基于决策树模型的信用风险等级预测
2022-08-24游杰藓重庆理工大学
文/游杰藓(重庆理工大学)
一、引言
现在人们在外面借共享充电宝、骑共享单车、支付宝的花呗等,都是基于一个人的信用,可以说信用现在已经影响到我们生活的方方面面,而且对企业和个人的信用预测是金融领域的主要研究问题。中国的银行等金融机构也正在面临着互联网金融的挑战,如某东的白条、一些*呗、一些*粒贷等。因此,对信用等级的预测也引起了金融机构从业人员的极大兴趣,对信用等级预测准确率的提高是当前金融领域亟待解决的问题。
以前一些专家对信用的评价主要是用一些传统的统计方法,例如根据人们以往的收入、工作、家庭等情况来判断一个人的信用等级,其最大的优点是有清晰的解释性,但缺点是前提条件非常严格,且其结果往往带有主观性,数据也有滞后性和不及时性。而现在利用机器学习算法模型进行建模预测信用的方法已获得了广泛的应用。在机器学习算法模型中,决策树是最常用的算法模型之一。
在互联网技术发展迅速的时代,利用人工智能去处理大量的数据已经成了现在的主流。而机器学习作为人工智能的核心,已经受到了广泛的关注。本文运用机器学习的五种模型分别对四个国家的人们的以前数据进行信用预测,以选出最优方法。
二、相关工作
由于互联网的发展,机器学习的模型算法已被广泛运用到对信用风险、信用等级的预测上,目前已经取得了不错的效果。方匡南等人使用Lassologistic进行指标的筛选、构建个人信用风险评估模型,提高了信用风险预警的效果。沈翠华和高万林(2004)利用SVM对企业信用等级镜像分析[5]。Hui-Chung Yeh(2007)运用决策树、神经网络以及判别分析方法进行信用评估时得出决策树分类准确率最高,线性判别分析准确率最低的结论。郑也夫、徐军等(2012)对60家上市公司与75家非上市公司,通过机器学习的一些模型进行比较研究,得出决策树的算法在上市公司信用风险评估中效果最好的结论。
在决策树运用的其他研究方面,张凯、丁波等人采用决策树算法构建了预测成人学位英语考试成绩的分类模型,其预测准确率为81%。王联英等人将决策树算法用在人力资源推荐方面,以此提升招聘平台的人力资源推荐质量。
此外,已经有越来越多的企业都建立了自己的信用评分体系,如*巴的“芝麻信用”、*讯的“*信用”等。
综上,目前已有大量学者和企业在研究采用机器学习算法进行信用等级预测,总结出了一些最优算法模型。
三、模型介绍
(一)实验模型结构
大数据个人征信是指将云计算、大数据分析等新技术运用到个人征信系统的信用评估和数据预测等环节,通过对个人可变的信用数据进行不断地采集而实现动态的信用分析。
本文通过决策树的构造算法及应该以怎样的顺序来选取实例的属性进行扩展予以说明,并分析了其他几种模型算法的优缺点,以得出信用等级预测结果准确率相对较好的模型。
(二)DECISION TREE 决策树
1.概述
DECISION TREE算法是从机器学习领域中逐渐发展起来的,它采用了从最顶向下的递归方式来构造决策树。最早的决策树算法是概念学习系统,之后的许多决策树算法基本是概念学习系统衍生而来的。如今,利用DECISION TREE算法对数据进行分类得到了深入的研究。由此,在决策树的基础上又形成了越来越多的生成算法。
2.决策树的构造算法
假设如下:给定训练集TR,分类对象的属性表AttrList为[A1,A2,A3,……,An],全部分类结果构成的集合为Class,表示为{C1,C2,C3,……,Cm},一般n≥1和m≥2。对每一属性Ai,其值域为ValueType(Ai),值域可以是离散的,也可以是连续的。这样决策树TR的元素就可表示成
输入:训练集TR={特征向量Xn,分类结果Cn}Nn=1,属性列表AttrList
输出:以属性Ai为根节点的决策树
(1)从属性表中选择某一属性Ai作为检测属性。
(2)根据Ai取值的不同,将TR划分为k个训练集TR1,TR2,TR3,……, TRk,其 中,TRj={
(3)从属性表中扣除已做检测的属性Ai。
(4)对每一个j,用TRj和新的属性表递归调用CLS以生成字分支决策树DTRi。
(5)返回以属性Ai为根,DTR1,DTR2,DTR3,……,DTRk为子树的决策树。
3.属性的选取方法-信息熵
属性的重要性不同,选取方法不同,对树的构造及结果的准确率往往是不同的,以下是属性的选择方法:
(1)信息熵:
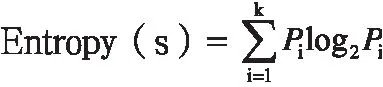
(2)信息增益Gain:Coin(S,A)
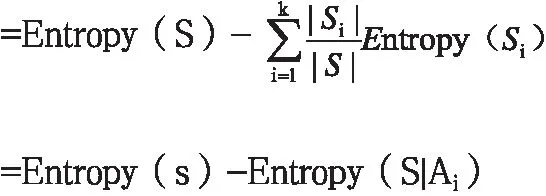

(三)SVM(Support Vector Machine)支持向量机
支持向量机是在监督学习中最有影响力的方法之一。SVM输出的仅仅是样本的类别,且SVM最重要的创新是核函数。
(四)KNN(K-Nearest Neighbor)K-最近邻
K近邻算法是一种统计分类器,于1968年提出,是最简单的有监督的机器算法之一,对包容性数据的特征变量筛选特别有效。
(五)NAIVE BAYES朴素贝叶斯
贝叶斯定理是英国数学家贝叶斯发明的,它主要描述了两个概率之间关系的定理。因为它的应用广泛性和良好统计推断性质,被越来越多地应用于各个领域,成为现代统计学的重要分支。
(六)CNN(Convolutional Neural Network)卷积神经网络
卷积的目的在于将某些特征从图像中提取出来,就像视觉系统去辨识有方向性的物体边缘。卷积神经网络是受视觉神经机制的启发而设计的一种特殊的深层神经网络模型。
四、实验结果
我们用以上五种模型分别预测了四个不同国家的人们信用数据集。
(一)评价标准
(1)准确率(ACC):指使用测试集对模型进行分类时,分类正确的记录个数占总记录个数的比例:
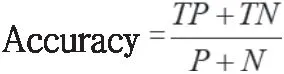
TP(True positives):被正确地划分为正例的个数;TN(True negatives):被正确地划分为负例的个数;FP(False positive):被错误地划分为正例的个数;FN(False negative):被错误地划分为负例的个数。
(2)F1分数(F1 Score),F1分数能看作是模型精确率和召回率的一种加权平均,它的最大值是1,最小值是0。
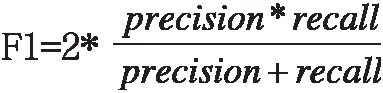
Precision,即精度是精确性的度量,表示被分为正例的示例中实际为正例的比例。
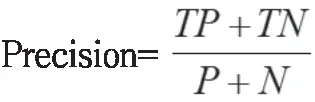
Recall,即召回率是覆盖面的度量,度量有多个正例被分为正例。

表2 以F1分数为标准的Chinese Credit Approval Data Set

表3 以准确率(ACC)为标准的Japanese Credit Screening Data Set

表4 以F1-score为标准的Japanese Credit Screening Data Set

表5 以准确率(ACC)为标准的Statlog (Australian Credit Approval) Data Set
(二)结果
表1至表8是用五种模型得出的四个国家的人们信用等级预测,分别用了ACC和F1-score评价标准,五种机器学习算法模型的准确率如表1-8所示。

表1 以准确率(ACC)为标准的Chinese Credit Approval Data Set

表8 以F1-score为标准的Statlog (German Credit Data) Data Set
五、实验分析
实验分别运用机器学习的五种模型对四个不同国家的个人信用进行预测。首先运用支持向量机、K-最近邻、朴素贝叶斯、决策树、卷积神经网络五种不同的算法对数据集进行训练,以便记住相关指标和模型对分类准确度的贡献率,为测试集中的试验做准备。
从表中的数据总体可以看出,无论是对哪一个国家的信用等级预测,用卷积网络模型(CNN)对人的信用预测所得出的结果的准确率都是最低的,这是因为CNN具有的缺点;另外是卷积神经网络目前广泛应用于图像处理领域,对图像进行领域间采样,在数据挖掘方面不如其他几种算法模型。
而支持向量机、K-最近邻、朴素贝叶斯的预测结果的准确率相差不大,但预测结果的准确率都不如决策树高。相较于CNN,SVM能利用有限的训练数据信息,力图在模型的学习能力与其复杂性之间取得较好的折中;但是SVM对于无法直接输入又含有一定结构信息的结构化数据不能直接解决。

表6 以F1-score为标准的Statlog (Australian Credit Approval) Data Set

表7 以准确率(ACC)为标准的Statlog (German Credit Data) Data Set
K-最近邻(KNN)模型与其他算法不同的是,它不仅可以解决二分类场景的问题,并且也可以解决多分类的问题;但当样本量很大时,很大一部分点附近没有样本点,这就使利用空间中的每一附近的样本点来构造预估的近邻法就非常难以运用。
朴素贝叶斯(Naive Bayes)在预测结果的准确率上虽然比CNN高,但当属性个数较多或属性之间相关性较大时,它的分类效率不如决策树模型,对朴素贝叶斯分类的准确性有影响。
从得出的实验结果总体看来,DECISION TREE算法模型在这五种模型中,对信用预测结果的准确率是最高的,因为决策树能够提取规则,构建一棵决策树;除此之外,决策树仅通过少量比较就能找到树叶,空间复杂度非常小,这使得该算法模型中的条件很简单,易于理解。
六、总结
本文基于机器学习的几种模型建模,并用真实数据集进行信用等级准确率的预测分析,最终选择出来的决策树算法模型在预测数据的准确率上表现良好,在实际运用中具有一定的研究意义。但在现实生活中,其问题的复杂程度要大得多,因此,其对信用预测的建模方法有待进一步优化。
