一种利用SE-Res2Net的合成语音检测系统
2022-09-09梁超,高勇
梁 超,高 勇
(四川大学 电子信息学院,四川 成都 610065)
0 引言
说话人识别(Automatic Speaker Verfication,ASV)技术目前在公共服务、司法鉴定和货币交易等领域的应用十分广泛,但与此同时也受到合成语音的频繁攻击,特别是面对诸如重放攻击[1]、语音转换[2]和语音合成[3]等攻击语音时,传统的ASV系统难以招架。目前常用的方法是在ASV系统前串联一个独立的、互不干扰的合成语音检测系统,首先将待检测语音输入到合成语音检测系统进行安全性验证,若该语音通过合成语音检测系统,则被判为真实语音,然后再输入到ASV系统中进行说话人匹配。
为了促进抗欺骗检测的研究,国际上每两年就会举办欺骗语音检测的ASVspoof挑战赛。ASVspoof2015[4]重点研究了语音合成和语音转换攻击的对策。ASVspoof2017主要研究了重放语音攻击的对策。ASVspoof2019[5]是第一个同时考虑研究3种欺骗攻击的挑战赛,评价指标除之前的等错误概率(Equal Error Rate,EER)外,还引入了最小串联成本检测函数(tandem Detection Cost Function,t-DCF)来表征整个系统的性能。本文使用的数据库是ASVspoof2019的逻辑访问数据库(Logical Access,LA)。
常见的合成语音检测系统可分为前端特征提取和后端分类器。文献[6]提出了一种新的信号分析方法——经验模式分解 (Empirical Mode Decomposition,EMD) 法,该方法依据信号的时间尺度特征进行信号分解,无需预先设置基函数,与传统的分析工具有着本质的区别。本文所用的语音特征先对信号进行EMD,然后分别计算基函数与信号的皮尔逊相关系数(Pearson Correlation Coefficient),再将皮尔逊相关系数处理后作为权值与基函数相乘叠加成新信号,达到优化的目的,接着对优化后的语音信号提取梅尔倒谱系数(Mel Frequency Cepstral Coefficients,MFCC)以及逆梅尔倒谱系数(Inverse Mel Frequency Cepstral Coefficients,IMFCC),并拼接为双通道特征以此增加特征多样性,便于神经网络提取到更加高级的特征和进行泛化学习。
后端分类器主要使用了SE-Res2Net[7]网络。卷积神经网络(Convolution Neural Network,CNN)通过堆叠卷积块的分层方式获取多尺度特征,具有着巨大优势。与CNN不同,Res2Net通过将残差网络[8]中的主卷积替换成多层的残差结构连接的卷积核组以此来提取多尺度特征,具有更少的参数量,Squeeze-and-Excitation Networks (SENet)[9]注意力机制通过给每个特征通道分配权值建立起通道之间的相关性,使得模型更加关注权值较大的特征通道,同时抑制权值较小的特征通道。将Res2Net与SENet组合成SE-Res2Net模块,该模块可以任意地添加到现有模型之中。实验表明,SE-Res2Net网络适合作为合成语音检测后端分类器。
1 相关工作
文献[10]提出了常数Q倒谱系数(Constant Q Cepstral Coefficient,CQCC),CQCC是基于常数Q变换(Constannt Q Transform,CQT)得到的倒谱系数。与传统的MFCC相比,CQCC是一种时频分析方法,可以提供时间分辨率和频率分辨率,其在低频段的频率分辨率高,在高频段的时间分辨高,可以有效检测合成语言。线性频率倒谱系数(Linear Frequency Cepstral Coefficient,LFCC)[11]首先通过计算信号短时傅里叶变换(Short Time Fourier Transform,STFT)的幅度谱,然后取对数并使用线性间隔的三角滤波器,最后进行倒谱变换得到,该系数由于出色的性能,常作为合成语音检测的前端特征。
高斯混合模型 (Gaussian Mixture Models,GMM)[12]由于训练速度快、使用广泛,被用作ASVspoof2019的基线系统,在合成语音检测任务中,利用GMM分别拟合真实语音和合成语音2个模型。ConvLSTM[13]提出的目的是为了解决降水临近预报问题,将长短期记忆(Long Short-Term Memory,LSTM)公式中的Hadamard乘法改为卷积,不仅可以像LSTM一样建立时序关系,而且也可以像卷积网络一样刻画局部特征,其在获取时空关系上比LSTM有更好的效果。LSTM[14]网络通过在记忆单元中引入细胞状态保存长期的记忆信息,并利用门结构自适应地保留与遗忘细胞中有用和无用的状态信息,解决了循环神经网络长期依赖的问题。CNN[15]作为目前主流的神经网络,在图像识别和语音识别领域有着广泛应用。一般,随着网络层级的加深,模型的精度会不断提升,但与此同时梯度消失或梯度爆炸的问题愈加明显,网络甚至出现了退化。残差网络[8]的出现使得这种问题得到了有效解决,在训练较深的网络同时,可以保持良好的性能。注意力机制[9]参考了人脑的信号处理机制,可以快速从全局信息中筛选出当前任务中重要的、关键的局部信息,深度学习中的注意力机制是通过分配权值来实现放大关键信息和抑制低价值信息,可以任意地插入到模型中以提升实验表现。
2 实验原理
2.1 特征设计
特征提取流程如图1所示。
首先,对语音信号S进行EMD分解,得到若干个基本模式分量:
[s0,s1,…,sn]=EMD(S)。
(1)
然后,计算每个基本模式分量与原语音信号的皮尔逊相关系数:
[r0,r1,…,rn]=corrcoef[(s0,S),(s1,S),…,(sn,S)],
(2)
式中,r0,r1,…,rn分别是各模式分量与原信号的相关系数。计算加权系数:
R=|r0|+|r1|+…+|rn|,
(3)
(4)
式中,α0,α1,…,αn分别是各模式分量的权值,基本模式分量加权组合成新信号X′:
X′=α0×s0+α1×s1+…+αn×sn。
(5)
预处理包括预加重、分帧和加窗。预加重的目的是补偿高频分量的损失,提高高频分量。新信号X′经预处理后为xi(m),下标i表示分帧后的第i帧,通过快速傅里叶变换将时域数据转变为频域数据:
X(i,k)=FFT[xi(m)],
(6)
式中,k为频域中第k条谱线。对每一帧FFT后的数据计算谱线能量:
E(i,k)=|X(i,k)|2。
(7)
把每帧谱线能量谱通过梅尔滤波器,并计算在Mel滤波器中的能量:
(8)
式中,Hm(k)表示梅尔滤波器的频率响应。最后把Mel滤波器的能量取对数后计算倒谱系数:
(9)
式中,m为第m个梅尔滤波器(共M个);i为第i帧;n为DCT后的谱线。其中,傅里叶变换的点数为2 048,梅尔滤波器与逆梅尔滤波器的滤波器个数都为100,提取倒谱系数一阶、二阶差分系数共60维;最后将2种特征拼接起来构成三维特征,该特征为双通道特征作为后端分类器的输入,这样的特征相比于单个MFCC或IMFCC特征具有多样性,有利于神经网络提取到更高级的特征。
2.2 SE-Res2Net
残差块与Res2Net块的对比如图2所示。
图2(b)中,Res2Net网络通过增加多个感受野的方式来提取多尺度特征。具体来说,通过使用更小的滤波器组来代替图2(a)中的3×3滤波器,并且这些滤波器以残差分层的结构连接,以捕获全局以及局部特征。主卷积块部分在通过1×1卷积后,将特征沿通道方向均匀的分割成特征子集xi(i=1,2,…,m),其中m是总的分割子集数,特征子集和原特征具有相同的空间大小,除了特征子集x1,其余子集都会经过一个3×3卷积;除了特征子集x1和x2,其余特征子集xi都会先加上上一个经过3×3卷积后的yi-1后再进行3×3卷积,Ki表示第i个卷积核,上述过程可以表述为:
(10)
将yi拼接后通过1×1卷积来融合不同尺度的特征信息,最终得到具有不同感受野组合的特征信息。
在网络的参数量方面,假设输入输出特征的通道数分别是I_C和O_C,对于图2(a),其参数量为3×3×I_C×O_C,即9×I_C×O_C;对于图2(b),其参数量为(I_C/s)×(O_C/s)×9×(s-1),显然Res2Net具有更少的参数量。
2.3 后端分类器
将Res2Net和SENet组合后如图3所示,本文将该SE-Res2Net模块堆叠组成后端分类器,后端分类器网络图如图4所示。
SENet采用了特征重标定的策略,通过学习的方式自动获取每个特征通道的重要程度。相比于单独使用Res2Net,嵌入SENet使网络具有更多的非线性,可以更好地拟合特征通道间的相关性。目前主流的网络结构都是基于图3的方式叠加构造产生的,例如SE-BN-Inception,SE-ResNet以及本文中的SE-Res2Net等。
文献[16]证实了SENet模块的确可以给网络带来性能上的增益。

图4 后端分类器Fig.4 Back-end classifier
3 实验与结果分析
3.1 模型评价指标
在合成语音检测系统中,错误接受率(False Acceptance Rate,FAR)和错误拒绝率(False Rejection Rate,FRR)是2个重要的指标,其中FAR表示模型错误接受合成语音的概率,FRR表示模型错误拒绝真实语音的概率。EER是FAR与FRR相等时对应的错误概率,即:
EER=FAR(θ)=FRR(θ),
(11)
式中,θ为FAR与FRR相等时模型的阈值。ASVspoof2019大赛还使用了最小t-DCF衡量整个模型的性能,t-DCF的计算如下:
(12)
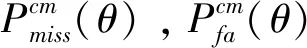
3.2 基于EMD分解的双通道特征验证
实验采用的数据集是ASVspoof2019大赛的逻辑访问数据集,具体如表1所示。
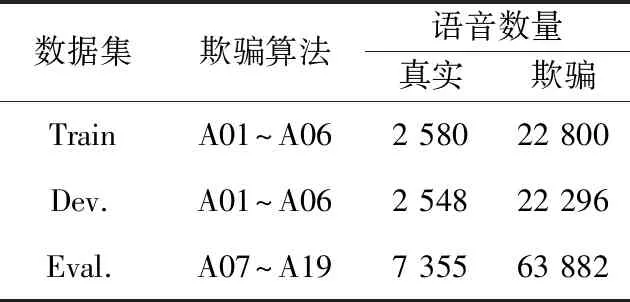
表1 ASVspoof2019 LA数据集
Train,Dev.,Eval.分别表示训练集、开发集和评估集。
前期搭建了Conv+ConvLSTM+FC(CCLSTM)和Conv+LSTM+FC(CRNN)两个小型网络结构来验证基于EMD分解的MFCC+IMFCC双通道特征的有效性,具体网络结构如图5所示。

(a) CCLSTM
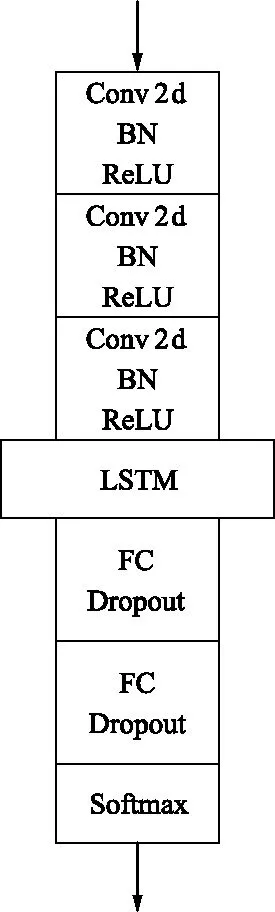
(b) CRNN
学习率为0.001,批次为32,共训练100个周期,训练完毕后分别在开发集和测试集上获得2项指标。实验结果如表2和表3所示。
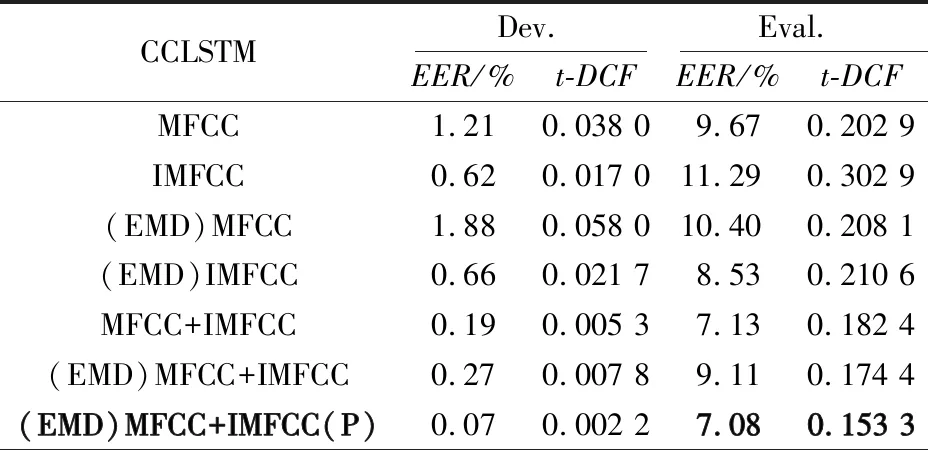
表2 不同特征在CCLSTM模型上开发集与评估集的EER与t-DCF

表3 不同特征在CRNN模型上开发集与评估集的EER与t-DCF
使用相同的网络模型,基于EMD分解的MFCC+IMFCC双通道特征效果相比于其他6种有一定的提升。与MFCC特征的结果相比,CCLSTM模型和CRNN模型在评估集上的EER指标分别降低了27%和32%,t-DCF指标分别降低了24%和6%。与IMFCC特征的结果相比,CCLSTM模型和CRNN模型在评估集上的EER指标分别降低了37%和37%,t-DCF指标分别降低了49%和23%。(EMD)MFCC+IMFCC特征是将信号进行EMD分解后将模态分量直接叠加后产生的特征,(EMD)MFCC+IMFCC(P)和(EMD)MFCC+IMFCC相比,在2个模型的评估集上的2个指标都有一定的提升,证明了对模态分量计算皮尔逊相关系数再进行权值相加产生的特征更适合合成语音检测任务。可见该双通道特征是具有实用价值的。
3.3 融合实验与结果分析
倒谱处理在压缩数据量的同时,也造成了数据丢失,导致双通道特征难以继续提升。从实验结果来看,基于EMD的双通道特征对实验的2个指标的提升趋近于极限,要想进一步提升实验效果,进行多特征融合[17]是一个方向。
除了双通道特征外,本文还引入了LFCC,CQCC和梅尔频谱(Mel Frequency Analysis,FBank)进行融合,4种特征的维度如表4所示。

表4 不同特征与维度
使用如图4所示的后端分类器,单个模型结果如表5所示。可以看出,LFCC提升最大,直接验证了LFCC适合合成语音检测任务。与基线系统相比,LFCC在评估集上的EER和t-DCF分别降低了41%和59%。基于EMD分解的双通道特征与基线系统相比,在评估集上的EER和t-DCF分别降低了29%和41%。接下来选择表5中的结果融合,首先归一化各个模型的打分结果再进行等均值融合,最终的融合结果与其他文献提出的Model1[8],Model2[18],Model3[19]以及ASVspoof 2019基线系统的CQCC++GMM和LFCC+6MM进行对比,结果如表6所示。

表5 不同特征在SE-Res2Net上的EER与t-DCF
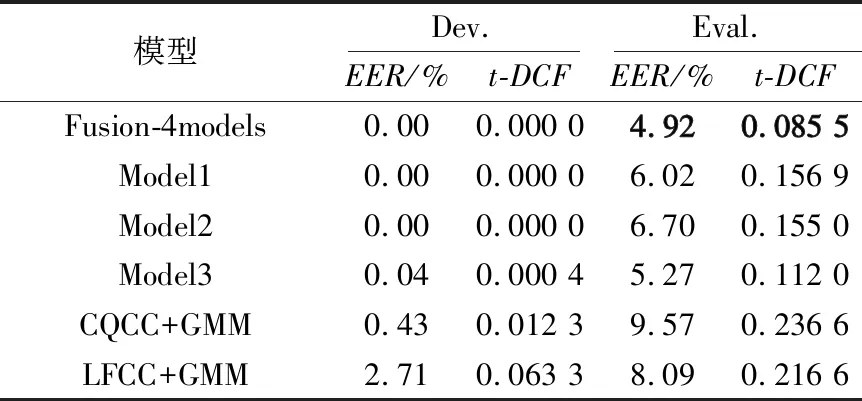
表6 融合模型的EER与t-DCF
Model1使用MFCC,CQCC和对数短时频谱特征,后端分类器使用了残差网络;Model2使用了CQCC,MFCC和短时傅里叶变换对数谱特征,后端分类器使用了SENet和扩张残差网络;Model3则使用了MFCC,IMFCC和LFCC特征,后端分类器使用了残差网络和GMM模型。相比于这3种模型,本文使用的模型效果更好。由表6可以看出,与表5中单个特征在评估集上的结果相比,融合后模型的EER与t-DCF两项指标都有着较明显提升,与基线系统CQCC+GMM相比,融合结果的评估集上的EER与t-DCF分别降低了约49%和64%。与基线系统LFCC+GMM相比,融合结果的评估集上的EER与t-DCF分别降低了约39%和61%。
4 结论
在前端特征提取上,本文设计了基于EMD分解的MFCC+IMFCC的双通道特征,实验表明,该双通道特征模型效果比MFCC和IMFCC好;在后端分类器上,采用了SE-Res2Net网络;最后将不同模型的打分结果进行了等均值融合来权衡不同模型的优缺点,进一步提升模型性能。本文选取的前端特征和后端分类器单一,并且没有验证模型对重放语音的有效性,后续工作会选取更多的特征和分类器进行实验,进一步提升合成语音检测系统的泛化性能。
