基于改进自适应k 均值聚类的三维点云骨架提取的研究
2022-08-30范晓明
鲁 斌 范晓明
随着三维扫描技术和建模技术的不断发展,点云模型已经被广泛地应用于实际的生产生活和科学研究[1],相关的模型处理技术也在不断地深入.骨架模型[2]作为三维模型的概括型表现形式,直观地显示了模型的拓扑连接性和几何结构,目前已有很多三维处理技术如三维重建[3]、模型分割[4-5]、点云配准[6-7]和模型形状检索[8-10]等以此为基础实现.因此,三维点云技术的飞速发展及模型种类的不断增多对骨架提取算法的准确性提出了更高的要求.L1-中值骨架提取算法[11]因其快速高效的特点,被广泛地应用于点云模型骨架提取中.该算法基于全局中值的思想,提出应用局部中值对点云提取初始骨架,通过不断扩大邻域半径达到针对不同区域实现不同程度收缩的目的;同时,根据点分布情况引入了引力约束和斥力约束来实现规整化,可以快速计算出较好的一维骨架.但该算法也存在随机采样造成的可重复性差,密度不均匀情况下采样很容易丢失细节,以及基于阈值的骨架伸长导致的错误骨架连接等问题.
本文针对以上缺点,提出了一种基于改进的自适应k均值(k-means)聚类引导的L1-中值骨架提取算法,主要的流程图如图1 所示.给定一个三维点云模型,首先采用八叉树对散乱点云进行组织,每个体素基于当前密度包含的点数不一;在此结构下完成中值采样,并利用采样点集自适应确定初始聚类中心实现k均值区域划分,应用局部中值迭代收缩得到各区域内的骨架分支;最后通过对L1局部分支拟合曲线完成骨架平滑及连接.本算法将密度因素及野点的影响考虑到采样问题中,保证模型的细节不会丢失,同时减少了后续骨架提取的迭代次数;区域划分约束下提取骨架,解决了跨区域连接错误的问题.实验结果表明,本文算法与L1-中值骨架提取算法相比,有效地提升了点云骨架的准确性与可重复性,可以达到更好的提取效果.

图1 本文算法流程图Fig.1 Flow chart of our proposed algorithm
1 国内外研究现状
最经典的骨架提取技术是Blum[12]在1967 年提出的中轴变换,该方法能够快速地提取二维形状内部的一维骨架(中轴线),但对形状表面的噪声十分敏感.Dey 等[13]首先定义了模型中轴面的子集为三维模型的一维曲线骨架.Cornea 等[14]对现有的一维曲线骨架提取技术做了很好的综述,提出了理想骨架应该具有的属性.虽然骨架并没有一个完全统一、标准的定义,但大多数骨架提取的方法都运用了中轴的概念,满足中心性;同时,骨架又不同于中轴,中轴能够感知到模型的边界上比较微弱的扰乱,而曲线骨架必须要具备较少的对模型边界上的声音的感知能力,具有鲁棒性.
近年来,国内外学者对于点云骨架提取问题做了大量的研究工作,可以概括为以下几类:1)距离变换法:基于几何三维结构的整体分析,对节点进行距离变换计算,形成距离场,通过筛选出局部极值点作为骨架点来达到构建整体骨架的目的.此方法在解决整体性比较好、细节不多的模型时效果明显,对于模型重构也有着很好的借鉴意义,但在离散域中,节点之间的关系无法准确定位,得出的骨架大多不连续,效果较差.2)Laplace 收缩法:由Au 等[15]提出的基于网格的骨架提取代表方法之一,运用Laplace 算子的收敛特性,通过反复平衡牵引将网格收缩到模型的中间位置,可以处理少量点云缺失问题,目前应用较为广泛.因需要反复调整Delaunay 三角网格,故时间复杂度较高.3)广义旋转对称轴法:利用平滑切割的迭代算法来计算点云的旋转对称轴,然后对非圆柱形连接区域进行特殊处理以得到一维曲线骨架.该方法利用旋转对称性可以实现有效地缺失弥补,但其前提假定模型是圆柱形的,并且过多的预处理操作极大地增加了时间复杂度.4)空间中轴法:Huang 等[11]提出的基于局部中值[16]迭代收缩实现骨架提取的算法,可以有效抵御野点的影响,避免了传统骨架提取方法中的预分割和人工编辑操作,具有较好的应用前景.
表1 列举了这4 类方法最近几年的代表性文章,并分析了各自的优缺点和适用范围.随着研究的不断深入,学者们也结合其他方法对L1-中值算法进行了扩展,在适用范围内都取得了不错的效果.

表1 三维点云骨架提取方法的比较Table 1 Comparison of three-dimensional point cloud skeleton extraction methods
本文还整理了2011~2019 年点云骨架提取方向的国内外论文共158 篇,基于年度论文发表数量及论文数量累计和绘制了图2 所示的柱形-折线图.总体上说,研究该方向的论文并不是特别多,但随着骨架提取作为前置工作与三维重建、点云分割、目标检测等领域技术的结合,该方向关注度呈螺旋式上升的趋势.

图2 2011~2019 年点云骨架提取方向论文发表年度趋势图Fig.2 Annual trend chart of the paper published in the point cloud skeleton extraction field from 2011 to 2019
2 基于八叉树分割的点云化简
2.1 八叉树分割
将输入点云体素化,利用八叉树算法覆盖输入点云.选择基于指针区域的八叉树进行实验,可以达到以下3 个目的:1)把散乱点云数据有序组织好,起到索引的作用;2)实现有计划地数据简化;3)为特征点估计定义邻域点.
八叉树分割方法递归地将空间上的所有节点都分解成8 个一样的子节点,即在这个空间上的所有体素的几何信息是一致的[28].图3 为八叉树分割的示意图,从递归结构上可以看出,该方法使用树遍历算法来查找节点,并且可以在节点上递归生成新节点,具有良好的拓扑结构.

图3 八叉树分割示意图Fig.3 Schematic diagram of octree segmentation
本文对于给定点云模型,首先计算输入点云数据的一个包围框如图4(a),对其进行八叉树分割,图4(b)、图4(c)给出了分割过程示意图;若子立方体内包含点云数据则保留,否则抛弃如图4(d),重复上述步骤直至满足判别条件,分割结果如图4(e)所示.基于后续点云下采样对八叉树的要求,采用固定的最小体素值作为判别条件,此时均匀排列的体素网格代表着输入点云的局部表面特征.

图4 八叉树分割可视化结果图Fig.4 Visualization result diagram of octree segmentation
2.2 八叉树中值下采样
基于密度进行下采样把采样点收缩为骨架点,从而生成骨架.对于一些点云密度不均匀的数据,随机采样会使得密度较高的区域采样点多,而密度较低的区域采样点少,收缩得到的骨架容易丢失细节,甚至出现较多的小骨架.
针对这种现象,本文提出基于八叉树的中值下采样方法,即取每个体素中包含的所有点的中值点作为采样点.在此,中值点是基于体素中心进行求解的,计算公式:

式中,ωj=1/‖CJ-qj‖.当前体素的点集为 {qj}j∈J,CJ是该体素中心,即点集的均值中心,ωj表示点qj的权重,与该点到体素中心的距离成反比.由式(1)可知,距离越远的点权重越小,对中值点的贡献率也就越小,因此中值点更能抵御野点的影响.
具体实现如下:首先通过八叉树进行点云数据组织并得到体素中心集合(如图5(a)中心位置的点所示),然后计算每个体素内的点到中心点的距离以赋予权重,接着根据式(1)求得体素中值点,最后作为采样点输出(如图5(b)所示).

图5 均值中心与中值中心对比图Fig.5 The mean center versus the median center
图6 为植物模型点云中值下采样的过程及结果.图6(a)为源点云;图6(b)表示八叉树分割点云的可视化过程,可以看出,由于第2.1 节中八叉树拆分的终止条件,最终得到的体素大小都是一样的,故可实现在点密集的区域和点稀疏的区域采样平衡,达到消除质量差异的目的;图6(c)中将基于体素中心的均值采样结果与本文采用的基于体素中值点的中值采样结果进行了对比,左图均值采样得到的采样点排列规整,在保持源点云结构和尺度的基础上进行了简化,右图中本文采样方法得到的采样点保留原有结构的同时对分支进行了细化,如枝干部位,这是因为取中值点作为采样点,很好地利用了中值滤波,起到弱化噪声点和离群点的作用.
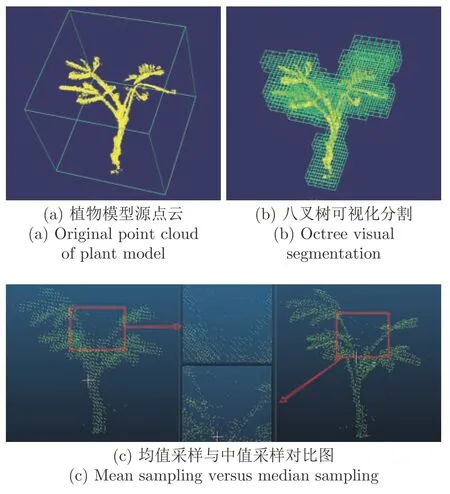
图6 植物模型点云中值下采样Fig.6 Median down-sampling of plant model point cloud
因此,基于八叉树的中值下采样方法,不仅实现了基于密度的采样平衡,而且基于中值思想得到的采样点集收敛于真实骨架,大大减少了后续骨架提取的迭代次数.
3 自适应k 均值聚类的区域划分
本文提出一种基于八叉树采样的自适应k均值聚类算法对点云模型进行划分,主要考虑到以下三点:1)八叉树组织点云数据可以减少后续聚类的工作量;2)自适应聚类中心和类簇个数k可明显减少迭代次数,同时降低人为误差;3)提前划分区域可有效降低骨架错误连接的发生.
3.1 k 均值聚类算法
k均值聚类算法[29]的主要特征是随机确定k个初始聚类中心,基于距离比较对源点进行归类划分并计算得到新的聚类中心,进行下一轮迭代,中心位置不变时结束归类.归类的过程实际上也是最小化误差的过程,k均值最小化,是要最小化所有点与其关联的聚类中心点之间的距离之和,即评估指标(Sum of squared errors,SSE),计算公式为:

式中,Ci是第i个类簇,p是Ci中的样本点,mi是Ci当前的聚类中心,k值基于先验知识设定,即类簇的个数,也是点云区域的个数.SSE 是源点云中所有点的聚类误差平方和,代表了聚类效果的好坏.
k均值算法中,选择最近的聚类中心归类,是为了减小p引起的误差,而重新定位聚类中心则是用于减小mi引起的误差,所以每一次迭代都会将误差最小化.
3.2 自适应k 值
k均值算法中涉及到类簇个数k的指定,但在实际中k值的选择即给定点云划分的区域个数非常难以估计.为降低因人为误差造成划分结果的不准确性以及最小化误差平方和SSE,本文采用肘部法则对SSE 曲线图进行分析,以自适应得到一个建议的k值.
肘部法则使用SSE 作为性能度量,SSE 值越小则说明各个类簇越收敛.但并不是SSE 越小越好,考虑极端情况下将采样点集内的每个点都视为一个类簇,那么SSE 的值降为0,显然达不到分类的效果.肘部法则为本文提供的是在类簇数量与SSE 之间寻求一个平衡点的方法.
应用肘部法则计算得到自适应k值的步骤如下:1)确定k值的上限kmax和下限kmin,即可能的最大类簇数和最小类簇数.由于本文实验数据集均为结构清晰的实物点云模型,且考虑到骨架提取对区域个数的约束,本文设定kmax=10,kmin=2;2)从kmin递增至kmax,计算出不同k 值下的SSE,并绘制曲线图;3)曲线图下降途中的拐点所对应的k 值,则是相对最佳的类簇数量值.此处以从Fast-Scan 三维扫描仪采集的飞机模型为例,得到如下k-SSE 曲线图:
由图7 可以看出,当设定的类簇数不断接近最佳类簇数时,SSE 呈现快速下降态势,而当设定类簇数超过最佳类簇数时,SSE 仍会继续下降,但下降态势趋于缓慢,因此拐点处的k值已经达到了合适的分类效果,即类簇数量与SSE 之间的一个平衡点.
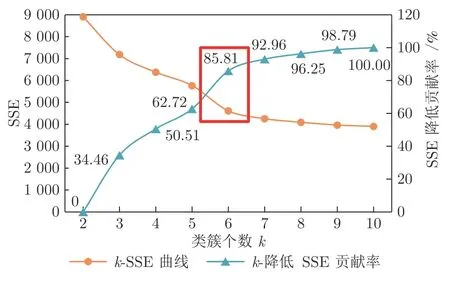
图7 飞机模型点云的k-SSE 关系曲线图Fig.7 k-SSE relation graph of aircraft model point cloud
对于拐点的确定,为避免目测法带来的人为误差且结合折线图的走势,本文借鉴主成分分析中保留方差百分比的方法,即k 值的选取类似于主成分个数的选取,可通过当前k值对误差平方和SSE 的降低贡献率来判断,计算公式:

在图7 所示的曲线图中,拐点k=6 处对SSE的降低贡献率已经达到了85.81%,拐点后的k值贡献率增加不大且接近100%,因此选取拐点为满足条件的最小k值.经实验证明,μ取0.8 较为合适.
3.3 自适应k 均值聚类中心
k均值算法随机确定初始聚类中心,很可能会收敛到局部最优.实验证明,初始聚类中心的好坏,对聚类的效果以及算法的迭代次数都有着很明显的影响.
最坏的情况如图8(b)所示,两个初始点选在了同一个类簇中,很有可能导致原本属于一个类簇的点被分成了两类.另外,初始中心最好选择数据中的点,若中心在点云数据之外,其移动到最终位置势必会增加迭代次数.

图8 初始中心位置导致分类结果不同Fig.8 The initial center position results in different classification results
k-means++算法[30]的基本思想是,初始聚类中心之间的相互距离要尽可能远.结合以上分析,并考虑到算法中距离计算的工作量,本文在八叉树采样点集中使用k-means++算法来确定初始聚类中心.首先从采样点集中随机选择一个点作为第1 个聚类中心,之后对于每个采样点计算到最近的聚类中心的距离D(x),轮盘赌法选出下一个点作为新的聚类中心,直到得到k个中心点.轮盘赌法中每个点被选择的概率与D(x)成正比,D(x)越大,被选取作为聚类中心的概率也就越大.
图9 给出了飞机模型点云自适应得到的k个初始聚类中心.如图中圆点标注的位置,初始聚类中心正好分散在最终得到的类簇中,避免了因初始中心聚集而导致的迭代次数的大幅增加.箭头上的数字表示自适应得到k个中心的先后顺序,验证了kmeans++算法中相互距离尽可能的远的取点原则.

图9 飞机模型点云的初始聚类中心Fig.9 Initial cluster center of aircraft model point cloud
该方法可以实现初始聚类中心的分散选取,从而减少聚类迭代次数,大大改善了k均值算法的有效性.算法流程如图10 所示.
3.4 自适应k 均值聚类的算法流程
基于八叉树采样的自适应k均值聚类算法流程如图10 所示,具体步骤如下:

图10 自适应k 均值聚类算法流程图Fig.10 Flowchart of adaptive k-means clustering algorithm
步骤1.初始化k值的上下限参数kmax、kmin及贡献率阈值μ,并输入源点云及采样点云.
步骤2.令当前聚类个数为kmin,在采样点云使用kmeans++算法自适应得到kmin个初始聚类中心.
步骤3.基于初始聚类中心进行k均值聚类,计算源点云所有点到每个聚类中心的距离,选择最近的中心进行归类.
步骤4.更新k个聚类中心的位置,取当前簇内所有点的平均值作为新的聚类中心.计算先后中心的距离,若存在中心点移动,则返回步骤3;否则保存当前分类结果及误差平方和SSE,k的值加1,若k大于kmax,进行下一步,否则利用新k值返回步骤2.
步骤5.在所有分类情况均完成后,利用式(3)得到满足条件的最小k值,即自适应类簇个数.该k值下的分类结果即为所求.
步骤6.进行类簇染色,使用不同颜色对类簇加以区分.
步骤7.停止算法,输出点云.
图11 给出了飞机模型点云完成自适应k均值聚类得到的分类结果.可见,该点云自适应区域个数k为6,箭头指向的点为最终的聚类中心,数字表示当前类簇的索引值,图中的线段标注,表示初始聚类中心到最终聚类中心的直线距离,因自适应初始聚类中心确定的好,所以中心位置移动不大,且不存在跨区域移动,大大减少了聚类的迭代次数.

图11 飞机点云自适应k 均值聚类的分割结果Fig.11 Adaptive k-means segmentation results of aircraft point cloud
图12 分别给出了含羞草模型点云和瑜伽动作模型点云完成自适应k均值聚类得到的分类结果.其中,含羞草模型点云自适应区域个数k为7,瑜伽模型点云自适应区域个数k为6.

图12 自适应k 均值聚类的分割结果Fig.12 Adaptive segmentation results of k-means clustering
4 骨架提取
4.1 骨架分支的生成
通过八叉树分割得到一系列采样点后利用L1-中值骨架算法进行区域内骨架收缩提取.骨架收缩提取的基本思想是通过选取采样点邻域内的中值而不是平均值进行收缩,产生新的骨架点,不停地迭代并重新将其分配至所在区域的源点的中心.直接应用L1-中值算法往往会产生稀疏分布,造成结果中的一些中心点过度收缩产生一团点簇.为此使用了一个调整函数在局部空间中轴形成一种排斥力,完成规整排布.
给定散乱采样点Q={qj},j∈J⊂Ω3,以及对应邻域点X={xi},i∈I⊂Ω3,利用最优化式(4)可得到一系列骨架点:


式(4)中第1 项确定局部L1-中值收缩骨架点,基于采样点在输入点集中的邻域点的引力作用向局部中值移动;第2 项规整项,基于采样点集内的邻域点形成斥力,避免收缩过近,根据点分布情况[31]见式(5),其中γi是平衡引力和斥力的参数.θ(r)是高斯权重函数,由式(6)可知,固定邻域半径下,距离采样点越远,所贡献权重也就越小,从而起到了中值滤波的作用.把式(5)代入L1-中值求解项中得出:

实际情况中,对于形状不规则的模型,区域点集粗细不一,给定一个邻域半径难免出现过收缩和欠收缩的情况.为减少迭代次数,本文提出一种基于区域划分的自适应半径骨架提取的算法,针对不同区域设定不同的初始邻域半径,避免由于初始半径设定的太小导致迭代次数增加;以相同的增长率扩大半径,寻找新的分支并进行骨架连接,对于已经收缩到位的分支进行固定.
基于区域大小以及包含的源点数计算不同的邻域半径h0,实验发现,对于点数小于五万的点云收缩成骨架的最大邻域半径为 3h0,默认值h0=,dbb是指该区域点云包围盒对角线长度,J指该区域内源点云集合的点数目.
4.2 基于区域的骨架连接
使用上述公式计算收缩得到的粗骨架,在连续性和平滑性这两点上还存在不足,甚至会影响到骨架的准确性,所以本文在原有最优化公式上添加了一个正则项,用于局部分支的曲线拟合,以形成密切联系的骨架.定义以下平滑函数:

N(xi)是该点的邻域点集,v(xi)是邻域中点的个数.平滑函数P(X)通过将邻域点的距离最小化,来优化骨架点的位置,得到局部拟合的曲线骨架.图13(a)中第3 个点与它的相邻点不呈曲线分布,从数学角度来讲,即在空间坐标轴主方向贡献了方差.应用式(8)的平滑函数最小化方差,则得到了图13(b)中骨架点的平滑分布.

图13 局部曲线拟合示意图Fig.13 Schematic diagram of local curve fitting
基于区域划分的骨架连接,由于本身是一个整体,每个区域一般都会存在跨区域连接.基于骨架分支拟合曲线,分支两个端点沿伸长方向加值延长至当前邻域半径的2 倍,若与其他区域骨架点相交,则以相交点为端点固定该伸长分支,并进行标记,否则偏转角度进行连接;若与本区域内骨架点相交,则遍历该区域所有骨架是否已存在跨区域连接,若不存在,待本区域分支均连接完毕后,再伸长一个半径长度的活动段进行寻找,找到则连接,否则结束骨架连接,示意图见图14.最后采用四边形细分的方法[32]对骨架平滑化和椭圆拟合方法[33]进行骨架中心化.

图14 骨架连接示意图Fig.14 Skeleton connection diagram
5 实验与分析
为验证算法的提取效果,本文选用点云由FastScan 三维扫描仪采集,是没有经过任何预处理、包含噪声或离群点的非均匀密度的点云数据.该数据集[11]包括植物、动物、静物和人体动作等15 类三维模型,部分采用本文算法的骨架提取结果数据如表2 所示.

表2 不同模型的实验结果对比Table 2 Comparison table of experimental results of different models
图15 是在情侣雕塑的点云模型上做骨架提取的结果,该模型由自适应k均值聚类算法大体对称地分为了7 个区域,涉及多处跨区域环状连接.实验结果表明,本文算法可以很好地处理对称环状连接问题,得到平滑骨架.同时,点云模型中含有部分噪声和离群点,并且扫描出的点云密度并不均匀,在这种情况下,能够提取出较为理想的骨架,显示了算法的强鲁棒性.

图15 情侣模型的点云骨架提取Fig.15 Point cloud skeleton extraction of couple model
图16 是在瑜伽动作的点云模型上做骨架提取的结果,该模型属于四肢型动作模型的一种,身躯和四肢在区域大小、点数和形状上存在差异,且骨架提取在扁平区域很容易出现过度收缩的现象.实验表明,在采样点和区域分割约束下,提取的骨架具有较高的准确度,保留了骨架的连续性.

图16 瑜伽模型的点云骨架提取Fig.16 Point cloud skeleton extraction of yoga model
图17(a)含羞草模型中存在叶子点云密度不均匀及数据缺失的现象.提取的骨架结果表明,本文算法对原始点云的质量并没有严格的先验要求,仍可以提取出较为准确的骨架线,具有强鲁棒性.

图17 含羞草模型的点云骨架提取Fig.17 Point cloud skeleton extraction of mimosa model
为进一步说明本文算法的优越性,将其与2 种最先进的骨架提取算法L1-中值算法[11]和基于距离场引导的L1-中值算法[18]进行了比较.以下是分别在鹿模型、珊瑚模型和较复杂的树木模型上进行骨架提取的实验结果.
图18 是鹿雕塑的点云模型做骨架提取的结果,该模型上半部分包含细小分叉,同时底部较分支部分尺度和点数都相差较大;在图18(b)展示的L1-中值骨架提取结果中,丢失了很多骨架分支,且存在多处骨架连接错误,造成这些现象的原因主要有2 个:1)L1-中值算法采用随机下采样使得原本点稀疏的分支点数减少以致无法形成骨架;2)骨架分支距离过近导致错误连接;图18(d)方法[18]的结果除以上问题外,还出现了错误的骨架闭环,且该算法本身易受点云缺失的影响,导致模型底部的骨架连续性较差;然而这些在图18(c)本文算法得到的结果中有相当明显的改善,本文通过八叉树中值采样保证分支的密度平衡,以减少骨架的丢失,另外区域划分对骨架连接进行了约束,提高了骨架准确率.
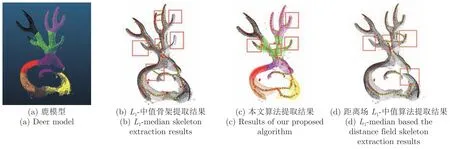
图18 鹿模型的点云骨架提取对比结果Fig.18 Comparison results of point cloud skeleton extraction of deer model
图19 是珊瑚雕塑的点云模型做骨架提取的结果,该模型形状可看似骨骼明显的树形结构,在图19(b)展示的L1-中值骨架提取结果中,多处出现骨架不连续,提取效果较差;图19(d)方法[18]相较于L1-中值算法,虽然在连续性上有所改善,但仍然丢失了大量的骨架分支;而图19(c)本文算法通过区域约束使得提取结果很好地保持了同一区域内骨架的连通,且尽可能多的保留细节,极少丢失骨架.

图19 珊瑚模型的点云骨架提取对比结果Fig.19 Comparison results of point cloud skeleton extraction of coral model
图20 是树木点云模型做骨架提取的结果,树木模型相对复杂,含有较多错综连接的树杈及细小无形的枝叶,且较为集中.图20(b)展示的L1-中值骨架提取结果中,树木丢失了接近一半的骨架,且枝叶部分几乎无骨架分支形成;图20(d)方法[18]的结果中不仅丢失了较多关键骨架,而且提取出的骨架离散不连通,效果较差;图20(c)中本文算法通过区域划分首先将枝叶和树干分类隔开,分别提取骨架再进行连接,避免发生枝叶分离或提取不出骨架的情况,很好地保持了树干的拓扑结构,并且具有很好的连通性.

图20 树木模型的点云骨架提取对比结果Fig.20 Comparison results of point cloud skeleton extraction of tree model
由以上对比实验可以看出,该算法提取的骨架比其他方法更准确,可有效地识别更多的分支.同时,实验部分所涉及模型的形状和拓扑结构各异,点云的密度也不尽相同,本文算法仍能得到很好地骨架提取结果,具有较好的适应性,未来可更好地应用于其他相关领域,具有较强的学习扩展能力.
但同时该算法也存在着一些缺陷,均匀子空间采样在保留细节的同时偶尔会导致产生多余的小骨架,如图21(b)标注,因恐龙脚部点云呈平面分布且离散而收缩成了两个骨架分支;另外,局部点云内部缺失严重时,易形成局部骨架闭环,如图22(b).

图21 恐龙模型的点云骨架提取Fig.21 Point cloud skeleton extraction of dinosaur model

图22 动作模型的点云骨架提取Fig.22 Point cloud skeleton extraction of movement model
6 结束语
本文针对传统骨架提取算法中提取结果可重复性差、易丢失细节及连接错误等问题,提出了一种基于改进的自适应k均值区域划分的骨架提取算法,对骨架提取和连接进行约束.该算法利用八叉树中值采样,起到抵御野点和平衡点云分布密度的作用;基于采样点进行自适应k均值区域划分,实现保留局部细节;基于区域自适应半径进行L1-中值骨架收缩,有效地减少了工作量.实验结果表明,该算法大大减少了迭代次数,有效避免了细节的丢失及错误骨架的连接,具有强鲁棒性、高准确率等优点.
需要注意的是,本文算法尽管在k均值聚类时实现了自适应确定参数,可客观地进行合理的区域划分,但在L1-中值算法中的参数仍使用了实验观察法,这些参数对骨架提取结果有着一定的影响;同时提取的骨架结果保留细节的同时偶尔会有多余的小骨架产生,且在局部点云内部缺失严重时易形成局部骨架闭环,因此如何更加便捷准确地确定参数及完善骨架,这将是下一步重点解决的问题.
