XR-MSF-Unet:新冠肺炎肺部CT 图像自动分割模型
2022-08-16谢娟英张凯云
谢娟英,张凯云
陕西师范大学 计算机科学学院,西安710119
新型冠状病毒肺炎(corona virus disease 2019,COVID-19)给人类带来了巨大危害。2020 年2 月4日中国国家卫生健康委员会发布《新型冠状病毒感染的肺炎诊疗方案》(试行第五版),将CT(computed tomography)影像列为新冠肺炎临床诊断的重要依据。然而,医生浏览大量CT 影像做出诊断是繁重的体力和脑力工作,而且新冠肺炎病情多变,存在个体差异,给医生准确诊断带来挑战。利用人工智能(artificial intelligence,AI)技术精确划分CT 影像感染区域,辅助医生进行诊断是提高新冠肺炎诊断效率和准确率、减轻医生负担、减少漏诊和误诊的重要手段。
随着深度学习技术的不断发展,利用人工智能技术分割医学图像取得了很大进展。刘辰等人利用编解码结构和双向卷积长短记忆网络组成的卷积神经网络分割海马体MRI 图像获得了与专业医生几乎相同的分割结果;胡敏等人提出残差八度卷积块,结合混合注意力机制改进U-Net网络,从而更精确地分割脑出血CT 图像;沈怀艳等人提出一种利用多尺度语义特征融合和注意力机制的分割网络MSFA-Net,实现从腹部CT 图像中自动分割肝脏;余昇等人采用MBConvBlock 编码器模块、插值重构的解码器模块和改进的三重阈值策略改进U-Net网络,在气胸X 射线图像分割中取得了良好的性能;钱宝鑫等人提出了一种基于空洞空间金字塔池化、级联操作和注意力机制的编解码结构的肺部分割网络,有效分割出肺实质区域。
新冠肺炎患者肺部CT 图像,感染区域为毛玻璃样阴影及实变,斑片状模糊阴影弥漫整个肺区,极易与肺部气管、血管等混淆。因此,基于AI 技术有效分割新冠肺炎肺部CT 图像感染区域极具挑战。国内外关于新冠肺炎CT 图像辅助诊断研究包括CT 图像感染区域分割和分类两大类。分类方面:Wang 等人提出一种联合学习框架,通过对异构数据集进行学习,区分肺部CT 图像为新冠肺炎阳性和阴性;Butt等人使用传统ResNet-23 与加入注意力机制的ResNet-18 对新冠肺炎CT 图像与普通肺炎CT 图像和正常CT图像进行多分类研究。分割方面:Chen等人利用大量新冠肺炎CT 图像训练UNet++,对CT 图像进行分割,达到专业医生相当水平,但该研究依赖于大量CT 图像;Shan 等人提出一种基于“瓶颈结构”的VB-Net 网络来分割新冠肺炎CT 图像,并提出专业医生参与的“人在回路(human-in-the-loop,HITL)”的半监督训练策略减少网络训练时间,提高分割效率;Chen 等人通过在U-Net中加入残差结构和注意力机制改进网络,提高新冠肺炎CT 图像分割效果,但没有解决训练样本不足问题;Fan 等人提出基于并行解码器和多注意力机制的Inf-Net 网络对新冠肺炎CT 图像进行分割,并提出半监督训练方式缓解标记数据不足问题,实现对不同感染区域的多类分割;Budak 等人提出一种基于注意门控机制的ASegNet 模型实现自动分割新冠肺炎CT 图像的病变区域;Kumar 等人提出基于RFA(receptive-fieldaware)模块的LungINFseg 模型,其中提出的RFA 模块可以扩大感受域且不丢失任何特征信息,从而提高模型学习能力。此外,还有分割和分类相结合的研究:如,Wang 等人采用两步法来确定新冠肺炎是否阳性,训练一个弱监督分割网络对CT 图像进行分割,然后用DeCoVNet 网络识别是否新冠肺炎阳性;吴辰文等人利用BIN(batch normalization&instancenormalization)残差块改进U-Net网络分割新冠肺炎CT图像,结合多层感知器对分割后的图像进行分类预测。
尽管新冠肺炎CT 图像感染区域分割研究取得了较大进展,但是依然存在如下问题:首先,大部分研究所用数据集是非公开的,训练样本少,易导致过拟合,研究结果泛化性能较差,所得系统无法辅助临床诊断;其次,新冠肺炎肺部CT 图像复杂,极易与其他肺部疾病混淆,编码器提取有效分割特征非常困难;另外,新冠肺炎感染区域的弥漫性、位置不定、边界不清、形状多变,需要分割模型有极强的细节特征提取能力。
为解决上述问题,本文首先利用数据扩充技术对数据集进行扩充,增加数据多样性,以增强模型鲁棒性,缓解目前存在的相关训练数据不足导致的模型过拟合问题。其次对U-Net 网络结构进行改进,在Xie等人的ResNeXt结构启发下,提出XR(X ResNet)模块,使用XR 替换U-Net的两层普通卷积,以增强模型的特征提取能力。然后提出即插即用的融合多尺度特征的注意力模块MSF(multi-scale features fusion module),融合不同大小感受野、全局、局部以及空间信息,提取包含更多细节信息的特征,以强化模型的细节分割效果。综合上述改进,提出针对新冠肺炎CT 图像感染区域自动分割的新模型XR-MSF-Unet。
1 相关工作
1.1 U-Net网络
传统语义分割采用基于颜色、形状等低级语义信息,无法很好分割复杂图像。深度学习技术使用高级语义信息进行分割。2015 年,Long 等人首次使用全卷积神经网络对自然图像进行端到端分割,实现了从传统方法到深度学习方法的突破。2015 年Ronneberger 等人在全卷积神经网络基础上提出UNet 结构,在ISBI 细胞分割挑战赛中获得第一名。UNet 网络包含编码和解码两部分,编码器进行下采样操作,提取原始图像空间特征,解码器进行上采样操作,根据编码器所提取的空间特征构造出图像。为了防止对应特征丢失,对应编码器和解码器之间有跳跃连接。U-Net的编码器采用两层3×3 卷积、ReLU激活函数和2×2 最大池化,来提取图像特征,共进行4次下采样,该过程降低特征图尺寸,增加通道数,最终通道数为原来的16 倍。解码器部分使用2×2 反卷积进行上采样,减少通道数,逐渐恢复特征图尺寸。
然而,新冠肺炎CT 图像十分复杂,U-Net 在编码器每一个阶段仅使用普通的两层卷积和池化操作来提取特征,相较于经过设计的卷积组合,这样的特征提取方式容易导致模型无法提取到全部有用的特征信息,甚至还会有一部分特征在这个过程中丢失。此外,U-Net 的解码器在逐步恢复图像时也采用简单的两层卷积和反卷积进行,这样又会导致一定的特征信息损失,最终使得网络无法完全恢复图像的复杂特征信息。另外,U-Net 没有考虑全局、局部和不同空间位置的特征差异。为了提取新冠肺炎CT 图像的复杂特征,提升对该类CT 图像感染区域分割的准确性,本文将对U-Net的特征提取结构进行改进。
1.2 卷积块的聚集残差变换
深层网络模型往往具有更强特征提取能力。Alex 等人提出的AlexNet 通过堆叠卷积和分组卷积增加网络深度,在2012 年的ImageNet 竞赛中取得冠军。随后,加深网络深度和堆叠卷积成为深度学习的热点。Szegedy 等人提出的Inception 系列网络,使用特定的堆叠卷积和分组卷积提取更多特征信息,但Inception 系列网络的超参数有较强针对性,泛化性一般;另外,随着网络层数加深,模型的时间复杂度和空间复杂度不断增加,并带来梯度爆炸和消失问题。为此,He 等人2016 年提出ResNet,通过跳层连接避免网络层数加深带来的问题,同时避免高层特征损失,得到保留更多细节信息的特征图,提高网络提取信息的能力。
在ResNet 基础上,Xie 等人于2017年结合Inception 系列网络的“分解-转换-融合”策略,提出ResNeXt 网络。ResNeXt 提出“基数(cardinality)”概念,表示聚合的相同拓扑结构的数量。ResNeXt 网络将输入图像经过“基数”个相同拓扑结构,聚合这些结构的输出,经过一个全局池化得到最终的特征映射。通过聚合“基数”个相同拓扑结构,使模型在增加少量参数基础上,提取到更多特征信息,有效增加模型的特征提取能力,提升模型性能。
1.3 注意力机制
注意力机制是深度学习领域备受青睐的技术,其原理源于人类视觉注意力机制,目的是使模型在处理信息时能实现信息资源的高效分配。注意力机制通过快速扫描全局,发现需要关注的重点区域,即注意力焦点,对这些区域投入更多关注,从而获得更多信息,同时抑制其他区域的干扰信息。Tsotsos等人在1995 年首次将注意力机制引入计算机视觉领域,认为注意力作用就是通过减少处理样本,增加样本间的特征匹配度,优化传统视觉搜索方法。2017年的图像分类挑战赛ILSVRC 中提出的SENet开启了融入注意力机制的深度学习。目前,注意力机制在分类、目标检测、语义分割等计算机视觉领域被广泛应用。
新冠肺炎肺部CT 图像感染区域不仅包含磨玻璃阴影、铺路石征、血管、气管扩张等影像学表现,还有肺部正常血管、气管以及结节等信息。对图像感染区域进行分割,需要模型能够“关注”感染区域。因此,本文将使用注意力机制,以使模型重点“关注”感染区域,抑制其他信息,实现新冠肺炎CT 图像感染区域的有效分割,提升模型的分割效果。
2 本文方法
本章首先介绍提出的XR-MSF-Unet 模型的整体结构,然后详细阐述XR-MSF-Unet 模型中提出的XR模块和MSF 注意力模块,最后介绍训练模型使用的损失函数。
2.1 XR-MSF-Unet模型
XR-MSF-Unet模型结构如图1 所示,包括编码区和解码区,是一个端到端的分割模型。提出的XR 模块进行特征提取和恢复,编码区每个XR 模块后是提出的多尺度特征融合注意力模块MSF,解码区通过连续4 次上采样,恢复图像分辨率,输出分割图像。
从图1 可见,XR-MSF-Unet 模型引入XR 模块 提取更多特征信息,输入图像经过5 个XR 模块组成的编码器进行4 次下采样,提取到尽可能多的特征信息,再使用4 个XR 模块组成的解码器进行上采样,尽可能多地恢复图像信息。为了防止编码区和解码区对应位置的特征丢失,使用跳跃连接来连接对应的编码器和解码器,和U-Net 不同的是这里不需要剪裁,只需要拷贝即可。为了使模型重点“关注”感染区域,XR-MSF-Unet 模型在编码器的每个XR 模块之后加入提出的多尺度特征融合注意力模块MSF,期望从丰富的特征信息中“关注”感兴趣区域,提高模型的细节分割效果。

图1 XR-MSF-Unet网络结构示意图Fig.1 Diagram of XR-MSF-Unet network structure
2.2 聚合残差块模块XR
新冠肺炎肺部CT 图像感染区域形状复杂、边界模糊,与图像中其他结构极易混淆。为了更好地分割出新冠肺炎肺部CT 图像感染区域,对ResNeXt 模块进行推广,提出图2 所示的XR 模块。每个分支都由1×1、3×3 和1×1 卷积组成,且都含有跳层连接,个分支聚合,构成XR 模块。XR 模块通过个残差块的不同卷积提取图像特征,以便获得更好的分割特征。
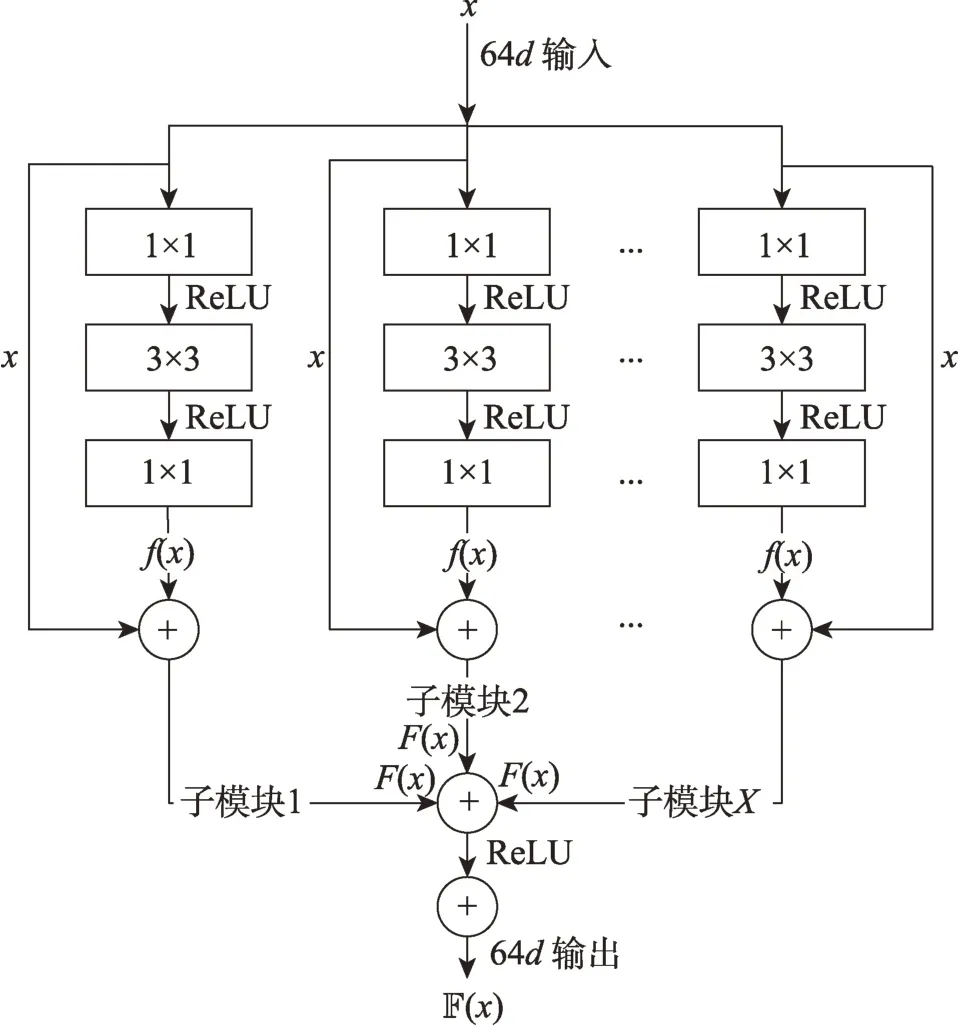
图2 XR 模块结构图Fig.2 Diagram of XR module structure

如图2 所示,由于不同分支的卷积路径关注的特征信息不同,同一特征图在经过不同的卷积路径后得到的特征图也是不相同的,但是不同路径得到的特征图的耦合性较低,综合所有卷积路径的特征图并进行融合可以互相补充缺失的特征信息,这样有利于得到更加完整的图像特征信息。此外,XR 模块的每一条卷积路径使用了一个完整的残差结构,由于残差结构可以解决网络加深带来的性能退化问题,从而进一步避免了特征提取过程中产生的特征损失,更加有助于模型提取到更多特征信息。
2.3 多尺度特征融合注意力模块MSF
新冠肺炎感染区域大多为弥漫性感染,整幅图像中各个角落都可能存在感染区。卷积感受野大小决定特征关注区域大小,感受野过大或过小可能会使CT 图像部分感染区域被分割错误。另外,新冠肺炎感染区域位置不定,形状复杂,极易与其他肺部结构混淆,因此,为使模型能发现感染区域并增加其发现感染区域的能力,提出图3 所示的融合多尺度特征的即插即用注意力模块MSF(multi-scale features fusion module)。
为了避免感受野不同给模型特征提取带来的问题,MSF 模块使用3×3、5×5 和7×7 三种不同大小感受野的卷积核以并行的方式提取特征,这三种不同大小的卷积核分别具有小、中、大三种不同大小的感受野,提取的特征分别经过批归一化BN 和ReLU 激活后进行特征融合,这样并行的特征提取策略可以最大程度地减少串行卷积带来的特征损失,可以保证融合后的特征图中尽可能多地包含图像的各种特征信息。之后,融合的特征分别经过全局注意力模块(global attention module,GAM)和空间注意力模块(spatial attention module,SAM)构成的一个分支以及局部注意力模块(local attention module,LAM)和空间注意力模块SAM 构成的另一个分支,最后将两支注意力模块特征加和,实现不同大小感受野、全局、局部和不同空间特征的融合,使最终输出的特征图包含不同尺度和位置的信息,从各种维度最大限度保证模型提取到图像更多的特征信息。


图3 多尺度特征融合的注意力模块MSFFig.3 MSF attention module fusing multi-scale features

全局注意力模块GAM 如图4 所示,采用注意力模块CBAM(convolutional block attention module)中的通道注意力模块(channel attention module,CAM)。其中的全局平均池化(global average pooling,GAP)在结构上对整个网络进行正则化,避免了过拟合;全局最大池化(global max pooling,GMP)可以找到每个通道最大值的坐标,减少输出层特征维度,减少图像噪声对提取特征的影响。因此,GAP 和GMP 模块有助于模型获取上下文关系,使GAM 模块能更好地关注全局重点信息,有利于模型“关注”散布在整个图像中的感染区域,增加模型的整体性能。1×1 卷积、ReLU 激活函数、1×1 卷积组成GAM 模块的网络连接层,为Sigmoid 函数,⊕为加和操作。GAM 模块得到式(5)表示的特征图。

图4 全局注意力模块GAMFig.4 Global attention module GAM

局部特征信息提取的LAM 采用Wang 等人提出的ECA(efficient channel attention)注意力模块。ECA对输入特征图进行全局平均池化,通过一个1×大小的一维卷积实现局部跨通道交互,表示参与该通道注意力预测的邻域通道数,代表局部跨通道交互的覆盖率,实验中值自动选择。
使不同邻域通道参与某一个通道预测,能有效注意到图像的细节信息,提高模型对图像细节信息的“关注”能力。因此,本文使用该模块提高模型对感染区域局部细节的“关注”,实现更加精细的分割。
空间注意力模块SAM 来自文献[30],其主要作用是让模型关注特征位置信息,关注有意义特征。SAM 模块对输入特征进行基于通道的最大池化和平均池化,得到两个单通道结果,将该两结果拼接,经过卷积操作得到一张二维特征图,再经过Sigmoid 函数得到最终的空间注意力特征图。与文献[30]的SAM模块对拼接特征进行7×7 卷积不同,本文通过实验选择1×1 卷积。
图3 中SAM 模块分别将GAM、LAM 模块的输出特征作为输入。GAM 模块的特征图经过SAM 模块得到式(6)融合全局和空间信息的特征图;LAM 模块的特征图经过SAM 模块后得到式(7)融合局部和空间信息的特征图。其中,AvgPool和MaxPool 分别表示平均池化和最大池化,[;]表示、拼接操作。

2.4 损失函数
医学图像分割领域常用的损失函数是Milletari等人在2016 年提出的Dice Loss。Dice Loss 能很好地解决医学图像中正负类样本不平衡问题。新冠肺炎感染区域分割图像中感染区域(正类)和背景区域(负类)的分布不平衡,因此,本文使用Dice Loss 作为损失函数。Dice Loss源于Dice 系数(dice coefficient,DC),Dice 系数是一种集合相似性度量函数,计算两个集合的相似度,取值在[0,1]之间,如式(8)。

其中,代表真实结果GT(ground truth),代表模型分割的结果(predicted value),|⋂|表示集合和交集的元素个数,||和||分别表示集合和的元素个数。Dice Loss表示为式(9)。

由于有监督的图像分割本质上是对像素点进行分类,Dice Loss在图像分割表示为式(10)。

其中,为图像总像素点数,为类别数,本文(=2)代表新冠肺炎图像的感染区域和背景。(,)∈[0,1]代表像素点被划分到第类的概率,即预测图中像素点属于类的概率,(,)∈[0,1]代表图像中像素点属于类的真实概率。
3 实验结果及分析
本章先介绍实验数据、评价指标和实验环境,然后测试本文的数据扩增方法、XR-MSF-Unet 模型及其各模块的性能,最后测试XR-MSF-Unet 模型的泛化性。
3.1 实验数据
第3.1~3.7 节的实验数据来自数据集COVID-19 CT Segmentation Dataset,包含约60 例新冠肺炎患者的100张CT 图像,是最具挑战性的COVID-19分割数据集,本文命名为COVID-19-1。第3.8 节的实验数据来自COVID-19 CT Segmentation Dataset的另外一个数据集,本文命名为COVID-19-2,以及来自COVID-19 CT Lung and Infection Segmentation Dataset和Mos-MedData的本文命名为COVID-19-3 和COVID-19-4 的数据集。
其中,COVID-19-1 数据集由意大利医学和介入放射学会(Italian Society of Medical and Interventional Radiology)收集,包含约60 名新冠肺炎患者的共100张轴向CT 图像和放射科医生对这100 张CT 图像感染区域的标注图像。COVID-19-2 数据集由Radiopaedia 的9 个不同病例的共829 张轴向二维CT 切片组成,其中有373 张为新冠肺炎切片,由放射科医生进行了感染区域的分割标注,原始数据格式为NIFTI。COVID-19-3 数据集由Coronacases Initiative和Radiopaedia 的20 个不同病例的共1 844 张新冠肺炎CT 切片组成,感染区域由有经验的放射科医生进行标注。COVID-19-4 数据集来源于俄罗斯莫斯科市立医院,包含1 110 个病例的肺部CT 图像,本文使用的为来自其中50 个病例的有专家标注图像感染区域的785 张确诊新冠肺炎CT 图像。各数据集的详细信息见表1。

表1 实验用COVID-19 CT 图像数据集Table 1 COVID-19 CT image datasets for experiments
3.2 评价指标与实验环境
实验结果评价使用Dice、IOU、F1-Score 和Sensitivity 四种常用的医学图像分割评价指标,这4 种指标的计算方式如式(11)~(14)所示,式(11)和式(8)本质上相同。

其中,表示网络输出的感染区域是真实的感染区域;表示网络输出的背景区域是真实的背景区域;表示网络输出的感染区域不是真实的感染区域,即错误地将背景分割为感染区域;表示网络输出的背景区域不是真实的背景区域,即错误地将感染区域分割为背景。这些评价指标的取值越大,代表模型的分割效果越好。
本文实验采用开源深度学习框架PyTorch1.5.1实现提出的XR-MSF-Unet 模型,使用GPU 加速网络模型的训练和测试,显卡型号为GeForce RTX 2080Ti。实验训练和测试阶段的batch size均为1,共训练200轮次。优化器采用RMSProp,初始学习率设置为0.001,权重衰减系数设置为1E-8。
不同优化器会影响模型性能,为此使用四种常见的优化器RMSProp(root mean square propagation)、Adam(adaptive moment estimation)、SGD(stochastic gradient descent)和Adamax(adam based on the infinity norm)分别训练模型,比较模型性能,选择最合适的优化器。实验中使用U-Net网络,四个优化器的初始学习率均设置为0.001,权重衰减系数均设置为1E-8。实验结果如表2 所示,加粗表示最好结果。

表2 不同优化器下的模型性能比较Table 2 Comparison of model performance using different optimizers
表2 结果显示,RMSProp 优化器使模型的Dice和F1-Score 指标最好;Adamax 优化器使模型的IOU和Sensitivity 指标最好;SGD 优化器的效果最差;虽然Adam 优化器使模型的Sensitivity 指标优于RMSProp 优化器的效果,但是其他指标均不如RMSProp 优化器。综上所述,以Dice 指标作为最主要的评价标准,RMSProp 优化器综合效果最好,因此,本文采用RMSProp 优化算法。
3.3 数据扩增方法测试
由于COVID-19-1 数据集的样本量对于需要大量训练数据的深度学习模型来说,会带来过拟合,将数据按1∶1 比例划分为训练集和测试集,对训练集的50 张CT 图像使用随机旋转、颜色抖动以及中心裁剪等方法进行扩增,最终得到包含原始数据在内的共350 张CT 图像作为训练集。使用U-Net网络来测试数据扩增的有效性,测试结果如表3 所示。实验中从训练集随机选择10%数据作为验证子集,用于调整模型参数,监控是否发生过拟合,其余90%作为训练子集训练模型。以测试集来测试训练所得模型的分割性能。

表3 数据扩增有效性测试结果Table 3 Testing results of data augmentation efficacy
表3 结果显示,U-Net模型的各项评价指标Dice、IOU、F1-Score 以及Sensitivity 在数据扩增之后,均得到提升,说明数据扩增有利于提升模型的分割性能。因此,本文后续实验均使用扩增后的数据集作为训练集。
3.4 XR 模块参数测试
XR 模块由个相同的残差块聚合而成,为了探究聚合多少个残差块模型性能最好,实验设计了只有1 个残差块和聚合2、4、8、16、32、64 个残差块的XR 模块,将这7 种聚合了不同数量残差块的XR 模块嵌入到U-Net 网络进行实验,实验结果如表4 所示,加粗表示最好结果。残差块数0 表示没有嵌入XR 模块的原始U-Net模型的实验结果。

表4 XR 模块中残差块参数X 测试的实验结果Table 4 Experimental results of parameter X of residual blocks embedded in XR module
表4 结果显示,当XR 模块只聚合一个残差块时,不仅没有提升原始U-Net 模型的分割效果,反而使其分割效果变差;但当聚合2 个以上残差块时,U-Net的分割效果开始逐渐提升,直到聚合32 个残差块时达到最好分割效果。而当聚合64 个残差块时,模型的分割效果最差。分析原因是过多的残差块使得模型过于复杂,造成了过拟合。因此,本文使用聚合32 个残差块的XR 模块替换U-Net中用于特征提取(编码)和恢复(解码)的卷积模块。
3.5 MSF 模块测试
本节将通过实验测试MSF 模块的空间注意力模块SAM 的最佳卷积核设置,MSF 模块对不同类型注意力模块特征进行加和时的权重系数设置,MSF 模块在U-Net 网络的最佳位置,比较MSF 与其他注意力模块的性能,并将MSF 模块嵌入不同baseline 验证其性能,最后对MSF 模块各个组件的有效性以及模块的复杂度进行实验分析。
提出的MSF 模块中的空间注意力模块SAM 需要经过一个卷积降维,该卷积块的卷积核大小对于整个MSF 注意力模块至关重要。本文通过实验测试MSF 模块的SAM 模块的卷积核大小设置。表5 展示了将MSF 模块加在U-Net 编码区,设置SAM 模块不同大小的卷积核得到的实验结果,加粗表示最好结果。

表5 SAM 模块的卷积核大小测试实验结果Table 5 Experimental results for testing kernel sizes of SAM module
表5 实验结果显示,当SAM 模块采用1×1 卷积核时,模型取得了最优的分割结果,说明在进行复杂图像分割时,1×1 的小卷积核能使特征图信息保存得更加完整,同时也能从特征图中获得更多细节特征,有利于模型“关注”细节特征,获得更好分割结果。因此,本文后续实验中,MSF 模块的空间注意力模块SAM 的卷积核大小设置为1×1。
MSF 模块对经过SAM 模块的融合全局与空间信息的特征图和融合局部信息与空间信息的特征图的对应元素相加得到融合特征。为了确定和这两个特征图加和时的权重比,分别对这两个特征赋予不同权重进行加和,测试对U-Net 模型性能的影响。实验结果如表6 所示,加粗表示最好结果。
表6 实验结果显示,当两部分特征图加和时的权重比为1∶1 时,MSF 模块能提取到分割性能最好的特征。当两部分特征图的权重比分别为2∶3、3∶7 和1∶4时,MSF 模块获得的特征的分割性能非常差,各项分割指标基本趋于0,而当权重比为3∶2、4∶1、7∶3 时,MSF 模块提取的特征的分割性能优于相反的权重比,说明特征对MSF 模块提取的特征的分割性能影响较大。当权重比为1∶9 和9∶1 时,MSF 模块提取的特征的分割能力大幅提升,仅次于权重比为1∶1时的特征,且9∶1 时MSF 模块提取的特征的分割能力更好,不仅说明特征图对MSF 模块提取的特征的分割性能影响较大,也说明特征图对MSF 特征的分割能力的强大贡献。综合上述分析,在融合两部分特征时将权重设置为1∶1 最佳。

表6 MSF 模块特征融合的权重测试实验Table 6 Experiments for testing weights for feature fusion of MSF module
提出的MSF 是即插即用注意力模块,放置在网络不同编码位置对实验结果会有不同影响。图5 展示了MSF 模块嵌入到U-Net 的8 种位置,对每一种情况进行实验测试,实验结果如表7 所示,加粗表示最好结果。

图5 MSF 模块在U-Net的不同位置Fig.5 MSF modules in different locations of U-Net
表7 实验结果显示,当MSF 模块在编码区时得到的分割结果最好。分析原因是MSF 模块的主要功能是获得图像更多特征信息,嵌入编码区域,距离输入层近,能够从原始图像获得更多特征信息,而解码区的特征是经过编码区特征提取后,上采样还原的特征,无法表达图像细节信息。

表7 MSF 模块在U-Net不同位置的模型性能Table 7 Performance of U-Net embedding MSF module in different positions
因此,后续实验均将提出的MSF 模块嵌入在编码区,也就是图5 的L2 所示。
为了验证提出的即插即用注意力模块MSF 在新冠肺炎肺部CT 图像感染区域分割中的有效性,将MSF 与其他注意力模块进行对比实验。为保证实验公平,所有注意力模块均放置在U-Net 编码区,实验数据集划分和实验环境均相同,测试结果如表8 所示,加粗表示最好结果。

表8 MSF 注意力模块与其他注意力模块的性能对比Table 8 Performance comparison of MSF and other attention modules
表8实验结果显示,在新冠肺炎肺部CT感染区域分割中,相比其他注意力模块,提出的MSF 模块嵌入U-Net 模型能够取得最优的分割结果。SE(squeezeand-excitation)、CBAM 和ECA 注意力模块不仅没有提升U-Net 的分割效果,反而使其性能降低。SCSE(concurrent spatial and channel squeeze and channel excitation)注意力机制虽然提高了U-Net 的Dice 指标,但提升较少,且加入SCSE的U-Net模型的IOU、F1-Score和Sensitivity 指标均不如原始U-Net 模型。综上分析可见,提出的MSF 模块在新冠肺炎肺部CT 感染区域分割中最有效。
为了更加清楚地显示MSF 模块能够更好地分割细节的优势,将表8 各模块的分割结果进行可视化显示。图6(a)、(b)展示了表8 带有不同注意力模块的U-Net 模型对测试集随机选择的两张CT 图像的分割结果,其中Ground Truth 表示真实标签,第二到第六行分别表示MSF+U-Net、ECA+U-Net、SCSE+U-Net、CBAM+U-Net 和SE+U-Net 各模型的分割结果,红色框标记的是各个模型的分割结果中更能体现分割细节的感染区域。各模型分割结果的边界细节使用Canny 边缘检测算法得到。

图6 MSF 模块与其他注意力模块的细节分割对比Fig.6 Comparison of segmentation details between MSF module and other attention modules
图6 的可视化结果显示,MSF 模块嵌入U-Net 模型的细节分割效果比嵌入其他几种注意力模块的效果都好。图6(a)红色框标记的Ground Truth 部分形状类似字母“M”,且与旁边感染区域之间有间隔缝隙。图6(a)嵌入不同注意力模块的U-Net 模型的分割结果中,嵌入MSF 的U-Net 模型的分割结果与真实标记最相似,且与其他感染区域不相连;ECA+UNet 模型的分割结果与旁边感染区域相连;嵌入其他注意力模块的U-Net 模型的分割结果虽然与旁边感染区域分开,但分割出的区域均与标记区域形状差异很大。图6(b)红色框标记的分割结果显示,只有MSF嵌入U-Net模型的分割结果与真实标记的Ground Truth 相似,其余各模型的分割效果都与真实标记相差很大。综上所述,相对于其他注意力模块,本文提出的多尺度特征融合注意力模块MSF 具有更好的细节分割能力。
为了进一步验证提出的注意力模块MSF 提取新冠肺炎肺部CT 图像分割特征的能力,将其嵌入FCN(fully convolutional networks)、FusionNet、SegNet三个不同模型进行实验。为了保证实验公平和有效,这三个Baseline 和U-Net 一样是编码区和解码区结构,MSF 模块均放置在各模型的编码区,实验数据划分和实验环境均相同,实验结果如图7 所示。图7(a)~(d)分别展示了MSF 嵌入U-Net、FCN、Fusion-Net 及SegNet 前后对应模型的Dice、IOU、F1-Score 和Sensitivity 指标值。
图7实验结果显示,将MSF模块嵌入U-Net、FCN、FusionNet及SegNet模型,除了U-Net模型的F1-Score和SegNet 模型的IOU,各模型的Dice、IOU、F1-Score和Sensitivity 评价指标均有所提升,其中,各模型的Dice 和Sensitivity 指标均得到提升。说明提出的MSF 模块能学习获得性能非常好的新冠肺炎CT 图像分割特征,这些特征的强大分割性能使得加入MSF 注意力机制模块的各模型能更好地分割新冠肺炎肺部CT 图像的感染区域。
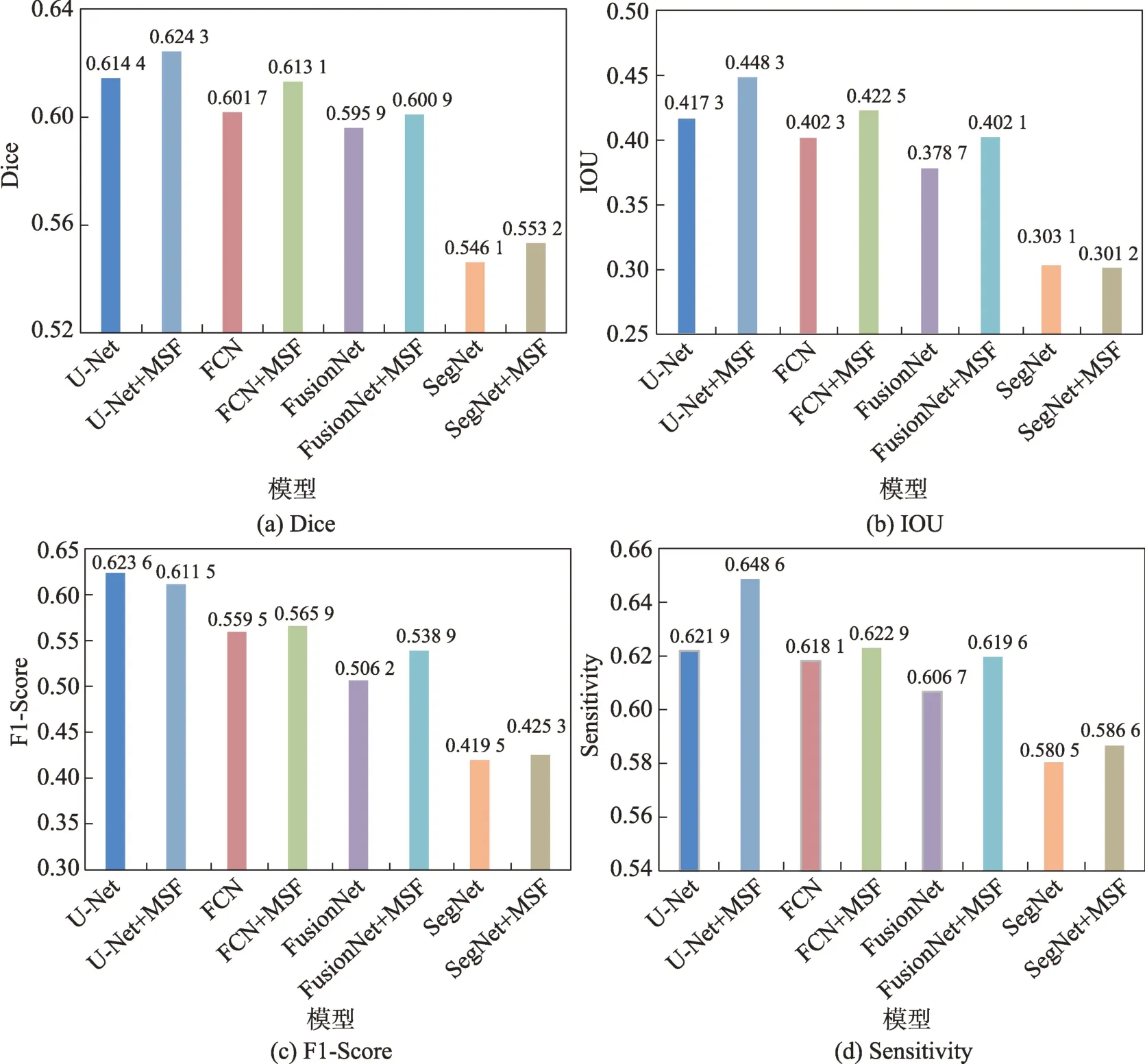
图7 MSF 模块嵌入不同Baseline的实验结果Fig.7 Experimental results of MSF module embedded in different baselines
作为一种即插即用的注意力模块,MSF 的有效性在第3.5.4~3.5.5 小节得到了验证,本小节对MSF模块中每一个组件的有效性和复杂度进行分析。使用DRF(different receptive field)表示MSF 模块中的不同大小感受野模块,采用消融实验方式验证DRF和MSF模块中的全局、局部和空间注意力模块GAM、LAM、SAM 的有效性。表9 中展示MSF 模块的消融实验结果,“√”表示包含相应模块。另外,模型的参数量(parameters)可以衡量模型的时间和空间复杂度,每秒帧率(frame per second,FPS)表示模型每秒内处理的图片数量,可以用来衡量模型的时间复杂度,因此MSF 模块的复杂度将通过计算模型的参数量和每秒帧率来进行评价。表9 同时展示了模型的复杂度。加粗表示最好结果。

表9 MSF 模块的消融实验及复杂度分析Table 9 Ablation experiments and complexity analysis of MSF module
表9 结果显示,将完整的MSF 模块加入U-Net 可以使模型达到最好的分割性能。无论是去掉MSF 模块中的不同大小感受野DRF,还是全局注意力模块GAM、局部注意力模块LAM 或者空间注意力模块SAM,模型的分割性能都受到不同程度的影响。其中,LAM 模块对模型的性能影响最小,然后依次是GAM、DRF 和SAM 模块。SAM 模块对模型的分割性能影响最强,说明SAM 模块关注的空间信息对MSF 模块提取到分割能力很强的特征很重要。
表9 模型的复杂度显示,添加MSF 模块U-Net 模型比原始U-Net 模型的参数量增加了近3 倍,每秒帧率FPS 也减少了差不多1/4。说明提出的MSF 模块在提升模型分割性能的同时,增加了模型的复杂度。另外,表9 结果还显示,MSF 模块的DRF、GAM、LAM 和SAM 模块对模型的复杂度影响都非常大,特别是大大降低了模型的效率。
综合以上分析可见,MSF 模块虽然增加了参数量,但能使模型具有更好的分割精度,并且对模型的运算实时性影响最小。
3.6 XR-MSF-Unet模型的消融实验
提出的XR-MSF-Unet 模型将U-Net 的两层卷积替换为XR 模块,并在U-Net 编码区加入注意力模块MSF。本节的消融实验,通过比较U-Net、XR+UNet、MSF+U-Net 和XR-MSF-Unet 对新冠肺炎肺 部CT图像的分割效果,验证提出的XR和MSF模块的性能。消融实验结果如表10所示,加粗表示最好结果。

表10 不同模块对U-Net模型性能影响的消融实验Table 10 Ablation experimental results of different modules on performance of U-Net
表10 实验结果显示,嵌入XR 模块的U-Net 在Dice、IOU、F1-Score 和Sensitivity 四个指标上提升了原始U-Net 对新冠肺炎CT 图像的分割性能;嵌入MSF 模块的U-Net除了F1-Score,在Dice、IOU 和Sensitivity 三个指标上提升了原始U-Net 对新冠肺炎CT 图像的分割性能;提出的同时嵌入XR、MSF 模块的XR-MSF-Unet 模型对新冠肺炎肺部CT 图像的分割效果最好。
3.7 XR-MSF-Unet模型与其他方法对比实验
为了验证提出的XR-MSF-Unet模型的性能,将其与U-Net、Attention U-Net、UNet++、FusionNet、SegNet、FCN、PraNet、BASNet、CaraNet和UNeXt十种方法进行实验比较。所有实验均在相同环境和相同划分数据集进行,实验结果如表11 所示,表中最后两列是各模型参数量和每秒帧率的比较,加粗表示最好结果。
表11 实验结果揭示,提出的XR-MSF-Unet 模型的Dice、IOU、F1-Score 和Sensitivity 各项指标均比对比模型好。XR-MSF-Unet 模型的各项指标比基准模型U-Net 分别高3.21、5.96、1.22 和4.83 个百分点。分割效果最差的是PraNet 模型,接着依次是SegNet、UNet++、FusionNet、FCN、Attention U-Net、CaraNet、UNeXt、BASNet。因此,提出的XR-MSF-Unet 模型能够实现新冠肺炎肺部CT 图像的有效分割。另外,表11 结果还显示,提出的XR-MSF-Unet 模型的参数量和每秒帧率均没有其他模型好。说明,该模型用时间换取了性能的大幅提高。对关注分割准确率的医学图像分割任务,本文的XR-MSF-Unet 模型具有实用价值。

表11 本文XR-MSF-Unet与其他方法的性能比较Table 11 Performance comparison of XR-MSF-Unet and other methods
为了清晰展示提出的XR-MSF-Unet 模型与其他方法的实验效果,随机选择了测试集中的5 张图像对分割结果进行可视化,如图8 所示。其中,第1 列是来自测试集的5 张肺部CT 原始图像,第2~12 列分别是Attention U-Net、FCN、FusionNet、SegNet、UNet++、U-Net、PraNet、BASNet、CaraNet、UNeXt和提出的XR-MSF-Unet 模型对这5 张CT 图像的分割结果,第13 列是医生标注的真实感染区域。

图8 不同方法的分割效果可视化展示Fig.8 Visualization of segmentation results of different methods
图8 各模型分割结果的可视化显示,PraNet 的分割结果最差,模糊不清。本文XR-MSF-Unet 模型的分割效果最好,能有效分割出感染区域,分割结果最接近专家标注的结果。BASNet模型的分割结果仅次于本文提出的XR-MSF-Unet模型。FCN、FusionNet、Seg-Net、U-Net 和CaraNet、UNeXt 对感染区域的分割不全,一些感染区域被忽视,且SegNet 的分割结果边界粗糙。U-Net、Attention U-Net、FusionNet、CaraNet 和UNet++的分割结果容易受肺部血管和结节等器官影响。
3.8 XR-MSF-Unet模型的泛化性测试
本节通过比较提出的XR-MSF-Unet 模型在COVID-19-1、COVID-19-2、COVID-19-3 和COVID-19-4 数据集的分割性能,测试其泛化性。各数据集均按1∶1 划分为训练集和测试集,在训练集训练模型,测试集进行测试。由于COVID-19-2、COVID-19-3、COVID-19-4 数据集较大,没有进行数据扩增,使用原始数据训练网络。实验结果见表12 所示。

表12 XR-MSF-Unet模型的泛化性能测试Table 12 Generalization test of XR-MSF-Unet model
表12 中的实验结果显示,XR-MSF-Unet 模型在COVID-19-2、COVID-19-3 和COVID-19-4 数据集均取得比在COVID-19-1 数据集更优的结果。其中,在COVID-19-3数据集的性能最好,然后依次是在COVID-19-2、COVID-19-4、COVID-19-1 的性能。由此可见,XR-MSF-Unet 模型具有很好的泛化性能。另外,表12 实验结果还显示,数据集规模越大,XR-MSF-Unet模型的性能越好,说明数据集规模越大模型学习获得的分割特征越好。
4 结束语
提出了自动分割新冠肺炎肺部CT 图像的新模型XR-MSF-Unet,该模型提出了XR 模块来增强模型的特征提取能力,提出了融合多尺度特征的即插即用注意力模块MSF 来提取新冠肺炎肺部CT 图像的细节特征。
新冠肺炎CT 图像公开数据集的大量实验测试验证了提出的XR 模块和MSF 模块的性能,并验证了提出的XR-MSF-Unet 模型是实现新冠肺炎肺部CT图像感染区域端到端自动分割的良好模型。
尽管如此,XR-MSF-Unet 模型的分割性能还有很大提升空间。另外,模型nnU-Net在医学图像分割领域展示了很好的性能,未来可以结合nnU-Net 模型的设计思路对XR-MSF-Unet 模型进行改进;除此之外,还需要进一步在模型优化、损失函数构造以及数据扩增方法等方面进行探索,提升模型对新冠肺炎CT 图像分割的准确性以及实时性;并尝试将提出的模块与nnU-Net 模型结合,实现更好的新冠肺炎CT 图像端到端分割,辅助医生进行快速准确的诊断。
