了4.7%和3.7%,推理速度达到了图片3.8 ms。在全场景监控数据集上,mAP50达到了89.6%,处理监控视频时速度可以达到154 fps。实验结果表明,MODN-BAM能够有效地应用于全场景监控下的目标检测,并且具有较快的检测速度,完全可以达到实时检测的效果。
