一种基于风险感知策略的多节点任务调度方法
2022-09-22赵亦玄楚涌泉
刘 斌 赵亦玄 王 辉 楚涌泉 付 琨
①(中国科学院空天信息创新研究院 北京 100094)
②(中国科学院大学 北京 100049)
③(中国科学院大学电子电气与通信工程学院 北京 100094)
④(中国科学院网络信息体系技术重点实验室 北京 100094)
⑤(首都师范大学信息工程学院 北京 100048)
⑥(北京航空航天大学软件开发环境国家重点实验室 北京 100191)
⑦(中科边缘智慧 北京 100190)
1 引言
随着无线通信技术的不断进步,越来越多的文献开始研究关于集群网络中节点容错处理方法[1]及节点容错调度[2],由无人机组成的分布式集群具有设备数量多、计算任务复杂、多源设备协作的特点[3],可执行勘探、检测等数据处理的工作。集群中的每个无人机(Unmanned Aerial Vehicle, UAV)都被视为一个具有计算能力的节点,实现数字化信息的快速处理。但在复杂的真实环境下,任何计算节点(无人机)不仅面临着自身任务处理能力有限,还可能出现网络带宽受限等问题[4]。一般地,资源不充裕的节点会将本地计算任务卸载[5]到资源充足的计算节点[6],然而这会导致目标节点上正在执行的计算任务的中断,给目标集群带来一定风险。同时整个集群还需要承担无人机节点随机接入或离开时产生的网络波动。
在现有工作中,研究者在解决分布式集群中任务计算与处理的问题时,普遍从节点资源利用率和任务处理时延的角度入手,将问题转化为分布式任务分配与调度的问题。IBM研究中心和帝国理工大学的研究将资源分配和任务调度问题建模为一个马尔可夫决策过程[7],为了减少状态空间,进一步将该问题转化为两个具有分割的状态空间的独立的马尔可夫决策过程,并利用李雅普诺夫优化技术设计了一个代价最优的在线算法。研究针对无线城域网下Cloudlet集群的负载均衡问题,澳大利亚国立大学[8]给出的算法理念是:首先求取各任务的平均响应时间,然后决定每个Cloudlet需要分配多少任务到其他Cloudlet中。宾夕法尼亚州立大学[9]的研究指出目前多数模型将用户服务请求(或应用程序)当作专用资源片,其获得的计算、通信和存储资源都是不可共享的,并且指出存储资源不可共享的假设不适用于数据分析服务,如虚拟现实等,这些服务通常有部分存储资源是可以共享的;该研究针对联合服务放置和请求调度问题建立线性规划模型,首次将通信资源和计算资源加入约束条件,并将同类型服务的存储资源设定为可共享的,将优化目标设为最大服务用户数,并给出了线性时间解的算法。佐治亚理工学院[10]提出了Femtoclouds框架,这是一种将边缘集群设备转化为Cloudlet的边缘计算框架,用于处理来源于集群中或集群外的计算任务;Femtoclouds根据关键路径将其拆分成多个路径依赖的子任务,然后结合风险控制机制依照执行时间小的优先策略将子任务分配到边缘设备上;在边缘设备内部,基于各队列中任务已执行时间为指标,对各队列中的任务进行公平调度,并加入截止时间优化策略,优先处理接近截止时间的任务。上述工作的主要思想都是尝试将计算任务划分为细粒度的多个任务组件,再根据任务的资源需求特性、实时的网络连接状态等因素,动态地在计算终端之间进行任务的调度,通过多方算力间的协同工作来实现应用的分布式执行,但类似的解决方案尚无法满足无人机集群所面临的场景。由于单个节点(无人机)的机动性高且不稳定,整个网络对可处理节点波动变化的容错能力的要求越来越高[11]。
综上所述,有效降低计算节点(无人机)的处理任务时间,将计算任务合理高效地在每个计算节点间动态调度以加快任务处理与反馈,同时还要保障集群网络执行任务调度过程中可对节点的高度动态性和不稳定性做出容错处理成为本文研究重点。为解决上述问题,本文提出一种新颖的计算任务调度策略,充分考虑了任务的时效性,同时为机动计算节点设计了容错机制可以更好地应用于复杂环境。主要研究成果如下:(1)针对任务的执行要求和节点的资源状况选择合适的优化目标组合,并研究基于多目标优化方法的任务调度策略以尽量满足这些优化目标。(2)针对多节点情况下因节点失效或离开等导致任务中断的情况,研究任务调度的错误处理机制和容错机制。错误处理机制用于确保任务的完整执行,监控任务在传输过程或执行过程的具体运行情况,当任务执行失败中断后重新调度并重新执行。
2 面向多节点协同计算的任务调度方法
2.1 多节点环境下协同计算任务调度框架
本文提出的调度框架的执行过程可总结为以下步骤:(1)用户提交任务后,任务加入调度器的等待队列。(2)预测器对任务进行分析,提供任务在各计算节点上的预计执行时间。(3)控制器根据各计算节点的实时资源信息和网络信息作出任务分配决策。(4)任务追踪器对需要进行计算卸载的任务,向对应的计算节点上的任务调度接收服务发起计算卸载。(5)任务追踪器在计算节点上监控各任务的执行情况,并进行错误处理,如:对被中断的任务重新发起调度和卸载执行过程。框架示意图如图1所示。
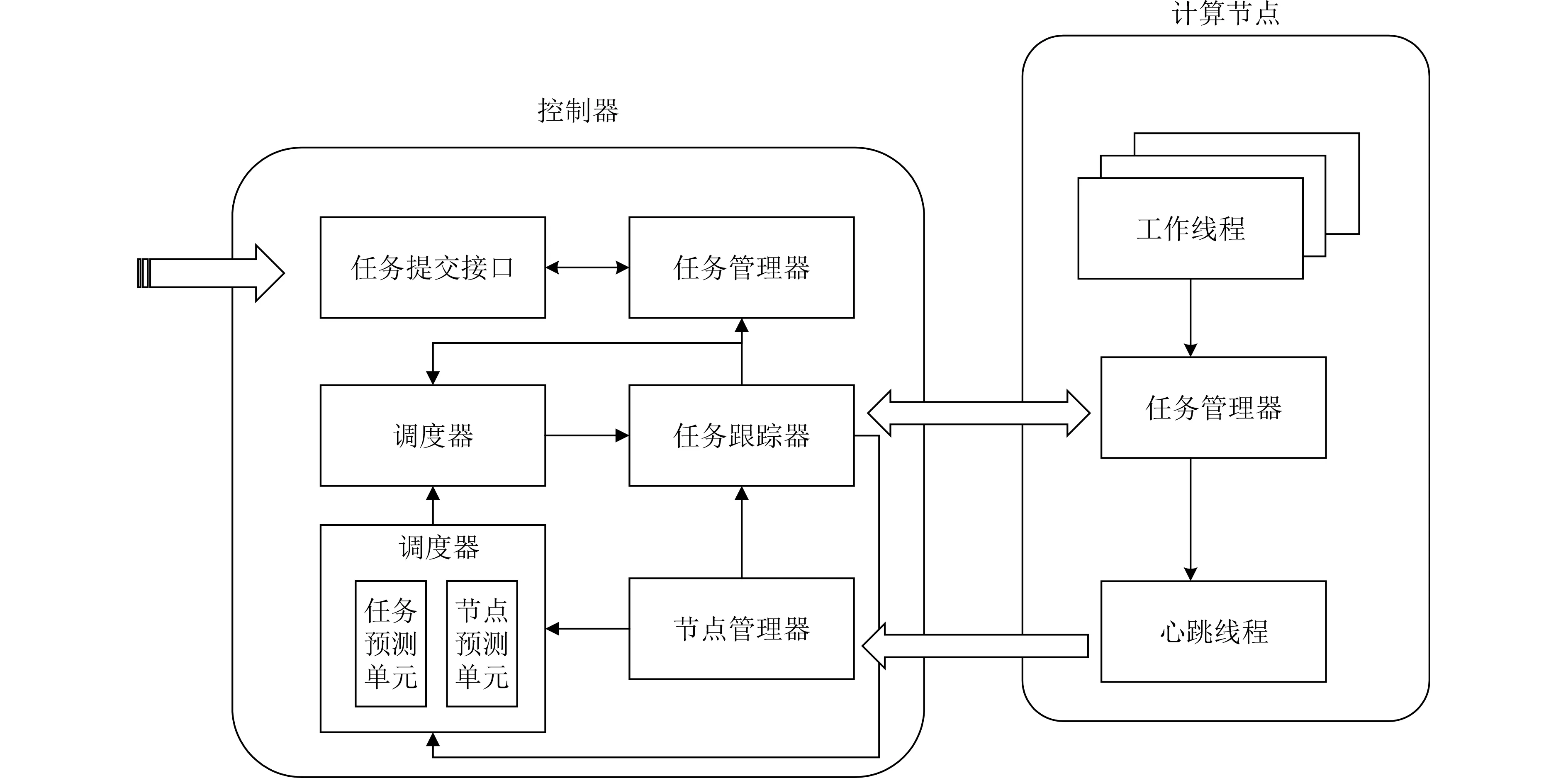
图1 任务调度框架示意图
2.2 产生概率分布和预测值的方法
在上述任务调度框架中,预测器负责产生任务分配决策所需各变量的预估值。预测器包含1个任务预测单元集合和1个节点预测单元集合。每个任务预测单元为1个或1组具有类似软硬件配置的节点,负责维护已执行任务的时间分布信息。类似地,节点预测单元为1个或1组具有类似网络环境的节点,负责记录和预估存留时间信息。
本文采用一种黑盒方法[12]来为每个任务产生概率分布和预测值。该方法假设大部分任务与先前所有任务的某个子集类似,且类似任务有相似的执行时间。该方法不需要获取任务的结构信息或用户预先提供的信息,但需要每个任务的属性集合。本文选用3个属性:提交任务的镜像名、任务的CPU需求和任务的内存需求。对于每个属性-键值对,该方法通过直方图跟踪所有具有相同属性和值的任务的执行时间并生成一个经验分布。每个属性-键值对在直方图中由算法进行预估,数值类型包括:平均值、中值、衰减率为0.5的移动平均值以及最近20个任务的平均值。同时在每次预估时维护4个点估计方法的归一化平均绝对误差(Normalized Mean Absolute Error, NMAE)。当预估一个带有若干属性任务的执行时间时,从所有属性-键值对应的直方图中比较所有点的估计值的NMAE,选择最低NMAE对应的点估计值和执行时间分布。此外,本方法使用一个直方图以跟踪所有任务的执行时间,用于预估平均任务执行时间。根据以上原理,每个任务预测单元为1个或1组服务节点维护其任务执行时间的分布。同理,每个节点预测单元为1组服务节点维护其存留时间的分布,但并不用区分多种属性维护存留时间的分布。
本方法采用一种基于流的直方图算法以构建直方图[13]。1个直方图是1个键值对的集合,作为1个实数集合的近似代表,表示为{(v1,f1),(v2,f2),...,(vB,fB)}。 对于每对(vi,fi),1≤i ≤B,vi表示1个数字的值,fi表示该数字的频数。1个直方图在生成时规定最大键数量B,当新加入某个数值而导致直方图总键数超过规定数量时,归并数值最近的两个键值对。
本方法定义了概率直方图的概念,表示为{(v1,p1),(v2,p2),...,(vB,pB)}。 对于每对(vi,pi),1≤i ≤B,vi表 示一个数字的值,pi表示该数字的概率。因此,概率直方图是一个概率分布的近似代表。本方法新增两个算法用以将直方图转换为概率直方图,如表1和表2所示。

表1 右移和概率转换过程(算法1)

表2 从给定值开始概率转换过程(算法2)
算法1首先根据1个位移值对1个直方图进行右移操作,然后将给直方图转换成概率直方图。算法2首先在某个直方图中根据某个给定值,过滤掉小于该值的点,然后将剩余的直方图转换为概率直方图。本方法所述任务调度策略中各种时间值的概率分布的关系如图2所示。
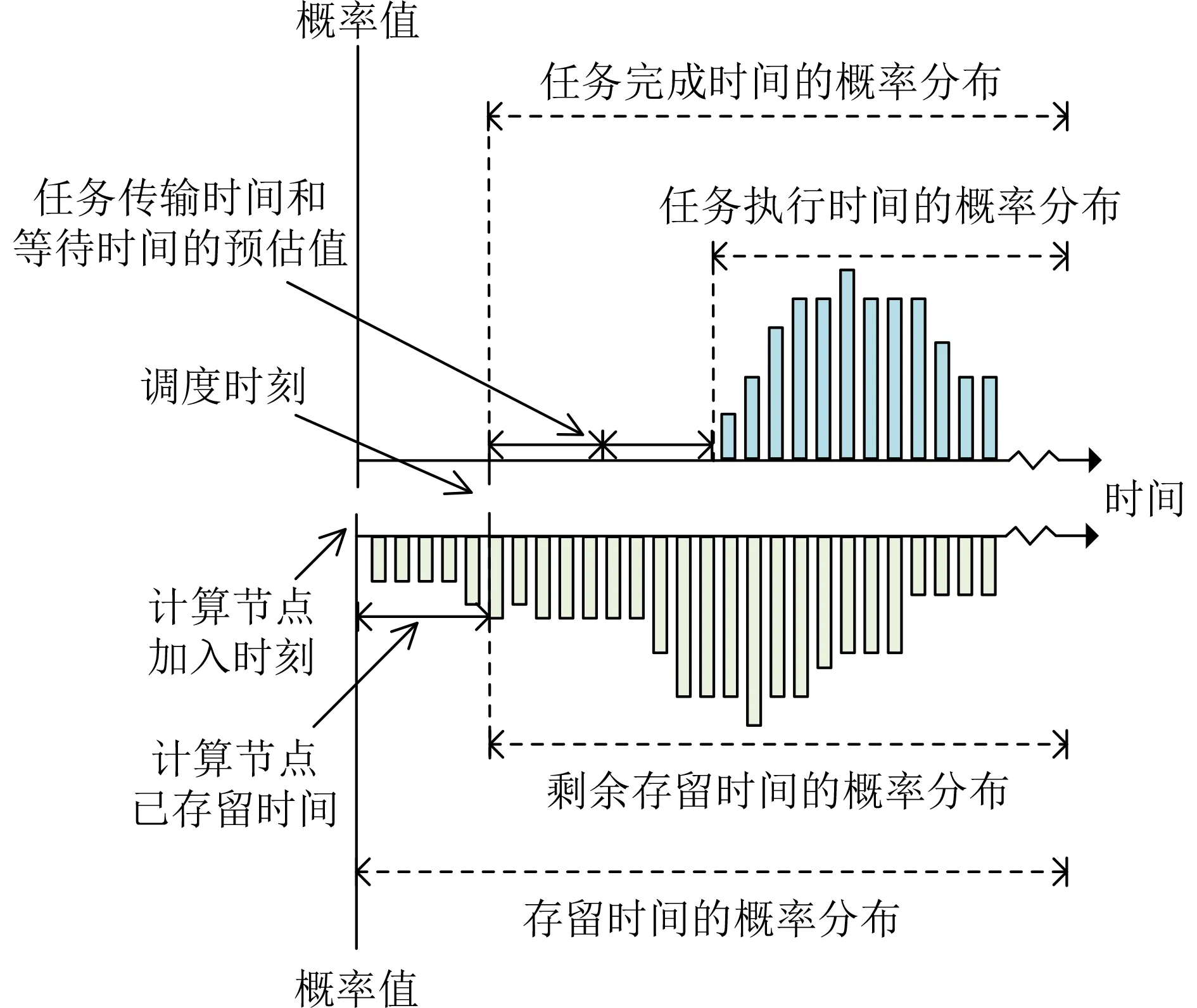
图2 各时间值概率分布的关系
预测器从任务预测单元获取任务的执行时间的概率分布,并在计算任务的传输时间和等待时间后,使用算法1可以获得任务完成时间的概率分布和预测值。类似地,从节点预测单元获取存留时间的概率分布,在计算该节点的已存留时间后,使用算法2可以获得节点剩余存留时间的概率分布。
在可扩展性方面,本方法主要使用3种设计以减少内存占用。首先,基于流的直方图算法使用归并方法控制其最大支持的键数量,其本身的设计能够使用固定大小的内存来维护1个任意键值对数量的直方图。其次,每个任务预测单元不必仅为单个服务节点维护1个执行时间直方图,可同时对应一群软硬件配置相似的节点。最后,每个节点预测单元为1群网络环境相似(比如在同一接入点范围内)的节点维护1个存留时间直方图,而不仅是单个节点。
2.3 风险感知的多节点计算任务调度策略
2.3.1 最小化平均完成时间的任务分配策略


本文整体看待任务集中的所有任务,构建最小化任务平均完成时间的策略,将该任务分配问题构建为0-1整数线性规划问题如式(4)所示

在遗传算法的选择过程中,本文选用轮盘赌方法。在交叉过程中,选用标准的单点交叉操作子。在变异过程中,选用实值变异方法,设定变异比例为30%。每个染色体中的选中任务被随机分配给可选的计算节点。本文设定染色体数量为30%,迭代次数为500。
2.3.2 风险感知的鲁棒任务分配策略
本文选用一种直方图算法[15]分类记录每个已完毕任务的运行时间及其频率分布,并采用了多评估方法预估某个任务的运行时间,认为应该使用某个时间变量的概率分布,而非该变量的一个单点估计值(如平均值和中值等)。本文将节点的预计存留时间和节点在当前集群中已度过的时间两者差值定义为节点的剩余存留时间。当将一个任务分配至一个计算节点时,假设该计算节点的剩余存留时间为一个随机变量RPT,其概率分布率为式(7)
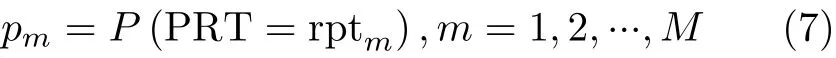

然而任务中断概率并不能准确反映该中断的潜在时间开销。对于不同的计算节点,在具有相同的任务中断概率的同时可能具有不同的存留时间,任务在中断时已运行的时间也不一定相同。因此,应该从时间值的角度来比较分配的优劣, 而不单是任务中断概率。
由于每次任务分配决策是相互独立的,故在量化单次任务中断的时间开销时假设任务的第2次执行必然完成。又假设任务在重新调度时也被分配至一个软硬件配置相似的计算节点,即第2次正常运行时间与第1次正常运行时间相同。基于以上假设,则定义在任务中断风险下的期望完成时间为随机变量TCT, 其定义为


在求解该规划问题的优化过程中,为了获取最小代价,一方面需要为每一个任务最小化额外开销时间,另一方面从总体上最小化任务的平均完成时间。从任务分配过程看,调度器将为每个任务尽量分配计算力强且风险小的计算节点。
以上策略的一个关键点是任务中断风险的时间量化,而非仅仅获知中断概率。假如贪婪地保证中断概率尽量小而不考虑完成时间的对比,那么会将多个任务分配至一个稳定的计算节点,导致该计算节点的负载不均衡,反而增加任务的等待时间,且从整体上看,任务的平均完成时间会增大。故任务的正常完成时间和额外开销时间应当同时考虑。
在求解算法上,可以沿用上述遗传算法。其中规划问题的总代价更新为
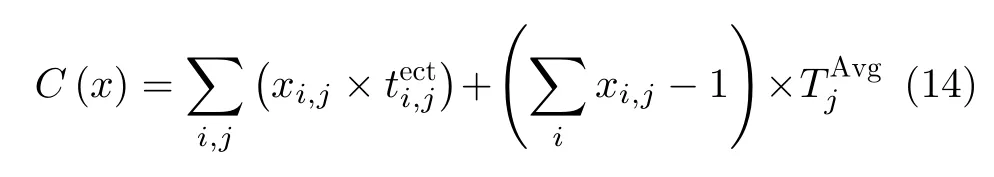
3 实验及结果分析
3.1 硬件配置
本文使用若干移动设备搭建了一个测试床。其中,使用一部台式计算机作为本地节点,该计算机配置有Intel(R) Core(TM) i5-8400的CPU和16 GB的内存。使用包括Surface Pro 4(M3),树莓派3B+和树莓派4B 3种类型移动设备作为计算节点。各设备的硬件配置参见表3。各设备通过WiFi相互连接。

表3 计算节点硬件配置
本文同时设置模拟实验以评估在大量计算节点下各策略的任务分配性能,并验证不同的参数配置对任务分配性能的影响。模拟实验使用模拟计算节点,模拟计算节点与真实的计算节点的区别在于,该计算节点软件运行在同一台式计算机,而非移动设备。本文使用均匀分布 U(8 Mbit/s, 80 Mbit/s)为每个模拟计算节点生成带宽值,并使用一个sleep函数模拟任务的传输过程。
本文使用泊松过程来模拟计算节点的到达规律,并使用正态分布生成每个移动设备在集群中的存留时间。其中,正态分布的方差设置为均值的10%。
3.2 对比基准策略
本文将上述容错机制加入调度策略中,提出一种具有容错能力的动态节点任务调度方法(Dynamic Node of Task Assignment, DN-TA),将与以下算法策略作对比。
(1)最短完成时间优先(Shortest Completion Time First, SCTF):贪婪地将任务分配至能有最小完成时间的计算节点。
(2)最小化批量完成时间(Minimize Batch Completion Time, MBCT):即最小化平均完成时间的任务分配策略。
(3)在现有相关工作Femtocloud中使用的启发式算法。对于每一个任务,该算法首先根据节点的任务中断频率递增排序。然后将首个节点设为最佳节点,并迭代地按序与余下每一个节点对比两个指标。一个指标是候选节点与最佳节点的相对节省时间,另一个是候选节点与最佳节点的相对增加风险。假如相对节省时间超过相对增加风险,则将该候选节点设置为最佳节点。
在以上3个算法策略中,前两个策略都默认任务的运行过程是无风险的。后者则考虑了任务中断风险,但其仅仅考虑任务中断概率,并没有量化任务中断带来的额外开销时间,但相同的任务中断概率可能对应不同的额外开销时间。
3.3 性能指标
对于没有截止时间限制的任务,本文使用平均完成时间和平均任务执行次数来评估任务分配性能。对于带有截止时间限制的任务,本文使用截止时间错失率来评估任务分配性能。这些指标的定义如下所示。
(1)平均完成时间(average completion time):该指标计算所有已完成任务的完成时间的平均值。
(2)平均任务执行次数(average number of executions):该指标计算所有已完成任务的平均执行次数。该指标直接反映了任务分配策略选择低风险节点的能力,即避免任务中断的能力。
(3)截止时间错失率(deadline miss ratio):该指标统计所有未能在截止时间前完成的任务所占的百分比。
3.4 仿真实验与分析
(1)测试床实验。在测试床实验方面,由于实验设备数目较少,不使用泊松过程模拟计算节点的到达过程。当一个计算节点离开时,该节点在一段空闲时间后重新加入集群。使用正态分布生成该空闲时间的长度,该分布的均值等于节点平均存留时间的20%,标准差为均值的10%。因此,每个计算节点在集群的存留时间占比为80%。任务到达率设为每分钟10个任务。实验的参数设置如表4所示。各任务分配策略在测试床实验的性能对比结果如图3所示。
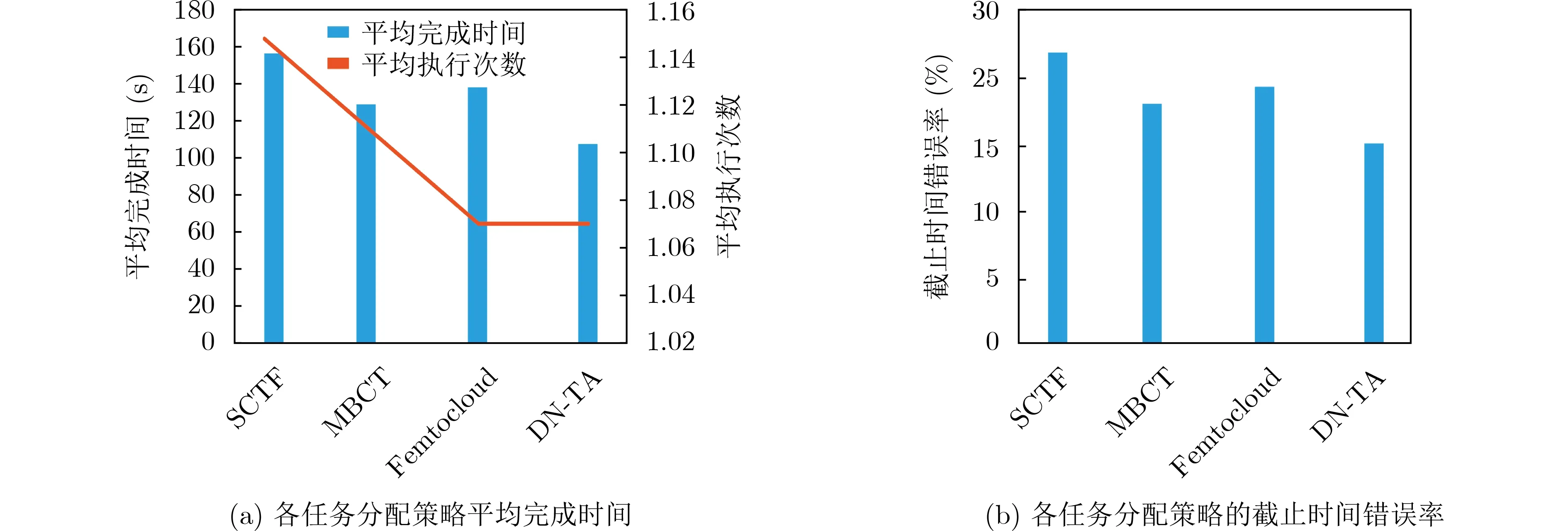
图3 测试床实验结果
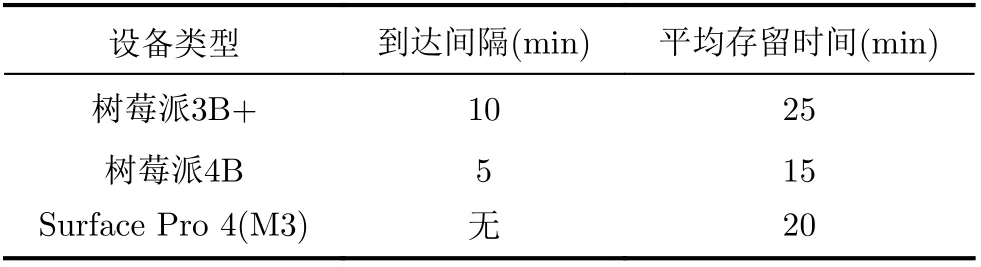
表4 测试床参数设置
本文所提出的策略DN-TA具有最短的平均完成时间和最低的截止时间错失率,并和Femtocloud获得相近的平均任务执行次数。从任务中断风险避免的性能看,DN-TA和Femtocloud两个考虑任务中断风险的策略相比不考虑的两个策略获得更小的平均任务执行次数。然而,尽管DN-TA和Femtocloud具有差不多的平均任务执行次数,但却具有最短的平均完成时间和更低的截止时间错失率。这一方面反映了DN-TA的最小化平均完成时间的策略的有效性,另一方面反映了Femtocloud在优先确保较小的任务中断风险时,未能同时考虑最小化部分任务的完成时间。
(2)模拟实验。在模拟实验中,本文研究一些参数配置(比如任务到达速率,计算节点的平均存留时间等)在任务分配性能上对各任务分配策略的影响。改变这些参数,可以改变集群的整体计算能力和工作负载,从而改变任务中断风险的大小。在模拟实验中,各参数的默认值如表5所示。

表5 默认参数设置
(a) 任务到达速率的影响分析。任务到达速率直接影响了集群的工作负载量和各计算节点等待队列的长度。等待队列长度越长,则在队列尾部的任务的中断风险越高。因此任务到达速率越高,任务中断风险也越高。研究改变任务到达速率对任务分配性能的影响的实验结果如图4所示。
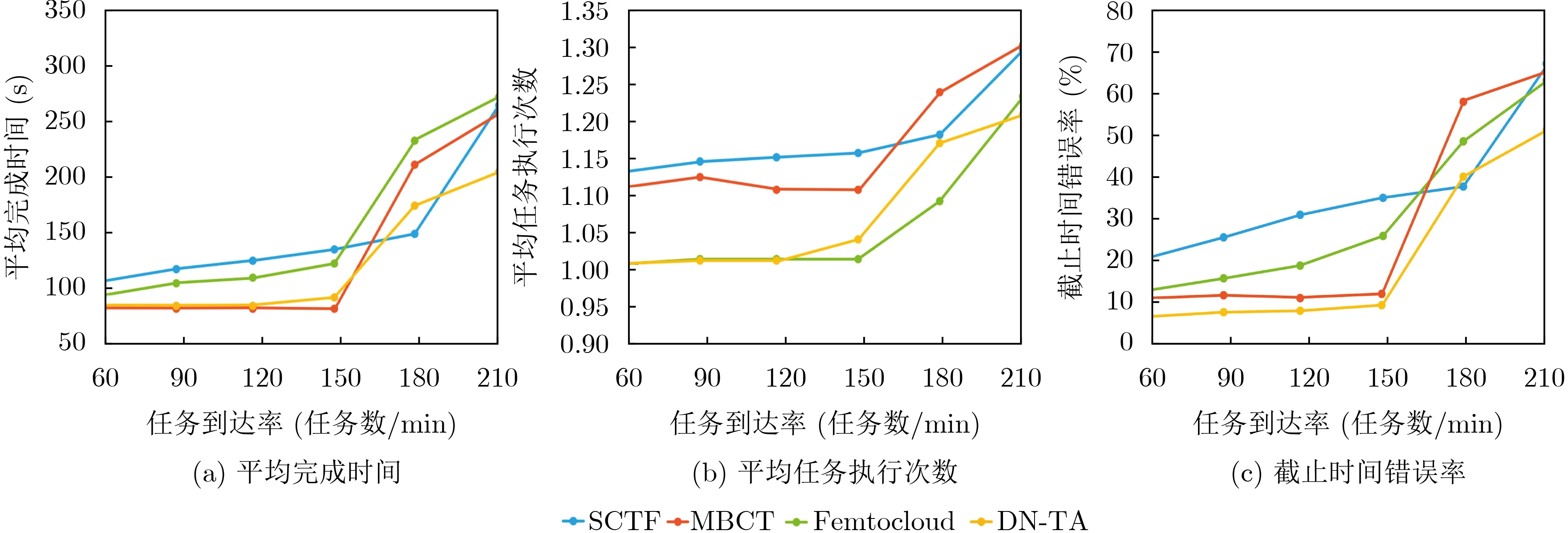
图4 任务到达速率的影响
总体上,平均完成时间、平均任务执行次数、截止时间错失率3个指标值都随着任务到达速率的增大而增大。在大部分情况下DN-TA具有最短的平均完成时间和最低的截止时间缺失率。与同样最小化平均完成时间的策略MBCT相比,当任务到达速率较低时,DN-TA 具有近似的平均完成时间。但当任务到达速率较高时(大于150 任务/min),DNTA具有更短的平均完成时间和更低的截止时间缺失率,表明在任务中断风险较高时,DN-TA的风险感知机制的有效性。与Femtocloud相比,尽管Femtocloud有更低的平均任务执行次数,但DNTA却具有更低的平均任务完成时间。这表明DNTA在更可靠的执行和更短的执行时间两者的权衡中表现更好,因其量化了中断风险的额外时间开销,可以直接比较潜在的额外开销时间和因选择更短无风险完成时间而节省的时间,以预估中断风险下期望最短完成时间。
(b) 计算节点到达速率的影响分析。计算节点到达速率直接影响了集群中计算节点的数量,更多的计算节点能承担更多工作负载,减少等待队列长度,提供更稳定的运行环境,减少任务中断风险。研究改变计算节点到达速率对任务分配性能的影响的实验结果如图5所示。
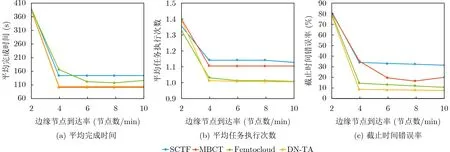
图5 计算节点到达速率的影响
总体上,所有指标随着到达速率增大而降低。当到达速率大于4 节点/min时,DN-TA和Femtcloud具有差不多的平均任务执行次数,但DN-TA有更短的平均完成时间和更低的截止时间缺失率,表明DN-TA能更好地衡量更可靠的执行和更短的执行时间。与MBCT相比,DN-TA有差不多的平均完成时间但有更低的截止时间缺失率。这表明MBCT的各任务的完成时间有更大的方差,在部分任务的分配决策中,因总是选择最短的无风险完成时间反而增加因任务中断导致的额外开销时间。当到达率为2节点/min时,所有策略的截止时间缺失率都很高且差距不大,说明此时工作负载十分繁重,也说明了在负载十分繁重的情况下,考虑风险感知并无帮助。
(c) 计算节点异构性的影响分析。该模拟实验目的在于验证任务分配策略是否能充分利用具有更高计算能力但却有更短的平均存留时间的计算节点。本文在保持原有的节点的同时,新加入一组模拟节点。这些节点运行在一台性能更强的配置有Intel(R) Core(TM) i7-8700的 CPU和6 GB内存的台式机上。研究改变异构节点的到达速率对任务分配性能的影响的实验结果如图6所示。
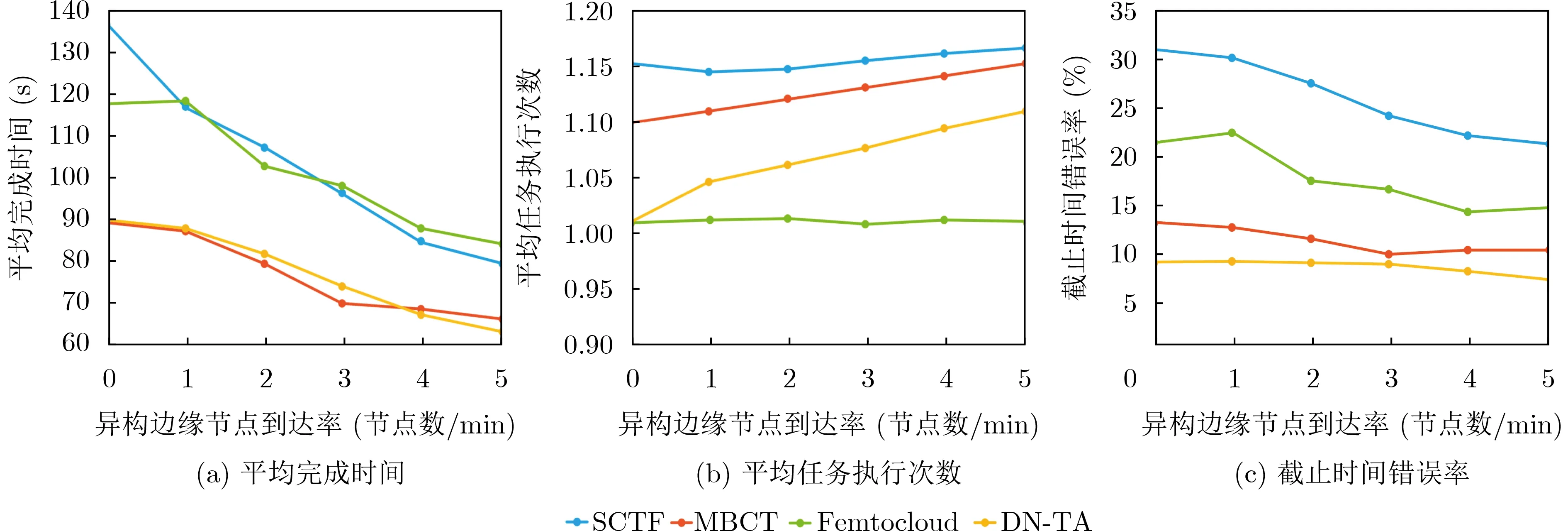
图6 计算节点异构性的影响
总体上,所有指标都随着异构节点到达速率增大而减小。相比其他策略,Femtocloud能很好地保持较低的平均任务执行次数,因该策略优先保障任务更可靠执行。而DN-TA倾向于使用能具有更短完成时间的节点,尽管此时的任务风险增大。
(d) 计算节点平均存留时间的影响分析。计算节点的平均存留时间直接影响了任务中断风险。在此实验中,为了在改变平均存留时间的前提下,保持整体集群中计算节点的可用性,采用与测试床实验一样的实验方法。每个计算节点在退出集群后,在一段时候后重新加入集群。本文将每个节点的可用时间占比保持在80%。研究改变计算节点平均存留时间对任务分配性能的影响的实验结果如图7所示,其中+∞表示节点在实验过程从不退出集群。

图7 计算节点平均存留时间的影响
DN-TA和Femtocloud在3个指标上都优于其余两个不考虑任务分配风险的策略。从截止时间缺失率看,除平均存留时间为+∞时的其余情况下,工作负载偏重。此时,尽管 Femtocloud有更低的平均任务执行次数,但其平均完成时间与DN-TA差不多。表明了此时任务中断带来的额外的开销时间与选择更短无风险完成时间而节省下来的时间基本相等。
4 结束语
在实际的多计算节点间任务调度执行过程中,不同的任务调度策略将导致不同的任务响应时延,甚至出现节点并不满足任务资源的需要导致任务延误乃至失败的情况。针对这一问题,本文围绕实际情况,研究多计算节点的任务调度方法,根据卸载任务的具体需求以及机动计算节点的动态状态信息进行实时调度,使得计算任务能够分布式进行,实现缩短任务的平均响应时间等目标。本文提出的DNTA策略使调度方法具有容错性,同时基于多目标优化的任务调度算法使整个调度流程提升了效率。
