融合LightGBM与SHAP的糖尿病预测及其特征分析方法
2022-08-29孙瑞娜
王 鑫,廖 彬,李 敏,2,孙瑞娜,3,4
1(新疆财经大学 统计与数据科学学院,乌鲁木齐 830012)
2(新疆大学 信息科学与工程学院,乌鲁木齐 830008)
3(中国科学院 信息工程研究所,北京 100093)
4(中国科学院大学 网络空间安全学院,北京 100093)
E-mail:liaobin665@163.com
1 引 言
目前,医疗领域是人工智能技术发展相对较快的一个领域,科技型公司推出医疗人工智能产品,传统的医疗企业也大量引入人工智能专业人才和技术,人工智能在医疗领域的应用范围得到不断的拓宽,“智慧医院”,“数字诊疗”等成为医疗新方向.机器学习是当下最炙手可热的人工智能技术,各类预测算法被广泛应用于医疗大数据,有利于对各种疾病进行探测[1,2]、诊断[3,4]、治疗[5]和管理[6,7]工作.
糖尿病严重危害着人们的身体健康,是一种常见的慢性疾病,根据国际糖尿病联盟协会(IDF)的数据统计:2019年全球大约有4.63亿成年人(20岁~79岁)患有糖尿病;已经导致420万人死亡(1)https://www.idf.org/aboutdiabetes/what-is-diabetes/facts-figures.html,其中中国作为世界上糖尿病患病人数最多(大约1.16亿人)的国家,如果能够充分利用机器学习算法提高糖尿病预测模型的性能表现以及模型的可解释性,这对于辅助医生进行糖尿病诊断工作具有重要的现实意义.虽然目前已有不少这方面的研究工作,例如基于支持向量机(SVM)[8,9]、朴素贝叶斯[10]、决策树[10-12]、深度神经网络(DNN)[13]、随机森林[14,15]、Xgboost[16]等的机器学习模型,分别在皮马印第安人糖尿病数据集、加拿大保健预防监测中心等数据集上建立了预测模型,但是这些传统模型在准确率(Accuracy)、精确率(Precision)等性能指标上基本都在90%以下,还未达到投入临床应用的性能要求.在此背景下,为了进一步提高对糖尿病预测的准确率、精确率、召回率(Recall)、F1值等性能指标,本文基于集成学习LightGBM算法,使用美国国家糖尿病、消化及肾脏疾病研究所提供的皮马印第安人糖尿病数据集(Pima Indians Diabetes Data Set,以下简称Pima糖尿病数据集)作为研究对象,在对其进行数据预处理、模型训练、超参数优化、泛化能力分析、模型性能分析、模型解释等工作的基础上,建立了性能更为出色的预测模型.本文工作主要集中在以下3个方面:
1)基于LightGBM算法建立了糖尿病预测模型,并通过对比实验,比较了其他模型在准确率、精确率、召回率(Recall)、F1值等指标上的表现,验证了本文模型的性能优越性.
2)通过网格搜索技术对模型超参数进行调优,进一步提高模型性能表现,同时通过对比各模型的学习曲线,证明了本文模型在样本量较少时,同样拥有不错的泛化能力.
3)在利用LightGBM算法保证预测性能的基础上,为了增强模型的可解释性,基于SHAP模型对影响糖尿病的关键因素进行了分析,为糖尿病的医疗诊断提供了决策参考.
2 相关研究
近年来,随着信息科技化的不断发展,国内外学者致力于利用机器学习算法辅助医疗诊断,对糖尿病预测研究方面进行深入探索,提出的部分预测模型及其在实验当中的表现效果汇总如表1所示.其中,Annja等[8]提出一种基于SVM的糖尿病预测模型,在Pima数据集上进行验证工作,模型的准确率达到78%.Aiswarya等[10]分别使用决策树和朴素贝叶斯两个模型对糖尿病的诊断进行分类,同样应用在Pima糖尿病数据集上,决策树和朴素贝叶斯的分类准确率分别为74.8%和79.5%.与文献[10]类似,Ashiquzzaman等[13]利用深度神经网络(DNN)训练预测模型,在Pima数据集上将模型准确率指标提升到88.41%.
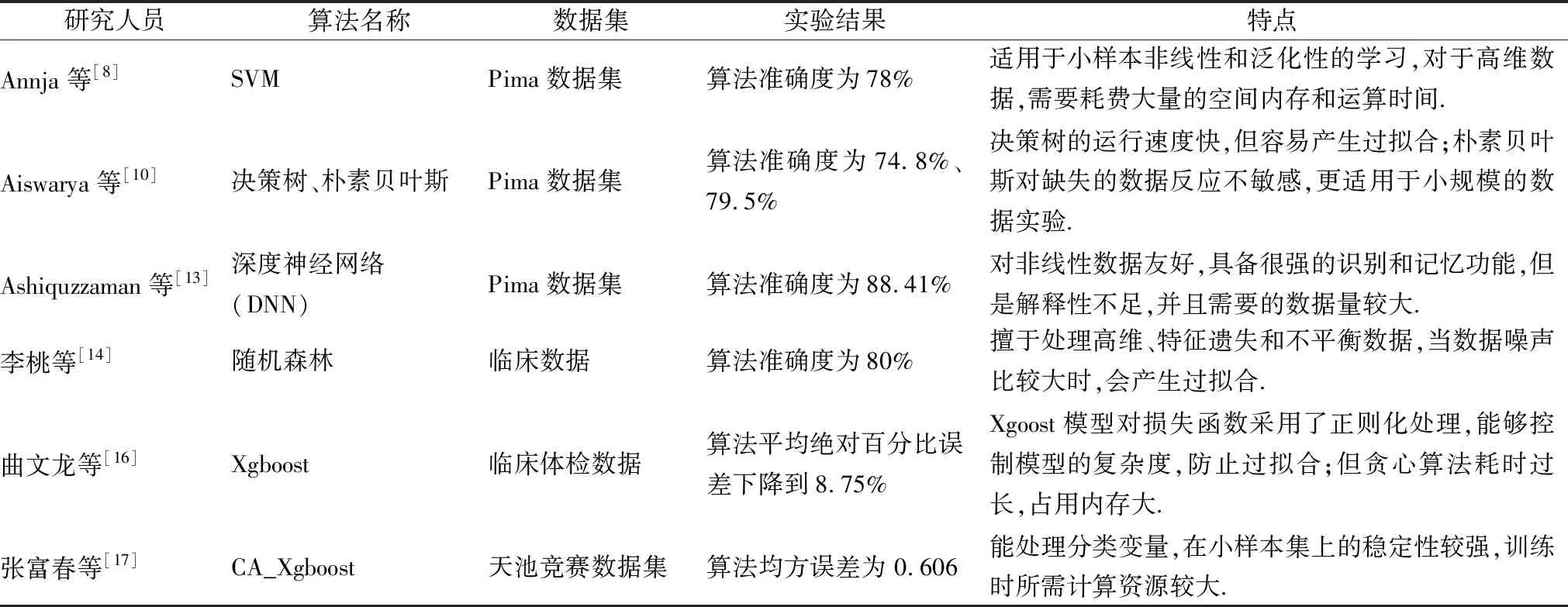
表1 已有分类算法相关研究综合比较Table 1 Comprehensive comparison of classification algorithms
李桃等[14]基于随机森林(RandomForest),在上海交大第六人民医院的2型糖尿病临床数据上建立预测模型,预测精度为80%,优于传统的逻辑回归算法.曲文龙等[16]采用Xgboost算法作用到6000多个体检人员的真实糖尿病体检数据中,对比SVM和随机森林的平均绝对百分比误差下降到8.75%.张富春等人[17]在原有集成算法Xgboost的基础上,利用遗传算法调参得到改进模型GA_Xgboost模型,对天池竞赛平台提供的糖尿病临床数据进行血糖值预测,算法的均方误差优于其他机器学习算法的同时缩短了调参时长.2016年Perveen[18]等对比分析了bagging与boosting两类集成学习算法,在加拿大保健预防监测中心的数据集上的效果,结果发现adaboost优于bagging算法.已有基于集成算法的工作相比传统的机器学习模型,在准确率、精确率等性能表现上更为出色,但是同样也存在两个方面的问题:1)由于模型复杂度增加,当数据样本量不足时,容易出现模型泛化能力较差的现象;2)诸如文献[14-16,19]中采用的诸如Xgboost、随机森林等集成学习,以及文献[13]中的深度神经网络均为黑箱机器学习模型,这使得建立的预测模型缺乏可解释性.
为了解决已有研究中存在的以上两点问题,本文在用LightGBM算法保证预测性能的基础上,引入SHAP增强模型的可解释性.本文与已有的研究工作不同之处在于:1)预测模型不同,其中文献[8-10]都是以Pima数据集为研究对象,采用SVM、决策树、朴素贝叶斯以及深度神经网络作为预测模型,本文基于集成学习的LightGBM算法在准确率等性能指标上性能更优;2)由于文献[14-16]中均为黑箱的机器学习模型,对建立的预测模型缺乏可解释性,为了解决这一问题,本文通过引入SHAP模型,能够对患糖尿病的影响因素进行分析,为糖尿病诊断建议提供了决策参考.
3 模型构建方法
本章3.1节对LightGBM算法原理进行概述,3.2节对SHAP模型进行了介绍,阐述了基于LightGBM的糖尿病风险预测及特征分析模型的实现过程,本文所用到的符号及其解释如表2所示.

表2 符号说明表Table 2 Symbol description
整个基于LightGBM的糖尿病风险预测及特征分析模型的构建流程如图1所示,主要包括数据处理、模型训练、超参数优化、模型性能比较分析、模型解释分析等核心模块.

图1 糖尿病风险预测及特征分析模型流程图Fig.1 Flow chart of diabetes risk prediction and characteristic analysis model
3.1 模型构建流程
本实验选取LightGBM算法对Pima数据集进行是否患有糖尿病进行分类预测建模,轻量级梯度提升树(Light Gradient Boosting Machine,LightGBM)是一种基于决策树的梯度提升框架,起源于微软亚洲研究院在NIPS发表的系列文献[20,21].其优点包括计算准确率高、运行速度快、支持并行处理、占用内存少和适用于大规模数据处理等,相较于现有的集成算法Boosting在模型的精度表现和运算速度上都有较大的提升,目前被广泛地应用到排序、分类等多种机器学习任务中,且表现优异.
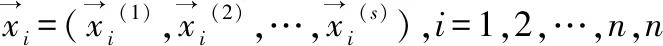
GOSS(Gradient-based One-Side Sampling)算法主要是基于训练梯度的样本采样,其主要思想是保留了所有大梯度样本,同时对小梯度样本进行采样,目的是用于减少训练样本的数量.采用原始的直方图算法计算节点的信息增益:令O为决策树在一个固定节点上的训练数据集,此节点在值为d处分割特征j的信息增益定义为:
(1)
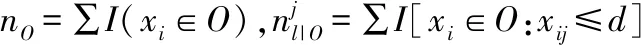
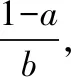
(2)
其中A是大梯度样本集,B是小梯度样本集当中随机采样的结果,Al=xi∈A:xij≤d表示左子节点被保留的重要样本集合,Ar=xi∈A:xij>d表示右子节点被保留的重要样本集合;Br=xi∈B:xij≤d表示左子节点被保留的不重要样本集合,Br=xi∈B:xij>d表示左子节点被保留的不重要样本集合,糖尿病预测模型训练算法流程如算法1所示.
算法1.Prediction model training algorithm
输入:
Parameter1:I:训练数据,d:迭代步数
Parameter2:a:大梯度数据的采样率
Parameter3:b:小梯度数据的采样率
Parameter4:loss:损失函数,L:弱学习器
输出:
Parameter:训练好的模型
1.models←{}
3.topN←a×len(I)
4.randN←b×len(I)
5.fori=1 toddo
6.preds←models.predict(I)
7.g←loss(I,preds)
8.w←{1,1,…}
9.sorted←GetSortedIndices(abs(g))
10.topSet←sorted[1:topN]
11.randSet←RandomPick(sorted[topN:len(I)],rand(N)
12.usedSet←topSet+randSet
13.w[randSet]×=fact//Assign weight fact to the small gradient data.
14.newModel←L(I[usedSet],-g[usedSet],w[usedSet])
15.models.append(newModel)
16.returnmodels
3.2 SHAP模型
基于LightGBM算法进行训练可以得到预测精度较高的预测模型,但是LightGBM相较于传统的统计模型,在模型的可解释性方面表现较差,几乎是一个黑箱模型.因此,本文采用SHAP值对模型中对糖尿病的影响因素进行解释分析,用来增强模型的可解释性.SHAP模型第一次出现在2017年,Lundberg和Lee[22]提出了SHAP值这一广泛适用的方法,用以解释各种模型(分类以及回归),特别是难以理解的黑箱模型.SHAP值的作用主要是用于量化每个特征对模型预测所做的贡献,源自博弈论中Shapley value.其基本的设计思想是:首先计算一个特征加入到模型当中时的边际贡献,然后计算该特征在所有特征序列中不同的边际贡献,最后计算该特征的SHAP值,即该特征所有边际贡献的均值.
假设第i个样本为xi,第i个样本的第j个特征为xij,特征的边际贡献为mcij,边的权重为wi,其中f(xij)为xij的SHAP值,例如第i个样本的第1个特征的SHAP值计算如下:
f(xi1)=mci1w1+…+mci1wn
(3)
模型对该样本的预测值为yi,整个模型的基线(通常是所有样本的目标变量的均值)为ybase,那么SHAP value服从以下等式:
yi=ybase+f(xi1)+f(xi2)+…+f(xis)
(4)
f(xi,1)就是第i个样本中第1个特征对最终预测值yi的贡献值,每个特征的SHAP值表示以该特征为条件时模型预测的变化.对于每个功能,SHAP值都说明了其所做贡献,以说明实例的平均模型预测与实际预测之间的差异.当f(xi,1)>0,说明该特征提升了预测值,反之,说明该特征使得贡献降低.LightGBM利用传统的Feature Importance只能反映出特征的重要程度,但并不清楚该特征对预测结果的具体影响力.SHAP值计算的最大优势就在于能够反映出样本中每一个特征对预测结果的影响力,而且还可以指出其影响程度的正负性.
4 模型构建及对比实验
4.1 模型评价指标
本文主要采用5项常见的分类性能指标来评估模型的优劣,分别是准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值和AUC值.其中准确率(Accuracy)作为最基本的一个评价指标,是针对所有样本而言,预测分类正确所占总体的百分比,公式表达见公式(5).精确率(Precision)是仅针对预测结果而言的指标,分类为正类的样本中预测分类正确所占的百分比,见公式(6).召回率(Recall)是针对原始样本而言,真实的正样本中预测分类正确所占百分比,也被称为查全率,其计算表达见公式(7).F1值是一个综合了Precision与Recall产出结果的指标,取值范围从0~1,其中1代表模型的输出最佳,反之,0代表模型的输出结果最差.通常将关注的类作为正类,其余类为负类,分类器在测试集数据上预测是否准确,可通过如表3所示的混淆矩阵进行表示.

表3 分类结果混淆矩阵Table 3 Confusion matrix of classification results
Accuracy、Precision、Recall和F1值作为评价指标具体公式如下:
(5)
(6)
(7)
(8)
除了上述的4个评价指标之外,还用到了一些综合指标来评价模型性能,本文用到ROC曲线和AUC值.受试者工作特征曲线(Receiver Operating Characteristic Curve,ROC)利用混淆矩阵中的参数,逐步增大分类阈值,通过计算真正例率(TPR)和假正例率(FPR),绘制而成,其中:
TPR(TruePositiveRate)=TP/(TP+FN),即将正例分为正例的概率.
FPR(FalesPositiveRate)=FP/(FP+TN),即将负例分为正例的概率.
AUC值(Area Under Curve)是ROC曲线下方的面积总和,AUC值越大,表示模型的精度也越高.
4.2 特征工程
本实验的Pima数据集来源于美国国家糖尿病、消化及肾脏疾病研究所所提供的美国亚利桑那州中南部的皮马印第安人糖尿病数据集(Pima Indians Diabetes Data Set).该地区拥有较为详细的糖尿病数据资料的原因,是因为该种族是糖尿病的高发人群,有超过30%的皮马人都患有糖尿病.Pima糖尿病数据集一共有8个特征和1个标签,共768例样本,数据基本特征属性如表4所示.
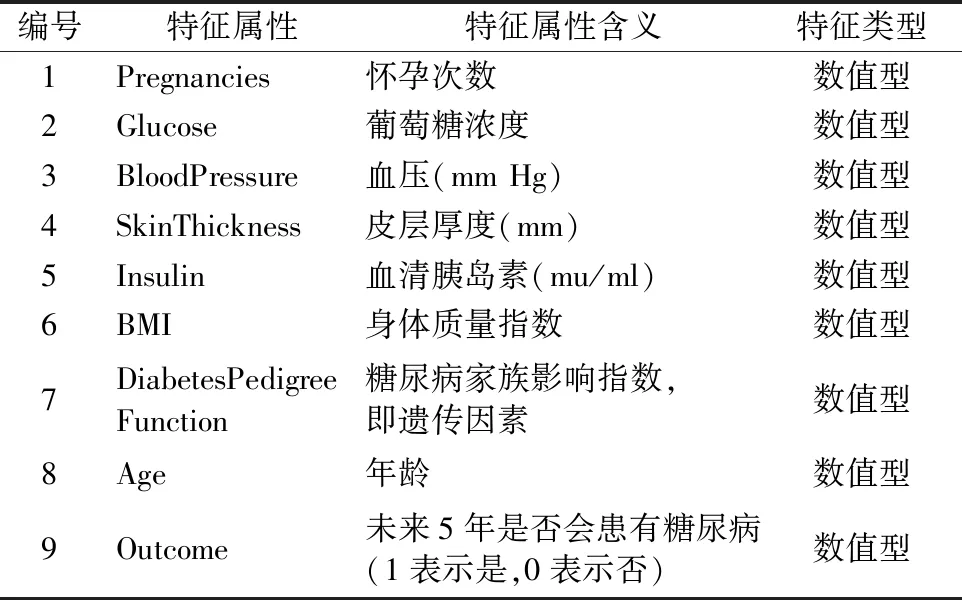
表4 Pima 数据基本特征Table 4 Basic characteristics of Pima data
在Pima数据集中268例被诊断为患有糖尿病,占总体的34.9%,500例不患糖尿病患病,占总体的65.1%.使用python当中pandas库describe函数对糖尿病原始数据进行描述性统计分析,结果如表5所示.可以发现,各特征字段存在缺失值、数量不一、单位不同,均值和方差相差甚远,数据预处理作为机器学习应用过程中不可或缺的环节,关系着实验结果的好坏,因此需要对糖尿病数据进行缺失值填充、异常值分析、数据变换、数据标准化等特征工程操作.

表5 糖尿病数据描述性统计Table 5 Descriptive statistics of diabetes data
1)缺失值填充
糖尿病数据进行缺失值可视化处理,结果见图2,白色代表数据缺失,全为黑色则表示特征完整,白色相对黑色占比越多证明缺失情况越严重.可以看出特征Glucose、BloodPressure、BMI、SkinThickness和Insulin都存在缺失,其中SkinThickness和Insulin缺失程度较大,高达29.6%和48.7%,其他特征没有缺失值.对于缺失特征的填充工作,按照病人是否患有糖尿病进行中位数填充,将数据分为患病和不患病两类,根据患病类别的中位数和不患病类别的中位数进行分开填充.
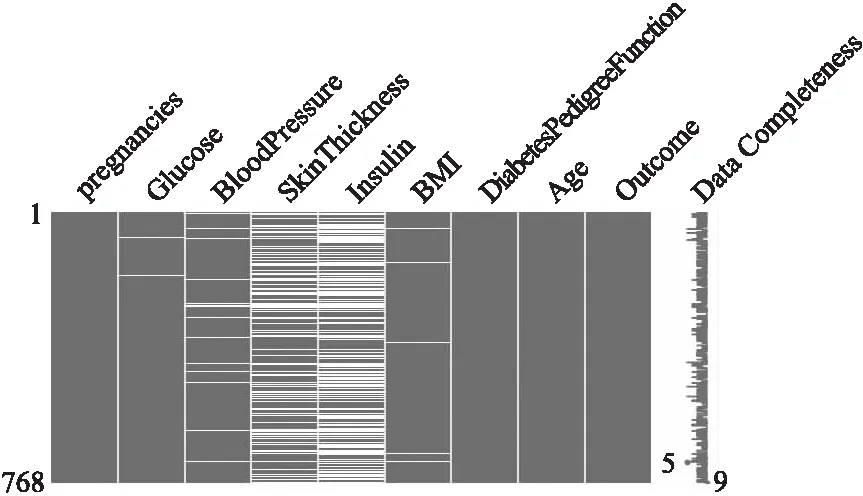
图2 特征缺失情况Fig.2 Feature missing
2)异常值分析
采用数字异常值(Numeric Outlier)方法筛选数据中的异常值,通过IQR(Inter Quartile Range)计算得到四分位数间距,将四分位数之外的数视为异常值.为了给异常值同时也是真实值保留一定的缓冲空间,将异常值较多的特征进行数据变换处理.
3)数据标准化
由于各个属性特征的单位不同,为了消除由于单位不同的影响,解决不同属性之间的差异性和不可比性,需要在实验前对数据进行标准化处理,由于Pima数据集中存在的离群值较多,所以使用稳健标准化(RobustScaler)对数据进行标准化处理,能够最大限度地保留数据集中的异常值(离群点),根据四分间距(IQR)缩放数据,来弱化异常值的影响.RobusScaler的计算方法如下:
(9)
其中,vi表示数据集中的某个值,median表示数据的中位数,IQR是数据的四分间距值.标准化后的数据为如表6所示.
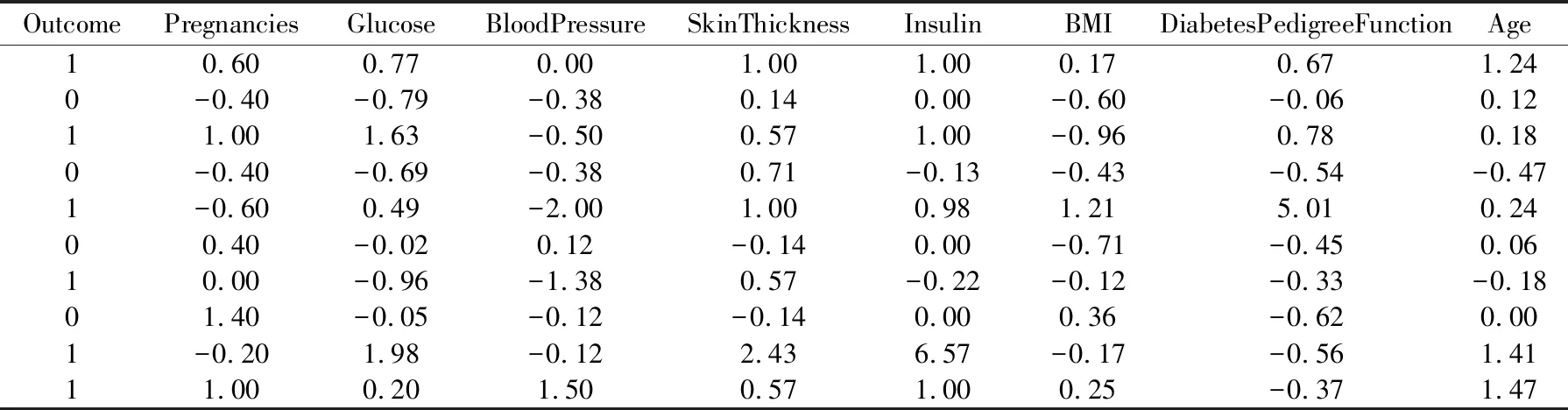
表6 标准化后的Pima数据Table 6 Standardized Pima data
4.3 与已有工作的实验对比
本节将本文的LGBM与已有的基于逻辑回归(LR)[23]、KNN、SVM[8]、随机森林(RF)[14]、决策树[10]以及Xgboost[16]6种模型进行对比.为了提高模型之间对比的公平性及可靠性,实验中采用了十折交叉验证方法进行性能评估,如图3所示为以Accuracy值作为评价指标并绘制箱型图,初步查看预测精度的分布情况,LGBM模型比已有工作中的6种模型要高.

图3 箱型图比较Fig.3 Comparison of box diagrams
本实验采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值和AUC值5项常用的评价指标来评估模型的优劣.表7和图4是上述7种算法加上PLGBM(参数优化后的LGBM,请参见4.4节)的各项评价指标综合对比结果.

表7 模型性能对比Table 7 Performance comparison of model

图4 各算法性能对比Fig.4 Performance comparison of various algorithms
根据表7和图4的实验结果可知,其中LGBM的预测准确率为90.9 %,精确率为88.6%,召回率85.4%,F1值为87%,AUC值为0.96,PLGBM在准确率、精确度、F1值和AUC值上都有提高.相比其他机器学习算法,集成类算法RF、Xgboost、LGBM在预测准确率上表现更好,都在90%以上,体现了集成算法的优越性.LGBM在各项性能上与Xgboost算法最为接近,但LGBM表现更优,性能提高约0.3%~2.1%,参数优化后性能提高约0.3%~4.5%,原因在于LGBM保留了小样本的信息增益,并且还具有支持高效并行的优势;Xgboost的预排序算法不同于GOSS采样策略,需要遍历每一个特征值,并且每遍历一次都会根据需要进行一次分裂增益的计算,预排序后还需要记录特征值及其对应样本的统计值索引,而 LGBM 使用了直方图算法将特征值转变为bin值,且不再需要记录特征到样本的索引,并且在训练过程中采用互斥特征捆绑算法减少了特征数量,将空间复杂度从O(2×#data)降低为O(#bin),极大地减少了内存的消耗.由此可见,在7个算法中,LGBM的结果更为准确,且占用内存更低,运行速率更快,其稳定性也相比其他算法更加优秀.
4.4 模型参数优化及泛化能力分析
LightGBM有6个核心参数,不同的参数具有不同的功能,这些参数是否设定合理,直接影响模型的好坏,传统的调参方法依赖经验判断和遍历实验,本文结合传统方法和网格搜索方法,帮助确定最佳参数如表8所示.
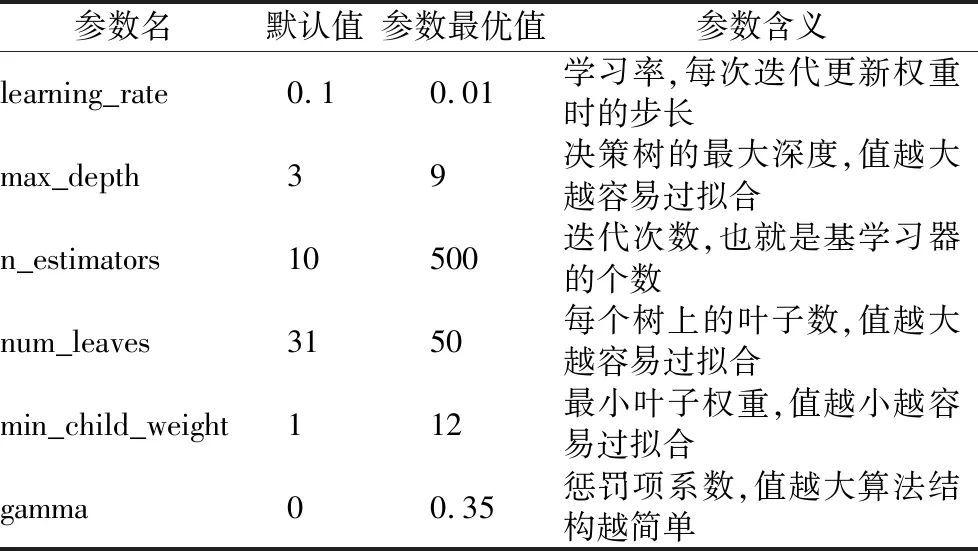
表8 LightGBM最优参数及默认值Table 8 LightGBM best parameters and default values
将标准化后的Pima数据中的614条用作训练数据集,剩余的154条作为测试集,对比LGBM的默认参数组合和调参实验过后的最佳参数组合,对患者未来5年内是否会患糖尿病进行预测.实验结果显示,调参过后的PLGBM模型精确度提升至91.6%,明显优于默认参数下的精确度90.9%,模型的ROC曲线比较如图5所示.

图5 LightGBM算法调参前后ROC曲线比较Fig.5 Comparison of ROC curves before and after parameter tuning
判断模型是否好,除了在训练集上表现良好,还要在交叉验证中具有良好的泛化表现,对新鲜的样本具有适应能力.本节主要通过学习曲线来分析来对模型进行收敛分析,图6为LightGBM与其他模型学习曲线的对比,其中包括KNN、SVM和Xgboost的学习曲线.
从图6中可以发现4种算法从拟合趋势上看,随着样本量的不断增大,模型的交叉验证分数呈逐渐增加的趋势,测试得分只有Xgboost出现性能略微下降的现象.而Xgboost与LightGBM模型在任何样本量情况下,拟合情况与其他两个算法都存在差距,拟合效果都要优于KNN和SVM.从拟合趋势上看,随着样本量的不断增大,LightGBM逐步趋于稳定,并且模型能够达到更优的拟合效果.

图6 LightGBM 与各分类模型的学习曲线对比Fig.6 Performance comparison of LightGBM with Kr 、SVR and Xgboost
4.5 基于SHAP的模型解释分析
图7显示了SHAP摘要图,该图根据要素对影响是否患有糖尿病的因素重要性进行排序.从图7可以看到:Insulin(血清胰岛素)、Glucose(葡萄糖浓度)、Age(年龄)、BMI(身体质量指数)、DiabetesPedigreeFunction(糖尿病家族影响指数,即遗传因素)等特征的差异对模型的影响较显著,并且这些因素对患有糖尿病都具有负面影响,随着该值的增加,患有糖尿病的风险越大.
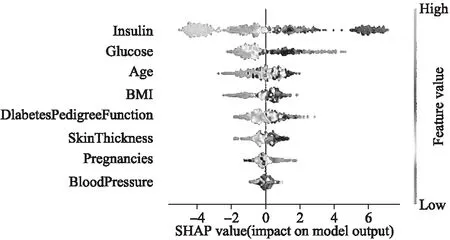
图7 SHAP特征分析Fig.7 Feature analysis
图8根据更改模型当中的特定特征,在x轴绘制了特征的值,在y轴上绘制特征的SHAP值,进行SHAP特征依赖分析,分别选取了Insulin(血清胰岛素)、Glucose(葡萄糖浓度)、Age(年龄)、DiabetesPedigreeFunction(糖尿病家族影响指数,即遗传因素)作为指定特征绘制图像.在图8中,Insulin(血清胰岛素)、Glucose(葡萄糖浓度)、Age(年龄)和DiabetesPedigreeFunction(糖尿病家族影响指数,即遗传因素)都随着值的增加SHAP值也随之增加,对促成糖尿病具有正向影响.
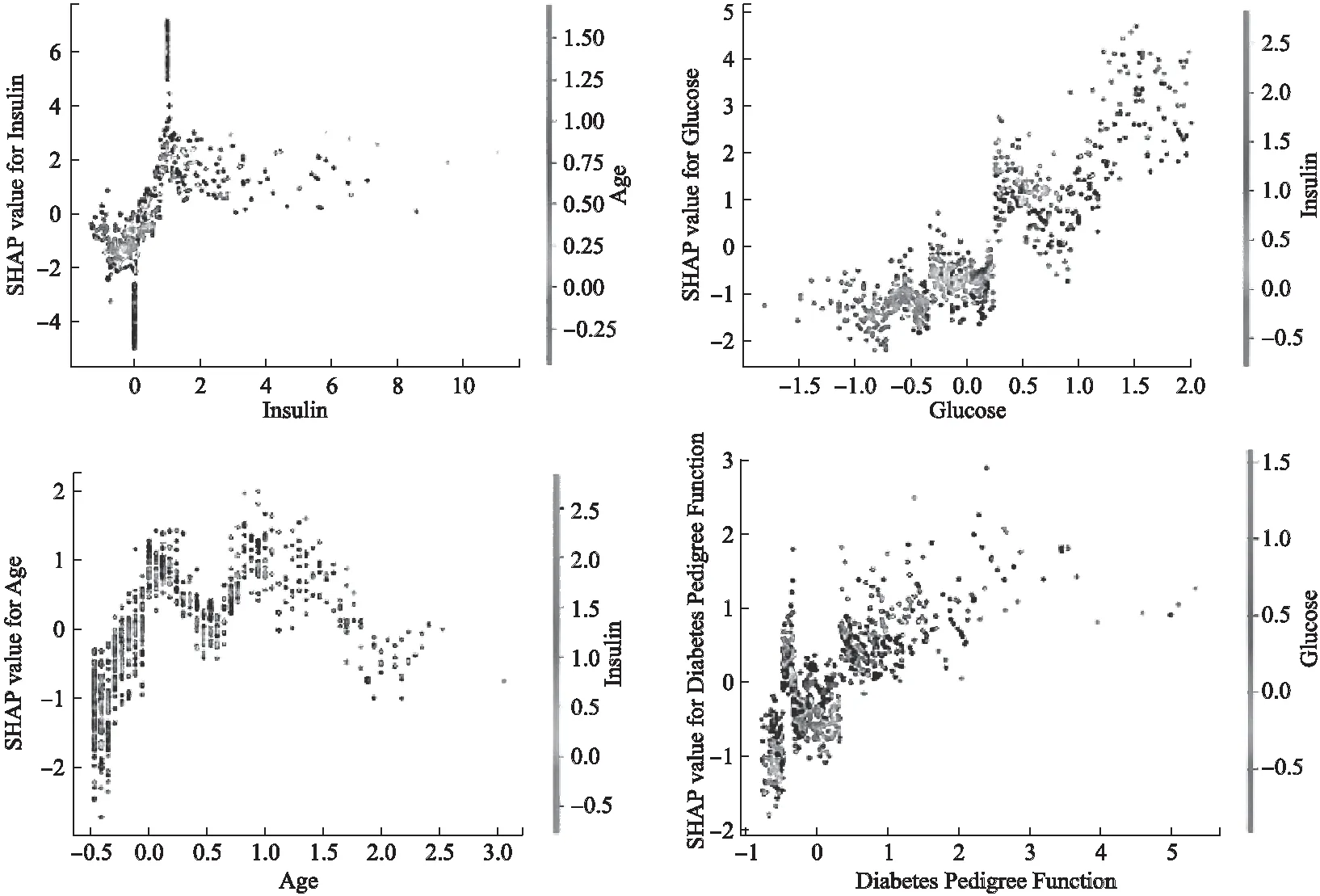
图8 SHAP特征依赖分析Fig.8 Feature dependence analysis
根据图9,SHAP模型、LightGBM模型和Xgboost模型的特征重要性排序可以看出,排名的特征顺序并不完全相同,可以得出影响是否患有糖尿病的关键因素包括:Insulin(血清胰岛素)、Glucose(葡萄糖浓度)、Age(年龄)、DiabetesPedigreeFunction(糖尿病家族影响指数,即遗传因素)、BMI(身体质量指数)以及SkinThickness(皮层厚度).其中3种算法都将Insulin(血清胰岛素)、Glucose(葡萄糖浓度)、Age(年龄)排在了前3位,可见这3个因素是影响是否患有糖尿病最关键的因素,胰岛素和葡萄糖浓度正是糖尿病的重要参考指标,研究结果表明,血清胰岛素、葡萄糖浓度是糖尿病血糖监测的重要临床指标,也是诊断患者是否患糖尿病的重要依据,如果空腹血糖大于7.0mmol/L或餐后两小时血糖大于11.1mmol/L,就存在患病的可能[24].年龄的因素应该也要列入医疗诊断的考虑当中,糖尿病的发病率还会随着年龄的增长而增长.其次DiabetesPedigreeFunction(糖尿病家族影响指数,即遗传因素)、BMI(身体质量指数)以及SkinThickness(皮层厚度),其重要程度在LightGBM和Xgboost算法中排名均在前,此外其他因素需要在诊断时进行综合分析.

图9 特征重要性(分别是SHAP、LightGBM、Xgboost)Fig.9 Feature importance(Respectively SHAP,LightGBM,Xgboost)
5 结论及下一步工作
中国作为糖尿病患病人数最多的国家,利用机器学习算法提高糖尿病预测模型性能及可解释性,对于辅助医生的诊断工作具有重要的现实意义.在此背景下,为了进一步解决已有基于集成算法的相关工作中存在的泛化能力不足以及解释力不强的问题,本文基于LightGBM算法构建糖尿病预测模型,同时引入SHAP模型进一步增强模型的可解释性.首先,在对Pima糖尿病数据集进行特征工程的基础上,将处理后的数据作为LightGBM训练模型的输入,将训练后的模型用于预测是否患有糖尿病;然后,通过网格搜索方法寻找LightGBM算法的最优参数,并且通过与逻辑回归(LR)、KNN算法、SVM、随机森林(RF)、决策树以及Xgboost等六种机器学习模型的对比实验,证明了LightGBM算法的有效性.最后利用SHAP模型进行特征解释分析,同时通过Xgboost和LightGBM的特征重要性排序,识别出了影响患糖尿病的关键因素是Insulin(血清胰岛素)、Glucose(葡萄糖浓度)、Age(年龄)、DiabetesPedigreeFunction(糖尿病家族影响指数,即遗传因素)、BMI(身体质量指数)以及SkinThickness(皮层厚度);模型可解释性的增强、预测性能的提高,对降低机器学习辅助诊断糖尿病的误诊率,提高诊断效率,具有重要的应用价值.
下一步工作主要是将模型推广到临床实践场景,并根据真实应用场景的需求,对特征工程、模型训练、超参数优化、误差及偏差分析等内容进一步优化.
