机器学习视域下新兴技术主题识别研究
——基于技术特征相似性
2022-09-01宋博文栾春娟梁丹妮
宋博文 栾春娟,2 梁丹妮
(1.大连理工大学人文与社会科学学部,辽宁 大连 116024;2.大连理工大学知识产权学院,辽宁 盘锦 124221)
随着新一轮科技革命和产业变革的加速兴起,世界性的科技竞争愈演愈烈,深化对技术创新的理解,加强对未来趋势的把控,对我国加速实施创新驱动战略部署以及创新体系建设至关重要。习近平总书记多次强调要将“因势而谋、应势而动、顺势而为”作为把握工作切入点和着力点的关键。在科技发展的历程中,新兴技术是未来科技的“萌芽”,新兴技术主题则反映出科技创新的趋势及方向。因此,高效且准确地挖掘新兴技术主题,对国家科技产业前瞻性布局以及企业发展态势的预见具有重要意义。
从定义上看,新兴技术是建立在科学基础上的革新,可能建立一个新行业或改造某个旧行业[1]。新兴技术主题与新兴技术由于名称相似,在研究中常被混淆,但两者在概念和特征上都存在显著的差异。依照Reardon S等提出的观点[2-4],新兴技术与新兴技术主题之间的差异一般归纳为3种:①新兴技术主题是对新颖特征的归纳,代表一类新兴技术;②新兴技术主题清晰明确,不存在新兴技术的模糊性与不确定特征;③不同于新兴技术的突显,新兴技术主题的凝练需要时间的积累,主题形成后会引导后续技术的发展。结合已有观点,本研究将新兴技术主题定义为能够概括归纳一段时期内新兴技术中具有新颖性的共性特征的关键词或短语。
从主题的产生路径上看,新概念的形成既包括颠覆式创新模式下新涌现的技术属性,也包括延续性发展模式下新的技术突破、性能提升与应用拓展。过往研究中,新兴技术主题的识别研究主要集中于对新技术名词或术语的探索,常采用时序分析、引文分析以及指标分析等方法对新近出现的关键词进行挖掘。然而,分析方法对探知应用方式改变或技术领域变迁等情况下的新兴技术主题缺乏敏感性,直接影响最终的识别结果。
综上,本研究针对发展模式变化带来的潜在新兴技术主题,提出一种基于技术特征相似性的新兴技术主题识别方法,尝试通过Word2Vec词嵌入模型对现有技术特征进行建模,在充分识别现有技术特征的基础上,采用K-means聚类分析与技术特征向量模型相融合的方式,构建基于技术特征相似性的新兴技术主题识别模型。在对新兴技术术语挖掘的同时,实现对潜在语义关系的探测,提升结果的解释性和准确性。
1 相关研究概述
新兴技术主题识别研究的目的在于挖掘技术发展过程中正在形成或已经形成但正发生转变的技术主题信息。研究者常采用专利、文献以及专家意见等作为数据源,挖掘其中潜在新兴技术主题信息,根据研究方法的区别可大致分为两类[5]:科学计量学方法与文本挖掘方法。
1.1 科学计量学方法
科学计量学方法是以专利、文献、新闻等文本的外部特征作为研究对象,采用数理统计来描述、分析、预测技术的现状与发展趋势,主要包括引文分析、共被引分析、知识图谱可视化、趋势分析等。2002年,Kleinberg J提出利用词频突显识别新兴趋势,通过识别某种主题词或关键词在短时间内的快速变化来进行新兴主题的识别[6]。2004年,Chen C M在Kleinberg J的研究的基础上[7],提出运用渐进知识领域可视化的方式识别新兴主题,并开发了Citespace文献计量学可视化软件,被广泛应用于文献计量学的研究当中。2011年Järvenpää H M等考虑到以往的研究多采用单一的数据,不能够全面认识新兴技术主题的发展,于是他在研究中通过技术生命周期曲线分别描述了文献、专利以及社会媒体在主题发展过程中的数量变化,并对这三者间的关系进行了阐释[8]。2012年,Abercrombie R K等利用文献、专利、网络信息、新闻等多方面数据构建新兴技术演进模型(TEM)[9],该模型将新兴技术主题的演进过程分为9个里程碑式的标记点,更大程度上从技术角度分析了新兴技术主题的变化过程。近年来,新兴技术主题研究指标不断丰富,研究内容也呈现多元化特点。
1.2 文本挖掘方法
随着机器学习的快速兴起,基于专利内容的文本挖掘法成为更高效的技术主题识别途径。黄鲁成等以精密技术为例[10],利用SAO(Subject—Action—Object)语义结构间的相似性挖掘新兴技术主题。Chen L F等提出动态隐含狄利克雷分布模型(Latent Dirichlet Allocation,LDA)[11],实现对新兴趋势时序性变化的动态监测。刘自强等以基因编辑技术为例[12],通过PWLR模型抽取更具新颖性与时效性的技术趋势。Kreuchauff F等以服务机器人为例[13],结合机器学习与SVM模型分析新兴领域信息。Hassan S U等利用64维指标的样本数据[14],提出结合引文分析与深度学习的新兴主题识别模型。研究者将全部重心集中在对新兴词汇的发现与探测上,不断对新兴技术新颖性特征的识别机制进行完善,忽略了对新兴特征内部信息的探索,新兴技术主题不仅是领域内出现的新技术术语,也是对新近技术结构、特征、用途等发生转变的一系列技术动态的概括。
因此,为获得明确清晰的技术主题,本研究首先剔除数据中噪音信息,选择具有代表性的技术特征信息;其次,为保证主题中不仅涵盖新兴词语还包含特征及用途转变,选用Word2vec模型对领域中全部现有技术特征进行训练;第三,为保证主题词具有代表性,先通过机器学习模型加权新近技术特征,再利用K-means聚类对不同属性技术主题加以区分,并结合专家意见调整模型参数,提炼新兴技术主题;最后,以生物技术领域为研究目标挖掘新兴技术主题,并与其他模型的识别结果进行比对,从而帮助完善新兴技术主题识别理论,同时为我国生物技术领域的前沿技术发展提供决策支持。
2 新兴技术主题识别模型构建
新兴技术主题识别不仅是对新技术术语的挖掘,也是对创新路径中潜在技术结构与知识组合的探索。因此,识别模型需要兼顾全面性与差异性,在对技术特征的选取上尽可能保证结果中新颖性信息的全面性,在技术主题的识别上最大程度地提升识别结果中新兴技术主题与已有技术主题间的差异性。
针对已有研究的不足,本研究综合运用自然语言处理、机器学习以及文本挖掘,提出一套基于技术特征相似性的新兴技术主题识别方法,如图1所示。具体分析过程包括4个模块:①特征抽取与预处理;②机器学习模型训练;③技术特征聚类分析;④技术主题提取与识别,如图1所示。首先,检索收集相关专利,并通过特征工程提取专利数据中的专利标题、新颖性、专利用途、专利优势信息构建技术特征集;其次,利用Word2Vec词嵌入模型对技术特征集进行训练;第三,根据时间切片区分新近涌现技术成果,并利用预训练模型对新近涌现技术成果进行技术特征向量化处理,再通过K-means聚类进行特征区分;最后,根据聚类结果获取技术关键词,将识别结果交给相关领域专家小组,通过专家意见判断聚类结果是否收敛,结合专家知识明确最终识别结果。
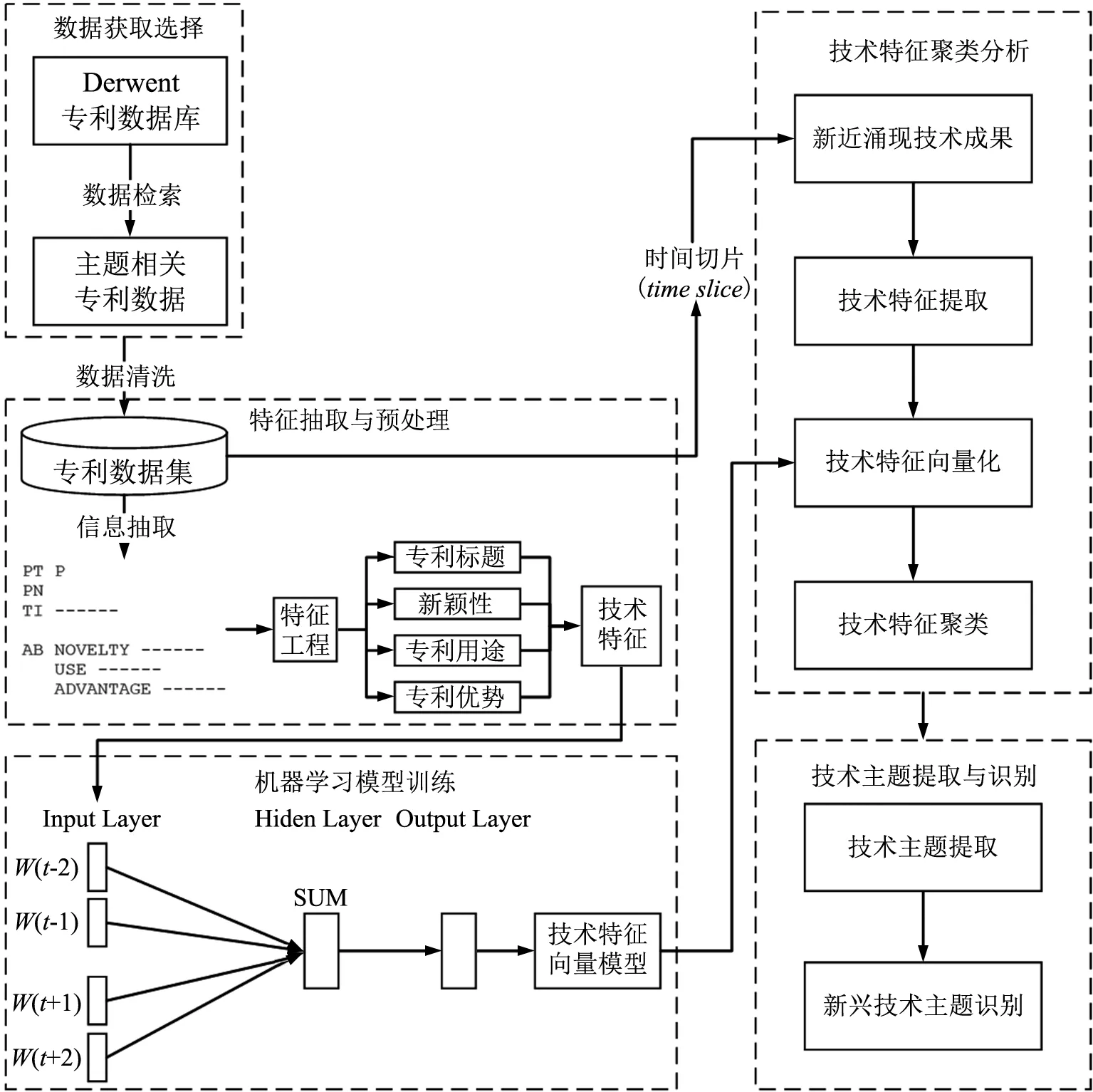
图1 新兴技术主题识别模型
2.1 特征工程与预处理
特征工程的目的在于最大程度地从原始数据中抽取有价值的技术特征信息,以满足模型及算法的需求,抽取结果直接决定着机器学习模型的效率与效果。每条德温特专利数据中都包含发明号(PN)、专利标题(TI)、发明人信息(AU)、专利权人信息或代码(AE)、德温特主入藏号(GA)、摘要(AB)、德温特分类代码(DC)、手工代码(MC)以及国际分类号(IP)等字段。其中,专利标题由德温特编辑团队的主题专家编写,目的是揭示专利的发明内容及其新颖性;专利摘要中包含新颖性、用途及优势3个部分的内容,分别概括了专利的应用背景、技术目的以及所属领域,技术性能的优化提升状况等信息,如表1所示。其中,专利标题项目中包括新的技术术语与应用途径;新颖性项目与用途项目中详细解读专利中的新术语、技术结构、特征及用途;优势项目对技术性能的提升程度进行说明。这4个部分著录项目包含不同创新路径下的新兴技术主题,能够准确全面地反映创新技术特征[15]。因此,本研究通过自然语言处理工具提取专利数据文本中的专利标题及摘要信息中的新颖性、用途以及优势4个字段,作为技术特征的来源。
在确定特征内容后,利用Python自然语言处理工具包NLTK(Natural Language Toolkit)对德温特专利数据进行处理。应用NLTK工具包提取专利文本中标题(TI)、新颖性(NOVELTY)、用途(USE)以及优势(ADVANTAGE)4个字段中的文本信息,剔除专利文本中的低频词、停用词、无关词汇,通过词形还原整理文章中的技术名词及相关应用信息,最终获得规范化的技术特征信息。
2.2 Word2Vec词嵌入模型
“现有技术”是衡量发明创造是否具有新兴特征的客观参照物[16]。本研究采用机器学习的目的在于通过对大量现有技术特征中语义知识的识别训练,实现对目标领域中全部技术关键词的整体把控,将每一个技术关键词及其之间的关系构建成一个词向量模型[17-18],从而成为客观区分新颖性特征的参照物。

表1 技术特征字段及含义
Word2Vec词嵌入模型是由Mikolov T等提出的轻量级的神经网络语言训练模型[19],模型结构主要包含输入层、隐藏层以及输出层。相较于传统独热表示模型(One-Hot Representation)不包含语义关系测度的词语符号化功能,Word2vec能够通过训练文本中的词语,将其映射为低维度的实数向量,构成一个词向量空间,进一步实现了对词语之间语法、语义关系的相似性测度[20],极大地满足了对新兴技术主题识别中准确区分不同特征的要求。
Word2Vec模型主要包括CBOW和Skip-gram两个模型[21],如图2所示。CBOW模型是在学习词语W(t)的前后语序W(t-2)、W(t-1)、W(t+1)、W(t+2)的条件下,对W(t)的语义语法关系进行预测;Skip-gram与之相反,是在明确W(t)的语义关系的前提下,预测W(t)的前后语序内容。本研究考虑到所选技术特征信息的内容与规模,采用Word2Vec模型中的CBOW作为技术特征的训练模型。
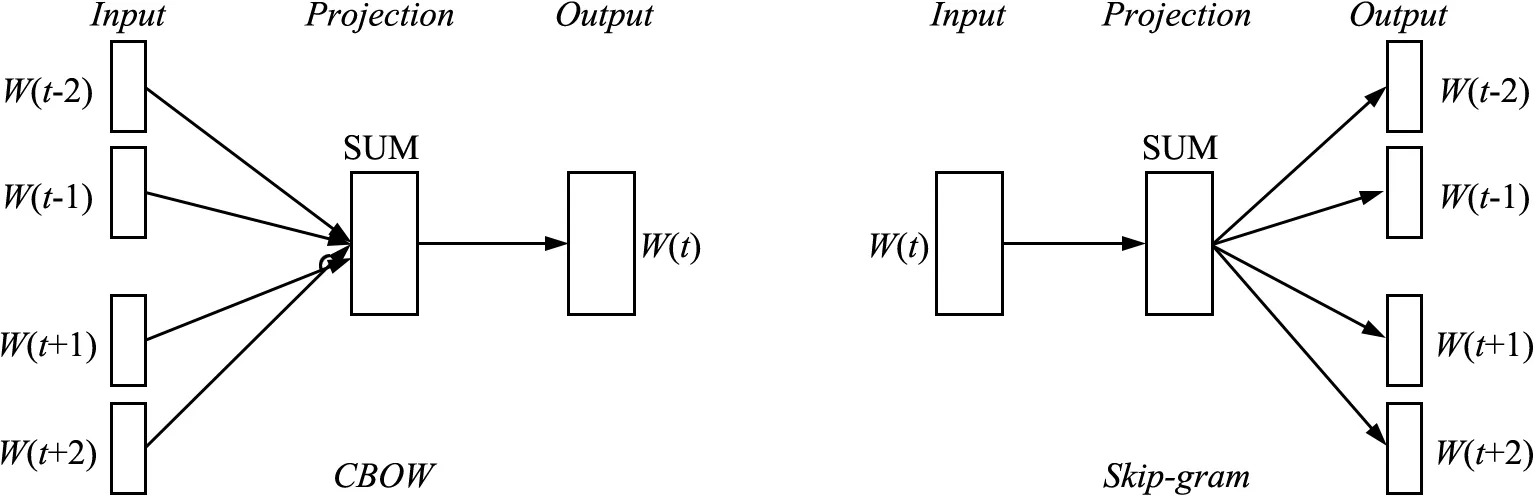
图2 CBOW与Skip-gram模型对比
2.3 技术特征聚类分析
技术特征聚类结果直接影响新兴技术主题识别的准确性。考虑到新兴技术主题既产生自新技术发展过程的快速兴起,也来源于技术开发过程中应用环境的转变[22],聚类算法必须在满足对非结构化数据聚类的同时,凝聚表达相同属性的技术特征。因此,本研究采用“技术特征向量化+特征聚类”的方式实现对不同属性技术特征的区分。
2.3.1 新近涌现技术特征提取
新兴技术主题主要来自新近出现的专利数据中,Porter团队从专利运营数据发现,新兴技术主题的形成需要历经技术自身完善、配套技术发展、市场商业认可等多个阶段,这一过程大致需要3~5年时间[23-25]。因此,检索数据库中近3年目标主题相关的专利数据,按照特征工程流程进行数据处理,提取其中所包含的新近涌现的技术特征。
2.3.2 技术特征向量化
技术特征向量化是对每条专利信息中所包含的技术特征进行向量化处理的过程,利用前述机器学习得到的词向量模型,对每条技术特征中的全部词语取加权均值,从而生成新近技术特征的句向量。
首先,本研究采用TF-IDF(Term Frequency-Inverse Document Frequency,词频逆文档频率)算法测度技术特征中每个词语的权重,用以凸显代表性术语在技术特征中的重要程度。词语权重随其在技术特征中的出现频率呈正比增加,随词袋模型中的出现频率呈反比下降,计算公式如式(1)。其中,ni,j通过词频矩阵计算,表示词语在文本中出现的频次;∑knk,j表示词袋模型中所有词语数量;|D|表示技术特征数量,|j:ti∈dj|表示包含词语的技术特征数量。
(1)
(2)
然后,对技术特征中的全部词语向量取加权均值,结合前述中获得的词语权重,生成技术特征向量,计算公式如式(2)。其中,TC_vec表示技术特征向量;veci表示词向量;m表示技术特征中包含的词语的数量;weight(i)表示通过TF-IDF算法获得的词语的权重。
2.3.3 技术特征聚类
技术特征聚类是将向量化的技术特征集合划分成若干簇,尽可能聚集表达相似属性的特征,扩大不同簇类间的差异性。因此,本研究采用K-means算法实现这一过程[26],算法将通过不断迭代和反复计算聚类中心直至聚类结果收敛,从而实现对表达相近含义技术特征信息的集合。
(3)
(4)
将2.3.2获得的技术特征进行K-means聚类,多维向量空间中技术特征间的相似性关系采用余弦相似度进行测度,计算公式如式(3)。K值的选择采用轮廓系数法,计算公式如式(4)所示。其中,ai表示i特征与同类型技术特征的平均距离;bi表示i特征与其他类型技术特征间的平均距离;Si表示轮廓系数,轮廓系数的取值在[-1,1]之间,且越趋近于1表示聚类的结果越清晰。通过对聚类系数K值的反复调整,选取轮廓系数最大时所对应的最优聚类系数。然后,采用该聚类系数对新近涌现技术特征进行聚类,最终得到不同类别的技术特征。
2.4 技术主题提取与识别
技术主题的提取与识别方法决定着主题识别模型最终结果的合理性。常用的文本主题抽取工具包括TF-IDF模型、TextRank模型[27]、LDA主题模型以及其他融合模型等[28]。本研究采用特征关键词结合专家意见的方式来实现主题识别。聚类分析将大量具有相同属性的技术特征构成特征集,每个特征集中包含大量反应集合属性特征的关键词,通过对词语重要性进行排序,提取出具有代表性的技术特征关键词。
技术主题聚类结果在考虑算法准确性的同时也需要兼顾专业性,引入领域专家参与新兴技术主题的最终判断,提升识别结果的专业性及应用价值。轮廓系数能够在算法层面反映聚类模型的效果,在应用层面则需要后验知识对模型进行修正和检验。将识别结果交给相关领域专家小组,通过专家意见判断聚类结果是否收敛,并由专家确定最终的新兴技术主题识别结果。
3 生物技术领域新兴技术主题识别
3.1 样本选取与预处理
生物技术(Biotechnology)是引领未来经济社会发展的重要学科领域,这一概念最初是由匈牙利工程师Karl Ereky提出,其影响力随着基因工程技术等现代生物技术的发展而逐渐加深。在美国商务部联合国家科学基金会等多家机构提出的“NBIC会聚技术”理念中,生物技术被视为实现未来技术应用的核心技术领域。因此,本研究将生物技术领域作为研究的重点,选择生物技术相关专利作为新兴技术主题识别实证研究的对象。
本研究以德温特创新索引为数据源,检索并收集2010—2020年间生物技术相关专利数据作为分析数据集。德温特创新索引(Derwent Innovation Index,DII)是世界最大的专利数据库之一,数据来源包括50余家专利授予机构,数据内容涵盖全球96%的专利数据信息,能够保证数据检索的全面性与准确性。检索式选择世界经济合作与发展组织(OECD)发布的生物技术相关专利检索式:IP*=(A01H-001/00 OR A01H-004/00 OR A61K-038/00 OR A61K-039/00 OR A61K-048/00 OR C02F-003/34 OR C07G-011/00 OR C07G-013/00 OR C07G-015/00 OR C07K-004/00 OR C07K-014/00 OR C07K-016/00 OR C07K-017/00 OR C07K-019/00 OR C12M OR C12N OR C12P OR C12Q OR C12S OR G01N-027/327 OR G01N-033/(53*,54*,55*,57*,68,74,76,78,88,92))。检索结果中2011—2020年发布的专利数据共计108 585件,用以进行专利词篇模型的构建。研究中新近涌现专利数据集,选择2018—2020年生物技术相关专利数据共计36 748件。
相关专利的特征分布情况如表2所示,从时间分布来看,2011—2020年间的专利数量呈现平稳上涨趋势,年均专利数量在1万件左右,2018—2020年的年均专利数量达到12 249件。在学科分类上,排在前3位的学科分别为化学、生物学以及药学,涉及化学专业的专利数量最高为100 893件,占专利总量的92.9%。IPC分类号是国际通用的技术分类工具,从生物技术的IPC分类情况看,抗原医药制剂、抗肿瘤药物、基因治疗药物是研究的热点方向。德温特分类代码是从技术应用角度提出的技术分类工具,生物技术的应用主要涉及发酵产业、天然聚合物生产以及生物制剂3个方向。
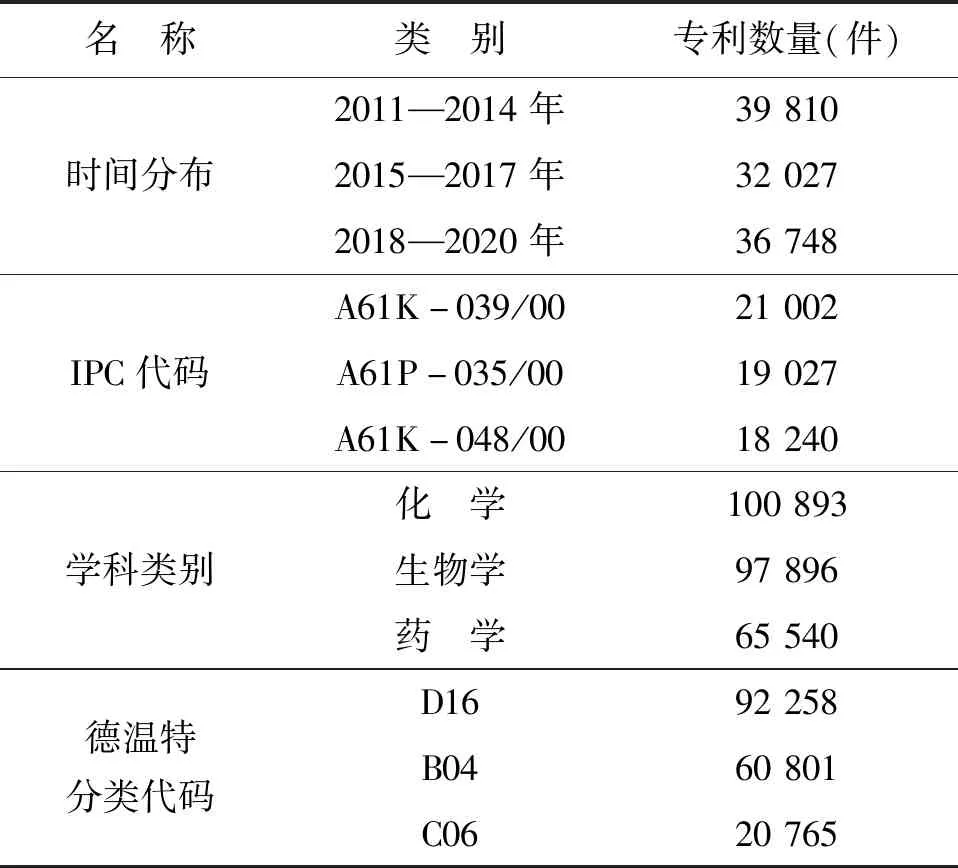
表2 生物技术专利特征统计(2011—2020年)
3.2 面向生物技术领域的新兴技术主题识别
3.2.1 技术特征模型构建
依照前述特征工程与机器学习训练模型的构建流程,首先抽取108 585条生物技术专利中的标题、新颖性、用途以及优势4个字段的数据信息;对数据进行清洗,将字段中的停用词与无关词汇去除,采用词型还原的方式处理剩余词语,构建生物技术特征集,采用相同流程处理新近涌现的36 748条生物技术专利数据,生成新近技术特征集。采用Word2Vec中的CBOW模型训练生物技术特征数据,参数设置为特征向量,维度选择默认值200;考虑到每条生物技术技术特征的词语数量不超过15,设置上下文窗口长度为7;主题词的选取需要保证所选术语的代表性,设置词频阈值为5;迭代次数选择6次,最终得到技术特征词向量模型。
3.2.2 基于技术特征的K-Means聚类
首先,将新近技术特征集中的词语转换为词频矩阵,结合前述技术特征词向量模型中的词频信息,统计新近技术特征集中词语的权重。然后,对每条技术特征中词语取加权均值,生成新近技术特征向量。再将技术特征向量进行序列化处理,计算不同特征间的余弦相似性。
完成前期数据处理后,为新近技术特征集搭建一个包含k个随机质心的集合,以新近技术特征为节点,特征间的余弦相似度作为节点距离,设定聚类系数k的取值范围[2,11]进行迭代运算。通过k值的调整观察轮廓系数的变化情况,如图3所示。当聚类系数取值为2时,轮廓系数的结果为0.1119,随着聚类系数的提升,轮廓系数不断趋近于1,取值为6时轮廓系数达到峰值的0.3558,其后随着系数增长而下降,当聚类系数取值为11时,轮廓系数为0.0513。因此根据轮廓系数评价结果,聚类系数k取值为6时,生物技术的新近技术特征分类最为清晰。
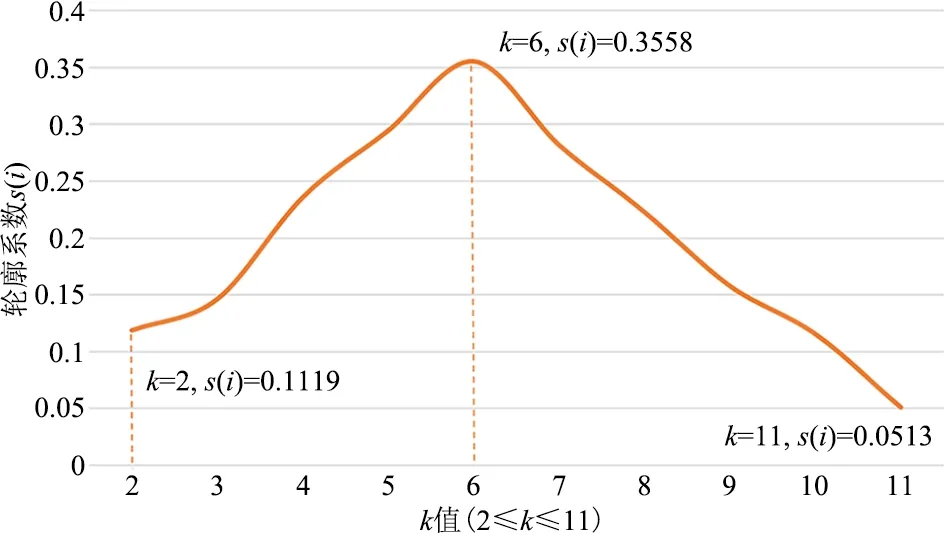
图3 K-Means聚类系数选取
3.2.3 新兴技术主题识别
根据新近技术特征的聚类结果,2018—2020年新兴生物技术可以分为6个大类,抽取每个聚类中的核心关键词信息,如表3所示。其中C1类中的技术术语主要涉及各类氨基酸制备工艺及其用途,其中包括:抗原决定基、纳米抗体、门冬氨酸、亮氨酸、苯丙氨酸、精氨酸、酪氨酸酶、组氨酸等;C2类中的技术术语主要涉及分子克隆及基因编辑技术,其中包括离心法、外显子、反义技术、DNA聚合酶、RNA干扰、核酸适配体等;C3类中的技术术语涉及免疫性疾病及病灶,其中包括超纯、免疫血清、白血病、接种体、肿瘤、感觉官能、固定化等;C4类中的技术术语涉及环境工程与废物处理技术,其中包括沉积作用、废物处理、人造物、提纯、湿地、废水、微生物、净化、厌氧菌、分解、植物等;C5类中的技术术语涉及重组疫苗及反向疫苗相关技术,其中包括淋巴细胞、载体、暗盒、激酶、病毒衣壳、白细胞介素、突变、腺病毒、芯片、免疫球蛋白、质粒、腺病毒、T细胞受体等;C6类中的技术术语涉及农作物增产抗病基因改良技术,其中包括未成熟体、孢子、吲哚、体细胞、再生、氯化物、农杆菌、土豆、短葶植物、外植体、琼脂等。

表3 生物技术相关新兴技术主题
最终的识别环节,通过两位生物技术专业教授对聚类识别结果的反复讨论,认为聚类结果已达到收敛,表述相同或相近生产工艺的技术关键词处于同一聚类。通过对技术关键词的解读分析,专家认为可根据聚类中的核心技术关键词分布情况,将上述技术关键词总结为新近兴起的6类生物技术主题:分别为氨基酸制备技术、分子生物技术、生物免疫治疗技术、生物净化/修复技术、疫苗制备技术、农业转基因技术。
3.3 对比分析与结果讨论
考虑到专家解读存在主观性,本研究引入LDA主题模型进行对比分析。将应用LDA主题模型提取新近生物技术领域专利中的技术主题结果作为对照组ETT-control,基于技术特征相似性的新兴技术主题模型的识别结果作为实验组ETT-experiment,将识别结果降维至三维空间进行可视化,并引入主题连贯性验证主题识别效果,聚类结果对比如图4所示。
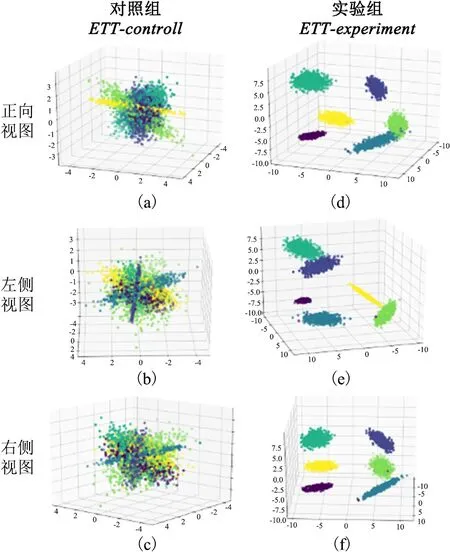
图4 新兴技术主题聚类结果对比
主题连贯性(Coherence,CV)是用于衡量同一主题内的词语间是否连贯的测量指标。本文采用Newman提出的UCI测度方法,基于滑动窗口对主题词进行分割,通过对特定主题词中所有单词对的点态互信息进行计算,得到模型的主题连贯性。主题连贯性的取值范围为[0,1],数值越接近于1说明效果越明显。通过计算,得出实验组的连贯性系数为0.512,对照组的连贯性系数为0.471。说明对于同一技术主题内的技术关键词,融合Word2Vec与K-means聚类的新兴技术主题识别模型具有更好的组内连贯性,能够更加清晰准确地反映主题信息。通过对照组与实验组在正视图、左侧视图以及右侧视图的对比,能够清晰地发现LDA主题模型提取出的5类技术主题之间存在大量的交叉,簇类之间界限模糊;相较之下,实验组提取的6类技术主题中,关键词凝聚在相应的技术主题之下,不同主题下的技术关键词之间少有重叠,簇类之间界限明显。
对比分析结果显示,融合Word2Vec与K-means聚类的新兴技术主题识别模型,相较于一般主题识别模型,能够更加准确地凝练,技术主题间的区分度更加明显。同时,由于模型中采用机器学习对大量现有技术进行训练识别,从而能够清晰区分技术特征的新颖性,能够更好地实现对领域中新兴技术主题的识别。
4 结 语
深刻认识前沿趋势,尽早识别新兴技术主题,对创新资源优化部署及提升国际竞争优势具有重要意义。当前,新兴技术主题识别大多采用单一指标或单一属性,缺乏基于多种演化路径的多维度主题挖掘分析。鉴于此,本文提出了基于技术特征相似性的新兴技术主题识别模型,模型通过抽取专利数据中包含的新技术属性构建技术特征集,并利用机器学习对现有技术特征进行建模,充分识别现有技术中的特征信息,再融合聚类分析算法与技术特征向量模型,对新近涌现技术特征进行主题识别,最后结合专家意见对新兴技术主题进行解读。以生物技术为例的主题识别结果显示,基于技术特征相似性的新兴技术主题识别模型相较于一般主题识别模型能够更加清晰准确地挖掘目标领域中的新兴技术主题。因此,本研究为新兴技术主题识别研究提供了新的研究方法及思路。
