基于子区域加权的不同年龄段人脸表情识别*
2022-08-20虞苏鑫贺俊吉
虞苏鑫,贺俊吉
(上海海事大学物流工程学院,上海 201306)
1 引言
人脸表情包含大量的个人行为信息,能反映人内心的情绪[1]。现今,随着人工智能的发展,人脸表情识别更是成为了研究的重要方向之一,其在安全驾驶[2]、医疗卫生[3,4]、虚拟现实[5]、远程网络教学[6]、人机交互[7 - 9]和安防监控[10]等方面都有着广泛的应用。例如在医疗卫生领域中,通过对各年龄段患者表情的识别,可准确高效地判断其疼痛等级并采取相应的措施。
在现有的表情识别研究中,文献[4]提出了结合RGB、深度和面部热图像的人脸疼痛表情识别方法。文献[5,6,11]采用的是主动外观模型方法,从彩色图像中提取面部表情点来作为识别的几何特征。文献[9,10,12]提出了基于主成分分析的表情识别方法。罗元等[13]通过对人脸表情图像进行离散余弦变换得到人脸的全局特征,再将其与人脸的局部纹理特征相融合,本文特指局部二值模式LBP (Local Binary Pattern)特征,获得了更为精确的表情特征,从而进一步提高了表情识别率。胡敏等[14]提出了采用经典线性分析法融合局部纹理和形状特征的人脸表情识别方法。由于人脸存在表情无关区域及不同区域对表情的贡献度不同,王镇镇[15]提出了基于人脸子区域加权和线性判别分析LDA (Linear Discriminant Analysis)的表情识别算法,研究人脸关键子区域分割及不同权值分配对表情识别的影响。
上述研究都是基于公开的表情数据库。例如,JAFFE数据库,该库中只包含青年人的表情图像,对于文献[4]中研究对象是老年人的情况,该数据库就不适用;CK+数据库中虽有不同年龄的受试者,但上述研究都是基于对他们的统一无区别实验,忽略了不同年龄段的人同一表情相关区域贡献度存在差异的问题,导致对特定年龄段的人脸表情识别效果不佳。为此,本文分别研究了不同年龄段的人各自最为有效的权值分配方式。具体方法如下:首先建立包含中老年人、青年人和儿童表情图像的数据库;再对数据库中的图像进行预处理,得到眼睛、嘴巴这2个与表情相关的区域的图像,以及单纯的人脸图像;然后提取整个人脸的表情轮廓特征,以及眼睛和嘴巴的纹理特征;最后将这3部分的特征数据经主成分分析法降维并归一化后进行加权融合,分别设置不同的权值组合,利用支持向量机进行表情分类。
2 数据库的获取及处理
本文着眼于不同年龄段人的表情识别,由于人脸子区域对表情识别的贡献度会因年龄的不同而不同,因此,为对不同年龄群体表情进行针对性研究,以准确提高不同年龄段人脸表情的识别率,本文通过采集3个不同年龄段人的表情图像建立了表情数据库。
首先,本文对中老年人、青年人和儿童这3个年龄段的参与者拍摄表情视频,然后从视频中提取共1 076帧表情图像,包括高兴、悲伤、生气、恐惧、惊讶、厌恶和中性,对每位参与者都采集这7种表情,共采集中老年人的表情图像380幅,青年人的表情图像406幅,儿童的表情图像290幅。各个年龄段人每人每种表情均采集5~8幅图像,将训练图像设置为每人每种表情的前3~5幅图像,而后2、3幅图像则设置为测试图像。
数据库建立以后,本文对数据库进行了一些必要的处理,主要是先对数据库中的图像进行人脸检测,再预处理这些人脸图像,包括确定眼睛的中心位置、校正人脸、裁剪纯人脸区域、分割表情关键子区域、尺寸归一化及直方图均衡化等,为下一步操作做好准备。
3 表情特征提取
3.1 表情轮廓特征
当人的表情不同时,其面部眉毛、眼睛和嘴巴等的边缘轮廓也会不同。为了更好地分离人脸表情相关区域和无关区域,本文采用最大类间方差阈值分割算法。该算法将图像所有像素点按灰度值的大小划分成2部分,使这2部分间的像素灰度差异最大,而每部分内的像素灰度差异最小[16],然后用边缘检测算子自动检测并描绘出所获得的二值化图像中表情相关区域的边缘轮廓特征,作为后续用于分类的特征之一,表示如式(1)所示:
F=[F0,F1,…,Fl-1]
(1)
其中,F表示表情轮廓特征向量,Fi表示第i个像素的灰度值,l表示图像的总像素数。最大类间方差阈值分割算法的实现效果如图1所示。

Figure 1 Features of facial expression profile图1 人脸表情轮廓特征
3.2 表情纹理特征
LBP算法对光照和旋转不敏感,计算相对简单,被普遍用于纹理分类、模式识别等任务中[17],因此本文提取关键子区域的LBP特征,作为融合的另一种特征。
最初LBP算子被定义在3×3的窗口内,此窗口中间点的LBP值可由式(2)计算得到:
(2)
其中,中间像素位置表示为(xc,yc),其灰度值为ic,四周像素的总个数表示为P,这些像素的值表示为ip,符号函数s(x)的定义如式(3)所示:
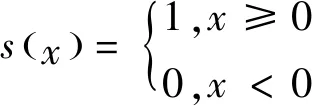
(3)
图2为一个LBP算子的编码和特征值的计算过程示例。图2a为图像某局部区域各像素点的值,取中心像素点的值作为阈值,将其四周大于或等于该阈值的像素赋1,其余赋0,得到图2b。将图2b中心点左边的值作为最高位,逆时针依次连接四周二进制码即可得图2a中心点所对应的二进制编码B,如式(4)所示:
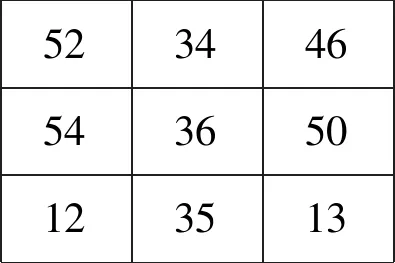
a 图像局部区域像素值 b 中心点的二进制编码
B=10001101
(4)
进而计算出中心点的LBP特征值,如式(5)所示:
LBP=1+4+8+128=141
(5)
为使LBP算子既可准确表征表情图像的局部信息,又可反映其全局信息,本文设计了一种基于子窗口的LBP特征值提取方法,具体做法如下所示:
(1)设子窗口的大小为21×19,将大小为126×133的人脸图像分割成大小为126×38的眼睛区域和大小为84×38的嘴巴区域,则眼睛被均等划分为12个子窗口,嘴巴被均等划分为8个子窗口,进而统计每个子窗口的LBP特征值。
(2)将眼睛和嘴巴所有子窗口的LBP特征值分别结合在一起,形成2个长的特征向量。分别如式(6)和式(7)所示:
E=[E0,E1,…,Em-1]
(6)
M=[M0,M1,…,Mn-1]
(7)
其中,E和M分别表示眼睛和嘴巴的LBP特征向量,m和n分别为相应的子窗口数目。
LBP特征值提取流程如图3所示。

Figure 3 Acquisition of LBP features图3 LBP特征值提取
4 不同年龄段人脸子区域加权识别法
本文针对不同年龄段人脸子区域对表情识别贡献度不同的问题,提出了基于子区域可变加权的表情识别方法。支持向量机常用于各种模式识别任务[18],因此本文采用支持向量机进行分类。基于子区域可变加权的表情识别方法实现过程如图4所示。
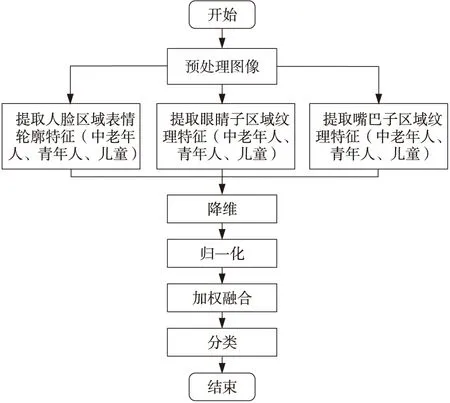
Figure 4 Implementation process of facial expression recognition based on variant weights of face sub-regions图4 基于子区域变加权的表情识别方法实现过程
具体步骤如下所示:
(1)分别采集中老年人、青年人和儿童的7种表情图像,建立较为完整的表情数据库。
(2)对数据库中的表情图像进行人脸检测,定位人眼中心,根据人眼中心连线与水平轴线的夹角校正人脸;再裁剪纯人脸区域、眼睛区域和嘴巴区域,并归一化人脸区域到126×133像素,归一化眼睛区域到126×38像素,归一化嘴巴区域到84×38像素;然后对图像进行直方图均衡化。
(3)分别提取3个年龄段人的整个人脸区域的表情轮廓特征,特征数据共126×133=16758维,提取眼睛区域和嘴巴区域的LBP特征,其中眼睛特征数据共有126×38=4788维,嘴巴特征数据共有84×38=3192维。
(4)分别对3个年龄段人提取到的表情轮廓和纹理特征进行主成分分析降维,将3部分特征均降到10维并将降维后的数据归一化到某固定范围,使最后的识别能达到最好的效果。
(5)分别将3个年龄段人脸区域的表情轮廓特征与眼睛和嘴巴的LBP特征进行融合(即特征相加),并根据不同区域对表情识别的贡献度分别多次设置人脸区域、眼睛区域和嘴巴区域的权值,分析比较不同权值组合对不同年龄段人表情识别的影响。
(6)运用SVM多类分类器分别对不同年龄段人的表情进行分类并计算分类正确率。
5 实验与结果分析
5.1 数据库预处理及表情特征提取
本节在自建的表情数据库上,对本文所提方法进行实验仿真。3个不同年龄段人的表情图像预处理的主要结果如图5~图7所示。

Figure 5 Facial expression images preprocessing of the middle-aged people and the old people图5 中老年人表情图像预处理

Figure 6 Facial expression images preprocessing of young people图6 青年人表情图像预处理

Figure 7 Facial expression images preprocessing of children图7 儿童表情图像预处理
图8~图10分别为这3个不同年龄段人的特征提取过程结果图。

Figure 8 Expression feature extraction of the middle-aged and the old people图8 中老年人的表情特征提取

Figure 9 Expression feature extraction of young people图9 青年人的表情特征提取

Figure 10 Expression feature extraction of children图10 儿童的表情特征提取
5.2 实验设计与结果分析
本文基于自建数据库,研究加权值对不同年龄段人表情识别率的影响,从而得出不同年龄段人最佳表情识别率所对应的最佳权值分配方式。
该实验中由于人脸、眼睛和嘴巴3部分的权值之和为1,每部分的权值都可由0取至1,本文按步长0.1取权值,则共有66种权值分配方式,用向量表示为:[WF,WE,WM]=[0,0,1],…,[0,1,0],[0.1,0,0.9],…,[0.1,0.9,0],…,[1,0,0]。在每种权值分配方式下,对每种表情均进行10次实验,然后取其平均值作为该表情的识别率,总识别率为该权值分配方式下所有7种表情识别率的平均值。为了更好地比较人脸、眼睛和嘴巴这3个区域分别进行权值调整后的总识别率,本文将权值作为横坐标,各条曲线分别对应相应的权值。将各个特征区域在各种权值分配方式下的最佳总识别率作为纵坐标,按照各年龄段人最佳总识别率值的分布区间分别选取纵坐标的范围及数据间隔,从而得出中老年人、青年人和儿童在各特征区域权值调整后的表情识别率变化曲线图,如图11~图13所示。
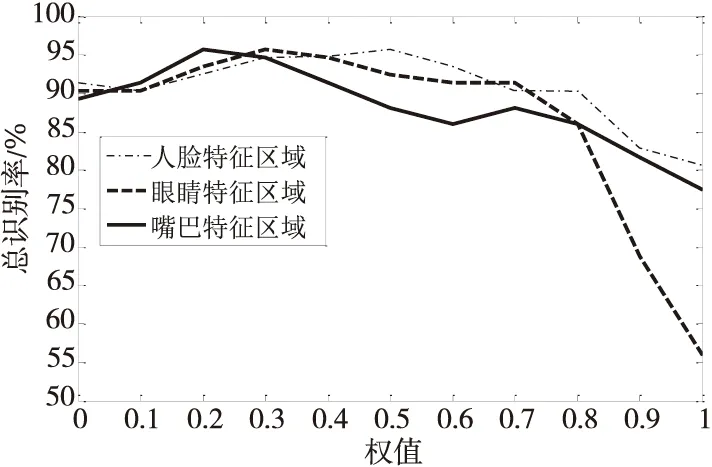
Figure 11 Expression recognition rate of the middle-aged and the old people图11 中老年人表情识别率

Figure 12 Expression recognition rate of young people图12 青年人表情识别率
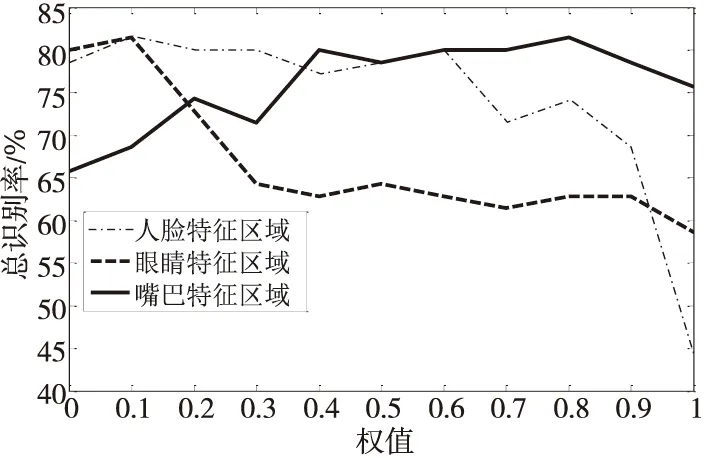
Figure 13 Expression recognition rate of children图13 儿童表情识别率
由图11可以看出,中老年人的表情识别率主要分布在70%~100%。随着人脸、眼睛和嘴巴特征区域权值的增加,其表情识别率都呈现先上升后下降的趋势。当任一特征区域的权值为0,即只融合另外2种特征时,其最佳表情识别率都能达到较好的水平,而当任一特征区域的权值为1,即只提取1种特征时,其表情识别率明显下降。当人脸特征区域的权值为0.5,眼睛特征区域的权值为0.3,嘴巴特征区域的权值为0.2,即[WF,WE,WM]=[0.5,0.3,0.2]时,中老年人的表情总识别率最高,约为95.7%,此时,人脸特征区域所占比重最高。
由图12可以看出,青年人的表情识别率主要分布在90%~100%。当任一特征区域的权值为0,即只融合另外2种特征时,其最佳表情识别率都能达到较好的水平,而当人脸特征区域的权值为1,即只提取人脸这1种特征时,其表情识别率明显下降。随着人脸特征区域权值的增加,青年人的表情识别率整体呈现下降的趋势,说明人脸区域的判别信息对青年人的表情识别作用甚微。随着眼睛特征区域权值的增加,青年人的表情识别率呈现先上升后下降再保持不变的趋势,随着嘴巴特征区域权值的增加,青年人的表情识别率呈现先下降后上升再下降的趋势,且当人脸特征区域的权值为0,眼睛特征区域的权值为0.4,嘴巴特征区域的权值为0.6,即[WF,WE,WM]=[0,0.4,0.6]时,青年人的表情总识别率最高,约为99.2%,此时,嘴巴特征区域所占比重最高。
由图13可以看出,儿童的表情识别率主要分布在50%~85%。随着人脸、眼睛和嘴巴特征区域权值的增加,其表情识别率整体都呈现上升、下降交替变化的趋势。当人脸或眼睛特征区域的权值为0,即只融合另外2种特征时,其最佳表情识别率都较好,而当人脸特征区域或眼睛特征区域的权值为1,即只提取这2种特征中的一种时,其表情识别率明显下降。当人脸特征区域的权值为0.1,眼睛特征区域的权值为0.1,嘴巴特征区域的权值为0.8,即[WF,WE,WM]=[0.1,0.1,0.8]时,儿童的表情总识别率最高,约为81.4%,此时,嘴巴区域所占比重最高。
由于中老年人和儿童对某些表情不够理解,导致对其表达存在偏差,且他们的有些图像采集环境较青年人复杂,有些图像的头部有较大程度的前后旋转,所以中老年人和儿童的表情识别率整体偏低。另外,由于儿童的训练样本数较其它2个年龄段人的少,因此儿童的表情识别率在三者中最低。
表1为对各年龄段人进行统一无区别实验所得的表情识别率与其可变加权组合下最佳表情识别率的对比结果。
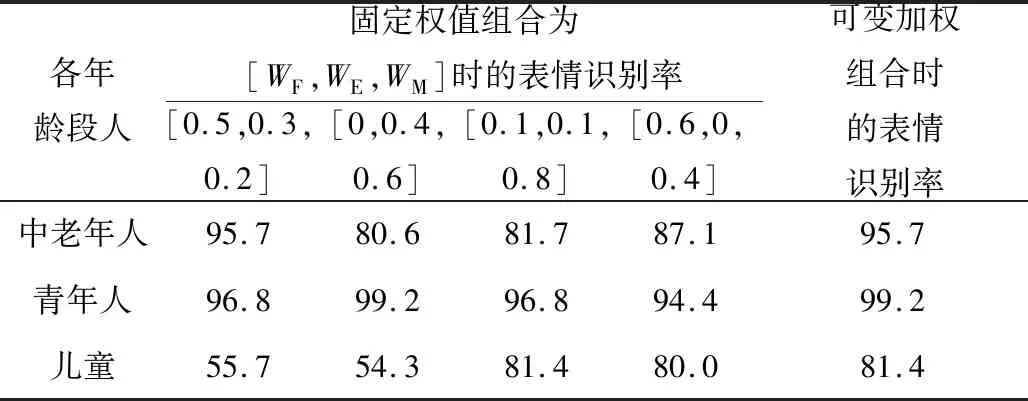
Table 1 Uniform and indistinguishable experiments for people at all ages表1 各年龄段人统一无区别实验 %
表1中固定权值组合栏下的第1~3列分别表示中老年人、青年人和儿童最高表情识别率所对应权值组合下的各年龄段人的表情识别率,第4列表示各年龄段人表情识别率综合最高时所对应的权值组合下的各表情识别率。
由表1可以看出,对某一特定年龄段人来说最好的权值组合并不能同时使其他年龄段人的表情识别率也最好,且在对不同年龄段的人用同一种综合最佳的权值分配方式时,其表情识别率均低于用可变加权组合时的表情识别率,即该固定权值组合并不是所有年龄段人的最佳方式。因此可得出结论:最佳表情识别率所对应的人脸各关键子区域分配的权重会因年龄段的不同而有所区别,这也验证了本文研究加权参数对不同年龄段人表情识别效果产生影响的重要性。
5.3 JAFFE数据库实验对比与分析
本节基于JAFFE公开数据库进行实验,比较分析本文方法与文献中方法的识别率。由于该数据库中的图像均为青年人图像,所以该实验在权值分配组合[WF,WE,WM]=[0,0.4,0.6]下进行。首先对JAFFE数据库中7种表情重复进行10次实验,得出10个识别率值,然后取其平均值作为该表情的总识别率,并与其它方法的识别率进行对比。实验对比结果如表2所示。
由表2可以看出,本文基于子区域可变加权融合的方法在JAFFE数据库上的表情识别效果最好,比文献中方法所得的识别率最低提高了0.3%,最高提高了2.6%,验证了本文方法的优越性。

Table 2 Comparative experiments表2 实验对比
本文方法对基于JAFFE数据库的表情识别率略低于自建库上青年人的表情识别率,主要是因为JAFFE中的样本数较少,导致一定的识别率下降。另外,由于本文使用的是自建数据库,数据量整体还不够多,所以采用的是传统的特征提取方法,而未采用基于深度学习的方法进行实验。
6 结束语
本文采用子区域可变加权的方法来研究自建数据库中不同年龄段人的表情识别与分类,通过分别实验不同的加权组合,得出了对于不同年龄段人来说最有效的权值分配方式。在最有效的权值分配方式下,中老年人的表情识别率最高可达95.7%,青年人的表情识别率最高可达99.2%,儿童的表情识别率最高可达81.4%,总体而言效果还算令人满意,验证了本文方法的优越性,表明了该研究的意义与价值。从中老年人和儿童的表情识别率低于青年人的部分原因可知,本文方法对复杂环境、前后旋转等的鲁棒性还不够好,这也将是下一步的研究内容。
