融合随机擦除和通道注意力的行人重识别方法
2022-08-29闫昊雷李小春张仁飞邱浪波
闫昊雷,李小春,张仁飞,邱浪波
1(空军工程大学 信息与导航学院,西安 710077)
2(武警陕西省总队,西安 710054)
3(陕西省信息化工程研究院,西安 710061)
E-mail:410538774@qq.com
1 引 言
随着信息社会的发展,通过视频传感器监控环境成为保障人民生命财产安全的重要手段之一.由于现实场景中受视频传感器像素低、现实环境复杂等因素影响,人脸识别技术无法进行跨区域的检测和识别,因此,行人重识别技术应运而生.其通过对输入目标的行人图像进行解析,可识别目标行人衣着、外形、携带物等特征,根据这些特征,算法可快速定位该目标所处监控下的实时具体位置,即完成第2次识别.这项技术极大的节省人员时间和精力,可广泛应用于智能安保、抓捕逃犯、丢失儿童寻找等现实场景中.但由于现实场景的复杂多变,视频传感器固定观察某处地域,无法获取全域行人的正面图像,且行人图像极易被障碍物遮挡,因此只能获取行人的部分图像,导致对行人特征的判别力不强,影响检测准确度.因此,行人重识别算法研究现如今仍具有挑战性[1].
行人重识别算法研究分为两大类:基于传统方法和基于深度学习方法.传统方法主要有手工设计特征和距离度量两种.手工提取特征的算法有LOMO[2]、HOG[3]、LBP[4]等.主要是从图像的颜色、纹理、梯度、形状等因素出发,寻求不同角度下的特征提取手段.度量学习方法主要有LMNN[5]算法、XQDA[6]算法和显著性加权度量学习[7]等,其根据特征之间的不同距离进行计算,从而提取出有用特征.由于传统方法有一定的局限性,很难处理不同视频传感器拍摄的行人存在的姿态、背景、光线、尺度不同等问题,近年来,随着深度学习理论研究的蓬勃兴起和硬件计算能力的快速发展,有学者开始探索基于深度学习的行人重识别算法,并逐渐取得一系列成果[8].与传统做法不同,利用深度学习解决行人重识别问题融合了特征提取与度量学习两个过程,在自动提取更有判别性特征的同时,将特征映射到更好的度量空间.基于深度学习的行人重识别网络模型由卷积神经网络构成,它可以从原始的图像中提取丰富的语义特征,其将行人重识别看作目标分类和检索任务,分为表征学习和度量学习.表征学习通过预测行人的ID,计算分类误差损失.度量学习通过输入多张图片,网络将这些图片映射到不同的特征空间,使得同类图片之间的距离尽可能小,不同图片之间距离尽可能的大.
基于深度学习的卷积神经网络可以自主提取图像特征,但随着网络层的增多会出现梯度消失现象,导致特征提取效果的下降,而ResNet[9]在卷积神经网络中融入残差结构,可以使网络向更深层延续下去,但带来的影响是提取到的特征信息未被有效利用.为进一步增强网络利用特征信息的能力,注意力机制作为嵌入在神经网络中的一种模块,旨在“帮助”神经网络快速定位图像的重要信息,忽略冗余信息,从而提取出图像的关键特征加以利用.通道注意力模块是注意力机制的一种,通过从图像通道维度进行观察,寻找图像的关键特征.研究者们提出了一些具有创新性的通道注意力机制算法.如Hu[10]等人提出一种压缩-激励操作,通过全局平均池化将各个通道降维后压缩为对特征图的权重,然后将获得的权重和原特征图相乘,获取新的特征图.Wang[11]等人在压缩通道信息的同时,进一步发掘通道之间的内部关系,在对通道降维的同时,保留与原始特征图关系紧密的通道.Zhang[12]等人根据自注意力的思想,结合通道自身信息判断其对于特征图的重要性程度,提出一种关联感知全局注意力模块.上述方法在对通道特征提取信息时手段单一,特别是对特征图使用全局平均池化操作,使模型忽略空间维度其他有用信息,导致对图像特征的提取不够有效.此外,由于实际场景中摄像头角度问题和行人姿态的多样性,导致在识别过程中易出现行人被物体遮挡的情况,此时模型只能通过部分特征进行再识别,使得模型精准度下降,因此,图像被遮挡也是影响行人重识别准确率的重要因素之一.
针对上述问题,本文提出一种融合随机擦除和残差注意力网络的行人重识别算法,该算法基于残差网络,可以使模型提取效果随着网络层的延伸不会下降,并融入改进后的通道注意力模块,使模型能提取重要信息,抑制冗余信息,提升网络的判别能力.同时,引入随机擦除作为数据增强的方法,提高模型的泛化能力,解决行人图像被遮挡的难题.最后使用难采样三元组损失函数[13]和交叉熵损失函数共同对该网络进行训练,提升模型预测的准确率.通过实验,检验了算法的可行性和有效性.
2 相关工作
2.1 ResNet-50网络
卷积神经网络通过对输入图像进行卷积操作,将局部感受区域的思想融合到空间信息和通道信息中,提取图像特征.ResNet-50网络是卷积神经网络ResNet网络的一种结构,其将残差块学习的思想和传统卷积神经网络进行结合,特有的残差模块可以使网络在层数加深时仍能提取到极为丰富的语义特征,解决传统卷积神经网络随着隐藏层增多而效果下降的难题,使得神经网络向更深处延展.
ResNet-50结构如图1所示.其中,conv_1为下采样层,主要用于对输入图像信息的进行预处理,conv2_x,conv3_x,conv4_x,conv5_x为4个layer层,用于对特征进行提取,conv5_x的最后一个池化层和softmax函数用于分类输出.layer层内部中,由1×1卷积核,3×3卷积核,1×1卷积核和批归一化层组成的结构称为Bottleneck,该4个layer层分别含有3,4,6,3个Bottleneck.参考Sun等人[14]的做法,本文在搭建的训练网络中移除conv5_x的下采样操作,旨在提高特征的判别能力.

图1 ResNet-50结构Fig.1 Structure of ResNet-50
2.2 随机擦除

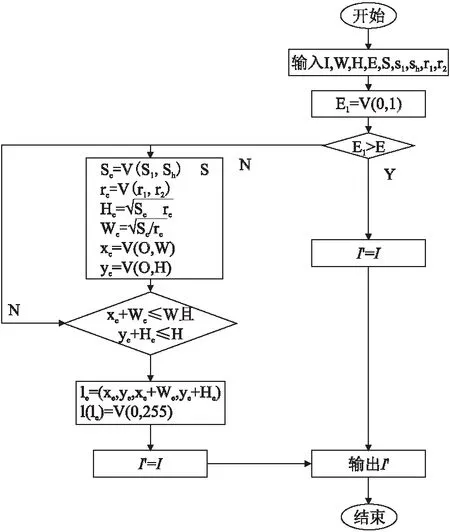
图2 随机擦除算法示意图Fig.2 Diagram of the random erasure algorithm
在本次实验中,将随机擦除的概率E分别按0.1为间隔初始化为10个概率数值进行对比,寻找一个最佳擦除概率.
若输入概率E1大于该值,则输出原图像.否则,对图像进行擦除.
2.3 注意力机制
注意力机制的本质来源于人类观察事物的特性.人类视觉在感知事物时不会全部关注每个细节,而是根据需求观察注意特定的一部分,而当人们发现一个场景经常在某部分出现自己想观察的东西时,人们会进行学习在将来再出现类似场景时把注意力放到该部分上.同样,神经网络进行卷积和池化的过程中,网络初始默认每个通道是同等重要的,因此引入注意力机制,使网络改为关注那些更为关键的特征,可以提高模型预测的精准度和收敛速度.
注意力机制分为硬注意力机制和软注意力机制[16].在硬注意力机制中,权重Ai表示图像区域ai被选中作为输入的概率,当区域被选中时,Ai取值为1,否则为0.软注意力机制中,权重Ai表示图像区域ai被选中作为输入的比例,可以通过计算出确定的加权向量.由于整个模型在确定性软注意力机制下是可微的,因此可以使用反向传播实现端到端的学习.软注意力较硬注意力相比可直接代值到模型中整体进行训练,且所求的梯度可以通过注意力模块反向传播到模型的其它部分.因此,本文中选择软注意力机制作为研究对象.常见的软注意力机制有空间注意力、通道注意力和自注意力.空间注意力模块关注图像哪里的特征是有意义的,通道注意力关注什么样的特征是有意义的,自注意力机制减少对外部信息的依赖,更擅长捕捉数据或特征的内部相关性,其分别从不同的角度对图像进行分析,从而选取最能代表图像信息的特征.本文选取软注意力机制中的通道注意力模块作为研究对象,其原理如图3所示.通道注意力使网络从通道角度对特征图进行理解,按照每个特征通道的重要程度赋予各通道相应的权重,权重学习方法如下:
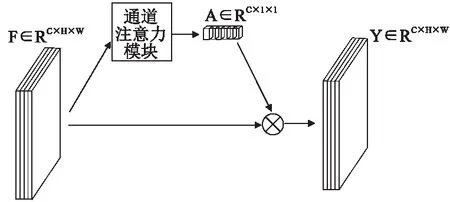
图3 通道注意力机制Fig.3 Channel attention mechanism
A=sigmoid(fc(compress(F)))
(1)
其中,F表示输入特征图.A为经过注意力模块后得到的注意力权重图,fc为映射函数,compress表示特征图的压缩方法.H和W分别为图像的高度和宽度.得到注意力权重图后,和输入特征图相乘,可得到该输入特征图融入通道注意力模块后的输出:
Y:,i,:,:=AiX:,i,:,:s.t.i∈{0,1,…,c-1}
(2)
其中,Ai为第i个向量的注意力权重,X:,i,:,:为第i个通道的输出,C为通道数量,Y:,i,:,:为融入注意力权重后的输出特征图.
3 融合随机擦除和改进通道注意力机制的残差网络
3.1 基本思想
本文首先对输入特征图使用随机擦除方法进行数据增强,使网络可以处理行人被遮挡等特殊情况,同时增强网络的泛化能力.然后将改进后的通道注意力机制融入ResNet-50网络形成残差注意力网络,提高网络对行人关键特征的提取能力,最后利用难采样三元组损失函数和交叉熵损失函数共同对模型进行训练,之后输出行人重识别算法结果.
3.2 RGA-C注意力模块
RGA-C[12]注意力模块是一种通道注意力模块,其在结合全局特征的同时,利用局部特征自身信息和其对应的关联性特征联合推断各通道的,重要性作为通道注意力权重.对于给定的特征图X∈RC×H×W,利用该模块可学习一个C维的通道注意力权重.将X中各通道的维度d=H×W的特征图作为图模型中的一个节点,并将X中所有节点构成一个含有C个节点的有向全连接图Pc.按照光栅扫描顺序对X中的节点进行标号,将X中的一个通道表示为Pc的一个节点,记作xi∈Rd,其中i=1,…C.节点i和节点j之间的相互关系可由xi和xj在投影空间进行点积运算表示:
ri,j=fc(xi,xj)=θc(xi)Tφc(xj)
(3)
其中,θc和φc分别是由1×1卷积核、批归一化层和ReLu激活函数组成的非线性映射函数.可用以下公式表示:
θc(xi)=ReLU(Wθxi)
(4)
φc(xi)=ReLU(Wφxi)
(5)


图4 RGA-C模块Fig.4 RGA-C module
对于Pc中的第i个特征节点xi,向量xi描述特征本身所含信息,向量ri表示特征内部关联性并保留全局范围的结构信息,这两个信息对推断通道重要性均有帮助,将ri,j和ri结合在一起,构成关联感知特征yi:
yi=[poolc(ψc(xi)),φc(ri)]
(6)
其中,poolc表示沿着特征向量通道维度作全局平均池化操作.这里ψc和φc分别表示原始特征和其对应关联性特征的非线性映射函数,由一个卷积核大小为1的卷积层,一个批归一化层和一个ReLU激活函数构成,其可表示为:
ψc(xi)=ReLU(Wψxi)
(7)
φc(ri)=ReLU(Wφri)
(8)

ai=Sigmoid(transpose(W2ReLU(W1yi)))
(9)
其中,W1和W2均由一个1×1的卷积层和一个批归一化层实现.W1将特征通道数量降低S1倍,W2将通道维度变为1,transpose操作通过交换次序将位于通道位置的一维向量交换至空间维度.
RGA-C将神经网络的layer层特征拆解为若干个特征节点,然后在全局范围内将给定的特征节点和其他特征节点进行相关性计算,推断各个特征节点的重要性程度,有效获取全局范围内的特征内在关联性,使模型更好寻找通道相互之间的内部联系,同时有效利用特征的全局结构信息.但在Bottleneck内部,该注意力模块对节点之间的关系未有效获取,导致在后续layer层的相关性计算时无关特征较多,一些不太重要的通道特征信息也参与关联感知特征的计算,影响模型的特征提取效果.
3.3 离散余弦变换
离散余弦变换(DCT)是数字信号处理中常用的变换之一,能很好的描述描述人类语音信号和图像信号的相关特征,也被认为是一种准最佳变换.Qin等人[17]将DCT变换应用到目标检测中,取得了较好效果.以往的注意力权重计算方法是使用全局平均池化进行对空间维度压缩,表示的信息比较单一,获得的权重无法较好代表各通道的重要程度.因此,在图像频域内通过进行DCT变换来选择不同频率从而产生更多的信息,通过这些信息给各个通道赋予不同的权重,使图像经全局平均池化后带来通道信息量小的问题得到改善,模型能够提取到更加关键的特征.二维的DCT公式如下:
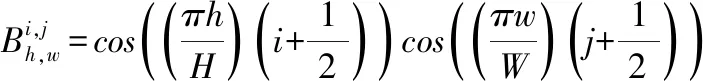
s.t.h∈{0,1,…,H-1},w∈{0,1,…,W-1}
(10)
其中,f2d代表二维变换后的频谱,H和W分别为输入图像的高度和宽度,x2d表示输入图像.
DCT的反变换可以表示为:
s.t.i∈{0,1,…,H-1},j∈{0,1,…,W-1}
(11)
对于式(10),特别的,当输入图像的h和w均为0时,可得:
(12)
GAP表示全局平均池化.由式(12)可知,全局平均池化实际上是图像DCT变换后的特殊情况,即是在最低频率分量上的值.将图像转换为频域上进行考虑,通过DCT变换,使得各通道内部更多的信息被挖掘出来,与只使用全局平均池化相比,DCT变换可以选择出更为丰富的通道特征.
根据式(11),可将输入图像信息在频域上展开为:

(13)
由式(13)发现,对输入图像采取全局平均池化操作只应用了式中第1项的最低频分量部分,未使用后面其他分项,导致对提取特征仍然有用的信息被舍弃了.因此,为获输入图像更多的特征,假设输入特征图为X∈RC×H×W,将通道分为n份,则有Xi∈RC′×H×W,,其中i∈{0,1,…,n-1},C′=C/n,给每个块分配一个二维DCT分量,则第i个通道被压缩后的向量可表示为:
s.t.i∈{0,1,…,n-1}
(14)
其中ui、vi为设定给通道的频率分量,Freqi∈RC′为经过压缩后的C′维向量.对各个通道特征向量进行结合,可得到整个特征图压缩后的分量:
Freq=compress(X)=cat([Freq0,Freq1,…,Freqn-1])
(15)
其中,Compress为输入图像压缩方法,cat表示对图像进行拼接操作,将此分量送入全连接层进行学习,得到注意力权重图:
msatt=sigmoid(fc(Freq))
(16)
其中,sigmoid表示激活函数,fc表示全连接层.
3.4 RGA-FC模块
由于RGA-C在特征提取过程中,layer层前的通道特征因为没有遵守一定的规则而不可避免地出现layer层前的特征信息冗余,导致在layer层进行关联感知特征提取时效率不高.为解决这个问题,在每个Bottleneck后加入DCT变换,形成RGA-FC通道注意力模块.RGA-FC具体结构如图5所示.图5中x为输入的特征图,layerx为网络的layer层,aout为输出的注意力权重图,RGA-FC模块先在Bottleneck后采用DCT变换,将通道信息按照一定的优先级次序进行提取,使通道重要特征表达的趋于完整,为下一步寻找通道间关联感知特征提供重要特征,这样RGA-C在寻找通道之间相互关系时,能准确得找到对特征较为重要的那些通道.
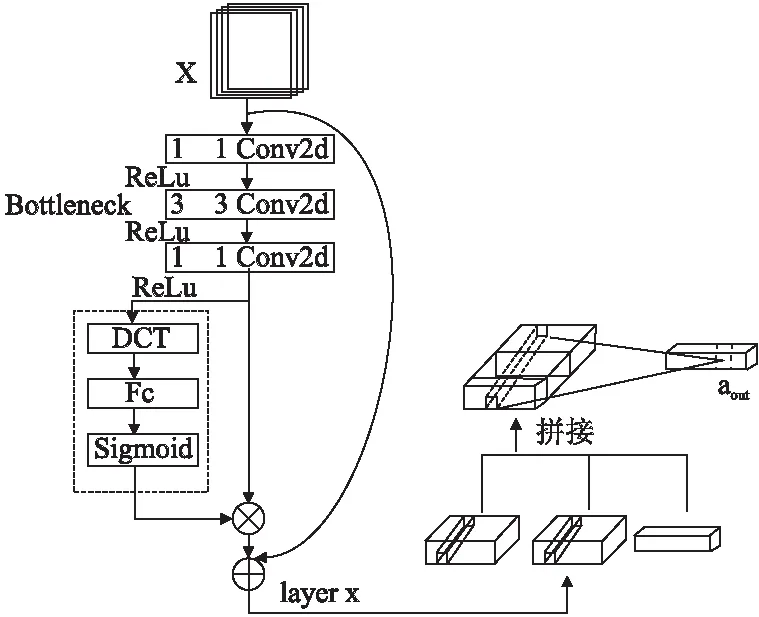
图5 RGA-FC模块Fig.5 RGA-FC module
3.5 损失函数
交叉熵损失函数是表征学习常用的损失函数之一.损失函数如下:
(17)
其中,n为每个批次训练的样本数,p(yi|xi)为输入图像xi和其类别标签yi,经过softmax函数进行分类,xi被识别为yi类的预测概率.
三元组损失函数是度量学习中常用的损失函数,难采样基于三元组损失函数进行改进.假设输入图像a和输入图像p为一对正样本对,输入图像a和输入图像n为一对负样本对.则三元组损失函数表示为:
Lt=(da,p-da,n+α)+
(18)
其中,(z)+表示max(z,0),da,p和da,n分别表示样本a分别与正样本p、负样本n之间的欧式距离,α是边距参数,用来表示阈值距离.如果三元组损失函数中的正负样本对都是简单易区分的,不利于网络的训练,因此选择难样本采样三元组损失函数进行模型训练,对于每个固定图像a在一个训练批次内选择距离最远的正样本图像p和距离最近的负样本图像n来训练网络,增强网络的泛化能力,从而使网络学习到更好的表征.
对于每一个训练组,随机挑选P个ID的行人,每个行人随机挑选K张不同的图片,即一个组含有P×K张图片.之后对于组中每一张图像a,挑选一个最难的正样本图像p和最难的负样本图像n和a组成一个三元组.定义和a为相同ID的图片集为A,剩下不同ID的图片图片集为B,则难采样三元组损失函数表示为:
(19)
其中batch为训练组,α为设定的阈值参数,本文选取为0.3.
为了使模型获取较好的训练效果,本文联合交叉熵损失函数和难采样三元组损失函数来共同作为所提出方法的损失函数,并采用级联方式分别进行训练,总体的损失函数的形式化描述如下为:
Lall=Lid+Lth
(20)
其中,Lall为联合损失函数,Lid为交叉熵损失函数,Lth为难采样三元组损失函数.
4 实验分析
4.1 数据集选取
选取行人重识别公开数据集CUHK03作为本次实验数据集.CUHK03数据集概况如表1所示.
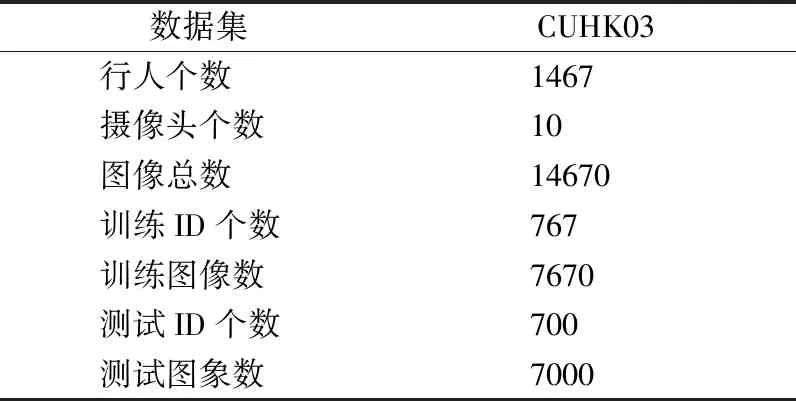
表1 CUHK03数据集简介Table 1 Introduction to the CUHK03 dataset
4.2 评价指标
4.2.1 Rank-k
Rank-k表示按照相似度排序后的前k张图像中,存在与查询图像属于同一ID的概率.本文实验中,选取Rank-1作为评价指标,即第1张图片与查询图像属于同一个ID的概率.
4.2.2 mAP
假设预测正确的样本数为TP,预测错误的样本数为FP.则精准率Precision定义为:
(21)
AP指平均精准度,指该类别图像的所有精准率的和除以含有该类别目标的图像数量,AP的表达式为:
(22)
其中nc为含有该类别目标的图像数量,M为返回的图像总数,Precisionc为第i个图像属于该类别的精准率.
mAP是模型在所有类别上预测的平均精准度,由于目标识别中有不止一个类别,因此需要对所有类别计算平均AP值.mAP的表达式为:
(23)
其中,C为总类别数,APk为第k类目标的平均精准度.
4.3 实验方案
为了验证行人重识别算法中注意力机制和随机擦除方法的有效性,设计如下两种方案:
方案1.通过初始化不同的随机擦除概率E,选取融入RGA-FC注意力模块的残差网络进行训练,对比不同随机擦除概率E下训练出的模型预测的精准度,选定一个最佳的随机擦除概率.
方案2.在同等训练环境下,将改进后的RGA-FC模块、ResNet-50基线网络和其他通道注意力机制进行对比,验证本文算法的有效性.
4.4 实验结果分析
在相同的训练环境下,基于本文提出的网络,通过调整不同的随机擦除概率E来测试模型,方案1实验结果如图6所示.从图6中可以看出,随机擦除方法对模型的准确度提升明显,随着随机擦除概率E的提升,模型预测准确率进一步提高,均高于未采取随机擦除方法训练出的模型.当擦除概率为0时,即对图像不进行随机擦除时,模型预测准确度较低,mAP和Rank-1分别只有62%和62.9%;采取随机擦除方法后,即使当设置擦除概率很小(0.1)时,训练出模型的预测效果比未采取擦除方法时均提高8个百分点以上.当擦除概率为1时,即对图像必定采取擦除方法时,模型预测准度虽有提升,但不是最佳预测结果,这是因为对所有输入图像某区域进行擦除时,由于擦除区域的不确定性,导致网络无法学习一个完整的行人图像,即无法获取输入图像的全局特征,导致提取不到关键特征,网络学习效果下降.总的来说,通过采用随机擦除方法对数据进行增强有助于提升模型预测结果,从图6中可以看出,当擦除概率E设置为0.9时,融合随机擦除算法和RGA-FC注意力模块训练出的模型预测效果最佳.因此,本文选取最佳的随机擦除概率E值为0.9作为实验参数.
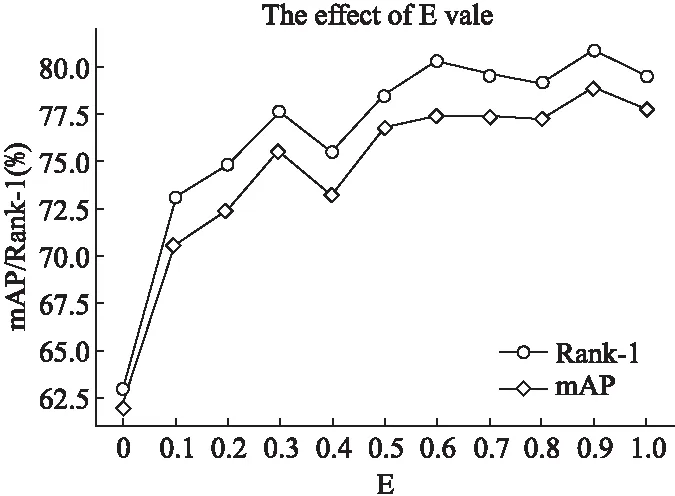
图6 概率E对实验效果的影响Fig.6 Influence of probability E on the experimental effect
方案2实验结果如表2所示.在CUHK03数据集上,本文提出的融合随机擦除的残差注意力模块将Rank-1提升至80.9%,将mAP提升至78.9%.相较于同样训练环境下的其他通道注意力模块,RGA-FC模块对通道内重要特征的有效表示和抑制冗余特征,从而提取出丰富且重要的通道信息,弥补了RGA-C通道注意力模块的不足,使模型预测准确率提升明显.

表2 方案2实验结果Table 2 Experimental results of program 2
本文基于ResNet-50神经网络,采用随机擦除方法模拟实际场景中行人被遮挡的现象,使模型泛化能力和精准度得到加强;在进行特征提取时,引入改进的通道注意力模块RGA-FC使模型提取到更具有判别力的行人特征;使用难采样三元组损失函数和交叉熵损失函数共同进行训练,提升了网络的识别能力和识别精度.通过实验结果对比可知,本文所搭建的融合随机擦除和改进的RGA-FC注意力模块的网络在行人重识别算法中具有较强的竞争性.
5 结束语
结合复杂的现实环境,提出一种融合随机擦除和残差注意力网络的行人重识别方法,改善了识别遮挡情形时行人重识别精准度低的问题,增强了模型的鲁棒性和泛化能力,可以应用于实际场景中有物体遮挡时的行人重识别.但是由于现实情况复杂多变,该算法在实际场景中虽改善了遮挡问题,但不良天候、光照等因素仍会使行人图像难以辨别,特别是在现实场景中,行人衣着等特征极易发生改变[20],快速准确识别特征改变后的行人使得行人重识别研究仍具有挑战性,因此还应结合不同实际场景做进一步的探索与研究.
