文档知识图谱构建及智能检索
2022-09-07卢卓君
卢卓君
(湖南省交通规划勘察设计院有限公司 湖南 长沙 410008)
0 引言
随着互联网的发展,文档数量急剧增加。但文档间存在着关联性较弱,查找不便,知识管理难的问题。此外,文档数据和其他数据相互隔离,而无法融合其他知识库的知识。另外,传统的文档数据维度单一,进行文档检索时,除了文本内容外,可利用的其他信息很少。如何从海量文档中快速、准确地检索出想要的文档已成为国内外研究的热点。
基于语义网,Google于2012年提出了知识图谱[1]的概念。它是一种以语义网络图来描述知识和构建各种事物之间关联关系的技术方法,基本组成单位为<实体,关系,实体>三元组以及<实体、属性、属性值>对。因其强大的知识语义处理和组织能力,知识图谱成为语义搜索、智能推荐[2]、大数据分析[3]等领域的研究热点。其构建过程见图1。
知识抽取:从非结构化和半结构化的数据中抽取出实体、关系和属性等结构化信息,并形成本体化的知识表达。
知识融合:将从不同来源得到的同一实体或概念的描述信息融合起来[4],形成全局统一的知识标识和关联。
知识加工:主要包括本体构建、质量评估等。通过构建本体能够层次清晰地描述知识库的概念层次体系。质量评估则是对知识图谱知识进行置信度评估,从而保证知识图谱总体质量。
本文以文档为出发点,构建文档知识图谱,通过图谱方式表达知识与实体及实体与实体间的关联关系,解决了文档间相互孤立、不规范、零散性等问题。为提高检索性能,设计了基于文档知识图谱的智能检索模型(Document Knowledge Graph Intelligent Retrieval,DKGIR)。
1 文档知识图谱构建
文档知识图谱构建是本文的核心方法之一,具体流程见图2。本文开发了统一的文档适配器模块;采用BERT-BiLSTM-CRF等技术进行关键词、实体、关系等知识的抽取;通过实体链接等技术进行本体融合和实体对齐,进而达到与业务知识图谱进行融合,最终形成融合的知识图谱。
1.1 知识建模
本文采用自顶向下的方式构建模式层,模式层定义了文档实体、属性以及实体间的关系,见表1、表2;采用自底向上的方式通过文档适配、知识抽取、知识融合等环节构建数据层。

表1 实体类型与属性

表2 三元组关系(
1.2 文档适配
文档类型多种多样,本文基于Python搭建了文档适配器模块,对常用的文档类型进行了针对性解析,并支持扩展其他类型的文档解析。
1.3 知识抽取
(1)本文对于不同类型文档的标题和正文,制定了不同的抽取策略,见表3。

表3 不同文档类型的标题和正文的抽取策略
组合规则如下。
①目录提取:规则1,匹配目录的开头字符“目录”;规则2,根据换行符或特征字符n个“.”提取目录中的标题,根据标题命名规律提取标题等级;规则3,根据特征字符“.”或规则2提取的第一个标题匹配目录的结尾,去除文本中目录部分;规则4,根据规则2提取的标题到剩下的正文中匹配相应的标题和其对应的正文,若没有匹配到目录则转②。
②根据标题的命名规律制定了标题提取模板,其正则表达式为:“[0-9.]{2,}|[第一二三四五六七八九十0-9篇章节:]{2,}”,剩下的工作与①同,并根据特征字符“.”出现的次数区分标题的等级,若没有提取出标题则转③。
③按换行符对文本进行切分,并将所有切片文段作为正文。
(2)对于关键词抽取,首先对文本分词后选择词性为名词、动词的词,然后计算词的TF-IDF值,选择高于阈值的作为关键词。
(3)实体抽取的方法包括基于规则的方法、基于统计学习的方法,基于神经网络的方法。本文基于BIO标注法,采用BERT-BiLSTM-CRF模型进行实体抽取。该模型见图3。
(4)知识抽取后,依据不同的关系类别对知识按照三元组的方式进行分类保存,并将实体和关系导入到orientdb图数据库中。
1.4 知识融合与存储
知识融合包括本体融合、实体对齐和知识合并等。针对本体融合,采用编辑距离的方法;针对实体对齐,采用实体链接技术,在记录链接时采用余弦相似度;针对知识加工,主要基于模式层进行本体的构建,利用orientdb图数据进行知识存储。为了提高检索速度,针对不同的场景建立了不同的索引机制,见表4。

表4 索引类型与场景
其中e1、e2为实体。
2 文档智能检索方案
本文基于知识图谱,利用实体信息,借助word2vec等技术,通过对查询项进行扩展、对查询意图进行解析等方式,提出了基于实体和关键词增强表示的DKGIR模型,实现了文档的智能检索,达到了更好、更快地为用户检索并提供更精准、更有效的检索结果。其流程图见图4。
2.1 查询意图识别
意图识别是识别用户输入的检索内容的真正意图,首先得进行意图解析,具体是指利用实体识别方法从用户输入的文本中识别出概念实体,从而得到用户输入查询和文档的实体序列表示。
2.2 实体抽取
本文利用AC自动机字符串搜索算法对用户输入进行实体识别。基于业务知识库和专业词库建立Tree实体树,对用户输入进行检索识别,识别结果可能并不唯一,比如输入“糖尿病足的治疗方案”,由于Tree实体树建立时导入了“糖尿病”和“糖尿病足”,因而两者都会被识别出来。对此,本文会对检索结果进行前缀和后缀判断,选择最长的匹配结果,即选择“糖尿病足”。
2.3 查询扩展
本文查询扩展包括关键词查询扩展和实体查询扩展。本文从知识图谱中抽取结构信息,使用Word2vec的Skipgram模型将图谱中的实体表示为空间向量形式,该模型见图5;采用余弦相似度计算查询项和扩展项的相似度,从而在知识图谱语义空间获得查询的扩展项;在寻找扩展项时,针对实体查询扩展会检测扩展项对应文档的标签数,若扩展项对应的标签数越多,说明扩展项的标签纯净度越低,检索时越易产生跨标签的检索结果,进而导致检索结果越偏离。定义标签纯净度为,见式(2)。此外,通过指定阈值来控制扩展项的质量以缓解语义漂移现象。
其中lables为扩展项对应的标签数。
2.4 文档检索
文档检索分为基于实体及其扩展的检索和基于关键词及其扩展的检索。
2.4.1 基于实体及其扩展的检索
首先遍历文档集,对于每篇文档,统计实体的频次及实体出现的文档数。其次,对实体进行扩展时,去除相似度低于阈值的实体,保留实体的相似度以及统计扩展实体的标签数。
2.4.2 基于关键词及其扩展的检索
检索内容中非实体部分称为关键词,比如“糖尿病足的治疗方案”,“糖尿病足”为实体,“治疗方案”为关键词。在关键词扩展时只保留大于阈值的扩展关键词。
本文基于1.4小节的索引机制查询相关文档。此外,本文对于文档不同部分的特征,针对关键词查询和实体查询赋予了不同权重,见表5。

表5 文档不同部分特征对于关键词查询和实体查询的权重
为度量查询实体和文档实体的类型信息,本文会在实体词频统计时考虑类型是否匹配。计算查询实体出现在文档dj的次数,如式(3)所示。
其中path为label间的最短路径长度,长度越短,说明label越相关,对应实体的相关度也越高。
实体的文档权重与共享的文档数量负相关,因此引入实体的文档权重项f(·),如式(5)所示。
其中ND表示文档集合数目,ne表示实体e出现的文档数。
因而,实体检索的特征得分函数,如式(6)所示。
2.5 排序算法
本文采用扩展项的计算方法与查询项的计算方法一致,原始检索得分与扩展项检索得分加权求和并乘以权重的方式得到最后的排序得分,公式如下:
其中代表实体的权重;a代表实体的标签纯净度,参考式(2);θ代表扩展实体的相似度,参考式(1);w为查询权重,k的取值为特征数,特征和查询权重见表5;g(e)参考式(6);Ⅱ为指示函数,判断查询项是否在文档对应的标题、关键词或正文里。
3 实验与评估
本文使用数据集Explicit Semantic Ranking(本文简称ESR,http://boston.lti.cs.cmu.edu/appendices/WWW2016/)作为基准数据集。
本文采用NDCG@k和Precision@k两项信息检索中常用的评价指标来评估本文提出的模型的性能,实验中k取20。
本文主要对滑动窗口大小size、实体权重、标题、关键词、正文的查询权重进行调参,使用网格搜索和5-折交叉验证的方式进行参数调优,选择最大化NDCG@20的参数值,最终各个参数的设置见表6。

表6 各参数设置
本文选取BM25模型、查询似然模型(Query Likehood Model,QL)[5]作为基准模型,实验结果见表7。由表6可知,在NDCG@20和Precision@20这两项指标上,本文提出的模型优于两个基准模型。出现上述结果的原因,一则在于本文提出的方法充分利用了文档知识图谱的强大语义表征能力及文档图谱的互联和依赖关系;二则在于充分利用了关键词、查询实体间的依赖关系及扩展项,扩展项基于知识图谱直接编码了整个图谱上的关系信息,能有效过滤实体表示学习中的噪声信息,缓解了查询不匹配及信息不完整等问题,且在查询的过程中充分考虑了实体的标签,标签的纯净度及实体标签之间的关联度等信息,能够捕捉更丰富的语义信息,使得相关度高的文档排名更靠前,而另外两种模型并未考虑,这也充分说明了本文提出模型的有效性。
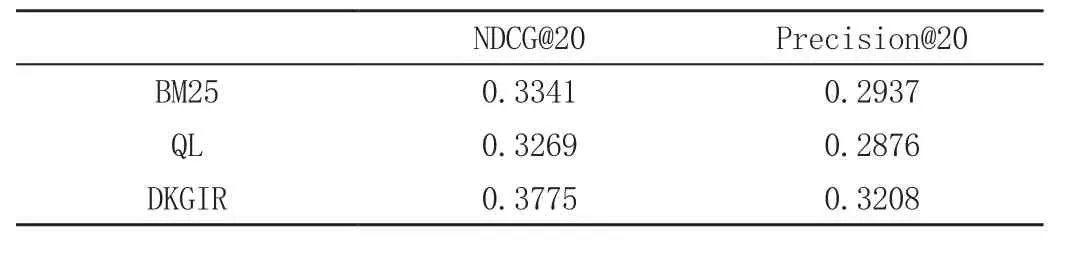
表7 实验结果
4 结语
随着网络的普及,如何从海量的文档中快速、准确地检索出想要的文档是近年来的热门研究。本文基于知识图谱技术,提出了构建文档知识图谱的方法,并在此基础上,充分考虑了关键词、实体、实体间关联关系、依赖关系、实体的标签信息等因素,对关键词和实体在知识图谱上进行语义扩展,并结合文档本身的结构特征,提出了基于文档知识图谱的智能检索模型DKGIR模型。并在公开数据集ESR上进行了对比实验,实验证明本文提出的模型对于文档检索具有有效性,对文档检索具有一定的实用价值。
