融合类别先验Mixup 数据增强的罪名预测方法
2022-08-30线岩团陈文仲余正涛张亚飞王红斌
线岩团 陈文仲 余正涛 张亚飞 王红斌
罪名预测是法律判决预测任务中具有代表性的子任务,也是法律辅助系统的重要组成部分[1].
罪名预测通常被看作针对案件事实的文本分类问题.早期研究工作通常利用统计机器学习方法实现罪名预测[2-4].随着深度学习在自然语言处理领域的广泛应用,基于深度学习方法的罪名预测模型大量涌现.
2018 中国“法研杯”司法人工智能挑战赛发布中文司法判决预测数据集,共包含260 余万条数据,数据源于“中国裁判文书网”公开的刑事法律文书[5].针对中文的司法判决预测任务,目前有较多的研究工作均在此数据集上展开.
Zhong 等[6]将多种判决预测任务之间的依赖视为有向无环图,提出了拓扑多任务学习框架,并将多种判决任务间的依赖关系融入分类模型,改进了罪名预测效果.Yang 等[7]借助多任务间的拓扑结构,通过多角度前向预测和反向验证提高了多任务审判预测性能.王文广等[8]提出了融合层次注意力网络和卷积神经网络的多任务罪名预测模型.已有研究表明,将罪名预测与其他相关判决预测任务联合建模,为模型提供更多的监督信息,可以改进罪名预测效果.
Jiang 等[9]采用深度强化学习方法抽取文本中的论据,并利用论据增强分类来提高罪名预测的准确率.刘宗林等[10]在罪名预测和法条推荐联合模型中融入罪名关键词提升了罪名预测性能.Xu 等[11]采用图神经网络学习易混淆法条之间的差异,并设计注意力机制充分利用这些差异从事实描述中抽取出明显特征去区分易混淆罪名.已有的罪名预测工作大多从多任务学习和外部知识融入的角度开展罪名预测研究,未考虑罪名预测的数据分布问题.
由于各类案件发生概率的差异较大,罪名预测数据存在着严重的类别不平衡问题.以 Hu 等[12]构建的罪名预测数据集为例,Criminal-L 训练集共包含149 类罪名,将各罪名按其样本占比降序排列,其中前10 类高频罪名对应的样本占比约为78%,而最后100 类罪名的样本仅占约3%,这是典型的“长尾数据”.各类罪名在数量上的高度不平衡易导致模型在训练时偏向于高频罪名而忽略低频罪名,造成在罪名预测时低频罪名易被错误分类的问题,从而严重影响模型性能.
针对罪名预测的类别不平衡问题,Hu 等[12]在人工标注法律属性的基础上,构建联合罪名预测和法律属性预测的多任务分类模型,提高了低频罪名的预测性能.He 等[13]在胶囊网络基础上,提出融合文本序列信息和空间信息的罪名预测模型,并引入Focal Loss 损失函数,有效提高了低频罪名的预测效果.
和已有的多任务方法[12]与改进损失函数的方法[13]不同,本文从数据增强角度研究罪名预测的类别不平衡问题.本文借鉴图像分类中的混合样本数据增强方法[14-15],在文本的表示空间中扩增训练样本,并提出融合罪名先验概率的标签合成策略,使合成样本偏向低频罪名类别,从而达到扩增低频罪名训练样本的目的.在表示空间中合成偏向低频罪名的训练样本,既扩增了训练样本的数量,又丰富了特征的多样性,有助于平滑模型的分类面,提高模型的泛化能力.
本文采用 Lin 等[16]提出的结构化自注意力句子嵌入方法构建罪名预测模型,并在模型训练过程中融入类别先验混合样本数据增强策略,提升模型性能.实验结果表明,本文提出的融入类别先验Mixup 数据增强的罪名预测方法可以在不增加人工标注和辅助任务的前提下,有效改进罪名预测模型性能,显著提高低频罪名的预测效果.本文提出方法的源代码可从网址https://github.com/xianyt/proir_mixup_charge 下载.
本文方法的主要贡献如下:
1)本文将Mixup 数据增强方法引入罪名预测任务中,利用文本表示空间中的插值操作合成训练样本.合成样本增加了训练样本的多样性,有效提高了罪名预测模型的泛化能力.
2)本文针对罪名不平衡问题,提出了类别先验引导的Mixup 数据增强策略.该策略在文本表示空间中生成倾向于低频罪名的合成样本,扩增了低频罪名样本,有效缓解了罪名不平衡问题,提高了低频罪名的预测效果.
3)与基线模型相比,本文方法在Hu 等[12]构建的3 个不同规模的罪名预测数据集上都取得了最好的预测效果.模型在宏准确率、宏召回率和宏F1 值上都有显著提升,低频罪名宏F1 值提升达到13.5%.
1 相关工作
已有的罪名预测研究工作主要从多任务联合学习[12]和外部知识融入[10]的角度来提升模型性能,并利用辅助任务和改进的损失函数来缓解罪名预测任务面临的类别不平衡问题.与已有工作不同的是,本文从数据增强角度来改进罪名预测方法,提升罪名预测性能.和已有罪名预测方法相比,本文方法没有引入辅助任务,也不需要额外的数据标注工作;另外,本文提出的数据增强策略不依赖于特定的文本编码器,可以应用于已有的罪名预测模型.
Zhang 等[14]提出的Mixup 方法是一种应用于图像分类的数据增强策略.该方法是从训练集中随机抽取图像样本,并通过线性混合来合成新的图像样本,有效改进了小样本图像分类的性能[14].由于文本是一种离散表示,所以Mixup 方法无法直接应用于文本分类任务.Verma 等[15]提出的Manifold Mixup 方法在图像的嵌入空间中利用随机混合图像的向量表示来生成编码空间中的伪样本;相比Mixup 方法,Manifold Mixup 能够提供更高层的监督信息,使模型具有更好的泛化能力.受Manifold Mixup 方法启发,本文提出了融合类别先验Mixup方法,与 Manifold Mixup 方法中对样本向量表示和标签采用相同混合因子的做法不同,本文方法针对文本表示和分类标签采用不同的混合因子,利用罪名的先验概率来生成偏向低频类别的伪样本,以此来缓解罪名不平衡问题.
目前,Mixup 方法在自然语言处理领域仅有少量的研究工作.Guo 等[17]将Mixup 数据增强方法应用于句子分类任务,提出了词级和句子级的Mixup策略,提升了句子分类的性能,将Mixup 数据增强方法应用于句子分类任务,提出了词级和句子级的Mixup 策略,提升了句子分类的性能.Chen等[18]将Mixup 方法应用于半监督文本分类任务,改进了分类效果.目前还未见针对不平衡文本分类问题的Mixup 方法.所以,本文面向罪名预测任务,研究不平衡文本分类的Mixup 数据增强策略具有明显的创新性.
2 罪名预测模型
本文提出的罪名预测方法在深度学习文本分类模型基础上,引入Mixup 数据增强策略,并利用罪名先验概率生成偏向低频罪名的伪样本,以此缓解罪名预测中的类别不平衡问题.
本文提出的罪名预测模型包括编码层、类别先验引导Mixup 层和分类层3 层.图1 展示了本文提出的罪名预测模型的总体结构.最下方的编码层用于学习罪名描述文本的向量表示,该层包括3 个子层,分别是词嵌入层、双向长短时记忆网络编码层[19](Bi-directional long short-term memory,Bi-LSTM)和结构化注意力层[9].在训练模型时,本文方法在编码层与分类层间加入类别先验引导Mixup层,该层通过随机混合的文本向量表示和对应的分类标签生成伪样本和伪标签.伪样本向量表示和文本向量表示被送入分类层.分类层通过全连接层和Softmax 激活函数计算罪名预测值,并针对伪样本和普通样本计算分类损失.

图1 罪名预测模型的总体结构图Fig.1 Overview of proposed charge prediction model
本文选择Bi-LSTM 作为文本编码器主要有3个方面的考虑.首先,Bi-LSTM 是一种被广泛应用的序列编码器,可以有效对长文本进行建模.Bi-LSTM 适合用于对篇章级的案件描述进行编码,其有效性已在多个罪名预测模型中得到验证[6-7,13];其次,在实验过程中作者发现,Bi-LSTM 与结构化注意力机制结合可能很好地获取多个侧面的文本分类特征.最后,相比于双向编码器表示模型(Bidirectional encoder representation from transformers,BERT)[20]等预训练语言模型,Bi-LSTM 结构简单易于训练,可应用于大规模文本分类问题.而且,在类别严重不平衡的罪名预测任务上,Bi-LSTM 模型训练过程中过拟合现象不明显.第4.4 节对比了不同文本编码器对罪名预测性能的影响.
案情描述和事实文本中的词序列x=[w1,w2,···,wn]经过词嵌入编码后得到词序列的低维向量表示E=[e1,e2,···,en],其中,n表示文本长度,wi表示文本中的第i个词,ei∈Rd表示第i个词的词向量,d表示词向量的维度.
Bi-LSTM 层以词序列的向量表示为输入计算词语在上下文中的向量表示:

为了获得具有上下文语义的词语表示,本文将正向和逆向的LSTM 输出和ei拼接作为第i个词在序列中的隐状态表示:

通过拼接hi序列可得到词序列的隐状态表示H∈Rn×(2u+d),其中,u表示隐状态的维度.

本文采用结构化自注意力层来计算文本多个侧面的向量表示.该层的注意力权重矩阵A∈Rr×n由2 层感知机计算得到,

式中,Ws1∈和Ws2∈是注意力层的参数,da和r为模型的超参数,da表示注意力层隐状态的维度,r是注意力机制的个数.
文本表示矩阵Z∈Rr×(2u+d)由词序列的隐状态表示H和注意力权重矩阵A的乘积得到,

文本的向量表示z由矩阵Z中的r个向量拼接得到,其维度为r×(2u+d).
在训练过程中,类别先验引导Mixup 层通过随机混合批次内的文本向量表示得到扩增的文本向量表示,其中M是一个批次内的样本数据量,具体方法将在第 3 节中详细阐述.
最后,分类层通过线性层和Softmax 激活函数预测各罪名的概率,

式中,W∈RK×r(2u+d)和b∈RK分别是线性层的权重矩阵和偏置,K表示罪名类别数.
3 类别先验 Mixup 数据增强方法
3.1 Mixup 数据增强策略
Mixup 数据增强方法的主要思想是通过混合随机抽取的2 个图像和对应标签来生成伪样本来扩增训练数据[14].在此基础上,Verma 等[15]提出在嵌入空间中生成伪样本的Manifold Mixup 方法,

式中,gk(·)表示神经网络编码器中从输入到第k层的前向过程,λ∈[0,1] 为混合因子,由Beta 分布采样得到.该方法在图像的嵌入空间中合成伪样本,利用更高层次的表示为模型提供更多的监督信号,从而有效提高了模型的泛化能力.
算法 1.类别先验Mixup 训练算法


3.2 类别先验 Mixup
本文借鉴Manifold Mixup 方法的思想,在文本的向量表示空间中合成伪样本.在此基础上,提出了融合类别先验的Mixup 数据增强策略.该策略在合成样本的表示和标签时采用不同的混合因子,并通过各类别罪名的先验概率计算标签的混合因子,以便使伪样本的标签偏向低频罪名.本文提出的融合类别先验Mixup 数据增强策略的公式可表示为:

式中,f(·)为将文本编码为向量的神经网络,λ∈[0,1]为样本的混合因子,由Beta (α,α)分布采样得到,α为超参数,λy∈[0,1] 为标签的混合因子,(xi,yi)和(xj,yj)是从同一个训练批次中随机抽取的样本对.
为了能在训练过程中通过Mixup 方法扩增低频罪名训练样本,本文通过融合各类别罪名的先验概率来指导 Mixup 为低频罪名标签赋予更大的混合因子,使得合成的伪样本更偏向于少样本类别.为此,首先根据类别先验概率计算类别混合因子λp:

式中,p(xi)和p(xj)分别为样本xi和xj所对应类别的先验概率.各类别罪名的先验概率根据训练集中的各类别罪名的占比计算得到.如果xi为低频罪名,则意味着其先验概率低,那么按式(9)为其分配较大的λp,以使得伪样本的标签偏向低频罪名;反之,为其分配较小的λp.
在得到λp后,本文将之与采样得到的样本混合因子λ进行平均得到标签混合因子λy:

通过引入类别先验,使得合成样本既扩增了训练样本,同时缓解了模型过于偏向高频罪名的问题.
本文将Mixup 数据增强策略引入深度学习罪名预测模型中.在训练过程中通过式(8)、式(9)和式(10)随机混合一个批次内的文本向量表示及其标签来获得伪样本,并利用交叉熵分别计算样本和伪样本的损失,模型损失L(θ)公式如下:

式中,第1 项为样本分类损失,第2 项为伪样本分类损失.M为一个批次的样本数量,K为罪名类别数,yik∈{0,1} 为样本i在类别k上的标签,∈[0,1]为伪样本j在类别k上的伪标签,分别为样本i和j在类别k上的预测值.
融合类别先验Mixup 数据增强的罪名预测模型的训练过程参见算法1.算法输入中的文本编码器对应第2 节的编码层,罪名先验概率由训练集中各罪名的样本数量预先估计得到.
4 实验及结果分析
为了验证所提出方法的有效性,本文将之与现有罪名预测方法进行对比实验,并分析了相关实验结果.
4.1 数据集与评价指标
本文采用Hu 等[12]构建的罪名预测数据集验证本文方法的有效性.该数据集主要针对低频罪名和易混淆罪名预测任务构建,不包含多被告、数罪并罚的情形.该数据集包含小、中、大3 个不同规模的子数据集,分别命名为Criminal-S、Criminal-M、Criminal-L,数据集统计信息参见表1.

表1 数据集统计信息Table 1 The statistics of different datasets
图2 展示了Criminal 数据集中3 个不同规模子数据集训练样本的高频、中频和低频罪名的分布情况.图2 中的高频、中频和低频罪名根据Criminal-S 数据集的样本数量统计得到,其中低频罪名为样本数少于10 的罪名(共 49 类),高频罪名为样本数多于100 的罪名(共49 类),其余的作为中频罪名(共51 类).由图2 可以看出,3 个不同规模数据集的罪名分布均呈现出典型的“长尾分布”特征,其中,49 类高频罪名样本占比约为97%,中频罪名样本占比仅为2.6%左右,而3 个子数据集的低频罪名更加稀少,均少于1%.从图2 还可发现,3 个不同规模的样本分布差异主要集中在低频罪名上.

图2 训练集罪名样本分布Fig.2 Charge distribution of the training set
为进一步比较3 个子数据集在类别不平衡上的差异,本文在图3 展示了样本数量最少的 75 个罪名的样本分布情况.本文统计了Criminal-S 数据集中各罪名的样本数量,并将罪名按样本从多到少排列作为图3 的横坐标.图3 的纵坐标为各罪名样本的占比.从图3 可发现,3 个数据集中频样本上的分布基本一致,但是在低频样本分布上具有明显差异.在Criminal-S 数据集中低频罪名的分布比较稳定,最低占比稳定在0.013%左右.Criminal-M 数据集的低频罪名占比在0.005%~0.013%之间波动,而Criminal-L 数据集的低频罪名占比在0.003%~0.013%之间波动.相比之下,Criminal-L 数据集类别不平衡程度最严重,Criminal-M 数据集次之,而Criminal-S 数据集类别不平衡程度最轻.

图3 训练集罪名部分样本分布Fig.3 Charge distribution of the training set
在评价指标方面,本文与文献[12-13]同样采用准确率(Accuracy,Acc.)、宏精确率(Macro-precision,MP)、宏召回率(Macro-recall,MR)和宏F1 值(Macro F1)作为模型性能的评价指标.
4.2 模型实现细节
本文采用Pytorch 实现提出的模型和算法.犯罪事实描述的最大词序列长度设为500,词频低于5 的词被视为未知词.词嵌入维度d设为100,并采用文献[12]的预训练词向量初始化嵌入层参数.Bi-LSTM 层的隐状态维度u设为300.嵌入层和Bi-LSTM 层的dropout 值分别设置为0.3 和0.1.结构化自注意力机制的头数r设为24,注意力层隐状态维度da设为128.样本混合因子λ由参数α=150的Beta 分布采样得到,标签混合因子λy由式(9)和式(10)计算得到.
模型采用Adam 梯度下降算法[21]训练,初始学习率设为 0.001,β1=0.9,β2=0.999,ε=10-8.最大训练轮次设为50,批次大小设为256.训练过程采用提前停止策略,并根据验证集损失函数最小选择最优模型.
为减小案件描述中不同金额、重量、酒精含量、年龄等对模型词汇表的影响,本文在数据预处理时对犯罪事实描述中的金额、重量、酒精含量、年龄等的数字部分进行了替换处理.例如,将“2018 年”替换为“×年”,“1 000 元”替换为“×元”.
4.3 对比实验
本文采用以下几种典型的文本分类模型和当前性能最优的罪名预测方法作为基线模型:
1)TFIDF+SVM:该方法采用词频逆文档频率(Term frequency-inverse document frequency,TFIDF)[22]抽取文本特征,特征维度为2 000,并采用支持向量机(Support vector machine,SVM)[23]作为分类器.
2)卷积神经网络(Convolutional neural networks,CNN):该方法利用多个不同尺度的卷积网络构建文本分类器[24].
3)长短期记忆网络:采用双层LSTM 作为案件事实编码器,并利用最大池化获取分类特征[19].
4)事实-法条注意力模型(Fact-law attention model,Fact-Law Att):Luo 等[25]提出的融合法条相关性与注意力机制的多任务罪名预测模型.
5)小样本属性模型(Few-shot attributes model,Few-Shot Attri):Hu 等[12]提出的融合法律属性与罪名预测的联合模型,该方法通过引入法律属性分类任务改进低频罪名预测性能.
6)序列增强型的胶囊模型(Sequence enhanced capsule model,SECaps):He 等[13]提出的融合文本序列信息和空间信息的罪名预测模型,并引入 Focal Loss 损失函数,进而改进低频罪名的预测效果.
除TFIDF+SVM 模型外,其余对比模型词嵌入维度设为100.LSTM 模型的隐状态维度设为100.CNN 模型的滤波器宽度为(2,3,4,5),每个滤波器的大小为25.基线模型实验结果引用自文献[12-13].
本文实现了2 个引入Mixup 数据增强策略的模型:LSTM-Att-Manifold-Mixup 表示引入Manifold Mixup 数据增强策略的罪名预测模型,LSTMAtt-Prior-Mixup 为融合类别先验Mixup 的罪名预测模型.本文方法与基线模型的对比实验结果见表2.
由表2 的实验结果可以看出,本文方法与基线模型相比,在3 个数据集上均取得了最好的预测结果,准确率、宏精确率、宏召回率和宏F1 值均显著优于基线模型.与现有最优模型SECaps 相比,本文模型LSTM-Att-Prior-Mixup 在Criminal-M 数据集上的性能提升最为明显,准确率提升了0.9%,MP 值提高了9.5%,MR 值提高了 11.8%,F1 值提高了10.5%.对比实验结果表明,类别先验Mixup数据增强方法能有效提高罪名预测模型的性能.

表2 罪名预测对比实验结果Table 2 Comparative experimental results
与LSTM-Att-Manifold-Mixup 方法相比,引入类别先验的LSTM-Att-Prior-Mixup 方法在召回率和F1 值上具有明显提升,但其对准确率和MP值的影响并不明显,在Criminal-L 的准确率和宏精确率略有下降.但总的来说引入类别先验有助于提高罪名预测的总体性能,而不会对模型准确率造成过多不利影响.LSTM-Att-Prior-Mixup 方法针对小规模数据集Criminal-S 的提升最显著,相比SECapsF1 提高了6.8%,而对于Criminal-M 和Criminal-L 数据集提升效果有所减弱,其主要原因可能是随训练样本的增多,Mixup 方法合成样本的作用在减弱,甚至成为一种不利于模型训练的噪声,从而影响模型的准确率和 MP 值.
为进一步验证本文方法对低频罪名分类性能的改进作用,本文针对不同频率罪名开展对比实验,根据训练集中罪名的出现频率将罪名划分为3 类,出现次数不高于10 的罪名被看作低频罪名,出现次数高于100 的罪名被看作高频罪名,其余的作为中频罪名.针对Criminal-S 数据集的不同频率罪名预测实验结果见表3.
由表3 可以看出,本文方法在高频、中频和低频罪名上的宏F1 值均优于基线模型.本文模型对低频罪名预测性能的提升尤为显著,相比SECaps 模型宏F1 值提升达到 13.5%.实验结果表明,本文提出的数据增强策略不仅能大幅改进低频罪名的分类效果,对高频和中频罪名预测性能也有一定的促进作用.其主要原因是合成样本有助平滑模型分类的决策面,而类别先验引导的Mixup 数据增强策略合成的数据有效增强了低频罪名的训练数据,从而提高了模型对低频罪名的泛化能力.
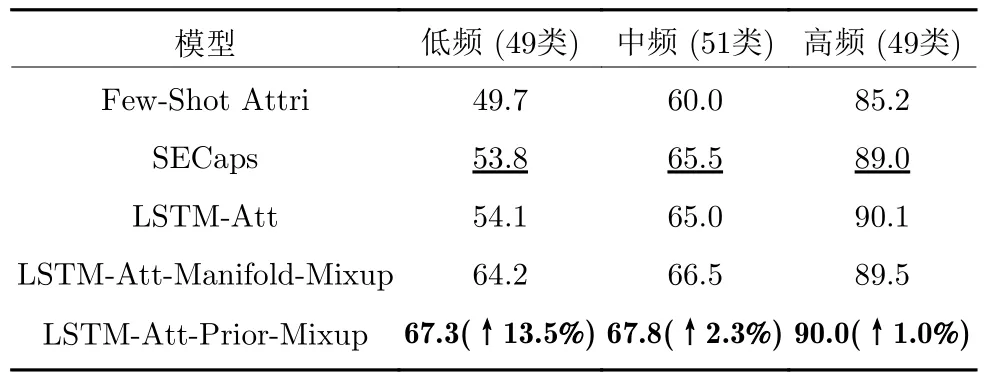
表3 不同频率罪名预测宏 F1 值Table 3 Macro F1 value of different frequency charges
为验证本文方法对易混淆罪名预测性能的改进,本文选取Criminal-S 数据集中4 组典型的易混淆罪名开展实验,它们分别是“放火罪”与“失火罪”、“抢夺罪”与“抢劫罪”、“行贿罪”与“受贿罪”、“盗伐林木罪”与“滥伐林木罪”.表4 为现有方法与本文方法针对易混淆罪名的宏F1 值.
由表4 可以看出,与基线模型相比,本文方法对易混淆罪名的预测宏F1 值获得了明显提高.相比性能最好的SECaps 模型,本文方法在易混淆罪名上的宏F1 值提升了1.6%.文本方法在易混淆罪名上与LSTM-Att-Manifold-Mixup 模型性能相当,宏F1 值仅相差0.2%.实验结果表明,在文本的嵌入空间中合成伪样本,可以改进模型的泛化能力,提升易混淆罪名预测结果.

表4 易混淆罪名预测宏F1 值Table 4 Macro F1 value for confusing charges
4.4 不同编码器对比实验
为了验证本文提出的数据增强方法对不同编码器的适应性,本文将模型中的文本编码器替换为BERT 预训练语言模型,并针对Criminal-S 数据集进行了对比实验.
考虑到司法文本的领域特性,本文采用清华大学人工智能研究院自然语言处理与社会人文计算研究中心提供的刑事文书BERT 预训练语言模型[26]作为模型的编码层.在实验中,本文实现了两个基于BERT 罪名预测模型,其中BERT-CLS 表示采用[CLS]对应向量作为文本表示的罪名预测模型;BERT-Att 表示在BERT 输出的基础上采用结构化自注意力机制获取文本表示的罪名预测模型.在微调BERT 模型时,作者根据实验发现将学习速率设为 1×10-4,并根据验证集的F1 值选择最优模型时获得的性能最好.此外,由于受限于GPU 的显存容量,BERT 模型训练的批次大小设为32.表5展示了不同编码器与不同Mixup 数据增强策略结合后,模型对测试集的预测 F1 值.
由表5 的实验结果对比可以看出,以BERT 作为编码器的模型预测性能均低于采用Bi-LSTM 作为编码器的模型.在实验过程中发现采用BERT 作为编码器的罪名预测模型存在严重的过拟合问题.在训练过程中,BERT 模型在训练集上的准确率上升很快,在第7~8 轮时模型对训练集的准确率达到1,但此时验证集的准确率为94%左右.出现这一现象的原因可能是BERT 模型参数量巨大,在微调时模型过于偏向高频罪名,从而导致模型的总体性能较差.
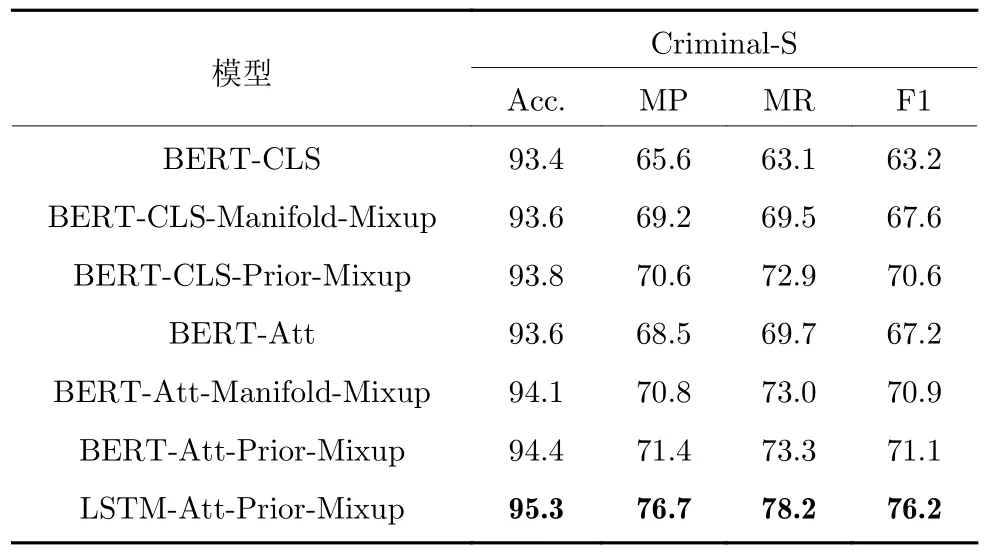
表5 不同编码器对比实验结果Table 5 Comparative experimental results of different encoder
对比不同的BERT 模型,BERT-Att 的性能要优于 BERT-CLS.实验结果表明在预训练语言模型的基础上,采用结构化注意机制有助于模型学习到更好的分类特征.
在数据增强策略方面,BERT-CLS 模型和BERT-Att 模型在引入数据增强策略后,模型性能均获得明显提升.与Manifold-Mixup 方法相比,本文提出的类别先验 Mixup 数据增强策略可获得更好的预测性能.
实验结果表明,本文提出的类别先验Mixup 数据增强策略可适用于不同的文本分类模型,同时有助于改进模型对类别不平衡文本分类数据的性能.
4.5 消融实验
类别先验Mixup 数据增强策略和结构化自注意力机制是本文方法的重要组成部分.为验证它们对罪名预测模型性能的影响,本文进行了2 组消融实验.第1 组实验从模型训练过程中移除类别先验Mixup 数据增强策略,该实验在表6 标记为LSTMAtt.第2 组实验在移除类别先验Mixup 数据增强策略基础上,将结构化自注意力层替换为最大池化层,该实验标注记为LSTM-Maxpool.
由表6 的消融实验结果可发现,移除类别先验Mixup 数据增强策略后,模型性能明显下降,模型针对Criminal-S 和Criminal-M 两个数据集的准确率和宏精确率有所下降,而3 个数据集的MR 平均下降了4.9%,F1 值平均下降了3.4%.实验结果表明,本文提出的类别先验 Mixup 数据增强策略对缓解罪名不平衡具有重要作用,数据增强策略可显著提高模型的召回率和F1 值,而不会对模型的准确率和宏精确率造成过多的影响.

表6 消融实验罪名预测结果Table 6 Results of ablation experiments
本文将结构化自注意力层替换为Max-pooling层后,模型性能大幅下降,准确率平均下降了0.9%,MP 平均下降了22.8%,MR 平均下降了28.4%,F1值平均下降了25.8%,该实验结果表明,从文本中获取丰富的分类特征对于罪名预测模型的性能提升具有重要影响.相比于最大池化层,结构化自注意力机制能够更加有效地捕获不同侧面案情的文本特征,从而大幅提高模型的性能.
从消融实验结果可看出,在利用结构注意力获取有效罪名分类特征的基础上,引入本文提出的类别先验Mixup 数据增强策略可进一步提高罪名预测性能.
4.6 超参数的影响
本节讨论模型主要超参数对罪名预测性能的影响.
样本混合因子λ决定了样本的合成比例,对伪样本的分布具有重要影响.本文对比了不同Beta分布超参数对模型性能的影响.图4 展示了不同超参数α下模型对Criminal-S 数据集的预测结果,横坐标为超参数α,纵坐标为模型性能指标.
由图4 的实验结果可以看出,随着超参数α的增大模型的性能也逐步提高.其原因是当α值较小时,采样得到的λ值偏向于0 或1,导致伪样本向量表示偏向其中一个样本,影响了伪样本的多样性.当α值增大时,采样得到的λ值趋向于0.5,则样本表示在合成样本中的占比趋向于平均,则合成样本在表示空间中分布更加均匀.这样的数据分布有助于平滑模型的分类决策面,提高模型的泛化能力.当α超过 150 后模型性能有所下降,其原因可能是采样得到的λ值接近0.5 且方差很小,这也会影响合成样本的多样性,从而对模型训练造成不利影响.

图4 Beta 分布超参数的影响Fig.4 Impact of Beta distribution parameters
当α超过150 后模型性能有所下降,其原因可能是采样得到的λ值接近0.5 且方差很小,这也会影响合成样本的多样性,从而对模型训练造成不利影响.
结构化自注意力层的超参数r决定了文本表示的维度.图5 展示了不同r值对应的模型性能,横坐标为r的值,纵坐标为模型的性能指标.
由图5 结果可以看出,随着注意力头数r的增大,文本表示包含的特征越来越丰富,模型的性能也不断提升.当r大于24 后,模型性能有所下降,其原因可能是当r增大时,模型的复杂度也随之增大,导致模型过拟合,降低了模型的泛化能力.

图5 注意力头数的影响Fig.5 Impact of head number in attention Layer
4.7 案例分析
本文通过可视化模型的注意力权重来分析罪名预测模型的分类依据,并通过对比LSTM-Att 模型和LSTM-Att-Prior-Mixup 的注意力差异对数据增强策略对模型的影响进行分析.
图6 展示了模型对低频罪名“拐骗儿童罪”案例的注意力权重分布情况.从总体上看,2 个模型都关注到了案情描述中比较重要的词语,比如“不知去向”“借口”等.但是,相比于LSTM-Att-Prior-Mixup 模型,LSTM-Att 模型的注意力更加分散,它还关注了许多与罪名分类无关的词语,如“港南区”“评定”等.可能正是由于这些注意力的分散导致LSTM-Att 模型将该案件错分为“非法拘禁罪”.

图6 低频罪名案例Fig.6 Sample of low frequency charge
图7 展示了模型对易混淆罪名“行贿罪”案例的注意力权重分布情况.与低频罪名案例中的情况类似,两个模型都关注到了案情描述中比较重要的词语,比如“行贿”“收受”“x万”等与行贿、受贿紧密相关的词语.然而,相比之下LSTM-Att 模型的注意力更加分散,从而导致模型将该案件错分为“受贿罪”.

图7 易混淆罪名案例Fig.7 Sample of confusing charge
综上所述,类别先验Mixup 有助于模型学习到更优的注意力机制,使得模型关注的词语更加集中,从而提高了模型对低频罪名和易混淆罪名的预测能力.
5 结束语
本文将Mixup 数据增强策略引入到罪名预测任务中,并针对罪名不平衡问题提出了类别先验Mixup 数据增强策略,有效缓解了类别不平衡带来的影响,提高了低频罪名和易混淆罪名的分类性能;相比已有方法,本文提出的类别先验Mixup 数据增强方法简单有效,无需额外的人工标注,也不需要引入辅助任务.
本文主要关注于改进低频罪名预测性能,并针对单罪名预测问题验证了所提方法的有效性,而数罪并罚情况下的Mixup 数据增强策略将在下一步工作中进行研究.
