融合深度学习和知识图谱的金融时间序列建模与预测
2022-08-29蒋慧敏
蒋慧敏,陈 锋
(中国科学技术大学 信息科学技术学院,合肥 230027)
E-mail:jianghm@mail.ustc.edu.cn
1 引 言
金融时间序列预测是以金融市场中时间序列变量作为数据和研究对象,构建数学模型以分析市场的变动规律,并对未来市场的动态变化进行预测的研究[1].金融时间序列预测由于其广泛的应用领域和巨大的影响,无疑是学术界和金融界金融研究人员的首选计算智能.
传统的时间序列预测方法主要是在确定时间序列参数模型的基础上得出模型参数,并利用求解出的模型完成预测工作.这种建模与预测方式不能较好地适应多元的大数据时间序列分析[2].目前利用深度学习模型,如长期短期记忆模型(Long Short-Term Memory,LSTM)等,可拟合更为复杂的数据进行时间序列预测.但是,这些模型缺少学习数据隐含的语义信息,导致预测结果不够准确,而且预测的结果往往缺乏可解释性.知识图谱的应用场景非常广泛[3],可以实现语义层面的特征搜索泛化,提升预测结果的可解释性.然而,现有的研究缺少将深度学习和知识图谱技术相融合来进行时间序列建模与预测的统一框架.因此,融合深度学习、知识图谱技术并应用到特定的时间序列预测与分析是一个有益的尝试.
考虑到金融时间序列拐点识别算法可有效感知重要点(Perceptually Important Points,PIP),对金融时间序列识别其局部趋势特征具有重要作用[4].本文采用Zigzag指标识别金融时间序列的重要点,从而减少噪声,有助于更加关注行情局部趋势特征和交易行为.
在实践中,金融产品之间的相关性是不可忽视的因素[5].例如,某控股公司的子公司或与其关系密切的公司,其股价走势可能具有一定的相关性.另外,在股票交易中,投资者会面临或大或小的风险,而股指期货则利用一种达成协议的方式使两者的风险对冲实现盈利[6],因此,在构造算法交易策略时通常会关注股指期货和现货市场波动的相关性.本文使用知识图谱及相关技术挖掘金融产品之间的相关性.首先,通过融合市场交易等信息来构建金融知识图谱,并使用TransR模型将实体投影到对应的关系空间中.然后,通过计算实体向量之间的欧氏距离选择与目标股票相关的金融产品,并将其特征与感知重要点等K线指标信息进行拼接融合.该方法的优点是充分考虑了现实中金融产品之间的内在相关性,避免了仅使用个股价格数据来进行预测的局限性.
在预测模型方面,考虑到获得标的金融产品及其相关的特征数据可看成时间序列数据,本文将上述这些信息作为基于注意力机制的双向长短期记忆网络(Bidirectional Long-Short Term Memory Network,BiLSTM)模型的输入,通过对模型进行训练与测试,得到了较优的预测结果.
论文的其余部分安排如下:第2节简要回顾了金融时间序列趋势预测的相关研究;第3节对本文所研究的问题进行了分析与界定;第4节详细讨论了所提出的预测模型;第5节给出实验设置和结果分析;第6节对论文进行了总结与展望.
2 相关工作
金融时间序列预测及其相关应用已被广泛研究多年.在这些研究中,针对特定的金融时间序列,尤其是对股票市场和期货市场的预测最受关注.
传统时间序列模型一般需要严格的数学原理作为支撑,并需要较严格的条件加以约束,从而借助外推原则来推测未来变化[7],例如自回归综合移动平均模型[8]、广义自回归条件异方差模型[9]和平滑转移自回归模型[10]等方法.然而,在实际的金融市场中的时间序列数据通常很难满足这些方法所需的平稳性、正态性等假设要求.
金融数据本质上是时间序列的多维向量,深度神经网络能够通过高维特征的非线性变化获得相比于传统方法更好的表达能力[11].考虑到LSTM在时间序列预测问题上表现良好[12],并在金融预测方面可能比传统的循环神经网络有更好的效果.文献[13]利用LSTM对中国股票收益率进行了建模和预测,与随机预测方法相比LSTM模型的预测精度从14.3%提高到27.2%.文献[14]采用将小波变换、堆叠式自动编码器与LSTM相结合,对股票价格进行预测,有效地提高了模型的性能.此外,传统的神经网络模型没有考虑模型输入与输出之间的相关性,于是文献[15]将注意力机制加入长短期记忆模型,提出了一种基于注意力的金融时间序列预测模型AT-LSTM,有效地解决了时间序列预测的长期相关性问题,并提高了基于神经网络的时间序列预测方法的可解释性.
使用Zigzag指标预测金融时间序列走势是K线特征趋势算法交易模型的关键技术之一.文献[16]使用Zigzag技术指标来发现识别金融数据短期趋势的兴趣模式(motif),可以获得较高的预测精度和投资收益.受Zigzag技术指标在分割数据并发现motif方面应用的启发,本文在特征识别中引入Zigzag指标,以帮助深度神经网络训练过程中减少相同趋势之间的差异,扩大不同趋势之间的差异.
另外,鉴于金融市场的复杂性,在预测价格走势时,许多研究者考虑了金融产品之间的相关性.文献[17]提出了一种耦合随机游走模型来度量股票之间的相关性.文献[18]将股票价格序列作为维纳过程,用两个维纳过程之间的相关性取代股票之间的相关性.这些方法只利用已知的股票价格时间序列数据,仅从数据的角度来衡量相似性,缺乏语义信息和可解释性.近年来,使用知识图谱将外部信息整合到学习过程中来生成事件表示,以学习外部市场信息对金融价格走势的影响.文献[19]提出了一种基于异构信息融合的股市预测改进方法,通过构造股票运动张量来模拟股票、事件和情绪之间的内在关系,通过对中国A股和港股数据的评价表明了模型的有效性.但在实际趋势预测问题上,外部市场之间的关系是复杂的,现有研究没有充分考虑行情局部趋势特征模式和交易行为相关性分析.
3 问题描述
预测未来短期交易日的金融标的价格走势可以帮助投资者进行交易决策时获得更高的交易回报率.它可以分为两个子问题:1)交易回报和趋势是什么;2)如何进行建模与预测.本小节首先定义价格变化的回报函数和趋势变动函数,然后给出需要预测的问题.
3.1 交易回报和趋势定义
实际操作中,由于交易成本的原因,许多场景下并不需要准确地知道下一个分析周期的价格(收盘价),只需知道被观测市场的走向(升、降或平稳),从而决定下一步的交易操作(长期/短期-买入/卖出).本文主要研究金融K线历史数据预测将来中短期内的价格走势.
我们利用未来n个K线交易周期收盘价与当前K线收盘价之差和当前K线收盘价的比值来定义价格回报函数.
(1)
其中,HHV(X,n)函数为求n周期内X最高值,例如:对日K线来说,HHV(HIGH,5)表示求从当前日起未来5日内最高价.CLOSE函数返回当前K线收盘价.
据此,给出价格趋势变动函数trend,如公式(2)所示:
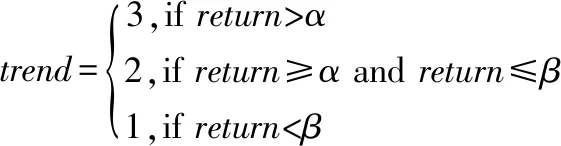
(2)
其中,trend代表当前的价格变动趋势,α和β分别表示价格向上变动幅度和向下变动幅度的阈值.
也就是说,我们将金融时间序列的涨跌趋势分为上涨(类别3)、平稳(类别2)、下跌(类别1)3种情况.α和β的值根据投资者的需求设定,如果取α=β=0.5,类别3代表未来n个K线交易周期存在投资回报率超过5%以上交易可能,类别2代表未来n个K线交易周期成交回报率均小幅振荡在-5%~+5%之间,类别1代表未来n个K线交易周期成交价均下跌超过5%.本文将收盘价作为一个交易日的价格,然后形成几个交易日的价格序列,并根据趋势的定义分类标注.
3.2 预测问题

(3)
(4)
其中n是参与训练数据的长度,m是趋势分类数.
4 融合深度学习和知识图谱的金融时间序列预测模型
本文基于金融量化数据,综合运用重要点识别和知识图谱相关技术来预测金融时间序列的涨跌趋势,本文提出了一种融合深度学习和知识图谱的面向局部特征模式的金融时间序列预测模型(Fusion Deep Learning and Knowledge Graph Forecasting Model based on Zigzag,ZKG),所提模型的总体框架如图1所示.
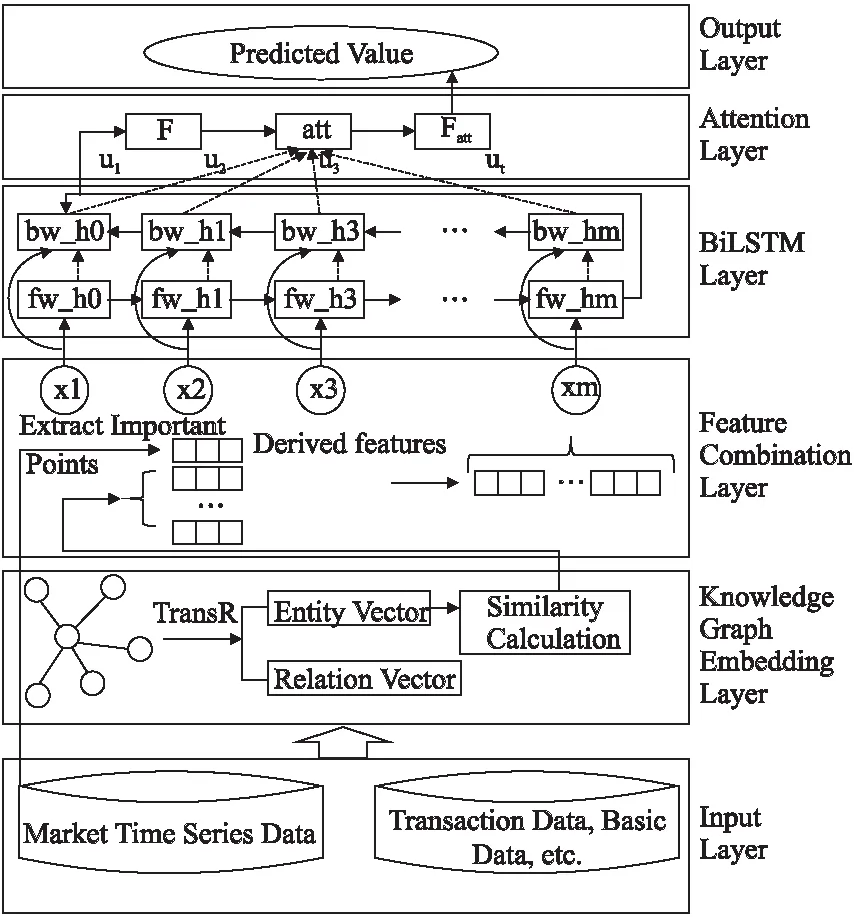
图1 本文预测模型的总体框架Fig.1 System framework of our prediction model
4.1 模型框架
在本文的研究中,我们首先对原始时间序列数据进行挖掘,识别出时间序列数据的重要点并对局部拐点趋势进行建模.同时,融合市场交易等信息构造金融知识图谱,从知识图谱中找出金融标的市场和交易数据间的潜在特征.采用TransR转换模型将金融知识图谱中的实体转化为向量表示,通过计算向量间的距离找到相似的金融产品,综合考虑其变动趋势,增强模型的语义表征和鲁棒性.
在选择金融时间序列的量化特征时,我们选择了常用的金融时间序列K线指标特征,如Zigzag、MA均线、MACD、KDJ等,丰富模型的特征池,并将其特征信息拼接融合得到综合特征信息向量.
在获得金融标的及相关金融产品的特征数据后,将这些特征信息作为基于注意力机制的双向长短期记忆网络模型的输入,然后进行模型参数学习和股价预测.与传统的循环神将网络(Recurrent Neural Network,RNN)模型相比,双向长短期记忆网络不仅能够有效避免长期依赖问题,而且增加了遗忘和保存机制.此外,采用注意力机制可根据时间序列数据在不同时刻的状态赋予不同的权重,从而能够更加关注关键交易日的信息,获得更好的预测结果.
4.2 重要点与趋势特征识别
识别出金融时间序列的重要点可以帮助提取金融时间序列的特征趋势.如何确定金融时间序列在上升或下降趋势中交替变化的时间点是否是一个真正的反转点是至关重要的.
4.2.1 Zigzag指标
Zigzag指标是金融时间序列数据的滞后技术指标,它被用来突出时间序列历史价值变动的显著高低趋势,并消除数据中的噪音.本文使用了Zigzag技术指标来检测重要点,并用来确定金融时间序列趋势特征的技术指标信号.
定义1.(Zigzag指标) 给定第i个时间序列Si(k)=〈si(k),si(k+1),…,si(k+n-1)〉,其中n是给定K线时间窗口大小,则Zigzag指标重要点序列Z定义如下:
1.Zi(k)=〈zi(k),zi(k+1),…,zi(k+n-1)〉
2.如果si(j)是基于深度(Depth)、偏差(Deviation)和回退(Backstep)3个参数的Zigzag重要点,则zi(j)=si(j);否则zi(j)=0.其中,k≤j≤k+n-1深度、偏差和回退是Zigzag指标识别算法的三个重要自定义参数,用于确定将过滤多少数据,以及该指标将对其已计算的值进行调整的频率.
定义2.(Zigzag深度)深度决定了K线的Bars数,其中当前Bar必须是极值Bar才能被确定为一个Zigzag重要点.对于深度参数,Zigzag重要点需要满足以下条件:
1.Si(k)=〈si(k),si(k+1),…,si(k+n-1)〉
2.Zi(k)=〈zi(k),zi(k+1),…,zi(k+n-1)〉
3.∀zi(j)∈Zi(k),k≤j≤k+n-1:
zi(j)=si(j)→(∀si(x)∈
{si(j-Depth)…si(j+Depth)},zi(j)≤si(x))
or(∀si(x)∈{si(j-Depth)…si(j+Depth)},zi(j)≥si(x))
定义3.(Zigzag偏差)偏差用来表示在一个的Zigzag高点之后建立新的低值所需的Bars数,以及在一个的Zigzag低点之后建立新的高值所需的Bars数.即,新Bar的值应该偏离以前的高或低值至少偏差量.对于偏差参数,Zigzag重要点需要满足以下条件:
1.Si(k)=〈si(k),si(k+1),…,si(k+n-1)〉
2.Zi(k)=〈zi(k),zi(k+1),…,zi(k+n-1)〉
3.∀zi(j)∈Zi(k),k≤j≤k+n-1:
(si(j-1)+deviation≤zi(j)∧zi(j)≥si(j+1)+
deviation)or(si(j-1)-deviation≥zi(j)∧
zi(j)≤si(j+1)-deviation)
定义4.(Zigzag回退)回退是Zigzag指标算法在回归计算中的回退K线Bars的个数.
Zigzag深度参数是用来确定要形成新的顶部或底部所需的最小Bar数,通常要求是一个整数.当这个参数过小时,可能会要求更频繁的计算;当这个参数过大时,可能会遗漏部分重要点.另一方面,Zigzag偏差表示重新形成新的底部/顶部和旧的底部/顶部之间的最小所需差异,它同时也描述了顶部和底部点之间的高度.
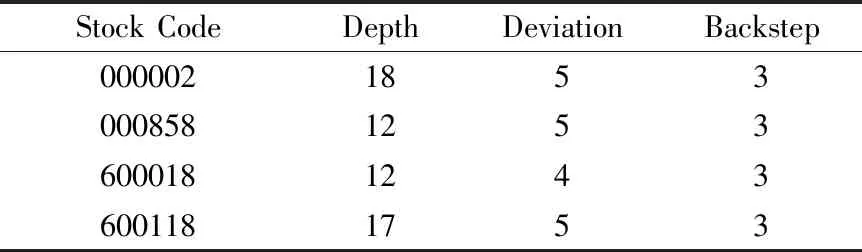
因此,当为Zigzag 指示器选择参数时,深度和偏差应在合适的区间选择,以确保噪声被过滤的同时又能检测出时间序列的重大变化.在本文中,这些参数是通过人工指定和系统优化计算确定的.
4.2.2 重要点识别
基于Zigzag的重要点识别算法的主要思想是基于Zigzag指标,通过优化深度、偏差和回退3个参数识别出满足某种特定模式的感知重要点序列,在此基础上确定金融历史时间序列数据中的特征趋势,并在后续工作中可以作为金融知识图谱构造的重要来源之一.算法1描述了改进的Zigzag算法,该算法的时间复杂度为O(n×k).其中,n为时间窗口中参与计算时间序列的K线数量;k为Zigzag指标的深度参数Depth和回退参数Backstep的最大值.
算法1.Zigzag Point Identification
输入:Data[]←currency time series,Bars←counting bars
Depth←Zigzag depth,Deviation←Zigzag Deviation,
Backstep←Zigzag Backstep
输出:Data[].HighMapBuffer,Data[].HighMapBuffer
1.limit←Depth,Data[].HighMapBuffer←0,Data[].HighMapBuffer←0,lasthigh←0,lastlow←0;
/*初始化开始位置,高点,低点*/
2.for(shift=limit;shift<.Bars;shift++){ /*计算高低点*/
3. val= Data[iLowest].LowestPrice;/* iLowest计算Depth区间内的低点*/
4. if(val==lastlow) val←0;
5. else {/*如果该低点是当前低点*/
6. lastlow←val;
7. if((Data[shift].LowestPrice-val)>Deviation×PointPrice))val←0;
/*是否比上个低点还低Deviation,不是的话则不进行回归处理*/
8. else {//找到一个新的低点
9. for(back=1;back<=Backstep;back++){
/*回退Backstep个Bar,把比当前低点高的纪录值给清空*/
10. res← Data[shift-back].LowMapBuffer;
11. if((res!=0)&&(res>val))
Data[shift-back].LowMapBuffer←.0;
12. }
13. }
14. }
15. if Data[shift].LowestPrice==val)
Data[shift].LowMapBuffer←val;
/*将新的低点进行记录*/
16. else Data[shift].LowMapBuffer←0;
17. val← Data[iHighest].HighestPrice;
/*iHighes计算Depth区间内的高点*/
18. if(val==lasthigh)val←0;
19. else {
20. lasthigh←val;
21. if((val-Data[shift].HighestPrice)>.Deviation×PointPrice))val←0;
22. else {
23. for(back=1;back<=Backstep;back++){
24. res←Data[shift-back].HighMapBuffer;
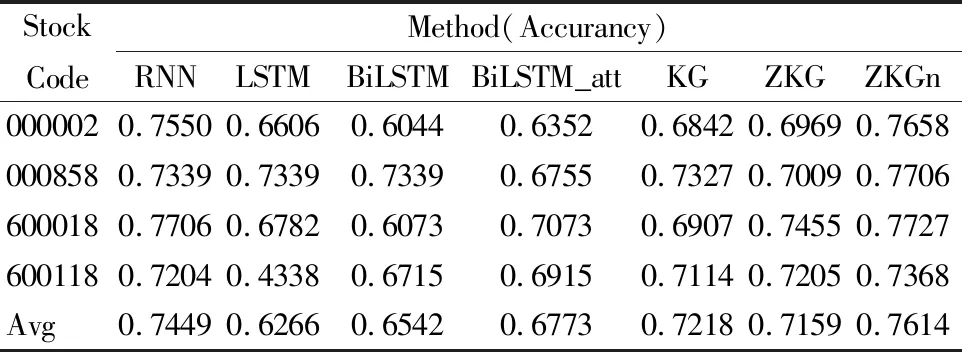
25. if((res!=0)&&(res 26. } 27. } 28. } 29. if(Data[shift].HighestPrice==val) Data[shift].HighMapBuffer←val; 30. else Data[shift].HighMapBuffer←0; 31.} 算法1中拐点高点的选取基于时间序列单根K线的最高价,低点的选取基于单根K线的最低价.这样选取策略的优点是考虑价格序列的多维特征,以适应趋势波动较为平稳时的拐点识别. 根据时间序列数据的趋势信息识别并提取重要转折点,充分挖掘行情数据的局部特征模式,达到压缩数据、减少噪声影响的目的,算法1的输出将作为接下来趋势预测的输入特征之一. 传统的趋势预测方法没有充分考虑行情局部趋势特征模式和交易行为相关性分析.为了解决上述问题,本文引入知识图谱方法并将其应用于异质信息融合中.图2描述了基于金融知识图谱的交易信息与市场信息集成主要业务活动. 图2 交易信息与市场信息集成活动图Fig.2 Activity chart for integration of transaction information and market information 4.3.1 挖掘交易特征信息 知识图谱G是根据现实世界中实体(结点)、实体间关系(边)相互连接起来所形成的一种网络结构,一般用三元组形式表示不同元素之间的复杂关系,可将图谱中的每一条知识直观地表示为G= 现货股票市场和期货市场往往会存在关联,期货价格(特别是股指期货)往往引领股票价格上涨与下跌,如隔夜期货市场相关品种走势对于第2天股市相关板块影响巨大.以股指期货沪深300股指期货合约为例,在第1次迭代中,实体类型包括投资者、合约代码等,关系类型包括喜好关系,盈亏关系等.在第2次迭代中,我们添加了涉及到的相关股票所属公司、行业、地区等实体属性,以及公司之间的持股、关联和隶属等关系. 本文采用自顶向下的知识图谱构建方法,选取来自投资者成交单的交易数据和相关基础数据等构造金融知识图谱.对交易和市场数据进行离散化和语义化处理并形成离散化的三元组,并在此基础上构造出金融时序知识图谱,挖掘金融实体间的相关性和潜在特征. 金融时序知识图谱FinKG为一张有向标签图FinKGt=(Ts,Te,E,R,τ),其中E为知识图谱的顶点集,用于表示实体集合;R为知识图谱的边集,用于表示事实关系集合;τ为E×E→R|k的函数,表示知识图谱中的所有元组;k表示在时间段[Ts,Te]按照时间前后排序的知识图谱三元组列表中,两实体之间存在第k次的关系R.金融知识图谱概念示例如图3所示. 图3 金融知识图谱概念示例Fig.3 Example of financial knowledge mapping Trans R对于每个三元组(h,r,t)中每个关系都定义了一个投影矩阵Mr∈Rk*d,将实体空间中的实体向量通过Mr投影到关系r的子空间,lhr和lht表示为: lhr=lhMr (5) ltr=ltMr (6) 对应的损失函数为 fr(h,t)=‖lhr+lr-ltr‖L1∕L2 (7) 采用TransR转换模型将知识图谱FinKG中选定周期[Ts,Te]内的三元组(Ei,R,Ej)嵌入到低维空间内.对FinKG进行图嵌入操作,则其中每个元素被转化为向量表示.这样,FinKG中选定周期[Ts,Te]内的实体(关联股票等)被嵌入到k维超平面中,关系被嵌入到d维超平面中.可根据实际经验选择k和d. 根据TransR原理,相似实体之间的k维向量距离较近.我们通过计算第i支股票向量vi和第j支股票向量vj之间的如公式(8)所示的欧氏距离来度量股票之间的相似性. (8) 我们可以用上面的方法来计算任何一对股票之间的相似性,而相关的股票是那些与目标股票具有top-K相似性的股票. 4.3.2 融合市场特征信息 为了更好地反映金融标的(如股票)价格趋势,本文选取一定周期内金融标的及其相关金融产品的的特征指标构建其市场信息,包括其来自市场行情数据(开盘价、最高价、最低价、收盘价、成交量等)及其衍生出的特征数据(Zigzag、MA均线、MACD、KDJ等)作为其特征信息. 1)基本数据 最基本的数据就是OHLC等行情数据.其他K线技术指标都是根据公开价、高价、低价、收盘价、成交量等基础数据计算得出的. Open(t):t时刻的开盘价. High(t):时间t时的高价格. Low(t):t时刻的低价格. Close(t):t时刻的收盘价. Volume(t):t时的交易量. 2)衍生特征数据 除了基本数据外,还考虑与某些和收益率最相关的衍生指标.除了基本数据外,还考虑与某些和收益率最相关的衍生指标.常用的衍生数据主要有Zigzag、MA均线、MACD、KDJ等数据. 除了这些金融指标数据外,其他数据也会作为衍生数据,例如交易时间,会按格式分为年、月、日、周等更加细分的参数;公司的股票代码、名称、行业地区等都会作为参数,纳入分析模型中. 对于每个标的金融产品,都会根据上述这些指标构建其特征信息特征向量,我们将第i天第j只相关股票的市场信息向量表示为mij.然后利用知识图谱和图嵌入技术选择与目标股票相关的金融产品,并将其特征信息拼接融合得到综合特征信息向量.如果我们选择了标的股票及与标的股票最相关的k只股票来共同预测标的股票未来走势,我们将得到第i天的基于相关股票的市场信息向量M=[mi1,mi2,…,mi(k+1)].将它们共同作为预测模型的输入数据,从而丰富输入数据的语义信息,提高预测精度. 在预测模型方面,我们采用了基于注意力的BiLSTM模型,金融标的及其相关金融产品的综合特征信息向量作为该模型的输入,预测模型的输出是“涨/跌/平稳”的趋势预测标签. 4.4.1 长短期记忆网络 LSTM最初由Hochreiter和Schmidhuber提出,随后由Alex Graves改进的一种专门设计的RNN体系结构,通过门结构控制信息传递从而为RNN训练过程中的反向传播梯度消失和爆炸提供了解决方案[20].然而,经典的LSTM网络按照时间顺序处理过去的信息,而忽略了未来的信息.因此,本文采用双向长短期记忆网络BiLSTM模型提取时间序列中的上下文信息,从而获取更加稳健的特征信息,更准确地预测金融时间序列变化趋势. BiLSTM将正向状态(正时间方向)和反向状态(负时间方向)的两个隐藏层连接起来,从而能够从两个不同的数据方向学习信息,做出更准确的预测.图4给出了本文使用的BiLSTM网络结构,将融合了包含重要点特征数据的市场时间序列数据、交易数据和其他基本数据的过去t个交易日的市场信息向量M输入到BiLSTM. 图4 BiLSTM网络架构Fig.4 BiLSTM network architecture 单个LSTM单元中有一个单元状态和3个门,即细胞状态ct,输入门it、遗忘门ft和输出门ot.形式上,LSTM可以表示为: it=σ(Wixt+Uiht-1+bi) (9) ft=σ(Wfxt+Ufht-1+bf) (10) ot=σ(Woxt+Uoht-1+bo) (11) (12) (13) ht=ot⊙tanh(ct) (14) 其中,xt表示当前的输入向量,ht表示当前隐藏层向量.Wi,Wf,Wc,Wo为权矩阵;bi,bf,bc,bo为偏置参数.⊙是向量内积,σ为sigmoid函数. (15) 其中,Wub为输出层与前向隐藏层的权重矩阵,Wub为输出层与后向隐藏层的权重矩阵,bu为BiLSTM的偏置参数. 4.4.2 注意力机制设计 注意力机制考虑每个输入元素的不同权重系数,可以有效捕捉数据的变化特征.由于股价走势往往与一些特定的时间点有关,比如相近时间节点或新政策出台时的信息可能对当前时间点的预测更为重要.为了关注这些重要时刻,我们在上述结构的基础上中加入了注意力机制. 本文将BiLSTM的输出状态[u1,u2,…,ut]作为注意力机制的输入,可以计算出t时刻的输出需要关注t′时刻隐藏状态的程度: rt=tanh(Wrut+Wr′ut′+br) (16) 对权重进行归一化得: at,t′=sigmoid(Wart,t′+ba) (17) 最终求得模型的输出值如下: (18) 其中,Wr,Wr′,Wa,br,ba均为可训练参数,被随机初始化后在训练过程中优化. 上述注意力机制根据时间序列数据在不同时刻的状态赋予不同的权重,从而学习不同时刻的信息对时间序列变化预测所起的关键性作用,使预测结果更加准确. 为了验证所提模型的有效性,本节将比较本文所提模型和其他基线模型的预测效果. 在实验中,我们使用某程序化交易系统收集的约1万条客户的成交单数据和相关基础数据等来构建知识图谱FinKG,并使用股票市场信息来构建训练和测试所提出的模型和其他基线模型的数据集.数据集将2018年以前的数据作为训练集,将2018年1月1日~2020年4月9日的数据作为测试集. 本文的实验环境是Intel Core i5-9400 CPU(2.90GHz)、Nvidia GeForce GTX 1660TI GPU(6G显存)和8 GB RAM.利用TensorFlow框架完成了深度学习实验. 模型评估使用的指标是预测的准确率Accuracy与Macro_F1值,计算方式如下所示: (19) (20) (21) (22) (23) 其中TP、TN、FP和FN可以通过表1的混淆矩阵得到. 表1 混淆矩阵结构Table 1 Confusion matrix structure 为了验证所提模型的有效性,本文选取了几个不同板块的中国市场代表性股票作为研究案例,对其价格上涨、平稳、下跌3种类型趋势变动进行预测,计算所提模型预测结果的准确率Accuracy和宏F1(Macro_F1)指标,并与其他基线模型进行对比与分析. 为了验证融合重要点特征对预测结果的有效性,本文进行了对比试验.其中,KG代表是仅使用FinKG挖掘相关金融产品而未融合重要点特征的模型,而ZKG是加入重要点特征后的模型. 为了验证重要点参数的选取对实验结果的影响,本文采用算法1进行Zigzag参数识别并选取文献[21]的方法对Zigzag参数进行优化,得到表2的优化后参数,ZKGn是加入参数优化后重要点特征的模型. 表2 Zigzag指标优化参数Table 2 Zigzag indicator optimization parameters 现以000002为例,其采用经典参数(5,2,3)和优化后参数(18,5,3)进行zigzag指标识别部分结果如图5所示. 图5 Zigzag感知重要点识别示例Fig.5 PIP using different Zigzag-related parameters 从表3可以看出,BiLSTM和BiLSTM_att的平均精度相较于LSTM分别提升了2.76%和5.07%,表明加入双向传播和注意力机制可以提高股价趋势预测的准确性.由前文分析知,通过构建FinKG并对交易和市场信息进行融合可以提高预测精度,而实验结果也验证了这一点,KG和ZKG方法预测的准确率相较于BiLSTM_att均有了明显的提升.ZKGn的准确率是所有方法中结果最好的,说明引入合适重要点特征信息后的ZKG在进行金融时间序列趋势预测中具有显著优势. 表3 基于准确率的各方法预测结果Table 3 Prediction results of each method based on accuracy 在多分类预测中,Macro_F1也是一个重要指标.F1指标是Precision和Recall是综合度量,对于模型而言要看的是整体的f1值,即Macro_F1,其值越高,说明在各类别中分类的平均效果越好.从表4中,我们可以看出,ZKG和ZKGn方法在Macro_F1指标表现显著好于相较于其他基线算法.值得一提的是,在准确率指标上表现较好的RNN在Macro_F1指标上表现最差,说明RNN的预测结果大幅偏置到了数据集上占比较大的那一类. 表4 基于Macro_F1的各方法预测结果Table 4 Prediction results of each method based on mf1-score 综合上述两个指标可以看出,本文提出的融合深度学习和知识图谱的面向局部特征模式的金融时间序列预测方面具有优秀的预测性能. 图6为各方法的准确率收敛曲线图.由图6可知,各方法的改进不仅会带来准确率的提升,同时也会加快收敛的速度.其中本文提出的ZKG和ZKGn方法具有较快的收敛速度,同时最终准确率也高于其他方法.表明本文提出的方法能够有效地预测金融时间序列的变动趋势,也证明了模型的可用性. 图6 各方法的acc曲线Fig.6 Performance of acc curve of each method 如图7所示为训练的损失函数随训练次数变化的曲线图,损失函数是用来评价模型预测值与真实值之间的预测误差的非负函数.损失函数越小模型越好,如图所示可知本文提出模型训练成功. 图7 各方法的loss曲线Fig.7 Performance of loss curve of each method 图8所示为000002在2018年~2020年的真实股价走势和使用ZKGn预测的趋势的示例图,短划线为实际价格曲线,实线为对应的预测趋势.价格的涨跌与趋势的变化直接对应,当股票价格大幅上涨或下跌时,趋势会发生显著变化;当股价处于一个相对复杂的波动时期时,走势也会随之波动.事实上,这两条曲线在上升趋势和下降趋势之间的变化是非常同步的,预测曲线在关键位置可以很好地拟合实际曲线,证明了ZKGn模型能够有效地预测股票价格的走势.事实上,本文所提出的模型在上述4个案例中均取得了良好的预测结果,证明了本文所提模型的通用性和稳健性. 图8 000002的预测结果和真实结果对比Fig.8 Comparison between the predicted results and the real results of 000002 实验结果表明,基于知识图谱和图嵌入技术集成交易与市场信息可以更好地挖掘投资者和市场的特征,同时,融合Zigzag重要点特征信息有助于提高预测性能.综上,本文所提出的模型具有较好的有效性、可用性与稳健性. 针对金融时间序列的相关性强、易变性高的特点,本文提出了一种基于融合深度学习和知识图谱的金融时间序列预测模型.首先,该模型可以实现对多序列特征变量输入的处理,通过Zigzag指标识别算法识别出重要点特征并对局部特征趋势进行建模.其次,模型可从金融知识图谱出发挖掘交易数据中丰富的语义信息及相似金融产品间的潜在特征,并使得模型更好地融合重要点等行情特征信息.最后,在真实金融数据集上进行了全面实验,实验结果表明本文所提出的预测模型取得了最佳的预测效果,验证了该模型在金融时间序列预测问题上的有效性、可用性与稳健性. 本文所提的模型和方法可实现自动化和可视化,不需要人工交互干预,这在实时交易场景下是非常实用的,因为预测与交易通常是即时进行的.文中的技术指标参数初始选择目前是通过历史数据挖掘得来的.下一步的工作是实现参数的自动预测,以确定哪些参数可以产生最优投资效益.另外,进一步丰富融合多源相关信息[22]的知识图谱库,以适应更广泛的领域,并在程序化交易平台上应用所提预测模型和技术.4.3 基于知识图谱的交易信息与市场信息集成
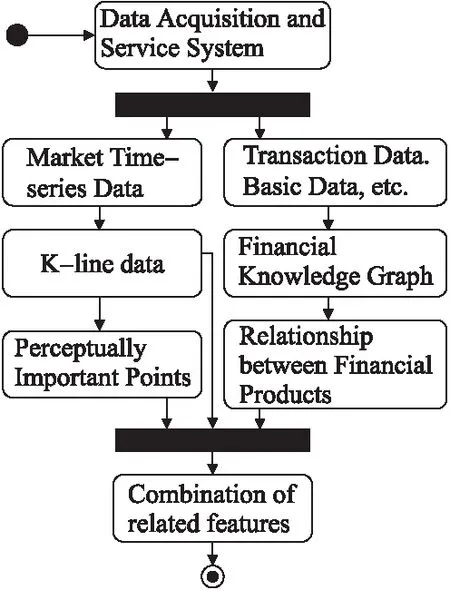
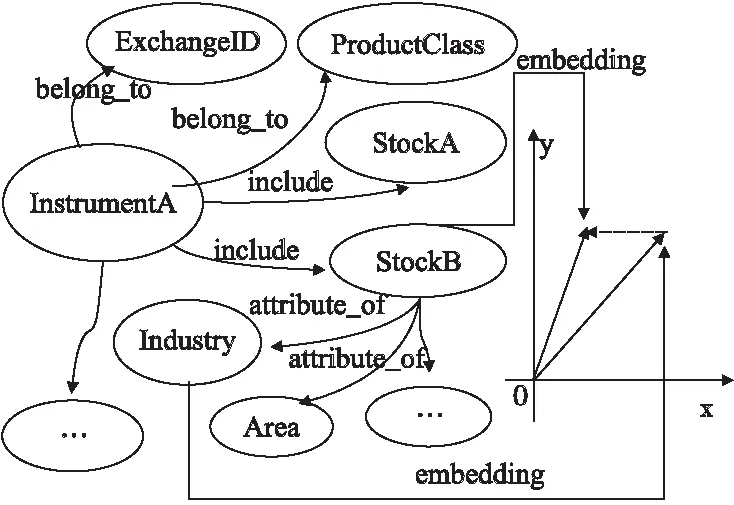
4.4 基于注意力的BiLSTM预测方法

5 实验结果与分析
5.1 实验设置
5.2 评估标准

5.3 结果分析

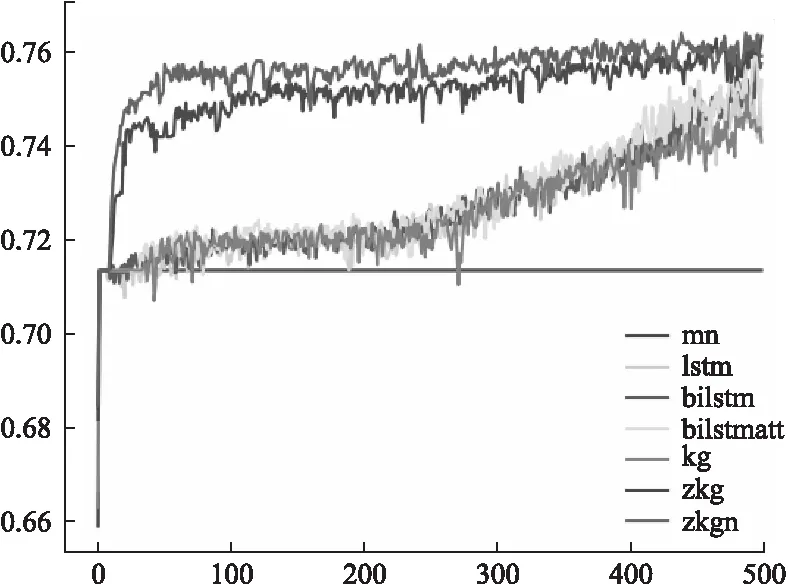

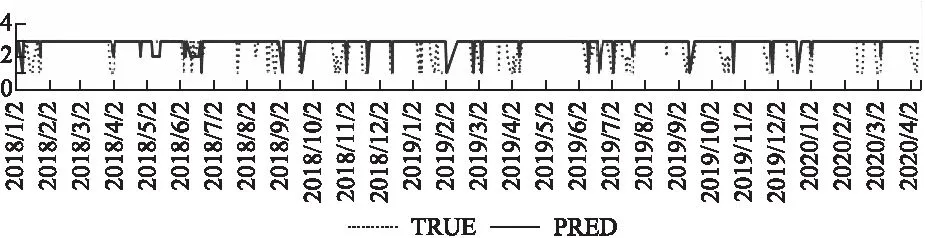
6 结 语
