去中心化加权簇归并的密度峰值聚类算法
2022-08-16赵力衡陈虹君
赵力衡,王 建,陈虹君
1.成都锦城学院 电子信息学院,成都611731
2.四川大学 计算机学院,成都610041
聚类算法是模式识别和数据挖掘领域中的一类常见的无监督算法。算法通过某种相似性计算将一组数据对象按照其自身的特征划分到不同的类簇中,并使同一簇内的对象尽可能相似,不同簇之间的对象尽可能不相似。现有聚类算法模型丰富,大致可以分为层次聚类、划分聚类、密度聚类、网格聚类、图论聚类、代表点聚类和模型聚类七种类型,被广泛应用于生物、能源、交通、图像处理、流形数据处理等领域。
聚类算法自应用以来,不断有学者提出新的聚类算法,Rodriguez 等人于2014 年在上提出了快速搜索和寻找密度峰值聚类算法(clustering by fast search and find of density peaks,DPC)。该算法是一种基于密度的聚类算法,依据样本的分布密度能无需迭代地快速找出任意形状数据集中的密度峰值样本,以之作为聚类中心,从而能够较高效地得到高精确的聚类结果。DPC 算法因此受到了广泛的关注,但该算法依旧存在着一些缺陷:(1)围绕聚类中心点进行聚类,若聚类中心点选取不当会对聚类结果造成显著影响;(2)DPC 算法需要人工指定聚类中心,使算法的自动化程度受到影响;(3)截断距离只考虑了数据的分布密度,忽略了数据的内部特征,影响了聚类结果的稳定;(4)DPC 在聚类过程中若存在样本分配错误,则错误样本邻近密度更低的样本将可能随之被分配到错误的类簇中,从而放大错误。
为解决这些问题,近年来众多学者对DPC算法进行了改进。Xie 等人提出了模糊加权K 最近邻分配点的密度峰值聚类算法(robust clustering by detecting density peaks and assigning points based on fuzzy weighted K-nearest neighbors,FKNN-DPC)。该算法基于K 近邻设计了一种独立于数据集规模且与截断距离无关的局部密度计算方式,将数据集划分成核心样本和离群样本,再采用新的K 近邻策略完成对非聚类中心点的分配,有效缓解了DPC 算法的跟随错误。Seyed等人提出了基于动态图的密度峰值聚类标签传播算法(dynamic graph-based label propagation for density peaks clustering,DPC-DLP)。算法根据重新定义的K近邻密度确定出聚类中心点,然后将类簇中心点和其相邻中心点形成一个KNN 图,最后采用图的标签传播方法分配剩余样本,更适用于图像聚类。丁世飞等人提出了一种基于不相似性度量优化的密度峰值聚类算法(optimized density peaks clustering algorithm based on dissimilarity measure,DDPC)。算法通过基于块的不相似性度量实现样本间的相似度计算,从而避免了小样本数据集上截断距离对聚类结果的影响,提高了在高维度数据集上的聚类效果。Liu 等人提出了基于共享近邻的密度峰值聚类算法(sharednearest-neighbor-based clustering by fast search and find of density peaks,SNN-DPC)。算法通过计算样本之间共享的近邻点个数,确定样本之间的相似度,避免了非聚类中心点分配时的跟随错误。王大刚等人提出了基于二阶近邻的密度峰值聚类算法(density peaks clustering algorithm based on second-orderneighbors,SODPC)。算法通过引入样本的二阶近邻计算直接密度和间接密度,避免了截断距离带来的影响。
本文所知文献对DPC 算法的改进主要着眼于聚类中心点的选取、避免分配跟随错误及效率等方面,没有采用无中心点聚类的优化算法。尝试提出一种去中心化加权簇归并的密度峰值聚类算法(densitypeak clustering algorithm on decentralized and weighted clusters merging,DCM-DPC)。算法在聚类过程中取消了聚类中心点的概念,认为位于彼此邻域内的局部高密度样本属于同一类簇,采用加权近邻思想,重新定义了样本邻域半径,从而划分出位于不同区域的局部高密度样本组,并在寻找样本组的过程中归并存在邻域重叠的区域,形成归并的核心样本组,最后将剩余样本按其近邻样本的众数归属到某个核心样本组中完成聚类。实验结果表明,DCM-DPC 算法有效避免了由聚类中心点和截断距离带来的误差,并在聚类效果上有明显的提高。
1 DPC 算法
DPC 算法基于样本密度实现对数据集的聚类,算法假设类簇中心具有以下两个特征:(1)聚类中心点的局部密度高于周围样本的局部密度;(2)聚类中心点之间的距离相对较远。对于给定的数据集={,,…,x},设每个元素的维度为。DPC 算法定义样本x的局部密度ρ为:

其中,d表示样本x与样本x之间的距离。为截断距离,定义为中任意两个样本之间的距离按升序排列后位于用户指定位置的值。对于函数()有:

当数据集规模较小时,DPC 采用高斯核函数描述局部密度:

相对距离δ表示样本x距离局部密度比它高且离它最近的样本的距离,当x不是最大密度样本点时δ为:

当x是最大密度样本点时δ为:

DPC 算法使用局部密度ρ和相对距离δ绘制出决策图,并选取γ最大的若干个样本作为聚类中心,聚类中心个数由用户指定:

以这些密度峰值点作为聚类中心,剩余的非聚类中心样本被分配给局部密度更高且距离最近的样本所在类簇,从而完成聚类。
DPC 算法在多数时候能获得不错的聚类结果,但尚存在一些不足:
(1)围绕聚类中心点进行聚类,即首先找出聚类中心点,然后非聚类中心点依据聚类中心点进行分配,从而完成聚类。截断距离是影响聚类中心选取的重要因素,图1(a)和图1(b)分别是flame 数据集在截断距离取5%和2%时的聚类结果,图中十字符号为聚类中心。可以看出,当截断距离不同时选取的距离中心不相同,聚类结果也出现显著差异。聚类过程中,不同截断距离除了影响聚类中心的选取外,还会引起局部密度等计算的变化,同样会影响聚类结果。因此,为消除聚类中心因素外其他因素对聚类结果的影响,图1(c)中将聚类效果优秀的截断距离采用5%的聚类中心替换为截断距离采用2%的聚类中心,替换后聚类结果中大部分样本被识别为离散点,聚类效果极差。可见聚类中心的选择可能显著影响聚类效果。
(2)通过决策图选取聚类中心,但聚类中心个数仍需人工指定,使算法的自动化程度受到影响。
(3)截断距离由用户主观选择,只体现了数据的分布密度,没有体现数据的内部特征,因此截断距离的改变容易使聚类结果变得不稳定。
(4)非聚类中心样本被分配给邻域密度大于该样本且距离其最近的样本所属的类簇。若一个样本分配错误,则该样本邻域内其他密度更小的样本就可能跟随该样本被分配到错误的类簇,形成“多米诺”效应,导致聚类结果不理想。
2 DCM-DPC 算法
针对上述不足,本文尝试提出一种基于去中心化加权簇归并的密度峰值算法(DCM-DPC),从消除聚类中心、簇归并和非核心样本分配策略三方面对DPC 算法进行改进。
2.1 去中心化的加权核心样本组策略
根据图1 的分析可以发现,聚类中心点的质量很重要,甚至能显著影响聚类效果,因此找出合适的聚类中心是现有密度峰值聚类算法的关键。从聚类算法的本质看,聚类是将相似的样本划分在一起,而不是将样本围绕某个中心点划分在一起,因此聚类中心并不是必须的,若能识别出相似的样本,就能完成聚类。
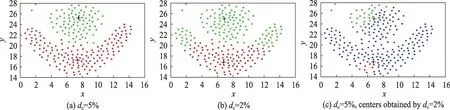
图1 不同聚类中心点的聚类效果对比图Fig.1 Clustering effect contrast diagram of different clustering centers
本文所知的DPC 改进算法文献均依赖于聚类中心点进行聚类,并没有在消除聚类中心方向进行优化。尝试提出一种新的去中心化聚类的核心样本组策略取代聚类中心点作为样本划分依据。核心样本组指具有较高局部密度且位于同一较高密度区域样本的集合,采用基于近邻思想的加权邻域半径来度量局部密度。近邻思想目标是找出加权邻域半径内的所有样本数量。
DPC 算法使用截断距离作为邻域半径,以截断距离内的样本数量作为局部密度。由于截断距离是人为主观选择,难以准确反映数据的分布特征,为此本文给出了新的局部密度及相关定义:
(权重系数)设定权重系数如下:
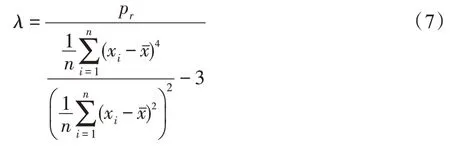
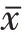
(加权邻域半径)设定加权邻域半径如下:

式中,d表示样本x与x之间的距离。
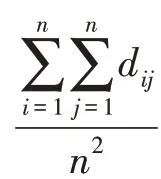
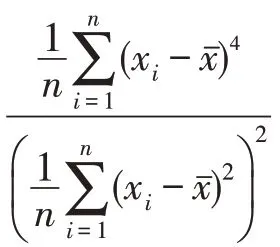
(2)修正系数p,数据集中的离散点对样本间距离均值的影响明显,容易导致邻域半径过大而失真,峰度系数对此修正不足,因此引入该系数用于修正邻域半径范围。
(局部密度)局部密度定义如下:

式中,为式(8)中表示的加权邻域半径。
以加权邻域半径内的样本数量作为局部密度,同时考虑到了数据的密度和内部结构的差异,能有效描述样本的分布状况,从而提升聚类效果。
算法依据局部密度将样本划分为核心样本、非核心样本和离散样本。
(核心样本、非核心样本及离散样本)核心样本c指在加权邻域半径内的局部密度高于指定阈值m的数据点。非核心样本b指内密度不高于指定阈值m的数据点。离散样本s指内不存在可以归属于任意簇的样本的数据点,如式(10)所示:
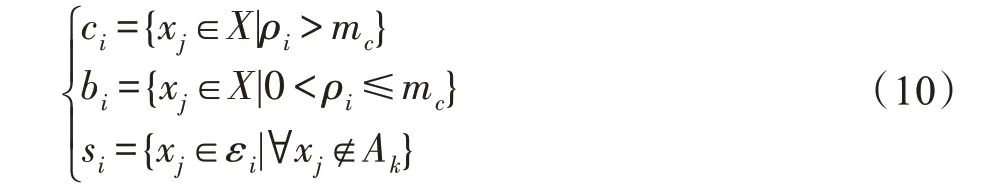
其中,ε表示x邻域半径内的样本,A表示任意类簇。
本文算法以近邻样本之间共享的样本数来度量样本之间相似度。样本划分依据是,核心样本的近邻样本较多,因此容易判断与近邻样本之间的相似性,从而与相似样本组成类簇,并可作为聚类的依据。非核心样本通常位于较低局部密度的区域,由于近邻样本较少,不容易判断该样本与近邻样本的相似性,若作为聚类依据,容易发生漂移。若样本无近邻点或虽有近邻点但这些近邻点都不属于任何类簇,则该样本同样不能归属于任一类簇,因此需要被标注为离散样本。三者的关系是,核心样本集与非核心样本集互斥互补,离散样本集则是非核心样本集的子集。
DPC 算法认为聚类中心点的局部密度在其周围样本中最高,可推断聚类中心点位于局部密度较高的区域,且其近邻存在局部密度较高的其他核心样本。如图2 所示,若样本1 是DPC 算法的聚类中心点,在邻域半径内密度最高,样本3 是样本1 邻域内一个局部密度较高的核心样本,显然两者有较高的相似性。DPC 算法认为聚类核心彼此距离较远,可以推断样本3 附近不存在其他聚类核心,可知样本3 归属于样本1 所在的类簇。同理,假设样本2 是样本3 邻域内另一个核心样本,则样本2 与样本3 也具有较高的相似性,且同属于样本1 所在类别。
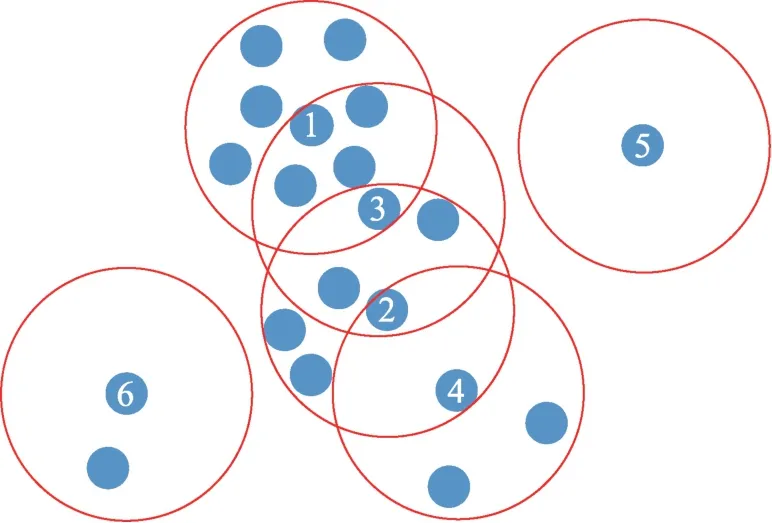
图2 数据分布示意图Fig.2 Schematic diagram of data distribution
可以发现,位于聚类中心点邻域半径内的核心样本和位于这些核心样本邻域半径内的其他核心样本同属于该聚类中心所在的类簇。样本4 是样本1邻域内的非核心样本,近邻点较少因此与其近邻点相似度都不高,难以确定是否属于同一类别。显然,非核心样本的近邻样本中属于某个类簇的样本越多,该非核心样本就与该类簇越相似。因此本文算法以非核心样本的近邻点所属类簇的众数确定其归属。离散样本5、6 因没有可以归属于任意类簇的近邻点,所以不属于任何类簇。可见,当聚类中心确定时,属于该类簇的核心样本成员,即核心样本组,亦就可以确定了,DPC 算法的聚类中心点就是核心样本组中密度最高的点。核心样本组的寻找可以从任意核心样本开始,找出其近邻核心点,进而扩散到整个数据集,从而实现无中心点的聚类。
图3(a)展示了Aggregation 数据集的样本分布图,由7 个相邻且不同形状的类簇构成,分别以不同的颜色表示。图3(b)是该数据集不同类簇的核心样本和非核心样本的分布图,不同类簇的核心样本颜色与图3(a)中相同类簇的颜色相同,非核心样本则以其他颜色表示。可以发现,每个类簇的核心样本都集中在类簇中间密度较高的区域,非核心样本则围绕在核心样本组的周围局部密度较低的区域,且当类簇密度较高时,该类簇的核心样本也较多,反之则偏少。可见,由核心样本构成的核心样本组在反映密度峰值的意义上与DPC 算法的聚类中心是一致的。DPC 算法依据聚类中心聚类时,若样本密度差异较大,同一类簇中可能找到多个密度峰值,使聚类结果不理想,而核心样本组则会将这些密度峰值划分到同一核心样本组中,从而避免该现象。因此核心样本组不但能够成为聚类的依据,而且聚类效果优于DPC 算法使用的聚类中心。
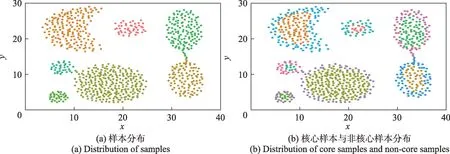
图3 Aggregation 数据分布图Fig.3 Distribution map of Aggregation dataset
2.2 簇归并策略
在给定数据集中,互为近邻的核心样本构成代表一个簇的核心样本组。识别核心样本的步骤中,只有核心样本会记录到代表类簇的核心样本组中,此时核心样本组等价于类簇。由于样本的顺序通常是未经排序的,当顺序遍历数据集寻找核心样本时,识别出的核心样本通常也是无序的,因此聚类过程中由核心样本组构成的类簇是变化的。由上节分析可知,互为近邻的核心样本属于同一类簇,因此当聚类过程中发现不同的核心样本组中存在相互近邻的样本时,表明这些样本组中的元素应属于同一类簇,需要将这些核心样本组归并成一个。
如图4 所示,核心样本按标号顺序被识别出。核心样本3 被识别时由于没有位于样本1 的邻域半径内,样本1 与样本3 此时应分别属于不同的簇(核心样本组)。当同时位于二者邻域半径内的样本5 被识别出时,可以发现三个样本是相似的,样本1 和样本3所在的簇是相似簇,需要以样本5 为介质进行归并。若不同核心样本所在簇不相似,则不进行归并,如样本1、3、5 和样本2、4 所在的簇。

图4 核心样本组归并示意图Fig.4 Schematic diagram of core sample groups
(类簇相似度)类簇相似度定义如下:
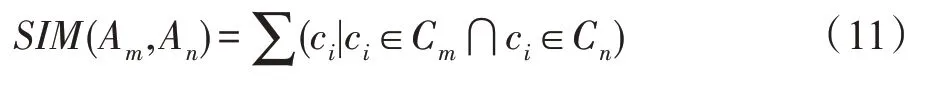
式中,C和C分别表示类簇A和A的核心样本组,c是C和C共享的核心样本。当(A,A)≥1时,类簇A和A相似。
当识别出所有核心样本后,没有归并的簇就组成了全部核心样本组。
2.3 非核心样本归属判定策略
样本与近邻点是相似的,越多近邻点属于同一类簇,表示样本与该类簇越相似,因此非核心样本b的归属采用近邻点所属类簇的众数来决定,包含b近邻点数p最多的类簇即为b最相似的类簇:

其中,N(b)∈A表示样本b属于类簇A的近邻点数量。当p=0 时,表示b为离散点。
DPC 算法中非聚类中心样本x单纯依赖于距离最近且局部密度更高的样本x,若x分配错误,x会跟随分配错误,容错率很低。本文算法使非核心样本的分配由多个近邻点共同决定,大幅提高了样本划分的容错率,因此能有效避免跟随错误。
特别是当数据集中出现类簇纠缠时,边界样本更容易出现距离其他类簇中有更高局部密度的样本更近的现象,因此本文算法相对于DPC 算法能更准确地识别出边界样本的所属类簇,使边界样本的分配更加精确可靠。
2.4 算法步骤
为消除样本属性之间量纲不一致带来的影响,本文将在计算前对数据进行归一化处理,将原始属性值通过线性变换映射到[0,1]区间。
(数据归一化)样本x的属性归一化定义如下:

式中,max(x)为样本x的属性的最大值,min(x)为样本x的属性的最小值。
算法步骤如下:
输入:数据集={,,…,x};核心对象邻域密度阈值m;邻域半径修正权值p。
根据式(13)对数据归一化。
根据式(8)计算加权邻域半径。
根据式(9)计算样本邻域密度ρ,然后根据式(9)划分样本:
将ρ>m的样本录入其近邻核心样本所在核心样本组,若样本的近邻核心样本还未被识别或无近邻核心样本,则该样本录入新核心样本组;
将ρ≤m的样本录入非核心对象队列中;
每当识别出一个核心样本时,检查该样本是否为核心样本组的共享样本,如果是则合并相似类簇。
完成核心样本识别后,对非核心样本按其近邻点所属类簇的众数,降序归入最相似的类簇中。
标识非核心样本队列中剩余没有近邻点的样本为离散点。
输出:聚类结果集。
2.5 算法复杂度分析
对于样本规模为的数据集,DPC 算法的时间复杂度主要来自计算任意两个样本间的距离、计算所有样本的局部密度以及计算每对样本之间的相对距离。每部分的时间复杂度均为(),因此DPC 算法的总时间复杂度为()。
本文DCM-DPC 算法的时间复杂度主要来源于:(1)计算数据集加权邻域半径的时间复杂度()。(2)计算每个样本的局部密度的时间复杂度()。(3)簇归并的时间复杂度(),其中为核心样本个数,小于样本个数,因此()<()。(4)划分非核心样本并标注离散点的时间复杂度<(),其中为样本的近邻点个数,≪,相比来说可以忽略不记;为非核心样本个数,<,且+=,有()≈()<(),因此本文算法总时间复杂度为(),与DPC 算法的时间复杂度相同。
3 实验结果与分析
3.1 实验数据集与评估指标
为验证DCM-DPC 算法的有效性,本文采用人工数据集与UCI 数据集进行测试和评估。为使测试数据多样化,选取的数据集在样本数量、属性数和类簇数跨度较大,这些数据集皆广泛地应用于聚类算法有效性的测试。数据集具体属性如表1 和表2 所示。
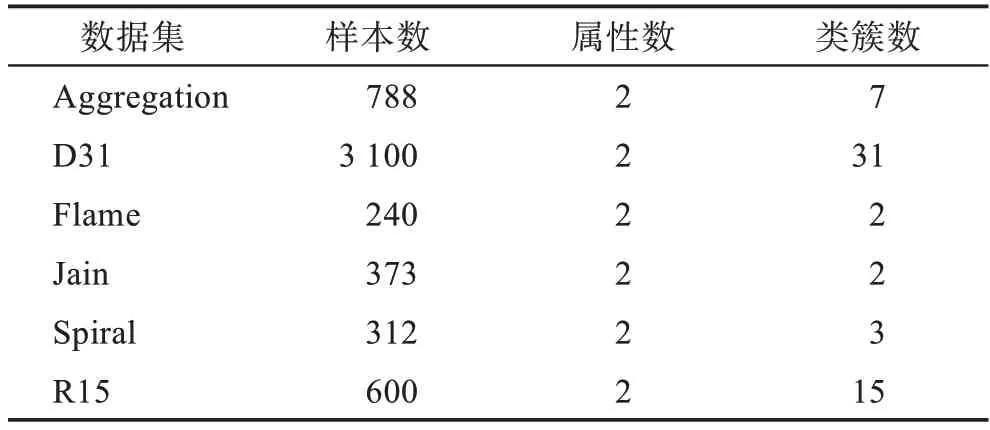
表1 人工数据集Table 1 Artificial datasets

表2 UCI数据集Table 2 UCI datasets
在以上数据集上选择DPC、FKNN-DPC、SNNDPC、DBSCAN和-means++算法与本文DCMDPC 算法进行比较。其中,DPC 和SNN-DPC 算法使用的是作者公开的源代码,FKNN-DPC、DBSCAN 和-means++算法参照原文献使用Python3.8 实现。本文依据参考文献对各算法的参数均进行了调优,以保证各算法的聚类效果。-means++算法因初始聚类中心的选取具有随机性会影响聚类结果,表3 和表4中采用100 次聚类结果的均值。
评估指标采用调整互信息(adjusted mutual information,AMI)、调整兰德系数(adjusted Rand index,ARI)和FMI 指数(Fowlkes Mallows index,FMI)。其中,AMI和FMI取值范围为[0,1],ARI取值范围为[-1,1],三者均是越接近1,表明聚类效果越优。
3.2 实验结果分析
表3 展示了6 种算法在UCI 数据集上的聚类结果,其中加粗字体表示较优的实验结果。实验结果显示,DPC 和FKNN-DPC 算法在属性数较多的数据集Soybean 上和Statlog 上聚类效果较差,但在属性较少的数据集Iris 上相对于SNN-DPC 和DBSCAN 算法取得了显著的优势;SNN-DPC 算法在Iris 和Soybean(Small)数据集上的聚类指标相对较差,但在Statlog(Heart)上取得了较好的聚类结果;-means++算法聚类效果正好与SNN-DPC 算法相反;DBSCAN 算法在3 个数据集上的聚类结果都不太理想;DCM-DPC 算法在Iris 数据集上的指标低于FKNN-DPC 算法,但在其余两个UCI 数据集上的聚类指标均优于全部对比算法,尤其在属性数量较多的数据集Soybean(Small)上和Statlog(Heart)上,算法根据近邻样本所属类簇的众数分配样本的策略有效利用了多个属性提供的维度信息来判断近邻样本间的相似性,使得DCMDPC 算法的聚类指标相对对比算法更具有明显的优势。
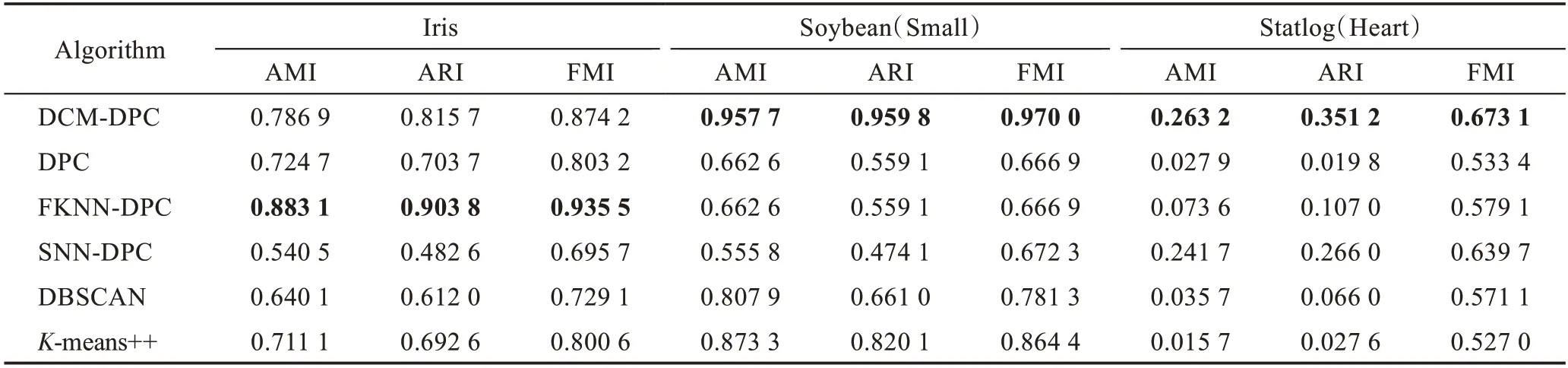
表3 6 种算法在UCI数据集上的聚类性能Table 3 Clustering performance of 6 algorithms on UCI datasets
表4 展示了6 种算法在人工数据集上的聚类结果,其中加粗字体表示较优的实验结果。实验结果显示,DCM-DPC 算法在参与测试的各个数据集上的聚类指标都较优秀,且比较平稳。在Aggregation、Jain、Spiral 和R15 人工数据集上,DCM-DPC 算法的聚类指标优于或持平对比算法,并在Jain 和Spiral 数据集上实现了零差错;在D31 和Flame 数据集中指标分别略低于FKNN-DPC 算法、SNN-DPC 算法和DPC算法。
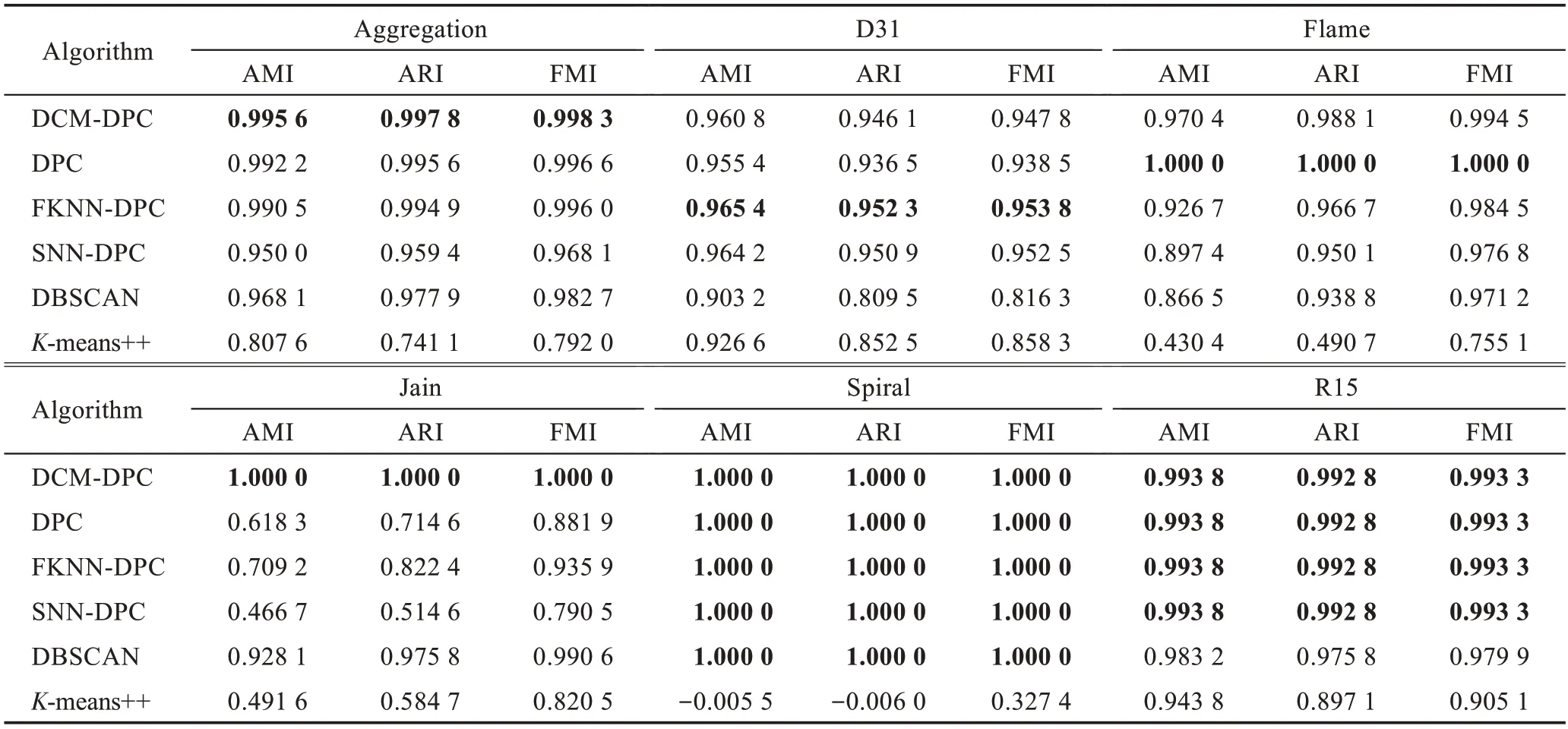
表4 6 种算法在人工数据集上的聚类性能Table 4 Clustering performance of 6 algorithms on artificial datasets
图5~图10 展示了6 种算法在人工数据集上的聚类效果,其中-means++算法选取实验聚类指标最优结果。不同类簇的样本以及离散点分别用不同的颜色表示。在同一组聚类效果对比图中,代表不同聚类算法的图片之间相同的颜色表示对应于同一个类簇。
图5 显示了6 种算法对Aggregation 数据集的聚类结果。除了-means++算法,其余5 种算法都在Aggregation 数据集上取得了较好的聚类效果。但DBSCAN 算法将左上角类簇右边缘部分样本和右侧两个类簇的邻接处样本误判成了离散点。在数据集左右两侧类簇的2 处边缘样本纠缠处,SNN-DPC 算法错误分配了17 个样本,DPC 和FKNN-DPC 算法分别错误分配了2 个样本;DCM-DPC 算法仅有1 个样本分配错误,聚类效果最好,对边缘样本的分配也是最准确的。

图5 Aggregation 数据集聚类效果Fig.5 Clustering effect on Aggregation dataset
图6 显示了6 种算法对D31 数据集的聚类结果。D31 数据集特点是规模较大,大部分样本聚合比较紧密,多处边缘样本存在纠缠,也有少数较为离散的样本。6 种算法聚类指标相差不大,DBSCAN 算法将大量类簇边缘样本误判成了离散点,指标最低;DCMDPC 算法对相互纠缠的边缘样本判断较准确,但在聚类过程中将右侧距离类簇较远的3 个样本误判成了离散点,使聚类指标略低于FKNN-DPC 和SNNDPC 算法。此外,D31 数据集中部分类簇存在少量样本深入到其他类簇的样本中,被其他类簇的样本包围,6 种聚类算法在此都进行了不同程度的误判,导致聚类效果有所下降。

图6 D31 数据集聚类效果Fig.6 Clustering effect on D31 dataset
图7 的Flame 数据集特点是一个类簇半包围着另一个类簇。除了-means++算法因其球形聚类特征使得聚类效果最差外,其余5 种算法在数据集上都取得了良好的聚类效果,其中DPC 算法聚类效果最优。DCM-DPC 算法在两个类簇交界处的样本划分非常准确,而FKNN-DPC、SNN-DPC 和DBSCAN 算法则在分配边界样本时都出现了错误。但DCMDPC 算法将左上侧2 个远离类簇的样本误判成了离散值,导致聚类指标略低于DPC 算法。
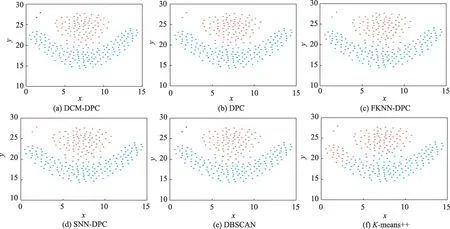
图7 Flame数据集聚类效果Fig.7 Clustering effect on Flame dataset
图8 的数据集Jain 是两个月牙状的类簇相互咬合。DPC、FKNN-DPC、SNN-DPC 和-means++算法在类簇咬合处都出现了大量样本分配错误,因此聚类指标较差。DBSCAN 算法则在聚类中心个数的确定上出现失误,将数据划分成了3 类。DCM-DPC 算法对咬合处样本的分配依旧非常准确,并实现了聚类结果零差错。
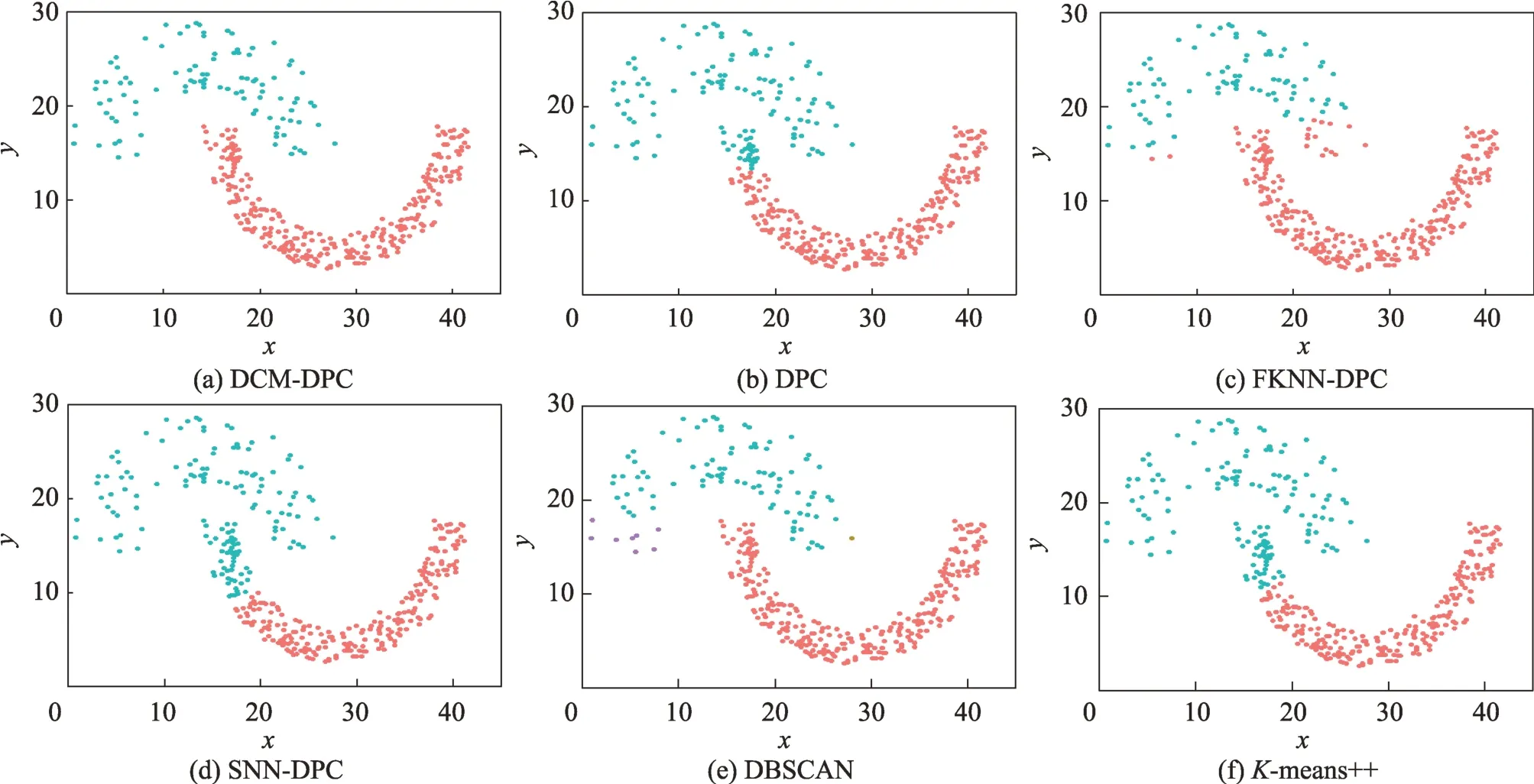
图8 Jain 数据集聚类效果Fig.8 Clustering effect on Jain dataset
图9 展示了6 种算法对Spiral 数据集的聚类结果。该数据集由三组相距明显的漩涡状类簇组成,类簇内部样本相邻紧密,类簇间样本相距较远,边界清晰,非常适合于密度聚类。除-means++算法外,其余5 种算法都准确无误地完成了聚类。
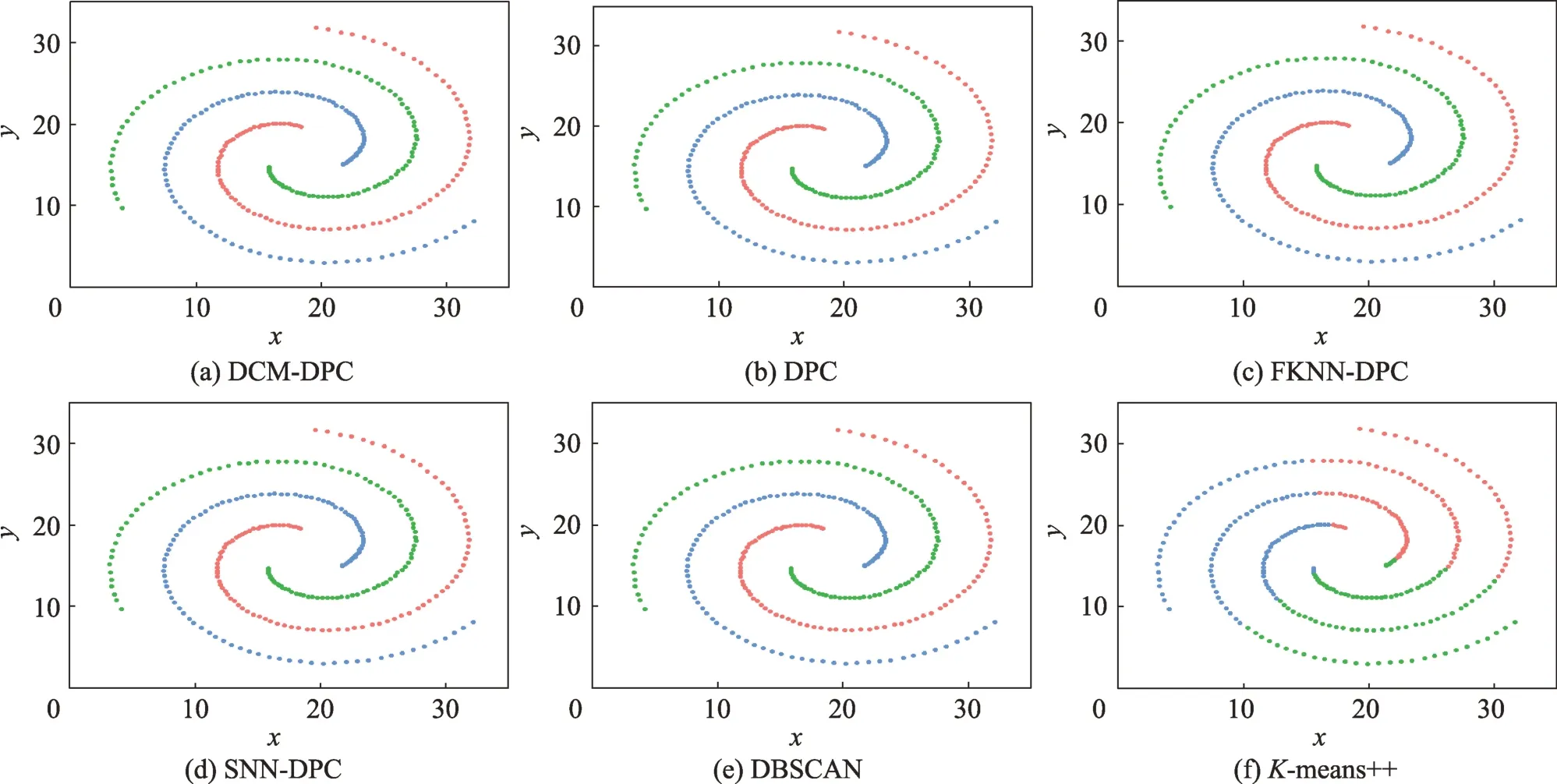
图9 Spiral数据集聚类效果Fig.9 Clustering effect on Spiral
图10 展示了6 种算法对R15 数据集的聚类结果。该数据集由15 个类簇组成,外圈类簇间隔明显,内圈类簇则相互纠缠。DCM-DPC、DPC、FKNNDPC 和SNN-DPC 算法聚类效果优于DBSCAN 和means++算法,且对内圈类簇边缘纠缠的样本归属判断准确度都较高。由于内圈的类簇中存在样本深入到其他类簇中,被其他类簇的样本包围,导致6 种算法均在此出现了误判。
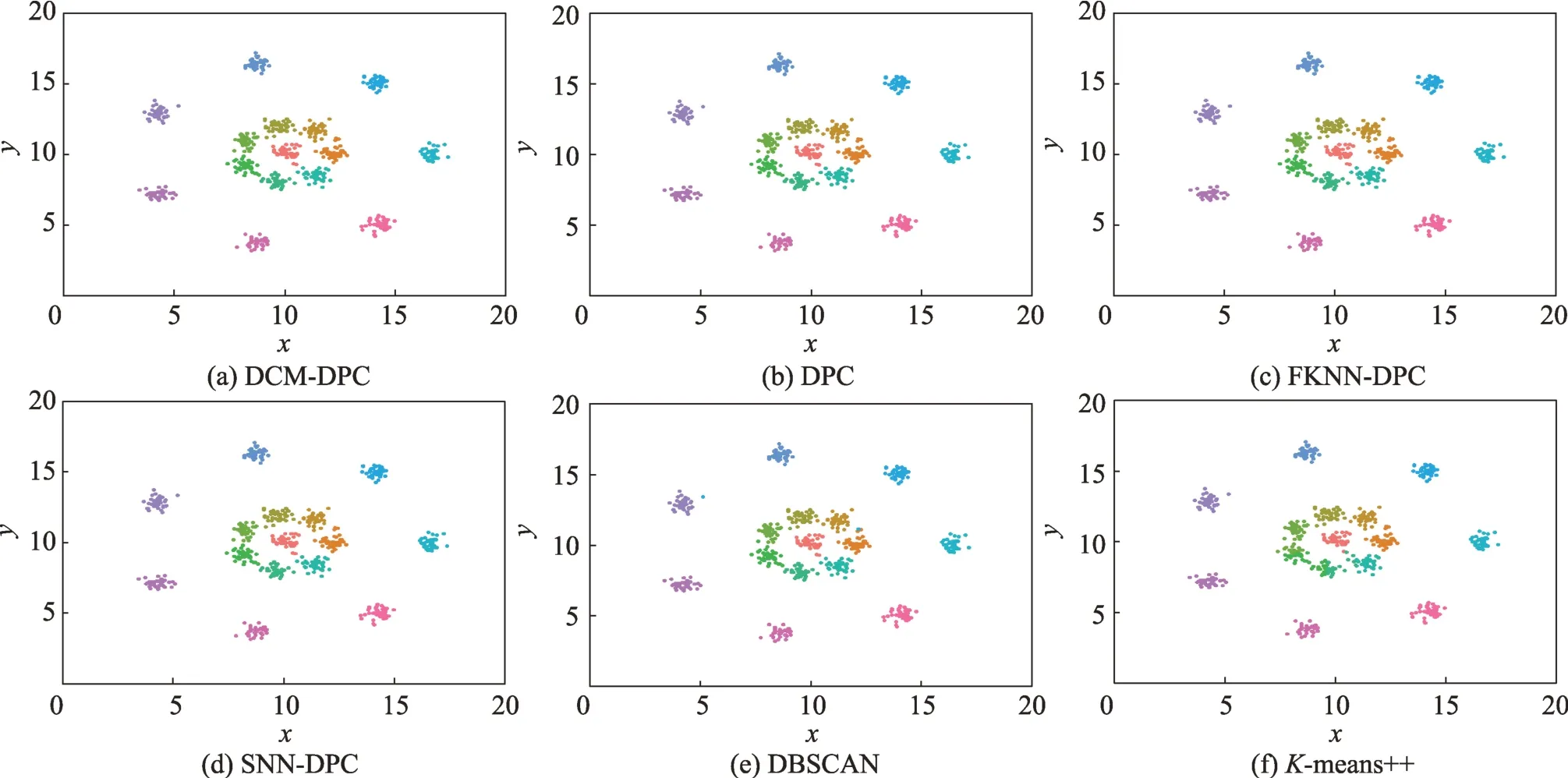
图10 R15 数据集聚类效果Fig.10 Clustering effect on R15 dataset
实验结果表明,DCM-DPC 算法在UCI 数据集Soybean(Small)和Statlog(Heart)的各项聚类指标均优于对比算法,在Iris 的聚类指标仅低于FKNN-DPC算法,且在属性较多的Soybean(Small)和Statlog(Heart)数据集上得益于多属性带来的丰富信息,聚类指标更加突出。在人工数据集Aggregation、Jain、Spiral 和R15 上,DCM-DPC 算法的三个指标均优于或等于对比算法。但由于DCM-DPC 算法在离散样本的判定上较为严格,可能会造成误判,这也是算法在数据集D31 上指标略低于FKNN-DPC 和SNNDPC 算法,在数据集Flame 上指标略低于DPC 算法的主要原因。
综合来看,DCM-DPC 算法在不同规模和属性数的数据集上都有良好的表现,对数据的适应广泛,并具有良好的鲁棒性。特别是对边界相互纠缠或咬合的类簇,能精确地分配其边界样本,相对于对比算法具有明显优势。
4 结束语
本文尝试提出了一种去中心化加权簇归并的密度峰值聚类算法DCM-DPC。DPC 算法依托聚类中心点聚类的方法容易影响聚类效果,且聚类中心点的选择需要人为干预。对此本文提出了消除聚类中心点的核心样本组聚类方法,通过由位于较高局部密度且互为近邻的样本组成的核心样本组形成类簇雏形,并取代聚类中心点成为其余样本划分的依据。核心样本组较聚类中心更加稳定,能使聚类具有更好的鲁棒性。新定义的局部密度更好地描述了数据的内部结构,使本文算法可以在不同规模、属性数和类簇的数据集上得到良好的聚类结果;通过样本的近邻点所属类簇的众数来决定样本归属,使样本划分时与类簇的关联性更强,有效缓解了跟随错误的产生。在人工和UCI数据集上的实验显示,本文算法在同类算法中具有较好的表现,且较对比算法能更加精确地分配相互纠缠或咬合的类簇的边界样本。由于本文算法在离散值的判定上比较严格,可能对游离的样本产生误判,提高对离散点的识别将是下一步的研究方向。
