面向高光谱图像分类的半监督双流网络
2022-08-31李政英
黄 鸿,张 臻,嵇 凌,李政英
(1.重庆大学 光电技术与系统教育部重点实验室,重庆 400044;2.中国电子科技集团公司第三十四研究所,广西 桂林 541004)
1 引 言
高光谱遥感技术利用高光谱传感器,以连续细分的波段对目标区域同时成像,获取的图像包含丰富的辐射、空间和光谱信息,广泛应用于地物分类、像元解混等研究中。高光谱遥感图像分类在土地监测、环境保护、防震减灾等领域发挥着重要的作用[1-2]。影响高光谱遥感分类精度的因素主要有两个,其一是高光谱图像波段多所导致的“维数灾难”问题,其二是光谱异质性导致的“同物异谱”“同谱异物”问题[3]。
针对“维数灾难”问题,学者们提出一系列特征提取方法以改善地物分类性能。按照是否利用样本先验信息,特征提取方法可分为无监督、监督和半监督学习3种。其中,无监督学习方法在无类别信息的前提下学习特征进行分类,如主成 分 分 析(Principle Component Analysis,PCA)[4]、邻域保持嵌入(NPE)[5]。监督学习方法利用样本的先验信息来提升分类性能,典型方法如 线 性 判 别 分 析(LDA)[6]、边 界Fisher分 析(MFA)[7]和部几何结构Fisher分析(LGSFA)[8]。高光谱图像由于标记样本困难,存在着大量未标记样本,半监督学习能够同时利用少量标记样本和大量无标记样本,取得了更好的分类性能[9],典型方法包括半监督鉴别分析(SDA)[10]、半监督局部鉴别分析(SELD)[11]、基于稀疏编码的几何子空间投影(SCGSP)[12]和监督稀疏流形鉴别分析(S3MDA)[13]。上述方法在高光谱遥感图像分类中取得了较好的分类结果,但依赖浅层特征描述子,在地物类别多且空间分布复杂时其分类性能受限[14]。
深度学习技术以其优秀的非线性映射能力,通过端到端方式从数据中分层学习高层抽象特征,有效提升了分类性能,代表方法有SAE,DBN,CNN等[15-16]。然而,深度学习参数量较大,依赖于大规模训练样本以保证模型的可靠性,且忽略了对高光谱图像中内部流形结构的探索[17]。黄鸿等提出DMRBN,将对深层特征的提取和对高光谱流形结构的探索同时考虑在内,在样本量较少时优于常用的特征提取方法和端到端模型[18]。然而高光谱图像具有空间一致性[19],该方法忽略了训练样本丰富的空间信息,不利于改善“同物异谱”“同谱异物”问题。
为了综合利用高光谱图像标记样本和大量未标记样本的局部空间信息以及光谱信息,本文提出了一种基于深度-流形学习的半监督双流网络(Semi-supervised Dual Path Network,SSDPNet),以解决“维数灾难”以及“同物异谱”“同谱异物”问题。SSDPNet以神经网络(Neural Network,NN)作为光谱流,2DCNN作为空间流,分别提取深度光谱、空间特征。为了使提取到的特征更具有鉴别性,并且综合利用大量未标记样本,在图嵌入框架下设计了一种半监督流形重构图模型,以度量标记样本之间的流形边界并保持无标记样本中的局部几何结构关系。此外,设计了基于均方误差和流形学习的联合损失函数,以优化空间流与光谱流网络,通过全连接层自适应调整两路网络权重,最后利用训练好的网络对测试像素的标签进行预测。在黑河与WHU-Hi龙口高光谱数据集上进行的实验表明,该方法有效地利用了光谱和空间信息互补的优势,在分类精度上具有明显的优势。
2 半监督双流网络
针对高光谱图像分类领域少量标记样本的高维特性,以及光谱异质性导致的“同物异谱”、“同谱异物”问题,本文综合利用大量无标记样本信息,提出了SSDPNet算法,其流程如图1所示。
图1中,x l=[x l,1,x l,2,x l,3…,x l,Nl],表示标记样本,x u=[x u,1,xu,2,x u,3…,x u,Nu],表示无标记样本,以上述样本为中心,选取11×11尺寸的图像块并经过PCA算法降维后作为空间流输入,分别 表 示 为。假 设 高 光 谱 数 据 集χ=[x1,x2,x3,…,x N],N为样本个数,每个样本包含D个光谱波段,样本标签l(x i)∈{1,2,…,c},其中c为样本类别数。

图1 SSDPNet算法流程Fig.1 Flow chart of SSDPNet algorithm
SSDPNet模型由NN,2DCNN,半监督流形重构图模型,以及自适应全连接层四部分组成。NN和2DCNN分别提取标记样本和大量未标记样本的光谱-空间信息。为了使提取到的特征具有鉴别性,在图嵌入框架下设计了一种半监督流形重构图模型,以度量标记样本之间的流形边界且保持无标记样本中的局部几何结构关系,再由全连接层自适应学习空-谱两个网络权重,得到光谱-空间联合鉴别特征,之后进行分类。
2.1 半监督流形重构图模型
半监督流形重构图模型由监督重构图M1(·)和无监督图M2(·)组成。监督重构图可学习到少量标记样本中的内蕴流形结构信息。具体来讲,首先对各样本点利用与其属于同一类别的近邻点进行重构;然后,利用同类样本点的近邻点以及各近邻点对应的重构点设计类内重构图,在特征提取空间中保持顶点间的相似性,使得类内特征更加聚集;与此同时,利用不同类别样本点的近邻点以及各近邻点对应的重构点设计类间重构图,在低维投影空间中抑制点间关系,使得类间特征更加分离。无监督图用来探究大量无标记样本中的局部几何结构信息,并在特征提取空间中保持这种关系,使得提取到的特征保持其原有的几何近邻结构。
2.1.1 面向标记样本流形结构学习的监督重构图
由于高光谱图像具有空间一致性,相邻像素大概率属于同类地物,即存在大量同质区域。通过对各样本点周围的同类近邻样本进行线性重构可减少噪声所带来的影响,同时能更好地保持同类数据间的局部线性结构。
对 于 样 本点x l,i以及 其 邻 域点x l,j,二者 之 间的重构权重R ij通过最小化重构误差获得,相应的目标函数定义如下:

为实现地物精细分析,对于从双流网络中提取到的空-谱特征,期望来自同一类的样本尽可能地接近,而来自不同类的样本尽可能地远离。为了实现该目标,在半监督流形重构图模型下设计了监督重构图,它包含一个类内重构图Gw(X,W w)和 一 个 类 间 重 构 图Gb(X,W b)。Gw(X,W w)用于描述数据中被期望保留的特性,其中X表示图的顶点,为类内图权值矩阵,用于度量样本x l,i和x l,j之间的类内相似性。若 图 中 两 个 顶 点x l,i,x l,j属 于 同 一 地 物 类别的kw个类内近邻点,则用权值为w wij的边连接二者,w wij表示了两顶点之间的相似关系,具体定义如下:
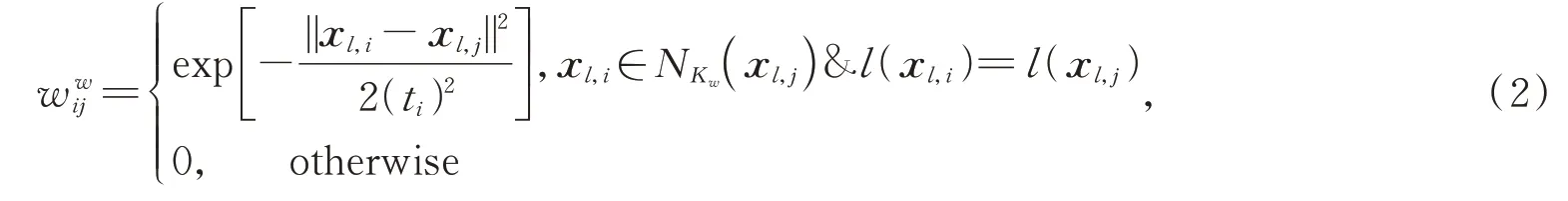
Gb则表示应该被避免的特性,X同样表示图的顶点为类间图权值矩阵,用于度量样本x l,i和x l,j之间的类间相似性。若x l,j属于x l,i的kb个类间最近邻点,则将二者用权值为的边连接,权重定义如下:
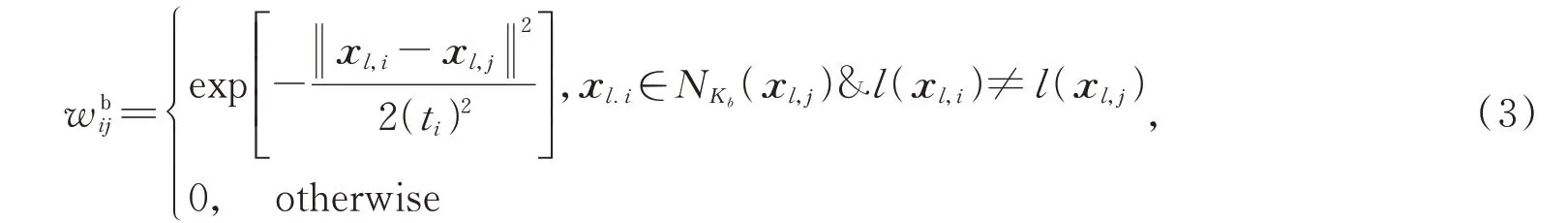
式中:x l.i∈N K b(x l,j)表示x l,j是x l.i非同类数据的K b近邻点,l(·)同样代表标记样本标签的one-hot编码向量。
为使提取到的特征具有可分性,期望类内近邻点与其相应重构点的距离越来越近,类间近邻点与其重构点的距离越来越远。因此,类内图目标函数Jw(·)和类间图目标函数Jb(·)可分别表示为:

式中M w和M b分别定义如下:

因此,监督重构图的目标函数M1(·)定义为:

2.1.2 面向未标记样本流形结构学习的无监督图
对于从双流网络中提取到无标记样本的空-谱特征,为使它在低维嵌入空间中保持其原有的几何近邻结构,在半监督流形重构图模型下设计了无监督图。无监督图利用无标记样本探索高光谱数据的局部几何邻域关系,并在网络优化过程中,由无标记样本提取到的深度特征能够保持原始样本间的结构信息。

式中:w uij由第i个和第j个训练样本之间的几何距 离 确 定,且表 示 无标记样本数。无监督图可以在深度特征中保持无标记样本间的几何近邻关系,相应的目标函数为:
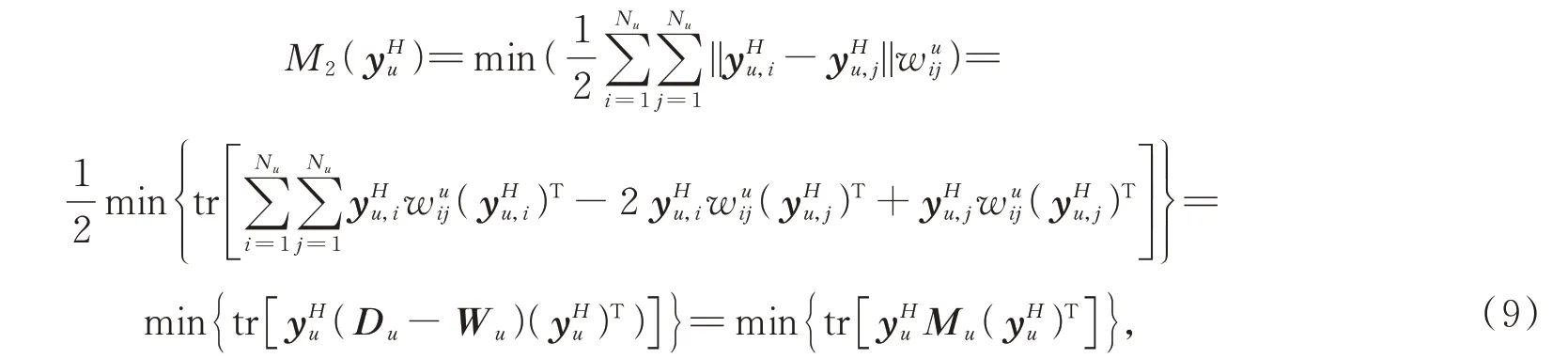
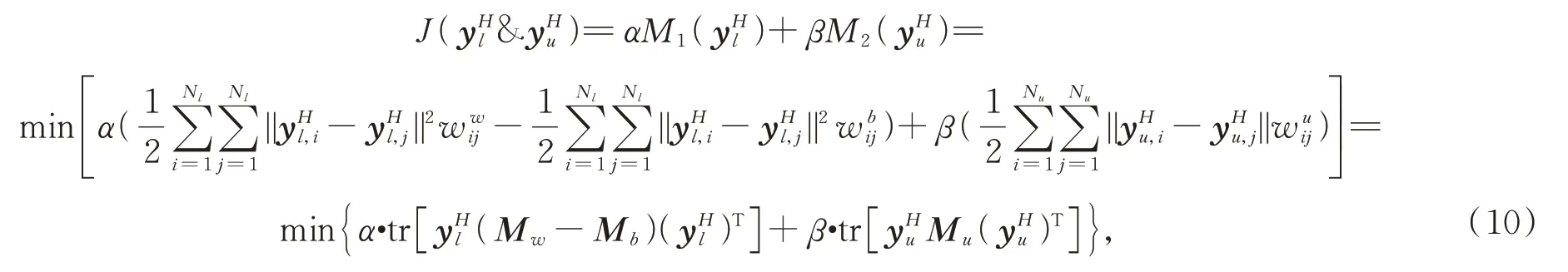
式中参数α和β用于平衡标记样本和无标记样本对模型的影响。
2.2 光谱流残差-流形协同度量
SSDPNet算法用NN作为光谱流以提取深度光谱特征。假设NN有H层,则第h层(1<h<H)第i个样本输入输出之间的代数关系为:

式中A h和b h是神经网络第h层的参数。NN同样引入均方误差损失函数来度量预测值与实际值的残差,计算如下:

SSDPNet的光谱流构造了一个协同损失函数,不仅可以计算预估结果和真实标签向量之间的差值,而且通过设计好的半监督图模型提高了提取到的深度特征的可分性,相应的损失函数表示如下:

迭代过程是网络优化的关键步骤,光谱流的迭代策略设计见式(14),并采用随机梯度下降法计算最佳的模型参数。光谱流损失函数J1关于NN第h层网络参数矩阵的梯度:

式中:
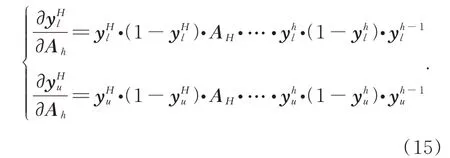
算法在训练过程中根据每一层计算得到的导数更新该层的网络参数,若η1表示光谱流学习率,则第h层的参数更新为:

2.3 空间流残差-流形协同度量与反向传播机制
本文算法采用2DCNN作为空间流提取深度局部空间特征。若输入N个图像块X Pi(1≤i≤N),则卷积后特征图的生成过程如下:

式中:表示卷积神经网络第m-1层的特征图,k m表示第m层的卷积核,b m表示偏移向量,最后通过f(·)即sig非线性激活函数得到第m层的特征图Y P,mi。
原始图像X P经过卷积层和池化层的交替传递,最后通过全连接网络得到提取出的特征,并使用均方误差作为损失函数。JC(Y P|k,b,AFc)表示为原始图像X P经过前向传导后所得输出与期望值的残差,表示为:
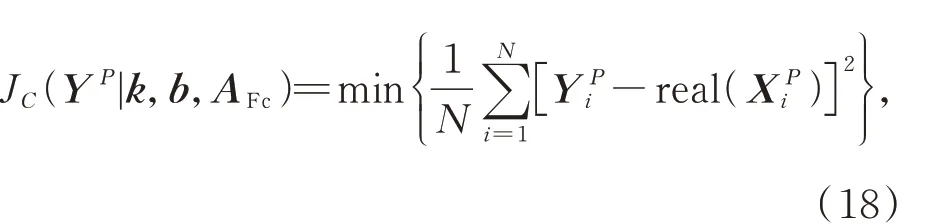
式中:AFc为全连接层权重,real(·)表示样本的真实值。为了使卷积网络提取到的局部空间特征具有鉴别性,设计了基于空间流的深度流形联合损失函数J2以协同度量卷积网络残差以及流形间距,J2表示为:
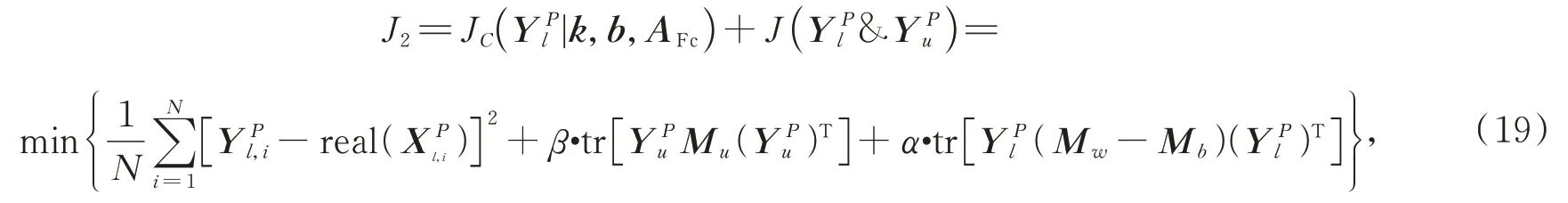
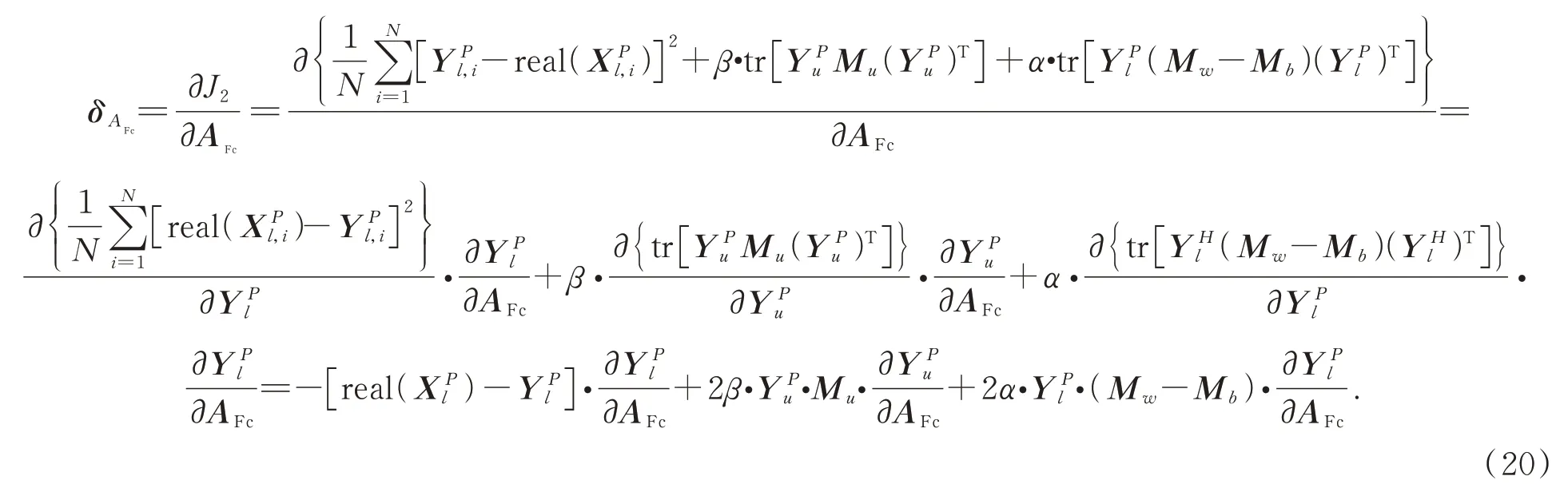
第m层卷积核网络参数b m,k m的梯度分别为:

式中:

若η2表示空间流学习率,则第m层参数更新为:

3 实验结果与分析
3.1 实验数据
本文采用黑河以及WHU-Hi龙口公开高光谱数据集进行对比实验。黑河数据集[20]是由中国国家自然科学基金委员会黑河计划科学数据中心用CASI/SASI传感器于中国甘肃省黑河流域地区采集到的高光谱图像。该图像由684×453个像素和135个光谱波段组成,共104 917个已标记样本点。空间分辨率为2.4 m,包含玉米、土豆等8种土地物类别,假彩色图和真实地物分布如图2所示。

图2 黑河数据集假彩色图与颜色标记的真实地物图Fig.2 False color map and color marked real feature map of Heihe dataset
WHU-Hi龙口数据集[21]由武汉大学RSIDEA研究组收集和共享的高光谱图像分类研究的基准数据集,是通过安装在无人机头部上的纳米级高光谱传感器在中国湖北省各地的农业区获得的,包含玉米、棉花、芝麻、阔叶大豆、窄叶大豆和水稻等9种地物类别。图像的空间分辨率约为0.463 m,尺寸为550×400,包含270个波段,假彩色图和真实地物分布如图3所示。

图3 龙口数据集假彩色图与颜色标记的真实地物图Fig.3 False color map and color marked real feature map of LongKou dataset
3.2 实验设置
为验证本文算法的有效性,选取RAW,无监督学习方法PCA,NPE,监督学习方法LDA,MFA,LGSFA,1DCNN,2DCNN,3DCNN,DMRBN,DLPNet,半 监 督 学 习 方 法SDA,SELD,SCGSP,S3MDA等与本文方法进行对比。其中,RAW表示不进行任何特征提取,直接采用分类器对样本进行分类。对于SSDPNet,根据经验α与β均取0.1,训练次数为3 000,学习率设置为1。以上实验均在64位Windows操作系统,i7-7800X中央处理器,32 G内存的条件下进行。每种算法重复进行10次实验,以均值±标准差(STD)的形式表征总体分类精度(Overall Accuracy,OA)、平均分类精度(Average Accuracy,AA)以及Kappa系数(Kappa Coefficient,KC),以便综合比较并判断各算法的分类性能。OA表示样本分类正确的个数除以总个数,它从总体上展现了所有样本分类正确的概率。AA指每种地物的分类精度取和后求得的平均值,但OA和AA仅侧重于分类结果正确的样本,未考虑错分样本和漏分样本。鉴于此,引入以离散多元法为基础的KC来更全面地评估算法性能。
为了分析无标记样本数目对网络性能的影响,在黑河数据集中每类选取5个标记样本,并且每类分别选取50~500的无标记样本作为训练集,其余样本作为测试,进行10次实验,结果如图4所示。

图4 黑河数据集上不同无标记样本数目下的实验结果Fig.4 Experimental results of different unlabeled sample numbers on Heihe data set
从图4可以看出,OA和KC随着无标记样本数的增加而逐渐变高,而后逐渐趋于稳定,证明通过构建无监督图,保持无标记样本的局部几何结构,能够提升网络的性能。但当无标记样本数达到一定程度后,其内部包含的结构信息逐渐趋于饱和,分类精度趋于平稳。
3.3 黑河数据集实验
为了评估每种方法在不同标记样本数目下的分类精度,每类随机选取ni个(ni=5,10,20,…,50)标记样本,每类500个无标记样本进行试验。表1给出了每种特征提取方法以及不同标记样本下的10次实验结果的分类精度以及标准差。
从表1可以看出,当样本量很小时,由于先验信息不足,监督学习方法性能受限,CNN等深度学习方法陷入过拟合,LDA,LGSFA等监督流形学习方法的性能逊于无监督学习方法(如PCA、NPE),半监督学习方法(如SDA,SELD等)优于无监督、监督学习方法。因为半监督学习方法不仅可以利用少量标记样本中的先验信息,还可以利用无标记样本中的局部几何结构信息。随着标记样本数目的增加,各种算法的分类精度逐渐增加,其中深度学习方法增速尤为明显,这是因为标记样本可提供充足的鉴别信息,深度学习方法可以学习到泛化性更强的抽象特征。本文算法在同时利用了标记样本的空-谱鉴别特征以及大量无标记样本中的局部几何结构信息,因此不论样本数多还是少,分类精度与其他监督、半监督、无监督方法相比均具有较强的竞争力。

表1 不同算法在黑河数据集上的分类结果(总体分类精度±标准差)Tab.1 Classification results with different methods on Heihe data set(overall accuracy±Std) (%)
为了探究SSDPNet各个模块的作用,在黑河数据集上进行消融实验。实验中每类选取5个、50个标记样本,无标记样本均为每类500个。具体设置为:(1)仅使用2DCNN提取空间特征;(2)在2DCNN基础上引入半监督流形重构图模型,这里称为2DCNN+SSGragh;(3)仅使用神经网络提取光谱特征,称为NN;(4)在神经网络基础上引入半监督流形重构图模型,称为NN+SSGragh。消融实验结果如表2所示。

表2 黑河数据集上的消融实验结果(总体分类精度±标准差)Tab.2 Ablation experimental results on Heihe dataset(overall classification accuracy±standard deviation)
消融实验结果表明,2DCNN和NN在半监督流形重构图的作用下,分类精度得到进一步提升。这是因为图模型可以挖掘样本中的内部流形结构,并且保持无标记样本中的局部几何结构,因此可以得到更有鉴别性的特征。SSDPNet的分类结果是最高的,因为其通过全连接层自适应调整空-谱两路网络的权重,得到具有鉴别性的空间-光谱特征。
为了对比每种算法在不同地物类别上的分类精度,从黑河数据集中随机选取0.1%的标记样本、1%的无标记样本用作训练,其余用作测试。表3为不同算法下不同地物类别的OA,AA和KC。图5展示了相应的实际地物分类效果。
从图5可以看出,本文算法相比其他方法分类图错分点较少,更为平滑,尤其是在“Corn”“Artificial Surface”类别上取得不错的效果,而其余算法则出现了“椒盐”现象。表3中,本文算法由于同时考虑了样本的局部空间特征、光谱特征以及内在流形结构的探索,分类性能得到了有效的提升,因此OA,AA,KC均为最高,且在大多数地物类别上也取得不错的效果。深度学习方法(1DCNN、3DCNN)等在某些地物类别上精度较低且标准差值较大,这是因为此类地物样本数过少以致其陷入过拟合。

图5 各算法在黑河数据集上的分类结果Fig.5 Classification results of each algorithm on Heihe data set

表3 不同算法在黑河数据集上各类地物的分类结果Tab.3 Classification results of each class samples via different methods on Heihe data set (%)

3.4 龙口数据集实验
为进一步验证本文方法的有效性,同样在龙口数据集中每类随机选取ni个(ni=5,10,20,…,50)标记样本,500个无标记样本进行试验。表4给出了每种特征提取方法以及不同标记样本下的10次实验结果的分类精度以及标准差。
从表4可以看出,各个算法的分类精度均随着标记样本数目的增加而增加,这是因为数目越多的标记样本可以提供的类别先验知识更加丰富。深度学习方法(如CNN,DMRBN)在样本量较少时,分类精度不如传统流形学习方法(如MFA,SELD)。这是因为数目不足的训练样本使其陷入过拟合,但是随着样本数的增加,其强大的非线性映射能力使得其精度逐渐优于其他流形学习方法。深度流形学习方法优于1DCNN等深度学习方法,因为它不仅提取深度抽象信息,还探索了内部的流形结构,不过由于只考虑了光谱信息,因此性能逊于3DCNN。本文方法不管在小样本还是大量样本的情况下都取得了较高的精度,这是因为与深度学习方法相比,SSDPNet不仅利用了标记样本与未标记样本的深度光谱特征,还利用了其周围的局部空间特征,可以自适应调整空-谱网络权重。此外,还利用了无标记样本中的局部几何结构信息。

表4 不同算法在龙口数据集上的分类结果(总体分类精度±标准差)Tab.4 Classification results with different methods on LongKou data set(overall accuracy±std) (%)
为进一步研究SSDPNet各个模块的作用,在龙口数据集上进行消融实验。实验中每类选取5个、50个标记样本,500个无标记样本。具体设置为:(1)仅使用2DCNN提取空间特征;(2)在2DCNN基础上引入半监督流形重构图模型,实验中称为2DCNN+SSGragh;(3)仅使用神经网络提取光谱特征,实验中称为NN;(4)在神经网络基础上引入半监督流形重构图模型,称为NN+SSGragh。消融实验结果如表5所示。
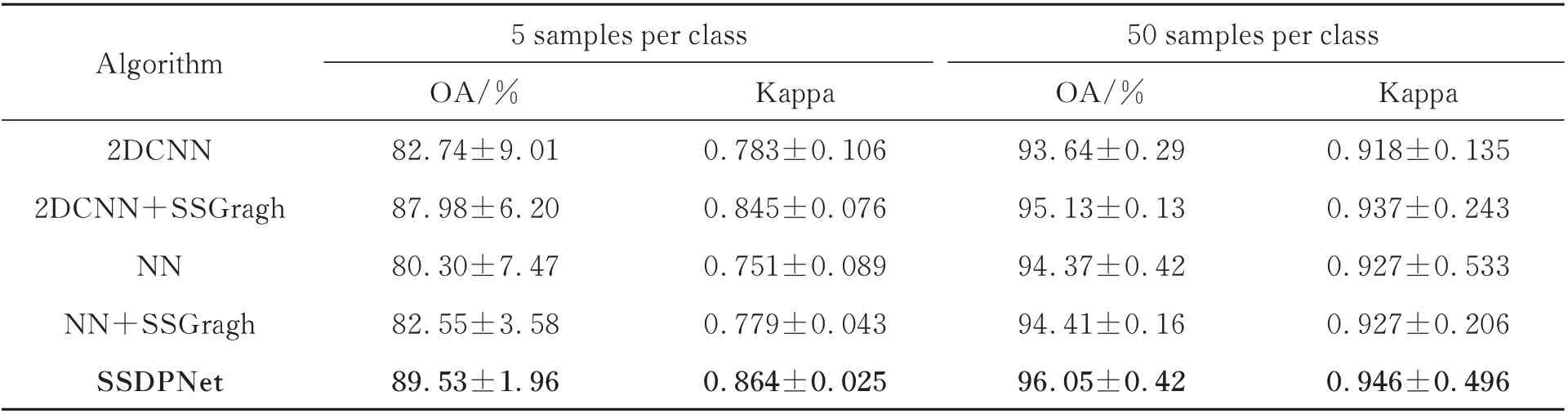
表5 龙口数据集下的消融实验结果Tab.5 Ablation experimental results on Longkou data set
在龙口数据集上的消融实验结果证明,训练样本数目不同时,NN和2DCNN两路网络的性能有些许差异,因此需要通过全连接层自适应调整空-谱两路网络的权重,使得精度占有优势的网络权重更大,反之权重更小,SSDPNet性能更加优异。该结果同样可以证明半监督流形重构图对2DCNN和NN的优化作用,因为它可以挖掘标记样本中的内部流形结构,并且保持无标记样本中的局部几何结构。
为了对比每种算法在不同地物类别上的分类精度,从龙口数据集中随机选取0.1%的标记样本、1%的无标记样本用作训练,其余用作测试。表6为不同算法下不同地物类别的OA,AA和KC。图6展示了龙口数据集实际地物分类效果。
图6中,本文算法产生的同质区域更为平滑,尤其是在“Rice”“Corn”类别上取得了不错的效果。从表6可以看出,SSDPNet对龙口数据集上各类地物的分类精度均较高,各项评价指标均为最高。由此表明,本文算法能有效地提取标记样本的深度空-谱鉴别信息,比其他只能利用光谱鉴别信息的算法鉴别性更高,性能更好。同时,SSDPNet能够有效利用无标记样本中的局部几何结构信息,比3DCNN等只能利用标记样本信息的算法精度更高。
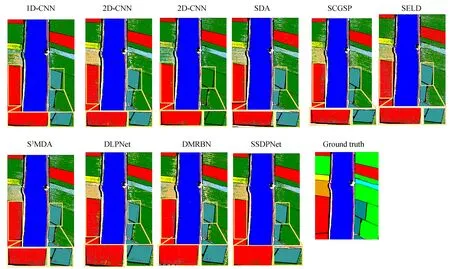
图6 各算法在龙口数据集上的分类结果Fig.6 Classification results of each algorithm on Longkou data set
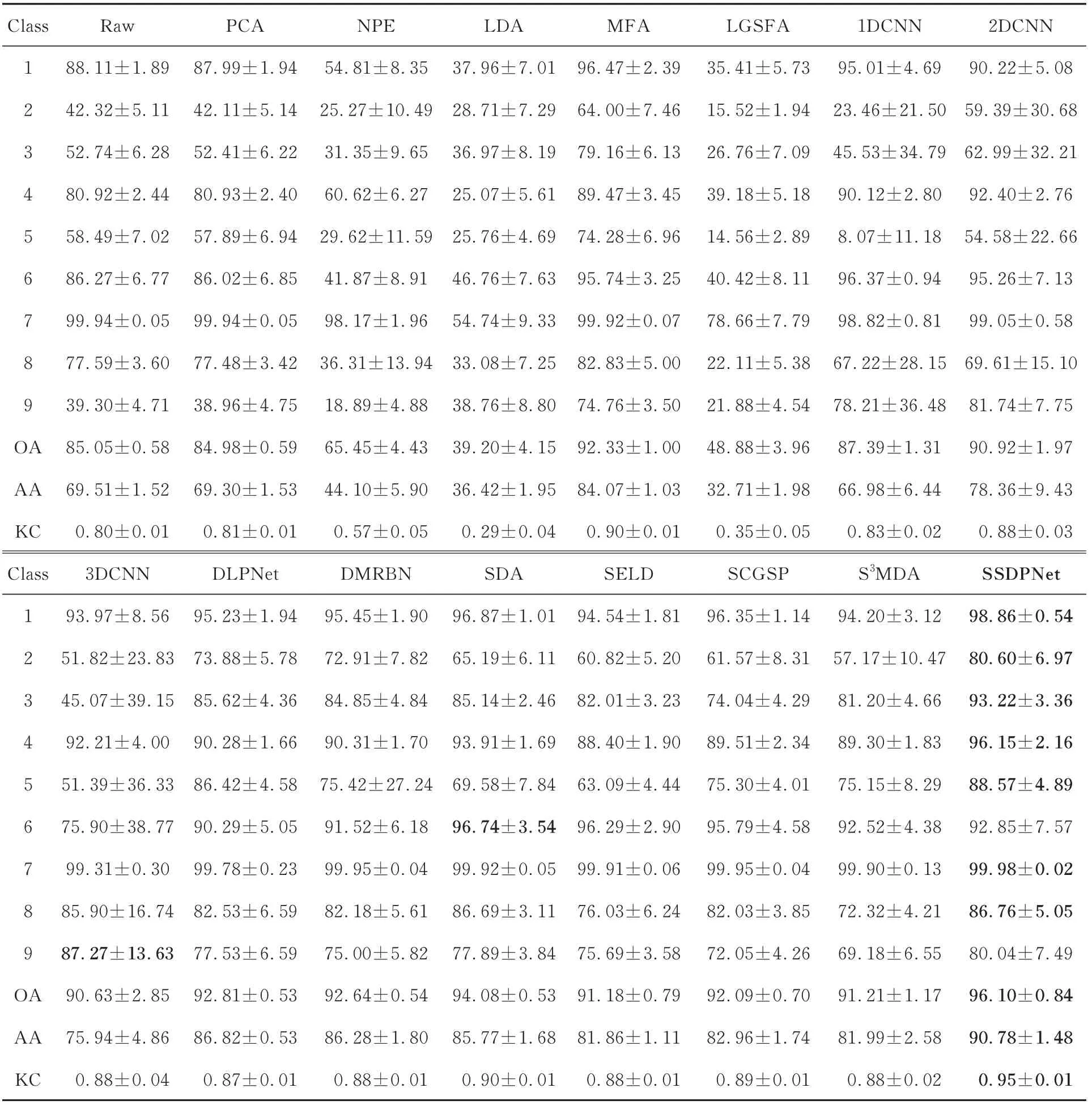
表6 不同算法在龙口数据集上各类地物的分类结果Tab.6 Classification results of each class samples via different methods on Heihe data set (%)

4 结 论
本文提出了一种半监督双流网络,该网络由空-谱双流网络结构、半监督流形重构图和一种融合方案组成。光谱流采用NN提取每个像素点光谱波段的光谱信息,以前述样本为中心构建图像块并在空间流中采用2DCNN来提取空间信息。此外,构建了半监督图模型,并设计了基于深度-流形联合损失函数以优化NN和2DCNN。在网络末端通过全连接层来自适应平衡两个网络的权重,充分平衡提取到的空-谱特征。在WHU-Hi-龙口和黑河高光谱数据集上的实验表明,该方法优于其他算法,尤其是在训练样本量比较少时具有更加明显的优势。但是该方法忽略了利用图像上下文之间的关系,因此下一步将探讨如何引入图卷积网络,以进一步提取图像丰富上下文信息,并将该算法拓展到目标检测领域。
